

复杂产品主要涉及工程密集型产品、系统和网络等,具有高成本、高附加值、高技术水平和多主体参与等典型特点[1-2]. 这些属性增加了开发复杂产品的风险,也对其风险评估活动提出了更高的要求. 失效模式与影响分析 (failure mode and effects analysis, FMEA) 是挖掘潜在风险,进行风险评估并对风险进行优先定级的有效逻辑分析方法[3]. 作为保障产品开发过程安全性和可靠性的重要方法[4-5],FMEA既可用于风险的事前预防,也可用于事后改进,已被广泛应用于航空航天[6]、信息系统[7]、核工业[8]以及医疗服务[9]等领域的复杂产品开发. 在传统FMEA方法中,每个失效模式的风险评估信息使用1到10的数字量表进行量化[10]. 数值难以准确刻画专家的评价信息,人们习惯采用“致命”、“严重”、“较低”等主观或定性的语言术语[11],因此越来越多的学者开始关注语言型FMEA方法.
现有语言型FMEA方法按照语言评价形式的不同可分为2种类型. 1)采用直接语言评价的FMEA方法:Zhao等[12]提出基于全乘比例分析多目标优化法和区间直觉模糊集的方法,用以处理FMEA评价中主观语言的不确定性和模糊性,使得失效模式的最终排序更为准确可靠;Liu等[13]采用混合平均算子构建群评估矩阵,利用改进的和谐性分析方法分析群区间二元组语言数据,解决了不同类型FMEA团队成员的评估信息差异问题,并在最终排序时考虑了风险因素的权重差异;Nie等[14]利用混合风险评估模型和多粒度语言分布评估来解决FMEA团队成员知识背景和经验的差异问题,采用最佳-最差和最大化推导方法来确定风险因素权重. 2)采用两两对比语言评价的FMEA方法:王睿等[15]利用直觉乘法加权平均算子集结失效模式的偏好矩阵并修正专家极端语言偏好信息,运用专家评价法和理想解模型法确定风险因素权重,有效提高了语言型FMEA风险评估的准确度;Carpitella等[16]结合可靠性分析和多准则决策方法来优化语言型FMEA方法,通过利用模糊逼近理想解排序法评估风险因子完成失效模式的排序,运用层次分析法评估不同专家的能力和经验差异,用以提高语言评价结果的准确性与可靠性.
上述方法在克服传统FMEA方法的缺陷方面发挥了积极作用,但在面向复杂产品开发情境时仍然存在以下不足. 1)在语言信息表达方面,现有语言型FMEA方法多假定专家能够直接绝对地给出失效模式的评价信息,未考虑复杂情境下,评价问题通常复杂晦涩. 复杂产品开发过程中存在众多交互影响的子模块,由于知识、经验有限,评价专家难以直接给出准确的绝对评价[17]. 2)在语言建模方面,已有研究假定不同评价专家对同一语言术语具备同样的理解,忽略了评价专家间可能存在的个性化语义差异;在复杂产品开发过程中,由于教育背景、地域分布不同,不同评价专家对于同一个语言术语集的理解可能存在差异[18-20],须考虑语义理解的一致性. 3)在因子赋权方面,现有研究多假定风险因子同等重要[21],较少同时考虑FMEA评价成员和风险因子的综合权重对结果的影响,忽略了风险因子和评价专家的重要性差异[22-23]. 在复杂产品开发过程中,利益相关者众多,存在不同的项目角色、从业经验、知识结构等因素,不同风险因子以及评价专家对结果的影响程度不尽相同.分布式语言偏好关系(distributed linguistic preference relation, DLPR)具有优越的成对比较信息表达能力,被广泛应用于医疗服务、故障诊断领域[24-25]. 本研究将分布式语言偏好关系作为专家表达评价信息的工具,构建针对专家评价信息的一致性驱动个性化语义模型,引入高级管理者对评价专家和风险因子的相对重要性分别进行评价以获得最终权重.
