A visual induced motion sickness (VIMS) estimation model based on attention mechanism was proposed to accurately assess the degree of VIMS experienced by users when interacting with virtual products. The model was constructed upon Transformer architecture, incorporating the self-attention mechanism within temporal and spatial sequences to capture the complex interactions between temporal and spatial features. By utilizing the optical flow information and user attention information, two sub-networks of motion flow and attention flow were designed to form a dual-flow network structure. The motion flow sub-network was responsible for capturing the motion features in the visual content, and the attention flow sub-network focused on extracting critical information, such as objects, textures, and other key elements within the user’s attention area. A late fusion strategy was employed to effectively combine the outputs of the dual-flow network. Experimental validation conducted on public video datasets demonstrated that the synergistic interaction between the attention flow sub-network and the Transformer architecture significantly enhanced the model accuracy. The VIMS model achieved optimal results in terms of the F1 score, accuracy and precision with values of 0.8468, 89.19% and 92.28%, respectively, representing a notable advancement over existing approaches.
CAI Yongqing, HAN Cheng, QUAN Wei, CHEN Wudi. Visual induced motion sickness estimation model based on attention mechanism. Journal of Zhejiang University(Engineering Science)[J], 2025, 59(6): 1110-1118 doi:10.3785/j.issn.1008-973X.2025.06.002
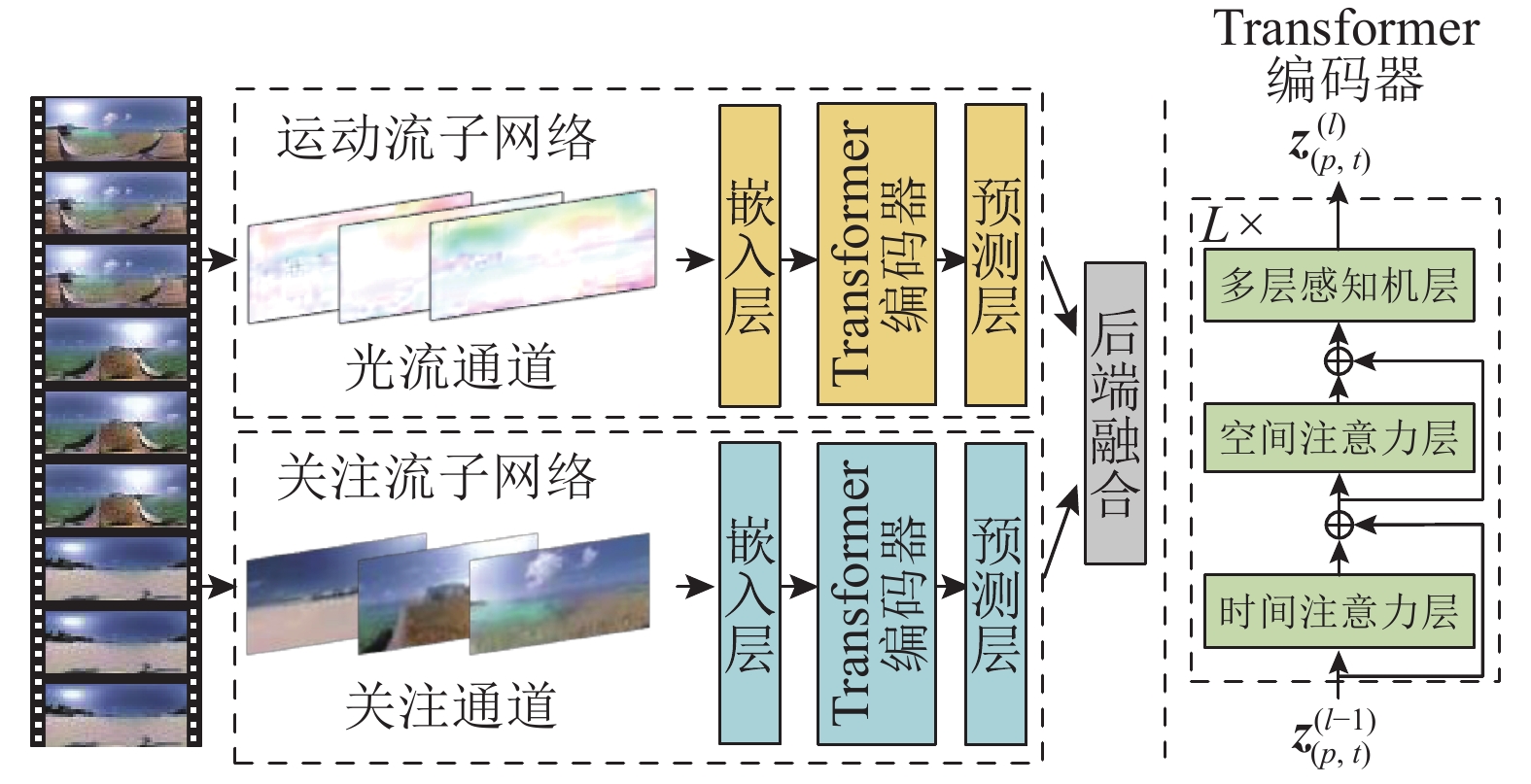
Fig.3
Flowchart of subnetwork based on Transformer architecture
阶段1:对输入视频进行预处理. 对于视频来说,输入为${\boldsymbol{ X}} \in {{\bf{R}}^{H \times W \times F}} $,表示$F$帧采样、尺寸为$ H \times W $的视频. 为了方便统一计算,将输入视频帧尺寸统一改为224×224大小. 将视频帧分成$N$个相同大小的正方形图像块,且$N = HW/{P^2}$,其中$P$为图像块的边长. 将输入视频拆解后,可以表示为向量$ {\boldsymbol{X}}(p,t) \in {{\bf{R}}^{{P^2}}} $,其中$ p $表示空间位置,$ p $=1,2,$\cdots $,$N$;$ t $表示时间位置,$ t $=1,2,$\cdots $,$F$. 如图3所示,将同一空间位置的不同时刻的图像块集合定义为时间块集合${{\boldsymbol{X}}_{^p}} \in {{\bf{R}}^{{P^2}}}$,表示当前时间序列中空间位置$ p $对应的图像块集合.
