

为了应对上述挑战,研究者们从特征提取、模型结构、注意力机制等多个角度进行深入探索. 在特征提取技术方面,Zou等[3]提出全尺度特征融合模块(AF-module),通过整合编码器与解码器的全局信息,显著增强了模型在复杂环境下的适应能力. Lu等[4]构建多尺度残差学习全局感知模型(GAMS-Net),有效捕捉了空间上下文与通道依赖性,提升了道路识别性能. 在模型结构优化中,Zhang等[5]将ResNet与U-Net框架相结合,借助丰富的跳跃连接促进信息传播. Xu等[6]提出模仿学习算法iCurb,通过模拟道路顶点与边缘特征,实现中心线提取. Liu等[7]在Faster R-CNN中嵌入注意力机制,通过融合多尺度特征提升了检测精度. 此外,注意力机制与全局建模成为研究热点. Chen等[8]设计双分支编码器并配合区域注意力模块(RANM),以拟合道路形态. Xu等[9]构建基于空间注意力的提取模型,融合道路与建筑物的全局信息. Wang等[10]利用非局部操作建模全局与局部特征关系,以提升分割效果. Qi等[11]提出动态蛇形卷积(DSC),在编解码器间引入可学习空间变换模块,显著增强了复杂场景下的道路提取能力.
尽管现有方法在不同方面取得了成效,但难以兼顾多分辨率影像与复杂拓扑结构的问题仍未完全解决,基于此,本文提出多尺度分辨率与带状特征融合网络(MSRSF-Net). 本文工作的主要创新如下. 1)设计多向带状注意力机制(MDSA),通过多方向带状卷积与方形卷积的特征融合,增强对道路关键区域的感知能力. 2)构建双分支多分辨率特征融合编码器(MRFF),将注意力机制与跨分辨率加权融合,提升模型对不同分辨率影像的适应性. 3)提出多向带状特征还原解码器(MDSR),采用带状转置卷积还原道路拓扑结构,通过多方向特征融合提高道路重建的质量.
1. 相关架构
基于改进的U-Net架构提出MSRSF-Net,该网络的核心创新在于编码器-解码器结构的协同优化,如图1所示. 其中,S为步长,P为填充的像素点数,D为空洞率. 编码器部分引入MDSA,通过带状卷积核提取道路的方向特征. 结合MRFF,实现跨尺度特征融合,以增强模型的鲁棒性. 解码器部分引入MDSR,利用带状转置卷积操作重建道路拓扑结构,从而显著提升提取结果的完整性与几何连贯性.
图 1
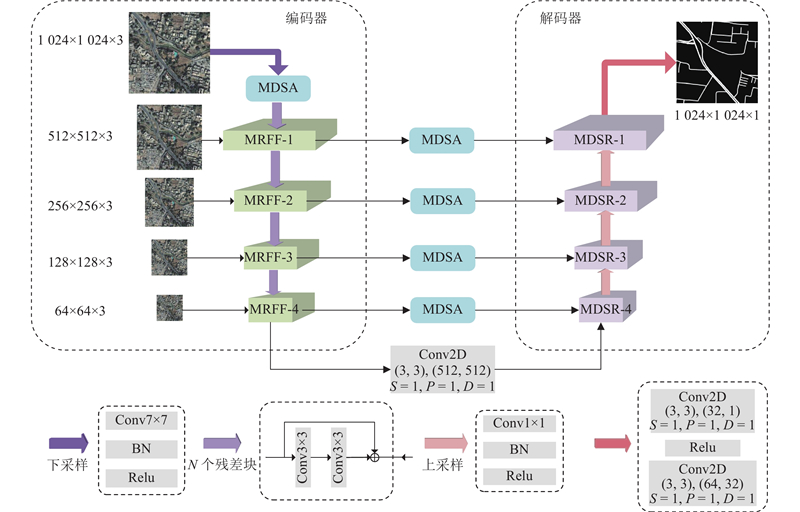
