

大语言模型(large language model, LLM)作为当前人工智能发展的核心驱动力,通过不断扩大的参数规模和愈发全面的推理能力,正在以惊人的速度重塑技术格局,推动产业变革. 举例而言,GPT-3等预训练大模型已然能够解决生活中大部分通用问题,而从BERT[1]的1.1亿参数量提升到ChatGPT-3[2]的
为了缓解算力问题对大模型训练的影响,主要采取2种策略,两者通常相辅相成. 参数高效微调(parameter-efficient fine-tuning, PEFT)[4]作为针对大模型训练的技术,仅须微调少量或者额外的模型参数,即可让大模型高效适配各种下游任务. PEFT可以显著减少计算和存储开销,且不损失模型性能. 例如,GPT-3的全参数微调需要更新大约1 750亿个参数,这在工业界和学术界都是几乎不可行的,但是如果使用PEFT中的LoRA[5]方法进行微调,在反向传播过程中只涉及37.7万个参数,且可以保持模型性能与采用全参数微调时的性能基本一致. 尽管如此,PEFT在前向传播阶段仍需完整的预训练模型来参与计算,故对算力仍有依赖. 为此,Wang等[6]对LoRA微调方法进行改进,提出PrivateLoRA,将核心权重矩阵和低秩矩阵部署在云端执行,边缘设备仅运行嵌入(embedding)层和语言模型头(LM head)层,在降低边缘设备算力需求的同时提升了数据与模型的隐私性. 然而,该方案缺乏云端计算验证机制,要求边缘设备完全信任云端输出,且该方法未能缓解我国算力资源紧张的现状及用户在云服务训练中的成本压力.
租赁云服务器进行外包训练,常用于解决此问题. 我国部分云服务商仍然保有旧款专业计算设备,可用于加速训练过程,分担算力压力. 但是将数据上传至云端训练,存在数据泄露和模型被盗的风险. 为此,多数解决方案倾向于运用加密计算或通过调整训练架构来保护隐私. 例如,赵敏等[7]基于半同态加密技术及加法秘密共享方案,设计多种安全计算协议,使得用户既可以不参与在线运算,也可以保护数据和模型参数的隐私. 但是此方法基于半同态加密技术,会产生额外的计算成本并导致精度的损失,而且这些安全协议只有在半诚实模型[8]中运行时才是安全的. Tian等[9]提出基于双服务器模型的卷积神经网络分类方案,可以在保护用户输入数据隐私的情况下高效地执行分类任务,但是此方案无法保护模型本身的隐私性,经过训练的模型会完全暴露给外包方. 郭丽[10]通过将计算量繁重的线性层的权重矩阵加密后外包给边缘服务器,由用户在本地恢复结果后执行非线性层运算,保护了数据集和模型的隐私. 但是此方案假设外包方会执行预定的计算过程,且参与协作的2个边缘服务器不会合谋,这在实际情况下很难实现.此外,云算力资源大多集中于少数几家大型云计算企业,资源的垄断导致云服务器的租赁价格维持在高位,而采用加密计算等隐私保护手段会额外增加计算负担,进一步推高总体训练成本,这成为了利用云算力缓解算力短缺时必须考量的难题.
整合并租用闲置算力作为全新的算力获取渠道,优势显著. 不仅能够接入更为先进的专业计算资源,而且相较于传统云服务,成本显著降低. 例如,投资NVIDIA A100 GPU并以18个月作为硬件折旧周期计算,平均每小时的计算成本仅为0.62美元,相比于AWS云服务器节省了约85%[11]. 同时,世界范围内持有闲置算力的个体或组织数量庞大. 特别是一些区块链矿工和矿池,因共识算法改变,其拥有的算力设备已无法在原场景中创造收益;若能将这部分算力重新部署,对他们而言除电力消耗外,几乎无额外开销. 然而,与稳定运行的云服务器不同,此类算力提供方的计算准确性和数据的安全性难以得到保证,加之网络环境等因素导致服务质量不稳定,这些都成为了影响该模式广泛应用的主要障碍. 为此,Teutsch等[12]基于区块链构建分布式计算框架Truebit,整合闲散算力,通过链上节点调度实现多节点并行任务处理,并采用结果对比机制检测异常计算行为. 但是Truebit依赖多节点冗余验证,导致计算量大幅增加,难以适配大模型等高密度计算场景. 此外,计算节点须直接访问原始数据,存在用户数据隐私泄露与模型窃取风险,严重制约了其在大模型训练领域的应用价值. 夏虎等[13]基于区块链提出面向外包安全多方统计计算的可验证隐私保护方案. 该方案依托区块链构建可信执行环境,利用智能合约对外包节点实现全行为监督,同时使用基于秘密共享的安全多方计算(secure multi-party computation, SMPC)机制保护参与方的输入隐私. 但是,将SMPC应用于大模型训练领域时面临计算效率低下、实现复杂度高以及通信开销增大等问题.
针对上述问题,提出基于区块链的大模型微调算力共享平台CompuDEX(compute power decentralized exchange). 有效地组织闲置算力,以低成本、匿名的方式提供服务,并通过对LoRA微调架构进行改造,实现模型和数据的隐私保护. 不仅在保证运行效率的前提下实现了比云服务商更低的使用成本,而且能够保护用户在微调过程中的数据集隐私、模型参数以及在现实世界中的身份信息. 此外,关注外包计算过程中的服务质量、公平交易与计算信任问题,利用零知识证明等密码学工具,设计信用值机制、PreferMatch和“红气球”激励机制,以促进用户公平竞争,提高平台的安全性和抗攻击能力.
1. 相关技术基础
1.1. 区块链
区块链[14]是共享的、不可篡改的分布式账本,记录了网络中所有的交易以及资产流转过程,不仅包括金钱的转移,而且涵盖信息传递、版权转让等几乎任何有价值的事务. 作为一种分布式数据库技术,区块链和传统的中心化数据库最大的不同之处在于,其数据对于所有用户来说都是公开可见的,操作也相对透明. 此外,在中心化数据库中,数据库的管理员可以任意修改数据库中的数据,而在区块链中,任何数据都不可被篡改,这得益于区块链独特的数据结构和运行模式.
区块链由一个个区块组成,每个区块通过引用父区块的区块头哈希值(hash),以链条的形式连接在一起. 每个区块由1个区块头和包含所有交易的区块体组成,其中区块头由父区块hash、默克尔根、时间戳等一系列元数据构成. 同时,区块链在没有中心化权威机构的情况下,通过共识机制[15]来确保所有诚实节点保持数据的一致性,即一个区块需要经过网络中的多数节点验证并通过竞争式或者投票式的共识后才会被确认生成.
如果攻击者想要修改区块链中的某条数据,哪怕是微小的改动,由于链式结构和hash的存在,都会使改动被放大并且沿着链向前传播;并且由于数据被网络中的多个节点记录,攻击者必须同时控制网络中大量独立运行的节点,这极大地增加了篡改数据的难度. 因此,可以认为区块链中的数据是极难被篡改的.
虽然区块链的特性使得其在金融、供应链管理等多个领域展现出巨大的能量,但是仍然面临着一些挑战. 例如,比特币网络中仍然采用工作量证明(proof of work, PoW)[16],这种共识机制需要大量的计算资源来挖掘新区块,会消耗大量的电力资源. 随着交易数量的增加,区块链的性能会降低;当有大量交易同时涌入时,可能需要等待很长时间,交易才可以被记录到区块链上. 另外,由于区块链处在不断增长的状态,区块链的数据存储需求在不断提高,对存储设备的要求也随着区块高度的增长而不断提高.
1.2. 智能合约
智能合约(smart contract)[17]是一种在区块链上自动执行的协议,其实质是由Solidity等编程语言编写的代码片段. 合约一旦被编译为字节码并部署到区块链上,就成为了永久固定的程序. 用户通过向合约地址发送交易来调用合约,每次调用合约函数时,都会在区块链上创建新的交易. 当合约达到预先设定的触发条件时,将会自动执行. 合约中所有的交易公开可见,任何人都可以查看智能合约的代码以及交易历史,并且由于其被部署在链上,具有不可篡改的特性,允许在不需要任何第三方的情况下执行可信的操作. 目前,智能合约已经被应用在金融、选举投票等多个领域.
智能合约有其缺点,例如,一旦被部署到链上,其运行代码就不可被修改;如果合约代码编写不当,则会产生严重的、难以修正的安全漏洞,只能通过部署新合约的方式来解决. 其次,由于Gas费的存在,智能合约存在一定的调用成本,使得在智能合约内执行复杂计算操作的难度增加.
1.3. PEFT与LoRA
随着大语言模型的普及,其参数量迅速增加到千亿级别,全量微调已经无法适应各类下游任务的需求. 这种微调方式不仅效率低下,而且部署成本高昂,对资源的需求也异常庞大. PEFT通过降低可训练参数的数量,有效减轻了微调阶段的硬件资源消耗. 现有的PEFT方案主要可以分为2类:一类是以BitFit[18]为代表的稀疏微调方法,仅对模型的部分参数进行重新训练,以提高训练效率;另一类是以LoRA为代表的方案,通过增加额外参数进行训练,从而在不改变原有模型结构的基础上实现微调.
