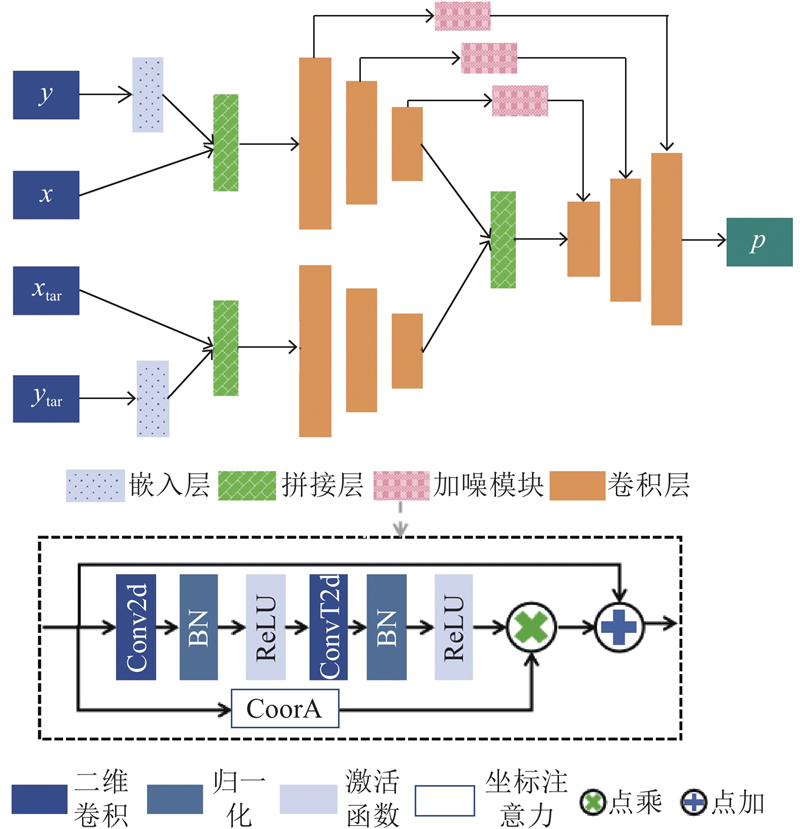
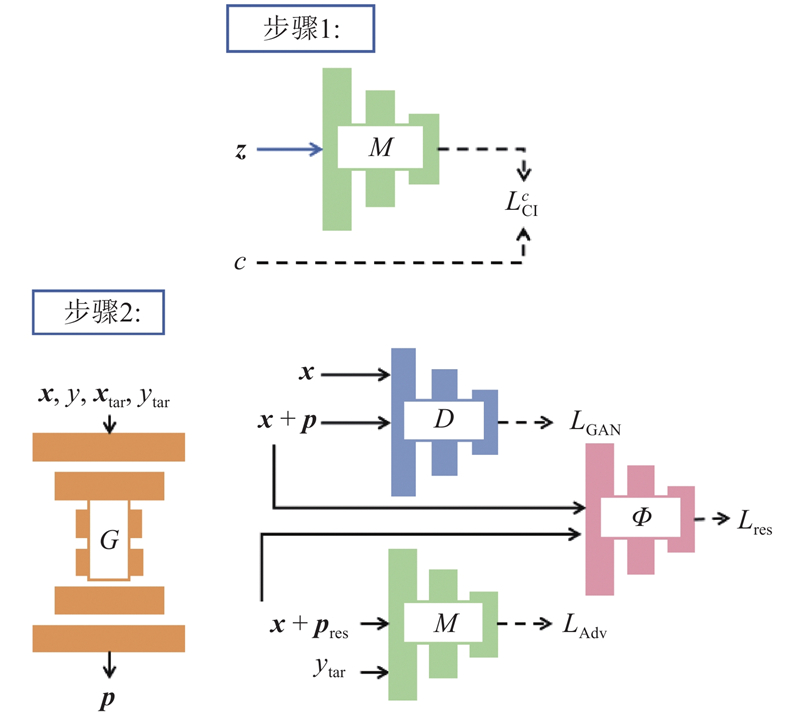
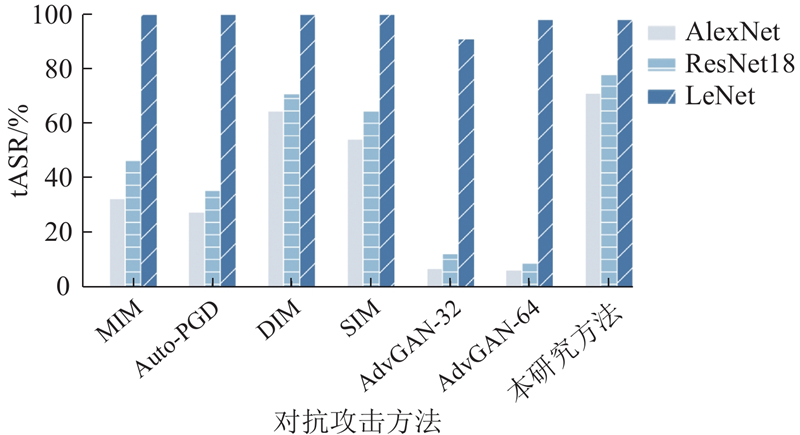
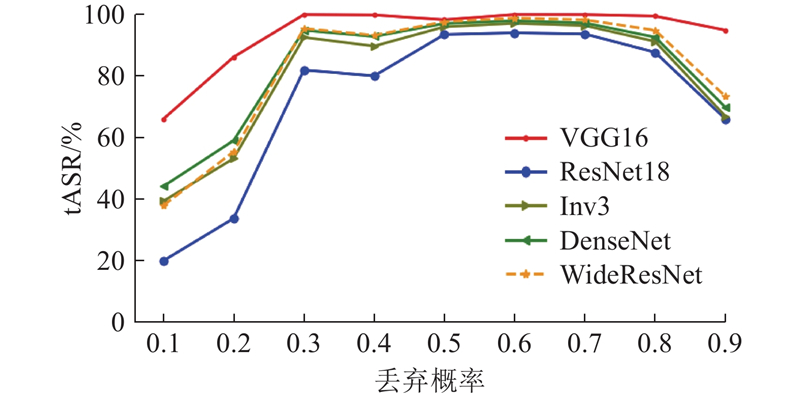
A generative adversarial attack method based on dual guidance of target class impressions and regularized adversarial examples was proposed to enhance the transferability of targeted adversarial samples. The adversarial perturbations of shallow features were generated by leveraging the skip-connection mechanism of the UNet model to improve the attack effectiveness of the adversarial samples. To improve the targeted attack success rate, the generator was guided to generate adversarial perturbations containing the features of target classes using the impression images and labels of target classes as input. The Dropout technique was employed on the generated adversarial perturbations in the training phase to reduce the dependence of the generator on surrogate models, thereby improving the generalization performance of the adversarial samples. Experimental results demonstrated that the adversarial samples generated by the proposed method exhibited significant targeted transferability on the MNIST, CIFAR10, and SVHN datasets when attacking classification models such as ResNet18 and DenseNet. The average black-box targeted attack success rate was improved by more than 1.6% compared with that of the benchmark attack method MIM, demonstrating that the adversarial samples generated by the proposed method could evaluate the robustness of the deep models more effectively.
