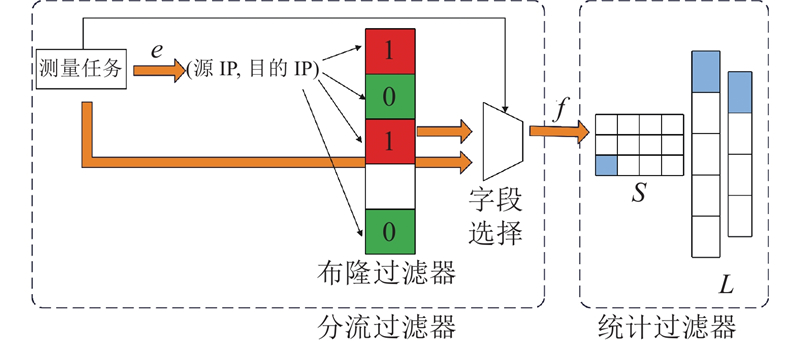
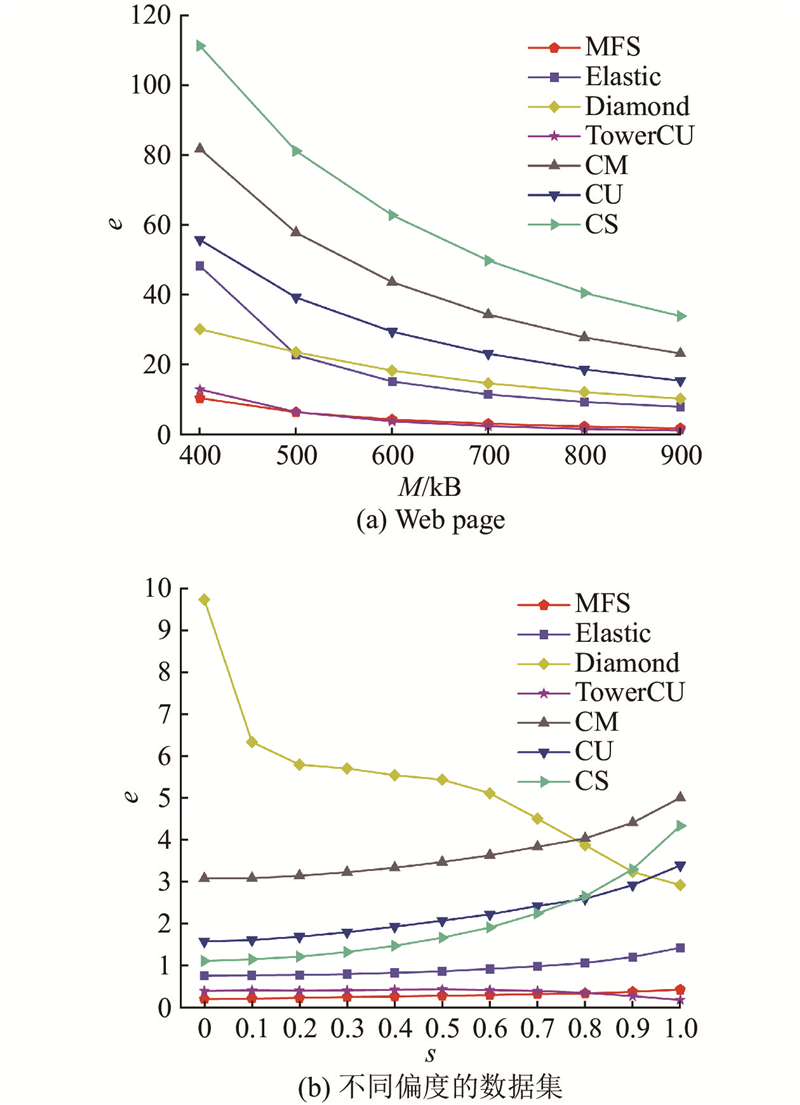
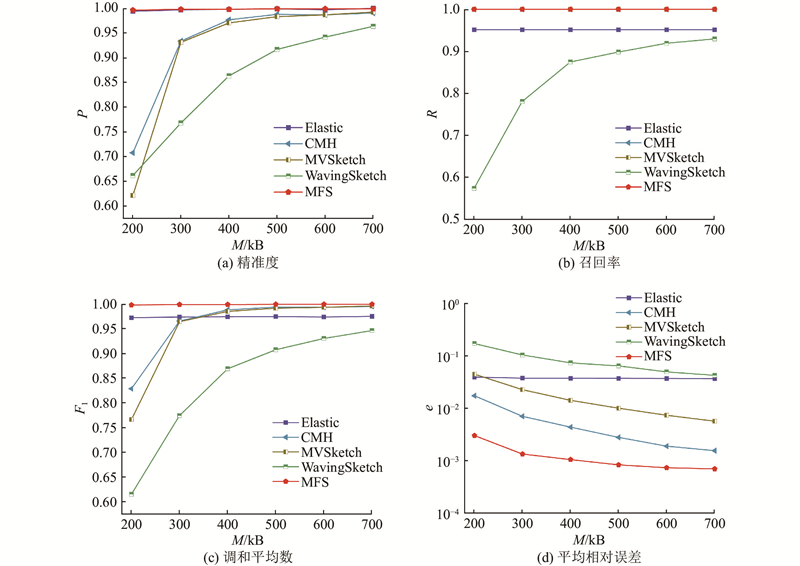
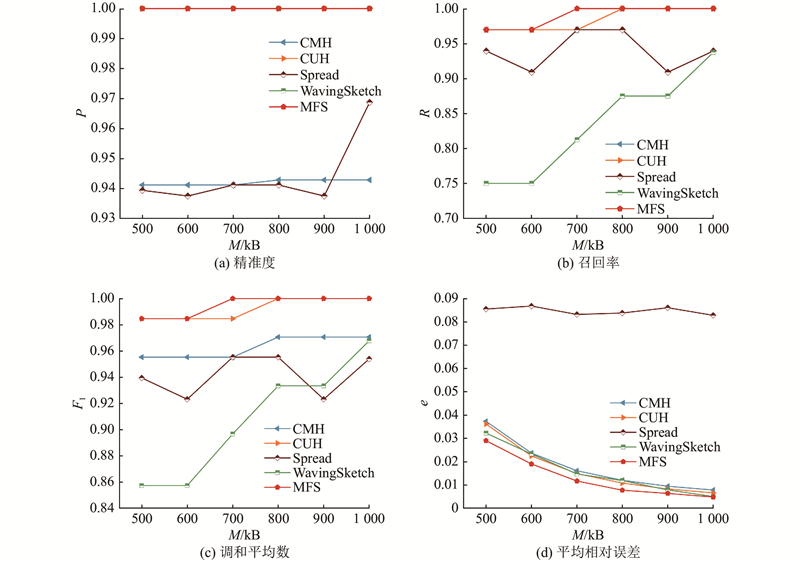
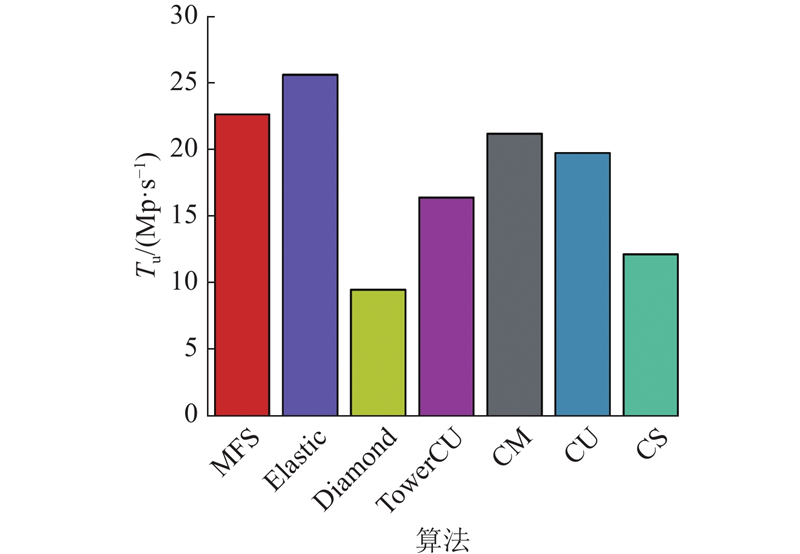
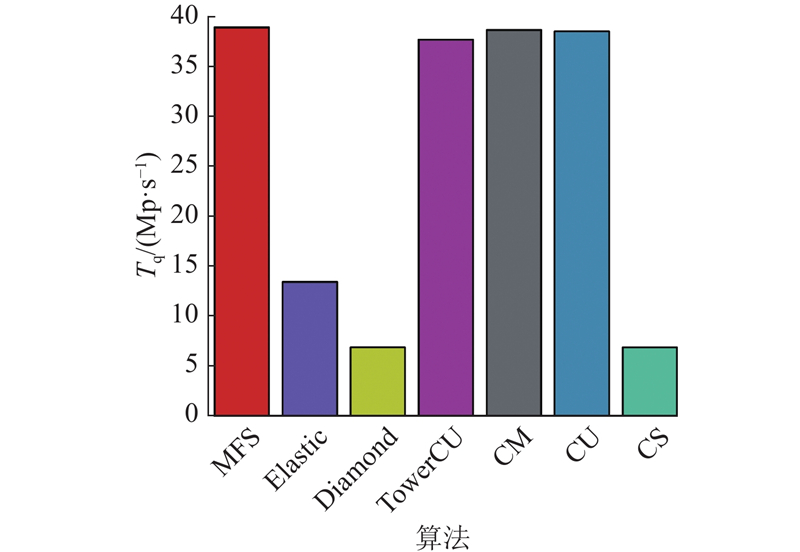
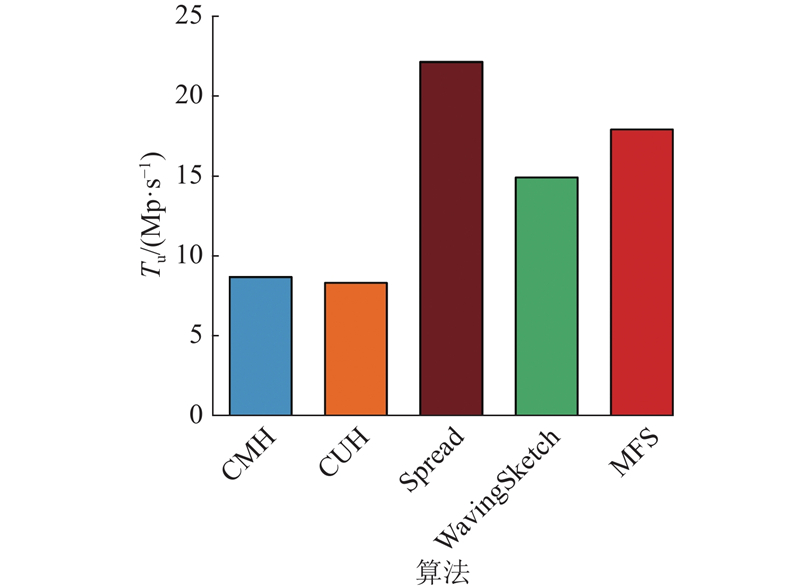
A novel multiple filter sketch (MFS) was proposed and analyzed for theoretical errors to address the problem that the classic sketches cannot be directly applied to superspreader measurement. The MFS removed repetitive packets by a front-end streaming filter, so that the superspreader measurement can be finished while considering the flow size estimation. The post-stage statistical filter was divided into three levels of substructures to capture flows with different sizes so as to adapt to the skewed network traffic distribution characteristics in reality. The memory utilization and the measurement accuracy of the sketch were improved. An asymmetric insertion and query algorithm (AIQ) was proposed to quickly finish the insertion and query operations by using the skewed distribution characteristics of the traffic, which can meet the requirement of link forwarding speed. The experimental results show that the proposed multiple filter sketch improves the measurement accuracy of flow size by approximately 2 to 48 times, the measurement accuracy of heavy hitters by approximately 3 to 53 times, and the measurement accuracy of superspreader by about 2.0 to 3.0 times, compared with the current state-of-the-art schemes. The measurement throughput of MFS can be comparable to that of the classical sketch.
