[1]
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3156–3164.
[本文引用: 2]
[2]
XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// Proceedings of the 32nd International Conference on Machine Learning . Lille: [s. n.], 2015: 2048–2057.
[本文引用: 2]
[3]
陈巧红, 裴皓磊, 孙麒 基于视觉关系推理与上下文门控机制的图像描述
[J]. 浙江大学学报: 工学版 , 2022 , 56 (3 ): 542 - 549
[本文引用: 1]
CHEN Qiaohong, PEI Haolei, SUN Qi Image caption based on relational reasoning and context gate mechanism
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (3 ): 542 - 549
[本文引用: 1]
[4]
王鑫, 宋永红, 张元林 基于显著性特征提取的图像描述算法
[J]. 自动化学报 , 2022 , 48 (3 ): 735 - 746
WANG Xin, SONG Yonghong, ZHANG Yuanlin Salient feature extraction mechanism for image captioning
[J]. Acta Automatica Sinica , 2022 , 48 (3 ): 735 - 746
[6]
SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems . Montreal: ACM, 2014: 3104–3112.
[本文引用: 1]
[7]
MAO J, XU W, YANG Y, et al. Explain images with multimodal recurrent neural networks [EB/OL]. (2014–10–04)[ 2023–10–20]. https://arxiv.org/pdf/1410.1090.
[本文引用: 1]
[8]
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6077–6086.
[本文引用: 3]
[9]
刘茂福, 施琦, 聂礼强 基于视觉关联与上下文双注意力的图像描述生成方法
[J]. 软件学报 , 2022 , 33 (9 ): 3210 - 3222
[本文引用: 1]
LIU Maofu, SHI Qi, NIE Liqiang Image captioning based on visual relevance and context dual attention
[J]. Journal of Software , 2022 , 33 (9 ): 3210 - 3222
[本文引用: 1]
[10]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . [S. l.]: Curran Associates Inc. , 2017: 6000–6010.
[本文引用: 1]
[11]
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2019–05–24)[2023–10–20]. https://arxiv.org/pdf/1810.04805.
[本文引用: 1]
[12]
HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 4634–4643.
[本文引用: 3]
[13]
PAN Y, YAO T, LI Y, et al. X-linear attention networks for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10971–10980.
[本文引用: 3]
[14]
CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10578–10587.
[本文引用: 3]
[15]
WANG Y, XU J, SUN Y End-to-end transformer based model for image captioning
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2022 , 36 (3 ): 2585 - 2594
DOI:10.1609/aaai.v36i3.20160
[本文引用: 1]
[16]
GAO J, MENG X, WANG S, et al. Masked non-autoregressive image captioning [EB/OL]. (2019–06–03) [2023–10–20]. https://arxiv.org/pdf/1906.00717.
[本文引用: 3]
[17]
GUO L, LIU J, ZHU X, et al. Non-autoregressive image captioning with counterfactuals-critical multi-agent learning [C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence . Yokohama: ACM, 2021: 767–773.
[本文引用: 1]
[18]
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems . Vancouver: ACM, 2020: 6840–6851.
[本文引用: 1]
[19]
SONG J, MENG C, ERMON S. Denoising diffusion implicit models [C]// International Conference on Learning Representations . [S.l.]: ICLR, 2020: 1–20.
[20]
ZHOU Y, ZHANG Y, HU Z, et al. Semi-autoregressive transformer for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops . Montreal: IEEE, 2021: 3139–3143.
[本文引用: 3]
[21]
CHEN T, ZHANG R, HINTON G. Analog bits: generating discrete data using diffusion models with self-conditioning [C]// International Conference on Learning Representations . [S.l.]: ICLR, 2023: 1–23.
[本文引用: 4]
[22]
HE Y, CAI Z, GAN X, et al. DiffCap: exploring continuous diffusion on image captioning [EB/OL]. (2023–05–20) [2023–10–20]. https://arxiv.org/pdf/2305.12144.
[本文引用: 3]
[23]
HO J, SAHARIA C, CHAN W, et al Cascaded diffusion models for high fidelity image generation
[J]. Journal of Machine Learning Research , 2022 , 23 (1 ): 2249 - 2281
[本文引用: 1]
[24]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Computer Vision – ECCV 2014 . [S.l.]: Springer, 2014: 740–755.
[本文引用: 1]
[25]
PLUMMER B A, WANG L, CERVANTES C M, et al. Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 2641–2649.
[本文引用: 1]
[26]
KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3128–3137.
[本文引用: 2]
[27]
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics . Philadelphia: ACL, 2002: 311–318.
[本文引用: 1]
[28]
DENKOWSKI M, LAVIE A. Meteor 1.3: automatic metric for reliable optimization and evaluation of machine translation systems [C]// Proceedings of the Sixth Workshop on Statistical Machine Translation . Edinburgh: ACL, 2011: 85–91.
[本文引用: 1]
[29]
LIN CY. ROUGE: a package for automatic evaluation of summaries [C]// Text Summarization Branches Out . Barcelona: ACL, 2004: 74–81.
[本文引用: 1]
[30]
VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 4566–4575.
[本文引用: 1]
[31]
LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation [C]// Proceedings of the International Conference on Machine Learning . [S. l.]: PMLR, 2022: 12888–12900.
[本文引用: 3]
[32]
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the International Conference on Machine Learning . [S. l.]: PMLR, 2021: 8748–8763.
[本文引用: 1]
[33]
KINGMA D P, BA J. ADAM: a method for stochastic optimization [EB/OL]. (2017–03–30)[2023–10–20]. https://arxiv.org/pdf/1412.6980.
[本文引用: 1]
[34]
LU J, YANG J, BATRA D, et al. Neural baby talk [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7219–7228.
[本文引用: 2]
[35]
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1179–1195.
[本文引用: 2]
[36]
JIANG W, MA L, JIANG Y G, et al. Recurrent fusion network for image captioning [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 510–526.
[本文引用: 2]
[37]
YAO T, PAN Y, LI Y, et al. Exploring visual relationship for image captioning [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 711–727.
[本文引用: 2]
[38]
HERDADE S, KAPPELER A, BOAKYE K, et al. Image captioning: transforming objects into words [EB/OL]. (2020–01–11)[2023–10–20]. https://arxiv.org/pdf/1906.05963.
[本文引用: 2]
[39]
ZHANG X, SUN X, LUO Y, et al. RSTNet: captioning with adaptive attention on visual and non-visual words [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 15465–15474.
