[1]
王刘旺 机器视觉技术在电力安全监控中的应用综述
[J]. 浙江电力 , 2022 , 41 (10 ): 16 - 26
[本文引用: 1]
WANG Liuwang A review of the application of machine vision in power safety monitoring
[J]. Zhejiang Electric Power , 2022 , 41 (10 ): 16 - 26
[本文引用: 1]
[2]
赵振兵, 张薇, 翟永杰, 等. 电力视觉技术的概念、研究现状与展望[J]. 电力科学与工程, 2020, 36(1): 1–8.
[本文引用: 1]
ZHAO Zhenbing, ZHANG Wei, ZHAI Yongjie, et al. Concept, research status and prospect of electric power vision technology [J]. Electric Power Science and Engineering , 2020, 36(1): 1–8.
[本文引用: 1]
[3]
齐冬莲, 韩译锋, 周自强, 等 基于视频图像的输变电设备外部缺陷检测技术及其应用现状
[J]. 电子与信息学报 , 2022 , 44 (11 ): 3709 - 3720
DOI:10.11999/JEIT211588
[本文引用: 1]
QI Donglian, HAN Yifeng, ZHOU Ziqiang, et al Review of defect detection technology of power equipment based on video images
[J]. Journal of Electronics and Information Technology , 2022 , 44 (11 ): 3709 - 3720
DOI:10.11999/JEIT211588
[本文引用: 1]
[4]
闫云凤, 陈汐, 金浩远, 等 基于计算机视觉的电力作业人员行为分析研究现状与展望
[J]. 高电压技术 , 2024 , 50 (5 ): 1842 - 1854
[本文引用: 1]
YAN Yunfeng, CHEN Xi, JIN Haoyuan, et al Research status and development of computer-vision-based power workers’ behavior analysis
[J]. High Voltage Engineering , 2024 , 50 (5 ): 1842 - 1854
[本文引用: 1]
[5]
陈佛计, 朱枫, 吴清潇, 等 生成对抗网络及其在图像生成中的应用研究综述
[J]. 计算机学报 , 2021 , 44 (2 ): 347 - 369
DOI:10.11897/SP.J.1016.2021.00347
[本文引用: 1]
CHEN Foji, ZHU Feng, WU Qingxiao, et al A survey about image generation with generative adversarial nets
[J]. Chinese Journal of Computers , 2021 , 44 (2 ): 347 - 369
DOI:10.11897/SP.J.1016.2021.00347
[本文引用: 1]
[6]
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks
[J]. Communications of the ACM , 2020 , 63 (11 ): 139 - 144
DOI:10.1145/3422622
[本文引用: 1]
[7]
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver: NeurIPS Foundation, 2020: 6840–6851.
[本文引用: 1]
[8]
NICHOL A, DHARIWAL P, RAMESH A, et al. GLIDE: towards photorealistic image generation and editing with text-guided diffusion models [EB/OL]. (2022−03−08) [2025−01−14]. https://arxiv.org/abs/2112.10741.
[本文引用: 1]
[9]
SAHARIA C, CHAN W, SAXENA S, et al. Photorealistic text-to-image diffusion models with deep language understanding [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems . New Orleans: NeurIPS Foundation, 2022: 36479–36494.
