[1]
BYAMBADORJ Z, NISHIMURA R, AYUSH A, et al. Multi-speaker TTS system for low-resource language using cross-lingual transfer learning and data augmentation [C]// Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference . Tokyo: IEEE, 2021: 849–853.
[本文引用: 1]
[2]
GOKAY R, YALCIN H. Improving low resource Turkish speech recognition with data augmentation and TTS [C]// Proceedings of the 16th International Multi-Conference on Systems, Signals and Devices . Istanbul: IEEE, 2019: 357–360.
[本文引用: 1]
[3]
SHEN J, PANG R, WEISS R J, et al. Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions [C]// Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing . Calgary: IEEE, 2018: 4779–4783.
[本文引用: 2]
[4]
REN Y, HU C X, TAN X, et al. FastSpeech 2: fast and high-quality end-to-end text to speech [EB/OL]. (2022−08−08)[2024−08−25]. https://arxiv.org/pdf/2006.04558.
[本文引用: 3]
[5]
KIM J, KIM S, KONG J, et al. Glow-TTS: a generative flow for text-to-speech via monotonic alignment search [C]// 34th Conference on Neural Information Processing Systems . Vancouver: [s.n.], 2020: 1−11.
[本文引用: 2]
[6]
KIM J, KONG J, SON J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech [EB/OL]. (2021−06−11)[2024−08−25]. https://arxiv.org/pdf/2106.06103.
[本文引用: 1]
[7]
KATUMBA A, KAGUMIRE S, NAKATUMBA-NABENDE J, et al Building text-to-speech models for low-resourced languages from crowdsourced data
[J]. Applied AI Letters , 2025 , 6 (2 ): e117
DOI:10.1002/ail2.117
[本文引用: 1]
[8]
KONG J, KIM J, BAE J. HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis [C]// 34th Conference on Neural Information Processing Systems . Vancouver: [s.n.], 2020: 1−12.
[本文引用: 2]
[9]
MORRISON M, KUMAR R, KUMAR K, et al. Chunked autoregressive GAN for conditional waveform synthesis [EB/OL]. (2022−03−03)[2024−08−25]. https://arxiv.org/pdf/2110.10139.
[本文引用: 3]
[10]
KARRAS T, AITTALA M, LAINE S, et al. Alias-free generative adversarial networks [EB/OL]. [2021−10−18][2024−08−25]. https://arxiv.org/pdf/2106.12423.
[本文引用: 3]
[11]
TAN X, QIN T, SOONG F, et al. A survey on neural speech synthesis [EB/OL]. (2021−07−23)[2024−08−25]. https://arxiv.org/pdf/2106.15561.
[本文引用: 3]
[12]
LEE J, JUNG W, CHO H, et al. PITS: variational pitch inference without fundamental frequency for end-to-end pitch-controllable TTS [EB/OL]. (2023−06−06)[2024−11−20]. https://arxiv.org/pdf/2302.12391.
[本文引用: 2]
[13]
WOO S, DEBNATH S, HU R, et al. ConvNeXt V2: co-designing and scaling ConvNets with masked autoencoders [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 16133–16142.
[本文引用: 1]
[14]
VAN DEN OORD A, DIELEMAN S, ZEN H, et al. WaveNet: a generative model for raw audio [EB/OL]. (2016−09−19)[2024−08−25]. https://arxiv.org/pdf/1609.03499.
[本文引用: 1]
[15]
KANEKO T, TANAKA K, KAMEOKA H, et al. iSTFTNet: fast and lightweight mel-spectrogram vocoder incorporating inverse short-time Fourier transform [C]// Proceedings of the ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing . Singapore: IEEE, 2022: 6207–6211.
[本文引用: 1]
[16]
SIUZDAK H. Vocos: closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis [EB/OL]. (2024−05−29)[2024−08−25]. https://arxiv.org/pdf/2306.00814v3.
[本文引用: 3]
[17]
DONAHUE J, DIELEMAN S, BIŃKOWSKI M, et al. End-to-end adversarial text-to-speech [EB/OL]. (2021−03−17)[2024−08−25]. https://arxiv.org/pdf/2006.03575.
[本文引用: 1]
[18]
NGUYEN T T T, TRAN D D, RILLIARD A, et al. Intonation issues in HMM-based speech synthesis for Vietnamese [C]// Spoken Language Technologies for Under-Resourced Languages . Petersburg: [s.n.], 2014: 98−104.
[本文引用: 1]
[19]
NGUYEN T V, NGUYEN B Q, PHAN K H, et al Development of Vietnamese speech synthesis system using deep neural networks
[J]. Journal of Computer Science and Cybernetics , 2019 , 34 (4 ): 349 - 363
DOI:10.15625/1813-9663/34/4/13172
[本文引用: 1]
[20]
TRANG N T T, KY N H, RILLIARD A, et al. Prosodic boundary prediction model for Vietnamese text-to-speech [C]// Proceedings of the Interspeech 2021 . [S.l.]: ISCA, 2021: 3885−3889.
[本文引用: 1]
[21]
PHUONG P N, QUANG C T, DO Q T, et al. A study on neural-network-based text-to-speech adaptation techniques for Vietnamese [C]// Proceedings of the 24th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA2021) . Singapore: IEEE, 2021: 199−205.