[本文引用: 2]
[40]
WANG N, XIE J, WU J, et al Controllable image captioning via prompting
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2023 , 37 (2 ): 2617 - 2625
DOI:10.1609/aaai.v37i2.25360
[本文引用: 2]
[41]
YU H, LIU Y, QI B, et al. End-to-end non-autoregressive image captioning [C]// Proceedings of the ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing . Rhodes Island: IEEE, 2023: 1–5.
[本文引用: 2]
[42]
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 375–383.
[本文引用: 1]
[43]
MA Y, JI J, SUN X, et al Towards local visual modeling for image captioning
[J]. Pattern Recognition , 2023 , 138 : 109420
DOI:10.1016/j.patcog.2023.109420
[本文引用: 1]
2
... 作为多模态任务的新兴分支,图像描述(image captioning)任务受到越来越多的关注[1 -5 ] . 图像描述任务目的是生成自然句子用于描述图片内容. 受深度学习方法在机器翻译上的启发[6 ] ,大部分图像描述模型都采用编码器与解码器架构. 编码器负责提取图像的视觉特征,解码器负责通过视觉特征生成对应描述文本. 早期工作[1 ,7 ] 将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
... [1 ,7 ]将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
2
... Performance comparison of different image description models in Flickr30k dataset
Tab.6 模型 B@1 B@4 M C Deep VS[26 ] 57.3 15.7 15.3 24.7 Soft-Attention[2 ] 66.7 19.1 18.5 — Hard-Attention[2 ] 66.9 19.9 18.5 — Adaptive[42 ] 67.7 25.1 20.4 53.1 NBT[34 ] 69.0 27.1 21.7 57.5 Relation-Context[3 ] 73.6 30.1 23.8 60.2 LSTNet[43 ] 67.1 23.3 20.4 64.5 本研究 74.5 31.2 23.9 65.4
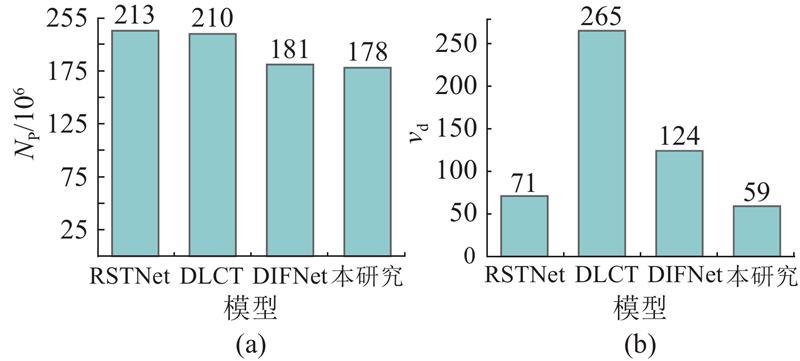
比较不同图像描述模型在模型参数量N P 和推理速度v d 上的差异,结果如图6 所示. 可以看出,所提模型的参数量最少,不仅在资源利用方面更加高效,而且降低了实验的复杂度;在推理速度方面,所提模型的优势明显,表现出更快的响应速度和更高的效率. ...
... [
2 ]
66.9 19.9 18.5 — Adaptive[42 ] 67.7 25.1 20.4 53.1 NBT[34 ] 69.0 27.1 21.7 57.5 Relation-Context[3 ] 73.6 30.1 23.8 60.2 LSTNet[43 ] 67.1 23.3 20.4 64.5 本研究 74.5 31.2 23.9 65.4 比较不同图像描述模型在模型参数量N P 和推理速度v d 上的差异,结果如图6 所示. 可以看出,所提模型的参数量最少,不仅在资源利用方面更加高效,而且降低了实验的复杂度;在推理速度方面,所提模型的优势明显,表现出更快的响应速度和更高的效率. ...
基于视觉关系推理与上下文门控机制的图像描述
1
2022
... Performance comparison of different image description models in Flickr30k dataset
Tab.6 模型 B@1 B@4 M C Deep VS[26 ] 57.3 15.7 15.3 24.7 Soft-Attention[2 ] 66.7 19.1 18.5 — Hard-Attention[2 ] 66.9 19.9 18.5 — Adaptive[42 ] 67.7 25.1 20.4 53.1 NBT[34 ] 69.0 27.1 21.7 57.5 Relation-Context[3 ] 73.6 30.1 23.8 60.2 LSTNet[43 ] 67.1 23.3 20.4 64.5 本研究 74.5 31.2 23.9 65.4
比较不同图像描述模型在模型参数量N P 和推理速度v d 上的差异,结果如图6 所示. 可以看出,所提模型的参数量最少,不仅在资源利用方面更加高效,而且降低了实验的复杂度;在推理速度方面,所提模型的优势明显,表现出更快的响应速度和更高的效率. ...
基于视觉关系推理与上下文门控机制的图像描述
1
2022
... Performance comparison of different image description models in Flickr30k dataset
Tab.6 模型 B@1 B@4 M C Deep VS[26 ] 57.3 15.7 15.3 24.7 Soft-Attention[2 ] 66.7 19.1 18.5 — Hard-Attention[2 ] 66.9 19.9 18.5 — Adaptive[42 ] 67.7 25.1 20.4 53.1 NBT[34 ] 69.0 27.1 21.7 57.5 Relation-Context[3 ] 73.6 30.1 23.8 60.2 LSTNet[43 ] 67.1 23.3 20.4 64.5 本研究 74.5 31.2 23.9 65.4
比较不同图像描述模型在模型参数量N P 和推理速度v d 上的差异,结果如图6 所示. 可以看出,所提模型的参数量最少,不仅在资源利用方面更加高效,而且降低了实验的复杂度;在推理速度方面,所提模型的优势明显,表现出更快的响应速度和更高的效率. ...