[本文引用: 1]
[10]
张美锋, 谭翼坤, 陈世俊, 等 基于DAGAN的电气设备小样本红外图像生成技术与应用
[J]. 电工技术 , 2023 , (6 ): 76 - 79
[本文引用: 1]
ZHANG Meifeng, TAN Yikun, CHEN Shijun, et al Infrared image generation technology and application of small sample of electrical equipment based on DAGAN
[J]. Electric Engineering , 2023 , (6 ): 76 - 79
[本文引用: 1]
[11]
何宇浩, 宋云海, 何森, 等 面向电力缺陷场景的小样本图像生成方法
[J]. 浙江电力 , 2024 , 43 (1 ): 126 - 132
[本文引用: 1]
HE Yuhao, SONG Yunhai, HE Sen, et al A few-shot image generation method for power defect scenarios
[J]. Zhejiang Electric Power , 2024 , 43 (1 ): 126 - 132
[本文引用: 1]
[12]
杨剑锋, 秦钟, 庞小龙, 等 基于深度学习网络的输电线路异物入侵监测和识别方法
[J]. 电力系统保护与控制 , 2021 , 49 (4 ): 37 - 44
[本文引用: 1]
YANG Jianfeng, QIN Zhong, PANG Xiaolong, et al Foreign body intrusion monitoring and recognition method based on Dense-YOLOv3 deep learning network
[J]. Power System Protection and Control , 2021 , 49 (4 ): 37 - 44
[本文引用: 1]
[13]
王德文, 李业东 基于WGAN图片去模糊的绝缘子目标检测
[J]. 电力自动化设备 , 2020 , 40 (5 ): 188 - 198
[本文引用: 1]
WANG Dewen, LI Yedong Insulator object detection based on image deblurring by WGAN
[J]. Electric Power Automation Equipment , 2020 , 40 (5 ): 188 - 198
[本文引用: 1]
[14]
黄文琦, 许爱东, 明哲, 等 基于生成对抗网络的变电站工作人员行为预测的方法
[J]. 南方电网技术 , 2019 , 13 (2 ): 45 - 50
[本文引用: 1]
HUANG Wenqi, XU Aidong, MING Zhe, et al Prediction method for the behavior of substation staff based on generative adversarial network
[J]. Southern Power System Technology , 2019 , 13 (2 ): 45 - 50
[本文引用: 1]
[15]
邵振国, 张承圣, 陈飞雄, 等 生成对抗网络及其在电力系统中的应用综述
[J]. 中国电机工程学报 , 2023 , 43 (3 ): 987 - 1004
[本文引用: 1]
SHAO Zhenguo, ZHANG Chengsheng, CHEN Feixiong, et al A review on generative adversarial networks for power system applications
[J]. Proceedings of the CSEE , 2023 , 43 (3 ): 987 - 1004
[本文引用: 1]
[16]
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 10674–10685.
[本文引用: 1]
[17]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Medical Image Computing and Computer-Assisted Intervention . Munich: Springer, 2015: 234–241.
[本文引用: 1]
[18]
ZHANG L, RAO A, AGRAWALA M. Adding conditional control to text-to-image diffusion models [C]// IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 3813–3824.
[本文引用: 3]
[19]
MOU C, WANG X, XIE L, et al. T2I-adapter: learning adapters to dig out more controllable ability for text-to-image diffusion models [C]// AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2024: 4296–4304.
[本文引用: 1]
[20]
JU X, ZENG A, ZHAO C, et al. HumanSD: a native skeleton-guided diffusion model for human image generation [C]// IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 15942–15952.
[本文引用: 3]
[21]
LIU X, REN J, SIAROHIN A, et al. HyperHuman: hyper-realistic human generation with latent structural diffusion [EB/OL]. (2024−03−15) [2025−01−14]. https://arxiv.org/abs/2310.08579.
[本文引用: 1]
[22]
闫政斌. 鲁棒性多姿态人体图像生成方法研究[D]. 天津: 天津工业大学, 2023.
[本文引用: 1]
YAN Zhengbin. Research on robust multi-pose human image generation method [D]. Tianjin: Tianjin University of Technology, 2023.
[本文引用: 1]
[23]
左然, 胡皓翔, 邓小明, 等 基于手绘草图的视觉内容生成深度学习方法综述
[J]. 软件学报 , 2024 , 35 (7 ): 3497 - 3530
[本文引用: 1]
ZUO Ran, HU Haoxiang, DENG Xiaoming, et al Survey on deep learning methods for freehand-sketch-based visual content generation
[J]. Journal of Software , 2024 , 35 (7 ): 3497 - 3530
[本文引用: 1]
[24]
文渊博, 高涛, 安毅生, 等 基于视觉提示学习的天气退化图像恢复
[J]. 计算机学报 , 2024 , 47 (10 ): 2401 - 2416
[本文引用: 1]
WEN Yuanbo, GAO Tao, AN Yisheng, et al Weather-degraded image restoration based on visual prompt learning
[J]. Chinese Journal of Computers , 2024 , 47 (10 ): 2401 - 2416
[本文引用: 1]
[25]
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 3213–3223.
[本文引用: 1]
[26]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
[本文引用: 1]
[27]
CHENG B, MISRA I, SCHWING A G, et al. Masked-attention mask Transformer for universal image segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1280–1289.
[本文引用: 1]
[28]
XU Y, ZHANG J, ZHANG Q, et al. Vitpose: simple vision Transformer baselines for human pose estimation [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems . New Orleans: NeurIPS Foundation, 2022: 38571–38584.
[本文引用: 1]
[29]
LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation [C]// International Conference on Machine Learning . Baltimore: PMLR, 2022: 12888–12900.
[本文引用: 1]
[30]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision . Zurich: Springer, 2014: 740–755.
[本文引用: 1]
[31]
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: NeurIPS Foundation, 2017: 6629–6640.
