

用户导向的设计方法主要考虑用户行为、情境创建、用户体验3个维度. 王超等[3]通过分析乘客在卧铺中的4种行为,对卧铺布局进行优化设计. Yang等[4]构建多情境功能-行为-结构 (function behavior structure, FBS)和质量功能配置(quality function deployment,QFD)融合模型,挖掘不同情境下的用户需求和产品功能之间的关系. 由于单维度的创新设计无法兼顾产品设计、产品制造和用户使用,更多学者将多维度进行融合. 耿秀丽等[5]从需求和用户体验2个角度确定产品服务系统(product service system, PSS)的重要度,采用概率语言术语集评价体验维度与模块的关联关系. 苏珂等[6]通过现有产品使用情境演化构建潜在情境,利用新情境下的用户体验和反馈挖掘需求. 上述方法存在局限性:1)以知识驱动为主,数据驱动为辅,受限于设计人员的知识和经验,需求挖掘不全面;2)缺乏隐性需求挖掘的具体实现路径和方法;3)在产品快速更迭的背景下,产品创新设计面临的问题更加不确定和非结构化,依靠结构化的知识难以求解. 为了在产品创新设计过程中兼顾产品显性需求和未来隐性需求,Lee等[7]构建基于PSS的高级创新产品服务系统(innovative product advanced service systems, I-PASS),提出主控式创新理论,主控式创新矩阵是该理论的核心内容. 主控式创新设计理论为产品创新过程中信息挖掘的全面性提供了理论支撑,却未摆脱知识驱动创新的局限,需求挖掘不充分. 该理论虽考虑了未来隐性需求和市场,但缺乏预测未来需求的有效方法.
随着信息化的快速发展,运用数据驱动需求挖掘的方法识别实际用户需求成为企业发展的重要趋势[8]. 已有学者通过对在线评论[9-10]、产品运行数据[11-12]的分析挖掘产品的可见需求. 评论数据驱动的需求挖掘侧重于用户的主观反馈和情感偏好,难以获取全面客观的用户需求;运行数据驱动的需求挖掘侧重于分析产品的客观表现,无法挖掘用户的情感因素和主观需求;基于评论数据和运行数据的需求挖掘对未来产品隐性需求预测不足. 基于发明问题解决理论(Teoriya Resheniya Izobreatatelskikh Zadatch,TRIZ)的技术成熟度预测、技术进化理论、需求进化定律等需求预测理论可以利用专利数据准确挖掘未来产品的隐性需求[13-14],有效弥补评论数据、运行数据驱动的需求挖掘方法在获取未来隐性需求方面存在的缺陷. 本研究将主控式创新设计理论、多源数据驱动需求挖掘方法、需求预测理论进行集成,构建多源数据驱动的主控式创新框架,解决传统的基于设计知识和单源数据驱动的需求挖掘方法存在的过度依赖设计经验、需求挖掘不全面、缺乏未来隐性需求预测方法等缺陷.
1. 多源数据驱动的主控式创新框架
主控式创新设计理论是企业进行产品创新设计的系统性方法,为企业制定产品未来的战略规划提供了理论依据. 在传统主控式创新设计理论的基础上,通过多源数据集成驱动主控式创新矩阵的生成,构建如图1所示的多源数据驱动的主控式创新框架. 多源数据驱动的主控式创新框架包含3个层级:用户满意度识别层、过渡矩阵生成层和隐性需求预测层. 用户满意度识别层通过大数据驱动,挖掘用户对产品的满意度;过渡矩阵生成层结合满意度、市场调研数据和产品模块化信息,利用过渡矩阵实现对可见需求量化和排序;隐性需求预测层利用进化理论预测未来隐性需求. 各个层级的流程如下. 1)用户满意度识别层:获取评论数据与运行数据,对在线评论数据进行情感分析,得到产品的特征满意度;对运行数据进行性能分析,得到产品的性能满意度. 为了将特征集群满意度、市场数据、性能满意度、模块信息集成,实现需求价值排序,引入主控式创新矩阵的过渡矩阵. 2)过渡矩阵生成层:将用户满意度识别层输出的特征满意度转化为用户需求价值,实现对用户需求的量化分析,结合市场的调研结果得到过渡矩阵Ⅰ;将用户满意度识别层输出的性能满意度转化为性能需求价值,建立“性能需求-功能需求-产品模块”映射关系,生成过渡矩阵Ⅱ;融合以上2个过渡矩阵,获得主控式创新矩阵一、二象限的内容,以此为依据作为本研究中显性需求/市场的数据支撑. 3)隐性需求预测层:利用目标产品的专利数据判定产品生命周期,结合技术进化相关理论对宏观的未来隐性需求进行技术细化和可行性分析,预测未来隐性需求,生成主控式创新矩阵第三象限的内容. 由多源数据驱动,经过3个层级的分析,最终生成目标产品主控式创新矩阵,为企业的产品规划和战略布局提供指导.
图 1

图 1 多源数据驱动的主控式创新框架
Fig.1 Dominant innovation framework driven by multi-source of data
2. 用户满意度识别层
2.1. 基于评论数据的特征满意度分析
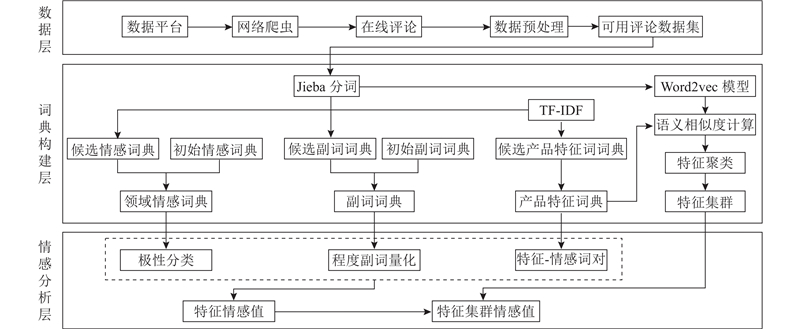
目标产品的评论数据样本数量较少,无法实现对机器学习模型和深度学习模型的大样本数据训练,为此基于词典的情感分析理论,本研究提出基于词典的情感分析方法. 该方法包含数据层、词典构建层、情感分析层3个层级,如图2所示.
