

基于区块链的数据收集方法是研究热点,区块链是集体维护的分布式数据库,利用加密技术避免信息被篡改与伪造. 为了保证网络中各节点数据一致,须设计合理的共识机制[4]. 现有共识机制可粗略分为2大类. 1)基于证明的“proof-of-x”共识机制. 这类共识机制主要应用于公链系统,其需要矿工证明某个活动或条件已经被完成,以此获得添加区块和获得奖励的权利,其中工作量证明(Proof-of-Work, PoW) 算法使用最广泛[5],占数字加密货币总市值的90%以上. 此外,还有权益证明(Proof-of-Stake, PoS)[6]算法、委托权益证明(Delegated-Proof-of-Stake, DPoS)算法[7],但它们将大部分算力集中在计算随机数哈希值、用户资产和高信用节点上,未考虑数据本身特征,难以准确检验数据质量. Huang等[8]提出BlockSense,通过引入同态加密技术保护用户数据隐私,使用数据证明(Proof-of-Data, PoD)算法控制数据质量,但其缺乏对RSS指纹数据分布的进一步深入分析. 2)基于投票的共识机制. 这类共识机制中的成员倾向于对每一个决策进行投票,依多数投票决出结果,或由群体普遍接受某决策,在某些情况下,领导者被选中后代表成员群体执行活动. 许多研究[9-14]将基于投票的共识机制应用于众包采集过程,本质上是选择可信度高的节点,但其仍缺少对数据本身特点的考虑. Li等[9]提出基于区块链的通用框架CrowdBC,使用智能合约来执行任务. Wu等[10]在BRPC方案中提出挖掘真实值算法,从用户信用度的角度评估数据质量,并使用Paillier密码系统实现计算验证协议以保护用户隐私. Cai等[11]设计了可验证的群智感知系统,利用同态性质检查数据聚合的正确性. Shen等[12]提出基于区块链的轻量化隐私保护质量验证众包收集框架,设计的参与者管理合约让众包任务能够透明、公平地执行,在质量控制方面,将信用值高的节点提交的数据作为高质量数据,并给出报酬分配策略. Lu等[13]设计基于区块链的匿名可溯源问责众包系统,保证了用户的匿名性与隐私;Zou等[14]提出去中心化的可信众包收集系统CrowdHB,其采用混合区块链架构,并利用智能合约实现位置隐私保护,在提高系统性能的同时保证数据质量. 在质量控制方面,这一类方法本质上是对网络中结点的筛选而非对数据本身的筛选.
上述基于区块链的众包数据收集方法在隐私安全、区块链安全、激励机制等方面取得了一定进展,但他们在数据质量控制方面尚未充分考虑数据的分布特征. 因此,如何设计针对室内定位数据收集的去中心化RSS数据质量控制方法,已经成为亟待解决的难题.
针对以上挑战,提出去中心化的室内定位众包数据质量控制方法. 本研究的主要贡献如下:1)提出基于区块链的众包指纹数据收集共识算法PoWFQ,通过考虑历史RSS数据分布,从均值和方差的角度衡量数据分布差异,识别异常值并将其剔除,并使用环签名技术保护用户账号隐私,在质量评估阶段对比新数据与历史数据,防止恶意用户上传相同数据进行双花攻击;2)设计有效的激励函数,综合考虑用户数据与历史数据分布的差异、用户提交的数据量以及用户耗能,并在用户分配报酬前使用非交互式Schnorr协议进行数据确权,实现对用户提交高质量RSS数据的有效激励;3)在多个真实指纹数据集上进行全面的实验,验证PoWFQ方法的有效性.
1. 相关理论与技术基础
1.1. 非交互式Schnorr协议
Schnorr协议[15]在Alice(证明者)和Bob(验证者)之间交互运行. Alice公开她的公钥
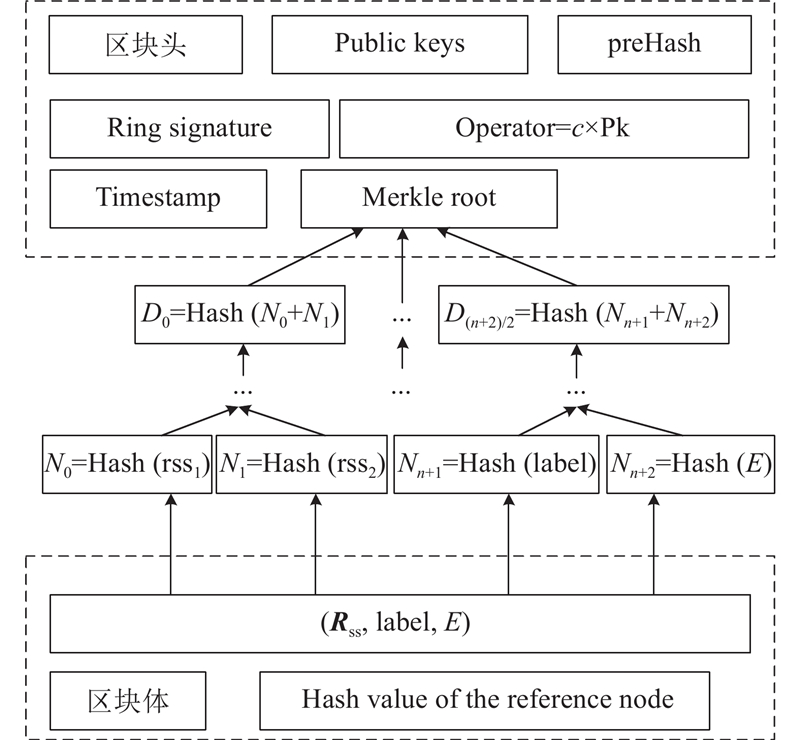
1.2. 区块结构
为了满足用户隐私需求与数据质量验证工作,除了基本的前块哈希值、时间戳、Merkle根外,PoWFQ在区块头中还加入了环签名所需的公钥集合、与环签名以及用于身份认证的操作数
图 1
1.3. 单点信号传播模型
RSS信号具有聚集性,短时间内对于同一个AP而言,相同位置的RSS信号相对稳定但可能会有异常值[16],因为温度、湿度、障碍物等环境因素或者恶意用户扰动都可能会导致信号出现异常值.