[本文引用: 1]
[32]
BIŃKOWSKI M, SUTHERLAND D J, ARBEL M, et al. Demystifying MMD GANs [C]// International Conference on Learning Representations . Vancouver: ICLR, 2018: 1–36.
[本文引用: 1]
[33]
HESSEL J, HOLTZMAN A, FORBES M, et al. CLIPScore: a reference-free evaluation metric for image captioning [EB/OL]. (2022−03−23) [2025−01−14]. https://arxiv.org/abs/2104.08718.
[本文引用: 1]
机器视觉技术在电力安全监控中的应用综述
1
2022
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
机器视觉技术在电力安全监控中的应用综述
1
2022
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
1
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
1
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
基于视频图像的输变电设备外部缺陷检测技术及其应用现状
1
2022
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
基于视频图像的输变电设备外部缺陷检测技术及其应用现状
1
2022
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
基于计算机视觉的电力作业人员行为分析研究现状与展望
1
2024
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
基于计算机视觉的电力作业人员行为分析研究现状与展望
1
2024
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
生成对抗网络及其在图像生成中的应用研究综述
1
2021
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
生成对抗网络及其在图像生成中的应用研究综述
1
2021
... 电力安全是我国经济发展的重中之重,而电力人员行为的精准识别对于安全事故的避免至关重要[1 ] . 目前,基于深度学习的图像处理技术逐渐成为研究热点,并在电力图像优化、设备缺陷检测、作业行为监测等细分领域逐步得到了推广和应用[2 -3 ] . 但是,电力图像数据具有私密性和特殊性,其采集、筛选、标注、整理等环节均需要耗费大量的人力物力,数据获取难度很大且质量较差[4 ] . 同时,深度学习模型的训练需要大量数据作为支撑,这给人工智能算法在电力领域的开发与利用带来了极大困难[5 ] . ...
Generative adversarial networks
1
2020
... 生成式人工智能(generative artificial intelligence, GAI)是指利用人工智能技术自动生成文本、图像、音频、视频等,主要包括2类方法:生成对抗网络[6 ] (generative adversarial network, GAN)和去噪扩散概率模型[7 ] (denoising diffusion probabilistic model, DDPM). 当前生成模型在文本提示的图像生成任务中效果良好,已有工作如GLIDE[8 ] 、Imagen[9 ] 等,但是仅仅通过文本提示无法准确地控制结构、形状、位置等细节信息. ...
1
... 生成式人工智能(generative artificial intelligence, GAI)是指利用人工智能技术自动生成文本、图像、音频、视频等,主要包括2类方法:生成对抗网络[6 ] (generative adversarial network, GAN)和去噪扩散概率模型[7 ] (denoising diffusion probabilistic model, DDPM). 当前生成模型在文本提示的图像生成任务中效果良好,已有工作如GLIDE[8 ] 、Imagen[9 ] 等,但是仅仅通过文本提示无法准确地控制结构、形状、位置等细节信息. ...
1
... 生成式人工智能(generative artificial intelligence, GAI)是指利用人工智能技术自动生成文本、图像、音频、视频等,主要包括2类方法:生成对抗网络[6 ] (generative adversarial network, GAN)和去噪扩散概率模型[7 ] (denoising diffusion probabilistic model, DDPM). 当前生成模型在文本提示的图像生成任务中效果良好,已有工作如GLIDE[8 ] 、Imagen[9 ] 等,但是仅仅通过文本提示无法准确地控制结构、形状、位置等细节信息. ...
1
... 生成式人工智能(generative artificial intelligence, GAI)是指利用人工智能技术自动生成文本、图像、音频、视频等,主要包括2类方法:生成对抗网络[6 ] (generative adversarial network, GAN)和去噪扩散概率模型[7 ] (denoising diffusion probabilistic model, DDPM). 当前生成模型在文本提示的图像生成任务中效果良好,已有工作如GLIDE[8 ] 、Imagen[9 ] 等,但是仅仅通过文本提示无法准确地控制结构、形状、位置等细节信息. ...
