

随着机械设备结构设计的日益复杂以及功能配置的不断增强,准确预测设备的剩余使用寿命(remaining useful life, RUL)已成为预测和健康管理(prognostics and health management, PHM)应用部署的重大挑战[1-3]. 数据驱动的RUL预测方法,比如卷积神经网络(CNN)和循环神经网络(RNN)等深度学习模型,已成为当前研究的焦点. 其中,时序卷积网络[4-5]和自注意力机制[6-8]等变体拥有更大的感受野,可以有效捕获长期时序特征,因而被广泛研究. 在工业场景中,同类设备或相似设备在不同的工作条件和服役环境下的退化过程存在差异,产生了具有多种退化特征的异构工况数据. 如何利用退化信息完整的旧工况数据(源域数据)构建高精度预测网络,并将其有效迁移至退化信息稀疏的新工况数据(目标域数据)以实现RUL预测,是跨工况寿命预测的核心问题. 传统的RUL预测模型难以解决数据分布偏移的跨工况预测问题;虽然域适应技术可以提供一定的解决方案[9-10],但是仍然面临着数据难以被充分利用和受限于隐私保护的挑战.
常见的域适应方法包括域距离度量方法和域对抗方法,分别用于减少源数据和目标数据之间的域距离,以及提取域不变特征. 王昊等[11]建立轴承故障迁移诊断模型,综合利用最大均值差异(maximum mean discrepancy, MMD)和距离方差衡量不同分布的差异,并改进膨胀卷积神经网络以提取信号中的多尺度泛化特征. Wu等[12]提出用于跨域RUL预测的加权对抗损失函数,使对抗模型不同域中具有相似RUL的样本对齐. 蔡伟立等[13]提出基于动态对抗域适应的迁移学习方法,该方法能够快速搭建新加工工艺条件下的刀具剩余寿命预测模型. 这些域适应方法大多聚焦于无监督域适应,其中目标域完全无标记,只有源域有完整标签. 但是在工业场景中,工厂在试运行或前期运行时已经积累少量目标域标签数据,无监督方法难以利用目标域的标签数据实现预测精度的提升. 而半监督域适应方法在使用源域的完整标签数据的基础上,能够充分利用目标域的稀疏标签数据辅助域适应,显著提升了域适应效率和目标域预测精度.
在工业生产中,与传感信号耦合的实际设备通常分布在相互独立的不同工厂中. 目前研究通常假设传感数据可以被同时获取,但是由于数据安全和隐私保护方面的要求,各工厂不愿直接共享传感器数据,因此当前域适应研究中假设的数据集中训练范式和各工厂无限通信模式,在实际应用中难以实现. 联邦学习的提出为解决该隐私保护问题提供了有效途径[14-15]. 在联邦学习中,中央服务器对来自不同客户端、在本地训练的模型执行平均操作以获得全局优化模型,在确保预测精度的同时实现了数据不出本地的隐私保护. Zhang等[16]将联邦迁移学习方法用于表面肌电手势识别,以提高识别准确性,同时保护隐私. 刘翀赫等[17]通过将去中心化学习和分层联邦学习相结合,构建基于无线设备直通网络的分层联邦学习框架,在降低全局聚合频率的同时减少训练时间,以提高模型性能. 然而,在设备的半监督RUL预测领域,目前较少有联邦学习框架能够在数据共享下的隐私保护与本地多域可用数据的域适应之间取得平衡.
针对上述问题,设计半监督域对抗联邦协作模型(semi-supervised domain adversarial federated collaborative model, SAFCM). 在联邦框架各端差异化部署预测子模型,通过域对抗机制提取有效退化特征,利用域距离度量方法对齐不同域的标签空间,实时传输模型参数并进行动态联合加权,实现模型的异步训练与更新,最终搭建高精度隐私保护的域适应预测模型.
1. 问题描述
由于服役设备的隐私限制以及多样化工作条件,现有方法缺乏安全协作机制,难以兼顾跨工况信号的安全通信与半监督RUL预测的准确性. 域适应技术和联邦框架的集成可以克服高价值敏感信号的分布偏移,提高跨工况下隐私保护、域适应和寿命评估性能. 因此,设计SAFCM,用于实现隐私保护下高精度、高鲁棒性的跨工况半监督RUL预测,具体结构如图1所示.