图 1 多尺度分辨率及带状特征融合的 U 型网络
Fig.1 U-network with multi-scale resolution and fusion of strip feature
1.1. 多向带状注意力机制
图 2
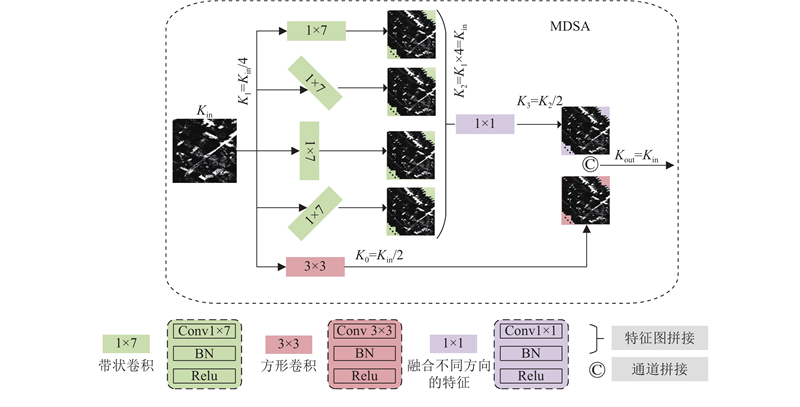
MDSA采用水平、垂直及左、右对角线4个方向的带状卷积核,并行提取道路特征. 针对斜向特征的提取,通过对输入图像进行特定角度的旋转后执行卷积操作实现. 具体而言,2个斜向带状卷积使用旋转图像的思想,即在进行卷积操作前先将图像顺时针旋转
MDSA模块借鉴残差网络的架构,处理流程如下. 输入特征图
式中:
将
1.2. 多分辨率特征融合编码器
遥感影像分辨率的差异会导致特征提取结果产生显著偏差[13],而现有的道路提取方法普遍存在多尺度特征建模不足的问题. 设计多分辨率特征融合编码器(multi-resolution feature fusion encoder, MRFF),通过构建跨尺度特征交互机制,实现不同分辨率遥感图像特征的多尺度融合.
图 3
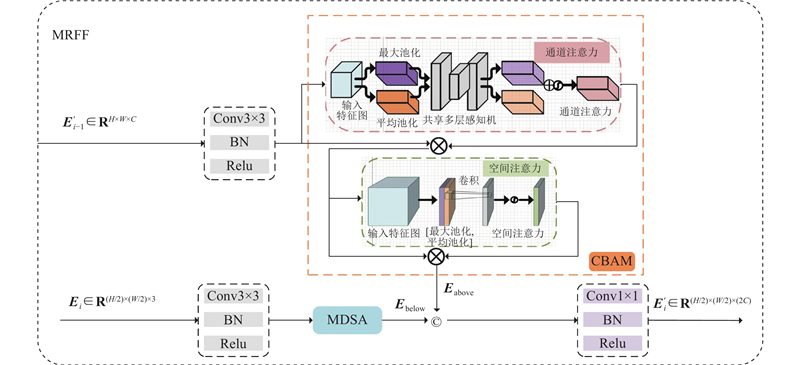
MRFF的上分支对输入特征图
式中:
2个分支的输出经拼接和卷积降维,形成兼具局部细节与全局语义的特征表示
1.3. 多向带状特征还原解码器
针对现有的解码架构在道路拓扑特征重建中的不足,提出多向带状特征还原解码器(multi-directional strip reconstruction decoder, MDSR). 传统的方形转置卷积因几何结构与道路走向不匹配,易导致边缘锯齿伪影,而带状卷积的感受野与道路线性特征更契合,能够有效地提升几何还原精度.
MDSR解码器通过4个方向的带状转置卷积提取多角度道路特征,并整合上下文信息,以恢复全局道路结构. 该模块进一步融合带状卷积与方形卷积的不同特征,有效提升对复杂拓扑(如交叉口)及遮挡场景的建模能力. 通过卷积层降维处理,在通道维度拼接所有方向的特征,最终通过转置卷积层融合多方向信息,输出重建后的道路特征. 模块通过融合4个方向上的上下文特征及局部特征,增强传递给解码器的特征图,使解码器更加聚焦于道路特征. 整个网络的解码过程包含4个结构相同的解码模块,其中1个解码模块的示意图如图4所示.