基于DAGAN的电气设备小样本红外图像生成技术与应用
1
2023
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
基于DAGAN的电气设备小样本红外图像生成技术与应用
1
2023
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
面向电力缺陷场景的小样本图像生成方法
1
2024
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
面向电力缺陷场景的小样本图像生成方法
1
2024
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
基于深度学习网络的输电线路异物入侵监测和识别方法
1
2021
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
基于深度学习网络的输电线路异物入侵监测和识别方法
1
2021
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
基于WGAN图片去模糊的绝缘子目标检测
1
2020
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
基于WGAN图片去模糊的绝缘子目标检测
1
2020
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
基于生成对抗网络的变电站工作人员行为预测的方法
1
2019
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
基于生成对抗网络的变电站工作人员行为预测的方法
1
2019
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
生成对抗网络及其在电力系统中的应用综述
1
2023
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
生成对抗网络及其在电力系统中的应用综述
1
2023
... 近年,基于GAN的电力图像生成方法逐步引起了研究者的关注,尤其是条件控制生成方法. 张美锋等[10 ] 通过改进数据增强生成对抗网络,将多尺度特征融合到U-Net架构的解码器中,扩充变电站设备的红外图像样本. 何宇浩等[11 ] 基于语义相似性匹配机制设计面对上下文的LoFGAN生成器,改善了电力缺陷样本不足的问题. 杨剑锋等[12 ] 利用条件生成对抗网络,将输电线路背景图和异物图作为随机变量,扩充异物入侵样本,提升了网络在下游检测任务中的性能. 王德文等[13 ] 设计基于Wasserstein距离优化的GAN,提升无人机航拍绝缘子模糊图片的清晰度. 黄文琦等[14 ] 通过全局生成对抗网络和局部生成对抗网络分别生成和优化视频场景和人体细节. 目前,GAN在电力图像生成方面的应用主要采用去模糊化、细节优化等方式解决简单的图像质量问题,实现电力图像样本的增强[15 ] ,但模型缺少高质量图像的生成能力. ...
1
... 在去噪扩散概率模型相关研究中,稳定扩散模型[16 ] (stable diffusion model, SDM)由于利用编码器和解码器将高分辨率的输入映射到潜在空间进行加噪与去噪,具有空间高效性和表达丰富性,是当前研究的主流基准网络;其主干结构为U-Net[17 ] . 目前,已有的工作如ControlNet[18 ] 、T2I-Adapter[19 ] 、HumanSD[20 ] 及HyperHuman[21 ] 等,均在稳定扩散模型的基础上探究条件控制图像生成. 然而,以上方法采用的数据主要为艺术绘画、人物风景、运动摄影等以人物为中心的图像,人物在图像中占据大比例画面,而电力图像以覆盖电力场地为目的,不以人物为中心,其中电力人员在多个位置与电力设备进行交互,两者存在巨大差异. ...
1
... 在去噪扩散概率模型相关研究中,稳定扩散模型[16 ] (stable diffusion model, SDM)由于利用编码器和解码器将高分辨率的输入映射到潜在空间进行加噪与去噪,具有空间高效性和表达丰富性,是当前研究的主流基准网络;其主干结构为U-Net[17 ] . 目前,已有的工作如ControlNet[18 ] 、T2I-Adapter[19 ] 、HumanSD[20 ] 及HyperHuman[21 ] 等,均在稳定扩散模型的基础上探究条件控制图像生成. 然而,以上方法采用的数据主要为艺术绘画、人物风景、运动摄影等以人物为中心的图像,人物在图像中占据大比例画面,而电力图像以覆盖电力场地为目的,不以人物为中心,其中电力人员在多个位置与电力设备进行交互,两者存在巨大差异. ...
3
... 在去噪扩散概率模型相关研究中,稳定扩散模型[16 ] (stable diffusion model, SDM)由于利用编码器和解码器将高分辨率的输入映射到潜在空间进行加噪与去噪,具有空间高效性和表达丰富性,是当前研究的主流基准网络;其主干结构为U-Net[17 ] . 目前,已有的工作如ControlNet[18 ] 、T2I-Adapter[19 ] 、HumanSD[20 ] 及HyperHuman[21 ] 等,均在稳定扩散模型的基础上探究条件控制图像生成. 然而,以上方法采用的数据主要为艺术绘画、人物风景、运动摄影等以人物为中心的图像,人物在图像中占据大比例画面,而电力图像以覆盖电力场地为目的,不以人物为中心,其中电力人员在多个位置与电力设备进行交互,两者存在巨大差异. ...