图 1
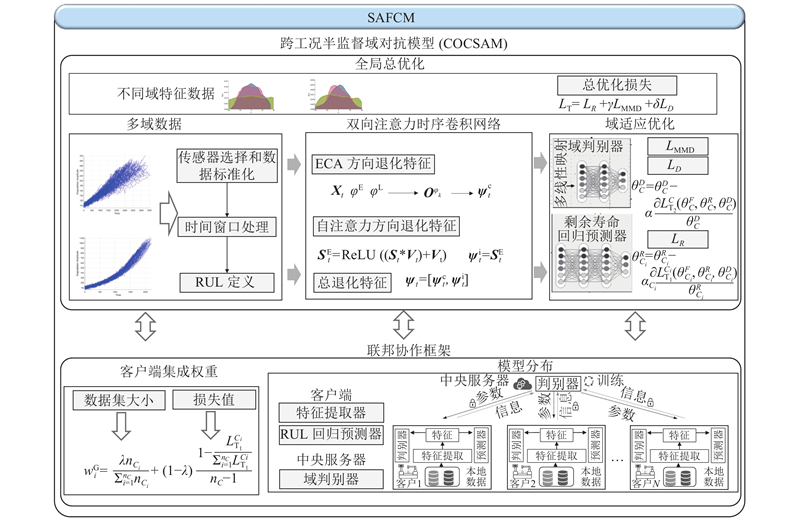
图 1 半监督域对抗联邦协作模型模型整体框架图
Fig.1 Overall framework diagram of semi-supervised domain adversarial federated collaborative model
针对域数据分布偏移和数据利用不充分的挑战,构建跨工况半监督域对抗模型(cross-operating-condition semi-supervised domain adversarial model, COCSAM),实现半监督域适应. 该模型主要包含基于双向注意力时序卷积网络的特征提取器、回归预测器和域判别器3个子模型. 针对数据隐私保护需求,构建联邦协作框架以承担中央服务端和客户端之间的通讯任务,将数据处理模式从单一数据来源扩展到协作多源聚合. 最后,以COCSAM作为训练基模型,将各子模型部署在联邦协作框架各端进行多端异步更新与聚合,实现基模型COCSAM和联邦协作框架的集成,得到整体模型SAFCM.
2. 基于COCSAM的跨工况RUL预测方法
2.1. 基于双向注意力时序卷积网络的退化特征提取器
为了增强模型对退化时变特征的提取能力,将高效通道注意力机制(efficient channel attention, ECA)[18]和自注意力机制[19]作为2个并行的方向,设计双向注意力时序卷积网络作为退化特征提取器. 将设备在时间点
对于特征提取的ECA方向,将
对于特征提取的自注意力方向,主要通过3个不同的查询(Q)、键(K)和值(V)分支提高模型对各传感器通道内特征的提取能力. 通过各分支平衡退化特征的粒度和维度,计算得到传感器通道内的注意力向量值:
式中:注意力分数矩阵
最后,将ECA方向的退化特征
2.2. 跨工况COCSAM建立
对于在跨工况下服役的设备,部分设备可能拥有大量标记信号
1) 基于双向注意力时序卷积网络的特征提取器. 将构建的卷积网络模块
2) 半监督联合域判别器. 域判别器D由多层感知(multi-layer perceptron, MLP)层和全连接层组成,旨在区分半监督联合分布,其所有可训练参数的集合定义为
3) 域不变RUL回归预测器. 回归预测器R以特征提取器的输出特征作为输入,其输出结果作为域判别器的输入数据;整体由多个全连接层组成,所有训练参数的集合定义为
2.3. COCSAM多目标平衡优化
COCSAM的多目标优化过程见图2. 首先,剩余寿命预测损失函数为
图 2
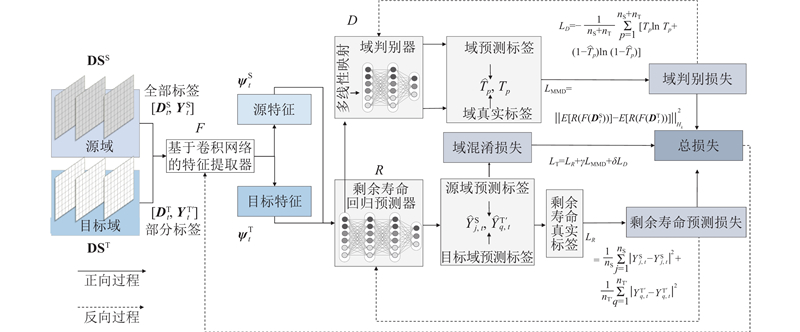