LI Zhuo, MENG Jinhu, LIN Shengyan, GAO Yuan, GU Dawei, YOU Chenzhi, LIU Kaihua. Network superspreader measurement algorithm based on multiple filter sketch. Journal of Zhejiang University(Engineering Science)[J], 2025, 59(2): 289-299 doi:10.3785/j.issn.1008-973X.2025.02.007
随着网络的快速发展,网络测量已成为维护网络可靠性的必要手段[1]. 它为大量网络功能的实现提供了充足的信息,比如流量工程[2]、容量规划[3]和拥塞控制[4]等. 其中,流频率测量、大象流测量和超点测量等是实现上述网络工程的基础[5-6]. 流频率是某段测量时间内具有相同流标识的数据包总和. 大象流指其流频率与所有流的流频率和的比值超过一定阈值的流,它的出现与网络异常强相关[7]. 超点指具有很多不同连接的主机,比如受分布式拒绝服务(distributed denial of service, DDos)攻击的服务器[8]、受蠕虫病毒感染的主机[9]、端口扫描[10]等.
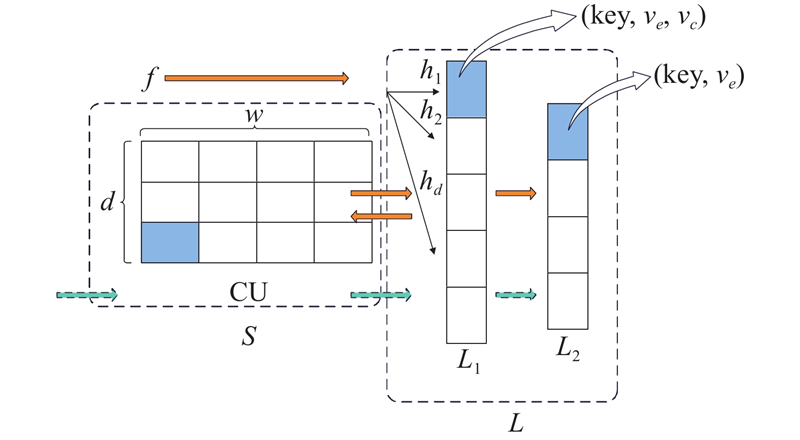
为了兼顾算法的插入吞吐量和查询吞吐量,提出非对称的插入查询算法AIQ. 如图1所示,插入与查询的所有可能路径分别用实线和虚线箭头标注. 假设插入流标识为$ f $的数据包,
L1首先被访问,根据在L1中流标识$ f $的匹配情况和相关计数器的溢出情况,决定接下来是否需要访问CU或L2. 虽然先访问L1,但是L1只允许在流标识匹配成功时才能插入. 所有流实际上是先插入CU,然后逐渐变大后进入L1,此时L1部分才真正有流插入. 当查询流$ f $时,CU可以先被访问. 这种插入时先访问L1而查询时先访问CU的方式得益于偏态的流分布特征,可以让少数大象流快速插入L1,增加插入吞吐量,又可以使得CU立即返回大部分小流的查询结果,增加查询吞吐量.