... Quantitative results of different methods under multiple metrics
Tab.2 方法 FID KID CLIP-Score PCK/% OKS ControlNet[18 ] 274.72 6.62 67.33/30.31 47.5 0.872 HumanSD[20 ] 331.05 11.65 62.21/29.24 89.4 0.946 PoseNet 130.79 5.12 87.23/30.32 75.4 0.889 PoseNet+图像滤波器 130.43 4.90 89.81/30.43 90.4 0.978 PoseNet+图像滤波器+双阶段训练 128.25 4.56 91.02 /31.44 94.2 0.979
所提方法在FID、KID和CLIP-Score(图-图/图-文)上分别取得了130.79、5.12、87.23/30.32的分数. 与其他模型相比,所提模型在生成时具有更高的图像质量与图文一致性. 在加入过滤策略之后,生成数据的整体质量得到进一步提升,并且在关键点准确度指标PCK和OKS上取得了90.4%和0.978的分数,较过滤之前分别提升了19.9%和10.0%,超过了人体图像生成的专用模型HumanSD,说明所提过滤策略极大地提高了生成结果中关键点的准确性,提升了整体准确度. 总体来看,所提方法在所选6项指标中均为最优,其有效性得到了验证. 尽管直接微调已经取得了不错的效果,但是由于电力数据集样本稀缺,采取双阶段训练策略,在通用数据集上预训练后再用电力数据集微调,使得模型具有准确的多模态条件提示生成能力,同时能够在电力场景下理解提示并生成与提示对应的人物图像. 采用预训练+微调的双阶段训练策略后,相比于直接微调,在图像质量和图像/文本一致性上提升效果明显,说明模型学习到了通用场景下丰富的图像信息,使得生成效果进一步提升. ...
... Comparison of generation efficiency for different behaviors with different algorithms
Tab.3 算法 $ {\eta }_{\mathrm{d}} $ $ {\eta }_{\mathrm{k}} $ $ {\eta }_{\mathrm{p}} $ ControlNet[18 ] 53 30 68 HumanSD[20 ] 77 57 71 PoseNet 100 100 100
2.4. 可视化结果分析 进一步地,对所提方法生成结果进行可视化分析,通过对生成图像的主观视觉感受来体现所提方法的有效性. ...
1
... 在去噪扩散概率模型相关研究中,稳定扩散模型[16 ] (stable diffusion model, SDM)由于利用编码器和解码器将高分辨率的输入映射到潜在空间进行加噪与去噪,具有空间高效性和表达丰富性,是当前研究的主流基准网络;其主干结构为U-Net[17 ] . 目前,已有的工作如ControlNet[18 ] 、T2I-Adapter[19 ] 、HumanSD[20 ] 及HyperHuman[21 ] 等,均在稳定扩散模型的基础上探究条件控制图像生成. 然而,以上方法采用的数据主要为艺术绘画、人物风景、运动摄影等以人物为中心的图像,人物在图像中占据大比例画面,而电力图像以覆盖电力场地为目的,不以人物为中心,其中电力人员在多个位置与电力设备进行交互,两者存在巨大差异. ...
3
... 在去噪扩散概率模型相关研究中,稳定扩散模型[16 ] (stable diffusion model, SDM)由于利用编码器和解码器将高分辨率的输入映射到潜在空间进行加噪与去噪,具有空间高效性和表达丰富性,是当前研究的主流基准网络;其主干结构为U-Net[17 ] . 目前,已有的工作如ControlNet[18 ] 、T2I-Adapter[19 ] 、HumanSD[20 ] 及HyperHuman[21 ] 等,均在稳定扩散模型的基础上探究条件控制图像生成. 然而,以上方法采用的数据主要为艺术绘画、人物风景、运动摄影等以人物为中心的图像,人物在图像中占据大比例画面,而电力图像以覆盖电力场地为目的,不以人物为中心,其中电力人员在多个位置与电力设备进行交互,两者存在巨大差异. ...
... Quantitative results of different methods under multiple metrics
Tab.2 方法 FID KID CLIP-Score PCK/% OKS ControlNet[18 ] 274.72 6.62 67.33/30.31 47.5 0.872 HumanSD[20 ] 331.05 11.65 62.21/29.24 89.4 0.946 PoseNet 130.79 5.12 87.23/30.32 75.4 0.889 PoseNet+图像滤波器 130.43 4.90 89.81/30.43 90.4 0.978 PoseNet+图像滤波器+双阶段训练 128.25 4.56 91.02 /31.44 94.2 0.979
所提方法在FID、KID和CLIP-Score(图-图/图-文)上分别取得了130.79、5.12、87.23/30.32的分数. 与其他模型相比,所提模型在生成时具有更高的图像质量与图文一致性. 在加入过滤策略之后,生成数据的整体质量得到进一步提升,并且在关键点准确度指标PCK和OKS上取得了90.4%和0.978的分数,较过滤之前分别提升了19.9%和10.0%,超过了人体图像生成的专用模型HumanSD,说明所提过滤策略极大地提高了生成结果中关键点的准确性,提升了整体准确度. 总体来看,所提方法在所选6项指标中均为最优,其有效性得到了验证. 尽管直接微调已经取得了不错的效果,但是由于电力数据集样本稀缺,采取双阶段训练策略,在通用数据集上预训练后再用电力数据集微调,使得模型具有准确的多模态条件提示生成能力,同时能够在电力场景下理解提示并生成与提示对应的人物图像. 采用预训练+微调的双阶段训练策略后,相比于直接微调,在图像质量和图像/文本一致性上提升效果明显,说明模型学习到了通用场景下丰富的图像信息,使得生成效果进一步提升. ...