LoRA通过冻结预训练模型权重,并将可训练的低秩分解矩阵注入Transformer架构的每一层,从而显著减少下游任务的可训练参数数量. 这种可训练的低秩分解矩阵被称为LoRA A和LoRA B. 用户可以为同一个预训练模型构建不同的LoRA子模块,通过使用这些模块来轻松地切换适配的下游任务,进而减少存储需求和任务切换开销. 其次,LoRA的设计使算力需求门槛降低了3倍,并且与完全微调相比不会带来推理延迟. 最重要的是,LoRA与其他模型训练方法是正交的,可以与众多训练方法相结合,提高训练效率.
2. 平台架构与运行流程
CompuDEX的架构如图1所示. 参与者主要由需求方(Demander)和算力提供者(Provider)组成,Demander指寻求模型微调服务的用户,Provider是贡献计算资源的用户. 在开始训练任务前,为了防止Demander的数据集泄露,须对预训练模型进行拆分,将与词处理相关的层,例如embedding层、LM head层提取出来在Demander本地执行. 此外,为了防止Demander的模型被窃取,LoRA A和LoRA B模块同样在Demander本地执行. 模型的剩余部分,鉴于其高计算需求,交由Provider执行.
图 1

CompuDEX以区块链为根基,结合使用多种智能合约,为Demander与Provider建立去信任的交流平台,确保各方在合作过程中的安全与信任. 执行流程主要分为任务准备与偏好匹配、任务执行、任务候补和任务结算4个阶段,下面分别对这4个阶段进行详细叙述.
2.1. 任务准备与偏好匹配阶段
该阶段可以细分为任务数据准备和偏好匹配2个阶段.
1)任务数据准备. 当Demander想要执行训练任务时,需要做以下准备:对预训练模型的权重进行预处理,将模型权重分为Demander和Provider 2个部分,并根据LoRA生成LoRA权重矩阵;准备模型权重和训练代码;根据Provider的数量对数据集进行划分.
2)偏好匹配. 对于需要进行大模型微调的Demander而言,每个Demander都有其特色. 有的对时间非常敏感,不考虑训练成本,只追求尽快完成训练,而有的对于时间的要求宽松,能够接受较慢的训练速度,但是要求训练价格低. 同样,不同的Provider也有各自的心理预期. 一些Provider使用闲置或者较旧的设备,提供算力的能力有限,服务质量不高,售价相对较低. 另一些Provider通过投资新设备的方式加入网络,拥有先进的高性能计算设备和高速网络,致力于提供优质服务,期望获得较高的收益,定价自然更高.
鉴于上述原因,为了更好地满足各方需求,设置PreferMatch机制,如图2所示. 这是一个双选的过程,不仅让参与者在擅长的领域发挥优势,而且能够在一定程度上减少资源浪费. 此外,借助区块链的不可篡改特性,Demander和Provider在匹配阶段确定的价格将成为最终结算的依据. 任何一方都无法抵赖,确保了交易的透明性和不可否认性.
图 2

1)Demander通过偏好匹配合约发布任务,发布时须详细说明任务的具体要求与偏好,包括所用的开源大模型、训练数据集的大小、预期单次计算所需时间及单价区间等任务元数据和相关信息. 同时,Demander还须将模型权重和训练代码存放于公开可访问的位置,以便于Provider预先下载和准备. Provider会定期查询合约以确认是否有新任务正在发布,并根据任务详情和个人条件判断是否接受. 合约会记录接受任务的Provider地址,用于身份认证.
2)每个任务的发布周期有一定时限,在此期间,接受任务的Provider需要在任务发布结束之前生成符合Demander要求的报价信息,逾期未提交者将被合约视为自动放弃. Provider首先需要使用Demander的公钥PKD加密任务信息,然后用自身的私钥SKP对任务信息进行签名,最后将密文与签名一起上传至合约.
3)Demander每接受到1份来自Provider的报价信息后,首先使用自己的私钥SKD解密得到报价信息,再使用对应的公钥PKP进行验签. Demander将综合评估所有Provider提交的信息,自主选择合适的Provider执行任务.
2.2. 任务执行阶段
在现有大模型的训练过程中,1次序列生成会执行多次前向传播,且每次前向传播生成的通证(token)将作为下一轮前向传播的输入. 以下为任务执行阶段的主要步骤.
Demander首先将并行的多个输入经过分词器(tokenizer)分词后交由embedding层进行计算. 对输出的token进行签名,然后将签名和数据一起发送给Provider.
Provider接收到Demander传递的张量(tensor)后,按照事先约定好的计算协议进行计算,然后将生成的tensor签名后发送给Demander.
Demander接收Provider传递回来的tensor和签名,验签通过后将其与自身LoRA层计算后的tensor进行聚合,将聚合后的tensor经过LM head层计算以及解码后得到下一轮的输入. 此时如果解码后的结果为结束符标记或者生成token的长度已经达到预定上限,则执行下一步,否则跳回第1步.
此时序列生成过程已经结束,Demander需要根据预测结果与真实值计算损失,并通过反向传播来训练参数. 由于LoRA的特性,此过程完全在Demander本地执行,不需要Provider的参与.
Demander在任务执行阶段的伪代码如算法1所示,Provider在任务执行阶段的伪代码如算法2所示.
算法1 Demander在任务执行阶段的运行流程
输入:Provider传递的tensorP、签名signatureP、训练样本text
输出:计算后的tensorD、签名signatureD
1: 加载分词器tokenizer、嵌入层embedding_model、语言模型头部LM_head_model、LoRA模块及解码层Decoding
2: Input←tokenizer (text) //对文本进行分词
3: while 生成序列长度未达到设定上限 do
4: tensorD←embedding_model (Input)
5: signatureD←Sign (tensorD) //对数据签名
6: Send (tensorD, signatureD) //发送数据和签名
7: LoRA_outputs_tensor←LoRA_model (tensorD)
8: 等待接收Provider返回的tensorP和signatureP
9: if 验签失败 then
10: 提交signatureP和tensorP到合约
11: else
12: outputs_tensor←tensorP+LoRA_outputs_tensor
13: tensorP+LoRA_outputs_tensor
14: logits←LM_head_model (outputs_tensor)
15: next_token←Decoding (logits)
16: if next_token = <EOS>或者达到最大长度 then
17: break
18: Input←next_token
19: end if
20: end while
21: 进入反向传播阶段
算法2 Provider在任务执行阶段的运行流程
输入:Demander传递的tensorD、签名signatureD
输出:计算后的tensorP、签名signatureP
1: 初始化模型配置以及加载模型model
2: if 验签失败 then
3: 提交signatureD和tensorD到合约
4: else
5: tensorP←model (past_key_values, tensorD)
6: past_key_values←tensorP.past_key_values
7: signatureP←Sign (tensorP) //对数据签名
8: 将tensorP和signatureP返回给Demander
9: end if
在任务执行过程中,虽然Demander在任务选择阶段选择了相对最合适的Provider,但是在实际训练中,每一轮完整的batch都会涉及几十甚至上百次token交互. 由于每个计算节点的计算能力略有差异,每个样本的输出长度可能不同,以及由网络不稳定造成的短暂掉线或者直接掉线、计算节点设备故障等不稳定因素,几乎不可能做到所有Provider均在同一时间完成计算. 因此,Demander往往会对每一轮batch设定可接受的结束时间,无论是网络波动还是计算速度较慢,只要在结束时间之前提交所有的计算结果即可. 由此可见,短暂的网络不稳定对于整个训练过程的影响是可以接受的. 但是出现网络波动的计算节点会受到信用值降低的惩罚,影响其在后续任务中被选择的概率.
对于掉线后无法重连、设备故障导致无法计算甚至是作恶等情况,这些Provider将无法参与后续的任务进程. 此时如果剩余的计算节点无法满足任务计算需求,Demander可以通过在任务候补阶段重新补充节点来维持任务的推进.
2.3. 任务候补阶段
在任务执行期间,可能存在不诚实的Provider,若被检测出恶意行为,这些Provider将受到惩罚并被排除在后续流程之外. 如果不诚实的Provider过多,干扰了任务的正常运行,系统则须启动候补阶段,引入额外的Provider以维持任务进程的连续性.
在每一轮batch结束后,除了因恶意行为被惩罚的Provider外,还可能有Provider因网络中断或其他不可预见的情况而被迫离线且无法重新连接. 为了确保训练任务不受影响,Demander有权重新发起一轮PreferMatch,从网络中吸引新的Provider加入,保障训练过程的稳定性与完整性.
2.4. 任务结算阶段
在训练任务全部结束以后,进入任务结算阶段. 此阶段涉及酬金的计算和支付,具体金额由预设的计算单价与实际产生的计算量(通常以生成的token数量表示)的乘积决定. 其中计算单价已经在偏好匹配阶段由Demander与Provider共同商定,并在合约中存证,不可被改变.
计算数量因受到多种因素的影响而具有不确定性,包括但不限于模型的序列生成情况、训练效果等. 因此,在任务执行完毕后,双方在本地对生成的token数量进行统计和协商. 双方通过调用结算合约,上传统计得到的计算数量. 若上传的数量一致,则表明双方就工作量达成共识,可以直接以此数量进行结算. 若数量存在差异,Provider有权公开Demander在训练过程中提供的签名,每接收到1个附带签名的数据就会执行1次计算. 通过验签即可确认实际执行的工作量,从而解决争议. 最终,依据核实的数量完成结算,结算全部完成后,整个任务流程结束.