基于双注意模型的图像描述生成方法研究
1
2022
... 作为多模态任务的新兴分支,图像描述(image captioning)任务受到越来越多的关注[1 -5 ] . 图像描述任务目的是生成自然句子用于描述图片内容. 受深度学习方法在机器翻译上的启发[6 ] ,大部分图像描述模型都采用编码器与解码器架构. 编码器负责提取图像的视觉特征,解码器负责通过视觉特征生成对应描述文本. 早期工作[1 ,7 ] 将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
基于双注意模型的图像描述生成方法研究
1
2022
... 作为多模态任务的新兴分支,图像描述(image captioning)任务受到越来越多的关注[1 -5 ] . 图像描述任务目的是生成自然句子用于描述图片内容. 受深度学习方法在机器翻译上的启发[6 ] ,大部分图像描述模型都采用编码器与解码器架构. 编码器负责提取图像的视觉特征,解码器负责通过视觉特征生成对应描述文本. 早期工作[1 ,7 ] 将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
1
... 作为多模态任务的新兴分支,图像描述(image captioning)任务受到越来越多的关注[1 -5 ] . 图像描述任务目的是生成自然句子用于描述图片内容. 受深度学习方法在机器翻译上的启发[6 ] ,大部分图像描述模型都采用编码器与解码器架构. 编码器负责提取图像的视觉特征,解码器负责通过视觉特征生成对应描述文本. 早期工作[1 ,7 ] 将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
1
... 作为多模态任务的新兴分支,图像描述(image captioning)任务受到越来越多的关注[1 -5 ] . 图像描述任务目的是生成自然句子用于描述图片内容. 受深度学习方法在机器翻译上的启发[6 ] ,大部分图像描述模型都采用编码器与解码器架构. 编码器负责提取图像的视觉特征,解码器负责通过视觉特征生成对应描述文本. 早期工作[1 ,7 ] 将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
3
... 作为多模态任务的新兴分支,图像描述(image captioning)任务受到越来越多的关注[1 -5 ] . 图像描述任务目的是生成自然句子用于描述图片内容. 受深度学习方法在机器翻译上的启发[6 ] ,大部分图像描述模型都采用编码器与解码器架构. 编码器负责提取图像的视觉特征,解码器负责通过视觉特征生成对应描述文本. 早期工作[1 ,7 ] 将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
基于视觉关联与上下文双注意力的图像描述生成方法
1
2022
... 作为多模态任务的新兴分支,图像描述(image captioning)任务受到越来越多的关注[1 -5 ] . 图像描述任务目的是生成自然句子用于描述图片内容. 受深度学习方法在机器翻译上的启发[6 ] ,大部分图像描述模型都采用编码器与解码器架构. 编码器负责提取图像的视觉特征,解码器负责通过视觉特征生成对应描述文本. 早期工作[1 ,7 ] 将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
基于视觉关联与上下文双注意力的图像描述生成方法
1
2022
... 作为多模态任务的新兴分支,图像描述(image captioning)任务受到越来越多的关注[1 -5 ] . 图像描述任务目的是生成自然句子用于描述图片内容. 受深度学习方法在机器翻译上的启发[6 ] ,大部分图像描述模型都采用编码器与解码器架构. 编码器负责提取图像的视觉特征,解码器负责通过视觉特征生成对应描述文本. 早期工作[1 ,7 ] 将卷积神经网络(CNN)作为编码器去提取图片特征,再将循环神经网络(RNN)或长短时记忆网络(LSTM)作为生成模型产生描述. 为了更好地聚焦受关注的图像区域,Anderson等[8 ] 采用目标检测器(如Fast-RCNN)提取图片特征,并提出自上而下的注意力机制. 刘茂福等[9 ] 提出在传统视觉注意力中增加前一时刻注意力向量以保证视觉连贯性,并提出上下文双注意力机制捕捉更完整的语义信息. ...
1
... 受到如Transformer[10 ] 和BERT[11 ] 的语言模型启发,许多学者致力于研究基于Transformer的图像描述模型,以更好地捕捉图像特征和生成序列之间的关系. 例如,Huang等[12 ] 引入可训练的先验来增强Transformer编码器中的注意机制,并引入网络结构来构建全连接. Pan等[13 ] 将双线性池化集成到Transformer架构中,利用了空间和通道双线性注意分布. Cornia等[14 ] 利用网格结构连接多层编码器和解码器,充分利用低层和高层特征. Wang等[15 ] 将Swin Transformer运用到图像描述领域,引入预融合操作以增强多模态间的特征交互. 这类自回归方法仅支持单向的文本消息传递,通常依赖大量计算资源,计算复杂度与句子长度二次相关. 为了克服这一限制,学者开始关注使用非自回归的方法生成文本. 非自回归的方法能够实现双向文本消息传递,同时生成所有单词,加速处理过程,实现轻量化模型. 例如,Gao等[16 ] 提出掩码非自回归解码,用于并行生成带有增强语义和多样性的标注. Guo等[17 ] 提出的半自回归Transformer可以并行预测一组单词,并从左到右生成这些组,更好平衡了模型描述生成的速度和质量. ...
1
... 受到如Transformer[10 ] 和BERT[11 ] 的语言模型启发,许多学者致力于研究基于Transformer的图像描述模型,以更好地捕捉图像特征和生成序列之间的关系. 例如,Huang等[12 ] 引入可训练的先验来增强Transformer编码器中的注意机制,并引入网络结构来构建全连接. Pan等[13 ] 将双线性池化集成到Transformer架构中,利用了空间和通道双线性注意分布. Cornia等[14 ] 利用网格结构连接多层编码器和解码器,充分利用低层和高层特征. Wang等[15 ] 将Swin Transformer运用到图像描述领域,引入预融合操作以增强多模态间的特征交互. 这类自回归方法仅支持单向的文本消息传递,通常依赖大量计算资源,计算复杂度与句子长度二次相关. 为了克服这一限制,学者开始关注使用非自回归的方法生成文本. 非自回归的方法能够实现双向文本消息传递,同时生成所有单词,加速处理过程,实现轻量化模型. 例如,Gao等[16 ] 提出掩码非自回归解码,用于并行生成带有增强语义和多样性的标注. Guo等[17 ] 提出的半自回归Transformer可以并行预测一组单词,并从左到右生成这些组,更好平衡了模型描述生成的速度和质量. ...
