

通过对软件进行分类,可以更有效地管理和维护软件系统[1]. 在软件安全方面,对不同类型的软件进行分类,还能实施差异化的管控,制定安全策略.
目前,针对自动软件分类的研究较少. Canedo等[2]采用多种机器学习技术来分析和处理软件需求文档,能够有效地从复杂的需求文本中提取关键特征,根据这些特征对需求进行精准分类. Tanjong等[3]比较3种流行的需求文档分类技术,通过3个不同的数据集进行评估. 这些技术都没有发挥软件代码在分类中的作用. 双向编码表示转换(bidirectional encoder representations from transformers, BERT)[4]的出现为许多自然语言处理模型提供了新方向,比如基于代码的BERT(code based BERT, CodeBERT)[5]是专为源码设计的语言模型,利用多头注意力机制[6-10],为源代码提供丰富的语义表示.
针对上述问题,本文提出基于BERT的双模态软件分类模型. 针对软件描述文本的分类,结合基于掩码语言模型的纠错BERT (masked language model as correction BERT, MacBERT)与CNN,提出软件描述文本分类模型. 为了利用软件代码进行分类并提高软件分类的鲁棒性与精确度,分别采用基于BERT的2种编码器MacBERT和CodeBERT,为软件描述和代码进行双向编码. 基于自注意力机制原理,提出交叉自注意力机制(cross self-attention mechanism, CSAM).
1. 相关理论
1.1. BERT
在软件分类任务中,采用BERT模型对输入的软件描述文本和软件源代码进行深度表征学习,得到丰富的特征表示. 传统的文本分类技术,例如词袋模型(bag of words, BoW)[11]和术语频率-逆文档频率(term frequency-inverse document frequency, TF-IDF)[12],为简单的软件文本分类任务提供了有效的解决方案,但在捕获软件文本中的深层语义关系方面存在明显的局限性. BERT代表语言类深度学习模型的巨大进步,采用Transformer架构并创新性地引入自注意力机制,能够捕获文本中的长距离依赖关系和复杂的上下文结构. 这种设计使得BERT模型能够直接对软件文本进行深度编码,将依靠软件描述文本进行软件分类的问题转换为深度学习表征问题,实现前所未有的分类精度. 随着BERT的成功,研究者进一步探索它的潜能. Lan等[13]在BERT的基础上提出ALBERT,通过句子顺序预测任务替换BERT的下一个句子预测任务,并且增加参数共享,在保持模型高性能的同时,显著减小了模型大小和参数数量. Liu等[14]在BERT的基础上,提出RoBERTa,使用更大的预训练数据集和更长的训练时间,舍弃下一句预测(next sentence prediction,NSP)任务,获得更好的预训练和微调性能. 在利用软件文本进行软件分类的任务中,采用改进后的预训练任务和参数集,可以减少软件文本分类模型的训练时间,提高软件文本分类的精确率.
1.2. 自注意力机制
在软件分类的任务中,需要将处理软件源代码和软件描述文本的模型的输出进行融合. 鉴于2个模型的输出展现不同的特征,采用自注意力机制以增强关键特征,淡化次要特征. 该方法旨在优化模型的整体性能,确保在分类精度和效率方面达到最佳平衡.
自注意力机制是评估输入数据各部分之间相互作用的策略. 对于特定的序列或集合,该机制评估序列中每个元素与其他元素的关联度(通常通过点积计算),利用这些关联度权重生成新的加权表示. 专门设计自注意力机制,以捕获输入数据的长距离依赖关系,自注意力机制的结构如图1所示. 图中,Q、K、V分别为输入矩阵经过全连接层变换得到的查询、键和值矩阵.