图 2
2.1.1. 数据层
数据层主要是对产品的评论数据进行爬取和预处理. 在电商网站通过关键词搜索目标产品的相关评论信息,通过网络评论爬虫工具(八爪鱼)爬取搜索结果,导出为Excel形式. 电商平台存在噪声数据(如用户刷评),容易导致结果分析不准确. 因此,对评论进行预处理,具体包括筛除重复评论和剔除短评论.
2.1.2. 词典构建层
为了方便对特征进行聚类和情感量化分析,构建情感分析词典. 词典包含3个部分:领域情感词典、副词词典、产品特征词典. 产品特征是指被评价对象的属性和特点,词频-逆向文件频率(term frequency-inverse document frequency, TF-IDF)在特征词提取上优势明显,还能有效降低噪声词的权重,因此本研究采用TF-IDF提取特征词. 不同的评价者对同一产品特征的表述不尽相同(如“分辨率”“像素”“清晰度”都用来形容打印清晰度特征),须对产品相似的特征词进行聚类,形成特征集群,达到降低分析复杂性的目的. Word2vec模型根据词语之间的语义和语法关系将非结构化的词语转化为结构化的数字向量,利用数字向量计算特征词之间的语义相似度,将相似度大于阈值的特征词归为同一类,实现特征词的聚类. 情感词表明用户对某个产品特征的态度和情感倾向,副词代表用户对于该特征的情感强度. 精确分词和准确词性标注是词典构建的关键,本研究利用Jieba分词器对可用评论数据集进行分词,使用基于知识库和语料库结合的方法[15]构建领域情感词典、副词词典和产品特征词典.
2.1.3. 情感分析层
产品的情感量化分析须提取每条评论数据的“特征-程度副词-情感词”词组. 依存句法在分析句子成分之间关系时准确度较高,常用来提取特征-情感词对. 在提取词组的基础上,结合基于情感词典的情感分析方法计算每个特征集群的情感值,通过特征情感值换算得到产品特征集群的满意度.
式中:
式中:
式中:
2.2. 基于运行数据的性能满意度分析
图 3
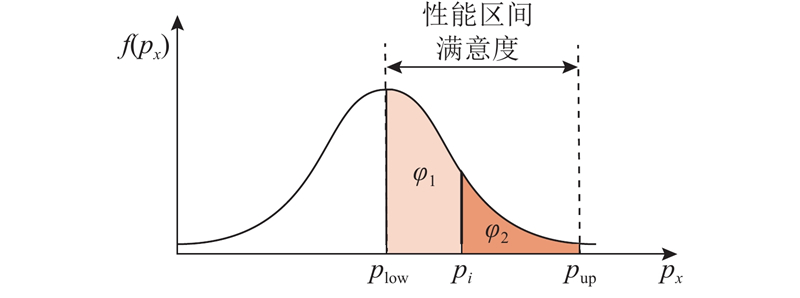
图 3 运行性能分布及性能需求区间
Fig.3 Operational performance distribution and performance requirement interval
其中
高斯分布的累积概率密度函数计算较为复杂,为此选择Sigmoid函数作为高斯分布累积函数的替代函数:
则性能需求满足度函数表示为
整理式(4)~式(8),得到性能满足度函数:
式中:
图 4
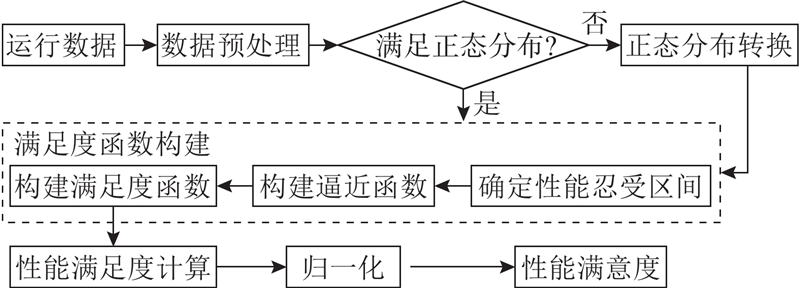
图 4 基于运行数据的性能满意度分析流程
Fig.4 Process of performance satisfaction analysis based on operational data
3. 过渡矩阵生成层
以往通过用户需求生成主控式创新是定性分析的过程,缺乏客观数据支撑,信息挖掘不全面. 为了对用户需求进行量化分析,引入主控式创新矩阵的过渡矩阵. 基于评论数据生成的过渡矩阵由评论数据和市场调研数据驱动,将量化的用户需求价值和市场价值进行关联;基于运行数据分析生成的过渡矩阵由运行数据和产品的模块信息驱动,将量化的性能需求价值和产品模块重要度进行关联. 2个过渡矩阵为主控式创新矩阵一、二象限的生成提供客观数据支撑.