1. 相关概念
1.1. 模糊偏好关系
定义1 令X = {x1, x2, ···, xn}为给定方案集,N = {1, 2, ···, n};X上的FPR为
定义2 令F = [flk]n×n为定义在X上的FPR,若存在加性传递性 (flk – 0.5)+(fkr – 0.5) = (flr – 0.5), 即flr = flk+fkr – 0.5,
1.2. 分布式语言偏好关系
定义3 令X = {x1, x2, ···, xn}为方案集,L = {p1, p2, ···, pT}为语言术语集,n为方案的数量,T为表示语言术语集L粒度的奇数,使用L定义在X上的DLPR为
1.3. 数值刻度模型
根据Dong等[30]对数值刻度模型 (numerical scale model, NS)的相关界定,存在定义4.
定义4 令L = {p1, p2, ···, pT}为语言术语集,则映射NS: L → R称为L的数值刻度. 如果NS严格单调递增,则称NS为L的有序数值刻度.
NS(pt)表示语言术语pt的数值索引,描述了pt的语义. 考虑不同专家对于相同术语集中的语义理解程度存在差异,NS(pt)的数值通常是因人而异的,个性化NS(pt)可以是语言术语集pt的个性化语义.
2. 基于个性化语义的语言型FMEA风险评估方法
2.1. 问题描述
对于FMEA问题,假设存在n种失效模式,表示为FM = {FM1, FM2, ···, FMn};
2.2. 一致性驱动的个性化语义建模
给定含有T个语言术语的语言术语集L = {p1, p2, ···, pT}及其数值刻度NS(pt). 个性化语义是指每个个体对L中的每个语言术语pt都具有不同的语义理解,即NS(pt)具有不同的值. 基于个性化语义的分布式语言偏好关系量化,是指采用NS(pt)将分布式语言偏好关系D = [dlk]n×n转换为对应的数值偏好关系F = [flk]n×n,其中dlk = {(pt , βt) | t = 1, ···, T}. 具体地,
在实际的决策过程中,更优的NS(pt)可使D的量化更加合理,因此通过最大化D的一致性来获得更优的NS(pt). F与D表达了同样的信息,为此通过计算F的一致性来间接反映D的一致性. 由加性转移属性的定义可知,决策者偏好结果完全一致的F应满足等式:
在实际的决策过程中,由于决策问题的复杂性和决策者知识的有限,式(3)一般难以成立,因此,令
D(flr)反映决策者在xl和xr之间的不一致水平. 由于D(flr)可能不落在 [0,1],对其进行如下修正:
1−AD(flr)刻画了决策者在方案xl和xr之间的一致性水平. 决策者在方案xl上的一致性水平表示为
决策者在所有方案上的一致性水平表示为
L中的语言术语具有对称性, NS(pt)须满足以下约束:
考虑到L中语言术语的有序性,NS(pt)须满足以下约束:
考虑到L中语言术语分布的合理性,NS(pt)须满足以下约束:
构建分布式语言偏好关系量化的个性化语义模型M1,表达式为
2.3. 两阶段个性化语义模型构建
基于M1,分别构建针对De、Dr和
2.3.1. 第一阶段
令L为用以评价领域专家重要性的语言术语集Le,D为De =
令L为用以评价风险因子重要性的语言术语集Lr,D为Dr =
求解Me和Mr,得到管理者针对专家与风险因子语言术语集Le和Lr的一致性最优个性化语义*NSe
2.3.2. 第二阶段
基于*NSe
令L为用以评价风险类型或失效模式的语言术语集Li,D为Dij =
根据M1构建Dij量化的个性化语义模型Mf,表达式为
求解Mf得到专家EXj对风险类型语言术语集Li中的语言术语ptij的个性化语义理解*NSij(ptij), 其中i = 1, 2, ···, h; j = 1, 2, ···, m; t = 1, 2, ···, Ti.
2.4. 失效模式排序过程
基于获得的*NSij,由式 (1) 得到最优的数值偏好关系*Fij =
基于Fc计算每个失效模式的得分S (FMl), l = 1, 2, ···, n, 并进行排序.