图 2 COCSAM中域适应多目标平衡优化框架
Fig.2 Domain adaptation multi-objective balanced optimization framework in COCSAM
式中:
考虑到跨工况预测任务的连续性和复杂性,进一步计算
式中:
最后,为了对齐域联合分布,将提取的特征
式中:
最终,COCSAM多目标优化总损失函数为
式中:
3. 基于联邦学习的SAFCM预测框架
3.1. 联邦协作框架
实际工业场景中,每个独立工厂在联邦学习框架中被称为客户端. 客户端记为
在SAFCM中,联邦协同框架的核心是全局参数聚合,由本地训练和协同训练2个阶段组成. 本地训练时,每个客户端
式中:局部损失
式中:
式中:
协同训练时,考虑到域判别器对半监督域对抗的重要性,将其设置在中央服务器端进行联邦训练更新,以整合更多的域分布信息,同时最大限度地避免额外的计算和通信成本. 作为式(6)、(8)的补充部分,域判别器的对抗性损失函数为
式中:
在每轮训练结束后,将
在协同训练中,需要对各客户上传的参数进行聚合加权,因此设计多维协同加权公式,通过平衡可用数据量和实时优化损失来确定每个客户端的全局交互权重系数
式中:
因此,特征提取器和回归预测器在每轮通信后更新为
3.2. 总体流程
SAFCM的总体流程如图3所示,共有3个过程. 1)预训练过程,主要对域判别器进行预训练. 2)训练过程,中央服务器随机选择比例
图 3
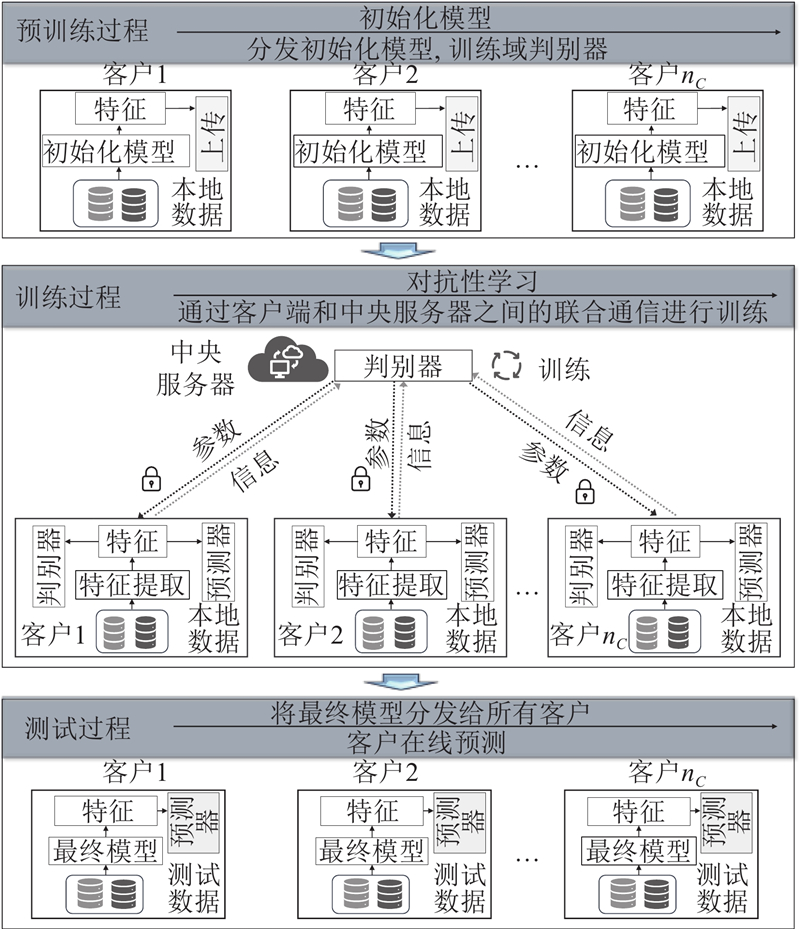
4. 实例分析
4.1. 实例一:C-MAPSS涡扇发动机数据集
4.1.1. 参数设置
实例一采用C-MAPSS涡扇发动机数据集[21],划分各客户端与中央服务器并搭建联邦通讯框架,实现基于SAFCM的RUL预测. 该数据集由4个不同的子数据集组成,包括FD001、FD002、FD003和FD004. 每个子数据集对应不同的工况条件,数据分布均不相同. 依次选取各子数据集作为源域,其余子数据集作为目标域,共形成12个源-目标对. 将所有数据划分为
1)传感器选取与数据标准化:选取前2个运行状态监测传感器和14个性能监测传感器获取的数据为原始特征[22]. 考虑到不同的运行条件,用K均值聚类和归一化方法将数据转换为统一范围.
2)时间窗口处理:采用大小为
3)RUL定义:基于分段函数为每个运行至故障的时间序列构建实际的RUL序列[23].
式中:
将处理后的训练数据按9∶1的比例随机分为训练集和验证集,利用上述指标评估不同超参数下SAFCM对每个源-目标对的预测结果,从中选取在验证集上平均效果最好的模型设置,对每轮结果运行10次取平均值,以减少随机误差的影响. SAFCM网络结构的超参数如表1所示,其中结构和层数根据数值实验结果确定,
表 1 SAFCM网络结构超参数
Tab.1
| 子模型 | |||
| 特征提取器方向一 | (5, 2) | (0.2, 0) | — |
| 特征提取器方向二 | (3, 7) | — | — |
| 域判别器 | — | (0.2, 0.2, 0.2) | (64, 32, 2) |
| 回归预测器 | — | (0.2, 0.2, 0, 0) | (64, 32, 16, 1) |
4.1.2. 效果分析
为了对COCSAM开展域适应机理研究,挖掘高维特征对目标域预测的潜在影响,对实例结果进行解释性分析. 图4展示了2组实验中高维特征值在域适应前后的概率密度分布,
图 4
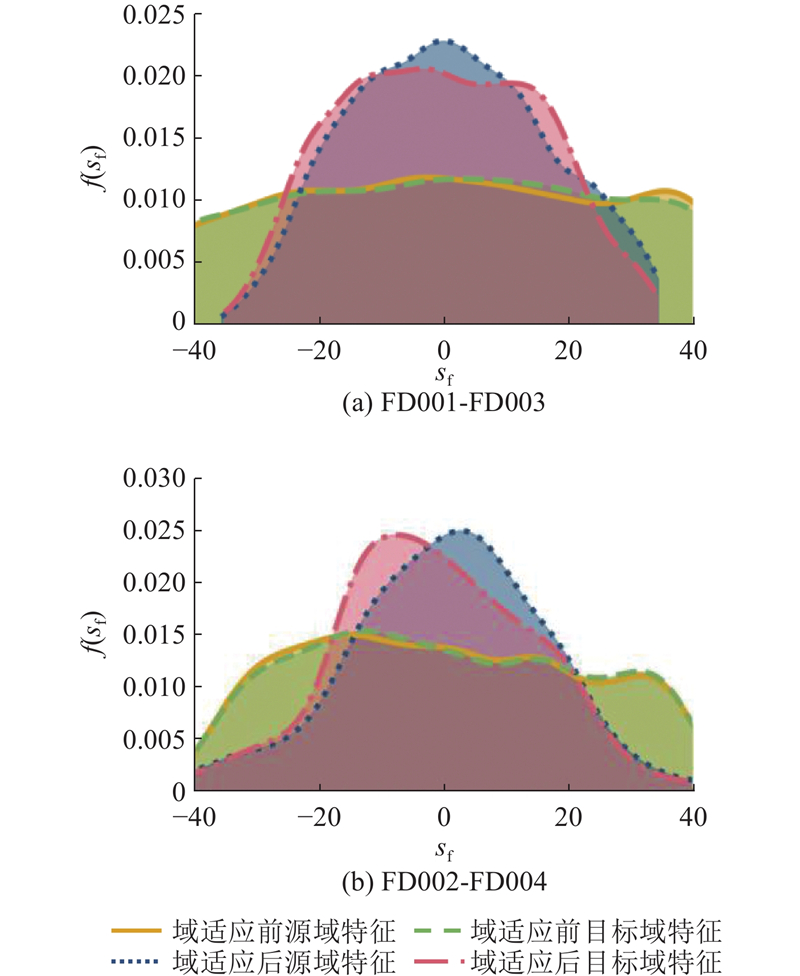
图 4 不同域特征在域适应前后的概率密度分布
Fig.4 Distribution of probability density for different domain features before and after domain adaptation
进一步地,用沙普利加性解释(Shapley additive explanations, SHAP)方法展示了不同传感器特征对COCSAM域适应影响的解释性分析,见图5,其中SHAP为衡量传感器对模型输出影响的SHAP值. 由图可知,传感器特征s11、s4、s17对预测结果的影响最大. 在其他特征中,影响最大的s3所占的影响比例不足s11的50%. 而且,排名靠前的特征同时表现出较大的正效应和负效应,说明其在不同观测值下对模型预测结果的影响差别较大且无明显规律.
图 5
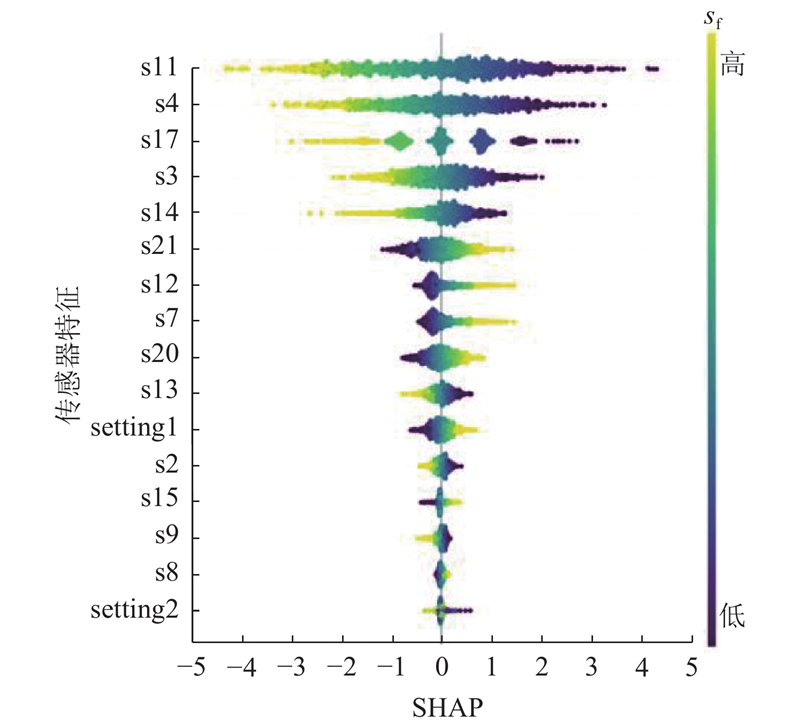
图 5 基于不同传感器特征对域适应结果的解释性分析
Fig.5 Interpretative analysis of domain adaptation results based on different sensor features
对双向注意力时序卷积网络进行消融实验,验证每个方向对特征提取的有效性,见图6. 结果表明,COCSAM的RMSE相较于单方向特征提取器D1、D2的RMSE明显降低. 例如,对于FD001-FD003,COCSAM双向网络能够比单向网络获得高达46.24%的性能改进. 此外,在所有比较实验中,COCSAM的性能表现比单向注意力方法更加稳定,有更强的鲁棒性.