3.1. 基于特征满意度的过渡矩阵生成
基于特征满意度生成的过渡矩阵建立特征集群的需求价值和市场价值的关联,完成主控式创新矩阵对用户需求和市场的定量化分析,分析流程如图5所示. 需求价值的分析包括特征集群满意度获取和需求价值计算;市场价值分析包括网络调研数据获取、调研结果分析和市场价值计算. 特征集群的满意度越高,表明产品特征表现越好,用户对该特征的需求能够得到满足. 相比于已满足的需求,当前产品中未满足的需求在设计中应该被优先考虑,具有更大的需求价值.
图 5
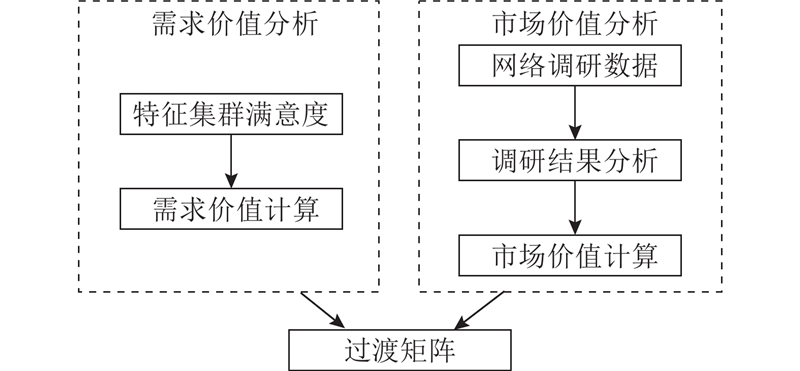
图 5 基于评论数据的过渡矩阵生成流程
Fig.5 Process of transition matrix generation based on review data
式中:
式中:
3.2. 基于性能满意度的过渡矩阵生成
基于性能满意度生成的过渡矩阵考虑需求价值和模块重要度2个维度,对通过运行数据得到的需求价值和产品模块重要度进行关联分析,生成过渡矩阵,实现主控式创新矩阵对用户需求和产品模块定量化描述. 性能满意度越低,对应的需求越需被满足,需求价值越高.
式中:
图 6
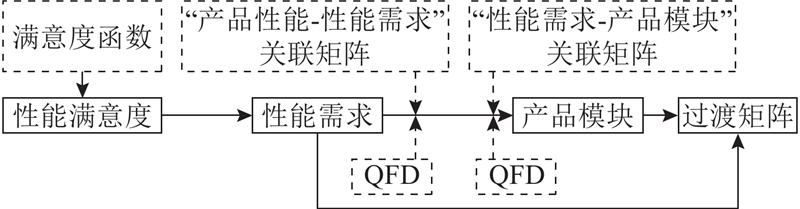
图 6 基于运行数据的过渡矩阵生成流程
Fig.6 Process of transition matrix generation based on operational data
4. 隐性需求预测层
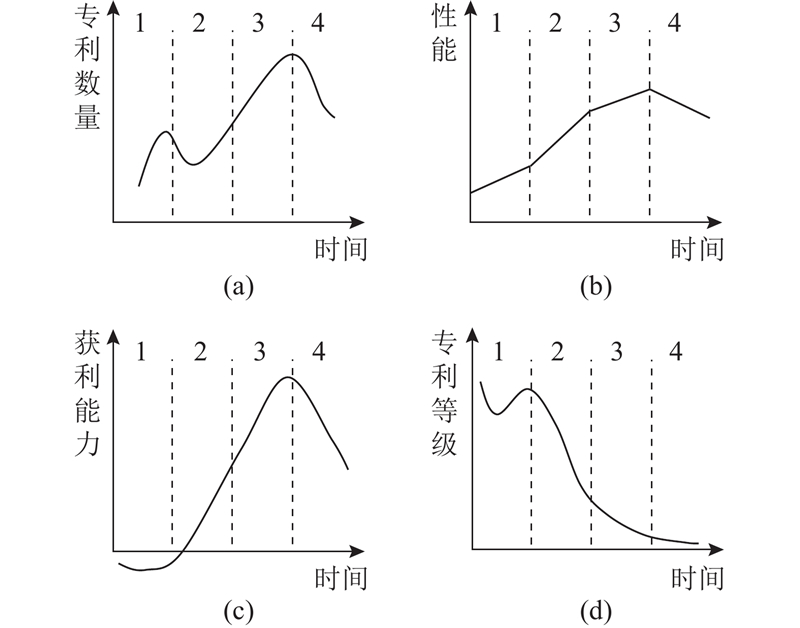
主控式创新矩阵一、二象限的内容为可见已满足和可见未满足的需求和市场,反映当前显性的用户需求和市场,但无法挖掘未来隐性的用户需求. 第三象限未来隐性需求难以直接从用户视角进行需求挖掘,须在已有显性需求的基础上,通过产品内部和相关技术的发展规律进行预测. 产品存在的主要目的是满足用户需求,成功的产品通常具备某些技术特征,能够有效地满足用户偏好和反映需求的变化趋势,同时蕴含大量用户需求信息. 因此,产品的技术进化规律必然反映用户需求的变化趋势[14].