[本文引用: 1]
[22]
WIN Y, LWIN H P, MASADA T. Myanmar text-to-speech system based on Tacotron (end-to-end generative model) [C]// Proceedings of the International Conference on Information and Communication Technology Convergence . Jeju: IEEE, 2020: 572−577.
[本文引用: 1]
[23]
HLAING A, PA W Word representations for neural network based Myanmar text-to-speech system
[J]. International Journal of Intelligent Engineering and Systems , 2020 , 13 (2 ): 239 - 249
DOI:10.22266/ijies2020.0430.23
[本文引用: 1]
[24]
HLAING A M, PA W P, THU Y K. Enhancing Myanmar speech synthesis with linguistic information and LSTM-RNN [C]// Proceedings of the 10th ISCA Workshop on Speech Synthesis . [S.l.]: ISCA, 2019: 189−193.
[本文引用: 1]
[25]
JANYOI P, THANGTHAI A. Investigation of an input sequence on Thai neural sequence-to-sequence speech synthesis [C]// Proceedings of the 24th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA2021) . Singapore: IEEE, 2021: 218−223.
[本文引用: 1]
[26]
CHOMPHAN S, KOBAYASHI T. Implementation and evaluation of an HMM-based Thai speech synthesis system [C]// Proceedings of the Interspeech 2007 . [S.l.]: ISCA, 2007: 2849−2852.
[本文引用: 1]
[27]
TESPRASIT V, CHAROENPORNSAWAT P, SORNLERTLAMVANICH V. A context-sensitive homograph disambiguation in Thai text-to-speech synthesis [C]// Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics . Edmonton: ACL, 2003: 103−105.
[本文引用: 1]
[28]
DHIAULHAQ M A, GINANJAR R R, LOVENIA H, et al. Indonesia expressive text to speech system based on global style token and Tacotron 2 [C]// Proceedings of the 8th International Conference on Advanced Informatics: Concepts, Theory and Applications . Bandung: IEEE, 2021: 1–6.
[本文引用: 1]
[29]
LANCUCKI A. FastPitch: parallel text-to-speech with pitch prediction [C]// Proceedings of the ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing . Toronto: IEEE, 2021: 6588−6592.
[本文引用: 2]
[30]
SKERRY-RYAN R J, BATTENBERG E, XIAO Y, et al. Towards end-to-end prosody transfer for expressive speech synthesis with Tacotron [EB/OL]. (2018−03−24)[2024−08−25]. https://arxiv.org/pdf/1803.09047.
[本文引用: 2]
[33]
LUKSANEEYANAWIN S. Intonation in Thai [M]// HIRST D, DI CRISTO A. Intonation systems: a survey of twenty languages . Cambridge: Cambridge University Press, 1998: 379−397.
[本文引用: 1]
[34]
GREEN A D. Word, foot, and syllable structure in Burmese [C]// Studies in Burmese linguistics . Canberra: Pacific Linguistics, 2005: 1–24.
[本文引用: 1]
[35]
BRUNELLE M, KIRBY J Tone and phonation in Southeast Asian languages
[J]. Language and Linguistics Compass , 2016 , 10 (4 ): 191 - 207
DOI:10.1111/lnc3.12182
[本文引用: 1]
[36]
MORISE M, KAWAHARA H, KATAYOSE H. Fast and reliable F0 estimation method based on the period extraction of vocal fold vibration of singing voice and speech [C]// 35th Audio Engineering Society International Conference 2009: Audio for Games . London: Curran Associates, Inc. , 2009: 77−81.
[本文引用: 1]
[37]
KUBICHEK R. Mel-cepstral distance measure for objective speech quality assessment [C]// Proceedings of the Proceedings of IEEE Pacific Rim Conference on Communications Computers and Signal Processing . Victoria: IEEE, 1993: 125–128.
[本文引用: 1]
[38]
RIX A W, BEERENDS J G, HOLLIER M P, et al. Perceptual evaluation of speech quality (PESQ): a new method for speech quality assessment of telephone networks and codecs [C]// Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings . Salt Lake City: IEEE, 2002: 749–752.
[本文引用: 1]
1
... 随着深度学习技术的不断进步和语音合成研究的深入,通用且资源丰富的语言如汉语和英语的合成语音质量正在逐步接近自然语音的水平. 对于缅甸语、越南语和泰语等非通用且资源较少的语言,由于语音数据有限和研究投入不足,合成语音与自然语音的差距明显[1 -2 ] ,提升低资源环境下的合成语音自然度具有挑战性. ...
1
... 随着深度学习技术的不断进步和语音合成研究的深入,通用且资源丰富的语言如汉语和英语的合成语音质量正在逐步接近自然语音的水平. 对于缅甸语、越南语和泰语等非通用且资源较少的语言,由于语音数据有限和研究投入不足,合成语音与自然语音的差距明显[1 -2 ] ,提升低资源环境下的合成语音自然度具有挑战性. ...