A narrative review of immersive virtual reality’s ergonomics and risks at the workplace: cybersickness, visual fatigue, muscular fatigue, acute stress, and mental overload
VON MAMMEN S, KNOTE A, EDENHOFER S. Cyber sick but still having fun [C]// Proceedings of the 22nd ACM Conference on Virtual Reality Software and Technology. Munich: ACM, 2016: 325–326.
BRUCK S, WATTERS P A. Estimating cybersickness of simulated motion using the simulator sickness questionnaire (SSQ): a controlled study [C]// Proceedings of the International Conference on Computer Graphics. Tianjin: IEEE, 2009: 486–488.
ARAFAT I M, FERDOUS S M S, QUARLES J. The effects of cybersickness on persons with multiple sclerosis [C]// Proceedings of the 22nd ACM Conference on Virtual Reality Software and Technology. Munich: ACM, 2016: 51–59.
ISLAM R, DESAI K, QUARLES J. Towards forecasting the onset of cybersickness by fusing physiological, head-tracking and eye-tracking with multimodal deep fusion network [C]// Proceedings of the IEEE International Symposium on Mixed and Augmented Reality. Singapore: IEEE, 2022: 121–130.
Prediction and detection of virtual reality induced cybersickness: a spiking neural network approach using spatiotemporal EEG brain data and heart rate variability
[J]. Brain Informatics, 2023, 10 (1): 15
LI R, WANG Y, YIN H, et al. A deep cybersickness predictor through kinematic data with encoded physiological representation [C]// Proceedings of the IEEE International Symposium on Mixed and Augmented Reality. Sydney: IEEE, 2023: 1132–1141.
ISLAM R, DESAI K, QUARLES J. VR sickness prediction from integrated HMD’s sensors using multimodal deep fusion network [EB/OL]. (2021-08-14) [2024-10-22]. https://arxiv.org/abs/2108.06437.
YAO S H, FAN C L, HSU C H. Towards quality-of-experience models for watching 360° videos in head-mounted virtual reality [C]// Proceedings of the Eleventh International Conference on Quality of Multimedia Experience. Berlin: IEEE, 2019: 1–3.
QUAN W, LI L, HAN C, et al. Objective evaluation of VR sickness and analysis of its relationship with VR presence [C]// Proceedings of the International Conference on Intelligent Computing. Singapore: Springer, 2024: 416–427.
CAO Z, KOPPER R. Real-time viewport-aware optical flow estimation in 360-degree videos for visually-induced motion sickness mitigation [C]// Proceedings of the 25th Symposium on Virtual and Augmented Reality. Rio Grande: ACM, 2024: 210–218.
BALA P, DIONÍSIO D, NISI V, et al. Visually induced motion sickness in 360° videos: comparing and combining visual optimization techniques [C]// Proceedings of the IEEE International Symposium on Mixed and Augmented Reality Adjunct. Munich: IEEE, 2018: 244–249.
KIM J, KIM W, AHN S, et al. Virtual reality sickness predictor: analysis of visual-vestibular conflict and VR contents [C]// Proceedings of the Tenth International Conference on Quality of Multimedia Experience. Cagliari: IEEE, 2018: 1–6.
LEE J, KIM W, KIM J, et al. A study on virtual reality sickness and visual attention [C]// Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Tokyo: IEEE, 2021: 1465–1469.
ZHAO J, TRAN K T P, CHALMERS A, et al. Deep learning-based simulator sickness estimation from 3D motion [C]// Proceedings of the IEEE International Symposium on Mixed and Augmented Reality. Sydney: IEEE, 2023: 39–48.
ALEXEY D. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03) [2024-10-22]. https://arxiv.org/abs/2010.11929.
FREMEREY S, SINGLA A, MESEBERG K, et al. AVtrack360: an open dataset and software recording people’s head rotations watching 360° videos on an HMD [C]// Proceedings of the 9th ACM Multimedia Systems Conference. Amsterdam: ACM, 2018: 403–408.
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. California: ACM, 2017: 6000–6010.
KUO P C, CHUANG L C, LIN D Y, et al. VR sickness assessment with perception prior and hybrid temporal features [C]// Proceedings of the 25th International Conference on Pattern Recognition. Milan: IEEE, 2021: 5558–5564.
PORCINO T, RODRIGUES E O, SILVA A, et al. Using the gameplay and user data to predict and identify causes of cybersickness manifestation in virtual reality games [C]// Proceedings of the IEEE 8th International Conference on Serious Games and Applications for Health. Vancouver: IEEE, 2020: 1–8.
YILDIRIM C. A review of deep learning approaches to EEG-based classification of cybersickness in virtual reality [C]// Proceedings of the IEEE International Conference on Artificial Intelligence and Virtual Reality. Utrecht: IEEE, 2020: 351–357.
A narrative review of immersive virtual reality’s ergonomics and risks at the workplace: cybersickness, visual fatigue, muscular fatigue, acute stress, and mental overload
Prediction and detection of virtual reality induced cybersickness: a spiking neural network approach using spatiotemporal EEG brain data and heart rate variability







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}