如图1所示为本研究所提方法的模型框架. 根据相应的基础数据输入进行评价,得到针对专家、风险因子以及失效模式的分布式语言偏好信息. 1)通过数值关系转换与最大化一致性水平构建量化De、Dr的个性化语义模型Me、Mr,求解模型得到针对专家、风险因子的一致性最优的个性化语义. 2)利用加权平均算子,计算得到专家、风险因子的权重数值,构建并求解个性化语义模型Mf,得到针对失效模式评价的最优个性化语义. 3)聚合全部的最优数值偏好关系得到集体偏好关系,进一步计算每个失效模式的数值得分并排序.
图 1
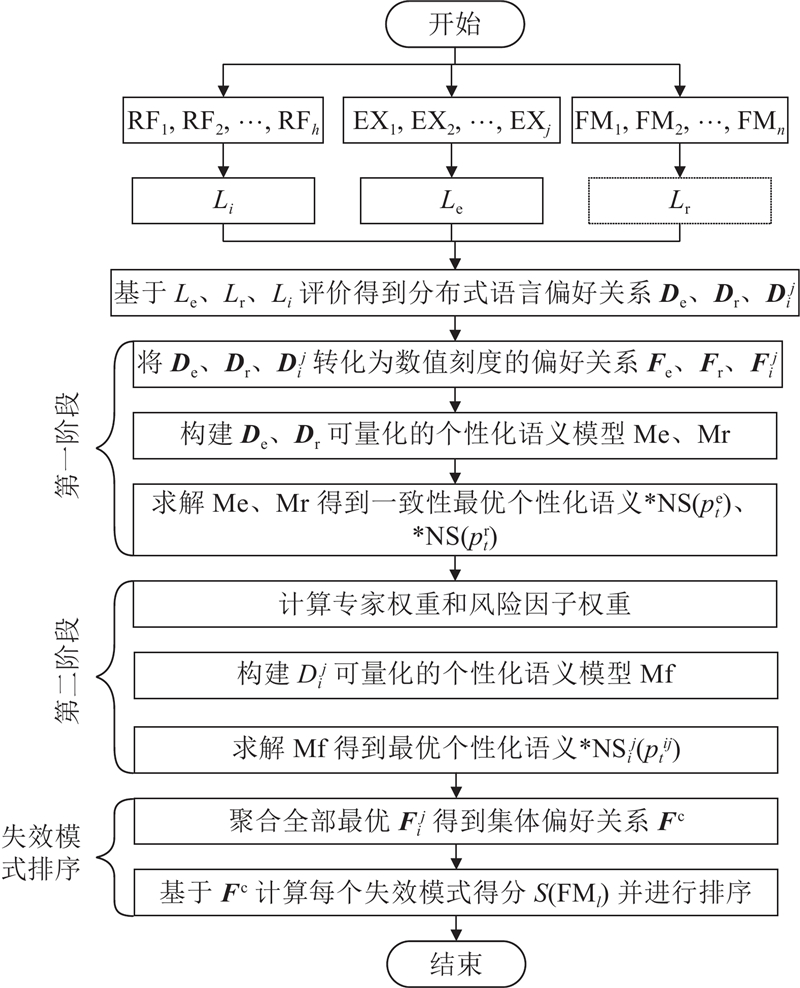
图 1 基于个性化语义的语言型FMEA风险评估方法的模型框架
Fig.1 Framework of linguistic FMEA method for risk evaluation based on personalized individual semantics
3. 面向航空发动机研制过程的风险评估
3.1. 案例背景
航空发动机研制是国防建设与经济社会发展的重要组成部分,集中体现国家的工业基础、科技水平与综合国力[32]. 航空发动机的研制技术难度高、投资成本大、研制周期长,项目风险远远高于一般的装备产品研发[33]. 由于航空发动机研制项目无法取得大量条件一致的历史风险数据,很难通过数理统计获得相关参数的概率分布,风险管理的原始数据一般由专家凭专业知识和工程经验进行主观评分的方法收集,对评价专家的经验具有较高的依赖性,且风险数据多是不确定的、模糊的. 在航空发动机研制过程中的各类风险活动复杂晦涩,风险之间往往牵一发而动全身[34-35],专家通常难以对某类风险给出直接绝对的评价,适合采用两两比较的语言评价方式. 航空发动机研制的主体众多,在知识结构、地域分布上均存在差异,使得来自不同领域、不同地域的专家在评价风险类型时存在不同的语言认知与经验感受. 不同专家的从业背景及其经验能力存在差异,风险因子对整体的影响与重要性也不同[36]. 采用分布式语言偏好评价航空发动机研制过程中的风险类型,考虑专家的个性化语义影响,同时考虑评价专家和风险因子的重要性差异,有助于提升航空发动机研制过程中风险评估的准确性与可靠性.