图 1
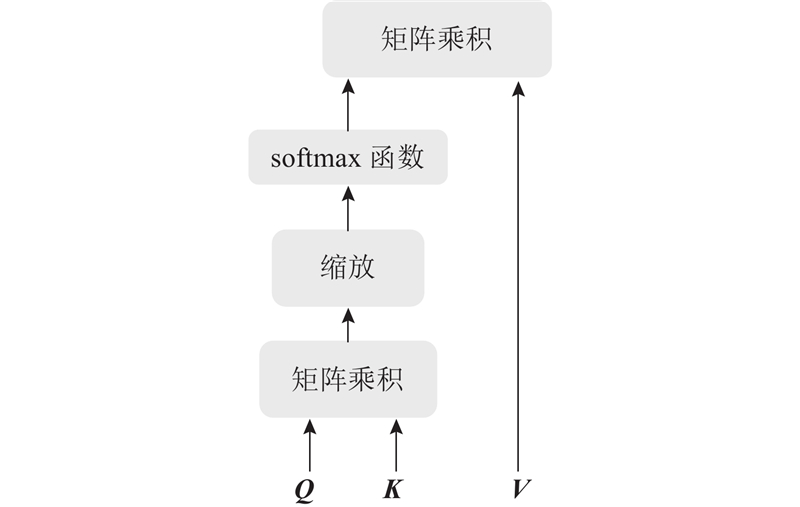
自注意力机制可以描述为将一组查询、键和值映射到输出. 实际计算中,将一组查询、键和值分别表示为矩阵Q、K和V. 矩阵由输入的特征向量X经过线性变换得到,如下所示:
式中:WQ、WK、WV分别为查询、键、值的权重矩阵. 这些矩阵作为模型的关键参数,在训练过程中不断学习与调整. 每个权重矩阵的作用是将输入特征向量X转换到新的表示空间,实现特征的有效提取和转换.
注意力函数的输出值为V的加权和,其中分配给每个值的权重由查询与相应键的softmax函数计算得到,如下所示:
式中:
2. 基于BERT的双模态软件分类模型
从以下几个方面描述软件分类模型,包括对输入的处理、实现分类模型、基本原理和实现细节. 本文使用的方法如下:对代码进行处理,保留代码中的函数名称、参数名称、类名和变量名信息,作为CodeBERT输入. 将软件描述文本的信息输入到基于CNN的MacBERT中[17],以提取局部和全局特征. 对2个模型进行如下的微调操作:提取CodeBERT和MacBERT预训练模型隐藏层的最后一层的输出,将所有词元或标记(在本文中词元或标记统一称为token)的输出进行平均化处理. 利用提出的交叉自注意力机制,确定每个模型的权重,进而实现特征的串联融合,生成新的特征向量. 新的向量经过全连接层和softmax层处理后,产生最终的分类结果.
2.1. 数据预处理
构建包含文本描述和代码段的数据集,数据来源于奥集能平台上使用Go语言编写的开源软件的代码以及对该开源软件的简单描述. 从gitee平台上获取一部分使用Go语言开发的开源软件代码和文本描述. 根据国家标准软件产品的类别,将软件分类为不同类别,形成了包含
图 2

图 2 软件分类数据集每个类别的数据分布
Fig.2 Data distribution of each category in software classification dataset
对于代码部分的处理,首先对代码文本进行预处理,将函数名称、变量名、类名和参数名称都转换成小写的形式,以提高模型的泛化能力,减少特征数量,降低模型处理的复杂度. 鉴于CodeBERT输入限制为最多512个词,因此手动保留函数名称、变量名、类名和参数名称.
对于函数内容,选择仅保留注释部分,认为这些部分通常含有丰富的语义信息. 为了便于理解代码的逻辑结构,函数中的特殊符号被转换为空格. 此外,函数名和类名的保留被视为至关重要,因为这些信息有助于揭示代码中函数间的调用关系. 在处理文本描述信息方面,统计结果表明文本长度的最大值、最小值和平均值分别为370、123和247. 当将文本信息输入到MacBERT模型时,设定输入的最大长度为256. 对于长度不足256的文本,将进行补齐操作,而长度超过256的文本则进行适当截断. 这种标准化处理方式能够确保模型接收到长度一致的输入,提高训练和推断的有效性.
2.2. 交叉自注意力机制
在软件分类任务中,分别采用CodeBERT和MacBERT处理软件代码和软件描述文本. 为了更好地利用2个模型提取的特征,提出交叉自注意力机制对2个模型提取的特征进行融合,旨在捕获软件描述中的多种关联性和上下文信息,增强模型的分类能力,结构如图3所示.
