

学者设计特定的数据结构来存储图流,以实现高效的图流分析. 大数据应用产生的图流规模巨大,导致存储完整图流信息的内存开销增加,因此基于近似存储的图流概要技术备受关注. 典型的图流概要技术如TCM[8]、gMatrix[9]和DMatrix[10]使用多个独立的邻接矩阵来近似地储存图流. 该项技术未有效缓解边间冲突,图流测量的准确性有待提高. 为了进一步提高测量精度,GSS[11]和Cuckoo Matrix[12] 通过在邻接矩阵中储存边的指纹对和权重的方式实现了精确的图流查询. GSS和Cuckoo Matrix须记录所有边的指纹,因此内存消耗高. 图流测量除了要准确地完成基于权重的查询任务外,还要完成实时的周期边查询. 周期边查询旨在发现以固定时间间隔到达的边. 在网络流量图中,检测周期性到达的边可以预防和检测破坏性强、危害极大的高持续威胁(advanced persistent threats, APT)攻击[13-14],维护网络的安全稳定. 在金融交易图流中存在短时间的大量金钱交易流,通过实时检测超过特定阈值的周期性交易流,能够快速发现可疑客户[15-16]. 此外,通过检测周期性的交易流还能了解用户购买行为的规律[17]. 现有的图流概要技术仅在邻接矩阵储存图流的权重信息,未储存图流的时间信息,检测周期边须借助边上一次到达的时间信息来确定图流的边是否具有周期性. 现有的图流概要技术无法测量图流中的周期边. PeriodicSketch[15]虽然能发现数据流的周期项,但是受到结构限制,图的底层结构未保留,无法执行其他图流查询.
由以上分析可知,现有的图流概要技术既不能在有限的内存中实现高精度和高速度图流测量,也不能储存时间信息来完成周期边测量. 本研究提出面向周期边测量的图流概要技术——周期交互矩阵(periodic interaction matrix, PIM). PIM由二维邻接矩阵和三维邻接矩阵组成. 二维邻接矩阵存储重边的标识、时间戳和权重,三维邻接矩阵存储轻边的权重,使PIM能够在有限内存下实时完成包括周期边查询在内的多种查询任务. 本研究提出基于权重和基于时间的替换策略,使用共享哈希技术来提高图流查询精度和插入查询速度.
1. 相关工作
现有的图流概要技术可分为2类:基于三维邻接矩阵的图流概要技术和基于二维邻接矩阵的图流概要技术. 基于三维邻接矩阵的图流概要技术的本质是使用由k个邻接矩阵组成的三维结构来存储图流. 每个矩阵大小相同,使用独立的哈希函数来压缩图流. TCM将图流中的边通过哈希函数平等的映射到每个矩阵对应的储存单元(桶)中以统计边的权重. gMatrix使用可逆哈希函数近似存储图流,通过使结构具备可逆性来实现图流的实时测量. 为了提高频繁边查询的准确性,Hou等[10]将多数投票算法与TCM结合,提出DMatrix,利用多数投票算法选出重边,再将边的键存入桶中以准确记录重边的权重. 由于桶内其他的边会被聚合,导致DMatrix的整体精度低. 基于三维邻接矩阵的图流概要技术算法简单,具有较高的插入和查询速度,但是该项技术测量的准确性有待提升.
为了进一步提升测量的准确性,学者开始研究基于二维邻接矩阵的图流概要技术. GSS在矩阵的每个桶中记录边的指纹对和权重,使用方形散列技术和额外的缓冲区提高测量精度. Chen等[18]基于GSS提出Scube,使用图流节点度估计模型和动态地址分配方法进行倾斜图流的高效测量. 为了进一步提高GSS的插入和查询速度,Li等[12]提出Cuckoo Matrix. 该方法为每条边分配原始桶和候选桶,并在桶内设计多个单元来记录边的指纹对和权重,以快速准确地完成图流概要. 基于二维邻接矩阵的图流概要技术通过在邻接矩阵中储存边的指纹对和权重来实现精确的图流概要,但是该项技术不仅算法复杂,而且会储存所有边的指纹,导致时空开销很大,无法在小内存场景中取得准确的测量结果.