3. 安全性机制与“红气球”激励
鉴于Provider来自世界各地,其诚信程度参差不齐,可能会在利益的驱使下作恶. 例如,为了获取训练报酬,不进行实际计算,而是随意编造tensor发送给Demander. Tensor作为抽象数据,不经过计算和对比检验,很难判断其真实性.
为了防范并惩处潜在的Provider恶意行为,设计一系列安全性措施与激励机制,旨在维护系统安全、稳定,同时促使Provider提供更高质量的服务.
3.1. 信用值机制
无论是因为网络条件等不可抗力因素,还是因为作恶行为导致Provider不能提供稳定的服务,都将阻碍微调进程,对Demander及其他Provider造成经济损失. 因此,挑选能够提供优质服务的Provider加入任务显得尤为重要.
平台引入信用值机制,旨在为Demander在选择合适的Provider时提供参考依据. 同时,该机制鼓励Provider在任务执行期间保持高标准的服务质量. 因为高信用值不仅增加了Provider被选中的可能性,而且允许其基于自身提供的优质服务设置较高的价格,从而获得更高的经济收益. 通过这种方式,信用评分机制促进了整个系统的健康与高效运行.
信用值由信用合约维护,以区块链账户地址为唯一的标识符. 新加入的Provider信用值为0,须通过在网络中持续表现诚实和提供高品质服务来提升自身信用值. 相反,作恶或频繁掉线将导致信用值下降. 每个地址的信用值都公开透明.
为了设计切实可行的信用值机制,注意到区块链中一种基于信用的物联网设备PoW共识机制[23]的信用值计算方法同样适用于CompuDEX. 通过调整每个参数的含义,可以有效地将该计算方法迁移应用至CompuDEX中.
式中:
式中:
每个Provider的消极行为计算方式为
式中:
通过上述方式,信用机制可以反映过去一段时间内Provider的表现. 在CompuDEX中,信用机制主要作为一种激励机制,促使Provider保证服务质量,并作为Demander选择Provider时的参考指标之一,但是并非一种确保安全性的机制. 真正的安全保障来自于挑战委员会,其负责审核Provider的计算结果,确保结果准确无误.
3.2. 挑战委员会
在每个训练任务开始前,Demander不仅要从网络中挑选Provider参与任务,而且需要选择若干挑战者组成挑战委员会. 挑战委员会的职责是确保Provider的计算结果准确无误. 只有信用值超过既定阈值的Provider才有资格申请加入挑战委员会,且同一个Provider不能在同一任务中担任多个角色. 然而,考虑到Provider能力参差不齐,以及任务执行的过程中存在等待时间,平台允许同一Provider同时在多个任务中担任不同的角色以提高算力利用率. 例如,在任务A中充当Provider的同时,也在任务B中担任挑战者. 对于挑战者,通过随机选择合约进行差额选择. 由Demander设定需要的挑战者人数X和接受报名的总人数N(N > X). 当报名数量达到上限N时,合约将不再接受后续的报名,并进入随机选择阶段.
利用水塘抽样算法[26]公平地从N个人中随机抽取X名挑战者构成挑战委员会,此过程的伪代码如算法3所示. 其中,第1行表示对选中的挑战者的编号数组challenger进行初始化,第3、4行表示计算随机数,根据随机数判断是否进行替换. 考虑到智能合约无法生成真正的随机数,为了避免选择过程被攻击者控制,结合最新区块的hash和报名序列i后再次取hash,以增强选择随机性. 第5~6行表示对数组中的挑战者编号进行替换.
算法3 基于区块链的水塘抽样
输入:报名人数N、选择的挑战者人数X
输出:从N个人中以相等的概率公平、随机地选取X个人的结果
1: 初始化数组challenger的大小为X,并赋值为[0, X−1]
2: for i←X+1 to N do
3: rand←uint (block.hash, i)
4: rand←mod (rand, i+1)
5: if rand < X then
6: Challenger[rand]←i+1
7: end if
8: end for
以最新区块的hash作为生成随机数的依据之一,能够增强算法的安全性. 以目前最成熟、用户量最大的国际区块链平台以太坊为例,以太坊每12 s生成1个新区块,因此攻击者只有12 s的时间计算出能够被成功选中的报名序列,并且需要确保自己的报名顺序与报名序列一致. 此外,如果报名时间超过12 s,实际选择时依赖的区块hash会改变,选择结果完全改变,从而使攻击无效.
为了提高训练效率以及流畅性,Demander在任务执行过程中会乐观地认为Provider的计算结果准确无误,即序列生成的过程不会被任何因素打断. 同时,Demander将自己以及Provider传输的tensor广播给挑战委员会,挑战委员会在挑战期内自主选择数据进行本地重现计算. 如果本地计算结果与Provider提交的结果存在差异,则有权向合约提交相应的欺诈证明. 挑战期从挑战委员会接收到数据开始,至此轮batch结束为止. 若在此轮batch结束前没有收到任何关于计算结果的欺诈证明,Demander则确认此轮的计算结果无误.
在训练过程中,若在反向传播阶段开始前已经提交过欺诈证明,则需要等待所有欺诈证明得到验证后再启动反向传播. 若无欺诈证明,反向传播直接开始. 如果在反向传播过程中有挑战者提交新的欺诈证明,训练过程暂停;待所有欺诈证明处理完毕后,Demander重新整理数据并重启反向传播.
关于欺诈证明的处理,由验证者对欺诈证明相关的数据进行重现计算,并根据计算结果在合约中投票,以决定欺诈的真实性. 若欺诈行为真实存在,对应的Provider将受到惩罚,提交欺诈证明的挑战者会获得奖励. 反之,挑战者会被扣除信用值. 当存在多个欺诈证明时,按照提交顺序逐一验证. 对于同一样本的多个欺诈证明,如果之前已有挑战者提交并验证其真实存在,后续有关此样本的欺诈证明不再被验证,且无法从中获得奖励.
3.3. “红气球”激励
考虑到挑战者的收入来源于成功举报作恶的Provider,当网络中的Provider大多保持诚实的情况下,挑战者可能发现无论如何计算也无法提交欺诈证明,从而无法获取任何奖励. 这种消耗时间和资源而没有回报的情况会严重打击挑战者的积极性,减少挑战者寻找潜在错误数据的动力,而不积极的挑战者会降低整个系统的安全性.
为了解决可能出现的挑战者怠惰问题,从DARPA网络挑战赛[27]中获取灵感,引入“红气球”机制以提高挑战者的积极性. 在此机制中,当Demander向挑战委员会广播数据时,会刻意植入若干条错误数据,这些数据隐藏在正常的数据中,将其称之为“红气球”. 积极的挑战者会尽可能多地计算数据,从而更有可能找到数据中隐藏的“红气球”. 当挑战者找到“红气球”时,可以提交关于这条数据的欺诈证明. Demander可以自由调整挑战者的数量和“红气球”的数量,以平衡系统的安全性和操作成本. “红气球”和挑战者越多,系统的安全性越高,但是会提高训练的成本.
此激励机制存在诸多挑战. 首先,正常的数据会附带Demander或Provider的签名,而“红气球”不携带任何验证信息. 当挑战者向智能合约提交某条数据的欺诈证明时,合约无法判断此数据是否是“红气球”,因此挑战者可以随意伪造假的“红气球”来获取奖励. 同时,Demander可以否认真正的“红气球”,因为没有任何证据表明这条数据是Demander刻意设计的. 其次,因为样本的序列生成过程涉及多个token的顺序生成,且前后具有关联性,Provider可能在序列生成的中途或者末尾作恶,而Demander由于算力的限制,无法设计出此类“红气球”. Demander仅能够将第1个生成的token设计为“红气球”,这对于提高挑战者的积极性没有帮助,挑战者只须验证每个样本的首个token是否正确就可以轻易发现“红气球”,而无须对每个样本的整个序列生成过程进行计算. 最后,由于合约公开透明的特性,Demander不能将“红气球”直接上传到合约以供合约进行验证. 为了解决上述挑战,引入零知识证明[28]改进“红气球”机制,运行流程如图3所示.