3
... 受到如Transformer[10 ] 和BERT[11 ] 的语言模型启发,许多学者致力于研究基于Transformer的图像描述模型,以更好地捕捉图像特征和生成序列之间的关系. 例如,Huang等[12 ] 引入可训练的先验来增强Transformer编码器中的注意机制,并引入网络结构来构建全连接. Pan等[13 ] 将双线性池化集成到Transformer架构中,利用了空间和通道双线性注意分布. Cornia等[14 ] 利用网格结构连接多层编码器和解码器,充分利用低层和高层特征. Wang等[15 ] 将Swin Transformer运用到图像描述领域,引入预融合操作以增强多模态间的特征交互. 这类自回归方法仅支持单向的文本消息传递,通常依赖大量计算资源,计算复杂度与句子长度二次相关. 为了克服这一限制,学者开始关注使用非自回归的方法生成文本. 非自回归的方法能够实现双向文本消息传递,同时生成所有单词,加速处理过程,实现轻量化模型. 例如,Gao等[16 ] 提出掩码非自回归解码,用于并行生成带有增强语义和多样性的标注. Guo等[17 ] 提出的半自回归Transformer可以并行预测一组单词,并从左到右生成这些组,更好平衡了模型描述生成的速度和质量. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
3
... 受到如Transformer[10 ] 和BERT[11 ] 的语言模型启发,许多学者致力于研究基于Transformer的图像描述模型,以更好地捕捉图像特征和生成序列之间的关系. 例如,Huang等[12 ] 引入可训练的先验来增强Transformer编码器中的注意机制,并引入网络结构来构建全连接. Pan等[13 ] 将双线性池化集成到Transformer架构中,利用了空间和通道双线性注意分布. Cornia等[14 ] 利用网格结构连接多层编码器和解码器,充分利用低层和高层特征. Wang等[15 ] 将Swin Transformer运用到图像描述领域,引入预融合操作以增强多模态间的特征交互. 这类自回归方法仅支持单向的文本消息传递,通常依赖大量计算资源,计算复杂度与句子长度二次相关. 为了克服这一限制,学者开始关注使用非自回归的方法生成文本. 非自回归的方法能够实现双向文本消息传递,同时生成所有单词,加速处理过程,实现轻量化模型. 例如,Gao等[16 ] 提出掩码非自回归解码,用于并行生成带有增强语义和多样性的标注. Guo等[17 ] 提出的半自回归Transformer可以并行预测一组单词,并从左到右生成这些组,更好平衡了模型描述生成的速度和质量. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
3
... 受到如Transformer[10 ] 和BERT[11 ] 的语言模型启发,许多学者致力于研究基于Transformer的图像描述模型,以更好地捕捉图像特征和生成序列之间的关系. 例如,Huang等[12 ] 引入可训练的先验来增强Transformer编码器中的注意机制,并引入网络结构来构建全连接. Pan等[13 ] 将双线性池化集成到Transformer架构中,利用了空间和通道双线性注意分布. Cornia等[14 ] 利用网格结构连接多层编码器和解码器,充分利用低层和高层特征. Wang等[15 ] 将Swin Transformer运用到图像描述领域,引入预融合操作以增强多模态间的特征交互. 这类自回归方法仅支持单向的文本消息传递,通常依赖大量计算资源,计算复杂度与句子长度二次相关. 为了克服这一限制,学者开始关注使用非自回归的方法生成文本. 非自回归的方法能够实现双向文本消息传递,同时生成所有单词,加速处理过程,实现轻量化模型. 例如,Gao等[16 ] 提出掩码非自回归解码,用于并行生成带有增强语义和多样性的标注. Guo等[17 ] 提出的半自回归Transformer可以并行预测一组单词,并从左到右生成这些组,更好平衡了模型描述生成的速度和质量. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
End-to-end transformer based model for image captioning
1
2022
... 受到如Transformer[10 ] 和BERT[11 ] 的语言模型启发,许多学者致力于研究基于Transformer的图像描述模型,以更好地捕捉图像特征和生成序列之间的关系. 例如,Huang等[12 ] 引入可训练的先验来增强Transformer编码器中的注意机制,并引入网络结构来构建全连接. Pan等[13 ] 将双线性池化集成到Transformer架构中,利用了空间和通道双线性注意分布. Cornia等[14 ] 利用网格结构连接多层编码器和解码器,充分利用低层和高层特征. Wang等[15 ] 将Swin Transformer运用到图像描述领域,引入预融合操作以增强多模态间的特征交互. 这类自回归方法仅支持单向的文本消息传递,通常依赖大量计算资源,计算复杂度与句子长度二次相关. 为了克服这一限制,学者开始关注使用非自回归的方法生成文本. 非自回归的方法能够实现双向文本消息传递,同时生成所有单词,加速处理过程,实现轻量化模型. 例如,Gao等[16 ] 提出掩码非自回归解码,用于并行生成带有增强语义和多样性的标注. Guo等[17 ] 提出的半自回归Transformer可以并行预测一组单词,并从左到右生成这些组,更好平衡了模型描述生成的速度和质量. ...
3
... 受到如Transformer[10 ] 和BERT[11 ] 的语言模型启发,许多学者致力于研究基于Transformer的图像描述模型,以更好地捕捉图像特征和生成序列之间的关系. 例如,Huang等[12 ] 引入可训练的先验来增强Transformer编码器中的注意机制,并引入网络结构来构建全连接. Pan等[13 ] 将双线性池化集成到Transformer架构中,利用了空间和通道双线性注意分布. Cornia等[14 ] 利用网格结构连接多层编码器和解码器,充分利用低层和高层特征. Wang等[15 ] 将Swin Transformer运用到图像描述领域,引入预融合操作以增强多模态间的特征交互. 这类自回归方法仅支持单向的文本消息传递,通常依赖大量计算资源,计算复杂度与句子长度二次相关. 为了克服这一限制,学者开始关注使用非自回归的方法生成文本. 非自回归的方法能够实现双向文本消息传递,同时生成所有单词,加速处理过程,实现轻量化模型. 例如,Gao等[16 ] 提出掩码非自回归解码,用于并行生成带有增强语义和多样性的标注. Guo等[17 ] 提出的半自回归Transformer可以并行预测一组单词,并从左到右生成这些组,更好平衡了模型描述生成的速度和质量. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
1
... 受到如Transformer[10 ] 和BERT[11 ] 的语言模型启发,许多学者致力于研究基于Transformer的图像描述模型,以更好地捕捉图像特征和生成序列之间的关系. 例如,Huang等[12 ] 引入可训练的先验来增强Transformer编码器中的注意机制,并引入网络结构来构建全连接. Pan等[13 ] 将双线性池化集成到Transformer架构中,利用了空间和通道双线性注意分布. Cornia等[14 ] 利用网格结构连接多层编码器和解码器,充分利用低层和高层特征. Wang等[15 ] 将Swin Transformer运用到图像描述领域,引入预融合操作以增强多模态间的特征交互. 这类自回归方法仅支持单向的文本消息传递,通常依赖大量计算资源,计算复杂度与句子长度二次相关. 为了克服这一限制,学者开始关注使用非自回归的方法生成文本. 非自回归的方法能够实现双向文本消息传递,同时生成所有单词,加速处理过程,实现轻量化模型. 例如,Gao等[16 ] 提出掩码非自回归解码,用于并行生成带有增强语义和多样性的标注. Guo等[17 ] 提出的半自回归Transformer可以并行预测一组单词,并从左到右生成这些组,更好平衡了模型描述生成的速度和质量. ...