2
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
3
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
... 完全端到端模型直接从字符或音素序列生成语音波形,相比两阶段模型在减少错误传播方面具有明显优势[11 ] . 这类模型有FastSpeech 2s[4 ] 、基于注意力机制的序列到序列模型EATS[17 ] ,基于变分自编码器的TTS模型VITS. 其中VITS结合变分推理、标准化流和对抗训练的方法,使用隐变量而非频谱串联语音合成中的声学模型和声码器,在通用语上展现出超越两阶段系统的性能. ...
2
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
1
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
Building text-to-speech models for low-resourced languages from crowdsourced data
1
2025
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
2
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
3
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
... 通用、高资源语言的合成语音已经越来越接近自然语音,而低资源条件下的语音合成系统仍然存在影响合成语音质量的共性问题:1)HiFi-GAN V1解码器结构为了补偿输入声学特征和输出波形之间时间分辨率的差异,使用多个转置卷积将输入特征上采样到所需的采样率,引入混叠伪影[9 -10 ] . 2) 不同语言的声调范围不同,在低资源条件下的可用训练数据较少,基线系统无法准确预测音高信息,导致合成语音语气平淡,缺乏足够的韵律信息[29 -30 ] ,这种情况在缅甸语、越南语和泰语等语言的合成语音中尤为明显. ...
3
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
... 通用、高资源语言的合成语音已经越来越接近自然语音,而低资源条件下的语音合成系统仍然存在影响合成语音质量的共性问题:1)HiFi-GAN V1解码器结构为了补偿输入声学特征和输出波形之间时间分辨率的差异,使用多个转置卷积将输入特征上采样到所需的采样率,引入混叠伪影[9 -10 ] . 2) 不同语言的声调范围不同,在低资源条件下的可用训练数据较少,基线系统无法准确预测音高信息,导致合成语音语气平淡,缺乏足够的韵律信息[29 -30 ] ,这种情况在缅甸语、越南语和泰语等语言的合成语音中尤为明显. ...
3
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
... 相比传统方法,基于神经网络的语音合成技术显著提高了合成语音的质量,成为研究的主流趋势[11 ] . 基于神经网络的语音合成模型可以分为两阶段模型和完全端到端模型. ...
... 完全端到端模型直接从字符或音素序列生成语音波形,相比两阶段模型在减少错误传播方面具有明显优势[11 ] . 这类模型有FastSpeech 2s[4 ] 、基于注意力机制的序列到序列模型EATS[17 ] ,基于变分自编码器的TTS模型VITS. 其中VITS结合变分推理、标准化流和对抗训练的方法,使用隐变量而非频谱串联语音合成中的声学模型和声码器,在通用语上展现出超越两阶段系统的性能. ...
2
... 基于神经网络的语音合成模型已成为研究主流,这些模型有Tacotron 2[3 ] 、FastSpeech 2[4 ] 、Glow-TTS[5 ] 和VITS[6 ] 等. 其中Tacotron 2、FastSpeech 2和Glow-TTS属于两阶段模型,这类模型须结合声码器实现从文本到时域语音的生成. 声码器大都由英语或汉语训练而成,这样的声码器用于低资源条件下目标语言的语音合成会缺少目标语言的声学特征,产生声学特征失配问题[7 ] . VITS采用变分自动编码器结合标准化流的方法,其完全端到端的设计在通用语语音合成的性能上超越了传统的两阶段模型. 直接把VITS应用在低资源语音合成上并不可取. 一方面,以VITS中的解码器为代表的HiFi-GAN[8 ] 生成器结构将转置卷积作为上采样,这样的操作可能引入混叠干扰[9 -10 ] . 在低资源条件下,合成语音的摩擦音(如/s/、/ʃ/、/f/等)和爆破音(如/p/、/t/、/k/等)会因混叠干扰而变得模糊且易混淆[11 ] ,使得合成语音的可理解性降低并影响合成语音质量. 另一方面,现有模型训练时将音调信息(如基频等)与文本信息耦合,由于缺乏对音调信息的显式建模,低资源环境下的模型难以有效模拟目标语音的声调和语气,导致生成的语音语气平淡[12 ] ,限制了合成语音的自然度和表现力. ...
... 受限于Tacotron系列模型的自回归特性,采用该系列模型的语音合成系统语音合成速度较慢,而且语言特征捕捉存在局限. 当前基于端到端模型的低资源语音合成研究相对较少,主要原因是端到端语音合成模型虽然能生成自然度较高的语音,但其内部处理过程中韵律信息和文本信息交织而非显式解耦[12 ] . 这种混合处理方式限制了模型对文本中韵律特征的深入解析和有效捕捉,可能影响合成语音的韵律准确性,降低语音的自然性和可理解性. 尤其是在训练数据有限的情况下,这种现象更为明显[28 ] . ...