1.2.1. 插入过程
在测量开始时,L部分和S部分的计数器被清空,流标识字段置为空. 所有输入的数据包首先通过哈希$ {h_1} $访问L1. L1只允许在流标识匹配的情况下插入,所以若$ {h_1} $索引到的桶的流标识与输入数据包的流标识$ f $不匹配,则会尝试进行第2次哈希$ {h_2} $定位第2个桶,继续判断桶中流标识是否与$ f $匹配. 若不匹配,则至多进行$ d $次哈希计算尝试匹配,记录哈希值. 根据L1中流标识的匹配情况和计数器的溢出情况,决定访问L2或CU. 算法1详细描述了插入过程,以流标识为$ f $的数据包为例,分6种情景解释插入.
2) L1中流标识匹配成功,但是对应的计数器${v_e}$在插入之前已经溢出,流$ f $将插入L2. 在L1中可能进行了$ n $($ n \in [1:d] $)次哈希计算,流标识匹配成功,$ n $至少为1,所以$ {r_1} $必然是有效的. 利用$ {r_1} $在L2中索引一个桶,如果其流标识与$ f $不匹配,那么遍历L2找到与$ f $匹配的桶,将对应的$ {v_e} $加1. 若找不到流标识为$ f $的桶,则放弃在L2中的插入,插入结束.
4) L1中没有与$ f $匹配的流标识,且在CU中对应的计数器在插入后未发生溢出. 流$ f $借助$ {r_1},{r_2}, \cdots ,{r_d} $插入CU中,将对应的计数器加1.
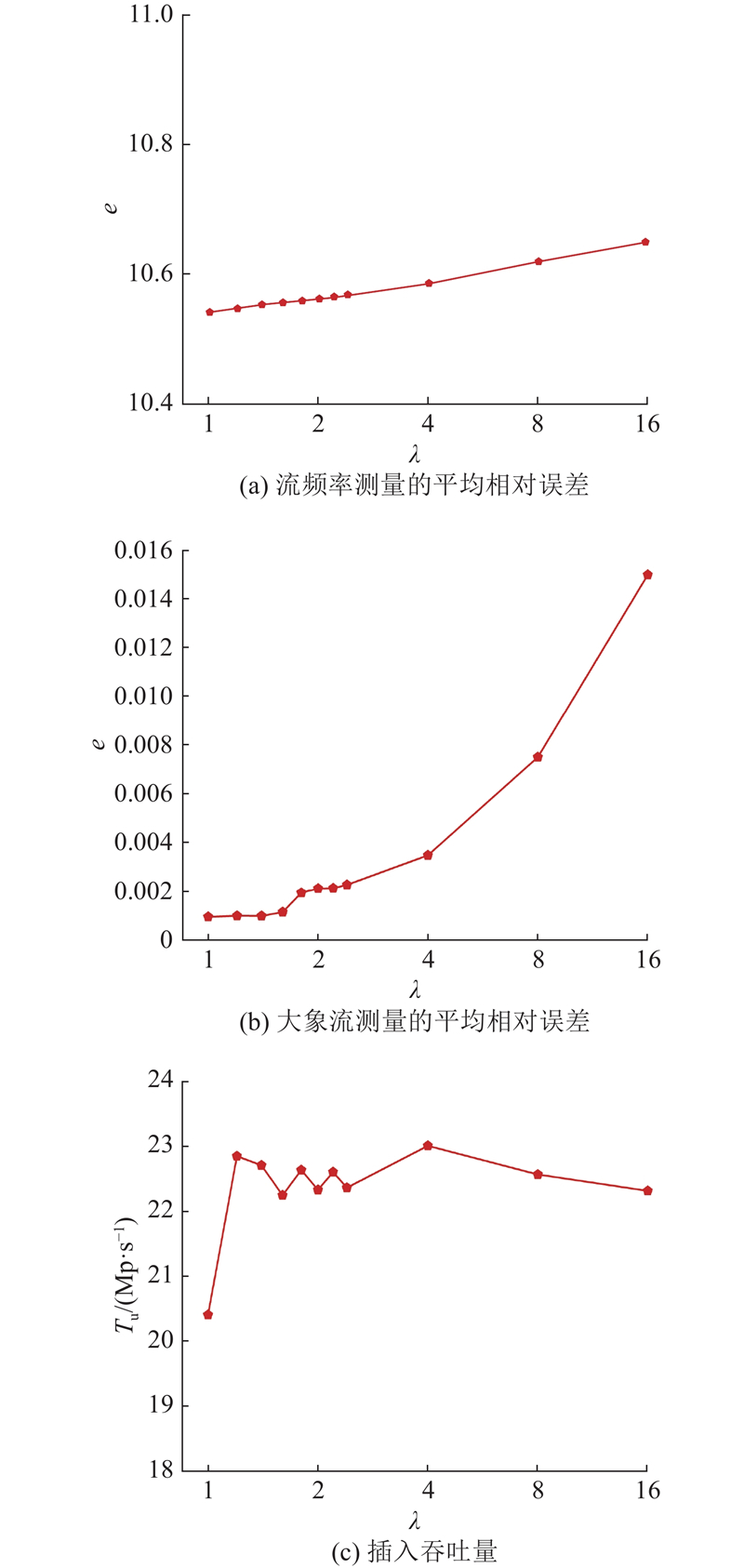
5) L1中没有与$ f $匹配的流标识,且CU中对应的计数器插入之前已经发生溢出. 该数据包以CU的方式更新L1中$ d $个桶中的计数器$ {v_c} $. 将$ d $个桶中${v_e}$和$ {v_c} $的最小值分别记作$ {X_{\min }} $和$ {Y_{\min }} $,对应的桶索引分别记作$ l $和$ m $. 如果$ {Y_{\min }} > \lambda {X_{\min }} $,那么触发流替换,将$ (f,{Y_{\min }}) $插入桶$ l $中. 桶$ l $之前的流$ ({f_m},{X_{\min }}) $额外进行$ d $次哈希计算,将对应桶的计数器$ {v_c} $赋值为$ {X_{\min }} $.
6) L1中没有匹配的流标识,且CU中对应的计数器在插入之后发生溢出. 流$ f $将插入L1对应的$ d $个桶中. 若这$ d $个桶中存在空桶,则将该空桶的流标识字段$ {\text{key}} $置为$ f $,${v_e}$置为1,否则以CU的方式更新$ d $个桶的计数器$ {v_c} $,如算法1的38~41行.
1.2.2. 查询过程
给定流标识$ f $,查找对应频率的过程,如算法2所示.
算法2 AIQ查询算法
Input: 流标识$ f $ Output:$ f $的频率
1: Procedure QUERY ($ f $) 2: $ {v_0} \leftarrow $CU查询值 3: if$ {v_0} < {\tau _0} $then 4: return$ {v_0} $ 5: else 6: $ {v_1} \leftarrow $L1查询值 7: if$ {v_1} \lt {\tau _1} $then 8: return$ {v_1}+{\tau _0} - 1 $ 9: else 10: returnL2查询值 11: function QUERY_CU($ f $) //返回CU查询值 12: for$ i $=1 to d 13: $ {r_i} \leftarrow {h_i}(f) $ 14: return min (CU [$ {r_i} $]) 15: function QUERY_L1($ f $) //返回L1查询值 16: for$ i $=1 to d 17: ifL1[$ {r_i} $].Key=fthen 18: returnL1[$ {r_i} $].