[2]
GANDHI A, ADHVARYU K, PORIA S, et al Multimodal sentiment analysis: a systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions
[J]. Information Fusion , 2023 , 91 : 424 - 444
DOI:10.1016/j.inffus.2022.09.025
[本文引用: 1]
[3]
CAO R, YE C, ZHOU H. Multimodal sentiment analysis with self-attention [C]// Proceedings of the Future Technologies Conference . [S. l. ]: Springer, 2021: 16-26.
[本文引用: 1]
[4]
BALTRUSAITIS T, AHUJA C, MORENCY L P Multimodal machine learning: a survey and taxonomy
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2018 , 41 (2 ): 423 - 443
[6]
HAN W, CHEN H, PORIA S. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis [EB/OL]. (2021-09-16)[2025-05-28]. https://arxiv.org/pdf/2109.00412.
[本文引用: 1]
[7]
HAZARIKA D, ZIMMERMANN R, PORIA S. Misa: modality-invariant and specific representations for multimodal sentiment analysis [C]// Proceedings of the 28th ACM International Conference on Multimedia . Seattle: ACM, 2020: 1122-1131.
[本文引用: 4]
[8]
TANG J, LIU D, JIN X, et al Bafn: bi-direction attention based fusion network for multimodal sentiment analysis
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2022 , 33 (4 ): 1966 - 1978
[本文引用: 1]
[9]
WU Y, LIN Z, ZHAO Y, et al. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis [C]// Findings of the Association for Computational Linguistics . [S. l.]: ACL, 2021: 4730-4738.
[本文引用: 1]
[11]
HAN W, CHEN H, GELBUKH A, et al. Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis [C]// Proceedings of the 2021 International Conference on Multimodal Interaction . Montréal: ACM, 2021: 6-15.
[本文引用: 4]
[12]
LI Z, GUO Q, PAN Y, et al Multi-level correlation mining framework with self-supervised label generation for multimodal sentiment analysis
[J]. Information Fusion , 2023 , 99 : 101891
DOI:10.1016/j.inffus.2023.101891
[本文引用: 1]
[13]
MORENCY L P, MIHALCEA R, DOSHI P. Towards multimodal sentiment analysis: harvesting opinions from the web [C]// Proceedings of the 13th International Conference on Multimodal Interfaces . Alicante: ACM, 2011: 169-176.
[本文引用: 1]
[14]
ZADEH A, LIANG P P, PORIA S, et al. Multi-attention recurrent network for human communication comprehension [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New Orleans: AAAI Press, 2018: 5642-5649.
[本文引用: 1]
[15]
PORIA S, CHATURVEDI I, CAMBRIA E, et al. Convolutional MKL based multimodal emotion recognition and sentiment analysis [C]//IEEE 16th International Conference on Data Mining . Barcelona: IEEE, 2016: 439-448.
[本文引用: 1]
[16]
ALAM F, RICCARDI G. Predicting personality traits using multimodal information [C]// Proceedings of the 2014 ACM Multimedia on Workshop on Computational Personality Recognition . Orlando: ACM, 2014: 15-18.
[本文引用: 1]
[17]
CAI G, XIA B. Convolutional neural networks for multimedia sentiment analysis [C]// Natural Language Processing and Chinese Computing: 4th CCF Conference . Nanchang: Springer, 2015: 159-167.
[本文引用: 1]
[18]
GKOUMAS D, LI Q, LIOMA C, et al What makes the difference? an empirical comparison of fusion strategies for multimodal language analysis
[J]. Information Fusion , 2021 , 66 : 184 - 197
DOI:10.1016/j.inffus.2020.09.005
[本文引用: 1]
[20]
TSAI Y H H, BAI S, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics . Florence: ACL, 2019: 6558-6569.
[本文引用: 5]
[21]
CHEN C, HONG H, GUO J, et al Inter-intra modal representation augmentation with trimodal collaborative disentanglement network for multimodal sentiment analysis
[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing , 2023 , 31 : 1476 - 1488
DOI:10.1109/TASLP.2023.3263801
[本文引用: 1]
[22]
YUAN Z, LI W, XU H, et al. Transformer-based feature reconstruction network for robust multimodal sentiment analysis [C]// Proceedings of the 29th ACM International Conference on Multimedia . Chengdu: ACM, 2021: 4400-4407.
[本文引用: 1]
[23]
MA L, YAO Y, LIANG T, et al. Multi-scale cooperative multimodal transformers for multimodal sentiment analysis in videos [EB/OL]. (2022-06-17)[2025-05-28]. https://arxiv.org/pdf/2206.07981.
[本文引用: 1]
[24]
YU W, XU H, YUAN Z, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S. l. ]: AAAI Press, 2021: 10790-10797.
[本文引用: 5]
[25]
WANG D, GUO X, TIAN Y, et al TETFN: a text enhanced transformer fusion network for multimodal sentiment analysis
[J]. Pattern Recognition , 2023 , 136 : 109259
DOI:10.1016/j.patcog.2022.109259
[本文引用: 5]
[26]
MELAS-KYRIAZI L. Do you even need attention? a stack of feed-forward layers does surprisingly well on imagenet [EB/OL]. (2021-05-06)[2025-05-28]. https://arxiv.org/pdf/2105.02723.
[本文引用: 1]
[27]
TOLSTIKHIN I O, HOULSBY N, KOLESNIKOV A, et al Mlp-mixer: an all-mlp architecture for vision
[J]. Advances in Neural Information Processing Systems , 2021 , 34 : 24261 - 24272
[本文引用: 1]
[28]
TOUVRON H, BOJANOWSKI P, CARON M, et al Resmlp: feedforward networks for image classification with data-efficient training
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 45 (4 ): 5314 - 5321
[本文引用: 1]
[29]
NIE Y, LI L, GAN Z, et al. Mlp architectures for vision-and-language modeling: an empirical study [EB/OL]. (2021-12-08)[2025-05-28]. https://arxiv.org/pdf/2112.04453.
[本文引用: 1]
[30]
LIN H, ZHANG P, LING J, et al PS-mixer: a polar-vector and strength-vector mixer model for multimodal sentiment analysis
[J]. Information Processing and Management , 2023 , 60 (2 ): 103229
DOI:10.1016/j.ipm.2022.103229
[本文引用: 4]
[31]
SUN H, WANG H, LIU J, et al. CubeMLP: an MLP-based model for multimodal sentiment analysis and depression estimation [C]// Proceedings of the 30th ACM International Conference on Multimedia . Lisboa: ACM, 2022: 3722-3729.
[本文引用: 4]
[32]
BAIRAVEL S, KRISHNAMURTHY M Novel OGBEE-based feature selection and feature-level fusion with MLP neural network for social media multimodal sentiment analysis
[J]. Soft Computing , 2020 , 24 (24 ): 18431 - 18445
DOI:10.1007/s00500-020-05049-6
[本文引用: 1]
[33]
KE P, JI H, LIU S, et al. SentiLARE: sentiment-aware language representation learning with linguistic knowledge [EB/OL]. (2020-09-24)[2025-05-28]. https://arxiv.org/pdf/1911.02493.