某型航空发动机为改进改型类型项目,须根据客户需求对产品进行迭代升级,最终达到交付标准. 该类型项目虽然具有一定的历史经验可参考,但研发过程仍然具有相当高的不确定性. 型号总师通常负责设计制造验证阶段的总协调、总决策,根据以往研制项目判断研制过程中可能存在的风险类型. 风险可分为6类:技术难度过大、进度延期、政策频繁变化、市场需求突然改变、费用超支、成员能力不足,表示为FM = {FM1, FM2, FM3, FM4, FM5, FM6}. 传统上,每个风险类型的评估与发生率 (Occurrence, O)、严重度 (Severity, S) 和难检度 (Detection, D) 这3个具体风险因子相关[37],风险因子表示为RF = {RF1, RF2, RF3}. 由型号总师选择几个主要领域(设计、制造、采购、质量)的专家EX = {EX1, EX2, EX3, EX4}组成FMEA评价团队,根据如表1所示的语言术语集Li, i = 1, 2, 3,对6类风险类型的3个风险因子进行评价. 型号总师需根据如表2所示的Le从每位专家的知识背景、从业经验、部门环境等方面对4位专家进行重要性评价,再根据表2中的Lr从风险因子的影响程度、管控难度对3个风险因子进行重要性评价.
表 1 失效模式语言评价术语集
Tab.1
| pi | L1 | L2 | L3 |
| p1 | 非常低 | 非常轻微 | 非常不可以 |
| p2 | 低 | 轻微 | 不可以 |
| p3 | 较低 | 较轻微 | 较不可以 |
| p4 | 中等 | 中等 | 中等 |
| p5 | 较高 | 较高 | 较可以 |
| p6 | 高 | 高 | 可以 |
| p7 | 非常高 | 非常高 | 非常可以 |
表 2 专家与风险因子重要性语言评价术语集
Tab.2
| pi | Le | Lr |
| p1 | 非常不重要 | 非常不重要 |
| p2 | 不重要 | 不重要 |
| p3 | 中等 | 较不重要 |
| p4 | 重要 | 中等 |
| p5 | 非常重要 | 较重要 |
| p6 | — | 重要 |
| p7 | — | 非常重要 |
3.2. 考虑一致性与权重的两阶段个性化语义模型
第一阶段:根据型号项目总师对风险因子和评价专家的重要性评价结果,以及4个领域专家对某型航空发动机研制过程中6类风险类型的分布式语言偏好信息,基于M1构建量化De、Dr的个性化语义模型分别为
其中
第二阶段:基于 *NSe
根据式 (15) 、 (16),求解专家权重
表 3 领域专家对风险类型语言评价的最优一致性
Tab.3
| RFi | EX1 | EX2 | EX3 | EX4 |
| RF1 | ||||
| RF2 | ||||
| RF3 | ||||
| 加权一致性: | ||||
表 4 一致性最优个性化语义解
Tab.4
| RFi | pi | EX1 | EX2 | EX3 | EX4 |
| RF1 | p1 p2 p3 p4 p5 p6 p7 | ||||
| RF2 | p1 p2 p3 p4 p5 p6 p7 | ||||
| RF3 | p1 p2 p3 p4 p5 p6 p7 |
3.3. 基于两阶段个性化语义模型的风险类型排序
通过Mf获得的*NSij和数值转化公式,得到航空发动机研制过程中风险类型评估的最优数值偏好关系*Fij. 以4位专家对于风险因子RF1的语言评价结果为例,依据本研究所提方法得到的最优数值偏好关系
基于式(18)得到航空发动机研制过程中风险类型的集体偏好关系Fc,
将Fc代入式(20)计算得到某型航空发动机研制过程中6类风险类型的最终得分,分别为0.146 0、0.161 6、0.162 9、0.183 5、0.170 4、0.175 5. 由此可得,在航空发动机研制过程中,基于分布式语言偏好评价并考虑专家权重、风险因子权重与个性化语义的风险类型排序:FM4 > FM6 > FM5 > FM3 > FM2 > FM1. 市场需求突然改变是首要风险类型,航空发动机研制过程中客户的需求变动频率较大,若未能及时有效沟通协调,可能面临如产品无法顺利交付、费用与资源的大量损失的严重后果. 在风险管控过程中,管理者应当增加关注程度,通过充分的跟踪与及时的沟通主动寻求适当的预防与解决办法.