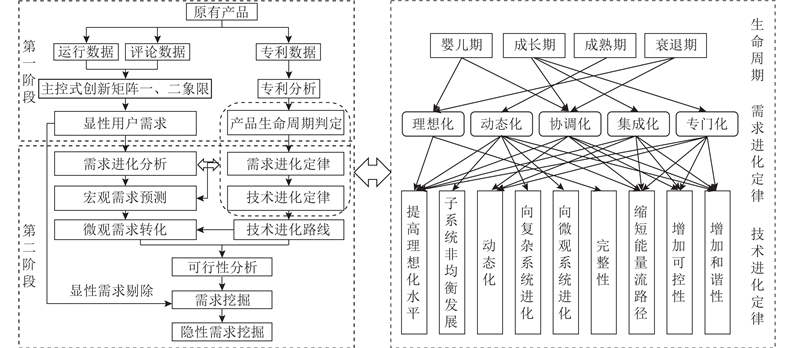
图 7
将产品生命周期与技术进化定律相结合,运用技术进化定律对应的技术进化路线对显性需求进行分析,实现对隐性需求的预测. 隐性需求的预测方法分为2个阶段,如图8所示. 在第一阶段,将主控式创新矩阵一、二象限的需求融合,作为显性的用户需求. 通过专利检索网站获取目标产品的专利数据,结合技术成熟度预测模式,判定产品的生命周期. 第二阶段完成显性需求到隐性需求的挖掘. 将产品生命周期和需求进化定律进行映射,根据需求进化定律挖掘产品宏观需求,确定产品需求宏观层面的演进方向. 根据需求进化定律选择对应的技术进化定律分析需求的技术特征,选中技术进化定律匹配的技术进化路线,预测宏观方向下的具体需求,完成宏观需求预测到微观需求预测的转化,结合技术进化潜力预测技术对需求进化进行可行性分析,获得产品的未来需求. 结合“生命周期-需求进化定律-技术进化定律”的对应关系[23],利用技术进化定律匹配的具体技术进化路线实现对产品未来需求的预测[24]. 结合主控式创新矩阵一、二象限的内容,从未来需求中剔除显性需求,预测未来的隐性需求.
图 8
5. 案例研究
5.1. 用户满意度识别
5.1.1. 特征满意度分析
以某创新设计企业的GO型号迷你打印机作为研究对象,验证多源数据驱动的主控式创新框架. 通过八爪鱼采集器从电商平台爬取GO的513条评论,将数据预处理得到的500条评论作为可用评论数据集. 对评论数据集进行分词操作,结合初始情感词典和初始程度副词词典,构建迷你打印机的领域情感词典、领域副词词典和领域特征词典. 使用哈工大的依存句法分析库LTP进行特征-情感词对提取,得到“特征词+情感词+副词”词对. 利用Word2vec生成特征词语义向量对特征词进行聚类,得到特征集群. 将语义相似度超过0.8的特征词归为特征集群,最终得到打印效果、用户操作、产品颜色、体积大小等15个特征集群,结合式(1)~式(3)得到每个特征集群的满意度,如表1所示. 由表可知,用户对于体积大小、款式型号、产品价格、产品运行、产品颜色等特征集群的情感值高,说明用户对这些特征集群的需求得到满足;用户对于打印效果、开关按键、运行声音、产品重量等特征集群的情感值低,说明用户对这些特征集群的需求未被满足.
表 1 GO的特征集群满意度
Tab.1
| 特征集群 | Sfc | 特征集群 | Sfc | 特征集群 | Sfc | ||
| 体积大小 | 1. 125 | 产品品牌 | 0. 900 | 产品重量 | 0. 750 | ||
| 型号款式 | 1. 000 | 用户操作 | 0. 859 | 运行声音 | 0. 750 | ||
| 产品价格 | 0. 938 | 配套软件 | 0. 857 | 开关按键 | 0. 750 | ||
| 产品运行 | 0. 929 | 产品形状 | 0. 815 | 打印效果 | 0. 602 | ||
| 产品颜色 | 0. 927 | 产品用途 | 0. 771 | 打 印 纸 | 0. 583 |
5.1.2. 性能满意度分析
查阅热敏打印机的技术标准规范和企业的热敏打印机产品测试报告可知,热敏打印机的打印清晰度、打印速度、马达温度和噪声是衡量产品性能的重要指标. 如图9所示,采集每个指标的多组数据,对采集到的数据进行正态分布检验. 由图可知,数据均满足正态分布. 构建各个性能-满意度关系的函数. 将GO的性能代入性能-满意度关系函数式(9)~式(13),得到对应的性能满意度;结合式(19)、式(20)计算性能需求价值,结果如表2所示. 由表可知,打印速度和马达温度的性能满意度比较高,推测出用户对于打印速度和连续打印的需求得到满足,性能需求价值低;清晰度和噪声的性能满意度较低,用户对清晰度和噪声的需求未被满足,性能需求价值高,通过优化设计可提高用户满意度.