${v_e}$ 19: return min (L1[$ {r_i} $].$ {v_c} $) 20: function QUERY_L2($ f $) //返回L2查询值 21: ifL2中存在匹配$ f $的桶$ k $then 22: returnL2[$ k $].$ {v_e} $+$ {\tau _0} - 1 $ 23: else 24: return$ {\tau _1}+{\tau _0} - 1 $
进行$ d $次哈希计算查询CU中$ d $个计数器的值,记录哈希值. 如果$ d $个计数器的最小值$ {v_0} $小于$ {\tau _0} $,那么直接返回$ {v_0} $. 否则,利用记录的哈希值查询L1. 若L1中存在流标识为$ f $的桶,且查询值对应的$ {v_1} $小于$ {\tau _1} $,则返回$ {v_1}+{\tau _0} - 1 $. 若$ {v_1} $等于$ {\tau _1} $,则继续查询L2. 当查询L2时,利用$ {r_1} $索引一个桶,若该桶的流标识与$ f $相同,则直接返回该桶计数器$ {v_e} $与$ {\tau _0} - 1 $的和. 否则,遍历L2,若存在与$ f $相同的流标识,则返回该桶计数器$ {v_e} $与$ {\tau _0} - 1 $的和. 若L2中不存在流标识$ f $,则返回$ {\tau _1}+{\tau _0} - 1 $作为查询结果,如算法2的第24行. 若在L1中不存在与$ f $相匹配的流标识,则返回$ d $个桶的$ {v_c} $的最小值与$ {\tau _0} - 1 $的和.
根据分层计数草图理论(layered counting sketch, LCS)[22]可知, CU和MI-SBF的理论数据结构是分层计数草图. 具体来说,当流标识为$ f $的流在CU或MI-SBF中的流频率估计误差上界为$ k $时,它们对应层数为$ k $的分层计数草图. CU的估计误差与假阳性概率有如下关系:
GENG N, XU M, YANG Y, et al. Adaptive and low-cost traffic engineering based on traffic matrix classification [C]// International Conference on Computer Communications and Networks. Honolulu: IEEE, 2020: 1-9.
YANG K, LI Y, LIU Z, et al. SketchINT: empowering int with towersketch for per-flow per-switch measurement [C] // International Conference on Network Protocols. Dallas: IEEE, 2021: 1-12.
DING R, YANG S, CHEN X, et al. Bitsense: universal and nearly zero-error optimization for sketch counters with compressive sensing [C]// Proceedings of the ACM SIGCOMM 2023 Conference . New York: ACM, 2023: 220-238.