3.4. 对比实验与分析
在不需要对语言进行精确刻画以及不需要考虑个性化语义的背景下,已有关于语言量化的研究多数假设语言分布为均匀分布的形式以此来简化语言信息处理工作[39]. 本研究考虑个性化语义在语言评价中的影响作用,通过构建模型与求解方法得到一致性最优下的个性化语义结果. 选择通常不涉及个性化语义背景的均匀分布方法与所提方法进行对比,论证所提方法的有效性与可行性.
若假设语义分布为均匀分布,即专家重要性语言术语集Le的均匀分布解为[0, 2/4, 2/4, 3/4, 1]、风险因子重要性语言术语集Lr的均匀分布解为[0,1/6, 2/6, 3/6, 4/6, 5/6, 1],型号总师对Le和Lr的一致性水平分别为
4位领域专家根据语言术语集Li对6类风险类型进行语言评价,假设语义分布为均匀分布 [0, 1/6, 2/6, 3/6, 4/6, 5/6, 1],求解得到相应的一致性水平,如表5所示. 对比所提方法获得的最优一致性水平可以看出,无论是不同专家对各个风险因子的一致性水平,还是对语言术语集Li的加权一致性,均低于所提方法得到的一致性水平. 因此,当领域专家对风险类型进行语言评价时,所提方法在一致性方面同样具有优越性.
表 5 均匀分布下的风险类型语言评价一致性水平
Tab.5
| RFi | EX1 | EX2 | EX3 | EX4 |
| RF1 | ||||
| RF2 | ||||
| RF3 | ||||
| 加权一致性: | ||||
由一致性水平与相关权重求解得到相应的数值偏好关系以及最终的集体偏好关系,代入式(20)计算得到假设语义均匀分布下的风险类型得分值,分别为
图 2
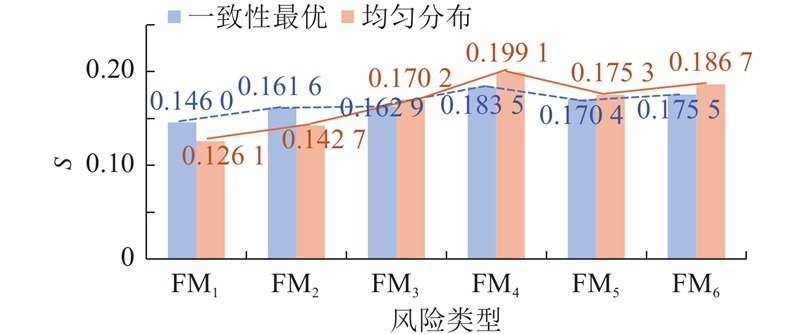
图 2 某型航空发动机研制过程风险类型得分
Fig.2 Risk type score in development process of certain aero engine
3.5. 讨论
为了进一步对比所提方法的优越性,采用传统FMEA方法计算预处理后的数据集,即最终风险模式排序根据风险类型的绝对数值乘积大小依次列出,得到风险排序结果为FM1 > FM2 > FM6 > FM5 > FM4 > FM3. 排序结果与所提方法存在差异. 主要原因:传统FMEA方法使用绝对数值对风险类型进行直接评价,未考虑评价专家或者风险类型重要性差异的影响. 在实际情况中,评价专家的权威性、在项目中负责的领域、经验能力均存在差异;型号总师更倾向于综合考虑全局因素,对风险类型的关注程度也存在差异. 例如,传统FMEA方法的排序首位为“技术难度过大”的管理风险,考虑航空发动机自身的产品技术特点,这一风险模式具有普遍性. 所提方法排序较前的风险是“客户需求突然改变”“成员能力不足”,考虑本研究案例数据的来源是改进改型的航空发动机研制项目,客户需求改变以及项目组成员能力能否完成任务更符合案例实际背景特征,也更能体现不同情境下的风险关注重点. 因此,与传统的FMEA风险评估方法对比,本研究提出的语言型FMEA评价方法更符合实际评估情况和专家评价习惯. 尤其是在面向复杂产品开发领域,本研究改进的语言型FMEA方法更适合在复杂晦涩情境进行风险评价活动,可以获得更为可靠的风险评估结果.
