

在雾天情况下,户外成像设备的信息采集会受到干扰,导致对比度下降、细节丢失,进而对交通监测、自动驾驶、遥感航拍等下游基于视觉的系统造成影响[1]. 因此,图像去雾研究显得至关重要.
早期雾天成像机理未被揭示时,图像去雾主要通过图像增强的方式实现,例如直方图均衡化[2]、小波变换[3]、Retinex[4]算法等,通过对图像整体进行对比度增强,进而提高图像视觉效果,但其本质并不能算作去雾. 直到大气散射模型被提出,雾气对视觉效果的影响得到了有效解释,后续基于该理论的图像去雾先验被陆续提出,如He等[5]提出的暗通道先验,基于有雾图像和清晰图像在最小通道上存在的关系求解透射率. Meng等[6]提出通过边界约束求解透射率. Zhu等[7]通过对大量图像进行统计,得出雾的分布与景深存在非线性关系,通过拟合景深估计函数求解透射率. Berman等[8]依据有雾图像中不同颜色在聚类后形成的簇,在RGB颜色空间内沿大气光方向线性分布提出雾线先验. Wang等[9]通过对有雾图像和无雾图像的最小颜色通道进行线性近似,快速求解透射率. Li等[10]提出通过快速伽马变换求解雾浓度分布的浓度尺度先验. 基于先验的去雾算法可以直接求解清晰图像,但鲁棒性欠缺且细节难以保留.
随着深度学习逐步成熟,其成为图像去雾领域的另一种主流方式. 基于神经网络强大的特征提取和映射能力,Li等[11]提出AOD-Net,将透射率求解和大气光估计统一起来,直接最小化重构误差,避免了传统模型中复杂的估计步骤. Chen等[12]提出GCA-Net,通过端到端的门控上下文聚合网络,融合不同层次特征. Bai等[13]提出SGID,通过深度预去雾器生成参考图像,利用渐进特征融合模块提升去雾效果. Zhou等[14]提出DWT-GAN,将特征提取转换到频域,充分挖掘低频、高频特征关系,并引入强大的预训练网络进行信息补充,提高泛化能力. Wang等[15]提出UCL-Dehaze网络,通过无监督对比学习和自对比感知损失函数,缓解域迁移问题并提升去雾性能. Chen等[16]提出DEA-Net,通过内容引导机制,将通道和空间权重进行交互,自适应地将输入特征中的低级和高级特征融合,提升去雾性能. Song等[17]以Transformer强大的自注意力机制为基础,设计Dehazeformer网络捕捉雾图的长距离依赖关系,建立不同尺度信息之间的映射关系. 在深度学习图像去雾算法中,多尺度特征提取和注意力机制的应用实现了有效的特征映射,但这些方法常面临细节信息丢失、特征冗余以及计算复杂度高的问题.
针对以上深度学习图像去雾问题,本研究提出代理注意力下域特征交互的高效图像去雾算法,具体贡献如下:1)构建代理注意力下的Swin Transformer编解码网络,在提取多尺度特征的同时,显著提高模型处理效率. 同时,编解码器通过级联高效多尺度注意力模块,增强空间和通道特征信息的流动,提升网络理解能力. 2)设计高频空间增强模块和低频通道增强模块,在提高频域特征利用率的同时,以低计算复杂度的特征提取操作充分提取频域特征,动态调整网络对频域特征的关注,实现有效的信息补偿. 3)在编码器中间层设计快速傅里叶卷积密集残差结构,利用空间和频谱信息去雾,提升恢复雾图观感. 同时,利用密集残差连接缓解深层网络梯度消失的问题.
1. 网络结构
所提去雾网络整体结构如图1所示,其由编码器、解码器、频域跳跃连接以及傅里叶卷积密集残差结构组成. 其中,编解码器以代理Swin Transformer级联高效多尺度注意力的编解码网络基本单元,充分提取并促进全局和局部特征的信息流动,在提高去雾性能的同时,加快网络处理速度. 频率跳跃连接以小波变换实现空间域和频域的转换,并设计高频空间增强模块和低频通道增强模块,分别在频域提取高频和低频特征,同时减少特征冗余,提升去雾效率. 中间层构造傅里叶卷积密集残差结构,通过谱变换操作,在全局感受野的视角下提取特征,进一步促进去雾图像更加自然. 提取到的频域特征与相应解码器输出在通道维度拼接并送入下一级解码器,逐层解码. 最后,将解码器输出与原始图像融合,生成无雾图像.