此外,上述图流概要技术均无法完成周期边测量. 因此,当前的图流概要技术无法在小内存下快速准确地完成图流查询,且不支持周期边测量.
2. 周期交互矩阵结构
高效完成多种查询任务的关键在于快速分离并使用不同的策略来储存轻重边. 如图1所示为PIM的数据结构,它由二维邻接矩阵SL、三维邻接矩阵DL和地址分配模块3个部分组成. SL用来储存重边,DL用来储存轻边,地址分配模块用来为边和节点生成SL和DL中的索引. SL为包含
图 1
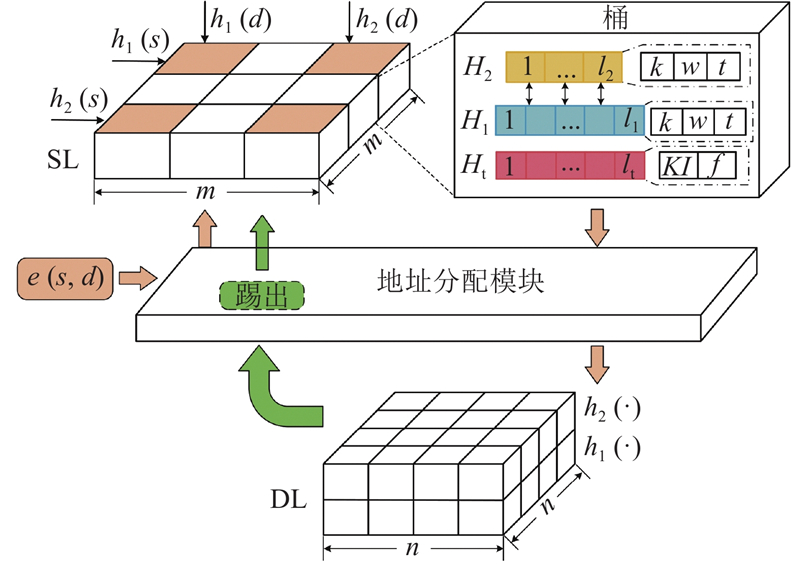
3. 基于周期交互矩阵结构的插入查询算法
3.1. 插入算法
为了提高边和节点的索引速度,PIM在地址分配模块使用共享哈希函数技术,SL和DL共用2个哈希函数h1和h2. 在SL中,到达的边(s,d)通过地址分配模块被h1和h2映射到4个桶中,以寻找位置储存,缓解了多条边聚合产生的冲突. 在DL中,地址分配模块使用h1和h2来分别得到(s,d)在2个邻接矩阵的索引位置. 共享哈希函数技术能快速得到边和点在PIM中的储存位置以提高插入和查询速度. 本研究提出能快速分离轻重边的投票替换策略以提高测量精度.
为了完成周期边测量,本研究提出时间投票替换算法. 周期边常由时间间隔
算法1 时间投票替换算法
输入: 边
1: Procedure Insert_Time (e,
2: for k = 0 to
3: if
4:
6: else if
7:
8:
10: else if k ==
11: if
12:
13:
14: if
15: 在
PIM的插入过程如算法2所示. 对于到达的边e,通过地址分配模块得到SL中需要访问的4个桶
算法2 插入算法
输入: 边
1: Procedure Insert(e)
2:
3: for i =1 to 4
4: InsertBucket(
5: if 在SL中插入失败then //开始在DL中插入
6:
7:
8: if
9: Kick_out(e,
10: else if
11: Kick_out(e,
12: function InsertBucket(B) //用于在DL桶中插入
13: for j=0 to
14: InsertCell(e,
15: for j=0 to
16: InsertCell(e,
17: if
18:
20: if
21:
22: function InsertCell (e, B.cell)
23: if
24: 计算
25: InsertTime(e,
26: else if cell.k==0 then
27: 在cell中插入,结束
28: function KickOut (e,
29:
30:
31: 在cell中记录
3.2. 查询算法
3.2.1. 节点权重查询算法
节点权重查询分为节点流出权重查询
算法3 节点权重查询算法
输入: 节点s
输出: 节点s的估计权重
1: Procedure NodeQuery (s)
2:
3: 访问
4: if 单元中k与
5:
6:
7: for i=0 to n−1
8:
9:
10:
11: return
3.2.2. 频繁边、频繁点和周期边查询
频繁边查询的任务是找出所有权重大于
3.2.3. 误差分析
假设DL的参数n =
引理 设向量V = [v1, v2, ···, vn]为图流的节点向量,
式中:
证明 由于哈希冲突,容易得到
由马尔科夫不等式得到
4. 实验与结果分析
4.1. 实验设置
4.1.1. 实验环境
实验平台为具有24核 3.50 GHz i9-10920X处理器和64GB DDR4 DRAM 的服务器,操作系统为Ubuntu18.04.6,所有方案均使用C++实现.