[本文引用: 1]
[34]
LIU Y, OTT M, GOYAL N, et al. Roberta: a robustly optimized bert pretraining approach [EB/OL]. (2019-07-26)[2025-05-28]. https://arxiv.org/pdf/1907.11692.
[本文引用: 1]
[35]
DEGOTTEX G, KANE J, DRUGMAN T, et al. COVAREP: a collaborative voice analysis repository for speech technologies [C]//IEEE International Conference on Acoustics, Speech and Signal Processing . Florence: IEEE, 2014: 960-964.
[本文引用: 1]
[36]
ZADEH A, ZELLERS R, PINCUS E, et al. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos [EB/OL]. (2016-08-11)[2025-05-28]. https://arxiv.org/pdf/1606.06259.
[本文引用: 1]
[37]
ZADEH A A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics . Melbourne: ACL, 2018: 2236-2246.
[本文引用: 1]
[38]
CHEONG J H, JOLLY E, XIE T, et al Py-feat: Python facial expression analysis toolbox
[J]. Affective Science , 2023 , 4 (4 ): 781 - 796
DOI:10.1007/s42761-023-00191-4
[本文引用: 1]
[39]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems . California: Curran Associates Inc , 2017: 5998-6008.
[本文引用: 1]
[40]
ZZADEH A, CHEN M, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis [EB/OL]. (2017-07-23)[2025-05-28]. https://arxiv.org/pdf/1707.07250.
[本文引用: 4]
[41]
LIU Z, SHEN Y, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors [EB/OL]. (2018-05-31)[2025-05-28]. https://arxiv.org/pdf/1806.00064.
[本文引用: 3]
[42]
ZADEH A, LIANG P P, MAZUMDER N, et al. Memory fusion network for multi-view sequential learning [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New Orleans: AAAI Press, 2018: 5634-5641.
[本文引用: 2]
[43]
RAHMAN W, HASAN M K, LEE S, et al. Integrating multimodal information in large pretrained Transformers [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [S. l.]: ACL, 2020: 2359-2369.
[本文引用: 3]
[44]
YANG B, SHAO B, WU L, et al Multimodal sentiment analysis with unidirectional modality translation
[J]. Neurocomputing , 2022 , 467 : 130 - 137
DOI:10.1016/j.neucom.2021.09.041
[本文引用: 3]
[45]
LEI Y, YANG D, LI M, et al. Text-oriented modality reinforcement network for multimodal sentiment analysis from unaligned multimodal sequences [C]// CAAI International Conference on Artificial Intelligence. Singapore: Springer, 2023: 189-200.
[本文引用: 3]
[46]
WANG Y, HE J, WANG D, et al Multimodal transformer with adaptive modality weighting for multimodal sentiment analysis
[J]. Neurocomputing , 2024 , 572 : 127181
DOI:10.1016/j.neucom.2023.127181
[本文引用: 3]
[47]
LIU W, CAO S, ZHANG S Multimodal consistency-specificity fusion based on information bottleneck for sentiment analysis
[J]. Journal of King Saud University-Computer and Information Sciences , 2024 , 36 (2 ): 101943
DOI:10.1016/j.jksuci.2024.101943
[本文引用: 3]
[48]
ZENG Y, LI Z, CHEN Z, et al A feature-based restoration dynamic interaction network for multimodal sentiment analysis
[J]. Engineering Applications of Artificial Intelligence , 2024 , 127 : 107335
DOI:10.1016/j.engappai.2023.107335
[本文引用: 3]
[49]
SHI H, PU Y, ZHAO Z, et al Co-space representation interaction network for multimodal sentiment analysis
[J]. Knowledge-Based Systems , 2024 , 283 : 111149
DOI:10.1016/j.knosys.2023.111149
[本文引用: 3]
Multimodal sentiment analysis based on fusion methods: a survey
1
2023
... 随着社交网络的迅猛发展,人们越来越乐于在快手、抖音、小红书等平台上发布表达个人观点的短视频,这些包含多模态信息的视频数据为多模态情感分析研究提供了良好的数据基础[1 ] . 多模态情感分析主要是利用文本、音频和视频等多模态数据,判断人们的情感倾向是积极、中性还是消极,在人机交互、商品推荐系统与市场预测等诸多领域得到广泛的应用[2 ] . ...
Multimodal sentiment analysis: a systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions
1
2023
... 随着社交网络的迅猛发展,人们越来越乐于在快手、抖音、小红书等平台上发布表达个人观点的短视频,这些包含多模态信息的视频数据为多模态情感分析研究提供了良好的数据基础[1 ] . 多模态情感分析主要是利用文本、音频和视频等多模态数据,判断人们的情感倾向是积极、中性还是消极,在人机交互、商品推荐系统与市场预测等诸多领域得到广泛的应用[2 ] . ...
1
... 如何实现多模态特征有效融合及提高单模态特征质量是多模态情感分析领域的主要挑战[3 -5 ] . 根据文本、音频和视频3种模态在融合过程中所占的比重,可以将融合方法划分为以下2类. 第1类方法采用三元对称方式在融合过程中等比例分配3种模态所占的比重,如MMIM[6 ] 、MISA[7 ] 、BAFN[8 ] 等. 上述方法在多模态情感分析任务中均取得良好的效果,然而不同模态情感信息的分布不均衡,与音频、视频模态相比,文本模态含有更丰富的情感信息. 在多模态情感分析任务中,若不考虑不同模态的相对重要性,则会影响多模态情感分析任务的准确性. 第2类方法通过增大文本模态的比重,突出文本模态在多模态情感分析任务中的相对重要性,如TCSP[9 ] 、AOBERT[10 ] 、BBFN[11 ] 等. ...
Multimodal machine learning: a survey and taxonomy
0
2018
Deep multimodal representation learning: a survey
2
2019
... 如何实现多模态特征有效融合及提高单模态特征质量是多模态情感分析领域的主要挑战[3 -5 ] . 根据文本、音频和视频3种模态在融合过程中所占的比重,可以将融合方法划分为以下2类. 第1类方法采用三元对称方式在融合过程中等比例分配3种模态所占的比重,如MMIM[6 ] 、MISA[7 ] 、BAFN[8 ] 等. 上述方法在多模态情感分析任务中均取得良好的效果,然而不同模态情感信息的分布不均衡,与音频、视频模态相比,文本模态含有更丰富的情感信息. 在多模态情感分析任务中,若不考虑不同模态的相对重要性,则会影响多模态情感分析任务的准确性. 第2类方法通过增大文本模态的比重,突出文本模态在多模态情感分析任务中的相对重要性,如TCSP[9 ] 、AOBERT[10 ] 、BBFN[11 ] 等. ...