图 6
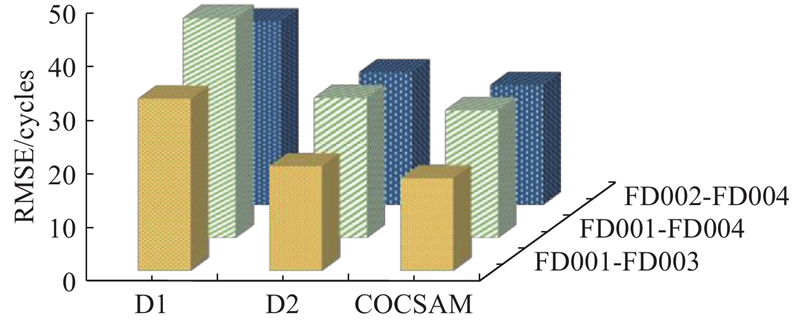
图 6 双向注意力时序卷积网络及其不同方向的变体的预测性能比较
Fig.6 Prediction performance comparison of bidirectional attention temporal convolutional network and its directional variants
将COCSAM与联邦协作框架结合并构建SAFCM后,为了验证联邦协作和域适应的有效性,将其与作为基线的源域模型和作为上限的目标域模型进行比较. 源域模型仅基于源域数据训练,而目标域模型仅基于目标域数据训练,其余设置和SAFCM相同. 跨工况适应的训练参数由网格搜索优化得到,见表2. 其中,
表 2 SAFCM网络的域适应训练超参数
Tab.2
| 参数 | 数值 | 参数 | 数值 | |
| 0.15 | 10 | |||
| 1 | 10 | |||
| 0.8 | 125 | |||
| 0.8 | 5 | |||
| 0.8 | 0.01 | |||
| 40 | (30, 20, 30, 15) |
为了方便展示,图7中高于20 000的预测Score值被统一表示为20 000,源-目标对FD001-FD002等被简化表示为1→2等. 结果显示,SAFCM在目标域上的预测结果均明显优于源域模型,且与目标域模型接近. 其中,由于FD001的故障模式较为简单,FD001作为源域的预测难度较高,但是SAFCM仍然取得了良好的预测效果,对FD004的域适应结果甚至优于目标域模型. 由于FD004数据复杂度高,仅使用其自身数据难以挖掘复杂的耦合关系,而通过域适应方法,可以借助更为简单的源域衰退模式来增强对复杂目标域的预测能力. 图7结果证明了SAFCM在联邦学习框架下具有优异的跨工况RUL预测性能.
图 7
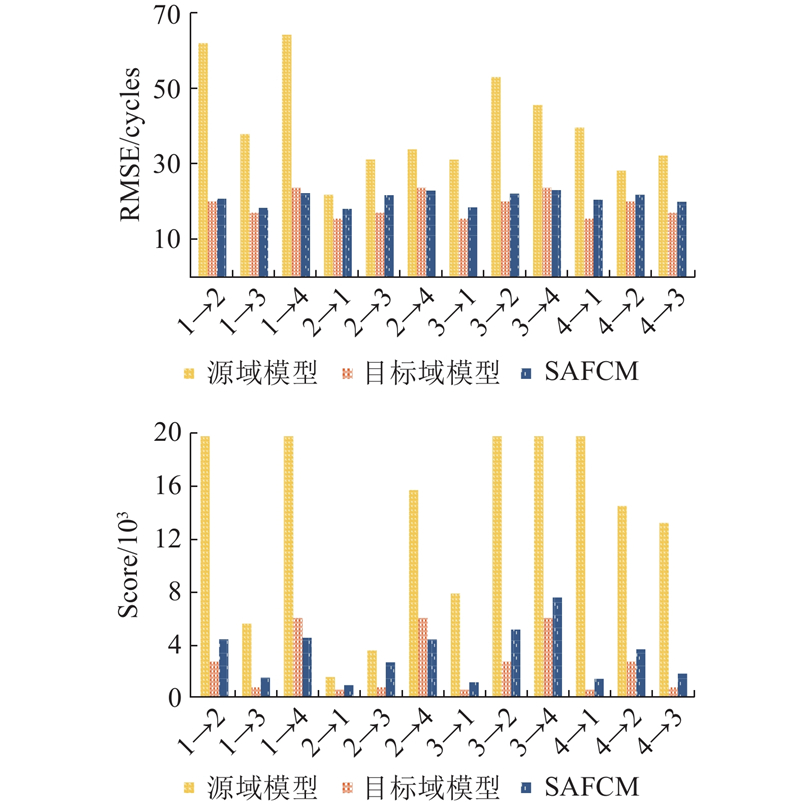
图 7 跨工况条件下不同预测模式的RUL预测结果
Fig.7 RUL prediction results of different prediction modes under cross-operating conditions
图 8