... Comparison of generation efficiency for different behaviors with different algorithms
Tab.3 算法 $ {\eta }_{\mathrm{d}} $ $ {\eta }_{\mathrm{k}} $ $ {\eta }_{\mathrm{p}} $ ControlNet[18 ] 53 30 68 HumanSD[20 ] 77 57 71 PoseNet 100 100 100
2.4. 可视化结果分析 进一步地,对所提方法生成结果进行可视化分析,通过对生成图像的主观视觉感受来体现所提方法的有效性. ...
1
... 在去噪扩散概率模型相关研究中,稳定扩散模型[16 ] (stable diffusion model, SDM)由于利用编码器和解码器将高分辨率的输入映射到潜在空间进行加噪与去噪,具有空间高效性和表达丰富性,是当前研究的主流基准网络;其主干结构为U-Net[17 ] . 目前,已有的工作如ControlNet[18 ] 、T2I-Adapter[19 ] 、HumanSD[20 ] 及HyperHuman[21 ] 等,均在稳定扩散模型的基础上探究条件控制图像生成. 然而,以上方法采用的数据主要为艺术绘画、人物风景、运动摄影等以人物为中心的图像,人物在图像中占据大比例画面,而电力图像以覆盖电力场地为目的,不以人物为中心,其中电力人员在多个位置与电力设备进行交互,两者存在巨大差异. ...
1
... 综上所述,虽然扩散模型相较于生成对抗网络在生成图像的清晰度、丰富度方面得到了显著提升,但是,如何控制模型生成想要的图像仍然是生成模型研究领域的一大难题[22 ] . 人体图像包含更加复杂的结构,并且需要考虑人体的姿态、形状和衣着等,给人体图像生成带来极大挑战[23 ] ,使得可控电力人员行为图像生成面临更多困难. ...
1
... 综上所述,虽然扩散模型相较于生成对抗网络在生成图像的清晰度、丰富度方面得到了显著提升,但是,如何控制模型生成想要的图像仍然是生成模型研究领域的一大难题[22 ] . 人体图像包含更加复杂的结构,并且需要考虑人体的姿态、形状和衣着等,给人体图像生成带来极大挑战[23 ] ,使得可控电力人员行为图像生成面临更多困难. ...
基于手绘草图的视觉内容生成深度学习方法综述
1
2024
... 综上所述,虽然扩散模型相较于生成对抗网络在生成图像的清晰度、丰富度方面得到了显著提升,但是,如何控制模型生成想要的图像仍然是生成模型研究领域的一大难题[22 ] . 人体图像包含更加复杂的结构,并且需要考虑人体的姿态、形状和衣着等,给人体图像生成带来极大挑战[23 ] ,使得可控电力人员行为图像生成面临更多困难. ...
基于手绘草图的视觉内容生成深度学习方法综述
1
2024
... 综上所述,虽然扩散模型相较于生成对抗网络在生成图像的清晰度、丰富度方面得到了显著提升,但是,如何控制模型生成想要的图像仍然是生成模型研究领域的一大难题[22 ] . 人体图像包含更加复杂的结构,并且需要考虑人体的姿态、形状和衣着等,给人体图像生成带来极大挑战[23 ] ,使得可控电力人员行为图像生成面临更多困难. ...