图 3
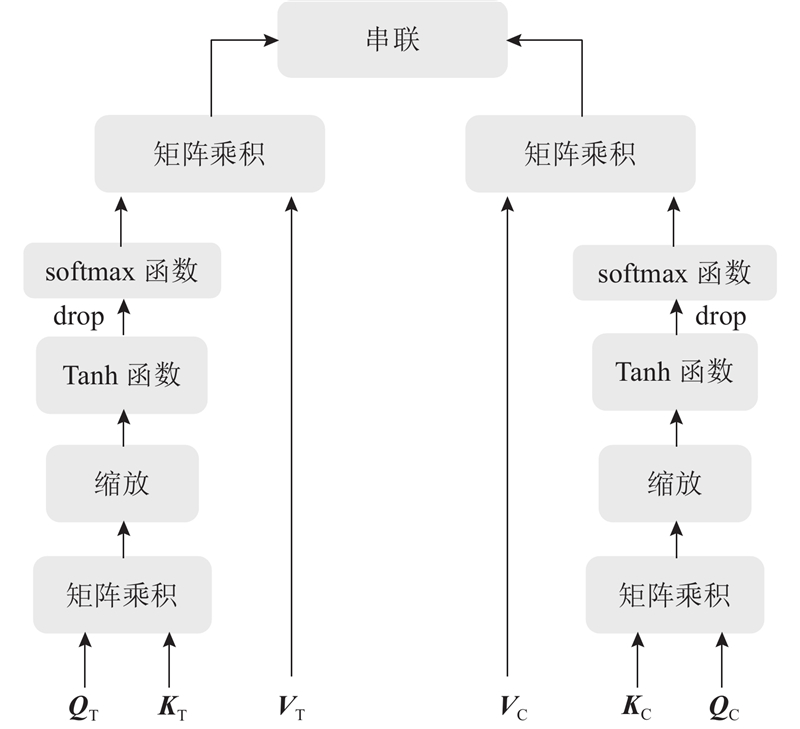
图3中,QC、KC、VC和QT、KT、VT分别为代码特征向量和文本特征向量经过全连接层得到的查询、键和值矩阵.
利用交叉自注意力机制,将软件描述文本和代码信息输入到2个注意力机制通道中. 模块的输入是通过CodeBERT和MacBERT提取出的代码特征向量XC和描述文本的特征向量XT. 这些特征通过全连接层进行线性变换,得到代码特征的QC、KC、VC和描述文本特征的QT、KT、VT.
软件的文本描述通常包含软件的功能和使用场景,是对软件分类的重要依据. 软件代码特征,如变量名、方法名和注释,可以更好地捕捉软件的实际行为和具体实现,在缺失文本描述时独立完成分类任务. 将两部分特征并行输入注意力机制中,使模型学习每个特征对应的权重,更好地融合2个模型.
在本文中,交叉自注意力机制对于处理代码和文本描述信息具有不同的侧重点. 对于代码处理分支,关键变量名、注释和方法名等信息在理解代码的意图方面发挥着至关重要的作用. 在处理文本描述信息的分支中,关键词对于确定软件类别极为重要. 为了使模型能够捕捉更复杂的模式和关系,增强模型在面对未知数据时的泛化能力,在注意力机制中引入Tanh激活函数. 这一步骤旨在提升模型的表达能力. 引入正则化技术,降低模型对训练数据中特定噪声或特征的过度敏感性,防止过拟合现象. 每个分支的注意力输出矩阵如下所示:
式中:O为每个分支的输出矩阵. CSAM模块的最终目的是融合2个模型的结果,更好地分配权重. 将上面算出的分支权重矩阵通过串联操作拼接在一起,得到交叉自注意力机制模块的输出. 该输出为文本和代码特征矩阵的综合权重矩阵,用于后续的模型分类任务.