图 9
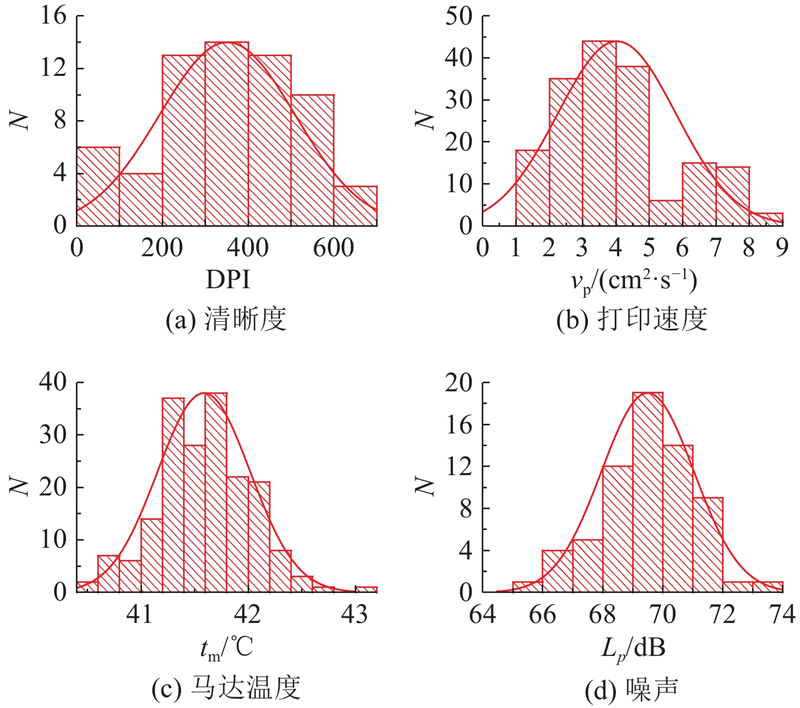
表 2 GO的性能满意度
Tab.2
| 性能指标 | |||
| 清 晰 度 | 437.84 | 1.00 | |
| 打印速度 | 0.00 | ||
| 马达温度 | 41.3 | 0.15 | |
| 噪 声 | 68.0 | 0.41 |
5.2. 过渡矩阵生成
将特征集群满意度的结果输入过渡矩阵,生成流程的需求价值分析端,由式(14)、式(15)计算得到特征集群对应的需求价值. 不同的需求对应的市场价值须结合市场调研数据,本研究通过对该创新制造企业市场调研数据划分产品需求的市场价值. 该企业对2022年热敏打印机使用过程中的常见问题进行网络调研,收集1 758份样本数据,样本分布如图10所示. 通过产品特征的样本数量来衡量不同特征市场价值的大小,样本数量大,市场价值高;结合式(16)、式(17)计算每个特征集群的市场价值. 需求价值和市场价值分析结果如表3所示. 以需求价值为横坐标,对应的市场价值为纵坐标建立过渡矩阵,结合式(18)计算特征集群到原点的距离
图 10
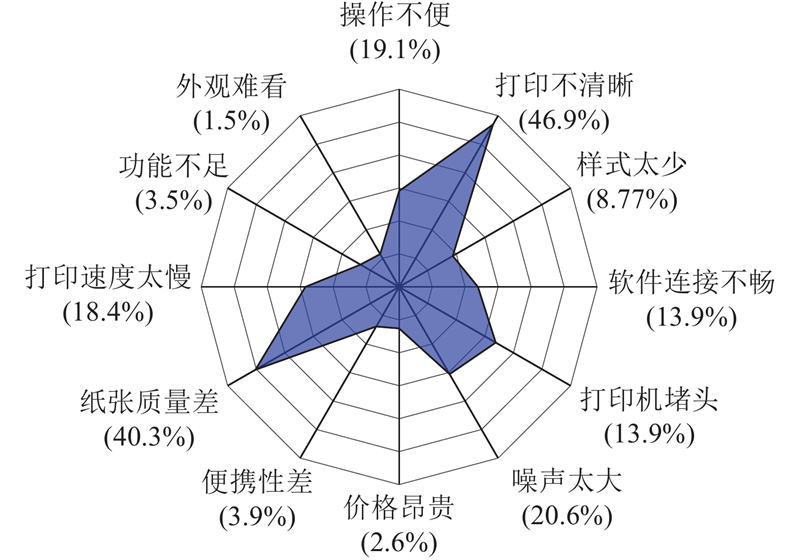
表 3 特征集群的需求价值和市场价值
Tab.3
| 特征集群 | Crvr | Mvr | 特征集群 | Crvr | Mvr | |
| 体积大小 | 0.000 | 0.083 | 产品形状 | 0.411 | 0.032 | |
| 型号款式 | 0.113 | 0.187 | 产品用途 | 0.495 | 0.075 | |
| 产品价格 | 0.215 | 0.055 | 产品重量 | 0.539 | 0.083 | |
| 产品运行 | 0.228 | 0.450 | 运行声音 | 0.539 | 0.439 | |
| 产品颜色 | 0.230 | 0.032 | 开关按键 | 0.539 | 0.000 | |
| 产品品牌 | 0.269 | 0.000 | 打印效果 | 0.935 | 1. 000 | |
| 用户操作 | 0.334 | 0.407 | 打 印 纸 | 1. 000 | 0.859 | |
| 配套软件 | 0.337 | 0.296 | — | — | — |
图 11
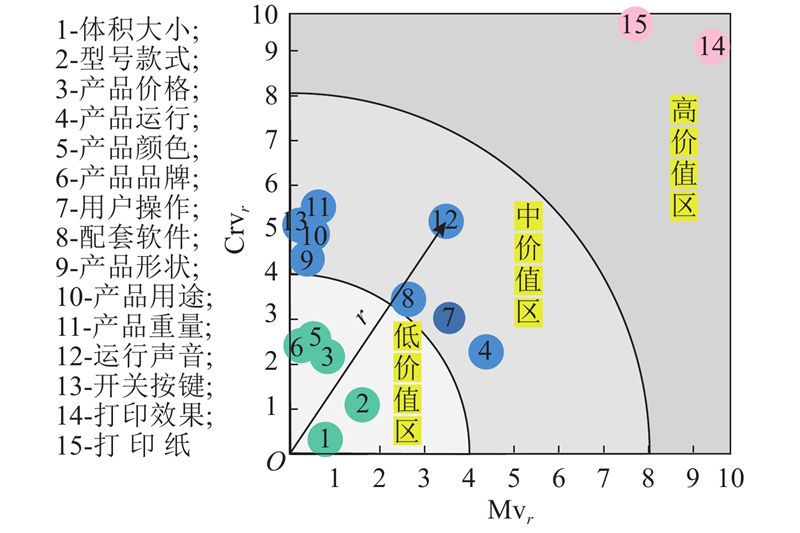
为了获取产品模块重要度,先建立D1,再建立D2,D1与D2相乘得到D3,对D3进行解模糊化得到D4,将D4的所有元素进行归一化处理得到
模块重要度和需求价值呈正相关,需求价值越高,对应的模块越重要. 由表2建立需求价值矩阵:
Dv与D5相乘得到各个模块的重要度impj,如表4所示. 以性能需求价值为纵轴,模块重要度归一化后的结果
表 4 GO不同模块的重要度
Tab.4
| 模块 | impj | |
| 充电管理模块 | 0.015 | 0.039 |
| 主控芯片 | 0.262 | 0.703 |
| 蓄电池 | 0.037 | 0.099 |
| 通信模块 | 0.024 | 0.063 |
| 马达驱动模块 | 0.158 | 0.425 |
| 按键按钮 | 0.000 | 0.000 |
| 热敏机芯 | 0.373 | 1.000 |
图 12
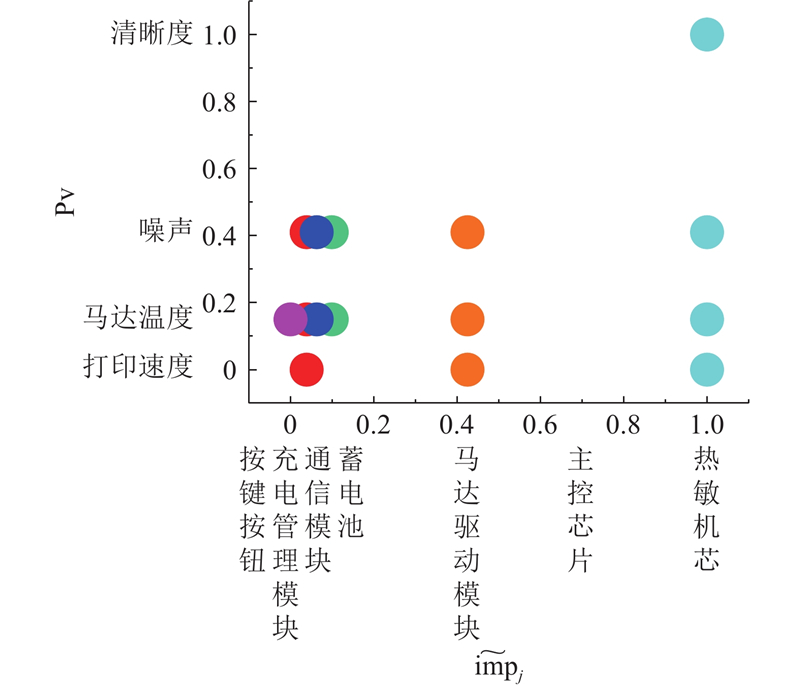
5.3. 不可见需求的预测
将生成的2个过渡矩阵进行融合,得到显性的用户需求和市场,填充到主控式创新矩阵的一、二象限中. 其中第一象限需求为“小体积、款式新颖”“价格便宜、运行流畅”“外观好看、品牌好”“App顺畅、操作简单”“功能丰富、小重量”“低噪声、按键方便”“高速打印、连续打印”,第二象限需求为“高质量打印纸”“多功能打印纸”“优质的打印效果(高清晰度、彩印)”. 在明确了可见需求的前提下,结合技术成熟度预测、技术进化理论、需求进化定律等方法对不可见需求进行预测. 研究通过专利公开数量对产品技术生命周期进行判定,在智慧芽专利检索平台对产品进行检索,检索关键词为“热敏打印机”,考虑到专利的时滞性,检索范围为2012年1月至2021年12月,一共检索到5 139条公开专利,公开变化趋势如图13所示. 专利公开数量NPP整体呈现上升趋势,结合技术成熟度预测模式可知,热敏打印机处于成长期阶段,结合生命周期和技术进化定律的对应关系,对迷你打印机的未来不可见需求进行预测,结果如表5所示.
图 13
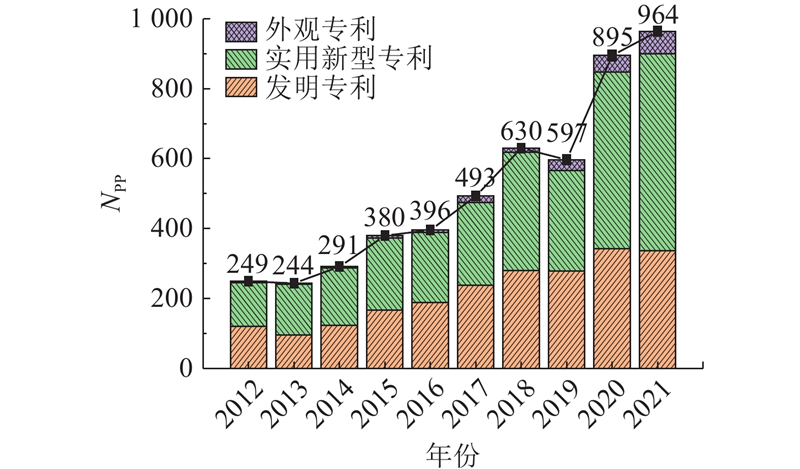
图 13 热敏打印机专利公开数量变化趋势
Fig.13 Trend of number of patent disclosures for thermal printers
表 5 产品成长期的隐性需求预测结果
Tab.5
| 技术进化定律 | 隐性需求预测 |
| 提高理想化水平 | 自动裁剪,自动装订,无损害打印头,声音提示 |
| 动态化增长 | 学习分析系统,可选装模块实现定制化 |
| 缩短能量流路径长度 | 太阳能充电 |
| 增加可控性 | 实时动态监测,防水抗摔,恒温打印头,语音指令识别 |
| 增加和谐性 | 便携3D打印机,无声打印机 |
图 14
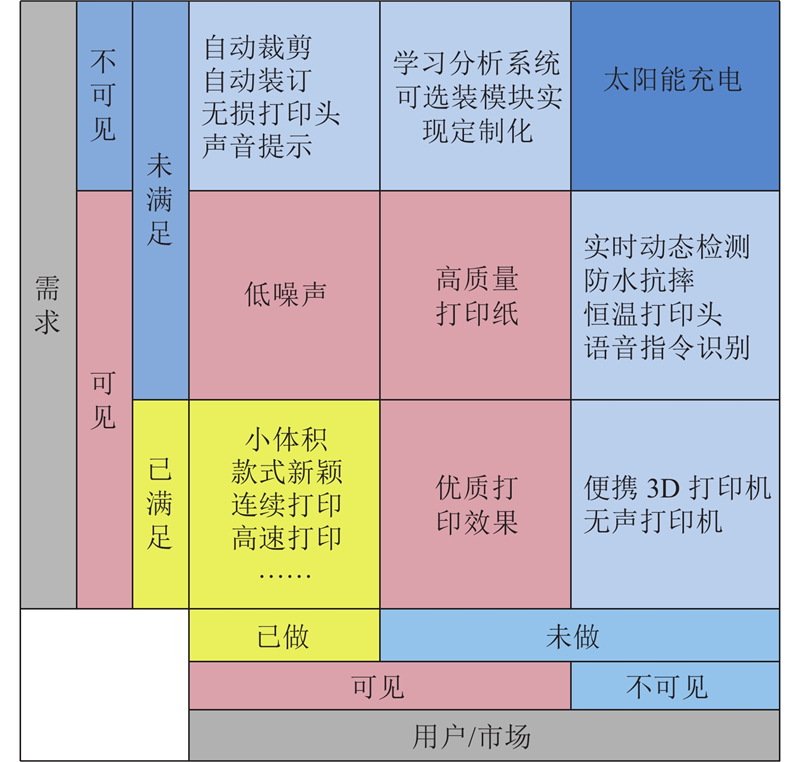
表 6 迷你打印机的需求市场细分
Tab.6
| 用户群体 | 使用场景描述 | 需 求 |