基于视觉提示学习的天气退化图像恢复
1
2024
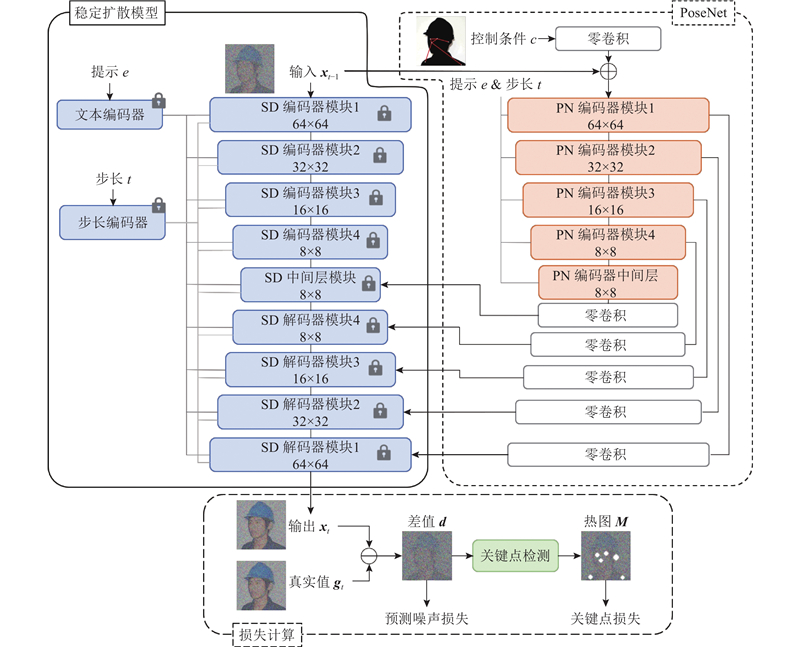
... 稳定扩散模型可以通过姿态条件引导反向过程,进而控制图像的生成,但是该方法所得的结果存在较大的解空间,从而导致生成的结果存在很大差异,不够精确[24 ] . 为了使模型输出更精确的人体图像,建立PoseNet模型,通过在稳定扩散模型中添加辅助模块,引入额外条件来控制生成过程,如图3 所示. 在PoseNet模型中,采用与稳定扩散模型相同的编码器模块及中间层,冻结稳定扩散模型的权重参数. PoseNet中每一个编码器模块的输出都通过1层跳跃连接结构与零卷积层相连,分别与对应层的稳定扩散模型的特征相加,最终被输入到解码器中解码,实现条件的融合与控制. 此外,在整体损失函数中添加关键点热图损失,帮助模型关注人体关节生成的准确度. ...
基于视觉提示学习的天气退化图像恢复
1
2024
... 稳定扩散模型可以通过姿态条件引导反向过程,进而控制图像的生成,但是该方法所得的结果存在较大的解空间,从而导致生成的结果存在很大差异,不够精确[24 ] . 为了使模型输出更精确的人体图像,建立PoseNet模型,通过在稳定扩散模型中添加辅助模块,引入额外条件来控制生成过程,如图3 所示. 在PoseNet模型中,采用与稳定扩散模型相同的编码器模块及中间层,冻结稳定扩散模型的权重参数. PoseNet中每一个编码器模块的输出都通过1层跳跃连接结构与零卷积层相连,分别与对应层的稳定扩散模型的特征相加,最终被输入到解码器中解码,实现条件的融合与控制. 此外,在整体损失函数中添加关键点热图损失,帮助模型关注人体关节生成的准确度. ...
1
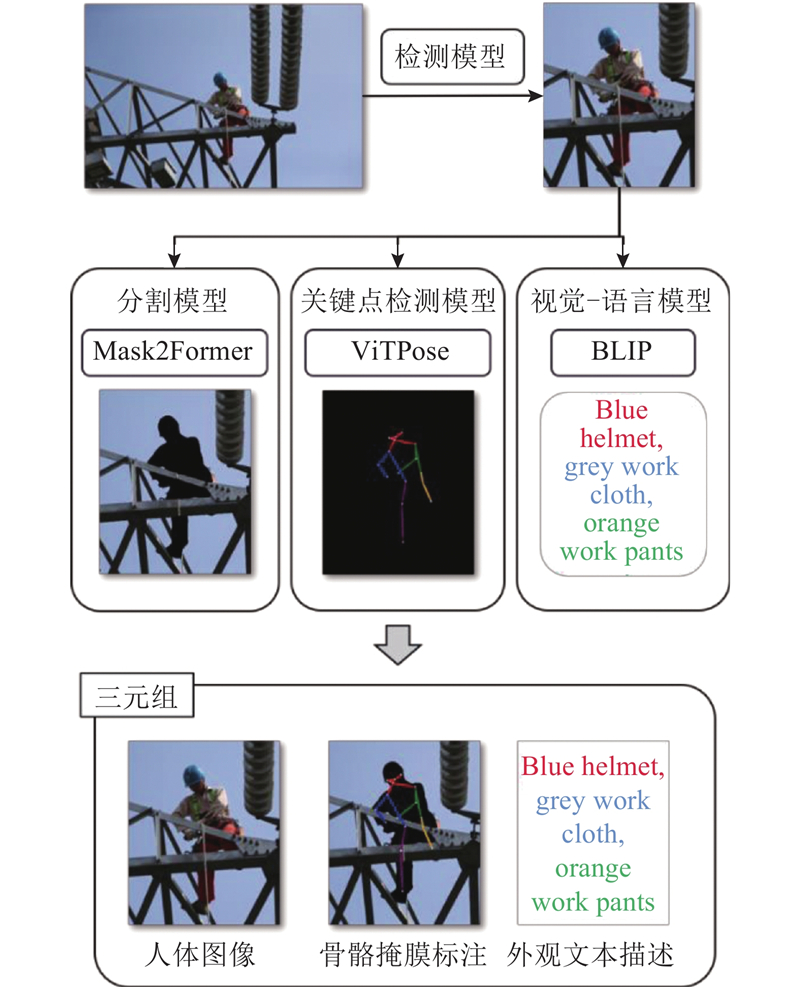
... 由于获取的原始电力人员图像数据不含任何标注信息,需要对原始数据进行标注,而使用人工标注会耗费大量的时间. 据统计,1张图像的语义分割标注时间约为1.5 h[25 ] . 目前大都采用深度学习辅助工具来生成需要的标注信息,如SpireView、Label-Studio. 但是,这些均为半自动标注方法,仍然需要人工介入(如提供起始点、大致框等),且标注形式单一. ...