2.3. 双模态软件分类模型
大量工作表明,在大型语料库上的预训练语言模型可以学习通用语言表示,避免从头开始训练模型[18-19]. 对于特定的下游任务,只需要微调(fine-tuning)预训练语言模型[20]. 这使得模型在小规模数据集上能够取得很高的精度[21]. 为了解决软件分类问题,提出基于BERT的双模态软件分类模型,如图4所示. 其中,Tk1
图 4
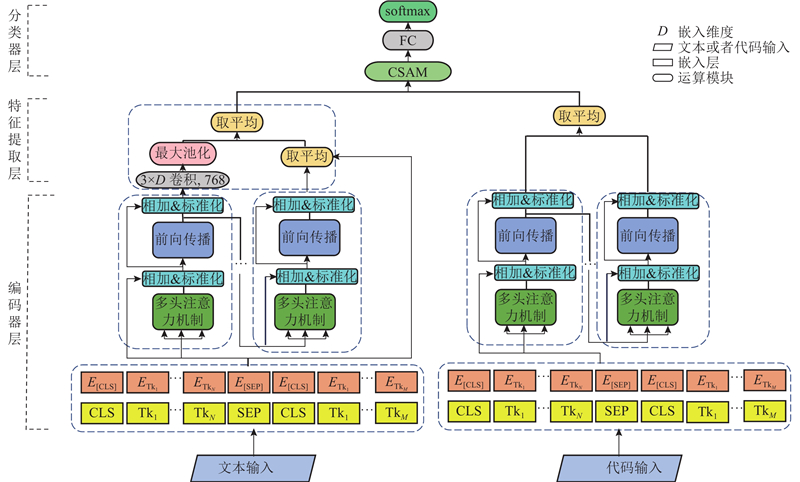
2.3.1. 编码器层
编码器模块分别使用CodeBERT和改进的MacBERT,对软件代码和软件描述文本进行编码. 编码器层中的BERT嵌入层表示如图5所示.
图 5

图5中,Ex(x为E的不同下标)表示不同嵌入层中的token. 分段嵌入用来区分文本中不同的句子. 由于在本例中只涉及单句话,即“使用模型预测下句话”,所有token均被标记为相同的嵌入,用EA表示. 无论是处理代码还是文本描述,CodeBERT和MacBERT的嵌入层均包含以下3个关键部分.
1)标记嵌入(token embeddings). 将代码和软件描述文本转换成固定大小的向量.
2)分段嵌入(segment embeddings). 对于软件描述文本,分段嵌入用于区分描述文本中不同的句子. 对于软件代码,分段嵌入用于区分多个代码片段相关的描述.
3)位置嵌入(position embedding). 对于软件文本描述和代码,位置嵌入的作用都是为了确定词汇在序列中的位置.
3个部分的嵌入相加,生成每个token的统一嵌入,如下所示:
式中:L为嵌入层的输出嵌入表示,
编码器层使用CodeBERT和MacBERT模型的嵌入层处理代码和文本,利用BERT模型预训练特征,生成语义更加丰富的特征向量. 这样的设计充分利用预训练语言模型在大型语料库上学到的通用语言表示,为软件分类任务提供更强大的语义表达.
2.3.2. 特征提取层
通过上层的嵌入层,代码和描述文本已经被表示为语义丰富且具有全局特征的向量. 为了提高对软件描述文本的分类精度,对文本向量进行局部特征的提取. 采用CNN来捕获软件描述文本中的局部显著特征信息,如关键词. 在卷积层使用一维卷积、卷积核为3的卷积运算,提取文本中包含的局部显著特征,如关键短语[22-23]. 为了保留文本的原始特征,在设计时作出新的调整:不直接使用经过BERT完全训练后的向量,将BERT第1层的输出特征向量输入到CNN中. 该方法旨在最大化地利用CNN在捕捉局部关键特征方面的优势. 此外,该方法有助于避免模型的过拟合问题,提高模型对文本内容中细节特征的识别与揭示能力. 这不仅增强了模型在处理具体数据时的准确性,而且提升了模型在新数据上的泛化能力.
对于代码输入,在编码器层中使用CodeBERT,将代码转化为代码向量. 对于代码向量,直接抽取CodeBERT的多层双向Transformer特征提取器的最后一个隐藏层的所有token. 为了获得更加丰富的语义,采用Reimers等[24]提出的将所有token进行取平均的操作,具体如下. 从BERT得到一个句子的token向量集合H,其中每个token的向量是512维的,该句子有n个tokens,则H ={h1,h2
这样的处理方式有助于保留代码中的语义信息,提供更全面的表示,用于后续的模型训练. 之后将处理完毕的文本特征向量和代码特征向量输入到分类器层.