设用户在位置
式中:
2. RSS指纹数据质量控制框架
根据对室内定位指纹信号特点与传播模型的分析,提出考虑指纹数据分布特性的基于区块链的众包指纹数据质量控制方法框架,具体如图2所示. 边缘服务器负责任务发布、报酬计算与协调节点的连接;众包用户负责感知无线信号并上传;验证工人负责评估数据质量;全节点负责维护和验证完整区块链数据.
图 2
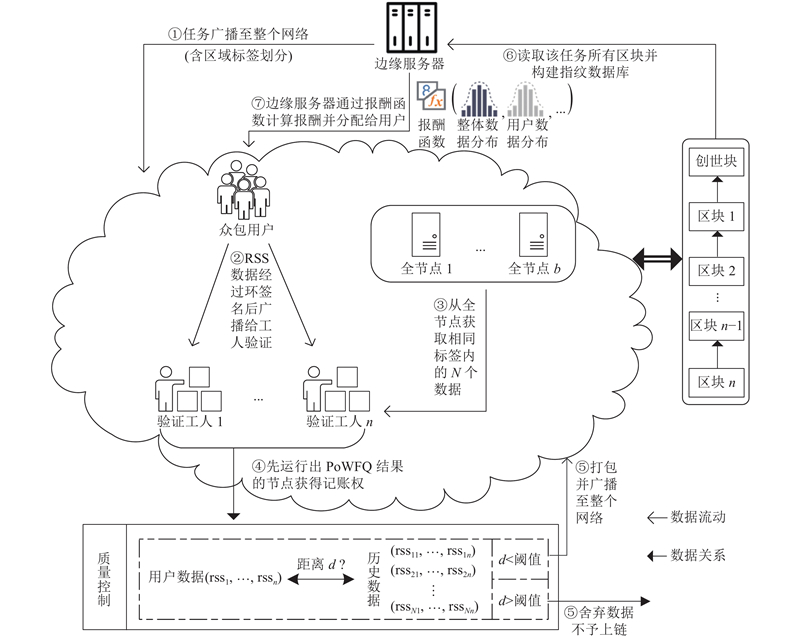
图 2 去中心化的室内定位RSS指纹数据质量控制框架
Fig.2 Framework of decentralized indoor positioning RSS fingerprint data quality control
RSS指纹数据采集流程如下. 1)边缘服务器进行任务发布(见图2中过程①),其中,任务文件包含目标建筑的室内区域网格划分与位置标签划分,边缘服务器在每一个任务开始与结束时都须向全网节点广播;2)众包用户收到任务信息后使用自己的终端设备在目标场景中采集RSS指纹信息,为了不向验证工人透露账户身份信息,使用环签名机制[18]实现对验证节点的身份匿名,随后将数据广播给与自己相连接的节点(见图2过程②);3)验证工人接收到新的待验证数据后向全节点请求历史数据,确认用户未发起双花攻击后,利用PoWFQ算法对比用户当前新数据与历史数据,当新数据满足质量需求时,将其打包成区块并被广播至整个区块链网络;当新数据不满足质量需求时不予上链(见图2过程③、④、⑤);4)当到达采集任务截止时间或边缘服务器须停止任务时,向全网广播任务停止消息,随后边缘服务器访问区块链网络获取数据,构建完整数据集并训练室内定位模型(见图2过程⑥);5)边缘服务器根据用户数据误差为其分配报酬(见图2过程⑦). 本研究重点研究过程⑤的数据质量控制方法以及过程⑦的报酬分配方法.