1
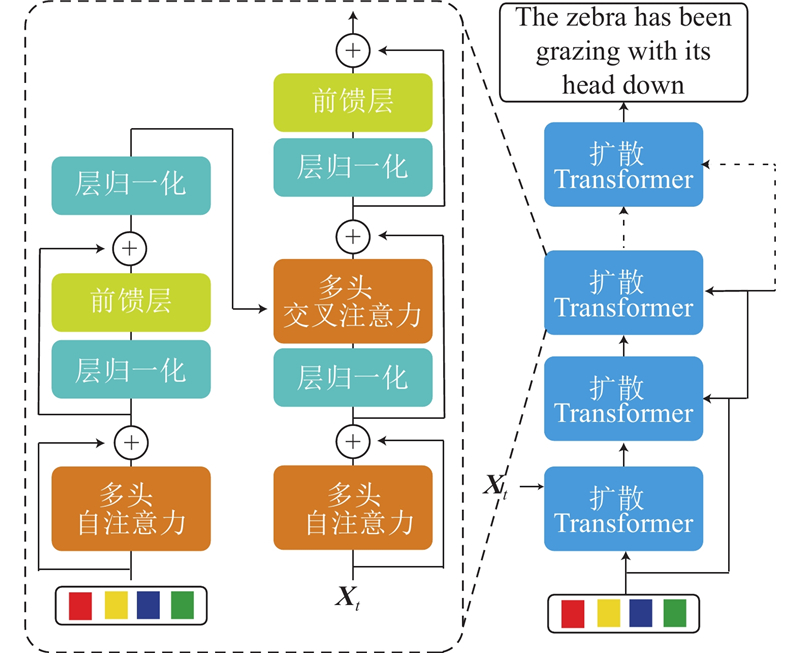
... 随着扩散模型[18 -20 ] 在图像生成领域上的成功应用,基于扩散模型的文本生成也成为新的研究方向. 与典型的一次性离散句子生成不同,连续扩散过程被视为参数化的马尔可夫链,逐渐向句子中引入高斯噪声. 通过学习每个逆向状态转移,可以从噪声增强的数据中还原原始句子数据,实现文本的生成. Chen等[21 ] 提出将离散文本编码成二进制位的方法,利用自条件扩散模型生成标注. He等[22 ] 提出以自然的方式转换离散标记,在离散标记上应用连续扩散,成功融合提取的图像特征用于扩散式文本生成. 大多数基于扩散模型的图像描述方法不但存在生成的文本不匹配输入图像,无法有效通过图像的语义条件进行控制以及单词重复或遗漏等问题;在扩散过程中,还存在由于噪声不足导致的训练不充分的问题. 本研究提出基于跨模态级联扩散模型的图像描述方法,引入跨模态语义对齐模块对输入图像视觉语义信息和文本语言信息进行映射对齐,对齐后的语义特征用于指导扩散模型每个逆向状态转移的学习;将级联的方式应用于扩散模型,实现文本的生成,通过加强扩散模型中的噪声计划、充分训练模型来增强语义的连贯性和内容的丰富性. ...
3
... 随着扩散模型[18 -20 ] 在图像生成领域上的成功应用,基于扩散模型的文本生成也成为新的研究方向. 与典型的一次性离散句子生成不同,连续扩散过程被视为参数化的马尔可夫链,逐渐向句子中引入高斯噪声. 通过学习每个逆向状态转移,可以从噪声增强的数据中还原原始句子数据,实现文本的生成. Chen等[21 ] 提出将离散文本编码成二进制位的方法,利用自条件扩散模型生成标注. He等[22 ] 提出以自然的方式转换离散标记,在离散标记上应用连续扩散,成功融合提取的图像特征用于扩散式文本生成. 大多数基于扩散模型的图像描述方法不但存在生成的文本不匹配输入图像,无法有效通过图像的语义条件进行控制以及单词重复或遗漏等问题;在扩散过程中,还存在由于噪声不足导致的训练不充分的问题. 本研究提出基于跨模态级联扩散模型的图像描述方法,引入跨模态语义对齐模块对输入图像视觉语义信息和文本语言信息进行映射对齐,对齐后的语义特征用于指导扩散模型每个逆向状态转移的学习;将级联的方式应用于扩散模型,实现文本的生成,通过加强扩散模型中的噪声计划、充分训练模型来增强语义的连贯性和内容的丰富性. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
4
... 随着扩散模型[18 -20 ] 在图像生成领域上的成功应用,基于扩散模型的文本生成也成为新的研究方向. 与典型的一次性离散句子生成不同,连续扩散过程被视为参数化的马尔可夫链,逐渐向句子中引入高斯噪声. 通过学习每个逆向状态转移,可以从噪声增强的数据中还原原始句子数据,实现文本的生成. Chen等[21 ] 提出将离散文本编码成二进制位的方法,利用自条件扩散模型生成标注. He等[22 ] 提出以自然的方式转换离散标记,在离散标记上应用连续扩散,成功融合提取的图像特征用于扩散式文本生成. 大多数基于扩散模型的图像描述方法不但存在生成的文本不匹配输入图像,无法有效通过图像的语义条件进行控制以及单词重复或遗漏等问题;在扩散过程中,还存在由于噪声不足导致的训练不充分的问题. 本研究提出基于跨模态级联扩散模型的图像描述方法,引入跨模态语义对齐模块对输入图像视觉语义信息和文本语言信息进行映射对齐,对齐后的语义特征用于指导扩散模型每个逆向状态转移的学习;将级联的方式应用于扩散模型,实现文本的生成,通过加强扩散模型中的噪声计划、充分训练模型来增强语义的连贯性和内容的丰富性. ...