图 3
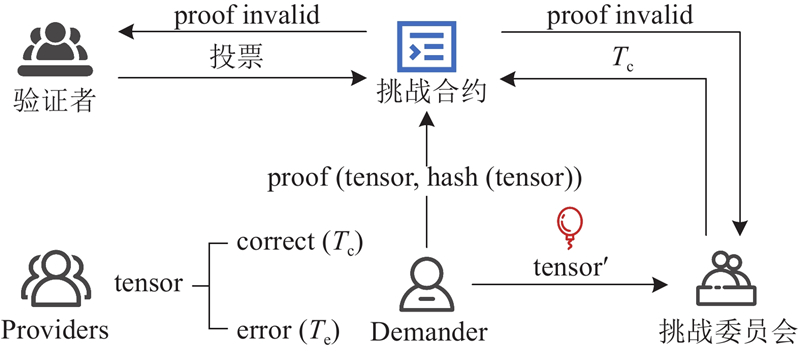
图 3 基于零知识证明的“红气球”激励机制运行流程
Fig.3 Workflow of "Red Balloon" incentive mechanism based on zero-knowledge proof
对于Provider生成的任意tensor,其结果只可能是正确或错误2种情况之一. 当Demander想要将某条计算数据构造成“红气球”时,将接收到的tensor作为秘密,并将tensor的hash作为公开信息来构造零知识证明. 在向合约提交零知识证明后,Demander刻意构造错误的tensor'广播至挑战委员会. 挑战委员会在收到此次前向传播的数据后进行重现计算,必然无法复现与tensor'相同的结果,由此认定这是1条错误数据. 随后,挑战者将其认为的正确计算结果Tc提交至合约. 合约利用Tc和Demander提交的proof进行验证,若验证成功,则表明Provider和挑战者的计算结果相同,Provider未作恶,且挑战者成功找到了“红气球”. 若验证失败,说明Provider和挑战者的计算结果存在差异,数据会交由验证者再次进行重现计算并投票,由合约根据投票结果来判断作恶方.
为了防止挑战者依据Demander上传证明的时间来推测“红气球”的出现时机,进而缩小需要验证的数据范围,“红气球”证明的上传与数据广播被设计为非同步进行的过程. 具体而言,Demander应先上传“红气球”,随后延迟一定时间再广播tensor′数据,实现证明与数据的异步传输,以增强系统的安全性.算法4为基于gnark库[29]实现的生成“红气球”的零知识证明过程.
算法4 生成“红气球”的零知识证明
输入:“红气球” secret、“红气球”的hash、零知识证明电路r1cs
输出:零知识证明proof
1: Function DefineCircuit (secret, hash) //定义零知识证明电路
2: mimc←NewMiMC (frontend.API)
3: mimc.Write (secret) //计算secret的哈希
4: AssertIsEqual (hash, mimc.sum()) //与给出的hash对比
5: pk, vk←groth16.setup (r1cs) //生成公钥、私钥
6: assignment←Circuit (secret, hash)
7: witness←frontend.NewWitness (assignment, BN254)
8: proof←groth16.Prove (r1cs, pk, witness) //生成零知识证明
通过上述改进,Demander能够以极低的计算消耗,在前向传播过程中的任何时间点生成“红气球”. 借助零知识证明,Demander能够向智能合约提交关于“红气球”真实性的证明,而无须披露“红气球”的内容. 这一机制有效地杜绝了挑战者未经实际计算即可轻易验证或猜测“红气球”的可能性.
值得注意的是,即使零知识证明的电路设计和秘密数据的哈希值对外公开,挑战者若不进行实际计算,也无法获知秘密数据. 更重要的是,由于哈希函数的性质,挑战者几乎不可能在有限时间内通过哈希碰撞的方法反向推导出原始的秘密数据,这极大地增强了系统的安全性.
4. 分析与实验
4.1. 特性分析
区块链是CompuDEX的运行基础,因此本平台拥有和区块链技术相同的诸多特性,在抵抗外部干扰以及保护用户隐私方面表现出强大的能力.
4.1.1. 去中心化
不同于银行、大型数据库等中心化权威机构,区块链的显著特色在于去中心化的网络架构. 借由点对点(peer-to-peer, P2P)网络,区块链数据并非集中存储,而是分布在全球各地的节点中,每个节点都保有完整的数据副本. 这种分布式的特性消除了单点故障,增强了系统的稳定性和安全性.
链上数据的一致性通过共识算法来保证. 比特币与以太坊这两大主流网络分别采用PoW与权益证明(proof of stake, PoS)达成共识. PoW要求矿工通过计算复杂哈希函数来竞争区块创建权,而PoS允许验证者通过质押代币获取记账资格. 比特币的全网算力近半年稳定在约5×108 TH/s[32](即每秒执行5×1020次哈希运算),以太坊的PoS质押总量已超过4 700万枚以太币(ETH)[33]. 对这2个网络发起51%攻击[34],无论是通过控制算力还是通过控制代币,都是几乎不可能完成的任务. 同时,区块链社区通过广泛协作的方式不断优化网络. 以太坊改进提案(Ethereum improvement proposal, EIP)[35]允许任何人通过提案参与社区治理. 例如,EIP-
区块链的去中心化特性和共识机制确保了其决策不受单一实体的操控. 以Uniswap为例,作为以太坊上最大的去中心化交易所,当面临因用户购入欺诈性代币而引发的法律诉讼时,其去中心化的特性成为关键辩护点. 法庭认为Uniswap本身不具备对代币发行及用户交易的控制能力,加之代币发行者的匿名性导致无明确被告,最终裁定Uniswap不承担责任. 此外,任何企图干预区块链运行的行为都极其困难. 尤其是在面对外部压力时,这种特点使得区块链展现出强大的韧性. 龙卷风现金(Tornado Cash)作为以太坊上的项目,虽然受到美国政府的制裁,但是不仅没有被真正地关闭,而且资产价值依然超过了5.6亿美元[36]. 这充分体现了区块链的去中心化特性,即使其面临强大的外部干扰,也能保持功能和服务的连续性.
4.1.2. 隐私性
门罗币(Monero)[43]作为高度注重隐私的加密货币,凭借先进的匿名技术获得了广泛关注. 其采用环签名、隐蔽地址等技术,确保交易不可被追踪,常被用于需要隐私保护的支付场景.
4.2. 成本分析
CompuDEX旨在利用闲置算力进行模型训练,但是闲置算力Provider的成本难以被准确评估. 同时,网络中不乏希望通过投资新硬件来获取收益的投资者. 这类投资者提供的服务质量通常最优,但是成本也最高. 为了验证CompuDEX的可行性,即不论何种算力提供方都存在利润空间,以及租用高质量服务相比于租用云服务器在成本上仍然具有优势,在成本分析实验中选择成本最高的投资者作为计算依据. Provider仅参与训练过程中的前向传播阶段,反向传播阶段由Demander在本地执行,不需要对任何人付费,故只对比前向传播阶段的成本.
4.2.1. Provider计算成本
Provider成本可以细分为以下3个主要部分.
1)电费:以国内电价0.6元/(kW·h)估算[44],V100的满载功率为250 W,则电费为0.15元/h.
2)硬件成本:通过调研国内多家云服务商的产品信息,可以发现V100是我国大多数云服务商能够提供的最先进的GPU,因此选用V100作为Provider的投资目标. 鉴于我国市场上缺乏公开的官方销售渠道,参考亚马逊平台在美国的V100售价,约为10 500元. 此外,在使用GPU加速训练的过程中,CPU等其余硬件的作用相对较小,且价格相差巨大,故本研究主要关注GPU的成本. 以显卡常规保修期限3 a的一半,即18个月作为逾期投资回收周期,计算得出V100平均成本为0.82元/h.
3) 智能合约调用成本.
4.2.2. 智能合约调用成本
智能合约作为训练过程中重要的一环,为训练的发布、存证等环节提供了安全性保证. 计算调用合约时的Gas费:
1) PreferMatch. 对PreferMatch阶段的参与者通过合约提交任务相关信息时的Gas消耗进行分析. Demander通过合约保存任务的描述信息,这些信息本质上是以字符串(String)表示的文本. 使用String长度为100、200、400和800的文本进行调用,每调用10次取平均值,得到的Gas消耗数量分别为117 727、184 327、317 527和583 872. 当String长度为800时,根据式(4)计算得到费用约为0.15元. 2)随机选择合约. 对挑战者随机选择合约时的Gas消耗进行分析,在报名人数N=4、8、16、32的情况下,分别设置挑战者比例为25%、50%、75%和100%,对每种情况进行10次调用并取平均值,得到的Gas消耗如表1所示.当32个Provider报名时,最大GasUsed=166 628,根据式(4)计算得到费用约为0.05元.
表 1 不同挑战者比例和报名人数对应的Gas消耗
Tab.1
| 挑战者比例/% | GasUsed | |||
| N=4 | N=8 | N=16 | N=32 | |
| 25 | 34 049 | 42 312 | 62 930 | 98 863 |
| 50 | 36 495 | 49 735 | 70 229 | 125 146 |
| 75 | 37 577 | 52 232 | 85 337 | 149 648 |
| 100 | 38 096 | 56 457 | 96 180 | 166 628 |
综上所述,在本方案中调用合约的费用相比于训练产生的费用非常低. 在长期的训练过程中,PreferMatch和随机选择仅执行1次,因此这部分开销放在整个训练成本中几乎可以忽略不计.
4.2.3. 成本对比
在实际场景中,Provider不会以成本价提供服务,因此在Provider的计算成本0.82元上增加10%的利润,用于模拟实际情况. 同时,设置与计算成本总价相同的奖励用于模拟挑战者的激励成本,以进一步提高真实性.
在对比对象方面,由于每个云服务商的商品不同,其售价也存在差异,实验在保证GPU加速卡统一为单张V100的情况下,尽可能地选择硬件条件相似的方案,分别为阿里云的ecs.gn6v-c8g1.2xlarge、腾讯云的GN10X.2XLARGE40、百度云的bcc.gn3.c8m64.1v100-32g和华为云的GPU加速型G5. 其按量付费的价格分别为26.46、18.04、15.24和22.28元/h.