3. 质量控制共识算法
3.1. 数据质量评估
结合数据采集点的聚集特点与信号传播模型,主要考虑基于公链的众包采集场景,假设用户提交的RSS数据可以表示为
某个特定标签内的真实数据分布的参数难以确定,但可以用历史数据的样本均值来逼近真实分布的均值. 部分公共场所已存在一些公开的RSS信号数据集,可以使用这些已公开数据集作为历史数据,以评估新数据的质量. 倘若目标任务区域或公共场所不存在相关的历史数据,可以提前设置一个RSS数据采样阶段,让节点在很短时间内(2~3 d)周期性采集该区域内的RSS数据作为初始历史数据[19],在后续众包收集过程中不断更新历史数据. 在获得历史数据后,便可求出其均值向量
当用户将采集的
算法1 质量验证算法
输入:
输出:
1. num == 0
2. while node.hash != genieshash do
3. getblock (node.hash)
4. if node.label ==
5. if node.data ==
6. return false
7. endif
8. num++
9. endif
10. if num == N
11. break
12. endif
13. node.hash = previousblockhash
14. endwhile
15. Calculate the mean vector and variance vector of N data
16. Copy variance into var_copy[ ]
17. Sort variance
18. var index[ ]
19. for i = 0 ; i < len(variance) ; i++
20. value = var_copy[i]
21. for v = range variance
22. if v == value
23. index = append(index, i)
24. endfor
25. endfor
26. sum = Sum (index)
27. var weight[ ]
28. Calculate weight
29. calculate
30. calculate
31. if
32. packing blocks and upload blocks
33. return true
34. else
35. print(‘数据质量不合格’)
36. return false
37. endif
常见的计算复合高斯分布之间距离的方法包括马氏距离(Mahalanobis distance)[20]、KL散度[21]、巴塔查里亚距离(Bhattacharyya distance)[22]. 其中,KL散度、巴塔查里亚距离须已知2批数据的概率分布,但考虑到用户提交的数据有可能仅有一条,KL散度、巴塔查里亚距离不适用于这种距离计算场景;马氏距离可计算2个向量之间的距离,同时考虑了各个维度上的差异以及它们之间的协方差结构,但利用其直接求
式中:
式中:d为阈值. 由式(2)可知,均值向量与各分量权重对用户提交数据的评价起重要作用,本研究通过引入区块链的公链技术,将数据质量控制过程从边缘服务器移至公链网络,且任一节点都可验证区块数据的正确性.
3.2. 质量控制阈值的选定
质量控制阈值
对于该m个样本的每一个属性列
式中:
该方法考虑了已有数据集中列属性数值的波动情况,认为波动少的属性列具有更高的可信度,分配更多的权重,设置权重的另一个原因是,用户采集的RSS信号往往具有稀疏性,对于第j个RP点来讲,该点能检测到的RSS信号强度个数有限,在计算
3.3. 抵御重放攻击
在区块链众包收集中,重放攻击是常见的安全威胁,该攻击通过重复提交已经执行过的交易或操作来欺骗系统,从而获得不当的利益或破坏系统的正常运行. 若攻击者在短时间内重复提交相同数据,可能导致区块链上存在相同的指纹数据,使模型的训练数据集特征单一,导致模型过拟合. 为了抵御该攻击,在验证节点检索链上的历史数据时,判断用户提交的待审核数据是否已存在,若发现存在相同数据,则直接停止验证过程,判定其为异常数据. Lee等[16]提到特定时间段内的RSS信号值趋于稳定但仍有波动,距今时间过长的信号记录可能会产生较大波动,所以在PoWFQ共识算法中读取特定标签内最新的N个数据,分析这一批数据的分布特征. 短时间内N的取值越大,消除环境噪声的效果越明显. 经过实验表明,使用PoWFQ算法可抵御重放攻击,防止恶意用户上传相同数据来骗取报酬.
4. 激励机制
为了激励用户提交满足质量要求的RSS数据,边缘服务器须根据用户上传数据质量为其分配合适的报酬.