4.1.2. 实验参数
在相同内存下,使用2个真实应用中的数据集对PIM、PTCM、PDMatrix、PCuckoo Matrix (简称PCuckoo)以及PeriodicSketch (简称Periodic)的准确性和速度进行评估. PTCM、PDMatrix和PCuckoo是将布隆过滤器[19]和图流概要技术结合后的改进方案,可以同时完成包括周期边查询在内的多种查询任务,Periodic仅用于周期边查询实验. 在实验中,DL与总内存之比为r,r的设置由节点查询、频繁边查询、频繁点查询以及周期边查询的平均相对误差来综合考量. 如图2所示,随着r由0.1增大到0.9,节点查询的平均相对误差先下降后上升,且在0.2到0.4的误差较低. 频繁边查询和频繁点查询在0.2时平均相对误差最低,周期边查询在0.1到0.5的平均相对误差较低. 为了准确完成上述4个查询,设置r=0.2. 为了方便实现PIM,计数器的大小设置为2的整数次幂. 根据实验测试,在SL的H1和H2中,每个单元k和t的内存大小设置为8字节,可存储边的标识和时间戳,w的v1和v2设置为2字节和4字节,可最佳区分重边和超重边. Ht中KI和f的内存大小分别设置为12字节和4字节. 在SL中每个桶的l1、l2和lt分别被设置为25、5和100,可取得最佳的准确性. 在DL中,每个计数器的内存大小设置为1字节,可最佳区分轻重边. 根据数据集中前100条频繁边、频繁点以及周期边得到查询的阈值. 对比方案的其他参数设置与原文献中的保持一致.
图 2
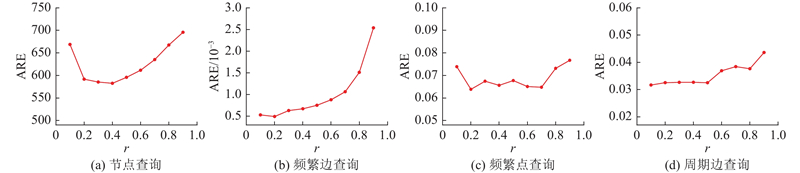
图 2 三维邻接矩阵内存大小与总内存大小占比实验
Fig.2 Experiment with ratio of memory size of three-dimensional adjacency matrix to total memory size
4.1.3. 数据集
4.1.4. 评价指标
1) 平均相对误差ARE:测量任务中所有查询误差的平均值为平均相对误差. 查询误差为真实值与测量值之差的绝对值与真实值的比值. 2) 调和平均数F1=2×精确率×召回率/(精准度+召回率). 以频繁边为例,精确率为方案找到的频繁边中真实频繁边的占比,召回率为所有频繁边中被找到的频繁边的占比. 3) 平均查询时间:测量任务中所有查询消耗时间的平均值.