对比5种方案下0~500 h的租用成本,如图4所示,其中t为租用时间,C为花费,p为租用单价.CompuDEX的租用单价是其他云服务器商的8%~14%,并且随着训练时间的增加,成本的差距越来越大. 云服务商的“按量付费”模式本质上是按时间计费,只是时间可以暂停,但是在使用时难免会出现空跑的情况. 在大模型动辄几十、上百小时的训练过程中,这种浪费会被进一步地放大. CompuDEX不仅支持按小时租用,而且能够真正地实现“按量付费”.
图 4
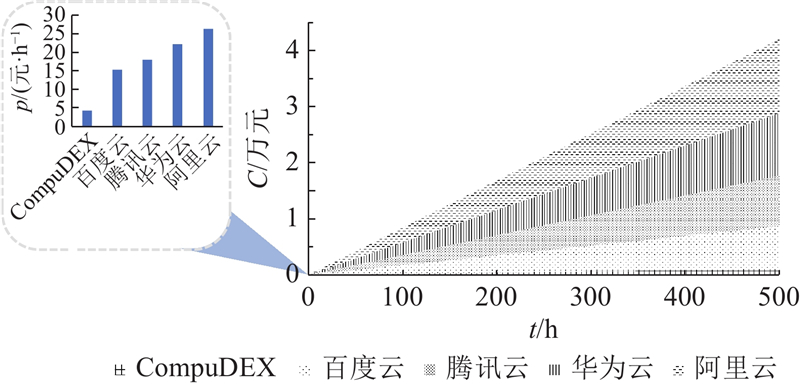
图 4 CompuDEX与云服务商租用价格对比
Fig.4 Comparison of rental prices of CompuDEX and cloud service providers
与云服务商相比,CompuDEX的另一大优势在于,其可以使用户租用到国内云服务商无法提供的先进计算设备. 尽管国外先进的计算设备无法进入中国市场,但是这并不妨碍海外用户通过加入区块链网络,为我国用户提供额外的算力支持. CompuDEX不仅拓宽了可用资源的范围,而且促进了跨国界的计算资源共享,为用户提供了更多样化的选择.
4.3. 效率分析
效率分析实验聚焦于CompuDEX相较于传统训练流程附加的步骤所造成的潜在效率损失. 从2个维度进行分析:1)分析激活值在网络中的传输时延对训练时间的影响;2)分析加密、解密、签名、验签以及零知识证明的生成与验证的效率. 实验环境为搭载AMD Ryzen 7 5800H@3.2 GHz处理器、内存为64 G、磁盘空间为1 TB的主机. 在网络传输实验中,采用1台阿里云轻量服务器与主机交互,配备2vCPU,内存为2 G,带宽为3 Mb/s. 实验过程中加密、解密、签名以及验签的算法使用python的cryptography[47]标准库实现,零知识证明的生成与验证借助gnark库完成.
4.3.1. 网络传输时延
CompuDEX虽然对LoRA微调流程进行了调整,但是没有增加任何的计算负载,只增加了激活值在网络中传输的时间. 在租用云服务器进行训练的过程中,数据被预先上传至服务器,使得实际训练与本地训练相当,即无须承担网络延迟的影响. 因此,将数据在硬件中流转的时间忽略不计,只专注于CompuDEX在网络传输层面引入的时间开销.
实验选用的传输数据为单个token通过Llama2-7B模型的embedding层的输出结果,为1个大小为[1, 14 096]的tensor,约为32 KB. 通过使用局域网、HTTP请求以及使用WebSocket通信协议3种方式对数据传输时延进行测试,其中HTTP请求分为使用公网IP和使用域名2种方式. 连续执行100次测试的时间消耗统计结果如图5所示,其中n表示第n次测试,t为每次测试消耗的时间.可以看出,内网传输数据相对稳定;通过HTTP传输时,时延普遍在80~110 ms,且波动较大;通过WebSocket传输的效果较好,相对于发起HTTP请求,能够大幅降低时延,且更加稳定.
图 5
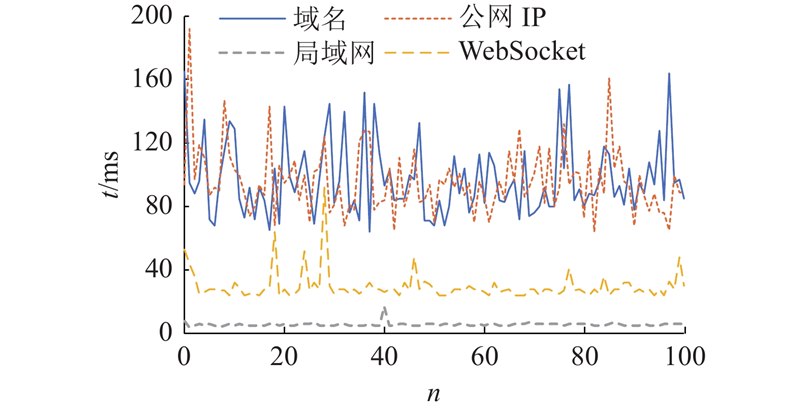
图 5 不同网络传输方式的时延对比
Fig.5 Latency comparison of different network transmission methods
使用WebSocket进行传输的时延相对较小的原因在于,大模型训练时的token处理速度非常快,单张V100显卡对Llama2-7B进行推理时平均每秒能生成25.2个token[48]. 若进行HTTP请求,每一次发送请求时都需要创建连接,而且由于发送的频率非常高,HTTP请求还会面临因连接池耗尽而导致的连接断开问题,不适用于本平台的使用场景. WebSocket只需要建立1次连接就可以以全双工的模式交互数据,时延较低,且更加地稳定,适用于本平台的使用场景.
对所有数据取平均值,并对SAMSum-train数据集的共1 620 520条数据模拟计算后得到的结果如表2所示. 其中,tind为单条数据的传输时间,tsum为整个数据集的传输时间总和.
表 2 不同网络环境中的tensor传输时间
Tab.2
| 网络环境 | tind/ms | tsum/h | 网络环境 | tind/ms | tsum/h | |
| 局域网 | 5.39 | 2.43 | 域名 | 96.53 | 43.45 | |
| 公网IP | 95.88 | 43.16 | WebSocket | 29.67 | 13.36 |
从平均单次时间可以看出,相对于V100本地推理速度,即25.2个token/s,单个token经过网络传输后,生成效率会增加约75%. 从累计时间可以看出,当Demander和Provider以1对1串行的方式收发数据时,完整推理整个SAMSum-train数据集需要额外消耗大约13.36 h. 然而,本方案中往往不只1个Provider参与训练;当多个Provider并行收发数据时,传输时间会有所降低.
4.3.2. 压缩传输
由于实验使用的数据为7B模型的隐层输出,当使用float64作为数据类型时,隐层的输出大小约为32 KB. 然而,随着模型参数量的上升,隐层的输出大小会进一步增大. 例如,13B和70B模型的隐层维度分别为5 120和8 192,使用float64作为数据类型时的隐层输出大小约为40 KB和64 KB. 为了降低数据在网络中的传输时间,对数据进行压缩处理,并统计压缩时间、解压缩时间等参数. 如表3所示,统计数据为执行100次后取平均值的结果. 其中,tc为压缩时间,td为解压时间,sc为压缩后的文件大小,r为压缩率,即原始文件大小与压缩后文件大小的比值.
表 3 不同压缩方式下tensor的压缩效率
Tab.3
| 压缩方式 | tc/ms | td/ms | sc/KB | r |
| 32 KB/Gzip | 1.92 | 5.59 | 16.81 | 1.97 |
| 32 KB/Bz2 | 2.40 | 10.81 | 14.85 | 2.23 |
| 40 KB/Gzip | 2.32 | 4.61 | 20.78 | 1.98 |
| 40 KB/Bz2 | 2.63 | 12.52 | 18.29 | 2.25 |
| 64 KB/Gzip | 3.44 | 5.40 | 32.74 | 1.99 |
| 64 KB/Bz2 | 3.54 | 16.30 | 28.39 | 2.30 |
分别采用原始数据和压缩后的数据进行网络传输,并统计传输时间,结果如表4所示. 其中traw为tensor直接在网络中传输的传输时间,tcomp为tensor压缩后在网络中的传输时间,ttot为压缩时间和传输时间的总和,sT为tensor大小.
表 4 直接传输和压缩传输的传输时间
Tab.4
| sT/KB | traw/ms | tcomp/ms | ttot/ms | |||
| Gzip | Bz2 | Gzip | Bz2 | |||
| 32 | 26.35 | 18.21 | 17.84 | 33.23 | 44.26 | |
| 40 | 27.68 | 20.76 | 19.76 | 34.62 | 50.06 | |
| 64 | 39.02 | 23.20 | 21.69 | 40.88 | 61.37 | |
此外,实验采用的数据类型为float64. 值得注意的是,在当前大语言模型的训练实践中,为了优化内存占用和计算资源,float16是更为常用的数据类型. 若采用float16,7B、13B和70B模型的隐层输出大小将分别降低至约8 KB、10 KB和16 KB. 这将降低网络传输本身带来的时延,从而进一步削弱压缩传输在提升传输效率方面的优势.
