

中国地处东亚季风区,地形复杂多样,频繁的暴雨极易导致城市洪涝灾害. 强降水危害居民的生命与财产安全,会对经济社会的发展造成严重影响. 过去40 a,中国平均每年洪涝灾害造成的直接经济损失约为573亿元,南方地区损失较重,南方地区死亡人数占总死亡人数的一半以上,是中国社会经济受自然灾害影响最为严重的地区. 2008—2013年,中国平均每年出现暴雨过程39次[1]. 2021年7月,河南省遭受特大暴雨洪涝灾害,其中以7月20日突发的郑州市“7·20”城市内涝灾害受灾情况最为极端突出. 此次灾害致使郑州市380人死亡、失踪, 占全省失踪总人口的95.5%; 直接经济损失高达409亿元,占全省总经济损失的34.1% [2].
随着国内互联网普及与社交媒体平台的发展,在各个重大洪涝灾害事件中,除了观测站点外,亲历者或者旁观者在社交媒体上分享的大量关于洪水灾害的图像、语音、视频、文本等信息可提供城市市区内涝的第一手有效灾情信息[7]. 经过相关处理之后,能够从这些文字与图像信息中提取用于科学研究的淹没深度、范围与历时等水文数据. 周利敏[8]认为,可以利用发布在社交媒体上的文字、视频与图片等大数据来进行灾前预防、准备以及在灾时分析受灾群众的需求. 金城等[9]以社交媒体上话题的代表性关键词为核心,通过某地区用户的热点话题演变情况来判断该地区受灾情况,以便于灾害应急管理者采取更有效的行动,还提出利用社交媒体大数据来追踪灾害影响范围和评估灾害损失. Jing等[10]在进行社交媒体图像识别时采用了文字标注辅助的方法,在区分洪水灾害中的人像、洪水图像和背景图片上起到了较好的效果.
本研究提出基于YOLOv5与Mask-RCNN的社交媒体淹没数据提取方法. 该方法主要包括:1)使用Selenium工具模拟浏览器并爬取以洪水为关键词的社交媒体图像,将图像通过2种淹没深度提取算法进行地点水深提取,聚合两模型的输出得到城市淹没深度分布;2)使用模拟淹没实验解决城市内涝研究中缺少城市淹没数据从而难以进行误差分析的问题.
1. 研究方法
1.1. YOLOv5图像识别算法
如图1所示为从社交媒体图像提取市区淹没深度方法的流程图. 目前,YOLO系列神经网络已经更新到第8个版本,并被评价为杰出的目标检测算法之一. 相比于多阶段检测算法,YOLO最显著的优势在于能在保证精度的同时具有极快的检测速度,且可以直接输出边界框的位置和类别,并保存为文件,便于直观查看与后续处理.
图 1
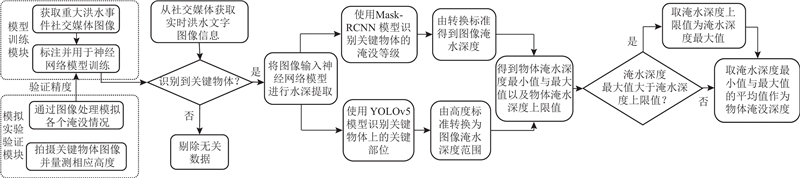
图 1 利用社交媒体图像提取市区淹没深度方法的流程图
Fig.1 Flow chart of extracting urban flood depths using social media images
如图2所示,YOLOv5神经网络模型以Focus结构与CSPnet(cross stage partial network)为主干网络(Backbone),具有较强的特征提取能力和计算效率. Focus结构是一种特殊的卷积操作,用于对输入图像进行下采样,能够减少计算量与参数量. CSPnet的主要思想为将部分特征图像首先进行卷积处理,再与其他图像拼接后共同作为下一层子网络的输入,这样可以有效减少网络参数并提高特征提取的效率.