... 如图1 所示为跨模态级联扩散模型的整体架构. 将给定图像作为输入,图像描述模型生成描述序列$ S=\{{w}_{1},{w}_{2},\cdots ,{w}_{T}\},{w}_{T}\in D $ , 其中D 为词汇总数,T 为序列长度. 具体来说,使用来自视觉Transformer模型(ViT)的[CLS]标记位置的输出特征,获取图像的全局特征表示;通过多模态编码器将视觉和语义模态对齐,并通过线性层进行映射. 在解码器端,采用扩散模型构建描述序列的生成,由于文本中的单词是离散数据,受Bit Diffusion[21 ] 中处理方式的启发,将每个单词转换为n 个二进制位. 在编码器端,构造跨模态语义对齐模块. 该模块从视觉编码器提取视觉特征,视觉特征通过多模态编码器以捕捉模态间的关系,促进视觉特征和文本特征的语义对齐. 对齐后的特征作为语义条件用于指导扩散模型. 在解码器端,构造级联的扩散模型. 每层扩散模型利用自条件和编码器端输出的多模态条件来学习. 为了实现更好的视觉与文本对齐和语言连贯性,这种级联结构通过在每层扩散模型中加入视觉特征指导扩散过程的方式来逐步增强输出的句子. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
3
... 随着扩散模型[18 -20 ] 在图像生成领域上的成功应用,基于扩散模型的文本生成也成为新的研究方向. 与典型的一次性离散句子生成不同,连续扩散过程被视为参数化的马尔可夫链,逐渐向句子中引入高斯噪声. 通过学习每个逆向状态转移,可以从噪声增强的数据中还原原始句子数据,实现文本的生成. Chen等[21 ] 提出将离散文本编码成二进制位的方法,利用自条件扩散模型生成标注. He等[22 ] 提出以自然的方式转换离散标记,在离散标记上应用连续扩散,成功融合提取的图像特征用于扩散式文本生成. 大多数基于扩散模型的图像描述方法不但存在生成的文本不匹配输入图像,无法有效通过图像的语义条件进行控制以及单词重复或遗漏等问题;在扩散过程中,还存在由于噪声不足导致的训练不充分的问题. 本研究提出基于跨模态级联扩散模型的图像描述方法,引入跨模态语义对齐模块对输入图像视觉语义信息和文本语言信息进行映射对齐,对齐后的语义特征用于指导扩散模型每个逆向状态转移的学习;将级联的方式应用于扩散模型,实现文本的生成,通过加强扩散模型中的噪声计划、充分训练模型来增强语义的连贯性和内容的丰富性. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
Cascaded diffusion models for high fidelity image generation
1
2022
... 采用非自回归方法中的扩散模型范式实现双向文本信息传递,同时生成所有单词. 受到级联扩散模型在图像生成方面的成功应用启发[23 ] ,使用级联方式堆叠多个扩散模型. 如图2 所示,每个扩散模型$ {f}_{i} $
1
... 将Microsoft COCO[24 ] 和Flickr30k[25 ] 作为基准数据集开展不同图像描述模型的性能比较实验. Microsoft COCO是图像描述任务最大的公共数据集,包含123 287张图片,其中82 783张图片用于训练,40 504张图片用于验证,每张图片有5个不同的描述. 在模型评估上,将Microsoft COCO按照Karpathy等[26 ] 所提方法进行分割,训练、验证和测试阶段分别对应113 287、5 000和5 000张图片. Flickr30k是Flickr8k数据集的扩展,主要涵盖人类的日常活动和事件,包含158 915个句子描述和31 783张来自Flickr的图像. 数据集的每张图片都有5个参考描述. 为了确保与现有研究的公平比较,使用公开可获取的训练-测试集划分,训练、验证和测试阶段分别对应29 783、1 000和1000 张图像. 使用评价指标:BLEU[27 ] 、METEOR[28 ] 、ROUGE[29 ] 和CIDEr[30 ] 公平地评估所生成描述的质量. ...
1
... 将Microsoft COCO[24 ] 和Flickr30k[25 ] 作为基准数据集开展不同图像描述模型的性能比较实验. Microsoft COCO是图像描述任务最大的公共数据集,包含123 287张图片,其中82 783张图片用于训练,40 504张图片用于验证,每张图片有5个不同的描述. 在模型评估上,将Microsoft COCO按照Karpathy等[26 ] 所提方法进行分割,训练、验证和测试阶段分别对应113 287、5 000和5 000张图片. Flickr30k是Flickr8k数据集的扩展,主要涵盖人类的日常活动和事件,包含158 915个句子描述和31 783张来自Flickr的图像. 数据集的每张图片都有5个参考描述. 为了确保与现有研究的公平比较,使用公开可获取的训练-测试集划分,训练、验证和测试阶段分别对应29 783、1 000和1000 张图像. 使用评价指标:BLEU[27 ] 、METEOR[28 ] 、ROUGE[29 ] 和CIDEr[30 ] 公平地评估所生成描述的质量. ...
2
... 将Microsoft COCO[24 ] 和Flickr30k[25 ] 作为基准数据集开展不同图像描述模型的性能比较实验. Microsoft COCO是图像描述任务最大的公共数据集,包含123 287张图片,其中82 783张图片用于训练,40 504张图片用于验证,每张图片有5个不同的描述. 在模型评估上,将Microsoft COCO按照Karpathy等[26 ] 所提方法进行分割,训练、验证和测试阶段分别对应113 287、5 000和5 000张图片. Flickr30k是Flickr8k数据集的扩展,主要涵盖人类的日常活动和事件,包含158 915个句子描述和31 783张来自Flickr的图像. 数据集的每张图片都有5个参考描述. 为了确保与现有研究的公平比较,使用公开可获取的训练-测试集划分,训练、验证和测试阶段分别对应29 783、1 000和1000 张图像. 使用评价指标:BLEU[27 ] 、METEOR[28 ] 、ROUGE[29 ] 和CIDEr[30 ] 公平地评估所生成描述的质量. ...
... Performance comparison of different image description models in Flickr30k dataset
Tab.6 模型 B@1 B@4 M C Deep VS[26 ] 57.3 15.7 15.3 24.7 Soft-Attention[2 ] 66.7 19.1 18.5 — Hard-Attention[2 ] 66.9 19.9 18.5 — Adaptive[42 ] 67.7 25.1 20.4 53.1 NBT[34 ] 69.0 27.1 21.7 57.5 Relation-Context[3 ] 73.6 30.1 23.8 60.2 LSTNet[43 ] 67.1 23.3 20.4 64.5 本研究 74.5 31.2 23.9 65.4
比较不同图像描述模型在模型参数量N P 和推理速度v d 上的差异,结果如图6 所示. 可以看出,所提模型的参数量最少,不仅在资源利用方面更加高效,而且降低了实验的复杂度;在推理速度方面,所提模型的优势明显,表现出更快的响应速度和更高的效率. ...