... Transformer[19 ] 作为当前广泛采用的深度学习模型架构,在诸多任务中都取得了优异表现,被广泛应用于计算机视觉、自然语言处理、语音处理等领域. 近年来,很多研究者采用Transformer进行多模态情感分析任务,如MulT[20 ] 、TCDN[21 ] 、TFR-Net[22 ] 、MCMulT[23 ] 等. 上述方法采用Transformer架构能够有效地实现文本、音频和视频模态特征之间的交互,学习不同模态特征之间的一致性信息,但是该类方法没有考虑单模态特征自身的特性对多模态情感分析的影响. 多模态表征学习的主要目标是学习不同模态特征之间的一致性信息及每个模态各自特征的差异性,有助于提高多模态情感分析的准确性[5 ] . Yu等[24 -25 ] 提出基于多任务学习的多模态情感分析方法,如Self-MM[24 ] 、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
1
... 如何实现多模态特征有效融合及提高单模态特征质量是多模态情感分析领域的主要挑战[3 -5 ] . 根据文本、音频和视频3种模态在融合过程中所占的比重,可以将融合方法划分为以下2类. 第1类方法采用三元对称方式在融合过程中等比例分配3种模态所占的比重,如MMIM[6 ] 、MISA[7 ] 、BAFN[8 ] 等. 上述方法在多模态情感分析任务中均取得良好的效果,然而不同模态情感信息的分布不均衡,与音频、视频模态相比,文本模态含有更丰富的情感信息. 在多模态情感分析任务中,若不考虑不同模态的相对重要性,则会影响多模态情感分析任务的准确性. 第2类方法通过增大文本模态的比重,突出文本模态在多模态情感分析任务中的相对重要性,如TCSP[9 ] 、AOBERT[10 ] 、BBFN[11 ] 等. ...
4
... 如何实现多模态特征有效融合及提高单模态特征质量是多模态情感分析领域的主要挑战[3 -5 ] . 根据文本、音频和视频3种模态在融合过程中所占的比重,可以将融合方法划分为以下2类. 第1类方法采用三元对称方式在融合过程中等比例分配3种模态所占的比重,如MMIM[6 ] 、MISA[7 ] 、BAFN[8 ] 等. 上述方法在多模态情感分析任务中均取得良好的效果,然而不同模态情感信息的分布不均衡,与音频、视频模态相比,文本模态含有更丰富的情感信息. 在多模态情感分析任务中,若不考虑不同模态的相对重要性,则会影响多模态情感分析任务的准确性. 第2类方法通过增大文本模态的比重,突出文本模态在多模态情感分析任务中的相对重要性,如TCSP[9 ] 、AOBERT[10 ] 、BBFN[11 ] 等. ...
... MISA[7 ] . 将模态投影到2个不同子空间. 一个子空间用于学习模态之间的共性,减小模态之间的差距;另一个子空间学习每个模态各自的特征. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
Bafn: bi-direction attention based fusion network for multimodal sentiment analysis
1
2022
... 如何实现多模态特征有效融合及提高单模态特征质量是多模态情感分析领域的主要挑战[3 -5 ] . 根据文本、音频和视频3种模态在融合过程中所占的比重,可以将融合方法划分为以下2类. 第1类方法采用三元对称方式在融合过程中等比例分配3种模态所占的比重,如MMIM[6 ] 、MISA[7 ] 、BAFN[8 ] 等. 上述方法在多模态情感分析任务中均取得良好的效果,然而不同模态情感信息的分布不均衡,与音频、视频模态相比,文本模态含有更丰富的情感信息. 在多模态情感分析任务中,若不考虑不同模态的相对重要性,则会影响多模态情感分析任务的准确性. 第2类方法通过增大文本模态的比重,突出文本模态在多模态情感分析任务中的相对重要性,如TCSP[9 ] 、AOBERT[10 ] 、BBFN[11 ] 等. ...
1
... 如何实现多模态特征有效融合及提高单模态特征质量是多模态情感分析领域的主要挑战[3 -5 ] . 根据文本、音频和视频3种模态在融合过程中所占的比重,可以将融合方法划分为以下2类. 第1类方法采用三元对称方式在融合过程中等比例分配3种模态所占的比重,如MMIM[6 ] 、MISA[7 ] 、BAFN[8 ] 等. 上述方法在多模态情感分析任务中均取得良好的效果,然而不同模态情感信息的分布不均衡,与音频、视频模态相比,文本模态含有更丰富的情感信息. 在多模态情感分析任务中,若不考虑不同模态的相对重要性,则会影响多模态情感分析任务的准确性. 第2类方法通过增大文本模态的比重,突出文本模态在多模态情感分析任务中的相对重要性,如TCSP[9 ] 、AOBERT[10 ] 、BBFN[11 ] 等. ...
AOBERT: all-modalities-in-one BERT for multimodal sentiment analysis
4
2023
... 如何实现多模态特征有效融合及提高单模态特征质量是多模态情感分析领域的主要挑战[3 -5 ] . 根据文本、音频和视频3种模态在融合过程中所占的比重,可以将融合方法划分为以下2类. 第1类方法采用三元对称方式在融合过程中等比例分配3种模态所占的比重,如MMIM[6 ] 、MISA[7 ] 、BAFN[8 ] 等. 上述方法在多模态情感分析任务中均取得良好的效果,然而不同模态情感信息的分布不均衡,与音频、视频模态相比,文本模态含有更丰富的情感信息. 在多模态情感分析任务中,若不考虑不同模态的相对重要性,则会影响多模态情感分析任务的准确性. 第2类方法通过增大文本模态的比重,突出文本模态在多模态情感分析任务中的相对重要性,如TCSP[9 ] 、AOBERT[10 ] 、BBFN[11 ] 等. ...
... AOBERT[10 ] . 设计Single-Stream Transformer方法,解决传统模态融合过程中模态特性难以保持的问题. 通过多模态掩码建模(multimodal masked language modeling,MMLM)和对齐预测(alignment prediction,AP)2个预训练任务,学习不同模态之间的依赖关系. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
4
... 如何实现多模态特征有效融合及提高单模态特征质量是多模态情感分析领域的主要挑战[3 -5 ] . 根据文本、音频和视频3种模态在融合过程中所占的比重,可以将融合方法划分为以下2类. 第1类方法采用三元对称方式在融合过程中等比例分配3种模态所占的比重,如MMIM[6 ] 、MISA[7 ] 、BAFN[8 ] 等. 上述方法在多模态情感分析任务中均取得良好的效果,然而不同模态情感信息的分布不均衡,与音频、视频模态相比,文本模态含有更丰富的情感信息. 在多模态情感分析任务中,若不考虑不同模态的相对重要性,则会影响多模态情感分析任务的准确性. 第2类方法通过增大文本模态的比重,突出文本模态在多模态情感分析任务中的相对重要性,如TCSP[9 ] 、AOBERT[10 ] 、BBFN[11 ] 等. ...
... BBFN[11 ] . 因为不同模态的情感信息分布不均衡,采用文本-音频、文本-视频模态对作为输入,实现模态之间情感信息的互补,避免多模态融合出现信息的冗余. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
Multi-level correlation mining framework with self-supervised label generation for multimodal sentiment analysis
1
2023
... 多模态情感分析是自然语言处理中的一项重要任务,通过从文本、音频和视频3种模态中提取情感信息,判断人的情感极性. 多模态情感分析主要分为特征提取、特征融合、情感预测3个阶段. 其中,多模态特征融合是多模态情感分析任务的关键. 当前,多模态特征融合方法主要包括早期融合方法、晚期融合方法、基于Transformer的融合方法、基于多任务学习的融合方法等[12 ] . ...