图 1
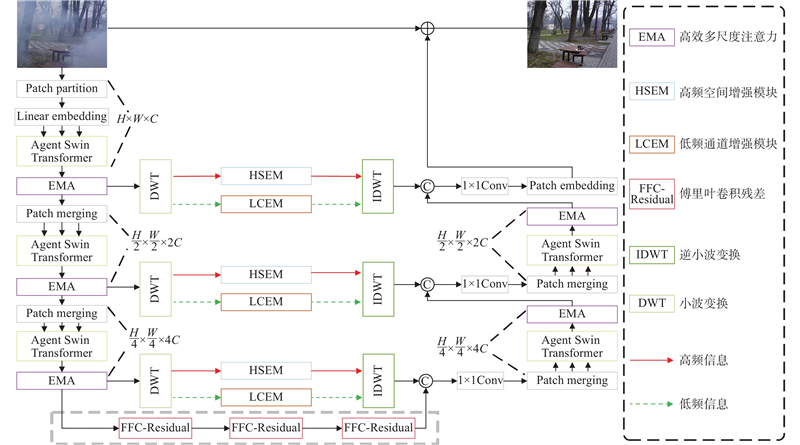
1.1. 编码器结构
1.1.1. 代理Swin Transformer (Agent Swin Transformer)
为了提取雾图深层次语义特征,以如图2(a)所示的Swin Transformer为基础,设计U-Net结构的多尺度特征提取网络. Swin Transformer基于如图2(c)所示的Softmax注意力建立当前块与其余块的依赖关系,为模型提供了强大的全局建模能力,但这也导致其计算复杂度随图像尺度的平方增长,且在特征提取过程中产生冗余,导致模型收敛慢,处理效率低. 为此,引入维度为n×d的代理矩阵
图 2
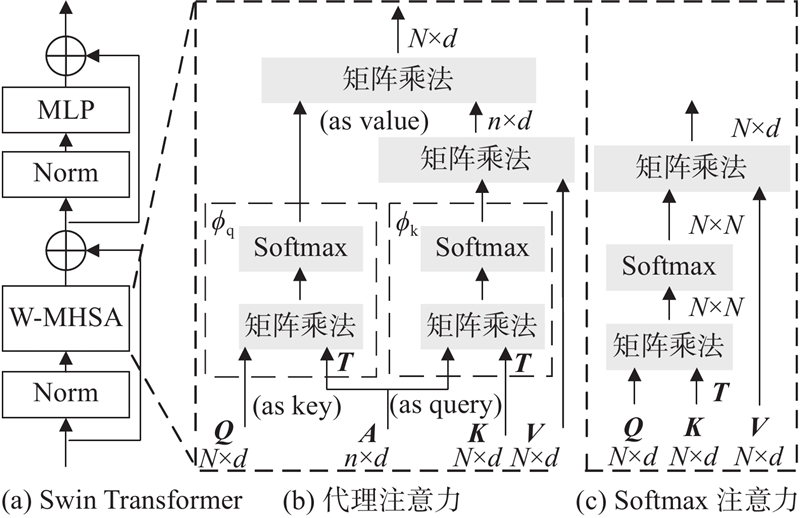
图 2 不同计算范式下的多头自注意力
Fig.2 Multi-head self-attention under different computational paradigms
式中:Atts表示softmax注意力.
通过以上操作,避开了
式中:
特征图输入编码器后,首先通过Patch Embedding将图像区块化,并转换为图块嵌入向量,随后传入代理Swin Transformer中进行特征提取,最后通过Patch merging操作,以块合并的方式降低分辨率,执行后续不同维度上的编码操作.