图 4
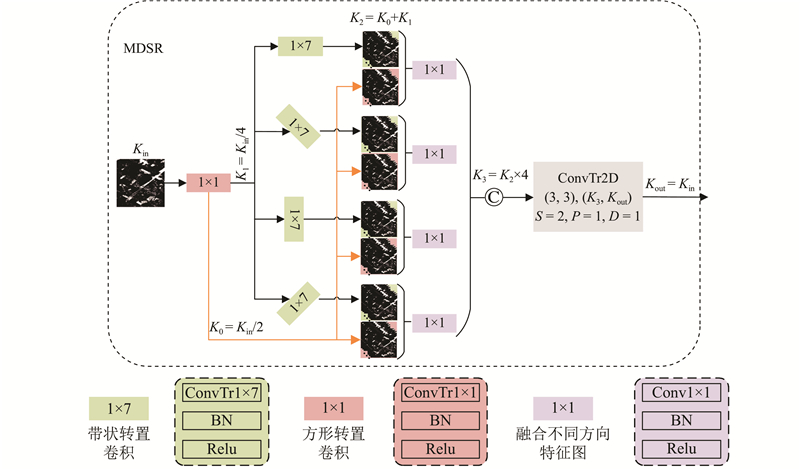
在MDSR的处理流程中,使用4个方向的带状转置卷积提取多角度道路特征,分别得到4个方向的特征表示(记为
式中:
2. 实验与分析
2.1. 数据集
选用DeepGlobe[16]、Massachusetts[17]和SpaceNet[18]3个公开遥感道路提取数据集,开展性能验证. 为了全面地评估模型性能,对MSRSF-Net与当前主流的先进模型进行对比分析. 各数据集的具体配置如下. DeepGlobe(DP)数据集包含11 206张
为了保证输入尺寸的一致性并充分利用图像的上下文信息,对所有的数据集采用统一的预处理流程. 将原始图像裁剪为1 024×1 024像素子图. 具体而言,Massachusetts数据集采用重叠裁剪策略,水平与垂直方向各重叠548像素. SpaceNet数据集采用重叠裁剪策略,水平与垂直方向的重叠像素数为784. 该预处理方案不仅实现了多源数据的尺寸统一,而且通过保留相邻区域的上下文信息,增强了模型对道路结构的理解能力,有助于提升模型的泛化性能.
2.2. 评价指标
在模型评估阶段,使用精确度P、召回率R、
式中:
2.3. 实验设置
在64位Windows 10操作系统环境下开展实验,硬件配置采用NVIDIA GeForce RTX
式中:
2.4. 消融实验
表 1 在DeepGlobe数据集上开展的不同模块消融实验
Tab.1
| 实验编号 | Baseline | MDSA | MRFF | MDSR | P/% | R/% | F1/% | IoU/% |
| 1 | √ | — | — | — | 70.17 | 66.53 | 68.31 | 51.86 |
| 2 | √ | √ | — | — | 76.20 | 74.51 | 75.34 | 60.45 |
| 3 | √ | — | √ | — | 77.72 | 77.83 | 77.77 | 63.63 |
| 4 | √ | √ | √ | — | 78.67 | 77.69 | 78.18 | 64.18 |
| 5 | √ | √ | √ | √ | 78.92 | 77.87 | 78.39 | 64.46 |
表 2 在Massachusetts数据集上开展的不同模块消融实验
Tab.2
| 实验编号 | Baseline | MDSA | MRFF | MDSR | P/% | R/% | F1/% | IoU/% |
| 1 | √ | — | — | — | 67.24 | 61.55 | 64.26 | 47.34 |
| 2 | √ | √ | — | — | 71.89 | 65.52 | 68.54 | 52.14 |
| 3 | √ | — | √ | — | 74.70 | 68.28 | 71.34 | 55.56 |
| 4 | √ | √ | √ | — | 78.86 | 66.87 | 72.37 | 56.70 |
| 5 | √ | √ | √ | √ | 76.58 | 69.14 | 72.68 | 57.11 |
表 3 在SpaceNet数据集上开展的不同模块消融实验
Tab.3
| 实验编号 | Baseline | MDSA | MRFF | MDSR | P/% | R/% | F1/% | IoU/% |
| 1 | √ | — | — | — | 65.68 | 68.51 | 67.05 | 50.44 |
| 2 | √ | √ | — | — | 69.93 | 71.58 | 70.72 | 54.70 |
| 3 | √ | — | √ | — | 72.16 | 75.28 | 73.69 | 58.34 |
| 4 | √ | √ | √ | — | 75.48 | 73.12 | 74.28 | 59.09 |
| 5 | √ | √ | √ | √ | 73.96 | 76.03 | 74.98 | 59.98 |
实验2在基准模型的基础上引入MDSA注意力机制,3个数据集的F1分数分别提升了7.03%、4.28%和3.67%,IoU分别提升了8.59%、4.80%和4.26%,表明该模块能够有效增强模型对道路特征的聚焦能力,显著改善提取完整性. 实验3在基准模型的基础上引入 MRFF编码器,
2.5. 对比实验
为了验证所提出模型在不同分辨率遥感图像上的有效性,将所提MSRSF-Net与7种主流的道路提取模型进行对比,包括 UNet++、DeepLabV3+、TransRoadNet、SGCNet、CARNet、RoadFormer和StripUnet[23].