由于用户匿名上传数据,在进行报酬分配前须先进行数据确权. 例如,用户A想要证明自己提交了区块m的数据时,边缘服务器生成一个随机数
根据式(1)中的电波传播模型,用户提交的数据服从高斯分布,不同位置点的信号满足独立同分布. 每一个位置采集的信号强度都有一个分布,如图3所示,按照区间估计思想认为落在
图 3
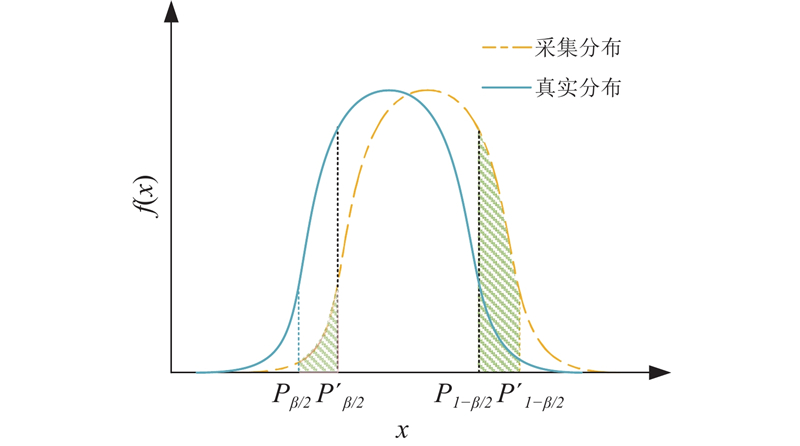
若采集的信号值落在
在计算用户A在标签k上的数据质量误差时,边缘服务器从链上获取标签k的m条记录:
对于其中某个属性列的变量
式中:
使用式(6)、(7)计算出置信区间后,再计算用户A提交数据的属性列
式(8)描述了当用户在
当边缘服务器能够量化出数据的质量误差后,便可通过用户提交的数据数量、数据质量与设备能耗3个角度为用户发放报酬. 手机在数据上传过程中的能耗主要受到以下几个因素的影响:
1)手机可能会配备不同类型的传感器,用于采集各种数据,如位置、加速度、声音等. 这些传感器的使用会消耗手机的电能.
2)数据上传须使用手机的网络连接,包括WiFi、蜂窝网络. 在数据传输过程中,手机须保持网络连接,这会消耗电能. 此外,网络环境的好坏也会影响到数据传输的能耗,例如在信号较弱的区域,手机可能需要更多的功率来保持网络连接. 网络传输能耗可以根据数据传输时的带宽、传输速率和传输距离等因素进行估算.
3)在数据上传之前,手机可能须对采集到的数据进行处理和压缩,以减少数据传输的大小和时间. 数据处理和压缩需要消耗手机的CPU和内存资源,从而增加了能耗.
4)在数据上传过程中,手机的屏幕须保持开启状态,以便用户操作和监控数据上传的进度,此过程也会增加手机的能耗.
综上所述,手机在参与众包数据上传时会消耗大量的电能,用
考虑到用户不会在报酬低于自身采集能耗的情况下完成众包任务,故服务器至少为众包用户补偿采集能耗;根据总能耗与数据质量,边缘服务器按如下公式给终端分发任务报酬:
用户提交的数据量越多、提交数据时的时间戳越大,得到的报酬则越多. 由式(9)可知
5. 实验结果分析
实验主要模拟2个阶段:1)用户端在采集到某个标签的RSS信号后,验证工人的数据质量控制过程,该过程将满足质量需求的数据记录上传至公链;2)在满足质量的数据收集完之后,数据需求方用这些数据训练机器学习模型并计算用户报酬. 实验评价指标分别为数据上传的效率、机器学习的模型性能以及数据集聚类程度.
5.1. 实验配置
实验分为终端侧与边缘服务器侧,终端侧使用Goland在本地模拟数据采集流程,实现数据共识、质量评估判断与数据上传工作;边缘服务器侧使用Pycharm部署CNN训练模型[23-24]实现室内定位模型的训练,同时对比经过本研究方法筛选前后的数据对模型精度的影响,判断众包采集任务的完成质量. 硬件设备如下:Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz 2.60 GHz,NVIDIA GTX965M 2G GDDR5 独立显卡,8 GB RAM,6 GB显存,CNN网络模型学习率为0.2,batch_size大小为64,需要训练的参数量为
表 1 CNN定位模型的网络参数
Tab.1
| 层 | 输出形式 | 参数个数 |
| Conv2d_1(Conv2D) | (None,1,53,32) | 192 |
| Conv2d_2(Conv2D) | (None,1,53,32) | |
| max_pooling2d_1(MaxPooling2D) | (None,1,24,64) | 0 |
| dropout_1 (Dropout) | (None,1,13,64) | 0 |
| flatten_1 (Flatten) | (None,832) | 0 |
| dense_1 (Dense) | (None,128) | |
| dropout_2 (Dropout) | (None,128) | 0 |
| dense_2 (Dense) | (None,10) |
5.2. 实验数据集
1) MALL数据集:采自一个31.8 m×14.95 m的购物中心区域,整个区域被划分为10个标签. 在所有采集位置点附近共布设了22个信标,可以稳定检测到来自35个WiFi AP的信号. MALL数据集包含
2) UJIIndoorLoc数据集:采自Universitat Jaume I的一个长为390 m宽为270 m区域的4层建筑,该数据集包含
3)WiFi-RSS数据集:采自东伦敦建筑大学,该数据集包含
通常情况下,RSS范围为(−45, −100) dBm,如果用户位置离AP位置近,则其RSS信号较强;相反,若用户位置远离AP位置,则其信号较弱甚至不可用. 实验中将信号强度较弱的RSS值设置为−200 dBm,3个数据集在输入到模型中使用前都使用z-score方法进行归一化处理.
5.3. 评价指标
实验采用3个性能指标来评价所提方法的性能,分别为出块耗时、模型性能与数据的轮廓系数. 本研究方法的总体目标是在可接受的出块耗时下尽可能提高模型性能.