2.3.3. 分类器层
在分类器层,采用交叉自注意力机制来融合文本和代码的特征向量,生成新的特征向量. 该机制允许模型更好地关注文本描述和代码之间的关联性,提高分类任务的性能. 模型通过接入全连接层和softmax层,完成软件的多类别分类任务. 全连接层的作用是进一步提取特征和调整特征权重,softmax层将得到的特征映射到不同的软件类别上,完成最终的分类工作. 该结构的设计能够综合利用文本和代码的信息,增强模型的表达能力,提高软件分类的准确性.
3. 实验与结果
3.1. 实验数据及模型参数
为了解决软件分类问题,提出基于BERT的双模态分类模型. 采用在奥集能和gitee平台上的5 300条软件数据作为数据集,其中软件根据国家软件标准分为12类,分布如图2所示. 为了避免测试偏差,从5 300条软件数据中抽取
使用Intel(R) Core(TM) i5-10505 CPU、16 GB RAM 、GeForce RTX3060. 实验使用Python3.6作为开发语言和pytorch深度学习库,双模态分类模型的具体参数如表1所示.
表 1 双模态分类模型的参数设置
Tab.1
| 参数 | 数值 |
| 迭代数 | 30 |
| 批数量 | 32 |
| 句子长度 | 代码512,文本256 |
| 学习率 | 10−5 |
| 隐藏层数 | 768 |
| Dropout | 0.5 |
| CNN隐藏层数 损失函数 | 1 Cross-entropy loss |
| 优化器 | Adamax |
3.2. 评价方法
采用计算精确率P、召回率R、F1 值(F1-score)来评价算法的效果.
式中:TP、FP、FN分别为真阳性、假阳性和假阴性.
3.3. 实验结果的对比
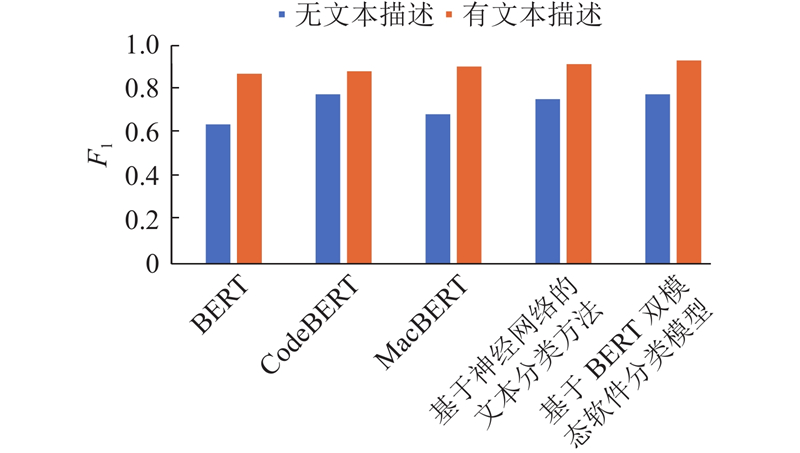
对模型在无文本描述和有文本描述情况下的性能进行测试. 为了验证所提方法的有效性,开展对比实验,将本文方法与常用的BERT分类模型、BERT的变种模型以及神经网络模型进行对比. 具体对比实验所使用的模型包括BERT、CodeBERT、MacBERT及Leclair等[25]提出的“基于神经网络的文本分类方法”.
表 2 没有文本描述情况下各模型的分类结果
Tab.2
| 模型 | P | R | F1 |
| BERT | 0.645 | 0.632 | 0.638 |
| CodeBERT | 0.786 | 0.764 | 0.775 |
| MacBERT 基于神经网络的文本分类方法 | 0.692 0.765 | 0.676 0.743 | 0.684 0.753 |
| 基于BERT双模态软件分类模型 | 0.786 | 0.764 | 0.775 |
在有文本描述的情况下,本文的分类效果如表3所示. 可知,本文方法在有文本描述的情况下具有更好的分类性能.
