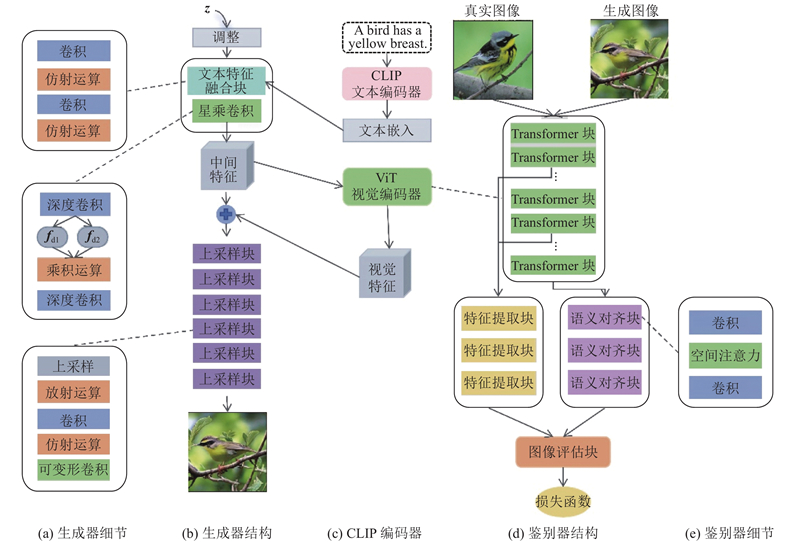
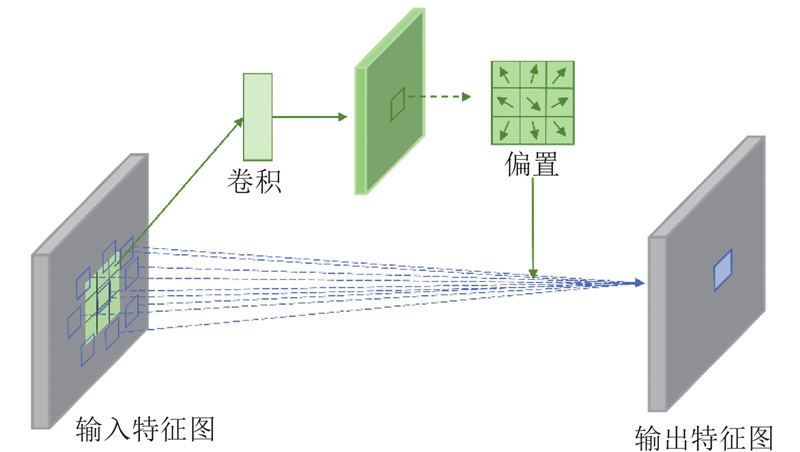
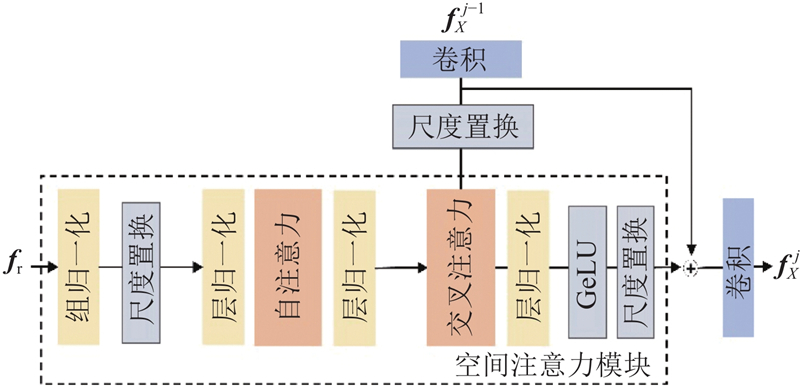
A new method was proposed to address text-image semantic inconsistencies and detail deficiencies in text-to-image generation. A discrimination mechanism was established that integrates real-image semantics with textual descriptions, mitigating text’s inherent information sparsity to alleviate detail omission or distortion in synthesized images. Deformable and star product convolutions were incorporated into a generator, enhancing the structural adaptability of the generator to improve fine-grained rendering and overall fidelity. To validate the effectiveness of the proposed method, model training and evaluation were conducted on the CUB and COCO datasets. Compared to generative adversarial networks trained with contrastive language-image pretraining (GALIP), the proposed method offers significant advantages in detail representation, semantic consistency, and overall image quality, while achieving efficient generation.
YANG Bing, ZHOU Jiahui, YAO Jinliang, XIANG Xueqin. Text-to-image generation method based on multimodal semantic information. Journal of Zhejiang University(Engineering Science)[J], 2026, 60(2): 360-369 doi:10.3785/j.issn.1008-973X.2026.02.014
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. [S.1.]: MIT Press, 2014: 2672–2680.
QIAO T, ZHANG J, XU D, et al. MirrorGAN: learning text-to-image generation by redescription [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 1505–1514.
TAO M, TANG H, WU F, et al. DF-GAN: a simple and effective baseline for text-to-image synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16494–16504.
TAO M, BAO B K, TANG H, et al. GALIP: generative adversarial CLIPs for text-to-image synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 14214–14223.
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the International Conference on Machine Learning. [S.l.]: ICLR, 2021: 748−763.
MA X, DAI X, BAI Y, et al. Rewrite the stars [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5694–5703.
XIONG Y, LI Z, CHEN Y, et al. Efficient deformable ConvNets : rethinking dynamic and sparse operator for vision applications [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5652−5661.
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// Proceedings of the 33rd International Conference on International Conference on Machine Learning. [S.l.]: ACM, 2016: 1060–1069.
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5908–5916.
ZHOU Y, ZHANG R, CHEN C, et al. Towards language-free training for text-to-image generation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 17886–17896.
RAMESH A, DHARIWAL P, NICHOL A, et al. Hierarchical text-conditional image generation with CLIP latents [EB/OL]. (2022−04−13)[2024−12−23]. https://arxiv.org/pdf/2204.06125.
VASWAMI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. [S.l.]: Curran Associates Inc. , 2017: 6000–6010.
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. (2021−06−03)[2024−12−23]. https://arxiv.org/pdf/2010.11929.
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770–778.
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. [S.l.]: ACM, 2017: 6629–6640.
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. [S.l.]: ACM, 2016: 2234–2242.
GU S, CHEN D, BAO J, et al. Vector quantized diffusion model for text-to-image synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 10686–10696.
GAFNI O, POLYAK A, ASHUAL O, et al. Make-a-scene: scene-based text-to-image generation with human priors [C]// Computer Vision – ECCV 2022. [S.l.]: Springer, 2022: 89–106.
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 10674–10685.
XU Y, ZHAO Y, XIAO Z, et al. UFOGen: you forward once large scale text-to-image generation via diffusion GANs [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 8196–8206.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}