1
... 将Microsoft COCO[24 ] 和Flickr30k[25 ] 作为基准数据集开展不同图像描述模型的性能比较实验. Microsoft COCO是图像描述任务最大的公共数据集,包含123 287张图片,其中82 783张图片用于训练,40 504张图片用于验证,每张图片有5个不同的描述. 在模型评估上,将Microsoft COCO按照Karpathy等[26 ] 所提方法进行分割,训练、验证和测试阶段分别对应113 287、5 000和5 000张图片. Flickr30k是Flickr8k数据集的扩展,主要涵盖人类的日常活动和事件,包含158 915个句子描述和31 783张来自Flickr的图像. 数据集的每张图片都有5个参考描述. 为了确保与现有研究的公平比较,使用公开可获取的训练-测试集划分,训练、验证和测试阶段分别对应29 783、1 000和1000 张图像. 使用评价指标:BLEU[27 ] 、METEOR[28 ] 、ROUGE[29 ] 和CIDEr[30 ] 公平地评估所生成描述的质量. ...
1
... 将Microsoft COCO[24 ] 和Flickr30k[25 ] 作为基准数据集开展不同图像描述模型的性能比较实验. Microsoft COCO是图像描述任务最大的公共数据集,包含123 287张图片,其中82 783张图片用于训练,40 504张图片用于验证,每张图片有5个不同的描述. 在模型评估上,将Microsoft COCO按照Karpathy等[26 ] 所提方法进行分割,训练、验证和测试阶段分别对应113 287、5 000和5 000张图片. Flickr30k是Flickr8k数据集的扩展,主要涵盖人类的日常活动和事件,包含158 915个句子描述和31 783张来自Flickr的图像. 数据集的每张图片都有5个参考描述. 为了确保与现有研究的公平比较,使用公开可获取的训练-测试集划分,训练、验证和测试阶段分别对应29 783、1 000和1000 张图像. 使用评价指标:BLEU[27 ] 、METEOR[28 ] 、ROUGE[29 ] 和CIDEr[30 ] 公平地评估所生成描述的质量. ...
1
... 将Microsoft COCO[24 ] 和Flickr30k[25 ] 作为基准数据集开展不同图像描述模型的性能比较实验. Microsoft COCO是图像描述任务最大的公共数据集,包含123 287张图片,其中82 783张图片用于训练,40 504张图片用于验证,每张图片有5个不同的描述. 在模型评估上,将Microsoft COCO按照Karpathy等[26 ] 所提方法进行分割,训练、验证和测试阶段分别对应113 287、5 000和5 000张图片. Flickr30k是Flickr8k数据集的扩展,主要涵盖人类的日常活动和事件,包含158 915个句子描述和31 783张来自Flickr的图像. 数据集的每张图片都有5个参考描述. 为了确保与现有研究的公平比较,使用公开可获取的训练-测试集划分,训练、验证和测试阶段分别对应29 783、1 000和1000 张图像. 使用评价指标:BLEU[27 ] 、METEOR[28 ] 、ROUGE[29 ] 和CIDEr[30 ] 公平地评估所生成描述的质量. ...
1
... 将Microsoft COCO[24 ] 和Flickr30k[25 ] 作为基准数据集开展不同图像描述模型的性能比较实验. Microsoft COCO是图像描述任务最大的公共数据集,包含123 287张图片,其中82 783张图片用于训练,40 504张图片用于验证,每张图片有5个不同的描述. 在模型评估上,将Microsoft COCO按照Karpathy等[26 ] 所提方法进行分割,训练、验证和测试阶段分别对应113 287、5 000和5 000张图片. Flickr30k是Flickr8k数据集的扩展,主要涵盖人类的日常活动和事件,包含158 915个句子描述和31 783张来自Flickr的图像. 数据集的每张图片都有5个参考描述. 为了确保与现有研究的公平比较,使用公开可获取的训练-测试集划分,训练、验证和测试阶段分别对应29 783、1 000和1000 张图像. 使用评价指标:BLEU[27 ] 、METEOR[28 ] 、ROUGE[29 ] 和CIDEr[30 ] 公平地评估所生成描述的质量. ...
3
... 对每张图片,使用BLIP[31 ] 中的ViT-L/14作为图像编码器,多模态编码器采用基于BERT预训练权重进行初始化,其中交叉注意力层参数的权重进行随机初始化,其他训练超参数遵循CLIP[32 ] 中的配置. 在文本处理过程中,删除标点符号并将字母转换成小写,描述都被截断成20个单词,使用SpaPy工具包进行标记化处理. 在词嵌入操作过程中,将词汇表中的单词映射到实数向量空间,调整所有输入图像的大小,使短边和长边的最大尺寸分别为384和640. 每个扩散模型的编码器和解码器均由3个 Transformer层组成,每层包含8个注意力头和512个隐藏状态. 使用交叉熵损失和L2损失训练模型60个周期,将网络学习率固定在1.0×10−5 . 参数优化使用Adam[33 ] 优化器,描述语句生成采用集束搜索方式,束大小为5. 整个系统由PyTorch实现,所有实验都在2×Nvidia 4090 GPU上进行. ...
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
1
... 对每张图片,使用BLIP[31 ] 中的ViT-L/14作为图像编码器,多模态编码器采用基于BERT预训练权重进行初始化,其中交叉注意力层参数的权重进行随机初始化,其他训练超参数遵循CLIP[32 ] 中的配置. 在文本处理过程中,删除标点符号并将字母转换成小写,描述都被截断成20个单词,使用SpaPy工具包进行标记化处理. 在词嵌入操作过程中,将词汇表中的单词映射到实数向量空间,调整所有输入图像的大小,使短边和长边的最大尺寸分别为384和640. 每个扩散模型的编码器和解码器均由3个 Transformer层组成,每层包含8个注意力头和512个隐藏状态. 使用交叉熵损失和L2损失训练模型60个周期,将网络学习率固定在1.0×10−5 . 参数优化使用Adam[33 ] 优化器,描述语句生成采用集束搜索方式,束大小为5. 整个系统由PyTorch实现,所有实验都在2×Nvidia 4090 GPU上进行. ...