图 2
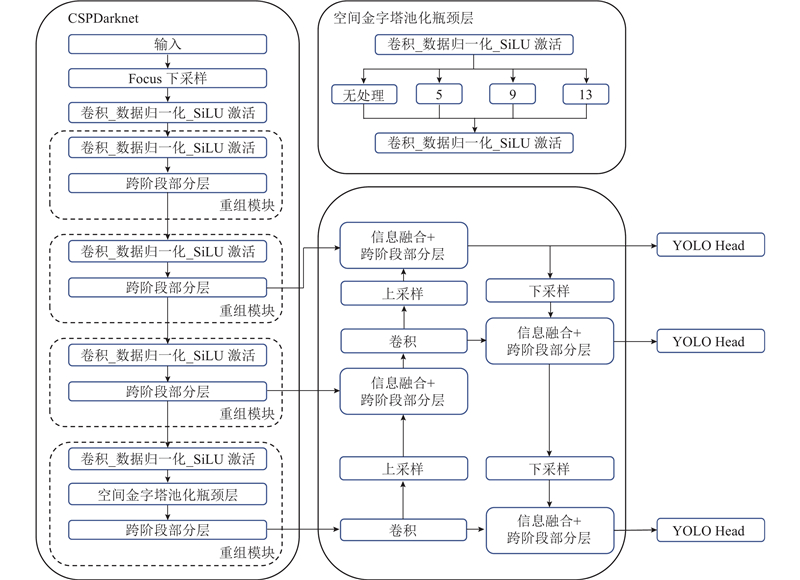
以空间金字塔池化(spatial pyramid pooling, SPP), PAN (path aggregation network)结构作为颈部层(Neck),这些特征金字塔网络结构能够增强模型对不同尺度目标的感知能力. 头部网络(Head)则是在YOLOv3的基础上使用了GIoU-loss(generalized intersection over union-loss)函数进行改进.
1.2. Mask-RCNN图像识别算法
Mask-RCNN (mask head with region based convolutional neural network)实例分割算法被广泛应用于目标检测、目标实例分割领域,模型架构如图3所示.
图 3
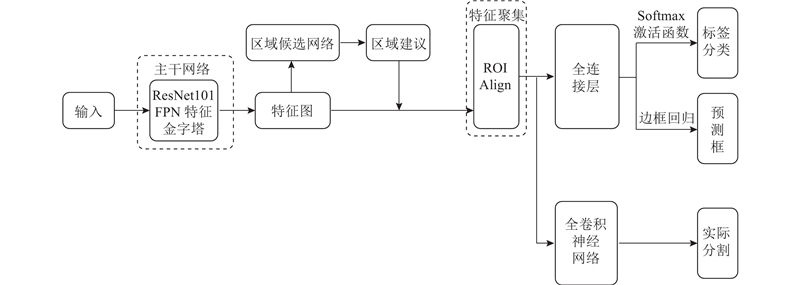
作为基于候选区域的算法,模型分两阶段来完成检测,网络输出最终包含了3个任务分支, 分别为目标的分类、目标框的坐标及目标区域的二值掩码实例分割,在像素级别进行特征点定位达到了将各个对象的边缘确定的效果.
Mask-RCNN在Faster R-CNN的基础上使用了全卷积神经网络(fully convolutional network,FCN)替换其中的全连接层,使得模型能够精准地完成语义分割的功能.
1.3. 结合关键部位转换高度的YOLOv5模型识别结果转换方法
为了将模型识别结果转化为淹没深度,提出结合关键部位转换高度的YOLOv5模型识别结果转换方法. 该方法的具体步骤如下.
YOLOv5神经网络作为目标检测模型,可以通过将图像中背景物体被淹没的部分转换为淹没深度以提取地点的内涝水深. 其中,YOLOv5识别模型包括关键物体识别模型与关键物体部位识别模型两部分. 关键物体的识别模型用于确认所要选用的关键部位识别模型与高度转换标准. 关键部位的识别模型用于提取图像淹没深度.
在进行图像识别前选取一批用于识别的关键物体作为“标尺”,如轿车、SUV、货车等,将需要识别的关键物体拆分为多个位于不同高度的易于识别的关键部位,每个关键部位的底部与顶部都有相对固定的高度,并制作相关的高度转换标准. 通过是否识别到关键部位判断淹没深度.