出块耗时是指区块链网络中生成新区块所需的时间,是区块链性能和效率的重要指标. 用共识结束时刻的时间戳减去共识开始时刻的时间戳来记录每一次共识验证的时间.
模型性能指标主要有训练精度、训练损失、验证精度与验证损失. 其中,训练精度为模型在训练数据集上预测正确的样本占总样本的比例;训练损失为训练数据集中真实标签与预测标签的交叉损失熵;验证精度为模型在验证数据集上预测正确的样本占总样本的比例;验证损失为验证数据集中真实标签与预测标签的交叉损失熵.
从基于学习的室内定位角度看,模型将样本划分到正确的标签便认为模型效果良好. 为了进一步评估数据的质量,引入轮廓系数
式中:n为数据集记录的总条数;
总体轮廓系数综合考虑了样本与其所属簇内的相似度、相邻簇间的不相似度,总体轮廓系数的取值范围为[−1.0,1.0],总体轮廓系数越接近1.0,簇内差距越小,簇间距离越大,数据集聚类效果越好;反之,聚类效果越差.
5.4. 实验结果与分析
5.4.1. 历史数据数量的影响
历史数据条数直接影响到PoWFQ的质量评估结果与共识耗时,采用滑动窗口的大小来衡量历史数据的数量,滑动窗口越大,参考的历史数据数量越多. 为了方便,研究滑动窗口大小为10、15、20时历史数据数量对共识耗时与模型性能的影响,实验结果分别用PoWFQ-winlen10、PoWFQ-winlen15与PoWFQ-winlen20表示.
如表2所示为PoWFQ方法在UJIIndoorLoc、MALL、WiFi-RSS这3个数据集上模拟上传300条数据记录时,滑动窗口大小分别为10、15、20对应的平均耗时. 可以看出,随着滑动窗口大小的增加,共识耗时大致呈现增长趋势,因为滑动窗口越大,须参考的历史数据数量越多,计算每个属性列的均值和方差耗时更多. 当滑动窗口为15时,在MALL和WiFi-RSS数据集上有非常微小的下降,这可能是因为在MALL和WiFi-RSS数据集上,PoWFQ计算均值和方差时的有效属性列数减少了;随着数据维度的增加,不管滑动窗口大小是多少,PoWFQ的共识耗时都在增加,在维度最高的UJIIndoorLoc数据集上的平均耗时分别达到
表 2 不同窗口大小下的平均共识耗时
Tab.2
| 数据集 | 平均耗时/ms | ||
| PoWFQ- winlen10 | PoWFQ- winlen15 | PoWFQ- winlen20 | |
| UJIIndoorLoc | |||
| WiFi-RSS | |||
| MALL | |||
如表3所示为滑动窗口大小为10、15、20时,PoWFQ筛选UJIIndoorLoc、MALL、WiFi-RSS这3个数据集后得到的新数据集对模型性能的影响. 其中,
表 3 不同窗口大小的PoWFQ对模型性能的影响
Tab.3
| 滑动窗口大小 | 数据集 | ||||
| PoWFQ-winlen10 | UJIIndoorLoc | ||||
| WiFi-RSS | |||||
| MALL | |||||
| PoWFQ-winlen15 | UJIIndoorLoc | ||||
| WiFi-RSS | |||||
| MALL | |||||
| PoWFQ-winlen20 | UJIIndoorLoc | ||||
| WiFi-RSS | |||||
| MALL |
如表4所示为滑动窗口大小为10、15、20时,PoWFQ筛选完UJIIndoorLoc、MALL、WiFi-RSS这3个数据集后数据集的轮廓系数. 可以看出,相比于滑动窗口大小为15、20时的轮廓系数,滑动窗口大小为10时,PoWFQ筛选3个数据集后得到的总体轮廓系数均达到了最大值,说明滑动窗口大小为10时,同一标签内的数据相似性更高,数据聚类效果更好,更有利于定位模型的训练.
表 4 不同窗口大小PoWFQ筛选数据集后轮廓系数的变化
Tab.4
| 数据集 | PoWFQ- winlen10 | PoWFQ- winlen15 | PoWFQ- winlen20 |
| UJIIndoorLoc | − | ||
| MALL | |||
| WiFi-RSS | − | − |
如表5所示为不同滑动窗口大小下,PoWFQ筛选完UJIIndoorLoc、MALL、WiFi-RSS这3个数据集后数据集记录条数的变化情况. 可以看出,对于MALL数据集与WiFi-RSS数据集而言,不同滑动窗口大小筛选掉的记录条数都约为
表 5 不同窗口大小PoWFQ筛选不同数据集后的条数变化
Tab.5
| 数据集 | UJIIndoorLoc | MALL | WiFi-RSS |
| 原始数据 | |||
| PoWFQ-winlen10 | |||
| PoWFQ-winlen15 | |||
| PoWFQ-winlen20 |
综合考虑共识耗时、模型训练精度与数据聚类效果3个方面,将滑动窗口大小设置为10时,PoWFQ算法能够获得更好的性能. 因此,以下所有实验均采用滑动窗口大小为10.