4.2. 实验结果与分析
4.2.1. 节点权重查询
如图3所示为不同规模数据集的节点权重查询平均相对误差. 在Network-Flow中,当内存S=40 MB时,PIM的平均相对误差与PDMatrix和PTCM相比分别降低了1个数量级和2个数量级. 在Wiki中,当S=150 MB时,PIM的平均相对误差与PDMatrix和PTCM相比分别降低了91.41%和95.79%. 在Lkml中,当S=32 MB时,PIM的平均相对误差与PDMatrix、PTCM和PCuckoo相比分别降低了99.95%、99.98%和95.87%. 原因是PIM在DL中使用2个邻接矩阵存储节点权重,提高了测量的准确性. 此外,PIM使用不同大小的计数器存储不同权重的节点,提高了内存利用率. 因此,PIM的整体测量精度更高. 由于PCuckoo储存所有节点的指纹,其节点权重查询的误差很小. 在有限内存下,PCuckoo会丢失一部分节点信息,导致无法准确地完成频繁边查询等其他测量任务.
图 3
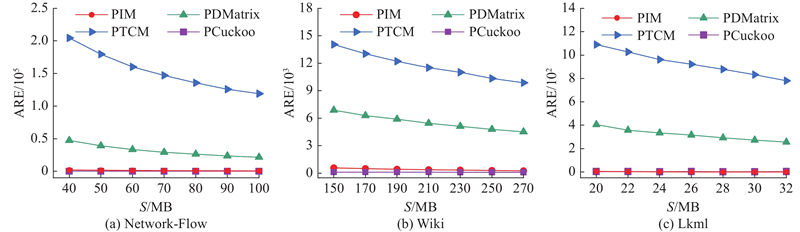
图 3 不同图流概要技术在3个数据集中节点权重查询的平均相对误差
Fig.3 Average relative error of node weight query using different graph stream summarization techniques in three datasets
4.2.2. 频繁边查询
如图4所示为不同规模数据的频繁边查询平均相对误差. 在Network-Flow和Lkml中,PIM的平均相对误差达到零,极大地减少了PDMatrix、PTCM和PCuckoo的平均相对误差. 此外,PCuckoo在Network-Flow中无法找到频繁边. 在Wiki中,当S=150 MB时,PIM的平均相对误差与PCuckoo、PDMatrix以及PTCM相比分别降低了2个数量级、3个数量级和4个数量级. 原因是PIM通过投票替换策略快速分离轻重边,减少了轻边对重边的影响. 此外,PIM在SL中记录了重边的标识,并在每个桶中设置了多个包含16比特和32比特计数器的单元,以存储重边和超重边. 因此,PIM能实时准确地完成频繁边查询.
图 4
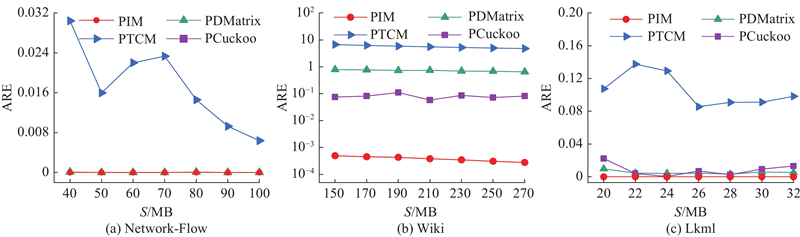
图 4 不同图流概要技术在3个数据集中频繁边查询的平均相对误差
Fig.4 Average relative error of heavy hitter edge query using different graph stream summarization techniques in three datasets
4.2.3. 频繁点查询
如图5所示为不同规模数据的频繁点查询平均相对误差. 实验结果显示,PIM在所有实验内存,尤其是小内存下,明显优于对比方案. 在Network-Flow中,当S=40 MB时,PIM的平均相对误差与PDMatrix相比降低了1个数量级,与PTCM和PCuckoo相比降低了2个数量级. 在Wiki中,当S=150 MB时,PIM的平均相对误差与PDMatrix、PTCM和PCuckoo相比分别降低了99.54%、92.40%和92.39%. 在Lkml中,当S=20 MB时,PIM的平均相对误差与PDMatrix、PTCM和PCuckoo相比分别降低了99.99%、99.99%和99.97%. 原因是PIM在DL中为每个节点分配了2个哈希函数,并使用2个邻接矩阵来存储节点信息,以适应不同节点度的图流. 此外,PIM在SL中为每个节点分配2个索引,并在每个桶中设置多个单元来储存同一源节点的不同边,使PIM能实时准确地完成频繁点查询.