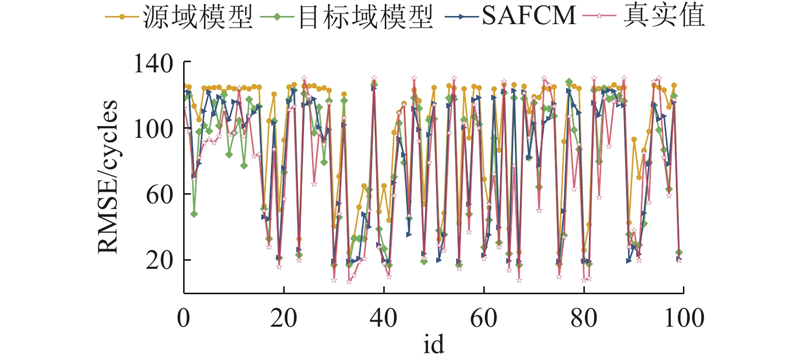
图 8 FD003-FD001任务中域适应RUL预测结果
Fig.8 Domain adaptation RUL prediction results in FD003-FD001 task
图 9
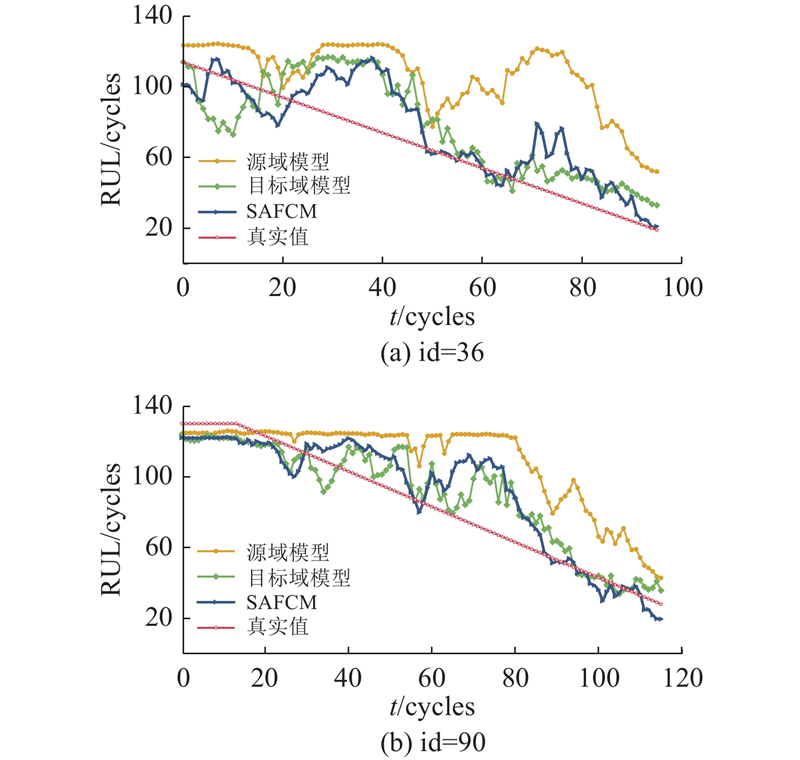
图 9 跨工况条件下采用不同发动机时的预测结果对比
Fig.9 Comparison of prediction results when adopting different engines under cross-operating conditions
为了验证模型的鲁棒性,对损失权重参数
图 10
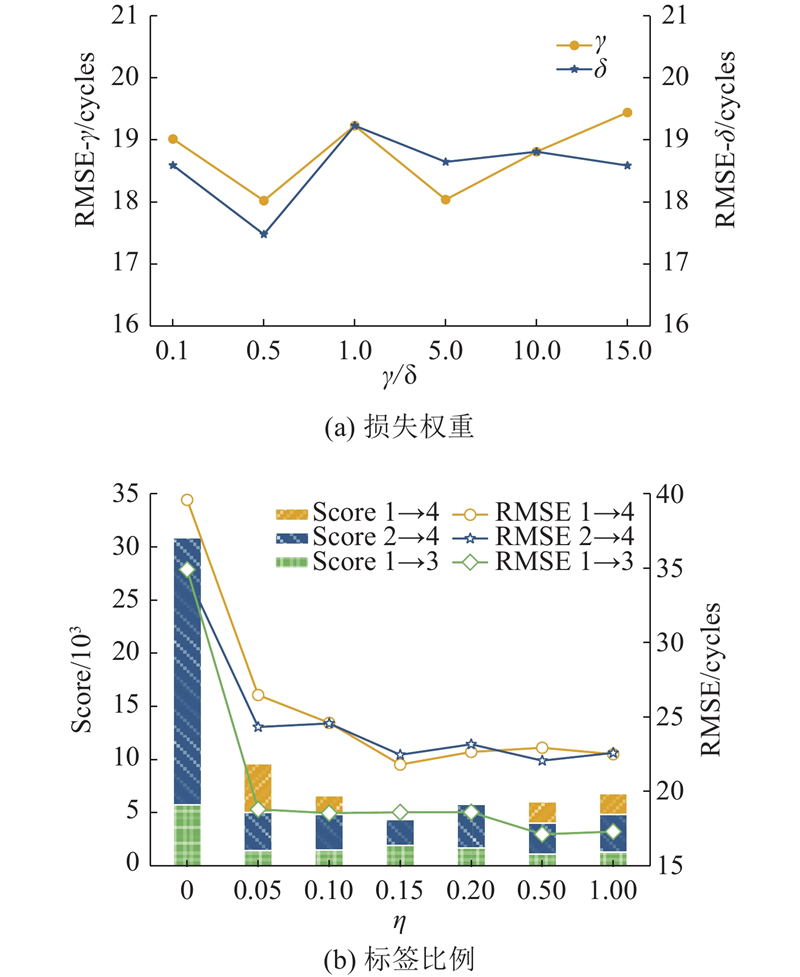
图 10 不同超参数取值下域适应结果的鲁棒性对比
Fig.10 Comparison of robustness of domain adaptation results under different hyperparameter values
通过提供不同比例
4.1.3. 性能对比
进一步地,将SAFCM与代表性的域适应方法进行比较,包括DANN[24]、CORAL[25]、CADA[26]和MCDA[27],结果如表3所示. 其中,RMSE1、RMSE2、RMSE3、RMSE4和Score1、Score2、Score3、Score4分别表示当源域为FD001、FD002、FD003、FD004时模型在不同目标域上的RMSE和Score值. 由于这些先进方法采用无监督学习并且忽略隐私保护需求,将数据集中训练,其理论结果会优于所提联邦框架的隐私保护训练模式. 为了公平比较,在这些方法的基础上加入半监督训练损失并应用到联邦协作框架中,同时确保所有方法的参数设置一致. 结果表明,SAFCM的RMSE始终表现优异;尽管Score呈指数级增长,不同方法的Score值差异较大,但是SAFCM的表现仍然良好,在相同的参数配置下表现出卓越的稳定性和预测性能. 提出的SAFCM在保证预测准确性和数据隐私保护的同时,实现了不同客户间跨工况数据的安全通信,为实际应用中的RUL预测提供了高可靠性的保障.