如表6所示为已有研究使用语言表达方式改进传统FMEA方法的文献梳理. 与改进的语言型FMEA风险评估方法相比,所提方法在语言信息的表达形式、信息的处理方式和权重的确定方面均有适应复杂产品开发情境的改进与提升. 由表6可知,已有改进型FMEA方法大多采用直接数值/语言评价,直接的语言或者数值评价虽然简便易行,但往往难以匹配复杂情境,对于一些难以直接判断的情况适应性不足. 本研究结合具体情境,选择间接的语言偏好形式评价,在信息表达形式方面丰富了既有FMEA方法. 在语言型FMEA的信息处理过程中,鲜少文献考虑语义影响,本研究基于个性化语义的风险评估结果更适合评价专家背景差异较大的复杂情境. 语言型FMEA更多关注风险因子的权重影响,较依赖单一的主观或客观赋权方法,所提方法不仅采用主客观结合的综合赋权方法,还同时考虑风险因子以及评价专家的权重影响,进一步补充了语言型FMEA方法中权重确定的研究.
表 6 语言型FMEA风险评估方法比较
Tab.6
| 方法 | 信息表达形式 | 信息处理方法 | 权重的确定方法 | ||||||
| 直接评价 | 间接评价 | 直接量化 | 考虑语义 | 主观赋权 | 客观赋权 | 综合赋权 | |||
| Liu等[13] | 区间二型模糊集 | — | √ | — | — | — | — | ||
| 王睿等[15] | 直觉乘法偏好关系 | — | √ | — | — | — | 专家评估+理想解模型法(风险因子) | ||
| Wang等[40] | 三角模糊数 | — | √ | — | — | — | — | ||
| Huang等[41] | — | 比例犹豫模糊语言集 | √ | — | 最好最坏法(风险因子) | — | — | ||
| Zhang等[20] | — | 分布式语言偏好信息 | — | √ | — | — | — | ||
| Huang等[42] | 语言Z数 | — | √ | — | — | 最小方差法(FMEA成员);优劣解距离法(风险因子) | — | ||
| 赵翼翔等[43] | 直觉模糊数 | — | √ | — | — | — | 层次分析法+数据本身(风险因子) | ||
| 王济干等[44] | 语言分布评价 | — | √ | — | — | 熵权法(风险因子) | — | ||
| Salah等[45] | 绝对数值评价 | — | √ | — | — | — | — | ||
| Song等[46] | 双向编码器表征法模型+向量空间模型 | — | √ | — | — | 熵权法(风险因子) | — | ||
| Liu等[47] | 模糊语言集 | — | √ | — | — | 专家间关系+风险评估信息(FMEA成员) | — | ||
| 本研究 | — | 分布式语言偏好信息 | — | √ | — | — | 专家评估+一致性最优个性化语义模型(FMEA成员+风险因子) | ||
4. 结 语
本研究面向复杂产品开发过程的典型特征与实际需求,针对已有语言型FMEA评价方法在风险管理问题中的不足,基于个性化语义并考虑专家与风险因子的权重差异,提出改进的语言型FMEA方法. 以航空发动机研制为例,通过开展实践数据的验证对比试验,论证了所提方法的可行性与有效性,表明该方法有助于增强结果的可信性与准确性. 所提方法的3个主要优势:1)采用分布式语言偏好关系改进语言FMEA评估中的语言信息表达方式,适用于晦涩复杂的复杂产品风险管理实践背景;2)考虑个性化语义对评价结果的影响,优化语言FMEA方法中语言建模与求解过程,有助于解决现实中语义感受与认知存在差异的问题;3)采用综合赋权法同时考虑评价专家与风险因子的重要性差异问题,增加了语言FMEA方法中权重赋予的整体性与客观性,有助于提高评价结果的可信性与准确性. 总体而言,与现有语言型FMEA方法相比,所提方法不仅能够较好地处理复杂背景下的风险评价问题,也充分考虑了语言的个性化、风险因子与评价者的差异性对评价结果的影响.