JONATH K, LIU Z. Analysis of cyber security rebuts and its rising aims on current technologies [C]// International Conference on Computer Network Security and Software Engineering. Zhuhai: IEEE, 2022: 134-141.
SONG G, HE L, ZHAO T, et al. Which doors are open: reinforcement learning-based internet-wide port scanning [C]// International Symposium on Quality of Service. Orlando: IEEE, 2023: 1-10.
ZHOU Y, JIN H, LIU P, et al. Accurate per-flow measurement with bloom sketch [C] // IEEE Conference on Computer Communications Workshops. Honolulu: IEEE, 2018: 1-2.
LI J, LI Z, XU Y, et al. WavingSketch: an unbiased and generic sketch for finding top-k items in data streams [C] // 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event. California: ACM, 2020: 1574-1584.
ESTAN C, VARGHESE G, FISK M. Bitmap algorithms for counting active flows on high speed links [C]// Proceedings of the 3rd ACM SIGCOMM Conference on Internet Measurement . San Francisco: ACM, 2003: 153-166.
COHEN S, MATIAS Y. Spectral bloom filters [C]// Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data . San Francisco: AC-M, 2003: 241-252.
EINZIGER G, FRIEDMAN R. A formal analysis of conservative update based approximate counting [C]// International Conference on Computing, Networking and Communications. Anaheim: IEEE, 2015: 255-259.
... 根据分层计数草图理论(layered counting sketch, LCS)[22]可知, CU和MI-SBF的理论数据结构是分层计数草图. 具体来说,当流标识为$ f $的流在CU或MI-SBF中的流频率估计误差上界为$ k $时,它们对应层数为$ k $的分层计数草图. CU的估计误差与假阳性概率有如下关系: ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}