所选的对比模型分别代表了不同技术路线的最新进展. UNet++通过嵌套密集跳跃连接重构编解码路径,提升特征融合效率,缓解梯度消失. DeepLabV3+融合空洞空间金字塔池化与编解码结构,在扩大感受野的同时,保留边缘细节. TransRoadNet首次将 Transformer结构引入道路提取任务,利用自注意力机制建模全局道路拓扑依赖关系. RoadFormer构建双分支Transformer架构,通过跨模态注意力融合RGB与几何特征,增强复杂场景下的鲁棒性. StripUnet提出使用条带卷积替代标准卷积,针对道路线性特征优化计算模式,实现高效推理. 这些模型从密集连接、多尺度融合、全局建模等不同角度推动了道路提取性能的提升.
图 5

图 5 MSRSF-Net 与其他几种先进的模型可视化结果对比
Fig.5 Comparison of visualization result of MSRSF-Net with several other advanced models
表4~6的定量分析表明,MSRSF-Net在R、
表 4 在DeepGlobe数据集上所提模型与其他几种先进的道路提取方法对比
Tab.4
| 方法 | P/% | R/% | F1/% | IoU/% | APLS/% |
| Unet++(2018) | 76.42 | 74.44 | 75.41 | 60.53 | 64.50 |
| DeepLabV3+(2018) | 79.60 | 85.92 | 81.43 | 70.21 | 67.96 |
| SGCNet(2022) | 72.78 | 66.98 | 69.76 | 53.57 | 57.39 |
| TransRoadNet(2022) | 81.01 | 84.13 | 82.53 | 70.20 | 67.00 |
| CARNet(2023) | 81.08 | 86.25 | 83.58 | 71.76 | 68.69 |
| RoadFormer(2024) | 83.86 | 85.36 | 84.61 | 73.38 | 69.62 |
| StripUnet(2024) | 82.82 | 85.32 | 84.05 | 72.04 | 68.46 |
| MSRSF-Net(本文模型) | 83.92 | 85.85 | 84.87 | 73.76 | 69.78 |
表 5 在Massachusetts数据集上所提模型与其他几种先进的道路提取方法对比
Tab.5
| 方法 | P/% | R/% | F1/% | IoU/% | APLS/% |
| Unet++(2018) | 78.79 | 60.69 | 68.61 | 52.08 | 59.25 |
| DeepLabV3+(2018) | 75.88 | 76.34 | 75.36 | 61.29 | 55.11 |
| SGCNet(2022) | 74.05 | 63.76 | 68.52 | 52.12 | 49.53 |
| TransRoadNet(2022) | 78.75 | 81.24 | 79.98 | 66.67 | 56.67 |
| CARNet(2023) | 79.02 | 81.73 | 80.35 | 67.21 | 56.80 |
| RoadFormer(2024) | 79.95 | 81.79 | 80.87 | 68.46 | 57.16 |
| StripUnet(2024) | 80.81 | 81.52 | 81.16 | 68.18 | 59.81 |
| MSRSF-Net(本文模型) | 80.80 | 82.14 | 81.46 | 68.57 | 60.27 |
表 6 在SpaceNet数据集上所提模型与其他几种先进的道路提取方法对比
Tab.6
| 方法 | P/% | R/% | F1/% | IoU/% | APLS/% |
| Unet++(2018) | 73.30 | 66.91 | 70.01 | 53.85 | 59.04 |
| DeepLabV3+(2018) | 72.85 | 72.55 | 72.70 | 57.10 | 61.27 |
| SGCNet(2022) | 73.96 | 68.75 | 71.27 | 55.56 | 60.73 |
| TransRoadNet(2022) | 74.63 | 74.36 | 70.83 | 54.84 | 61.29 |
| CARNet(2023) | 74.68 | 73.44 | 72.05 | 57.31 | 61.38 |
| RoadFormer(2024) | 74.35 | 75.73 | 74.88 | 58.91 | 61.45 |
| StripUnet(2024) | 75.07 | 74.48 | 74.06 | 58.82 | 62.09 |
| MSRSF-Net(本文模型) | 74.96 | 76.03 | 74.77 | 59.98 | 62.17 |
表 7 模型复杂度的分析
Tab.7
| 方法 | Np /106 | FLOPs/109 | v/(帧·s−1) | t/ms |
| DeepLabV3+(2018) | 54.71 | 82.73 | 15.74 | 66.67 |
| RoadFormer(2024) | 31.48 | 174.47 | 11.76 | 89.39 |
| StripUnet(2024) | 29.57 | 75.78 | 18.46 | 37.41 |
| MSRSF-Net(本文模型) | 34.61 | 60.20 | 16.67 | 35.12 |
综上所述,MSRSF-Net在多个不同分辨率数据集上的综合表现验证了该方法在道路提取任务中具有优异的鲁棒性与泛化能力. 其中,MRFF与MDSR模块的协同设计在保持模型轻量化的同时,有效提升了道路提取的精度与拓扑完整性,为遥感图像道路解析提供了可靠的解决方案.