1
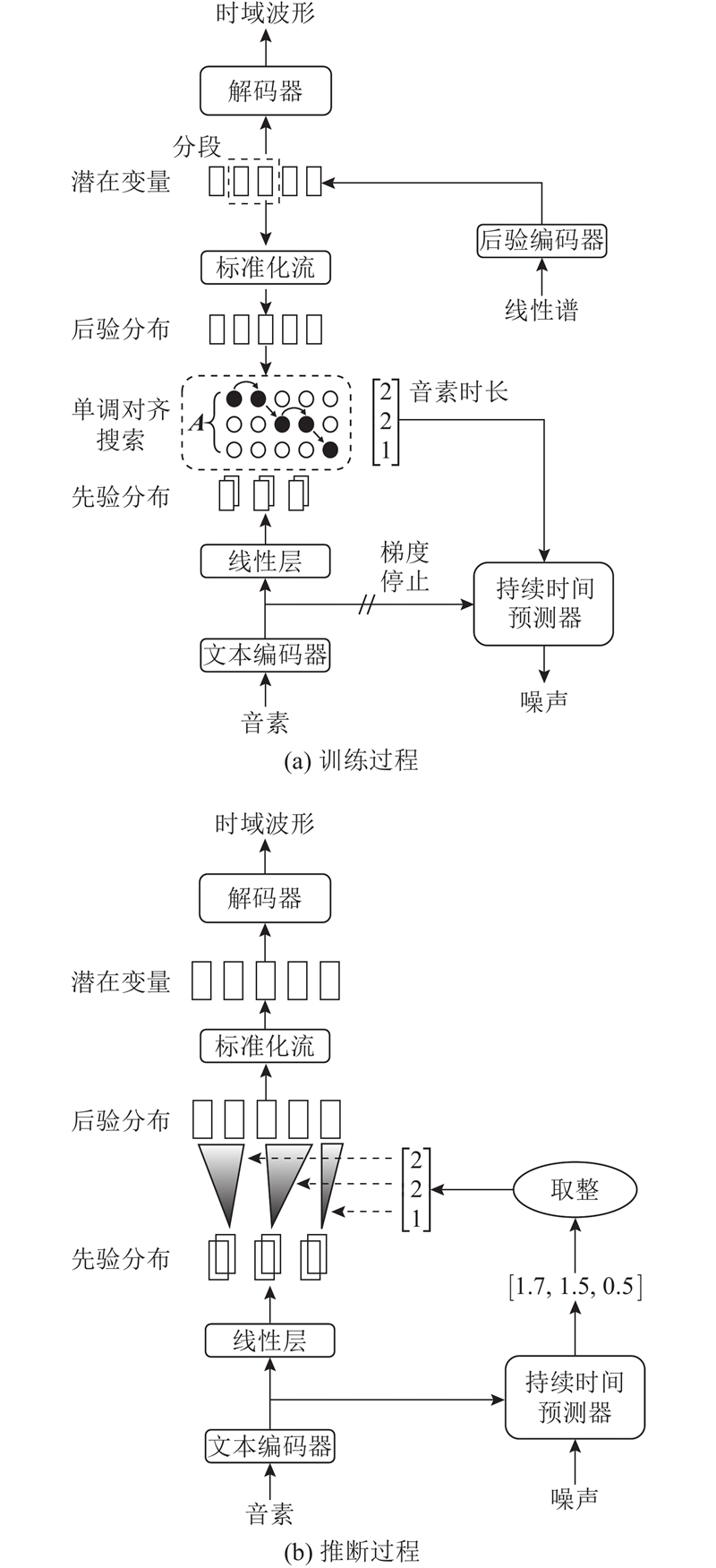
... 本研究以VITS为基线模型,分析该模型在低资源语言文本到语音转换(text-to-speech, TTS)任务中的局限性,并提出改进模型. 1)将原有的上采样卷积模块替换为包含跳连接的卷积结构模块—ConvNeXt V2[13 ] 以削弱混叠效应,应用逆短时傅里叶变换(inverse short-time Fourier transform,iSTFT)构建新的解码器结构以提高合成语音的自然度和流畅性. 2)为了更好地捕捉和模拟不同语言的声调和语气,将帧级别的基频预测器引入所提改进模型. 3)使用缅甸语、越南语和泰语数据集进行改进模型的训练与评估,通过与现有语音合成模型的性能对比,验证改进模型在低资源条件下提升合成语音的自然度和质量的优势. ...
1
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
1
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
3
... 两阶段模型由声学模型和声码器构成,2个阶段的模型均独立研发. 完全端到端模型减少了对人工设计的声学特征和参数的依赖,由输入文本或音素序列直接合成时域波形.在声学模型方面,Shen等[3 ] 改进Tacotron,提出的Tacotron 2通过使用梅尔谱来控制WaveNet[14 ] 生成器,并使用多尺度波形一致性损失提高语音的自然度和清晰度. 以Tacotron 2为代表的自回归模型在推理阶段的速度较慢,模型的鲁棒性表现不佳. 考虑到自回归模型存在的问题,Ren等[4 ] 提出非自回归模型FastSpeech 2,引入音高、能量和更有效的时长建模,使训练速度和语音质量得到提升. Kim等[5 ] 提出Glow-TTS,基于流的方法直接从文本数据学习语音波形的映射,并通过一系列可逆的变换步骤连续生成自然的语音波形,提升了合成语音的连贯性和自然感. 在声码器方面,基于深度学习的神经网络声码器逐渐成为研究主流,其中Kong等[8 ] 提出的HiFi-GAN在保持合成语音高保真度的同时实现了高效率的音频生成. 为了补偿输入声学特征和输出波形之间时间分辨率的差异,声码器通常需要多个转置卷积将输入特征上采样到所需的采样率,从而产生大量的计算成本,可能产生的高频混叠效应将导致音频波形出现不自然的周期性振荡[9 -10 ] . Kaneko等[15 ] 提出的iSTFTNet结合了神经网络和传统的信号处理技术,能够通过iSTFT直接从梅尔谱生成语音波形,在保持语音质量的同时降低了模型的复杂性和计算成本,提升了模型效率. Vocos[16 ] 在iSTFTNet的基础上去除了转置卷积,有效缓解了生成音频中的周期伪影现象. ...