| 学生群体 | 学生群体使用迷你打印机进行学习和错题打印 | 自动裁剪、自动装订、无损打印头、学习分析系统、恒温打印头、无声打印机,低噪声、高质量打印纸、优质打印效果,小体积、款式新颖、高速打印······ |
| 居家老人 | 老人使用智能产品不便,子女通过打印机远程提醒老人到点吃药和交流 | 无损打印头、声音提示、恒温打印头、语音指令识别,优质打印效果,APP顺畅、操作简单、运行流畅······ |
| 情侣/户外摄影 | 情侣需要远程打印传递消息以及户外拍照打印,户外摄影爱好者可以随时打印照片 | 自动裁剪、太阳能充电、防水抗摔、语音指令识别,优质打印效果,小体积、小重量、款式新颖、连续打印······ |
| 特定人群 | 有户外3D打印需求的群体或其他功能需求的群体 | 可选装模块实现定制化、便携3D打印 |
如表7所示为GO和其他迷你打印机的性能对比. 相比于GO, G4的打印分辨率提升了约50%,达到300. 同时,G4的打印纸类型更加丰富,包括不干胶打印纸、彩色打印纸、粘贴式打印纸3种类型. QL-820NWB相对于QL-800侧重改进打印机连接方式. 由电商平台爬取的评论数量可知,G4评论数远大于GO,G4销量更高;QL-820NWB相对于QL-800销量下降. 在G4中,该企业对打印噪声、打印清晰度和打印纸质量进行了优化. 依赖于主控式创新矩阵的指导,G4的优化方向更能满足用户偏好. 相对于利用市场调研等传统需求挖掘方法指导的竞品优化,G4的优化更成功.
表 7 不同产品性能对比
Tab.7
| 产品说明 | 产品型号 | 体积/mm3 | 款式数量 | Lp/dB | vp/(cm2·s−1) | 打印纸 | DPI | 连接方式 | 评论数量 |
| 目标产品 | GO | 80×79×33 | 4 | 68 | 不干胶 | 203 | 无线 | 513 | |
| 同期竞品 | QL-800 | 125×213×142 | 1 | 71 | 不干胶 | 300 | 有线 | 219 | |
| 下一代产品 | G4 | 86×79×39 | 4 | 62 | 不干胶 单色/粘贴式 | 300 | 无线 | ||
| 下一代竞品 | QL-820NWB | 125×213×142 | 2 | 70 | 不干胶 | 300 | 有线/无线 | 123 |
产品未来不可见市场须开发的产品和功能包括自动裁剪、自动装订、学习分析系统、太阳能充电、便携3D打印机等. 企业已将主控式创新矩阵第三象限的部分需求如自动裁剪、声音提示、学习分析系统作为未来的研究方向,部分产品已经具备自动裁剪功能. 企业还可以将文中未来市场其他内容作为产品的未来长远规划和布局,提前抢占未来市场.