1.1.2. 高效多尺度注意力(efficient multi-scale atten-tion,EMA)
图 3
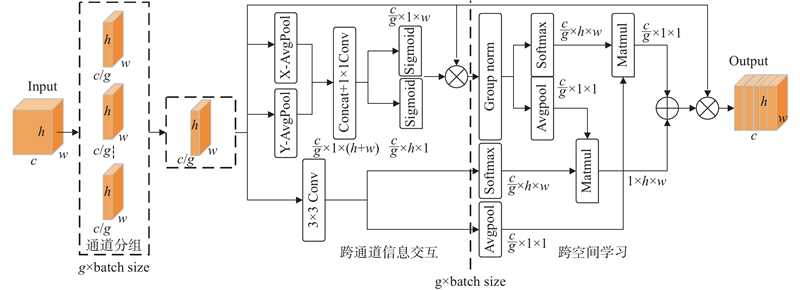
图 3 高效多尺度注意力(EMA)网络结构图
Fig.3 Network structure of efficient multi-scale attention(EMA)
通道分组将通道重塑到批次维度,避免特征提取产生过多的顺序操作和过大的网络深度,在保证信息有效性的同时降低计算成本,该过程表示为
式中:g为分组数,
跨通道信息交互由2个1×1分支捕获全局跨通道特征依赖关系和1个3×3分支捕获局部跨通道特征依赖关系实现. 2个1×1分支分别使用水平和竖直方向的1维全局池化进行通道编码,并在高度方向拼接,得到具有空间位置信息的跨通道依赖关系,之后通过一个1×1卷积提取2个方向的通道特征:
式中:
跨空间学习通过将1×1分支和3×3分支的输出池化,得到2个并行的全局特征,然后分别与另一个分支的输出相乘,实现全局和局部特征交互,该过程可以表示为
式中:
1.2. 频域跳跃连接
为了在图像去雾过程中保留更多的细节信息,通过小波变换,将每级编码器的输出转换到频域进行特征提取. 其中,高频信息对应图像的边缘和纹理细节,低频特征对应图像的亮度、颜色、饱和度等结构信息. 针对高低频特征的表征不同,设计空间增强模块和通道增强模块,在频域提取特征并增强. 增强后的特征通过小波逆变换恢复空间域特征图并送入解码器中,补偿丢失的特征.
1.2.1. 离散小波变换(discrete wavelet transform,DWT)
图 4

1.2.2. 高频空间增强模块(high-frequency spatial enhancement module,HSEM)
高频特征信息量少,若直接对3幅高频特征图进行连续卷积操作,会产生大量的空间特征冗余. 针对以上问题,构造如图5所示的高频空间增强模块. 该模块通过分离、融合、细化3个步骤,实现对细节信息的增强,同时减少特征提取过程中的空间冗余.
图 5
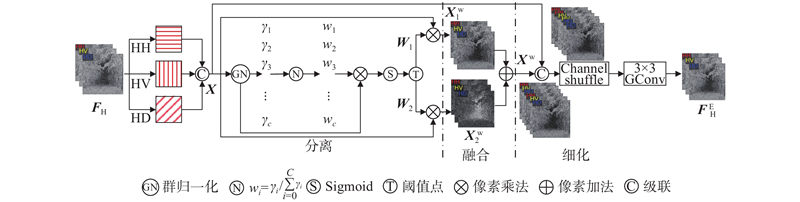
图 5 高频空间增强模块(HSEM)结构图
Fig.5 Structure of high-frequency spatial enhancement module(HSEM)
分离操作的目的是将信息丰富的特征和信息较少的特征分离出来. 具体来说,对于输入特征
式中:
将
最后,将输入特征
式中:CS为通道重排操作,
1.2.3. 低频通道增强模块(low-frequency channel enhancement module,LCEM)
针对低频特征结构信息丰富的特点,设计如图6所示的低频特征增强模块,在不增加额外计算开销的情况下,提高网络对雾气空间分布的理解.