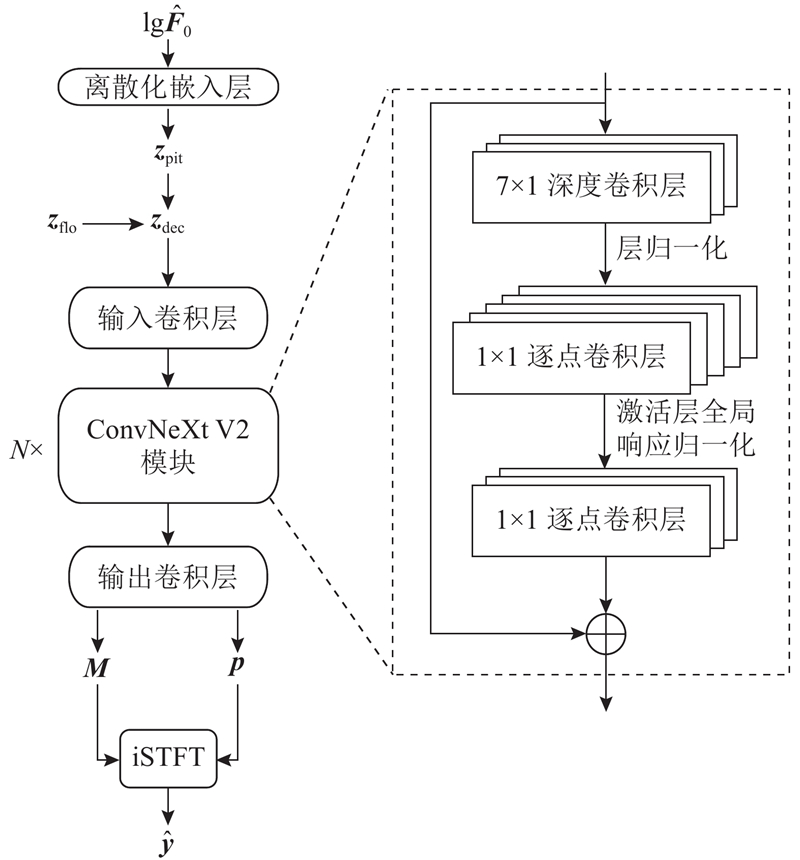
... 在VITS框架中,HiFi-GAN V1的生成器结构被用作解码器. 以HiFi-GAN为代表的生成对抗网络(generative adversarial network,GAN)类型的声码器结构在生成音频信号的频谱表示方面的表现欠佳. 一方面,STFT的幅度谱能清晰呈现信号在不同频率分量上的幅度变化. 尽管理论上可通过 STFT的幅度谱重建原始信号,但在实际应用中,仅依靠幅度信息仍会造成信号损失,且相位在时频域中的分布具有复杂性,因此建模相位分布是具有挑战性的任务. 另一方面,HiFi-GAN的生成器使用转置卷积层进行上采样,将低分辨率的音频特征映射到高分辨率的时域信号可能会引入混叠效应,导致音频波形出现不自然的周期性振荡[16 ] . ...
... 参考iSTFTNet的声码器结构,本研究设计基于iSTFT的解码器结构以根据中间变量对语音的幅度特征和相位特征进行估计,进而使用iSTFT恢复语音波形. 如图3 所示,考虑到音高信息本身具有的上下文关系以及模型对于音高信息的捕捉能力,将基频预测模块得到的对数基频$ \mathrm{lg}{\widehat{\boldsymbol{F}}}_{0} $ $ {\boldsymbol{z}}_{\mathrm{p}\mathrm{i}\mathrm{t}} $ $ {\boldsymbol{z}}_{\mathrm{f}\mathrm{l}\mathrm{o}} $ $ {\boldsymbol{z}}_{\mathrm{d}\mathrm{e}\mathrm{c}} $ . 整个解码器以ConvNeXt V2框架为基础骨干,由以下3个部分构成. 1)堆叠$ N $ [16 ] . 2)将生成器的输出映射到傅里叶谱系数:投影隐藏维度的激活值至具有$ 2+{\boldsymbol{n}}_{\mathrm{f}\mathrm{f}\mathrm{t}} $ $ \boldsymbol{M} $ $ \boldsymbol{p} $ $ {\boldsymbol{Z}}_{\mathrm{f}\mathrm{t}} $ . 3)进行iSTFT计算,得到时域波形$ \widehat{\boldsymbol{y}} $
1
... 完全端到端模型直接从字符或音素序列生成语音波形,相比两阶段模型在减少错误传播方面具有明显优势[11 ] . 这类模型有FastSpeech 2s[4 ] 、基于注意力机制的序列到序列模型EATS[17 ] ,基于变分自编码器的TTS模型VITS. 其中VITS结合变分推理、标准化流和对抗训练的方法,使用隐变量而非频谱串联语音合成中的声学模型和声码器,在通用语上展现出超越两阶段系统的性能. ...