5.4. 方法对比
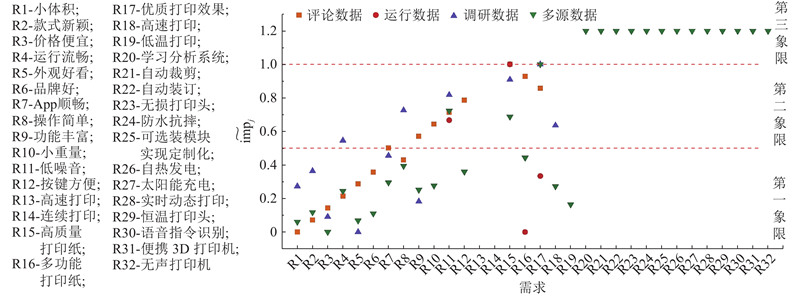
为了说明本研究方法的有效性,比较多源数据驱动的主控式创新框架、传统市场调研、单源运行数据驱动、单源评论数据驱动的需求挖掘结果,如图15所示. 由图可知,评论数据、运行数据、调研数据、多源数据驱动的需求挖掘方法在不同需求绝对重要度数值结果上存在差异,但不同需求之间的相对重要性基本一致,从需求R1到R19,4种方法计算的重要度呈现先升后降的趋势. 在显性需求部分,多源数据需求挖掘的结果数量更为密集,涵盖了R1~R19,需求挖掘更加全面;其次是评论数据,但未挖掘到R13、R14、R15、R18、R1;接着是调研数据,挖掘到58%的显性需求. 由于运行数据采集困难,挖掘到的需求最少,只挖掘到R11、R15、R16、R17. 在隐性需求部分,评论数据、运行数据、调研数据缺乏隐性需求挖掘的具体方法和实现路径,只能对显性需求进行识别,多源数据驱动的需求挖掘方法可以很好克服此缺陷,为隐性需求的识别提供了方法和理论支撑.
图 15
6. 结 语
本研究提出多源数据驱动的主控式创新框架,该框架包含用户满意度识别层、过渡矩阵生成层、不可见需求预测层3个层级;基于所提框架开展了多源数据驱动下主控式创新矩阵生成的具体方法研究. 主要贡献如下:1)提出多源数据驱动的主控式创新矩阵生成的新思路,延伸了需求获取的方式,为大数据分析技术在产品创新设计领域的应用提供了框架和方法指导;2)集成产品的评论数据、市场调研数据、运行数据、专利数据等多源数据,提出过渡矩阵实现对需求的量化分析,为需求的获取和分析提供了多源客观数据的支撑,弥补了设计知识和单源数据驱动创新存在信息挖掘不全面的缺陷;3)将需求预测理论和主控式创新设计理论相结合,填补了传统主控式创新矩阵第三象限生成缺乏具体方法和实现路径的不足;4)以GO型号迷你打印机为案例,详细阐述多源数据驱动下可见需求的获取和不可见需求的预测的详细过程,验证了所提框架的有效性,为企业的产品创新和战略布局提供了方法参考. 通过多源数据驱动的主控式创新矩阵,可以将创新思维和理论具体化与方法化,为企业的创新提供指导. 当前创新框架和方法的具体实施是半自动化的过程,未来将开展创新流程的软件化和平台化研究,实现该流程的自动化.
参考文献
A new user implicit requirements process method oriented to product design
[J].DOI:10.1115/1.4041418 [本文引用: 1]
A user centered methodology for the design of smart apparel for older users
[J].DOI:10.3390/s21082804 [本文引用: 1]
基于乘客行为分析的列车卧铺布局创新设计研究
[J].
et al. Innovative design of sleeper layout based on passenger behavior analysis
[J].
考虑用户体验的产品服务系统模块重要度判定方法
[J].
Importance degree determination approach for product service system modules based on user experience
[J].
面向相似认知用户集群的TRIZ超系统资源需求获取模型
[J].
Demand acquisition model of TRIZ super system resources for similar cognitive user clusters
[J].
Innovative product advanced service systems (I-PASS): methodology, tools, and applications for dominant service design
[J].DOI:10.1007/s00170-010-2763-7 [本文引用: 1]
基于云平台的用户隐式需求分析方法研究
[J].
Research on user implicit demand analysis based on cloud platform
[J].
基于在线评论的重要度绩效竞争对手分析的产品设计改进方法
[J].
Product design improvement based on importance performance competitor analysis of online reviews
[J].
基于运行数据驱动反向设计的复杂装备个性化定制
[J].DOI:10.3901/JME.2021.08.065 [本文引用: 1]
Mass personalization for complex equipment based on operating data-driven inverse design
[J].DOI:10.3901/JME.2021.08.065 [本文引用: 1]
Identification of performance requirements for design of smartphones based on analysis of the collected operating data
[J].DOI:10.1115/1.4037475 [本文引用: 1]
基于Kano模型和TRIZ技术进化法则的老年代步车设计
[J].
Elderly mobility scooter design based on Kano model and evolutionary laws of TRIZ technique
[J].
需求进化和技术进化集成的产品用户需求获取研究
[J].
Customer needs acquisition by integrating needs evolution with technology evolution
[J].
A data-driven approach for the optimisation of product specifications
[J].DOI:10.1080/00207543.2018.1480843 [本文引用: 1]
Data-driven approach to identify obsolete functions of products for design improvements
[J].DOI:10.3233/JIFS-202144 [本文引用: 1]
New sigmoid-like function better than fisher z transformation
[J].DOI:10.1080/03610926.2013.771750 [本文引用: 1]
Transforming non-normal data to normality in statistical process control
[J].DOI:10.1080/00224065.1998.11979832 [本文引用: 1]
The Box-Cox transformation technique: a review
[J].
面向多域协同的复杂产品再设计模块主从识别
[J].
Leader-follower identification of complex product redesign modules for multi-domain collaboration
[J].
基于多方法融合的需求提取模型研究
[J].
Research on requirement extraction model based on multi-method fusion
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}