随着传输数据规模的增大,压缩传输的总耗时与直接传输时间的差值呈现逐渐缩小的态势. 据此推断,当模型的参数规模达到或超过1.35×1011,且采用高精度的数据类型时,压缩传输的耗时将少于直接传输. 同时,对网络带宽受限而计算能力强大的用户而言,压缩传输亦可作为一种有效手段,缓解因网络瓶颈造成的高延迟问题.
4.3.3. PreferMatch耗时
任务发布阶段涉及任务信息的加密、解密、签名以及验签过程,下面将对此阶段的运行效率进行分析.
对1段132 KB的任务描述文本使用RSA非对称加密算法执行加密、解密操作,并对原文实施签名以及验签操作,使用的RSA密钥长度为2 048. 鉴于单次操作耗时较短,为了提高统计数据的精度,以100次操作为1个计算单元,执行10次取平均值. 结果显示,加密与签名共耗时约64 ms,验签与解密共耗时约63 ms. 基于cryptography库实现的加密、解密、签名和验签过程如算法5所示.
算法5 RSA加密、解密、签名与验签
输入:原始文本 text
输出:签名signature、密文ciphertext
1: private_key = rsa.generate_private_key (public_exponent =
2: public_key = private_key.public_key () //生成公钥
3: ciphertext = public_key.encrypt (text.encode (), padding.OAEP(mgf = padding.MGF1 (algorithm = hashes.SHA256()), algorithm = hashes.SHA256(), label = None ) ) //加密生成密文
4: signature=private_key.sign (text.encode(), padding.PSS(mgf=padding.MGF1 (hashes.SHA256()), salt_length=padding.PSS.MAX_LENGTH), hashes.SHA256()) //对原文进行签名
5: ciphertext_base64 = base64.b64encode (ciphertext).decode("utf-8")
6: signature_base64 = base64.b64encode (signature).decode("utf-8")
7: public_key.verify (base64.b64decode (signature_base64), original_text.encode(), padding.PSS (mgf = padding.MGF1 (hashes.SHA256()), salt_length = padding.PSS.MAX_LENGTH), hashes.SHA256()) //对签名进行验证
8: decrypted_text = private_key.decrypt (base64.b64decode (ciphertext_base64), padding.OAEP (mgf = padding.MGF1 (algorithm = hashes.SHA256()), algorithm = hashes.SHA256(), label = None)) //解密
尽管RSA对加密内容存在一定限制,例如使用2 048位的密钥时,可以加密的最大明文长度为190 B. 为了进一步验证PreferMatch在处理较长任务描述文本时的高效性,对长文本的处理效率进行分析实验.
由于长文本与短文本不同,采用的实验方法略有不同. 发送方首先采用对称加密算法AES对原文加密,然后使用算法RSA加密AES密钥,并对原文签名. 随后,发送方传输AES密文、RSA密文及签名. 接收方先通过RSA解密AES密钥,再用AES解密密文,最后完成验签过程. 实验中明文数据大小为1 KB,每组实验包含10次操作,共执行10组实验以获取平均值,得到发送方的平均耗时约为429.11 ms,接收方的平均耗时约为856.89 ms.
综上所述,无论面对短文本还是长文本,PreferMatch均能在极短时间内完成数据的加密、解密以及签名、验签工作. 在每一次训练任务中,PreferMatch仅须执行1次,在长达数十甚至数百小时的训练周期中,其耗时几乎可以忽略不计. 此外,实验以RSA为例执行加密、解密以及签名和验签操作,但是不将PreferMatch与RSA进行强制性绑定,用户在实际使用时可以自由选择合适的加密算法.
4.3.4. 签名与零知识证明效率
在训练过程中,除了网络传输时延、tensor的签名与验签,“红气球”激励机制中零知识证明的生成与验证亦会产生一定程度的效率损失. 为了量化这些因素对训练效率的影响,采用Llama2-7B模型的embedding层输出作为测试数据,该层产生的tensor序列化后的大小为32 KB. 为了验证CompuDEX对更大的模型的兼容性,进一步构造64 KB和128 KB的数据进行统计分析. 鉴于单次签名和验签的时间极短,采取累计10次连续操作的总耗时以获取更准确的测量值. 实验共收集100组样本数据,得到的统计结果如图6所示. 其中n表示第n个数据,t为签名、验签、生成零知识证明或验证零知识证明所需的时间.
图 6
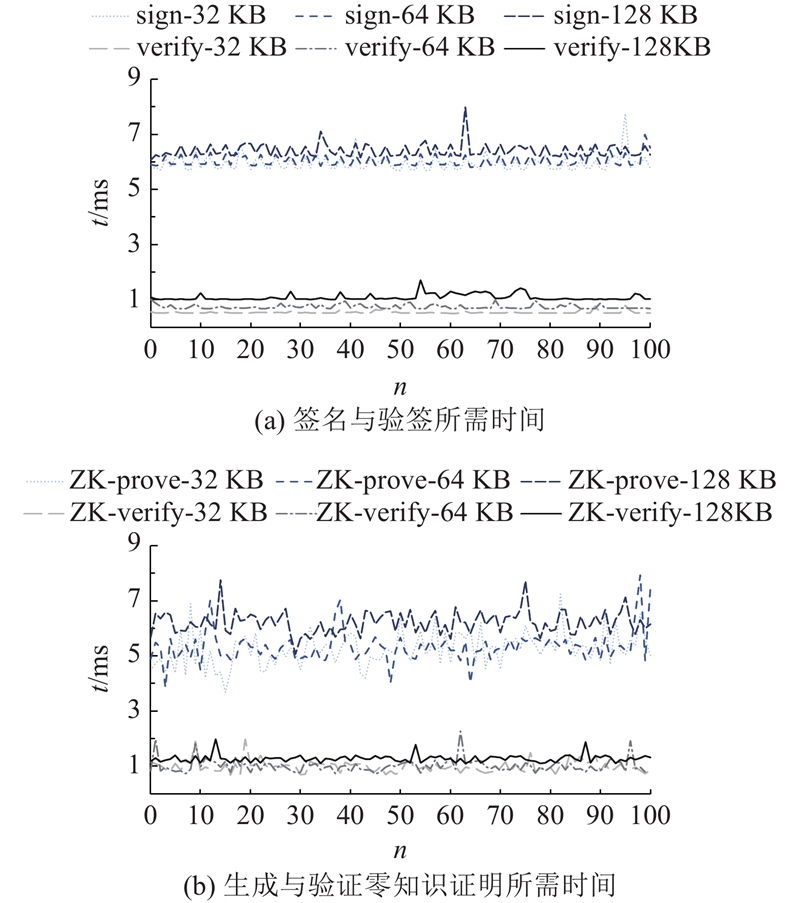
图 6 签名与零知识证明在不同数据量下的耗时
Fig.6 Time consumption of signatures and zero-knowledge proofs with varying data volumes
实验结果表明,对32 KB的数据签名10次消耗的时间为6.232 ms. 因此,对SAMSum-train数据集的所有token进行签名需要消耗0.28 h,验签时间仅为签名时间的大约1/6. 这一时间成本远低于训练及数据传输所需的时间,几乎可以忽略不计.
“红气球”激励机制经过特殊的设计,仅需精简的零知识证明电路即可保障安全性,体现出优越的性能. 由图6可知,尽管生成证明所需的时间随数据规模的扩大而略有增长,但是总体上保持在4~7 ms. 即使面对数据量的增加,验证过程的耗时也持续稳定在1 ms左右,具有稳定的高效表现.
4.4. 综合实验
为了深入阐述CompuDEX平台的可用性和性能优势,设计一系列真实世界实验以及模拟实验,包括1对1、1对2、1对4及1对8的训练场景,并将其与租用云服务器进行训练的标准方案进行对比. 实验设计如下.
首先采用4台配置为64 G内存、32核Intel Xeon Gold
图 7
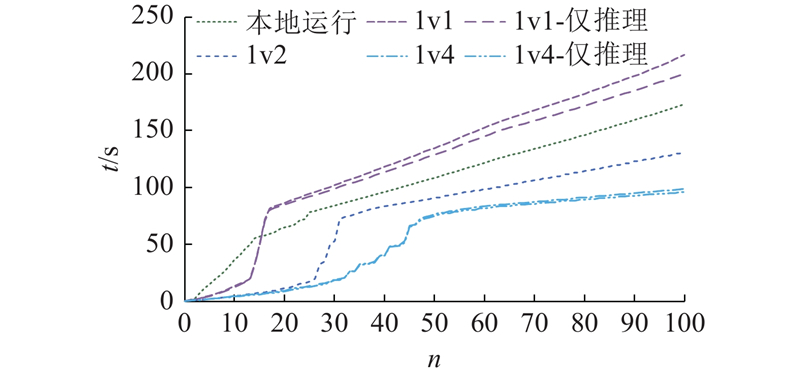
图 7 真实环境中不同并行Provider数量的推理时间
Fig.7 Inference time for different numbers of parallel providers in real-world environment
对比本地运行与单节点运行的结果可知,随着token的不断生成,由于网络延迟与额外操作的存在,时间消耗差距不断增大,但是主要的效率差距来源于CPU推理计算的时间差异. 当2个节点并行训练时,其推理效率就已经超过本地运行;当4个节点并行推理时,推理效率进一步提高.