1
... 早期融合方法是指将从文本、音频和视频模态提取的特征融合为1个多模态特征,将多模态特征输入到分类模型中进行情感极性预测,如Tri-Modal HMM[13 ] 、MARN[14 ] 、MKL[15 ] 等. 早期融合能够更快地实现文本、音频和视频模态特征的融合,从而更快地进行多模态情感预测,但是早期融合直接将3种模态特征融合为多模态特征,忽略不同模态特征之间的巨大差异,可能会增强多模态特征的信息冗余度,影响多模态情感分析的准确性. 晚期融合的关键在于对文本、音频及视频模态特征分别进行独立分类器训练,将3个分类结果融合为1个决策向量,进行多模态情感预测,如Ref[16 ] 、Multi-CNN[17 ] 、LF-LSTM[18 ] 等. 晚期融合使得每个模态都能选用最优的分类器,从而更有效地对单模态特征进行处理和分类,但是在训练过程中无法使不同模态之间进行有效交互,影响情感预测的效果. ...
1
... 早期融合方法是指将从文本、音频和视频模态提取的特征融合为1个多模态特征,将多模态特征输入到分类模型中进行情感极性预测,如Tri-Modal HMM[13 ] 、MARN[14 ] 、MKL[15 ] 等. 早期融合能够更快地实现文本、音频和视频模态特征的融合,从而更快地进行多模态情感预测,但是早期融合直接将3种模态特征融合为多模态特征,忽略不同模态特征之间的巨大差异,可能会增强多模态特征的信息冗余度,影响多模态情感分析的准确性. 晚期融合的关键在于对文本、音频及视频模态特征分别进行独立分类器训练,将3个分类结果融合为1个决策向量,进行多模态情感预测,如Ref[16 ] 、Multi-CNN[17 ] 、LF-LSTM[18 ] 等. 晚期融合使得每个模态都能选用最优的分类器,从而更有效地对单模态特征进行处理和分类,但是在训练过程中无法使不同模态之间进行有效交互,影响情感预测的效果. ...
1
... 早期融合方法是指将从文本、音频和视频模态提取的特征融合为1个多模态特征,将多模态特征输入到分类模型中进行情感极性预测,如Tri-Modal HMM[13 ] 、MARN[14 ] 、MKL[15 ] 等. 早期融合能够更快地实现文本、音频和视频模态特征的融合,从而更快地进行多模态情感预测,但是早期融合直接将3种模态特征融合为多模态特征,忽略不同模态特征之间的巨大差异,可能会增强多模态特征的信息冗余度,影响多模态情感分析的准确性. 晚期融合的关键在于对文本、音频及视频模态特征分别进行独立分类器训练,将3个分类结果融合为1个决策向量,进行多模态情感预测,如Ref[16 ] 、Multi-CNN[17 ] 、LF-LSTM[18 ] 等. 晚期融合使得每个模态都能选用最优的分类器,从而更有效地对单模态特征进行处理和分类,但是在训练过程中无法使不同模态之间进行有效交互,影响情感预测的效果. ...
1
... 早期融合方法是指将从文本、音频和视频模态提取的特征融合为1个多模态特征,将多模态特征输入到分类模型中进行情感极性预测,如Tri-Modal HMM[13 ] 、MARN[14 ] 、MKL[15 ] 等. 早期融合能够更快地实现文本、音频和视频模态特征的融合,从而更快地进行多模态情感预测,但是早期融合直接将3种模态特征融合为多模态特征,忽略不同模态特征之间的巨大差异,可能会增强多模态特征的信息冗余度,影响多模态情感分析的准确性. 晚期融合的关键在于对文本、音频及视频模态特征分别进行独立分类器训练,将3个分类结果融合为1个决策向量,进行多模态情感预测,如Ref[16 ] 、Multi-CNN[17 ] 、LF-LSTM[18 ] 等. 晚期融合使得每个模态都能选用最优的分类器,从而更有效地对单模态特征进行处理和分类,但是在训练过程中无法使不同模态之间进行有效交互,影响情感预测的效果. ...
1
... 早期融合方法是指将从文本、音频和视频模态提取的特征融合为1个多模态特征,将多模态特征输入到分类模型中进行情感极性预测,如Tri-Modal HMM[13 ] 、MARN[14 ] 、MKL[15 ] 等. 早期融合能够更快地实现文本、音频和视频模态特征的融合,从而更快地进行多模态情感预测,但是早期融合直接将3种模态特征融合为多模态特征,忽略不同模态特征之间的巨大差异,可能会增强多模态特征的信息冗余度,影响多模态情感分析的准确性. 晚期融合的关键在于对文本、音频及视频模态特征分别进行独立分类器训练,将3个分类结果融合为1个决策向量,进行多模态情感预测,如Ref[16 ] 、Multi-CNN[17 ] 、LF-LSTM[18 ] 等. 晚期融合使得每个模态都能选用最优的分类器,从而更有效地对单模态特征进行处理和分类,但是在训练过程中无法使不同模态之间进行有效交互,影响情感预测的效果. ...
What makes the difference? an empirical comparison of fusion strategies for multimodal language analysis
1
2021
... 早期融合方法是指将从文本、音频和视频模态提取的特征融合为1个多模态特征,将多模态特征输入到分类模型中进行情感极性预测,如Tri-Modal HMM[13 ] 、MARN[14 ] 、MKL[15 ] 等. 早期融合能够更快地实现文本、音频和视频模态特征的融合,从而更快地进行多模态情感预测,但是早期融合直接将3种模态特征融合为多模态特征,忽略不同模态特征之间的巨大差异,可能会增强多模态特征的信息冗余度,影响多模态情感分析的准确性. 晚期融合的关键在于对文本、音频及视频模态特征分别进行独立分类器训练,将3个分类结果融合为1个决策向量,进行多模态情感预测,如Ref[16 ] 、Multi-CNN[17 ] 、LF-LSTM[18 ] 等. 晚期融合使得每个模态都能选用最优的分类器,从而更有效地对单模态特征进行处理和分类,但是在训练过程中无法使不同模态之间进行有效交互,影响情感预测的效果. ...
A survey of transformers
1
2022
... Transformer[19 ] 作为当前广泛采用的深度学习模型架构,在诸多任务中都取得了优异表现,被广泛应用于计算机视觉、自然语言处理、语音处理等领域. 近年来,很多研究者采用Transformer进行多模态情感分析任务,如MulT[20 ] 、TCDN[21 ] 、TFR-Net[22 ] 、MCMulT[23 ] 等. 上述方法采用Transformer架构能够有效地实现文本、音频和视频模态特征之间的交互,学习不同模态特征之间的一致性信息,但是该类方法没有考虑单模态特征自身的特性对多模态情感分析的影响. 多模态表征学习的主要目标是学习不同模态特征之间的一致性信息及每个模态各自特征的差异性,有助于提高多模态情感分析的准确性[5 ] . Yu等[24 -25 ] 提出基于多任务学习的多模态情感分析方法,如Self-MM[24 ] 、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
5
... Transformer[19 ] 作为当前广泛采用的深度学习模型架构,在诸多任务中都取得了优异表现,被广泛应用于计算机视觉、自然语言处理、语音处理等领域. 近年来,很多研究者采用Transformer进行多模态情感分析任务,如MulT[20 ] 、TCDN[21 ] 、TFR-Net[22 ] 、MCMulT[23 ] 等. 上述方法采用Transformer架构能够有效地实现文本、音频和视频模态特征之间的交互,学习不同模态特征之间的一致性信息,但是该类方法没有考虑单模态特征自身的特性对多模态情感分析的影响. 多模态表征学习的主要目标是学习不同模态特征之间的一致性信息及每个模态各自特征的差异性,有助于提高多模态情感分析的准确性[5 ] . Yu等[24 -25 ] 提出基于多任务学习的多模态情感分析方法,如Self-MM[24 ] 、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
... MulT[20 ] 采用双向跨模态注意力机制,实现不同时间步模态序列之间的交互. ...