图 6
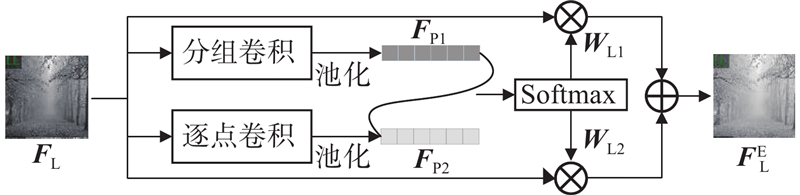
图 6 低频通道增强模块(LCEM)结构图
Fig.6 Structure of low-frequency channel enhancement module (LCEM)
LCEM使用分组卷积和逐点卷积取代k×k卷积,在提高信息表达能力的同时降低计算成本. 其中分组卷积减少了参数量和浮点运算量,但切断了通道间的信息流动. 而逐点卷积[24]弥补了信息损失,有助于通道间的信息流动. 因此,本研究对低频特征同时进行3×3分组卷积和1×1逐点卷积操作,然后通过全局平均池化得到全局信息更丰富的特征,该过程可以表述为
式中:
将上下全局分支叠加在一起,利用Softmax操作生成权重图
式中:
1.3. 快速傅里叶卷积密集残差连接
为了提高去雾图像的真实感和观感,在编解码器中间层构造如图7所示的快速傅里叶卷积残差块.
图 7
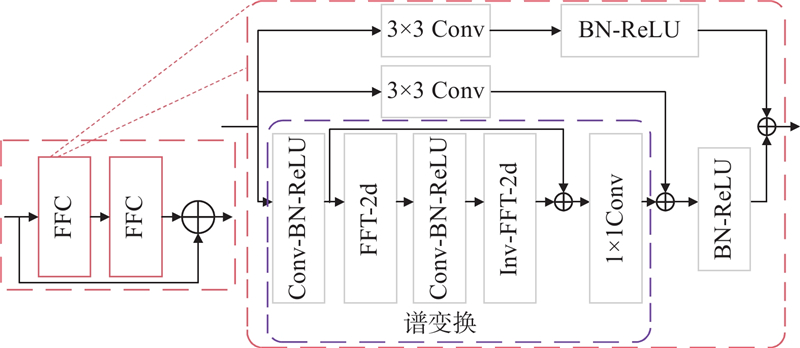
图 7 快速傅里叶卷积残差块(FFCR)结构图
Fig.7 Structure of fast Fourier convolution residual block (FFCR)
快速傅里叶卷积[25](fast Fourier convolution,FFC)基于通道级的快速傅里叶变换,具有输入特征图大小的全局感受野. 因此仅在网络最底层建立该结构,以最大限度地发挥其对全局雾气分布的建模能力,同时可以约束模型参数量和计算复杂度. FFC由全局和局部分支组成,局部分支通过3×3卷积提取局部特征,同时全局分支由卷积与谱变换进行全局特征提取. 由于深层网络中浅层特征容易丢失,通过将2个傅里叶卷积级联建立残差连接可以缓解梯度消失问题. 本研究共使用3个傅里叶密集残差结构,充分提取频域雾气分布特性. 其中,谱变换由以下3步实现:
1)
2)
3)
其中,步骤1)对输入特征使用二维快速傅里叶变换(FFT 2d),从而得到复数形式的频谱特征,然后将实部(幅度特征)和虚部(相位特征)分离并在通道维度拼接;步骤2)在频域进行ReLU激活、批归一化和卷积操作;步骤3)将实部和虚部结合恢复通道数,并通过二维傅里逆叶变换恢复空间域特征.
1.4. 解码器结构
解码器具有和编码器相同的结构,其接收傅里叶卷积密集残差连接和频域跳跃连接的输出特征,逐层解码并通过块嵌入操作恢复图像尺寸. 最后通过Patch Embedding操作进行反嵌入,将向量形式转换回图像补丁的形式,恢复图像的空间结构. 此外,输入雾图中包含雾的相关信息,将其与解码器特征逐像素相加,能进一步降低雾的影响,同时保留原始图像的整体结构和解码器输出的细节,更好地反映原始场景.