尽管采用的Llama2-7B模型的参数量相对较小,但是每个token的推理依然需要超过1 s的计算时间. 相比之下,除模型推理以外的额外时延仅为几十毫秒. 在实际训练中,GPU的推理性能显著优于CPU,可能会使实验结果发生变化. 为了排除硬件性能差异对计算时间的影响,采用程序延时的方式模拟Demander和Provider的计算流程. 根据V100 GPU在Llama2-7B上的平均推理速度(25.2个token/s),设定每个token在Demander和Provider中的推理时延均为40 ms. 此外,签名和验证操作的时延分别参照4.3.4节中通过实验得出的平均值,即0.6和0.1 ms.
Provider在1台配置为8核心英特尔Xeon E5-
图 8
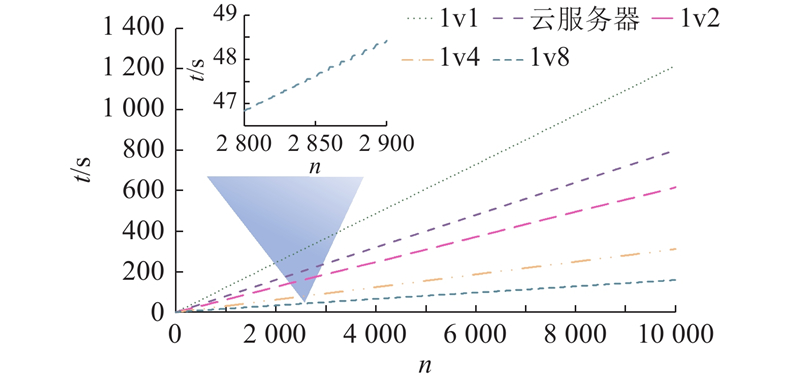
图 8 并行Provider数量对生成token所需时间的影响
Fig.8 Impact of parallel provider counts on token generation time
以单个token的生成时间为单位统计数据,共记录了10 000个token的生成时间. 相邻token的生成时间间隔仅为几十毫秒,导致token生成时间整体上在图中表现为近似连续的直线. 为了更直观地展示生成时间的变化趋势,对1v8训练模式下第2 800~2 900个token的生成时间进行放大观察. 结果显示,时间增长呈现出阶梯状的变化. 产生这种现象的原因在于,在并行训练的过程中,Demander会在短时间内接收到多个Provider的数据,这使得图中token生成时间的变化表现出较为平缓的趋势;而等待接收下一轮token的过程需要经过Demander和Provider的本地计算以及网络传输过程,耗时较长,因此在图中表现为明显的上升趋势. 综上所述,从长期看,token生成时间呈现出近似于直线的上升趋势;从短期看,其表现为阶梯状上升.
在1对1训练模式下,CompuDEX生成10 000个token的时间大约为云服务器的152%. 在加入了签名和验签操作的情况下,这一比例相较于4.3.1节中提到的175%的单次网络传输时延仍然有所下降,其原因在于,此次实验中对Demander设置的40 ms推理时延高于网络传输和签名、验签所需的时间,在一定程度上抵消了额外操作带来的效率损失.
当采取1对2训练模式时,CompuDEX的效率超越了云服务,生成时间为云服务生成时间的77%. 在1对4和1对8训练模式下,CompuDEX的效率进一步提高,生成时间分别仅为云服务器的39%和20%. 这表明随着并行节点数量的增加,网络延迟等额外操作的时间可以得到补偿,整体执行效率能够实现显著的提升. 然而,并行节点数量的增加也对用户网络带宽提出了更高的要求.
为了进一步验证CompuDEX的可行性和实际应用价值,在生成token的过程中,利用nload工具在公网服务器上监测从训练开始前10 s起、持续2 min的网络入站和出站实时流量. 监测结果如图9所示,其中t为训练时间,BW为占用的带宽.可以看出,尽管并行节点数量的增加提升了对网络带宽的要求,但是在8个节点并行训练的情况下,所需带宽仅为20 Mb/s. 结合运行效率而言,当并行节点数达到2个时,即可实现较为理想的效果,此时对带宽的需求仅为5 Mb/s.
图 9
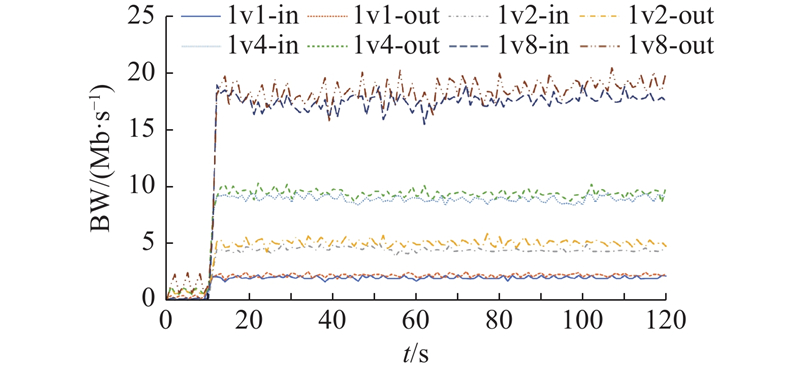
综上所述,CompuDEX的并行性有效抵消了网络延迟及其他额外操作对效率的影响. 具体来说,当2个节点并行时,生成时间仅需云服务器的77%,同时对带宽的需求保持在5 Mb/s;当并行节点数进一步增加至4个和8个时,生成时间仅需云服务器的39%和20%,相应的带宽需求仅为10和20 Mb/s. 这表明CompuDEX不仅能够显著提高训练效率,而且在资源消耗方面表现出色.
根据4.1节中的分析,本平台确保参与者身份匿名,监管方难以通过链上伪身份追溯至真实个人,从而削弱了对参与者实施管控的能力. 区块链固有的去中心化与抗审查特质排除了单一权威机构掌控全网的可能性. 网络中的数据被分散存储于各节点,受共识机制的保护,加大了监管方审查或篡改数据的难度. 因此,所提基于区块链的算力服务平台能够展现出抵御外界干预的强韧特性.
由于计算准确性由挑战委员会提供保障,如果Provider想要通过构造数据来欺诈Demander,骗取其报酬,Provider则必须和挑战者共谋. 然而,挑战者的收益来源于寻找Provider的错误数据,若挑战者和Provider共谋,自身则会没有收益. 而且,只要挑战委员会中存在至少1个诚实的挑战者,即可甄别Provider潜在的不端行径. 因此,Provider攻击成功的唯一可能在于控制挑战委员会中的所有成员,尽管挑战者皆源自网络中的高信用节点,但是仍然不能排除同一委员会中的所有成员均被控制的极端情况. 以下对此情形进行详细分析.
假设有N名挑战者申请加入挑战委员会,攻击者控制了其中K名挑战者,随机选择合约随机选择X名挑战者. 只有当X
式中:Pcmp为挑战者被完全控制的概率.
根据式(5)计算出当N=8时可能出现的所有情况,如图10所示.挑战委员会被完全控制的概率随恶意节点数量的增加而升高,其峰值接近0.9. 然而,通过增加选取的挑战者人数,这一风险能够得到有效抑制,概率降至大约0.1. 值得注意的是,增加选择的挑战者数量在初始阶段对风险降低有显著效果,但是当选择的挑战者数量继续增加时,出现边际效应. 另一方面,减少恶意节点的占比,对于降低被控制风险的效果明显. 但是随着恶意节点比例的进一步下降,其带来的效益相应地减弱. 因此,为了尽可能避免挑战委员会被控制的情况发生,应结合使用增加报名总数和增加选择的挑战者数量2种方式来降低概率. 可以观察到,当恶意节点占比少于50%时,概率Pcmp低于0.5. 现实中申请加入的节点相对诚实,所以实际的概率会低于理论值.
图 10
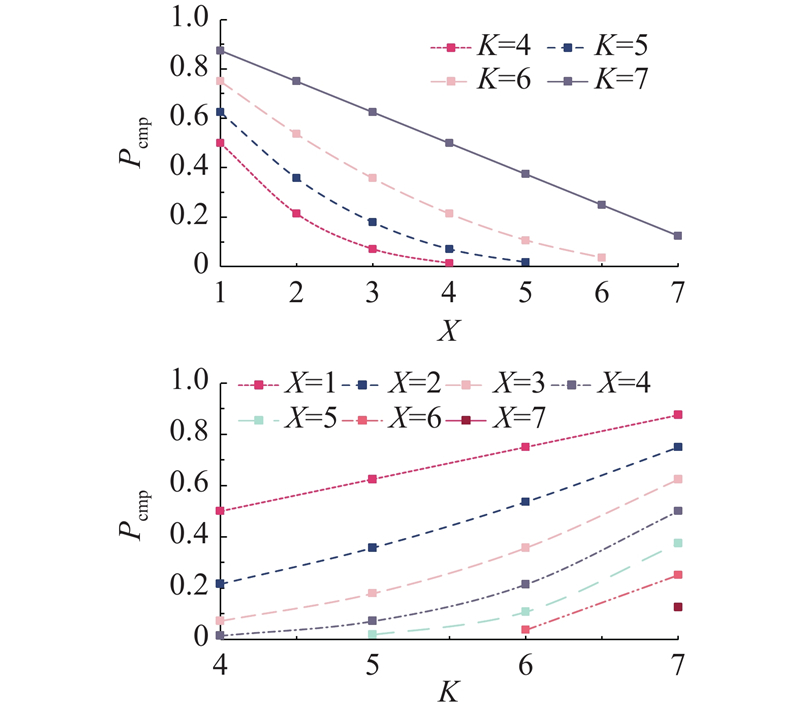
图 10 挑战委员会被完全控制的概率变化
Fig.10 Change in probability of challenge committee being completely controlled
此外,如果部分挑战者被控制,由于诚实的挑战者数量减少,会延长错误数据被发现的时间. 一旦此时间超过预定结束时间,可能会产生安全问题. 为了进一步分析被控制的挑战者比例对系统安全性的具体影响,设计模拟攻击实验.