表 3 SAFCM与其他先进方法的域适应预测性能比较
Tab.3
| 方法 | RMSE1/cycles | RMSE2/cycles | Score1 | Score2 | |||||||||||
| FD002 | FD003 | FD004 | FD001 | FD003 | FD004 | FD002 | FD003 | FD004 | FD001 | FD003 | FD004 | ||||
| DANN[24] | 31.21 | 24.07 | 27.23 | 22.71 | 22.41 | 24.18 | 12 415.32 | 4 005.81 | 9 016.18 | 2 289.48 | 3 700.22 | 5 349.81 | |||
| CORAL[25] | 39.97 | 42.01 | 38.35 | 35.47 | 36.40 | 37.26 | 37 600.07 | 46 826.09 | 28 640.64 | 9 321.05 | 13 314.34 | 19 782.51 | |||
| CADA[26] | 33.43 | 17.90 | 29.37 | 17.42 | 20.55 | 24.89 | 19 996.12 | 1 694.28 | 11 581.88 | 822.35 | 3 008.26 | 5 511.68 | |||
| MCDA[27] | 42.19 | 39.37 | 34.57 | 37.96 | 36.44 | 37.96 | 40 147.26 | 25 641.77 | 5 382.38 | 11 059.26 | 7 686.89 | 17 670.28 | |||
| SAFCM | 20.39 | 17.89 | 21.81 | 17.73 | 21.27 | 22.47 | 4 386.66 | 1 445.38 | 4 506.43 | 863.15 | 2 626.98 | 4 372.02 | |||
| 方法 | RMSE3/cycles | RMSE4/cycles | Score3 | Score4 | |||||||||||
| FD001 | FD002 | FD004 | FD001 | FD002 | FD003 | FD001 | FD002 | FD004 | FD001 | FD002 | FD003 | ||||
| DANN[24] | 22.26 | 28.86 | 25.48 | 19.51 | 22.85 | 22.12 | 5 082.15 | 7 540.77 | 9 888.57 | 1 000.34 | 6 214.72 | 3 324.13 | |||
| CORAL[25] | 35.63 | 40.10 | 38.58 | 35.73 | 38.35 | 35.14 | 9 446.81 | 35 069.45 | 29 449.80 | 10 294.36 | 36 487.91 | 9 525.98 | |||
| CADA[26] | 20.25 | 28.69 | 30.32 | 25.51 | 23.42 | 20.34 | 1 341.10 | 11 864.96 | 12 018.76 | 2 780.70 | 7 204.24 | 3 323.91 | |||
| MCDA[27] | 35.18 | 40.87 | 40.02 | 39.33 | 40.16 | 37.08 | 5 334.81 | 42 708.90 | 45 589.35 | 17 057.24 | 52 331.20 | 11 804.43 | |||
| SAFCM | 18.06 | 21.70 | 22.64 | 20.10 | 21.43 | 19.54 | 1 086.96 | 5 133.46 | 7 608.82 | 1 350.91 | 3 622.50 | 1 745.91 | |||
4.2. 实例二:某制造系统数控机床数据集
为了进一步验证SAFCM在不同操作条件、应用场景及数据集特征下的有效性,选取某制造系统的数控机床数据集进行实例验证. 该实例基于某个发动机曲轴制造系统中的6台数控机床,分别为数控铣削中心
从机床收集的退化信号序列的总体设置见表4,N1、N2分别为训练集和测试集的样本数目,
表 4 制造系统场景中传感器信号的总体设置
Tab.4
| 子数据集 | 机床类型 | ||||||
| 数控铣削中心 | 100 | 100 | 3 633 | 2 464 | 3 691 | 2 356 | |
| 数控车床 | 100 | 100 | 4 155 | 1 552 | 4 469 | 1 715 | |
| 数控铣床 | 100 | 100 | 2 103 | 1 039 | 1 939 | 1 007 | |
| 数控打孔机 | 100 | 100 | 2 279 | 69 | 2 290 | 26 | |
| 数控随动磨床 | 100 | 100 | 2 411 | 1 553 | 2 433 | 1 587 | |
| 数控抛光机 | 100 | 100 | 4 978 | 408 | 5 543 | 554 |
考虑到C-MAPSS数据集是在不同操作条件下对同一类型的设备进行寿命预测而获得的,本实例重点研究不同操作条件下不同类型设备的寿命预测. 表5展示了最终全数据的预测均值RMSEa和最小特征距离均值dmin,并展示了其中部分域适应对的RMSE值. 其中,RMSE1、RMSE2、RMSE3、RMSE4、RMSE5和RMSE6分别表示当源域为M1~M6时在不同目标域上的RMSE值. 结果显示SAFCM提取的特征更集中、有效,RMSE预测结果优于其他先进方法,说明SAFCM可以在保护传感器信号隐私的同时,有效地减少不同操作条件下的分布偏移,实现了跨工况下多设备类型的RUL预测.