2. 实验结果与分析
2.1. 实验环境与数据集
本研究算法基于PyTorch 框架实现,并在 NVIDIA V100 GPU 的 Ubuntu 环境下进行训练. 初始学习率设为10−4,采用Adam优化器[26](
OTS数据集包含
2.2. 损失函数
为了使所设计网络达到更好的去雾效果,设置平滑L1损失、多尺度结构相似性损失、感知损失的组合损失函数.
平滑L1损失[32]通过比较清晰图像和生成图像第i通道中像素x的差值,直观体现两者的差异,且从两方面约束梯度,避免了零点不可导引起的不收敛问题,其定义如下:
式中:
多尺度结构相似性损失从亮度、对比度和结构三方面度量图像相似性,其通过S级结构相似性[33](structural similarity,SSIM)损失计算得到,SSIM的范围为0~1.0,表达式如下:
式中:
式中:M表示尺度总数;α和βm为默认参数,α表示亮度项的权重,βm表示m尺度下对比度的结构相似性项的权重,本研究均取默认值1;lα控制亮度对MS-SSIM整体的贡献;
感知损失[34]可以提升特征提取效果并保留原始色彩信息,引入VGG-16作为损失网络,其定义如下:
式中:
用于监督本研究方法训练的总损失为
式中:
2.3. 定性分析
如图8所示展示了本研究算法与对比算法在RESIDE数据集(SOTS)上的测试结果. 对于室外场景,GCA和EPDN的去雾图像出现了过饱和现象,特别是在天空、湖面和树林区域. UCL在第1个场景的天空出现了轻微偏色;SGID、DEA-Net和Dehazeformer在远景区域去雾不彻底,尤其是在景深突变区域,如第2个场景湖面与天空之间的过渡区. GridDehazeNet与本研究算法的整体去雾效果接近,但前者在第1个场景偏亮,导致树林颜色淡化. 对于室内场景,GCA-Net去雾不彻底,如第3个场景的墙面和第4个场景的桌面均有雾气残留;GridDehazeNet和Dehazeformer在第3个场景的墙面也存在去雾不彻底;EPDN则导致第4个场景墙面过亮. 其余3种算法的去雾效果较接近. 相比之下,本研究方法的细节保留更加完整.
图 8

图 8 不同算法在SOTS数据集上的复原结果
Fig.8 Recovery results of different algorithms on SOTS dataset
如图9所示展示了本研究算法与对比算法在NH-HAZE数据集上的测试结果. 可以看出,GCA-Net、EPDN在浓雾区域去雾能力不足,且GCA-Net产生明显偏色. SGID、DEA-Net、GridDehazeNet产生了伪影,且细节丢失较多,边缘纹理模糊. UCL特征映射不准确,导致第1个场景中椅子在去雾图像中消失,且树干产生了伪影. Dehazeformer的去雾效果和本研究方法接近,但相较之下本研究方法保留了更多的细节信息,如局部放大中椅子的轮廓更加清晰.
图 9

图 9 不同算法在NH-HAZE测试集上的复原结果
Fig.9 Recovery results of different algorithms on NH-HAZE test set
如图10所示展示了不同算法在O-HAZE数据集上的复原效果,不同于NH-HAZE数据集,O-HAZE中的浓雾分布更加均匀. 测试结果表明,GCA-Net、EPDN恢复图像存在明显的偏色问题,且整体图像较为暗淡;SGID、DEA-Net、GridDehazeNet在浓雾区域的特征提取能力不足,复原图像去雾不彻底,且DEA-Net伴有偏色现象,GridDehazeNet产生了大量伪影;UCL表现出模型泛化能力不足的问题,特征映射不准确导致恢复图像不自然,且细节丢失严重;Dehazeformer整体恢复图像自然,但在远景浓雾区域有雾气残留;本研究方法恢复图像自然逼真,去雾彻底.