ZHAO Y, LV W, XU S, et al. DETRs beat YOLOs on real-time object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 16965–16974.
HU Y, YANG J, CHEN L, et al. Planning-oriented autonomous driving [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 17853–17862.
SZEGEDY C, ZAREMBA W, SUTSKEVER I, et al. Intriguing properties of neural networks [C]// International Conference on Learning Representations. Banff: International Machine Learning Society, 2014: 1-10.
DONG Y, LIAO F, PANG T, et al. Boosting adversarial attacks with momentum [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 9185–9193.
CROCE F, HEIN M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks [C]// Proceedings of the International Conference on Machine Learning. [S.l.]: JMLR. org, 2020: 2206–2216.
WANG X, HE K. Enhancing the transferability of adversarial attacks through variance tuning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 1924–1933.
PENG A, LIN Z, ZENG H, et al. Boosting transferability of adversarial example via an enhanced Euler’s method [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Rhodes Island: IEEE, 2023: 1–5.
WANG J, CHEN Z, JIANG K, et al
Boosting the transferability of adversarial attacks with global momentum initialization
[J]. Expert Systems with Applications, 2024, 255: 124757
DONG Y, PANG T, SU H, et al. Evading defenses to transferable adversarial examples by translation-invariant attacks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 4307–4316.
WU L, ZHAO L, PU B, et al. Boosting the transferability of adversarial examples via adaptive attention and gradient purification methods [C]// Proceedings of the International Joint Conference on Neural Networks. Yokohama: IEEE, 2024: 1–7.
ZHU Z, CHEN H, WANG X, et al. GE-AdvGAN: improving the transferability of adversarial samples by gradient editing-based adversarial generative model [C]// Proceedings of the 2024 SIAM International Conference on Data Mining. Houston: SIAM, 2024: 706–714.
QIAN Y, HE S, ZHAO C, et al. LEA2: a lightweight ensemble adversarial attack via non-overlapping vulnerable frequency regions [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 4487–4498.
LI M, DENG C, LI T, et al. Towards transferable targeted attack [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 638−646.
CHEN B, YIN J, CHEN S, et al. An adaptive model ensemble adversarial attack for boosting adversarial transferability [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 4466–4475.
LIN J, SONG C, HE K, et al. Nesterov accelerated gradient and scale invariance for improving transferability of adversarial examples [C]// International Conference on Learning Representations. [S.l.]: International Machine Learning Society, 2020: 1–12.
XIE C, ZHANG Z, ZHOU Y, et al. Improving transferability of adversarial examples with input diversity [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 2725–2734.
ZHAO Z, LIU Z, LARSON M. On success and simplicity: a second look at transferable targeted attacks [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. [S.l.]: NeurIPS Foundation, 2021: 6115–6128.
WU H, OU G, WU W, et al. Improving transferable targeted adversarial attacks with model self-enhancement [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 24615–24624.
XIAO C, LI B, ZHU J, et al. Generating adversarial examples with adversarial networks [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: AAAI Press, 2018: 3905–3911.
MOPURI K R, UPPALA P K, BABU R V. Ask, acquire, and attack: data-free UAP generation using class impressions [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 20–35.
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]// International Conference on Learning Representations. San Diego: ICLR, 2015: 1–14.
NETZER Y, WANG T, COATES A, et al. Reading digits in natural images with unsupervised feature learning [C]// Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning. Granada: NeurIPS Foundation, 2011: 1–9.
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770–778.
HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2261–2269
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2818–2826.
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe: NeurIPS Foundation, 2012: 1097–1105.
WANG X, HE K. Enhancing the transferability of adversarial attacks through variance tuning. [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 1924–1933.
LIN Q, LUO C, NIU Z, et al. Boosting adversarial transferability across model genus by deformation-constrained warping [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver: AAAI Press, 2024: 3459–3467.
LIU J, ZHANG C, LYU X. Boosting the transferability of adversarial examples via local mixup and adaptive step size [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Hyderabad: IEEE, 2025: 1–5.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}