分析4个Provider进行计算,8个挑战者进行检查的情况. 实验中,假设Provider和挑战者具有相同的计算能力,即4个Provider将会同时提供每一轮的计算结果,8个挑战者同时完成验证计算,每个样本的输出长度限制为1 000. 挑战者们每次接收到Provider的计算结果后,随机选择自己没有验证过的数据进行验证,选择过程完全随机,且挑战者之间互相不知道对方验证了哪些数据. 统计4个Provider均在第
表 5 不同诚实挑战者数量下检查错误数据所需时间
Tab.5
| N−K | 平均轮数 | treq/ms | text/ms |
| 1 | 100.07 | 60.07 | |
| 2 | 79.80 | 39.80 | |
| 4 | 64.36 | 24.36 | |
| 8 | 53.58 | 13.58 |
由实验结果可知,随着诚实挑战者数量的减少,检查出所有错误数据所需的时间逐渐增加. 虽然增加的时间较短,但是模型参数量、挑战者计算能力的差异以及输出长度的提高,均会对其产生影响. 如果Demander在Provider计算结束后立刻结束前向传播阶段,则存在有错误数据未被发现的风险. 因此,Demander可以多等待一段时间,使挑战者对计算结果进行充分验证,从而提高安全性.
此外,Demander可以通过给挑战者发送单独的“红气球”,检查其是否在检查数据. 如果该挑战者长时间没有提交关于“红气球”的欺诈证明,则证明其没有正常工作,Demander可以向平台提供证据,对该挑战者进行惩罚,从而进一步提高平台的安全性.
对比分析两大旨在缓解本地算力瓶颈的解决方案,即Truebit与PrivateLoRA. 对比结果如表6所示.
表 6 CompuDEX与其他算力瓶颈解决方案对比
Tab.6
| 方案 | 匿名性 | 隐私保护 | 运行成本 | 安全性 | 通用性 |
| Truebit | √ | × | 高 | 高 | 高 |
| PrivateLoRA | × | √ | 中 | 中 | 低 |
| CompuDEX | √ | √ | 低 | 高 | 中 |
Truebit协议采用冗余计算和区块链技术,实现了计算任务的外包. 多个Truebit节点执行同一任务,随后由验证中心评估执行结果的完整性,确保在至少有1个诚实节点的前提下识别并惩罚恶意行为. 同时,区块链技术可以有效保障参与节点的身份安全. 然而,Truebit协议要求将全量计算数据透明地展示给节点,无法维护数据集和模型权重的隐私. 此外,多节点冗余计算会使得训练成本成倍增加.
PrivateLoRA与CompuDEX皆通过改进LoRA微调架构来增强隐私保护,但是PrivateLoRA缺乏对云端计算结果的安全性审计,只适用于半诚实假设下的云服务环境. 且该方案未采取隐匿参与者身份的措施,影响了其广泛应用.
相比之下,CompuDEX不仅通过调整微调架构保护了数据隐私,而且依托区块链及多重安全机制,实现了用户身份的匿名化与计算过程的安全监控,使用户得以利用空闲算力,以较低成本高效地微调大模型. 尽管CompuDEX作为LoRA架构的衍生方案,可能并非所有大模型的理想微调方案,但是由于其仅优化了训练流程而未变更架构,能够兼容所有LoRA变体,且与现有的高效Transformer推理方法相互补充,提高了通用性.
5. 结 语
针对大模型微调所需的高算力和云计算的高成本问题,提出基于区块链的大模型微调算力共享平台CompuDEX. 首先,CompuDEX提供了可靠的去信任交易环境,同时允许参与者匿名操作,能够保护参与者的隐私. 基于智能合约和密码学技术设计的PreferMatch提高了用户选择的自由度,确保Provider之间公平竞争,从而提高了服务质量并进一步降低了训练成本. 其次,通过优化LoRA框架,仅将需要训练的LoRA模块保留在本地,实现了在不增加计算负担的条件下,确保模型和数据集的隐私安全. 最后,基于零知识证明设计“红气球”激励机制,以此激励挑战委员会检查计算结果,有效识别并惩处Provider的恶意行为.
实验结果表明,在经济层面上,CompuDEX的成本仅为租赁云服务器训练时的8%~14%. 在效率层面上,虽然当1对1训练时,CompuDEX在前向传播阶段最多会产生75%左右的额外时间开销,但是由于其并行化的特性,随着Provider数量的上升,CompuDEX的运行时间能够降低至云服务器的20%甚至更低. 同时,相较于现有两大缓解算力瓶颈的方案,CompuDEX展现出更为全面的优势.
CompuDEX仍然存在不足之处,这也将成为未来的研究方向. 首先,尽管已经通过限制验证者的来源来提升平台的可靠性,但是仍须假定超过半数的验证者保持诚实,才能确保系统的安全性. 未来将对前向传播阶段的计算进行细分处理,旨在识别计算任务中的冲突点,从而降低验证任务的复杂度,使验证计算能够直接在智能合约中执行,最终实现完全的去信任验证环境. 其次,虽然CompuDEX已经显著降低了对Demander硬件配置的需求,但是仍须具备本地LoRA模块的训练能力. 而且当并行节点数量增加时,对于Demander的网络带宽也有较高要求. 为此,将致力于探索更为高效的训练框架,以进一步削减Demander的硬件门槛,使其具备更为广泛的适用性.
参考文献
The miR-200 family and miR-205 regulate epithelial to mesenchymal transition by targeting ZEB1 and SIP1
[J].
GPT-3: its nature, scope, limits, and consequences
[J].DOI:10.1007/s11023-020-09548-1 [本文引用: 1]
Parameter-efficient fine-tuning of large-scale pre-trained language models
[J].DOI:10.1038/s42256-023-00626-4 [本文引用: 1]
基于同态加密的神经网络模型训练方法
[J].DOI:10.11896/jsjkx.220300239 [本文引用: 1]
Neural network model training method based on homomorphic encryption
[J].DOI:10.11896/jsjkx.220300239 [本文引用: 1]
Low-latency privacy-preserving outsourcing of deep neural network inference
[J].DOI:10.1109/JIOT.2020.3003468 [本文引用: 1]
基于区块链的外包安全多方统计计算可验证隐私保护方案
[J].DOI:10.3969/j.issn.1003-3106.2024.04.007 [本文引用: 1]
Blockchain-based outsourcing secure multi-party statistical computation verifiable privacy protection scheme
[J].DOI:10.3969/j.issn.1003-3106.2024.04.007 [本文引用: 1]
Blockchain challenges and opportunities: a survey
[J].DOI:10.1504/IJWGS.2018.095647 [本文引用: 1]
A survey of blockchain consensus protocols
[J].
LoRa+: an extension of LoRaWAN protocol to reduce infrastructure costs by improving the quality of service
[J].DOI:10.1016/j.iot.2020.100176 [本文引用: 1]
On tight security proofs for Schnorr signatures
[J].DOI:10.1007/s00145-019-09311-5 [本文引用: 1]
Towards secure industrial IoT: blockchain system with credit-based consensus mechanism
[J].DOI:10.1109/TII.2019.2903342 [本文引用: 1]
Reservoir-sampling algorithms of time complexity O(n(1+log(N/n)))
[J].DOI:10.1145/198429.198435 [本文引用: 1]
Reflecting on the DARPA red balloon challenge
[J].DOI:10.1145/1924421.1924441 [本文引用: 1]
A survey on zero-knowledge proof in blockchain
[J].DOI:10.1109/MNET.011.2000473 [本文引用: 1]
The 51% attack on blockchains: a mining behavior study
[J].DOI:10.1109/ACCESS.2021.3119291 [本文引用: 1]
区块链数据安全管理和隐私保护技术研究综述
[J].
Review of blockchain data security management and privacy protection technology research
[J].
A blockchain privacy protection scheme based on ring signature
[J].DOI:10.1109/ACCESS.2020.2987831 [本文引用: 1]
GarliChain: a privacy preserving system for smart grid consumers using blockchain
[J].
Traceable Monero: anonymous cryptocurrency with enhanced accountability
[J].DOI:10.1109/TDSC.2019.2910058 [本文引用: 1]
AI预训练大模型发展综述
[J].
Overview of the development of AI pre-trained large models
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}