本研究提出的语言型FMEA方法的应用背景适合复杂产品研制情境,对于一些技术成熟度较高的产品与行业背景,所提方法在应用层面的可操作性与简便性或有不足. 所提方法暂未涉及后续的共识达成阶段,主要原因是设计制造协同问题一直是行业痛点,不同开发领域间存在固有矛盾. 调整偏好达成共识容易产生违背专家初始意愿的后续问题,现有共识达成方法难以解决该复杂情境下的共识与意愿问题. 所提方法在风险识别部分的改进存在不足,仍然基于专家直接评价得到,未来计划结合人工智能领域的前沿方法进行更加全面的风险模式识别.
参考文献
The project-based organisation: an ideal form for managing complex products and systems?
[J].
Reliability and maintenance modeling for systems subject to multiple dependent competing failure processes
[J].DOI:10.1080/0740817X.2010.491502 [本文引用: 1]
Reliability evaluation of a stochastic-flow network in terms of minimal paths with budget constraint
[J].DOI:10.1080/24725854.2018.1504358 [本文引用: 1]
Failure modes and effects analysis: an evaluation of group versus individual performance
[J].DOI:10.1111/j.1937-5956.2012.01363.x [本文引用: 1]
Reliability improvement of electronics standby display system of modern aircraft
[J].
The European power plant conceptual study: helium-cooled lithium–lead reactor concept
[J].
Design of a safer approach to intravenous drug infusions: failure mode effects analysis
[J].DOI:10.1136/qshc.2003.007443 [本文引用: 1]
Comparison of the HAZOP, FMEA, FRAM, and STPA methods for the hazard analysis of automatic emergency brake systems
[J].DOI:10.1115/1.4051940 [本文引用: 1]
Systematic failure mode effect analysis (FMEA) using fuzzy linguistic modelling
[J].DOI:10.1108/02656710510625248 [本文引用: 1]
Failure mode and effect analysis using MULTIMOORA method with continuous weighted entropy under interval-valued intuitionistic fuzzy environment
[J].DOI:10.1007/s00500-016-2118-x [本文引用: 1]
An integrated failure mode and effect analysis approach for accurate risk assessment under uncertainty
[J].DOI:10.1080/0740817X.2016.1172742 [本文引用: 2]
Risk evaluation by FMEA of supercritical water gasification system using multi-granular linguistic distribution assessment
[J].DOI:10.1016/j.knosys.2018.05.030 [本文引用: 1]
考虑专家共识的改进FMEA风险评估方法
[J].
Improved FMEA method for risk evaluation considering expert consensus
[J].
A combined multi-criteria approach to support FMECA analyses: a real-world case
[J].DOI:10.1016/j.ress.2017.09.017 [本文引用: 1]
Distribution linguistic preference relations with incomplete symbolic proportions for group decision making
[J].DOI:10.1016/j.asoc.2019.106005 [本文引用: 1]
What computing with words means to me [discussion forum]
[J].DOI:10.1109/MCI.2009.934561 [本文引用: 1]
A consensus model for large-scale linguistic group decision making with a feedback recommendation based on clustered personalized individual semantics and opposing consensus groups
[J].DOI:10.1109/TFUZZ.2018.2857720
Personalized individual semantics-based approach for linguistic failure modes and effects analysis with incomplete preference information
[J].DOI:10.1080/24725854.2020.1731774 [本文引用: 2]
A novel failure mode and effect analysis model for machine tool risk analysis
[J].DOI:10.1016/j.ress.2018.11.018 [本文引用: 1]
基于多主体仿真的大群体应急决策风险致因分析
[J].
Risk-causing analysis of large group emergency decision-making based on multi-agent simulation
[J].