... 在实验中,采用5种评价指标,评估所提模型的效果. 平均绝对误差(MAE)用于计算情感预测值和真实值之间的误差,MAE越小表示模型效果越好. 七分类准确率A 7 为预测值与相应的真实值落在相同的[−3,+3] 7个区间的比值. 二分类准确率A 2 有以下2种计算方式. 一种是A 2 (non-negative/negative)[40 ] ,该指标在计算情感预测值时将标签值为零的中性情感数据归入非消极分类中. 另一种是A 2 (positive/negative)[20 ] ,该指标在计算情感预测值时排除了标签值为零的中性情感数据. 皮尔逊相关系数(corr)用于衡量预测值和真实标签之间的相关性,F 1 分数(F1-score)用来衡量模型的精确度. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
Inter-intra modal representation augmentation with trimodal collaborative disentanglement network for multimodal sentiment analysis
1
2023
... Transformer[19 ] 作为当前广泛采用的深度学习模型架构,在诸多任务中都取得了优异表现,被广泛应用于计算机视觉、自然语言处理、语音处理等领域. 近年来,很多研究者采用Transformer进行多模态情感分析任务,如MulT[20 ] 、TCDN[21 ] 、TFR-Net[22 ] 、MCMulT[23 ] 等. 上述方法采用Transformer架构能够有效地实现文本、音频和视频模态特征之间的交互,学习不同模态特征之间的一致性信息,但是该类方法没有考虑单模态特征自身的特性对多模态情感分析的影响. 多模态表征学习的主要目标是学习不同模态特征之间的一致性信息及每个模态各自特征的差异性,有助于提高多模态情感分析的准确性[5 ] . Yu等[24 -25 ] 提出基于多任务学习的多模态情感分析方法,如Self-MM[24 ] 、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
1
... Transformer[19 ] 作为当前广泛采用的深度学习模型架构,在诸多任务中都取得了优异表现,被广泛应用于计算机视觉、自然语言处理、语音处理等领域. 近年来,很多研究者采用Transformer进行多模态情感分析任务,如MulT[20 ] 、TCDN[21 ] 、TFR-Net[22 ] 、MCMulT[23 ] 等. 上述方法采用Transformer架构能够有效地实现文本、音频和视频模态特征之间的交互,学习不同模态特征之间的一致性信息,但是该类方法没有考虑单模态特征自身的特性对多模态情感分析的影响. 多模态表征学习的主要目标是学习不同模态特征之间的一致性信息及每个模态各自特征的差异性,有助于提高多模态情感分析的准确性[5 ] . Yu等[24 -25 ] 提出基于多任务学习的多模态情感分析方法,如Self-MM[24 ] 、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
1
... Transformer[19 ] 作为当前广泛采用的深度学习模型架构,在诸多任务中都取得了优异表现,被广泛应用于计算机视觉、自然语言处理、语音处理等领域. 近年来,很多研究者采用Transformer进行多模态情感分析任务,如MulT[20 ] 、TCDN[21 ] 、TFR-Net[22 ] 、MCMulT[23 ] 等. 上述方法采用Transformer架构能够有效地实现文本、音频和视频模态特征之间的交互,学习不同模态特征之间的一致性信息,但是该类方法没有考虑单模态特征自身的特性对多模态情感分析的影响. 多模态表征学习的主要目标是学习不同模态特征之间的一致性信息及每个模态各自特征的差异性,有助于提高多模态情感分析的准确性[5 ] . Yu等[24 -25 ] 提出基于多任务学习的多模态情感分析方法,如Self-MM[24 ] 、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
5
... Transformer[19 ] 作为当前广泛采用的深度学习模型架构,在诸多任务中都取得了优异表现,被广泛应用于计算机视觉、自然语言处理、语音处理等领域. 近年来,很多研究者采用Transformer进行多模态情感分析任务,如MulT[20 ] 、TCDN[21 ] 、TFR-Net[22 ] 、MCMulT[23 ] 等. 上述方法采用Transformer架构能够有效地实现文本、音频和视频模态特征之间的交互,学习不同模态特征之间的一致性信息,但是该类方法没有考虑单模态特征自身的特性对多模态情感分析的影响. 多模态表征学习的主要目标是学习不同模态特征之间的一致性信息及每个模态各自特征的差异性,有助于提高多模态情感分析的准确性[5 ] . Yu等[24 -25 ] 提出基于多任务学习的多模态情感分析方法,如Self-MM[24 ] 、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
... [24 ]、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
... Self-MM[24 ] . 提出基于Transformer的单模态特征融合架构,提出基于自监督策略的单模态标签生成模块来生成单模态情感标签. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
TETFN: a text enhanced transformer fusion network for multimodal sentiment analysis
5
2023
... Transformer[19 ] 作为当前广泛采用的深度学习模型架构,在诸多任务中都取得了优异表现,被广泛应用于计算机视觉、自然语言处理、语音处理等领域. 近年来,很多研究者采用Transformer进行多模态情感分析任务,如MulT[20 ] 、TCDN[21 ] 、TFR-Net[22 ] 、MCMulT[23 ] 等. 上述方法采用Transformer架构能够有效地实现文本、音频和视频模态特征之间的交互,学习不同模态特征之间的一致性信息,但是该类方法没有考虑单模态特征自身的特性对多模态情感分析的影响. 多模态表征学习的主要目标是学习不同模态特征之间的一致性信息及每个模态各自特征的差异性,有助于提高多模态情感分析的准确性[5 ] . Yu等[24 -25 ] 提出基于多任务学习的多模态情感分析方法,如Self-MM[24 ] 、TETFN[25 ] . 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
... [25 ]. 利用上述方法,既学习了不同模态之间的一致性信息,又学习了每个模态自身的差异性信息,从而提高了多模态表征的质量. ...
... TETFN[25 ] . 提出文本增强的Transformer融合网络,在多模态融合过程中增大文本模态的权重,减少冗余信息,提高多模态情感分析的准确性. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
1
... 近期,研究者们开始尝试使用多层感知器(multilayer perceptron,MLP)以替代注意力机制,开展图像分类的任务. Melas-Kyriazi[26 ] 提出使用MLP来取代注意力机制,进行图像分类. Tolstikhin等[27 ] 提出MLP-mixer框架,通过实验发现,在图像分类任务中,基于MLP的模型性能不低于传统的基于注意力机制和卷积神经网络架构的模型性能. Touvron等[28 ] 提出ResMLP的图像分类方法. 该方法包含2个MLP模块,一个负责处理Channel,另一个负责处理Token. 此后,Nie等[29 ] 将MLP引入多模态特征融合领域,Lin等[30 ] 设计基于MLP的PS-Mixer框架,用于多模态情感分析. Sun等[31 ] 提出基于MLP的CubeMLP多模态情感分析架构,CubeMLP由3个独立的MLP模块构成,具备在序列、模态和通道3个轴线上融合特征的能力,使得模型能够有效地传输和共享不同模态的信息,从而精准地提取含有情感信息的特征. Bairavel等[32 ] 提出运用对抗草蜂优化算法来进行特征提取的基于多层感知器的多模态情感分析方法,该方法能够从文本、音频和视频3种模态中提取质量更优的特征. ...