例如,以轿车为关键物体,可以拆分出车灯、轮胎、车牌等多个关键部位,为了合理量化水深,通过查阅常见“四座双轴客车”的车型部件尺寸标准与设计图以制作合适的高度转换标准,并经过现场量测验证精度,具体如表1所示. 表中,h1为关键部位高度.
表 1 轿车的关键部位高度转换标准
Tab.1
| 位置 | h1/mm | |||||
| 车轮胎 | 车把手 | 车前灯 | 后视镜 | 前车牌 | 后车牌 | |
| 顶部 | 660 | 914 | 737 | 483 | 622 | |
| 底部 | 100 | 813 | 640 | 940 | 343 | 480 |
每个部位的识别结果都将通过高度转换标准转换为高度信息,将每个部位顶部高度记为
图 4
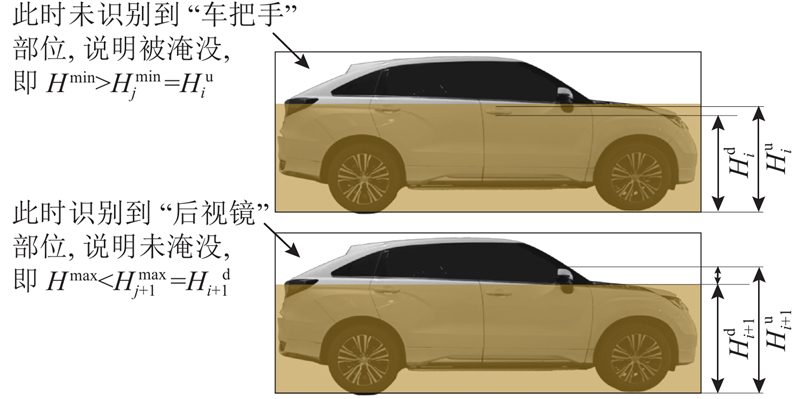
图 4 关键物体部位识别以及水深测量方法示意图
Fig.4 Schematic diagram of key object part recognition and water depth measurement method
预设图像淹没深度最大值
在最终结果中,应有
统计所有已识别到与未识别到的关键部位,将其转换为该物体的淹没深度范围.
1.4. 结合淹没等级转换高度的Mask-RCNN模型识别结果转换方法
对于获取的洪水图像数据,还可以通过Mask-RCNN模型,对关键物体的淹没等级进行识别从而提取淹没深度. 同样地,事先选定一批关键物体,确定其总高度. 对每个关键物体依据不同的淹没率设定淹没等级,根据关键物体的总高度制定相关的淹没等级高度转换标准,通过识别关键物体的露出部分占比判断淹没等级,并将关键物体的淹没等级转换为淹没深度.
在模型的训练中,对于淹没等级,根据图片分辨率分为2类,当图片分辨率高于800×600时划分20级淹没等级,当图片分辨率低于800×600时划分10级淹没等级. 以10级为例,淹没等级高度转换标准如表2所示. 表中,h2为各淹没等级对应的高度.
表 2 关键物体淹没等级高度转换标准
Tab.2
| 淹没等级 | h2/mm | |||
| 轿车 | SUV | 公交 | 货车 | |
| 1 | 75 | 80 | 150 | 235 |
| 2 | 225 | 240 | 450 | 705 |
| 3 | 375 | 400 | 750 | |
| 4 | 525 | 560 | ||
| 5 | 675 | 720 | ||
| 6 | 825 | 880 | ||
| 7 | 975 | 1950 | ||
| 8 | ||||
| 9 | ||||
| 10 | ||||
确定关键物体的类型后即可进行淹没高度的识别,配合制作的淹没等级高度转换标准能够提取图像中的淹没深度. 淹没等级识别法仅需进行一次图像识别,更加便于部署.