图 5
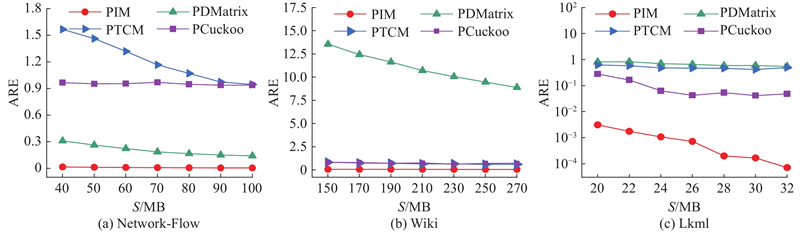
图 5 不同图流概要技术在3个数据集中频繁点查询的平均相对误差
Fig.5 Average relative error of heavy hitter node query using different graph stream summarization techniques in three datasets
4.2.4. 周期边查询
如图6所示为不同规模数据的周期边查询平均相对误差. 在Network-Flow中,PIM和Periodic的平均相对误差均小于0.5%,能实现准确的周期边测量. PIM与PDMatrix、PTCM以及PCuckoo相比,平均相对误差减少了2个数量级. 在Wiki中,当S=150 MB时,PIM的平均相对误差与PDMatrix、PTCM以及PCuckoo Matrix相比降低了2个数量级. 在Lkml中,当S=20 MB时,PIM的平均相对误差与PDMatrix、PTCM以及PCuckoo相比降低了93.51%、93.23%和98.23%. 原因是PIM在SL中记录边的时间戳和标识,同时采用时间投票替换算法选出多次出现的周期边,以实现准确的周期边查询.
图 6
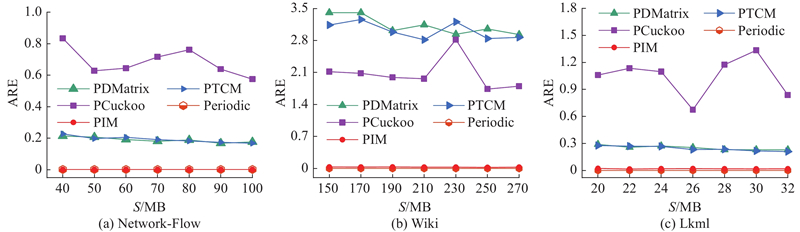
图 6 不同图流概要技术在3个数据集中周期边查询的平均相对误差
Fig.6 Average relative error of periodic edge query using different graph stream summarization techniques in three datasets
4.2.5. 调和平均数
如图7所示为不同规模数据集的频繁边、频繁点和周期边调和平均数. 在Network-Flow中,对于频繁边查询,PIM的调和平均数为1,与PDMatrix性能相同,优于PTCM. 此外,PCuckoo的调和平均数为0,无法完成频繁边查询. 对于频繁点和周期边查询,PIM的调和平均数非常接近1,优于PDMatrix、PTCM和PCuckoo Matrix,且与先进的周期测量方案Periodic性能相近. 在Wiki中,PIM3个任务的调和平均数接近1,明显优于PDMatrix、PTCM和PCuckoo. 在Lkml中,对于频繁边和频繁点查询,PIM的调和平均数为1,高于PDMatrix、PTCM和PCuckoo. 对于周期边查询,PIM的调和平均数与Periodic相近,优于其他对比方案. 这说明PIM可以准确地找到图流中的频繁边、频繁点和周期边,基本没有出现假阳性错误. 原因是PIM将轻重边分开储存,并在SL中记录了边的时间戳和标识. 此外,PIM使用基于权重和基于时间的投票替换策略快速分离轻重边,能够实时准确地完成图流查询.