1
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
Development of Vietnamese speech synthesis system using deep neural networks
1
2019
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
1
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
1
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
1
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
Word representations for neural network based Myanmar text-to-speech system
1
2020
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
1
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
1
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
1
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
1
... 针对缅甸语、越南语和泰语等东南亚低资源语言的深度神经网络的语音合成研究相对较少. 在越南语的语音合成研究中,Nguyen等[18 ] 在基于隐马尔可夫模型(hidden Markov model,HMM)的越南语TTS系统中探讨上下文特征对合成语音的影响,提出韵律特征以提高系统的自然性. Nguyen等[19 ] 开发出基于深度神经网络的越南语音合成系统,通过数据清理和更深架构的使用,实现比传统HMM更优的TTS性能. Trang 等[20 ] 进一步研究韵律边界预测模型,通过引入句法块和句法链接特征,显著提高了越南语TTS的自然性. Phuong等[21 ] 开展TTS自适应技术研究,利用少量越南语数据适应英语预训练模型,以合成高质量的语音. 在缅甸语方面,Win等[22 ] 通过采用Tacotron提升了缅甸语TTS系统的自然度. Hlaing等[23 ] 探索词向量在缅甸语TTS系统中的应用,研究词向量作为附加输入特征在DNN、LSTM-RNN以及混合模型中的效果,发现额外的输入特征能够提升合成语音的自然性. Hlaing等[24 ] 研究LSTM-RNN在缅甸语TTS中的应用,验证了上下文语言特征的重要性. 在泰语TTS领域,Janyoi等[25 ] 深入研究神经序列到序列语音合成,得出分词是神经序列到序列泰语TTS中文本处理任务的必要步骤. Chomphan等[26 ] 提出实现泰语语音合成的新方法,在统一的HMM框架中同时对频谱、音调和音素持续时间进行建模,并使用基于决策树的不同风格的上下文聚类技术对频谱、音调和音素持续时间的参数分布进行独立聚类以改善声调正确性和韵律自然性. Tesprasit等[27 ] 提出的泰语TTS框架可以同时解决分词和同形异义词歧义问题. 这些研究为泰语TTS合成技术的发展提供了新的思路和方法. ...
1
... 受限于Tacotron系列模型的自回归特性,采用该系列模型的语音合成系统语音合成速度较慢,而且语言特征捕捉存在局限. 当前基于端到端模型的低资源语音合成研究相对较少,主要原因是端到端语音合成模型虽然能生成自然度较高的语音,但其内部处理过程中韵律信息和文本信息交织而非显式解耦[12 ] . 这种混合处理方式限制了模型对文本中韵律特征的深入解析和有效捕捉,可能影响合成语音的韵律准确性,降低语音的自然性和可理解性. 尤其是在训练数据有限的情况下,这种现象更为明显[28 ] . ...
2
... 通用、高资源语言的合成语音已经越来越接近自然语音,而低资源条件下的语音合成系统仍然存在影响合成语音质量的共性问题:1)HiFi-GAN V1解码器结构为了补偿输入声学特征和输出波形之间时间分辨率的差异,使用多个转置卷积将输入特征上采样到所需的采样率,引入混叠伪影[9 -10 ] . 2) 不同语言的声调范围不同,在低资源条件下的可用训练数据较少,基线系统无法准确预测音高信息,导致合成语音语气平淡,缺乏足够的韵律信息[29 -30 ] ,这种情况在缅甸语、越南语和泰语等语言的合成语音中尤为明显. ...