Failure mode and effect analysis improvement: a systematic literature review and future research agenda
[J].DOI:10.1016/j.ress.2020.106885 [本文引用: 1]
A linguistic information granulation model and its penalty function-based co-evolutionary PSO solution approach for supporting GDM with distributed linguistic preference relations
[J].DOI:10.1016/j.inffus.2021.07.017 [本文引用: 1]
Linguistic information-based granular computing based on a tournament selection operator-guided PSO for supporting multi-attribute group decision-making with distributed linguistic preference relations
[J].DOI:10.1016/j.ins.2022.07.050 [本文引用: 2]
Decision-making with a fuzzy preference relation
[J].DOI:10.1016/0165-0114(78)90001-5 [本文引用: 1]
Group decision-making model with incomplete fuzzy preference relations based on additive consistency
[J].DOI:10.1109/TSMCB.2006.875872 [本文引用: 1]
Distributed linguistic representations in decision making: taxonomy, key elements and applications, and challenges in data science and explainable artificial intelligence
[J].DOI:10.1016/j.inffus.2020.08.018 [本文引用: 1]
Consistency and consensus measures for linguistic preference relations based on distribution assessments
[J].DOI:10.1016/j.inffus.2012.01.006 [本文引用: 1]
Computing the numerical scale of the linguistic term set for the 2-tuple fuzzy linguistic representation model
[J].DOI:10.1109/TFUZZ.2009.2032172 [本文引用: 1]
An improved FMEA method based on the linguistic weighted geometric operator and fuzzy priority
[J].DOI:10.1080/08982112.2015.1132320 [本文引用: 1]
世界航空发动机发展趋势及经验
[J].
Development trends and experience of world aero engines
[J].
Latecomer firm strategies in complex product systems (CoPS): the case of Iran’s thermal electricity generation systems
[J].DOI:10.1016/j.respol.2015.02.005 [本文引用: 1]
考虑自适应行为的研发网络风险传播模型构建及仿真
[J].
Risk propagation modeling and simulation in R&D network when considering the adaptive behaviors
[J].
Application of interval 2-tuple linguistic MULTIMOORA method for health-care waste treatment technology evaluation and selection
[J].DOI:10.1016/j.wasman.2014.07.016 [本文引用: 1]
Failure mode and effect analysis: FMEA from theory to execution
[J].
A constrained multi-swarm particle swarm optimization without velocity for constrained optimization problems
[J].DOI:10.1016/j.eswa.2019.112882 [本文引用: 1]
Personalized individual semantics based on consistency in hesitant linguistic group decision making with comparative linguistic expressions
[J].DOI:10.1016/j.knosys.2018.01.011 [本文引用: 1]
A risk evaluation and prioritization method for FMEA with prospect theory and Choquet integral
[J].DOI:10.1016/j.ssci.2018.08.009 [本文引用: 1]
New approach for quality function deployment based on proportional hesitant fuzzy linguistic term sets and prospect theory
[J].DOI:10.1080/00207543.2018.1470343 [本文引用: 1]
A new model for failure mode and effect analysis integrating linguistic Z-numbers and projection method
[J].DOI:10.1109/TFUZZ.2019.2955916 [本文引用: 1]
一种综合赋权的改进FMEA风险评估方法
[J].DOI:10.3969/j.issn.1007-7375.2021.03.011 [本文引用: 1]
An improved FMEA risk assessment method based on comprehensive empowerment
[J].DOI:10.3969/j.issn.1007-7375.2021.03.011 [本文引用: 1]
基于共识模型和前景理论的输水工程运行安全风险评价
[J].DOI:10.3880/j.issn.1003-9511.2022.01.012 [本文引用: 1]
Risk assessment of operation safety of water conveyance projects based on consensus model and prospect theory
[J].DOI:10.3880/j.issn.1003-9511.2022.01.012 [本文引用: 1]
Risk prioritization using a modified FMEA analysis in industry 4.0
[J].DOI:10.1016/j.jer.2023.07.001 [本文引用: 1]
A new approach to risk assessment in failure mode and effect analysis based on engineering textual data
[J].DOI:10.1080/08982112.2024.2304815 [本文引用: 1]
An improved FMEA method based on the expert trust network for maritime transportation risk management
[J].DOI:10.1016/j.eswa.2023.121705 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}