图 7

图 7 不同图流概要技术在3个数据集中频繁边、频繁点和周期边查询的调和平均数
Fig.7 Harmonic mean of heavy hitter edge, heavy hitter node, and periodic edge queries using different graph stream summarization techniques in three datasets
4.2.6. 插入查询时间
如表1所示为在Network-Flow中不同图流概要技术的平均插入时间和平均查询时间. PIM的平均插入时间与PDMatrix相比降低了35.47%,与PTCM相比降低了24.88%,与PCuckoo相比降低了97.33%. 原因是PIM的SL和DL共享2个哈希函数,减少了哈希次数. PIM的平均插入时间明显高于Periodic,原因是PIM须完成多项测量任务,操作复杂,而Periodic只进行周期边测量,操作相对简单. 对于节点权重查询,PIM的平均查询时间成本与PDMatrix相比降低了49.9%. 由于PIM须访问SL和DL中的多个单元,平均节点权重查询时间高于PTCM和PCuckoo. 对于频繁点查询,PIM的平均查询时间与PTCM和PCuckoo相比分别降低了72.23%和53.98%,略高于PDMatrix. 对于频繁边和周期边查询,PIM的平均查询时间与PDMatrix、PTCM和PCuckoo相比降低了68.91%~99.91%,且与Periodic的周期边查询时间相近. 原因是PIM只需查询SL即可得到频繁边和周期边的查询结果.
表 1 不同图流概要技术在Network-Flow数据集中插入和查询操作的平均时间成本
Tab.1
| 方案 | t/s | ||||
| 插入 | 节点权重查询 | 频繁边 查询 | 频繁点 查询 | 周期边 查询 | |
| PIM | 1.51×10−7 | 2.41×10−5 | 3.42×10−3 | 6.07 | 3.47×10−3 |
| PDMatrix | 2.34×10−7 | 4.81×10−5 | 1.10×10−2 | 4.44 | 2.88 |
| PTCM | 2.01×10−7 | 2.08×10−5 | 3.77 | 21.86 | 3.19 |
| PCuckoo | 5.67×10−6 | 9.12×10−6 | 3.49 | 13.19 | 4.99 |
| Periodic | 4.08×10−8 | — | — | — | 4.15×10−3 |
5. 结 语
本研究提出面向周期边测量的图流概要技术——PIM. PIM使用2种结构的邻接矩阵分别存储轻、重边,提高了查询精度和内存利用率,在存储重边的邻接矩阵中记录边标识、权重以及时间戳,能够实时完成频繁边、频繁点、周期边查询等多种查询任务. 本研究设计适配PIM结构的插入和查询算法,采用替换策略和共享哈希技术,提高了整体准确性和插入查询性能. 实验结果表明,与其他方案相比,PIM能在小内存下实时高效地完成图流测量,提高了多个查询任务的准确性. 在未来研究中,计划将PIM应用于更大规模且更复杂的图流场景,以进行更深入的图流概要研究.
参考文献
Empowering smart city situational awareness via big mobile data
[J].
Hierarchical and networked vehicle surveillance in ITS: a survey
[J].DOI:10.1109/TITS.2014.2340701 [本文引用: 1]
Toward query-friendly compression of rapid graph streams
[J].DOI:10.1007/s13278-017-0443-4 [本文引用: 1]
DMatrix: toward fast and accurate queries in graph stream
[J].DOI:10.1016/j.comnet.2021.108403 [本文引用: 2]
Graph stream sketch: summarizing graph streams with high speed and accuracy
[J].DOI:10.1109/TKDE.2022.3174570 [本文引用: 1]
Cuckoo matrix: a high efficient and accurate graph stream summarization on limited memory
[J].DOI:10.3390/electronics12020414 [本文引用: 2]
Advanced persistent threats (APT): an awareness review
[J].
Anti-money laundering: using data visualization to identify suspicious activity
[J].DOI:10.1016/j.accinf.2019.06.001 [本文引用: 1]
Online sales prediction via trend alignment-based multitask recurrent neural networks
[J].DOI:10.1007/s10115-019-01404-8 [本文引用: 1]
Space/time trade-offs in hash coding with allowable errors
[J].DOI:10.1145/362686.362692 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}