1.5. YOLOv5&Mask-RCNN组合模型
综上所述,两模型均可独立提取图像中物体的淹没深度,但各自存在不适用情况,且存在互补的可行性. 比如考虑到图像中物体被部分遮挡导致识别误差的情况,由于Mask-RCCN方法识别结果为露出水面的面积,得到的淹没水深结果往往高于实际结果,可以将Mask-RCNN方法得到的淹没深度值作为淹没深度最大值的可能值.
在得到两模型输出的淹没相关数据后,还须进行聚合得到最终地点淹没数据. YOLOv5模型输出结果为淹没范围而非淹没深度,将其淹没深度最大值
若同张图像中存在多个关键物体,由于各个关键物体的水平基准点不同,最终结果取各个关键物体淹没深度
1.6. 数据集制作
以Python为编程语言,采用Selenium自动化工具模拟网页浏览器以实现社交媒体图像的获取,将获取图像删重后根据配文中用户设定的地点关键词对图像进行分类. 最后使用labelImg软件将图像沿关键物体轮廓进行框选并标注以制作关键物体识别数据集,并同样制作关键部位识别法中的关键部位识别模型与淹没等级识别法中的淹没等级识别模型的训练数据集.
模型训练数据集来源为国内较大的社交媒体平台 “新浪微博”上用户发布的图片与影像信息,该平台的发布内容可由用户添加“超话”词条,对相关词条进行检索即可获取该“超话”中的所有发布的文字与图像内容. 以2021年引起较大互联网反响的“7.20”郑州洪涝灾害相关文字与图像为获取对象,能够保证数据获取量. 最终获得853张图像作为数据集来源,这些图像中并非均包含有“轿车”这一关键物体,也并非均存在淹没情况,以此保证数据多样性.
用于精度验证的模拟实验采用的数据集来源为现场拍摄的车辆图像共46张,车辆各部位高度经过量测确保无误以用于模拟淹没高度,通过图像处理共模拟了184种不同深度与拍摄角度的淹没情况保证泛用性.
用于可行性验证的社交媒体实验采用的数据集来源于“新浪微博”社交媒体平台上以关键词“郑州”和“暴雨”为目标获取的、经过时间筛选的“7.20”郑州城市市区内涝事件共计415张无重复图像.
1.7. 模型构建
关键部位识别法的模型识别对象如下:以“轿车”为关键物体,选取该关键物体的“轮胎”、“车灯”、“把手”、“后视镜”、“车牌”共5个外观部件.
模型训练的硬件环境如下:处理器为intel(R) Core(TM) i7-9750H CPU,内存为16 G,显卡为NVIDIA GeForce GTX
关键物体与关键部位识别模型的初始参数如下:训练迭代次数epoch= 300,较多的迭代次数可以使模型学习更充分,但如果过多,可能导致过拟合;每次训练的样本数目batch_size= 16,较大的批量大小可以提高训练效率,但也可能使模型陷入局部极小值或漏掉最优解,较小的批量大小可以帮助模型更好地泛化,但同时可能增加训练时间.
选取的超参数如下:初始学习率lr0= 0.01,权重衰减为
Mask-RCNN模型的训练在开源软件算法库(tensorflow=1.15.0)框架下进行,使用的编程语言为python3.7,使用CPU训练,具体参数设定值如下:epoch = 300,learning_rate =
1.8. 模型精度评价标准
选取以下几个常用的误差评价指标作为提取水深的评价指标:平均绝对误差(mean absolute error, MAE)、平均绝对百分误差(mean absolute percentage error, MAPE)、均方根误差(root mean square error, RMSE)和纳什效率系数(Nash-Sutcliffe efficiency coefficient, NSE),表达式如下:
式中:
2. 实验设计
2.1. 模拟实验
中国虽为洪涝灾害频发区,但存有洪水全过程数据记录的城市市区洪涝事件非常稀少,且现有的淹没深度数据往往无法与社交媒体图像的地点与时间相符. 若只使用这些数据对上述2种水深识别法进行评估可能会得到不可靠的结论,如对于关键部位识别法,虽然能够通过关键部位识别率对方法的精度进行简单评价,但难以对提取得到的淹没深度进行评价,对于淹没等级识别法则完全无法进行有效的误差评价.