5.4.2. 出块效率的实验对比分析
UJIIndoorLoc数据集模拟的采集数据中有520维RSS与一个位置标签,MALL数据集模拟35维RSS与一个位置标签,WiFi-RSS数据集模拟27维RSS与一个位置标签,如表6所示为使用不同数据集上传相同的300个样本时各共识算法的平均出块速度对比. 其中,ts为平均耗时. 可以看出,由于须计算复杂的哈希值,PoW的出块速度速度慢且极不稳定,出块耗时远高于PoS、DPoS、PoD以及PoWFQ. PoS通过验证持有代币的权益来确定出块权再生成新的区块;DPoS通过选举一组受托人来验证交易并生成新的区块;PoD以验证池中一批数据的中位数为基准,将与基准偏差大的数据剔除. 因此,PoS、DPoS和PoD的出块耗时主要花费在出块权的计算上,不需要大量的计算资源. 而且,这3种共识算法在每一次共识过程中的计算任务都基本相似. 因此,它们的出块耗时基本都约为10 ms.
表 6 不同共识算法上传300条记录的平均耗时
Tab.6
| 数据集 | ts/ms | ||||
| PoW | PoS | DpoS | PoD | PoWFQ | |
| UJIIndoorLoc | |||||
| MALL | |||||
| WiFi-RSS | |||||
PoWFQ在考虑多维RSS信号特征分布的情况下,计算样本分布与真实分布的带权均方差,用户能感知到的AP点多(用户所持设备的性能会影响用户能感知到的AP点个数与信号强度),上传的数据中RSS向量维度便相应增加,计算复杂度便也随之增加. 在3个数据集中,UJIIndoorLoc因其总体维度高及每条记录所含的有效维度多,在模拟共识处理的300条记录中,耗时约为21 ms;MALL与WiFi-RSS维度数量相近,耗时约为20 ms. 与PoS、DPoS相比,PoWFQ在保证数据质量的同时,区块的平均出块耗时不超过20 ms,在可接受范围内,并且PoWFQ在保护用户身份隐私、抵御双花攻击的同时,还能控制RSS指纹数据质量. 如表7所示为PoWFQ与其他共识算法的比较.
表 7 不同共识算法功能对比
Tab.7
| 共识算法 | 数据隐私 | 双花攻击 | 数据质量 |
| Pod | √ | × | √ |
| Pow | × | √ | × |
| Pos | × | × | × |
| Dpos | × | × | × |
| PoWFQ | √ | √ | √ |
5.4.3. 模型性能的实验对比分析