Mlp-mixer: an all-mlp architecture for vision
1
2021
... 近期,研究者们开始尝试使用多层感知器(multilayer perceptron,MLP)以替代注意力机制,开展图像分类的任务. Melas-Kyriazi[26 ] 提出使用MLP来取代注意力机制,进行图像分类. Tolstikhin等[27 ] 提出MLP-mixer框架,通过实验发现,在图像分类任务中,基于MLP的模型性能不低于传统的基于注意力机制和卷积神经网络架构的模型性能. Touvron等[28 ] 提出ResMLP的图像分类方法. 该方法包含2个MLP模块,一个负责处理Channel,另一个负责处理Token. 此后,Nie等[29 ] 将MLP引入多模态特征融合领域,Lin等[30 ] 设计基于MLP的PS-Mixer框架,用于多模态情感分析. Sun等[31 ] 提出基于MLP的CubeMLP多模态情感分析架构,CubeMLP由3个独立的MLP模块构成,具备在序列、模态和通道3个轴线上融合特征的能力,使得模型能够有效地传输和共享不同模态的信息,从而精准地提取含有情感信息的特征. Bairavel等[32 ] 提出运用对抗草蜂优化算法来进行特征提取的基于多层感知器的多模态情感分析方法,该方法能够从文本、音频和视频3种模态中提取质量更优的特征. ...
Resmlp: feedforward networks for image classification with data-efficient training
1
2022
... 近期,研究者们开始尝试使用多层感知器(multilayer perceptron,MLP)以替代注意力机制,开展图像分类的任务. Melas-Kyriazi[26 ] 提出使用MLP来取代注意力机制,进行图像分类. Tolstikhin等[27 ] 提出MLP-mixer框架,通过实验发现,在图像分类任务中,基于MLP的模型性能不低于传统的基于注意力机制和卷积神经网络架构的模型性能. Touvron等[28 ] 提出ResMLP的图像分类方法. 该方法包含2个MLP模块,一个负责处理Channel,另一个负责处理Token. 此后,Nie等[29 ] 将MLP引入多模态特征融合领域,Lin等[30 ] 设计基于MLP的PS-Mixer框架,用于多模态情感分析. Sun等[31 ] 提出基于MLP的CubeMLP多模态情感分析架构,CubeMLP由3个独立的MLP模块构成,具备在序列、模态和通道3个轴线上融合特征的能力,使得模型能够有效地传输和共享不同模态的信息,从而精准地提取含有情感信息的特征. Bairavel等[32 ] 提出运用对抗草蜂优化算法来进行特征提取的基于多层感知器的多模态情感分析方法,该方法能够从文本、音频和视频3种模态中提取质量更优的特征. ...
1
... 近期,研究者们开始尝试使用多层感知器(multilayer perceptron,MLP)以替代注意力机制,开展图像分类的任务. Melas-Kyriazi[26 ] 提出使用MLP来取代注意力机制,进行图像分类. Tolstikhin等[27 ] 提出MLP-mixer框架,通过实验发现,在图像分类任务中,基于MLP的模型性能不低于传统的基于注意力机制和卷积神经网络架构的模型性能. Touvron等[28 ] 提出ResMLP的图像分类方法. 该方法包含2个MLP模块,一个负责处理Channel,另一个负责处理Token. 此后,Nie等[29 ] 将MLP引入多模态特征融合领域,Lin等[30 ] 设计基于MLP的PS-Mixer框架,用于多模态情感分析. Sun等[31 ] 提出基于MLP的CubeMLP多模态情感分析架构,CubeMLP由3个独立的MLP模块构成,具备在序列、模态和通道3个轴线上融合特征的能力,使得模型能够有效地传输和共享不同模态的信息,从而精准地提取含有情感信息的特征. Bairavel等[32 ] 提出运用对抗草蜂优化算法来进行特征提取的基于多层感知器的多模态情感分析方法,该方法能够从文本、音频和视频3种模态中提取质量更优的特征. ...
PS-mixer: a polar-vector and strength-vector mixer model for multimodal sentiment analysis
4
2023
... 近期,研究者们开始尝试使用多层感知器(multilayer perceptron,MLP)以替代注意力机制,开展图像分类的任务. Melas-Kyriazi[26 ] 提出使用MLP来取代注意力机制,进行图像分类. Tolstikhin等[27 ] 提出MLP-mixer框架,通过实验发现,在图像分类任务中,基于MLP的模型性能不低于传统的基于注意力机制和卷积神经网络架构的模型性能. Touvron等[28 ] 提出ResMLP的图像分类方法. 该方法包含2个MLP模块,一个负责处理Channel,另一个负责处理Token. 此后,Nie等[29 ] 将MLP引入多模态特征融合领域,Lin等[30 ] 设计基于MLP的PS-Mixer框架,用于多模态情感分析. Sun等[31 ] 提出基于MLP的CubeMLP多模态情感分析架构,CubeMLP由3个独立的MLP模块构成,具备在序列、模态和通道3个轴线上融合特征的能力,使得模型能够有效地传输和共享不同模态的信息,从而精准地提取含有情感信息的特征. Bairavel等[32 ] 提出运用对抗草蜂优化算法来进行特征提取的基于多层感知器的多模态情感分析方法,该方法能够从文本、音频和视频3种模态中提取质量更优的特征. ...
... PS-Mixer[30 ] 是基于MLP的模型. 通过设计情感极性向量来预测情感的极性,通过强度向量来判断情感强度. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
4
... 近期,研究者们开始尝试使用多层感知器(multilayer perceptron,MLP)以替代注意力机制,开展图像分类的任务. Melas-Kyriazi[26 ] 提出使用MLP来取代注意力机制,进行图像分类. Tolstikhin等[27 ] 提出MLP-mixer框架,通过实验发现,在图像分类任务中,基于MLP的模型性能不低于传统的基于注意力机制和卷积神经网络架构的模型性能. Touvron等[28 ] 提出ResMLP的图像分类方法. 该方法包含2个MLP模块,一个负责处理Channel,另一个负责处理Token. 此后,Nie等[29 ] 将MLP引入多模态特征融合领域,Lin等[30 ] 设计基于MLP的PS-Mixer框架,用于多模态情感分析. Sun等[31 ] 提出基于MLP的CubeMLP多模态情感分析架构,CubeMLP由3个独立的MLP模块构成,具备在序列、模态和通道3个轴线上融合特征的能力,使得模型能够有效地传输和共享不同模态的信息,从而精准地提取含有情感信息的特征. Bairavel等[32 ] 提出运用对抗草蜂优化算法来进行特征提取的基于多层感知器的多模态情感分析方法,该方法能够从文本、音频和视频3种模态中提取质量更优的特征. ...