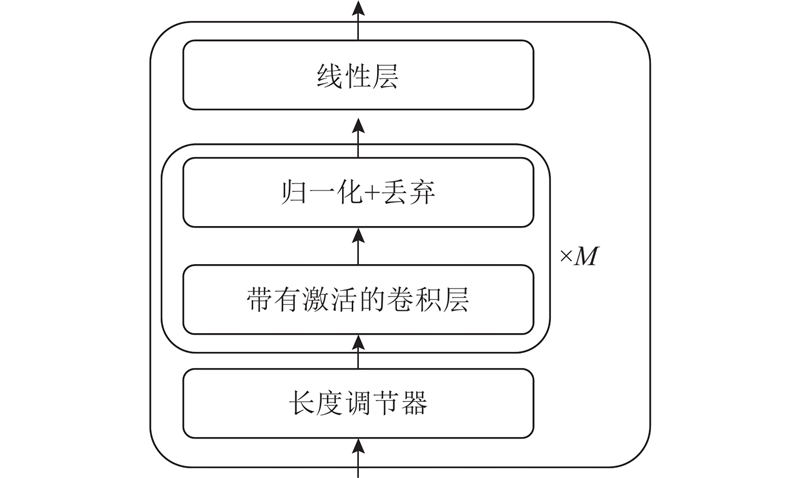
... 在低资源条件下VITS的训练过程中,基线系统无法准确捕捉和模拟声调,合成语音往往会缺乏生动性和情感[29 -30 ] . 可能的原因是现有研究在文本预处理时大多将固定的声调标签作为先验信息,这种离散标签不能完全捕捉声调的连续变化,导致合成语音在声调转折处出现不连贯的情况. 本研究通过在模型中添加帧级别的基频预测器并添加基频损失来提高语音合成的自然度和表现力. 如图4 所示,基频预测器由长度调节器和多个带有激活函数的卷积模块构成,其中长度调节器负责将文本编码器得到的文本维度特征变为帧级别,经过多个卷积模块后得到对数基频$ \mathrm{lg}{\widehat{\boldsymbol{F}}}_{0} $ $ {L}_{\mathrm{p}\mathrm{i}\mathrm{t}} $
2
... 通用、高资源语言的合成语音已经越来越接近自然语音,而低资源条件下的语音合成系统仍然存在影响合成语音质量的共性问题:1)HiFi-GAN V1解码器结构为了补偿输入声学特征和输出波形之间时间分辨率的差异,使用多个转置卷积将输入特征上采样到所需的采样率,引入混叠伪影[9 -10 ] . 2) 不同语言的声调范围不同,在低资源条件下的可用训练数据较少,基线系统无法准确预测音高信息,导致合成语音语气平淡,缺乏足够的韵律信息[29 -30 ] ,这种情况在缅甸语、越南语和泰语等语言的合成语音中尤为明显. ...
... 在低资源条件下VITS的训练过程中,基线系统无法准确捕捉和模拟声调,合成语音往往会缺乏生动性和情感[29 -30 ] . 可能的原因是现有研究在文本预处理时大多将固定的声调标签作为先验信息,这种离散标签不能完全捕捉声调的连续变化,导致合成语音在声调转折处出现不连贯的情况. 本研究通过在模型中添加帧级别的基频预测器并添加基频损失来提高语音合成的自然度和表现力. 如图4 所示,基频预测器由长度调节器和多个带有激活函数的卷积模块构成,其中长度调节器负责将文本编码器得到的文本维度特征变为帧级别,经过多个卷积模块后得到对数基频$ \mathrm{lg}{\widehat{\boldsymbol{F}}}_{0} $ $ {L}_{\mathrm{p}\mathrm{i}\mathrm{t}} $
Phonetic variation of Vietnamese tones in disyllabic utterances
1
1974
... 语言可分为声调语言和非声调语言2个大类. 在汉语、越南语、缅甸语、泰语等声调语言中声调是词汇区分的关键,同一个音节的不同声调可以代表不同的词义[31 ] ,不同声调具有不同的持续时间与音高变化范围. 越南语属于南亚语系,是越南的官方用语及通用媒介语,共包含平声、玄声、问声、跌声、锐声和重声6种声调[32 ] . 泰语属于汉藏语系,包含中平声、降声、升声、高平声和低沉声5种声调[33 ] . 缅甸语属于汉藏语系,包含低平声、高平声和高降声3种声调[34 ] . 对于缅甸语、泰语和越南语等声调语言,声调有助于区分拼写相同但含义不同的单词,对于清晰的沟通和理解至关重要[35 ] . 在语音合成中,基频是反映声调变化的重要声学参数,尤其在资源有限的情况下,通过精确控制和预测基频的变化,合成语音展现的情感和语气丰富,能够提高语音合成的自然度和表现力. ...
Vietnamese (Hanoi Vietnamese)
1
2011
... 语言可分为声调语言和非声调语言2个大类. 在汉语、越南语、缅甸语、泰语等声调语言中声调是词汇区分的关键,同一个音节的不同声调可以代表不同的词义[31 ] ,不同声调具有不同的持续时间与音高变化范围. 越南语属于南亚语系,是越南的官方用语及通用媒介语,共包含平声、玄声、问声、跌声、锐声和重声6种声调[32 ] . 泰语属于汉藏语系,包含中平声、降声、升声、高平声和低沉声5种声调[33 ] . 缅甸语属于汉藏语系,包含低平声、高平声和高降声3种声调[34 ] . 对于缅甸语、泰语和越南语等声调语言,声调有助于区分拼写相同但含义不同的单词,对于清晰的沟通和理解至关重要[35 ] . 在语音合成中,基频是反映声调变化的重要声学参数,尤其在资源有限的情况下,通过精确控制和预测基频的变化,合成语音展现的情感和语气丰富,能够提高语音合成的自然度和表现力. ...