由于PoW、PoS与DPoS的重点不是考虑RSS指纹的分布特性与数据质量,无论用户上传的数据是否合格,在PoW计算出合格的哈希值、PoS通过虚拟代币数量确定出块权、DPoS通过投票确定出块权后,这3种共识算法采集而来的数据与原始数据集一样. PoD认为一批数据中的中位数质量最佳,会将与中位数差值大于阈值
使用PoD共识算法与PoWFQ处理UJIIndoorLoc、WiFi-RSS、MALL这3个数据集,并将处理后的数据集用于训练机器学习模型,其性能如图4所示. 可以看出,在使用PoWFQ后,模型在UJIIndoorLoc、MALL、WiFi-RSS这3个数据集上分别在300、300、
图 4
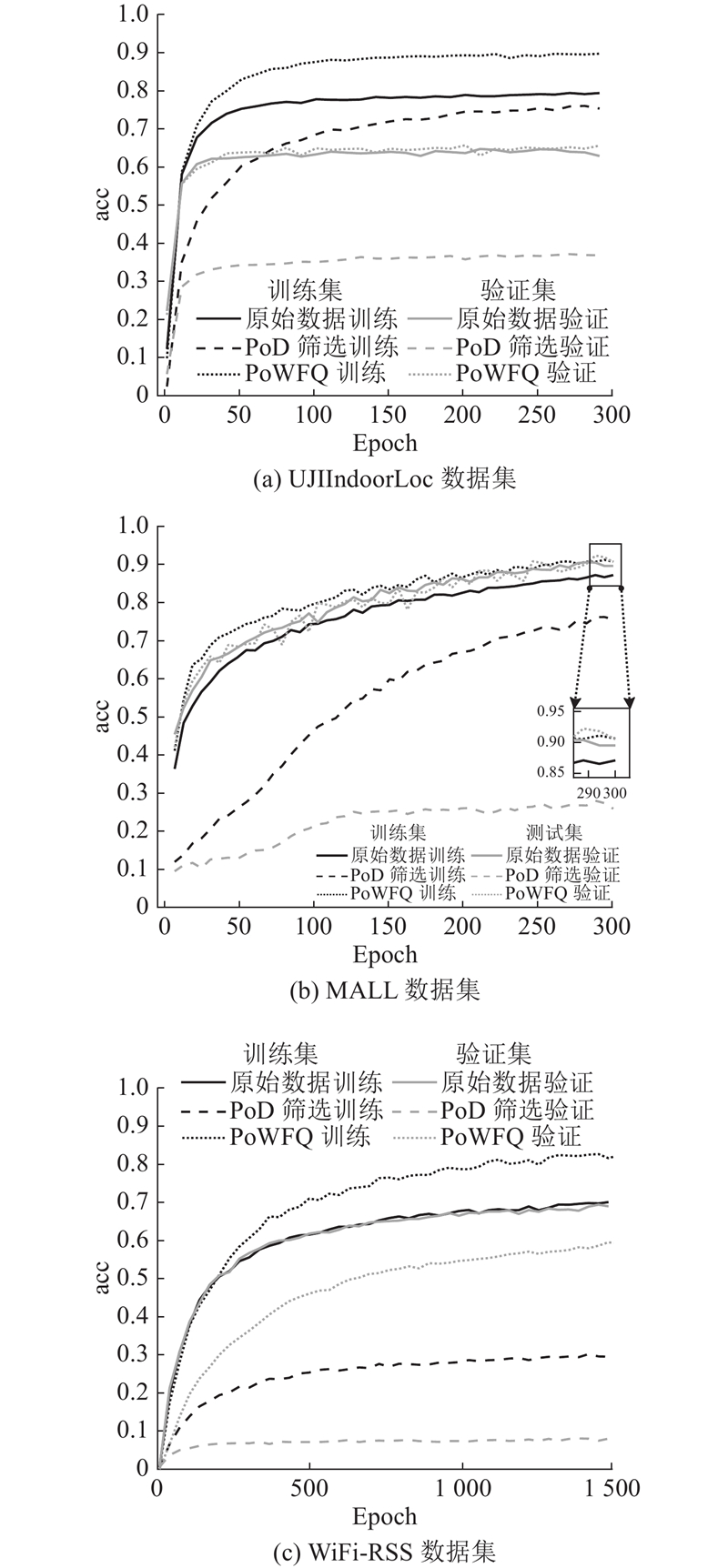
图 4 3个数据集上的模型训练和测试精度对比
Fig.4 Comparison of model training and testing accuracy on three datasets
如表8所示为3个数据集在使用PoWFQ筛选后模型性能的对比. UJIIndoorLoc与WiFi-RSS数据集中数据记录条数多且每条记录中可检测到的有效属性列数量有限,数据稀疏性比MALL数据集高,再加上UJIIndoorLoc与WiFi-RSS数据集记录条数是MALL数据集记录条数的2~3倍,使得PoWFQ能够剔除UJIIndoorLoc、WiFi-RSS数据集中更多的异常值数据记录. 相反,MALL数据集中记录条数更少,每条记录中可检测到的属性列条数基本在30列以上,而MALL数据集RSS信号的属性列总共为35列,数据的聚合程度本身就比UJIIndoorLoc与WiFi-RSS高,因此,PoWFQ方法能够识别的MALL中的异常数据更少,筛选前后的数据对模型性能的影响也比前2个数据集筛选前后对模型性能的影响要小. 值得注意的是,虽然PoWFQ筛选前后,模型的训练精度提升了近10个百分点,但是测试损失比共识处理前的测试损失要高出0.5~1.0倍. 结合图4与表8可以看出,PoD对无线信号的历史分布考虑不足,只对待验证数据进行中位数聚类,缺少对RSS信号时间层面变化规律的考虑. 在UJIIndoorLoc与WiFi-RSS数据集上,PoD的质量控制效果并不理想,与原始数据集相比,模型训练精度分别下降了约3和7个百分点,但在MALL数据集上的模型训练精度提升了约2个百分点,这可能是由于MALL数据集中数据的聚合程度本身较高,整体数据记录相似,而PoD的中位数滑动窗口算法筛选完该数据集后,相同标签内的数据特征更加稳定. 整体来看,PoWFQ算法通过考虑RSS信号特征分布对模型性能和数据质量控制有所帮助.