... CubeMLP[31 ] 由3个独立的MLP模块组成,将所有模态特征作为输入,在序列、模态、通道3个轴线上进行特征融合. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
Novel OGBEE-based feature selection and feature-level fusion with MLP neural network for social media multimodal sentiment analysis
1
2020
... 近期,研究者们开始尝试使用多层感知器(multilayer perceptron,MLP)以替代注意力机制,开展图像分类的任务. Melas-Kyriazi[26 ] 提出使用MLP来取代注意力机制,进行图像分类. Tolstikhin等[27 ] 提出MLP-mixer框架,通过实验发现,在图像分类任务中,基于MLP的模型性能不低于传统的基于注意力机制和卷积神经网络架构的模型性能. Touvron等[28 ] 提出ResMLP的图像分类方法. 该方法包含2个MLP模块,一个负责处理Channel,另一个负责处理Token. 此后,Nie等[29 ] 将MLP引入多模态特征融合领域,Lin等[30 ] 设计基于MLP的PS-Mixer框架,用于多模态情感分析. Sun等[31 ] 提出基于MLP的CubeMLP多模态情感分析架构,CubeMLP由3个独立的MLP模块构成,具备在序列、模态和通道3个轴线上融合特征的能力,使得模型能够有效地传输和共享不同模态的信息,从而精准地提取含有情感信息的特征. Bairavel等[32 ] 提出运用对抗草蜂优化算法来进行特征提取的基于多层感知器的多模态情感分析方法,该方法能够从文本、音频和视频3种模态中提取质量更优的特征. ...
1
... 1)文本特征提取:使用SentiLARE[33 ] 预训练语言模型来提取文本特征. SentiLARE是在RoBERTa[34 ] 的基础上融入情感极性和词性标签的预训练语言模型,能够提取含有更丰富情感信息的文本特征. ...
1
... 1)文本特征提取:使用SentiLARE[33 ] 预训练语言模型来提取文本特征. SentiLARE是在RoBERTa[34 ] 的基础上融入情感极性和词性标签的预训练语言模型,能够提取含有更丰富情感信息的文本特征. ...
1
... 2)音频特征提取:使用COVAREP[35 ] 来提取音频特征. 在CMU-MOSI[36 ] 和CMU-MOSEI[37 ] 数据集上所提取的音频特征维度都为74. ...
1
... 2)音频特征提取:使用COVAREP[35 ] 来提取音频特征. 在CMU-MOSI[36 ] 和CMU-MOSEI[37 ] 数据集上所提取的音频特征维度都为74. ...
1
... 2)音频特征提取:使用COVAREP[35 ] 来提取音频特征. 在CMU-MOSI[36 ] 和CMU-MOSEI[37 ] 数据集上所提取的音频特征维度都为74. ...
Py-feat: Python facial expression analysis toolbox
1
2023
... 3)视频特征提取. 在CMU-MOSI数据集上,使用Py-Feat[38 ] 来提取视频特征,视频特征维度为27. 在CMU-MOSEI数据集上,使用Feat来提取视频特征,视频特征维度为35. ...
1
... 在多头自注意力机制(multi-head Attention)[39 ] 中,Q K V Q K $ \sqrt{{d}_{K}} $ V
4
... TFN[40 ] :张量融合网络. 使用三重笛卡尔积,模拟单模态、双模态、三模态之间的相互作用. ...
... 在实验中,采用5种评价指标,评估所提模型的效果. 平均绝对误差(MAE)用于计算情感预测值和真实值之间的误差,MAE越小表示模型效果越好. 七分类准确率A 7 为预测值与相应的真实值落在相同的[−3,+3] 7个区间的比值. 二分类准确率A 2 有以下2种计算方式. 一种是A 2 (non-negative/negative)[40 ] ,该指标在计算情感预测值时将标签值为零的中性情感数据归入非消极分类中. 另一种是A 2 (positive/negative)[20 ] ,该指标在计算情感预测值时排除了标签值为零的中性情感数据. 皮尔逊相关系数(corr)用于衡量预测值和真实标签之间的相关性,F 1 分数(F1-score)用来衡量模型的精确度. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
3
... LMF[41 ] . 将高阶张量分解为低秩因子进行多模态融合,降低计算量. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
2
... MFN[42 ] 是记忆融合网络. 该网络由特殊的注意力机制(delta-memory attention network)、多视图门控记忆模块(multi-view gated memory)和长短期记忆递归神经网络组成. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
3
... MAG-Bert[43 ] . 使用BERT和XLNet,获取视频和音频特征. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
Multimodal sentiment analysis with unidirectional modality translation
3
2022
... MTSA[44 ] . 通过将视频与音频模态翻译为文本模态,开展情感预测任务. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
3
... TMRN[45 ] . 提出面向文本的多模态融合网络,该网络以文本模态为主,通过加强与音频和视频模态的交互,获取质量更高的模态表征. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
Multimodal transformer with adaptive modality weighting for multimodal sentiment analysis
3
2024
... MTAMW[46 ] . 设计新的多模态自适应权重矩阵,根据每个模态在情感分析中的贡献为每个模态分配合适的权重,使得情感分析的结果更准确. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
Multimodal consistency-specificity fusion based on information bottleneck for sentiment analysis
3
2024
... MIBSA[47 ] . 将文本、音频与视频3种模态分别投影到模态不变子空间与模态特定子空间中. 在模态不变子空间中学习不同模态之间的一致性信息,在模态特定子空间中学习单模态的独特信息,并运用信息瓶颈原理来控制信息流. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
A feature-based restoration dynamic interaction network for multimodal sentiment analysis
3
2024
... FRDIN[48 ] . 在多模态特征交互阶段,运用动态路由技术,实现模态内特征交互,学习单模态的内在信息. 通过不同模态间的交互,学习多模态的一致性信息. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...
Co-space representation interaction network for multimodal sentiment analysis
3
2024
... CRNet[49 ] . 将不同模态特征投射到模态不变子空间和模态特定子空间中,通过基于梯度的特征增强机制来提高2个子空间中特征的质量,从而更精确地学习不同模态的一致性信息与单模态自身的差异性信息,提高多模态情感分析的准确性. ...