表 5 数控机床数据集的RUL预测结果
Tab.5
| 方法 | RMSE1/cycles | RMSE2/cycles | RMSE3/cycles | |||||||||
| DANN[24] | 24.94 | 23.91 | 11.49 | 46.47 | 5.95 | 26.02 | 20.36 | 28.92 | 31.79 | |||
| CORAL[25] | 28.61 | 25.25 | 16.06 | 51.45 | 13.66 | 15.67 | 16.38 | 27.17 | 27.95 | |||
| CADA[26] | 27.45 | 21.49 | 17.88 | 45.68 | 5.42 | 14.87 | 20.34 | 25.65 | 30.39 | |||
| MCDA[27] | 24.63 | 24.99 | 17.70 | 43.89 | 10.81 | 12.95 | 22.32 | 27.47 | 29.79 | |||
| SAFCM | 14.47 | 20.87 | 9.66 | 27.99 | 5.17 | 7.80 | 16.08 | 21.35 | 26.45 | |||
| 方法 | RMSE4/cycles | RMSE5/cycles | RMSE6/cycles | |||||||||
| DANN[24] | 32.94 | 66.88 | 25.78 | 48.91 | 32.74 | 18.15 | 17.30 | 223.83 | ||||
| CORAL[25] | 26.03 | 69.53 | 27.82 | 44.01 | 31.10 | 16.32 | 11.37 | 140.67 | ||||
| CADA[26] | 25.83 | 68.50 | 28.31 | 41.92 | 29.84 | 17.92 | 14.11 | 214.08 | ||||
| MCDA[27] | 25.68 | 68.10 | 27.14 | 42.77 | 24.76 | 17.61 | 13.51 | 179.29 | ||||
| SAFCM | 20.30 | 66.31 | 25.29 | 38.54 | 19.46 | 16.26 | 10.66 | 86.49 | ||||
5. 结 语
面对实际工业场景中分布式设备的多样化工作条件和隐私保护需求对RUL预测的限制,提出寿命预测模型SAFCM. 其中,COCSAM框架采用域对抗和域距离度量双重机制,以减少负迁移并增强模型对目标域的预测能力. 特征提取器采用双向注意力时序卷积网络,可以改善稀疏时间序列数据的特征表示并深度挖掘时间耦合关系;域判别器对齐跨域的联合分布,以实现跨工况数据的域适应. 为了促进设备隐私保护和实时数据传输,将COCSAM与联邦协作框架相结合,将域判别器配置在服务器端更新,而提取器和预测器在客户端本地更新. 这种半监督的异步更新方法利用有限的目标域标签显著地提高了预测准确性和域适应效率,同时实现了数据安全通讯. 在C-MAPSS数据集和制造系统机床数据集上的验证结果表明,所提方法的效果优于其他先进方法,为隐私保护下的跨工况RUL预测提供了高可靠性和可拓展的网络结构. 未来将进一步考虑设备用户数据量分布不均衡的问题,以实现更灵活的框架结构. 此外,可以基于同态加密或差分隐私算法实现加密方案的优化设计,进一步研究并降低联邦通讯的计算开销.
参考文献
Remaining useful life prediction and challenges: a literature review on the use of machine learning methods
[J].DOI:10.1016/j.jmsy.2022.05.010 [本文引用: 1]
基于多时间尺度相似性的涡扇发动机寿命预测
[J].
Remaining useful life prediction of turbofan engine based on similarity in multiple time scales
[J].
Remaining useful life estimation for LFP cells in second-life applications
[J].
Prediction of sea temperature using temporal convolutional network and LSTM-GRU network
[J].
Temporal convolutional approach with residual multi-head attention mechanism for remaining useful life of manufacturing tools
[J].DOI:10.1016/j.engappai.2023.107538 [本文引用: 1]
Dual-aspect self-attention based on Transformer for remaining useful life prediction
[J].
Remaining useful life with self-attention assisted physics-informed neural network
[J].
Multi-scale integrated deep self-attention network for predicting remaining useful life of aero-engine
[J].DOI:10.1016/j.engappai.2023.105860 [本文引用: 1]
An unsupervised dual-regression domain adversarial adaption network for tool wear prediction in multi-working conditions
[J].DOI:10.1016/j.measurement.2022.111644 [本文引用: 1]
A sparse domain adaption network for remaining useful life prediction of rolling bearings under different working conditions
[J].
一种基于改进迁移策略与膨胀卷积神经网络的轴承故障诊断方法
[J].
Bearing fault diagnosis based on improved transfer strategy and dilated convolutional neural network
[J].
Weighted adversarial domain adaptation for machine remaining useful life prediction
[J].
基于迁移学习的刀具剩余寿命预测方法
[J].
Prediction method of tool remaining useful life based on transfer learning
[J].
Research on federated learning method for fault diagnosis in multiple working conditions
[J].
A federated transfer learning approach for surface electromyographic hand gesture recognition with emphasis on privacy preservation
[J].DOI:10.1016/j.engappai.2024.108952 [本文引用: 1]
基于无线D2D网络的分层联邦学习
[J].
Hierarchical federated learning based on wireless D2D networks
[J].
Remaining useful life estimation in prognostics using deep convolution neural networks
[J].
基于选择性深度神经网络集成的涡扇发动机剩余寿命预测
[J].
Remaining useful life estimation of turbofan engine based on selective ensemble of deep neural networks
[J].
Remaining useful lifetime prediction via deep domain adaptation
[J].
Contrastive adversarial domain adaptation for machine remaining useful life prediction
[J].DOI:10.1109/TII.2020.3032690 [本文引用: 5]
A multi-constrained domain adaptation network for remaining useful life prediction of bearings
[J].DOI:10.1016/j.ymssp.2023.110900 [本文引用: 5]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}