表 8 PoW、PoS、DpoS、PoD与PoWFQ对模型性能的影响
Tab.8
| 共识算法 | 数据集 | ||||
| PoW | UJIIndoorLoc | ||||
| WiFi-RSS | |||||
| MALL | |||||
| PoS | UJIIndoorLoc | ||||
| WiFi-RSS | |||||
| MALL | |||||
| DPoS | UJIIndoorLoc | ||||
| WiFi-RSS | |||||
| MALL | |||||
| PoD | UJIIndoorLoc | ||||
| WiFi-RSS | |||||
| MALL | |||||
| PoWFQ | UJIIndoorLoc | ||||
| WiFi-RSS | |||||
| MALL |
5.4.4. 采集数据质量分析
如表9所示为不同数据集筛选前后的轮廓系数. 可以看出,在使用PoD方法筛选过后,UJIIndoorLoc、MALL数据集总体轮廓系数下降了
表 9 不同数据集筛选前后的轮廓系数
Tab.9
| 数据集 | 原始数据 | PoWFQ筛选后 | PoD筛选后 |
| UJIIndoorLoc | |||
| MALL | |||
| WiFi-RSS |
5.4.5. 奖励报酬
MALL、WiFi-RSS数据集中未给出采集用户信息,因此本节实验仅在UJIIndoorLoc数据集上进行,如图5显示了UJIIndoorLoc数据集中18个用户的报酬因子RF,用各自的报酬因子乘以各自的采集消耗即为最终的采集报酬. 可以看出,多数用户的最终报酬为采集消耗的2倍,其他用户的采集报酬在采集消耗的1.5~1.8倍间不等. 除了数据质量外,UJIIndoorLoc的不同用户采集的数据记录条数也不同,对于提交了更多记录的用户,他们数据集的分布与完整数据集的分布更加接近,
图 5

图 5 UJIIndoorLoc数据集中用户的报酬因子
Fig.5 Reward factor of users in UJIIndoorLoc dataset
6. 结 语
针对移动众包下的无线RSS数据采集场景,考虑WiFi信号数据的分布特征,提出基于区块链的RSS数据质量控制算法PoWFQ,通过比较用户上传的数据与已有历史数据分布之间的差异程度来剔除异常值,使得众包数据聚合程度更高,这种轻量化的方法更容易在移动终端中实现. 在3个不同规模RSS指纹数据集上的实验表明,使用PoWFQ筛选过的数据使定位模型的训练精度分别提升了10、3和10个百分点. 而且,PoWFQ算法在这3个数据集上的出块时间均约为20 ms,在保护用户隐私、抵御双花攻击和控制数量质量的同时,获得了较快的出块速度. 在后续研究中,将考虑如何降低计算耗时,使PoWFQ更好地应用于实际海量RSS指纹采集场景.
参考文献
A noise robust kernel fuzzy clustering based on picture fuzzy sets and KL divergence measure for MRI image segmentation
[J].DOI:10.1007/s10489-022-04315-4 [本文引用: 1]
BDR-net: bhattacharyya distance-based distribution metric modeling for rotating object detection in remote sensing
[J].
边缘计算下指纹室内定位差分私有联邦学习模型
[J].DOI:10.7544/issn1000-1239.20210270 [本文引用: 1]
A differentially private federated learning model for fingerprinting indoor localization in edge computing
[J].DOI:10.7544/issn1000-1239.20210270 [本文引用: 1]
A differentially private indoor localization scheme with fusion of WiFi and bluetooth fingerprints in edge computing
[J].DOI:10.1007/s00521-021-06815-9 [本文引用: 1]
FSELM: fusion semi-supervised extreme learning machine for indoor localization with Wi-Fi and Bluetooth fingerprints
[J].DOI:10.1007/s00500-018-3171-4 [本文引用: 1]
A real-time fingerprint-based indoor positioning using deep learning and preceding states
[J].DOI:10.1016/j.eswa.2022.118889 [本文引用: 1]
Comparison of CNN applications for RSSI-based fingerprint indoor localization
[J].DOI:10.3390/electronics8090989 [本文引用: 1]
A survey of deep learning approaches for WiFi-based indoor positioning
[J].DOI:10.1080/24751839.2021.1975425
A survey and taxonomy of consensus protocols for blockchains
[J].DOI:10.1016/j.sysarc.2022.102503 [本文引用: 1]
A compute and wait in PoW (CW-PoW) consensus algorithm for preserving energy consumption
[J].DOI:10.3390/app11156750 [本文引用: 2]
BlockSense: towards trustworthy mobile crowdsensing via proof-of-data blockchain
[J].
CrowdBC: a blockchain-based decentralized framework for crowdsourcing
[J].DOI:10.1109/TPDS.2018.2881735 [本文引用: 2]
Blockchain-based reliable and privacy-aware crowdsourcing with truth and fairness assurance
[J].DOI:10.1109/JIOT.2021.3097950 [本文引用: 1]
Towards private, robust, and verifiable crowdsensing systems via public blockchains
[J].
Blockchain-based lightweight and privacy-preserving quality assurance framework in crowdsensing systems
[J].DOI:10.1109/JIOT.2023.3288349 [本文引用: 1]
CrowdHB: a decentralized location privacy-preserving crowdsensing system based on a hybrid blockchain network
[J].DOI:10.1109/JIOT.2021.3084937 [本文引用: 2]
Convolutional model with a time series feature based on RSSI analysis with the Markov transition field for enhancement of location recognition
[J].DOI:10.3390/s23073453 [本文引用: 2]
Toward a quality-aware online pricing mechanism for crowdsensed wireless fingerprints
[J].DOI:10.1109/TVT.2018.2805383 [本文引用: 2]
Extended hellwig’s method utilizing entropy-based weights and mahalanobis distance: applications in evaluating sustainable development in the education area
[J].DOI:10.3390/e26030197 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}