图 10

图 10 不同算法在O-HAZE数据集上的复原结果
Fig.10 Recovery results of different algorithms on O-HAZE dataset
I-HAZE是室内浓雾数据集,通过该数据集评估本研究方法在雾气感知和细节保留方面的性能. 如图11所示,GCA-Net、EPDN恢复的图像产生明显偏色,且较为暗淡,细节信息丢失较多. SGID在处理室内图像时泛化能力不足,恢复图像中残留雾气明显. UCL、DEA-Net、Dehazeformer在局部细节保留方面同样存在不足,尤其在远景部分,模糊现象较为突出. GridDehazeNet在墙面产生明显伪影,相较之下,本研究方法细节保留充分,边缘纹理清晰,雾气去除彻底.
图 11

图 11 不同算法在I-HAZE数据集上的复原结果
Fig.11 Recovery results of different algorithms on I-HAZE dataset
除了在成对数据集上测试以外,本研究在真实图像上进行了去雾性能测试,如图12所示为不同算法对真实图像的去雾对比. GCA-Net存在过饱和与光晕伪影现象;SGID去雾不彻底且在天空区域恢复不自然. UCL对远景去雾不彻底且存在一定的过曝现象;DEA-Net、Dehazeformer存在一定的过饱和;GridDehazeNet细节丢失严重. 相比之下本研究方法在图像恢复上自然逼真,边缘纹理清晰. 综上,本研究方法具有更好的去雾性能,细节保留充分,且具有较好的泛化能力.
图 12

图 12 不同算法在真实集上的复原结果
Fig.12 Recovery results of different algorithms on real set
2.4. 定量分析
采用峰值信噪比(peak signal-to-noise ratio, PSNR)和结构相似性(SSIM)作为评价指标,分别在SOTS-indoor、SOTS-outdoor、NH-HAZE测试集、O-HAZE数据集、I-HAZE数据集上进行客观比对,结果如表1所示. 其中,数据为相应数据集测试均值,粗体表示最优值,下划线表示次优值.
表 1 不同算法在不同测试集上的评价指标
Tab.1
| 算法 | SOTS-indoor | SOTS-outdoor | NH-HAZE | O-HAZE | I-HAZE | |||||||||
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |||||
| GCA-Net | 25.34 | 26.19 | 23.03 | 18.83 | 14.93 | |||||||||
| SGID | 22.63 | 24.97 | 22.81 | 17.25 | 16.51 | |||||||||
| UCL | 23.76 | 24.35 | 21.98 | 18.86 | 16.79 | |||||||||
| DEA-Net | 27.27 | 28.11 | 24.45 | 19.73 | 18.31 | |||||||||
| GridDehazeNet | 24.72 | 25.35 | 20.12 | 19.92 | 17.63 | |||||||||
| EPDN | 23.06 | 25.57 | 21.42 | 17.63 | 16.05 | |||||||||
| Dehazeformer | 25.54 | 26.93 | 24.96 | 20.13 | 18.46 | |||||||||
| 本研究算法 | 26.71 | 28.59 | 26.89 | 21.75 | 19.72 | |||||||||
在所有数据集和对比算法中,所提方法的PSNR仅在SOTS-indoor数据集上低于DEA-Net,这是由于室内场景较为单一,频域特征学习不充分;在NH-HAZE测试集上,PSNR和SSIM较同样使用了Swin Transformer结构的Dehazeformer分别提升了1.93 dB和
参数量NP和浮点运算量FLOPs的定量对比如表2所示,测试图像维度为3×512×512,运行时间t测试结果为50副图像的均值. SGID、UCL、EPDN为生成对抗网络. SGID基于景深估计,计算复杂度最高;UCL采用对比学习和9个残差块,浮点运算量较大;EPDN通过金字塔下采样,浮点运算量最低;GCA网络较浅且使用门控融合机制,参数量和浮点运算量较低;DEA-Net因细节增强卷积导致参数量和浮点运算量较大;GridDehazeNet由网格网络的多尺度全连接网络构成,浮点运算量较高;在与Dehazeformer保持相同模型深度的前提下,本研究方法通过引入代理注意力机制并通过对各模块进行轻量化设计,显著提升了处理效率. 综上,本研究算法在提升去雾性能和效率的同时,能将参数量和计算复杂度保持在合理的范围.