1
... 对每张图片,使用BLIP[31 ] 中的ViT-L/14作为图像编码器,多模态编码器采用基于BERT预训练权重进行初始化,其中交叉注意力层参数的权重进行随机初始化,其他训练超参数遵循CLIP[32 ] 中的配置. 在文本处理过程中,删除标点符号并将字母转换成小写,描述都被截断成20个单词,使用SpaPy工具包进行标记化处理. 在词嵌入操作过程中,将词汇表中的单词映射到实数向量空间,调整所有输入图像的大小,使短边和长边的最大尺寸分别为384和640. 每个扩散模型的编码器和解码器均由3个 Transformer层组成,每层包含8个注意力头和512个隐藏状态. 使用交叉熵损失和L2损失训练模型60个周期,将网络学习率固定在1.0×10−5 . 参数优化使用Adam[33 ] 优化器,描述语句生成采用集束搜索方式,束大小为5. 整个系统由PyTorch实现,所有实验都在2×Nvidia 4090 GPU上进行. ...
2
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Flickr30k dataset
Tab.6 模型 B@1 B@4 M C Deep VS[26 ] 57.3 15.7 15.3 24.7 Soft-Attention[2 ] 66.7 19.1 18.5 — Hard-Attention[2 ] 66.9 19.9 18.5 — Adaptive[42 ] 67.7 25.1 20.4 53.1 NBT[34 ] 69.0 27.1 21.7 57.5 Relation-Context[3 ] 73.6 30.1 23.8 60.2 LSTNet[43 ] 67.1 23.3 20.4 64.5 本研究 74.5 31.2 23.9 65.4
比较不同图像描述模型在模型参数量N P 和推理速度v d 上的差异,结果如图6 所示. 可以看出,所提模型的参数量最少,不仅在资源利用方面更加高效,而且降低了实验的复杂度;在推理速度方面,所提模型的优势明显,表现出更快的响应速度和更高的效率. ...
2
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
2
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
2
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
2
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
2
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
Controllable image captioning via prompting
2
2023
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
2
... 在Microsoft COCO和Flickr30k数据集中,将所提模型与常见模型进行性能比较,结果如表5 、表6 所示. 这些模型包括自回归方式的NBT[34 ] 、SCST[35 ] 、Updown[8 ] 、RFNet[36 ] 、GCN-LSTM[37 ] 、ORT[38 ] 、AoANet[12 ] 、M2-Transformer[14 ] 、X-Transformer[13 ] 、RSTNet[39 ] 、BLIP[31 ] 和ConCap[40 ] ,非自回归方式的MNIC[16 ] 、SATIC[20 ] 、Bit-Diffusion[21 ] 、DiffCap[22 ] 和E2E[41 ] . 由表5 可知,相比非自回归方法,所提方法的BLEU和CIDEr均为最优;相比自回归方法,2项指标都有显著提高. 由表6 可知,所提模型在Flickr30k数据集上的各项指标均达到最优. ...
... Performance comparison of different image description models in Microsoft COCO dataset
Tab.5 模型类别 模型 B@1 B@4 M R C 自回归方法 SCST[35 ] — 34.2 26.7 55.7 114.0 UpDown[8 ] 79.8 36.5 27.7 57.3 120.1 RFNet[36 ] 79.1 36.5 27.7 57.3 121.9 GCN-LSTM[37 ] 80.5 38.2 28.5 58.3 127.6 ORT[38 ] 80.5 38.6 28.7 58.4 128.3 AoANet[12 ] 80.2 38.9 29.2 58.8 129.8 M2-Transformer[14 ] 80.8 39.1 29.2 58.6 131.2 X-Transformer[13 ] 80.9 39.7 29.5 59.1 133.8 RSTNet[39 ] 81.1 39.3 29.4 58.8 133.3 BLIP[31 ] — 39.7 — — 133.3 ConCap[40 ] — 40.5 30.9 — 133.7 非自回归方法 MNIC[16 ] 75.4 30.9 27.5 55.6 108.1 SATIC[20 ] 80.6 37.9 28.6 — 127.2 Bit-Diffusion[21 ] — 34.7 — 58.0 115.0 DiffCap[22 ] — 31.6 26.5 57.0 104.3 E2E[41 ] 79.7 36.9 27.9 58.0 122.6 本研究 81.2 39.9 29.0 58.9 133.8
表 6 Flickr30k 数据集中不同图像描述模型的性能对比 ...
1
... Performance comparison of different image description models in Flickr30k dataset
Tab.6 模型 B@1 B@4 M C Deep VS[26 ] 57.3 15.7 15.3 24.7 Soft-Attention[2 ] 66.7 19.1 18.5 — Hard-Attention[2 ] 66.9 19.9 18.5 — Adaptive[42 ] 67.7 25.1 20.4 53.1 NBT[34 ] 69.0 27.1 21.7 57.5 Relation-Context[3 ] 73.6 30.1 23.8 60.2 LSTNet[43 ] 67.1 23.3 20.4 64.5 本研究 74.5 31.2 23.9 65.4
比较不同图像描述模型在模型参数量N P 和推理速度v d 上的差异,结果如图6 所示. 可以看出,所提模型的参数量最少,不仅在资源利用方面更加高效,而且降低了实验的复杂度;在推理速度方面,所提模型的优势明显,表现出更快的响应速度和更高的效率. ...
Towards local visual modeling for image captioning
1
2023
... Performance comparison of different image description models in Flickr30k dataset
Tab.6 模型 B@1 B@4 M C Deep VS[26 ] 57.3 15.7 15.3 24.7 Soft-Attention[2 ] 66.7 19.1 18.5 — Hard-Attention[2 ] 66.9 19.9 18.5 — Adaptive[42 ] 67.7 25.1 20.4 53.1 NBT[34 ] 69.0 27.1 21.7 57.5 Relation-Context[3 ] 73.6 30.1 23.8 60.2 LSTNet[43 ] 67.1 23.3 20.4 64.5 本研究 74.5 31.2 23.9 65.4
比较不同图像描述模型在模型参数量N P 和推理速度v d 上的差异,结果如图6 所示. 可以看出,所提模型的参数量最少,不仅在资源利用方面更加高效,而且降低了实验的复杂度;在推理速度方面,所提模型的优势明显,表现出更快的响应速度和更高的效率. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}