3. 结 语
提出融合多尺度分辨率与带状特征的U型网络架构MSRSF-Net,旨在解决遥感图像道路提取结果不完整的问题. MSRSF-Net通过引入创新模块,显著提升了道路提取的完整性和鲁棒性. 其中,MDSA采用多个方向的带状卷积核捕获道路拓扑结构,通过多尺度特征融合框架进行语义信息提取,利用融合卷积层对特征进行聚合. MRFF结合带状特征提取策略与双注意力机制抑制背景干扰,实现多尺度语义聚合. MDSR通过带状转置卷积核还原道路特征间的复杂拓扑关系,利用方向约束保持拓扑连贯性,从而有效提高提取结果的完整性. 实验结果表明,MSRSF-Net在多个流行数据集(DeepGlobe、Massachusetts和SpaceNet)上展现出显著优势,在关键评价指标APLS上优于现有的主流模型.
尽管MSRSF-Net在准确性方面表现优异,但是训练与推理时间仍需进一步的优化,以达到更快的收敛速度. 未来的研究将侧重于优化算法的计算速度,以实现更快的训练过程,并深入研究如何在保持高精度的同时提高效率,从而推动遥感图像道路提取技术在现实生活中的应用.
参考文献
基于地理国情普查高分辨率遥感影像的道路提取方法研究
[J].
Study on the extraction method of geographical conditions survey of high resolution remote sensing image based road
[J].
Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning
[J].DOI:10.1109/TMI.2016.2528162 [本文引用: 1]
GAMSNet: globally aware road detection network with multi-scale residual learning
[J].DOI:10.1016/j.isprsjprs.2021.03.008 [本文引用: 1]
Road extraction by deep residual U-Net
[J].DOI:10.1109/LGRS.2018.2802944 [本文引用: 1]
iCurb: imitation learning-based detection of road curbs using aerial images for autonomous driving
[J].DOI:10.1109/LRA.2021.3056344 [本文引用: 1]
DBRANet: road extraction by dual-branch encoder and regional attention decoder
[J].
MSACon: mining spatial attention-based contextual information for road extraction
[J].
NL-LinkNet: toward lighter but more accurate road extraction with nonlocal operations
[J].
A multiscale and multi-direction feature fusion network for road detection from satellite imagery
[J].
Multi-scale feature fusion and transformer network for urban green space segmentation from high-resolution remote sensing images
[J].DOI:10.1016/j.jag.2023.103514 [本文引用: 1]
Transferable contextual network for rural road extraction from UAV-based remote sensing images
[J].DOI:10.3390/s25051394 [本文引用: 1]
Road extraction from remote sensing images using a skip-connected parallel CNN-transformer encoder-decoder model
[J].DOI:10.3390/app15031427 [本文引用: 1]
MSFANet: multiscale fusion attention network for road segmentation of multispectral remote sensing data
[J].DOI:10.3390/rs15081978 [本文引用: 1]
CAFormer: a connectivity-aware vision transformer for road extraction from remote sensing images
[J].DOI:10.1007/s00371-025-03849-1 [本文引用: 1]
Optimising deep learning models for ophthalmological disorder classification
[J].DOI:10.1038/s41598-024-75867-3 [本文引用: 1]
Defect detection in manufacturing: an integrated deep learning approach
[J].DOI:10.4236/jcc.2024.1210011 [本文引用: 2]
Weakly supervised instance segmentation via class double-activation maps and boundary localization
[J].DOI:10.1016/j.image.2024.117150 [本文引用: 1]
StripUnet: a method for dense road extraction from remote sensing images
[J].DOI:10.1109/TIV.2024.3393508 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}