表 2 参数量和复杂性对比
Tab.2
| 算法 | NP/106 | FLOPs/109 | t/s |
| GCA-Net | 2.68 | 62.96 | 0.163 |
| SGID | 13.87 | 625.61 | 0.416 |
| UCL | 19.45 | 183.34 | 0.204 |
| DEA-Net | 3.65 | 128.92 | 0.179 |
| GridDehazeNet | 0.96 | 85.71 | 0.211 |
| EPDN | 17.38 | 19.20 | 0.185 |
| Dehazeformer | 2.51 | 93.99 | 0.244 |
| 本研究算法 | 2.74 | 97.64 | 0.158 |
2.5. 消融实验
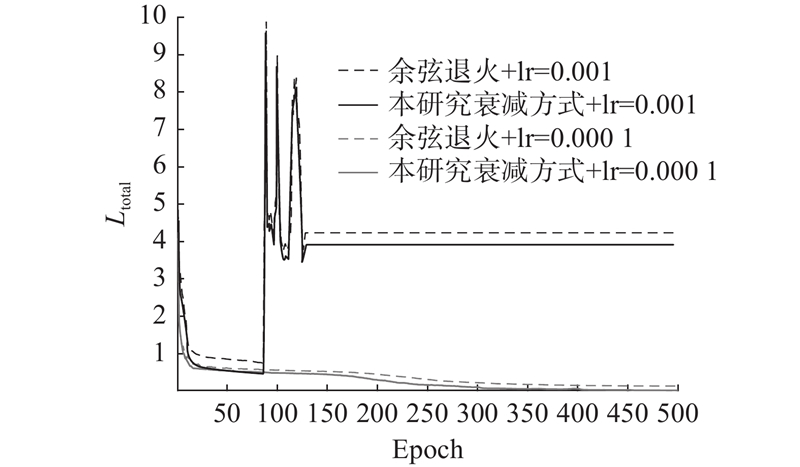
为了验证模型在NH-HAZE数据集上训练策略的有效性,对不同训练模式下的训练损失收敛效果进行测试. 如图13所示为不同设置下的训练损失变化情况. 其中,Epoch为训练轮数,可以看出,当初始学习率设置为10−3时,无论使用余弦退火策略自动调整学习率,还是使用本研究设置的300、400、450轮时衰减一半策略,模型均因梯度下降的步长太大而产生了震荡,最终导致模型不收敛. 当初始学习率设置为10−4时,在2种学习率衰减策略下,模型均逐步平稳地收敛. 相较于余弦退火策略,在本研究学习率调整策略下,模型收敛更快,且最终收敛到
图 13
为了验证代理注意力(Agent Attention)、EMA、HSEM、LCEM以及快速傅里叶卷积密集残差(FFCR)对网络的贡献,以Swin Transformer作为Baseline,依次添加模块,进行去雾性能消融实验. 所有的模型训练模式与数据和本研究方法保持一致,在NH-HAZE数据集上设置如表3所示7种消融模型. 由表3可以看出,相较于Baseline,model B加入代理注意力,获得了0.72 dB的PSNR增益和
表 3 去雾性能消融对比
Tab.3
| Model | Agent attention | EMA | HSEM | LCEM | FFCR | PSNR/dB | SSIM |
| A | — | — | — | — | — | 23.84 | |
| B | √ | — | — | — | — | 24.56 | |
| C | √ | √ | — | — | — | 24.93 | |
| D | √ | — | √ | √ | — | 26.14 | |
| E | √ | √ | — | — | √ | 25.16 | |
| F | √ | √ | √ | √ | — | 26.41 | |
| G (本研究模型) | √ | √ | √ | √ | √ | 26.89 |
为了直观说明各模块有效性,对7种模型在NH-HAZE的测试集上进行对比,结果如图14所示. 可以看出,Model B使用代理注意力,去雾更彻底,但细节信息仍然丢失严重;Model C中EMA模块的加入提高了模型对雾气的空间分布的感知,模型去雾性能和细节提取能力均有所提升. Model D中加入频域分支后,模型细节保留能力显著提升,且残雾进一步减少. Model E中在EMA模块和FFCR的作用下,恢复图像的视觉观感有所提升,且具有较好的细节保留能力. Model F中去雾彻底且图像细节纹理边缘清晰. Model G(本研究方法)的去雾性能、细节保留和图像观感在消融模型中达到最佳.