表 3 有文本描述情况下各模型的分类结果
Tab.3
| 模型 | P | R | F1 |
| BERT | 0.875 | 0.863 | 0.869 |
| CodeBERT | 0.883 | 0.876 | 0.880 |
| MacBERT | 0.903 | 0.901 | 0.902 |
| 基于神经网络的文本分类方法 | 0.913 | 0.912 | 0.913 |
| 基于BERT双模态软件分类模型 | 0.933 | 0.926 | 0.930 |
综上所述,被对比的算法未能充分挖掘代码与文本描述的信息及BERT输出矩阵的特性,导致错误的分类. 本文算法引入多样化的特征提取手段:采用CNN来捕捉局部信息,通过提出的交叉自注意力机制来精准调整2个特征向量的权重,融合出更有效的分类向量,提升分类的准确性. 为了证明提出模型的有效性,分析每个类别的精确率和召回率. 结果显示,除行业应用软件、地理信息软件、中间件软件等数据量较小的软件类别外,其他软件类别的分类精确率都约为95%,证明了提出模型的有效性,分类结果如表4所示.
表 4 各种软件类别的分类结果
Tab.4
| 软件类别 | P | R |
| 行业应用 | 0.908 | 0.913 |
| 网络通信 | 0.951 | 0.948 |
| 语言 | 0.964 | 0.961 |
| 多媒体 | 0.919 | 0.922 |
| 地理信息 | 0.895 | 0.897 |
| 人工智能 | 0.973 | 0.975 |
| 浏览器 | 0.928 | 0.934 |
| 中间件 | 0.902 | 0.901 |
| 开发支撑 | 0.957 | 0.946 |
| 数据库 | 0.943 | 0.948 |
| 操作系统 | 0.915 | 0.912 |
| 信息安全 | 0.934 | 0.936 |
图 6
4. 结 语
为了应对软件分类问题,本文引入基于BERT框架的双模态分类模型. 在该模型中,2种特定的BERT预训练模型被用于处理代码和文本,保证有效地捕捉代码的核心要素,并据此生成相应的代码向量. 对于软件的文本描述,采取经过优化的MacBERT模型,旨在全面地抽取文本向量的全局与局部特性. 在融合这些信息的过程中,模型利用提出的交叉自注意力机制平衡不同输入的权重,生成富有深度语义的综合特征向量. 本文提出的方法在不同的文本描述情境下都显著超越其他深度学习方法. 特别是在有文本描述的情境中,相较于BERT模型提高5.0%的精确率,超过其他改良型BERT模型,实现90%以上的精确率,表现出明显的实用价值.
总体而言,这一基于BERT的双模态软件分类策略能够解决传统手工软件分类的效率与准确性低的问题,为软件运维提供更加精准的决策工具,从而降低运维成本. 虽然当前模型在仅基于代码的分类中与CodeBERT持平,但未来仍计划对代码分类结果进行优化,以提升模型的整体表现.
参考文献
Requests classification in the customer service area for software companies using machine learning and natural language processing
[J].DOI:10.7717/peerj-cs.1016 [本文引用: 1]
Software requirements classification using machine learning algorithms
[J].DOI:10.3390/e22091057 [本文引用: 1]
A multi-head attention network with adaptive meta-transfer learning for RUL prediction of rocket engines
[J].DOI:10.1016/j.ress.2022.108610
A multi-head attention-based transformer model for traffic flow forecasting with a comparative analysis to recurrent neural networks
[J].DOI:10.1016/j.eswa.2022.117275
Distract your attention: multi-head cross attention network for facial expression recognition
[J].DOI:10.3390/biomimetics8020199
RMAN: relational multi-head attention neural network for joint extraction of entities and relations
[J].DOI:10.1007/s10489-021-02600-2 [本文引用: 1]
Understanding bag-of-words model: a statistical framework
[J].DOI:10.1007/s13042-010-0001-0 [本文引用: 1]
A comparative study of TF*IDF, LSI and multi-words for text classification
[J].DOI:10.1016/j.eswa.2010.08.066 [本文引用: 1]
Pre-training with whole word masking for Chinese bert
[J].
1D convolutional neural networks and applications: a survey
[J].DOI:10.1016/j.ymssp.2020.107398 [本文引用: 1]
Automated detection of contractual risk clauses from construction specifications using bidirectional encoder representations from transformers (BERT)
[J].DOI:10.1016/j.autcon.2022.104465 [本文引用: 1]
Convolutional neural networks as a model of the visual system: past, present, and future
[J].DOI:10.1162/jocn_a_01544 [本文引用: 1]
ConvUNeXt: an efficient convolution neural network for medical image segmentation
[J].DOI:10.1016/j.knosys.2022.109512 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}