1
... 语言可分为声调语言和非声调语言2个大类. 在汉语、越南语、缅甸语、泰语等声调语言中声调是词汇区分的关键,同一个音节的不同声调可以代表不同的词义[31 ] ,不同声调具有不同的持续时间与音高变化范围. 越南语属于南亚语系,是越南的官方用语及通用媒介语,共包含平声、玄声、问声、跌声、锐声和重声6种声调[32 ] . 泰语属于汉藏语系,包含中平声、降声、升声、高平声和低沉声5种声调[33 ] . 缅甸语属于汉藏语系,包含低平声、高平声和高降声3种声调[34 ] . 对于缅甸语、泰语和越南语等声调语言,声调有助于区分拼写相同但含义不同的单词,对于清晰的沟通和理解至关重要[35 ] . 在语音合成中,基频是反映声调变化的重要声学参数,尤其在资源有限的情况下,通过精确控制和预测基频的变化,合成语音展现的情感和语气丰富,能够提高语音合成的自然度和表现力. ...
1
... 语言可分为声调语言和非声调语言2个大类. 在汉语、越南语、缅甸语、泰语等声调语言中声调是词汇区分的关键,同一个音节的不同声调可以代表不同的词义[31 ] ,不同声调具有不同的持续时间与音高变化范围. 越南语属于南亚语系,是越南的官方用语及通用媒介语,共包含平声、玄声、问声、跌声、锐声和重声6种声调[32 ] . 泰语属于汉藏语系,包含中平声、降声、升声、高平声和低沉声5种声调[33 ] . 缅甸语属于汉藏语系,包含低平声、高平声和高降声3种声调[34 ] . 对于缅甸语、泰语和越南语等声调语言,声调有助于区分拼写相同但含义不同的单词,对于清晰的沟通和理解至关重要[35 ] . 在语音合成中,基频是反映声调变化的重要声学参数,尤其在资源有限的情况下,通过精确控制和预测基频的变化,合成语音展现的情感和语气丰富,能够提高语音合成的自然度和表现力. ...
Tone and phonation in Southeast Asian languages
1
2016
... 语言可分为声调语言和非声调语言2个大类. 在汉语、越南语、缅甸语、泰语等声调语言中声调是词汇区分的关键,同一个音节的不同声调可以代表不同的词义[31 ] ,不同声调具有不同的持续时间与音高变化范围. 越南语属于南亚语系,是越南的官方用语及通用媒介语,共包含平声、玄声、问声、跌声、锐声和重声6种声调[32 ] . 泰语属于汉藏语系,包含中平声、降声、升声、高平声和低沉声5种声调[33 ] . 缅甸语属于汉藏语系,包含低平声、高平声和高降声3种声调[34 ] . 对于缅甸语、泰语和越南语等声调语言,声调有助于区分拼写相同但含义不同的单词,对于清晰的沟通和理解至关重要[35 ] . 在语音合成中,基频是反映声调变化的重要声学参数,尤其在资源有限的情况下,通过精确控制和预测基频的变化,合成语音展现的情感和语气丰富,能够提高语音合成的自然度和表现力. ...
1
... 实验使用的数据来自缅甸语、越南语和泰语数据集. 越南语数据集由1位母语为越南语的女性说话人录制,总时长为6.9 h,音频前后保留50 ms的静音段并切分为3 996句,其中3 796句用于训练,150句用于测试,50句用于验证. 泰语数据集由1位母语为泰语的女性说话人录制,总时长为8.1 h,音频前后保留50 ms的静音段并切分为4 984句,其中4 784句用于训练,150句用于测试,50句用于验证. 缅甸语数据集由1位母语为缅甸语的女性说话人录制,总时长为4.1 h,音频前后保留50 ms的静音段并切分为2 530句,其中2 410句用于训练,90句用于测试,30句用于验证. 对应语言的文本均经过校对修改. 考虑到不同语言字符集的差异,为了更精准地表示文本内容,在文本预处理阶段将各语言的文本转换为国际音标表示. 所有音频数据均为单声道,采样率为22 050 Hz,16PCM编码,提取80维对数梅尔谱,快速傅里叶变换(fast Fourier transform,FFT)大小为1 024,跳跃长度为256,窗口长度为1 024. 参考基频使用WORLD声码器中DIO算法[36 ] 进行提取. DIO是高效的基频估计算法,用于语音分析中的周期性信号处理,相较于其他算法,不仅处理速度更快,还能保持估计结果的可靠性. ...
1
... 在客观评价方面,选择梅尔倒谱失真[37 ] MCD、基频的均方误差RMSE和感知语音质量评价[38 ] PESQ作为评价指标. MCD用于衡量合成语音与目标语音的接近程度,MCD值越低,表示合成语音与目标语音的相似度越高,质量越好. RMSE用于评估基频预测的准确性,RMSE值越低,表示合成语音的基频轮廓与目标语音越接近,合成质量越高. PESQ 提供相对综合的语音质量评价,评分范围为−0.5~4.5,分数越高表示语音质量越好. ...
1
... 在客观评价方面,选择梅尔倒谱失真[37 ] MCD、基频的均方误差RMSE和感知语音质量评价[38 ] PESQ作为评价指标. MCD用于衡量合成语音与目标语音的接近程度,MCD值越低,表示合成语音与目标语音的相似度越高,质量越好. RMSE用于评估基频预测的准确性,RMSE值越低,表示合成语音的基频轮廓与目标语音越接近,合成质量越高. PESQ 提供相对综合的语音质量评价,评分范围为−0.5~4.5,分数越高表示语音质量越好. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}