... Comparison of performance on CMU-MOSI dataset with other benchmark models
Tab.2 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.901 0.698 — / 80.8 34.9 —/ 80.7 LMF[41 ] (2018) 0.917 0.695 — / 82.5 33.2 —/ 82.4 MFN[42 ] (2018) 0.965 0.632 77.4 / — 34.1 77.3 / — MulT[20 ] (2019) 0.871 0.698 — / 83.0 40.0 — / 82.8 BBFN[11 ] (2021) 0.776 0.755 —/84.3 45.0 —/84.3 Self-MM[24 ] (2021) 0.713 0.798 84.0/85.98 — 84.42/85.95 MISA[7 ] (2020) 0.783 0.761 81.8/83.4 42.3 81.7/83.6 MAG-BERT[43 ] (2020) 0.731 0.798 82.5/84.3 — 82.6/84.3 CubeMLP[31 ] (2022) 0.770 0.767 —/ 85.6 45.5 —/85.5 PS-Mixer[30 ] (2023) 0.794 0.748 80.3/82.1 44.31 80.3/82.1 MTSA[44 ] (2022) 0.696 0.806 —/86.8 46.4 —/86.8 AOBERT[10 ] (2023) 0.856 0.700 85.2/85.6 40.2 85.4/86.4 TETFN[25 ] (2023)[45 ] (2023) 0.717 0.800 84.05/86.10 — 83.83/86.07 MTAMW[46 ] (2024) 0.712 0.794 84.40/86.59 46.84 84.20/86.46 MIBSA[47 ] (2024) 0.728 0.798 —/87.00 43.10 —/87.20 FRDIN[48 ] (2024) 0.682 0.813 85.8/87.4 46.59 85.3/87.5 CRNet[49 ] (2024) 0.712 0.797 —/86.4 47.40 —/86.4 本文模型 0.575 0.868 87.6/89.6 52.23 87.7/89.6
与基于张量的多模态情感分析方法TFN、LMF、MFN相比,所提方法在所有评价指标上均取得更优的结果. 与基于MLP的多模态情感分析方法CubeMLP、PS-Mixer相比,所提方法在各个评价指标上均得到有效的提高,尤其是在MAE指标上提升的效果最明显. 原因可能是利用基于多头注意力机制的模态内特征交互模块能够提高单模态特征质量,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征,有效提高多模态情感分析的准确性. 与基于Transformer的方法AOBERT、MTSA、TETFN、MAG-BERT、BBFN等相比,所提方法在所有评价指标上均取得了最优的结果. 原因可能是利用模态内特征交互机制能够有效地提高单模态特征的质量,采用MLP-Interactor机制能够更有效地实现不同模态之间的充分融合,利用SentiLARE预训练语言模型能够提取含有更丰富情感信息的文本特征. 与现有的先进模型MTAMW、MIBSA、FRDIN、CRNet等相比,所提方法在所有评价指标上取得最优的效果. ...
... Comparison of performance on CMU-MOSEI dataset with other benchmark models
Tab.3 模型 MAE corr A 2 A 7 F 1 TFN[40 ] (2017) 0.593 0.700 —/82.5 50.2 —/82.1 LMF[41 ] (2018) 0.623 0.677 —/82.0 48.0 —/82.1 MulT[20 ] (2019) 0.580 0.703 —/82.5 51.8 —/82.3 BBFN[11 ] (2021) 0.529 0.767 —/86.2 54.8 —/86.1 Self-MM[24 ] (2021) 0.530 0.765 82.81/85.17 — 82.53/85.30 MISA[7 ] (2020) 0.555 0.756 83.6/85.5 52.2 83.8/85.3 MAG-BERT[43 ] (2020) 0.543 0.755 82.51/84.82 — 82.77/84.71 CubeMLP[31 ] (2022) 0.529 0.760 —/85.1 54.9 —/84.5 PS-Mixer[30 ] (2023) 0.537 0.765 83.1/86.1 53.0 83.1/86.1 MTSA[44 ] (2022) 0.541 0.774 —/85.5 52.9 —/85.3 AOBERT[10 ] (2023) 0.515 0.763 84.9/86.2 54.5 85.0/85.9 TETFN[25 ] (2023)[45 ] (2023) 0.551 0.748 84.25/85.18 — 84.18/85.27 MTAMW[46 ] (2024) 0.525 0.782 83.09/86.49 53.73 83.48/86.45 MIBSA[47 ] (2024) 0.568 0.753 —/86.70 52.40 —/85.80 FRDIN[48 ] (2024) 0.525 0.778 83.30/86.30 54.40 83.70/86.20 CRNet[49 ] (2024) 0.541 0.771 —/86.20 53.80 —/86.10 本文模型 0.512 0.794 83.0/86.8 54.5 82.5/86.8
3.3.2. 消融实验 为了探究每个模块对模型的贡献,在CMU-MOSI数据集上进行消融实验,实验结果如表4 所示. 在多模态情感分析中,与音频、视频模态相比,文本模态具有更高的贡献度. 当前大多数研究主要使用BERT预训练语言模型来提取文本特征. 为了提取含有更丰富情感信息的文本特征,引入其他预训练语言模型. 通过实验发现,SentiLARE预训练语言模型的效果更优异,当用BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练模型来替换SentiLARE预训练模型时,大部分评价指标都出现明显的下降,这表明与BERT、DeBERT、RoBERTa、DistilBERT、ALBERT预训练语言模型相比,利用SentiLARE预训练语言模型能够提取更高质量的文本特征. 当移除模态内特征交互机制(intra-modality interaction)时,MAE上升,corr、A 7 、A 2 和F 1 均下降,表明利用所提的模态内特征交互机制,能够有效地提高单模态特征的质量和后续多模态情感分析的准确性. 当删去MLP-Interactor机制时,所有指标均下降,这表明MLP-Interactor机制能够增强不同模态之间的交互,学习不同模态之间的一致性信息,提高多模态情感分析的准确性. ...


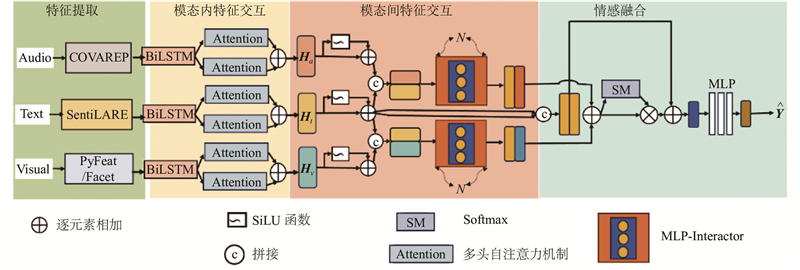
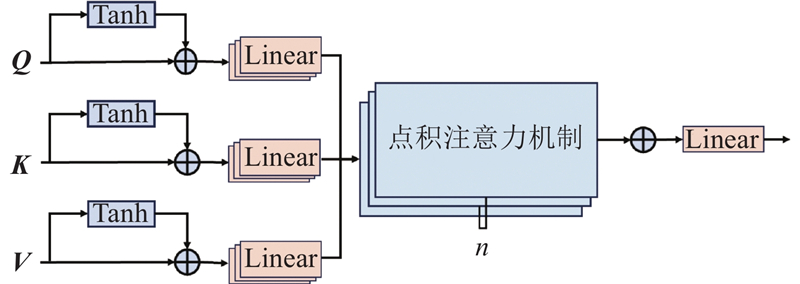
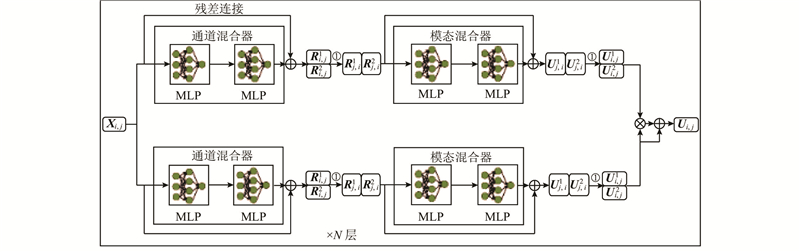


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}