图 14

为了验证代理注意力、HSEM、LCEM对模型处理效率的贡献,设计以下5种消融模型. Model 1:使用原有的多头自注意力,并使用空间注意力(spatial attention,SA)和通道注意力(channel attention,CA)分别对高低频特征加权;Model 2:将Model 1中的多头自注意力替换为代理注意力;Model 3:将Model 2中的SA替换为HSEM;Model 4:将Model 3中的CA替换为LCEM同时将代理注意力替换为可以降低模型计算复杂度的稀疏自注意力;Model 5(本研究方法):将Model 4中的稀疏自注意力替换为代理注意力. 去雾效率消融对比结果如表4所示. 可以看出,Model 2中代理注意力替换多头自注意力没有明显减少模型的参数量和浮点运算量,但由于注意力计算的方式被分为了2步,模型推理速度得到了显著提升. Model 3中使用本研究提出的HSEM替换SA,减少了频域特征的空间冗余,模型的参数量和浮点运算量显著降低,且图像处理速度进一步提升. Model 4稀疏自注意力同样提高了模型运行效率,但相较之下,本研究方法的模型参数量、浮点运算量以及处理速度更具优势.
表 4 去雾效率消融对比
Tab.4
| Model | NP/106 | FLOPs/109 | t/s |
| 1 | 3.23 | 138.34 | 0.287 |
| 2 | 3.21 | 135.31 | 0.184 |
| 3 | 2.84 | 110.76 | 0.177 |
| 4 | 2.76 | 102.43 | 0.163 |
| 5(本研究算法) | 2.74 | 97.64 | 0.158 |
3. 结 语
提出基于代理注意力与频域特征交互的高效图像去雾算法. 构建基于代理Swin Transformer与高效多尺度注意力模块的编解码网络架构,显著提升了模型推理速度,并增强了全局与局部的特征交互能力. 同时,设计频域跳跃连接与傅里叶卷积密集残差结构,利用频域信息补偿空间特征,在降低计算复杂度和特征冗余的同时,提升复原图像的整体视觉观感与细节保留能力. 实验结果表明,本研究算法在降低特征冗余和提升推理效率的同时具有良好的细节保留和去雾性能. 然而,对于浓雾中隐藏的极弱纹理信号,模型的恢复能力仍有待加强,这将作为未来研究的重点.
参考文献
基于深度学习的单幅图像去雾研究进展
[J].
Research advances on deep learning based single image dehazing
[J].
Adaptive histogram equalization and its variations
[J].DOI:10.1016/S0734-189X(87)80186-X [本文引用: 1]
Decomposition of hardy functions into square integrable wavelets of constant shape
[J].
Lightness and retinex theory
[J].DOI:10.1364/JOSA.61.000001 [本文引用: 1]
Fast image dehazing method based on linear transformation
[J].DOI:10.1109/TMM.2017.2652069 [本文引用: 1]
Self-guided image dehazing using progressive feature fusion
[J].DOI:10.1109/TIP.2022.3140609 [本文引用: 2]
UCL-dehaze: toward real-world image dehazing via unsupervised contrastive learning
[J].DOI:10.1109/TIP.2024.3362153 [本文引用: 2]
DEA-net: single image dehazing based on detail-enhanced convolution and content-guided attention
[J].DOI:10.1109/TIP.2024.3354108 [本文引用: 2]
Vision transformers for single image dehazing
[J].DOI:10.1109/TIP.2023.3256763 [本文引用: 2]
Fast Fourier convolution
[J].
Image quality assessment: from error visibility to structural similarity
[J].DOI:10.1109/TIP.2003.819861 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}