1
... 1)输入1张原始图像,通过YOLO[26 ] 检测出所有人体的最小外接矩形框,并按一定比例留出裕量,根据放大后的外接矩形框对图像进行裁切. ...
1
... 2)针对每个裁切出的人体外接矩形框,采用Mask2Former[27 ] 分割出人体掩膜,利用关键点检测模型ViTPose[28 ] 检测出人体关键点,将掩膜和关键点融合,并覆盖原图中的人体,形成骨骼掩膜标注. ...
1
... 2)针对每个裁切出的人体外接矩形框,采用Mask2Former[27 ] 分割出人体掩膜,利用关键点检测模型ViTPose[28 ] 检测出人体关键点,将掩膜和关键点融合,并覆盖原图中的人体,形成骨骼掩膜标注. ...
1
... 3)针对每个裁切出的人体外接矩形框,通过视觉-语言模型BLIP[29 ] 生成相应的外观描述,与前两者组成图像-骨骼掩膜标注-外观文本描述三元组. ...
1
... 该标注方法可以实现分割掩膜、关键点坐标、外观文本描述3种标注的一次性生成,且无须任何形式的人工介入. 在此标注的基础上,训练过程即是让模型学习如何通过骨骼掩膜标注及外观文本描述还原原始人体图像. 关键点为模型提供人体姿势信息,掩膜为模型提供稠密空间信息,文本描述为模型提供外观信息. 其中关键点的标注遵循COCO[30 ] 标注格式,以17个关键点来表示1个人,包括鼻子、左/右眼睛、左/右耳朵、左/右肩膀、左/右手肘、左/右手腕、左/右髋部、左/右膝盖、左/右脚踝. ...
1
... 根据电力人员行为特点,选取的图像生成评价指标包括2部分:通用的图像生成评价指标和专用评价指标. 具体定义如表1 所示.通用的图像生成评价指标包括:FID、KID、CLIP-Score、PCK和OKS. FID[31 ] 和KID[32 ] 分数用于评估模型生成结果的质量;CLIP-Score[33 ] 用于衡量图像/文本一致性,该指标分为图像-图像匹配度和图像-文本匹配度2项. 此外,引入姿态估计评价指标PCK和OKS来评估生成图像在人体姿势上的准确度. ...
1
... 根据电力人员行为特点,选取的图像生成评价指标包括2部分:通用的图像生成评价指标和专用评价指标. 具体定义如表1 所示.通用的图像生成评价指标包括:FID、KID、CLIP-Score、PCK和OKS. FID[31 ] 和KID[32 ] 分数用于评估模型生成结果的质量;CLIP-Score[33 ] 用于衡量图像/文本一致性,该指标分为图像-图像匹配度和图像-文本匹配度2项. 此外,引入姿态估计评价指标PCK和OKS来评估生成图像在人体姿势上的准确度. ...
1
... 根据电力人员行为特点,选取的图像生成评价指标包括2部分:通用的图像生成评价指标和专用评价指标. 具体定义如表1 所示.通用的图像生成评价指标包括:FID、KID、CLIP-Score、PCK和OKS. FID[31 ] 和KID[32 ] 分数用于评估模型生成结果的质量;CLIP-Score[33 ] 用于衡量图像/文本一致性,该指标分为图像-图像匹配度和图像-文本匹配度2项. 此外,引入姿态估计评价指标PCK和OKS来评估生成图像在人体姿势上的准确度. ...











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}