选择以模拟淹没识别实验为主、社交媒体图像识别实验为辅的方法进行模型精度测试. 模拟淹没识别实验的具体步骤如下:拍摄大量不同角度与高度情况下的“轿车”图片,通过图像处理模拟关键物体被洪涝灾害淹没,例如使用与内涝淹没颜色相近的色块遮盖车辆的部分部件以实现某些关键部位被洪涝淹没或者到达某个淹没等级的效果以模拟不同的内涝水深
具体实验方法如下:设计2种淹没情况对拍摄的图像进行处理,2种情况都能够识别出“轿车”关键物体,且都存在用色块代表的内涝洪水. 在第1种情况下,图像中关键部位显示连续,2种模型单独使用都能得到精确结果;在第2种情况图像下,有非内涝洪水阻挡某些关键部位或形成条带状未与淹没部分相接的遮挡,在这种情况下2种模型往往都不能得到较好的结果,而所提出的组合模型则能取得较好的效果.
将这些图像输入模型进行识别,将提取得到的图像淹没深度
2.2. 社交媒体图像实验
与模拟实验相比,在实际应用社交媒体图像时,还须考虑到社交媒体用户上传图像的晃动、解析度与拍摄角度等问题. 部分社交媒体平台存在压缩用户上传图像的问题,而过低的解析度非常容易导致识别误差,不同的拍摄角度可能导致图像中虽无内涝情况但存在关键部位被阻挡,因此还须验证实际社交媒体洪涝事件图像的实用性. 将2个模型所得结果进行交叉比对后统计得到各地点洪涝淹没高度,与已有的相近地点的实测城市市区内涝水深进行比对,以验证模型的有效性.
社交媒体图像实验的主要目的是验证所提出模型在实际应用场景中的可行性,由于现有实测数据在时间与空间角度上无法与所提取结果进行匹配,故取淹没水深模型重演结果进行验证 [20] .
2.3. 对比模型
除了所提出的基于YOLOv5和Mask-RCNN的组合模型以外,还选用YOLOv5与Mask-RCNN单模型进行对比实验,比较3个模型的各个精度指标以体现所提出模型的有效性.
3. 实验成果与分析
3.1. 社交媒体获取结果
以“郑州”和“暴雨”为目标获取的经过时间筛选的“7.20”郑州城市市区内涝事件文字信息共有
表 3 社交媒体文字信息获取示例
Tab.3
| 用户名 | 内容 | 发布时间 | 关键词 | 地点 |
| 用户A | #郑州大暴雨#淋得真棒 高抬腿走路 水淹大腿了 | 2021−07−21 21∶11:03 | #郑州大暴雨# | 郑州·花园路 |
| 用户B | #郑州大暴雨# 希望排水系统给力一些! | 2021−07−21 20:22:03 | #郑州大暴雨# | 郑州·祝福红城 |
| 用户C | #郑州特大暴雨为千年一遇##郑州暴雨# 看图 | 2021−07−21 00:22:03 | #郑州特大暴雨为千年一遇# | 郑州·河南省体育馆 |
3.2. 模拟实验评价
模拟实验共拍摄图像46张,通过图像处理共模拟了184种不同深度与拍摄角度的淹没情况.
图 5

图 5 YOLOv5图像识别模拟实验示例
Fig.5 Examples of image recognition simulation experiment using YOLOv5
图 6

图 6 Mask-RCNN图像识别模拟实验示例
Fig.6 Examples of image recognition simulation experiment using Mask-RCNN
表 4 3种水深提取模型的模拟实验误差分析
Tab.4
| 模型 | ||||
| YOLOv5 | 96.69 | 146.30 | ||
| Mask-RCNN | 137.40 | 227.60 | ||
| YOLOv5 &Mask-RCNN | 54.42 | 91.67 |
3种模型的模拟实验图像结果如图7所示. 可以看出,3种淹没深度提取方法都具有较高的精度,所提出的组合模型在精度上远高于YOLOv5与Mask-RCNN模型,组合模型克服了2种水深提取方法在水位极端值时的问题,展现出了较好的精度与可靠度,证明了方法的有效性.
图 7
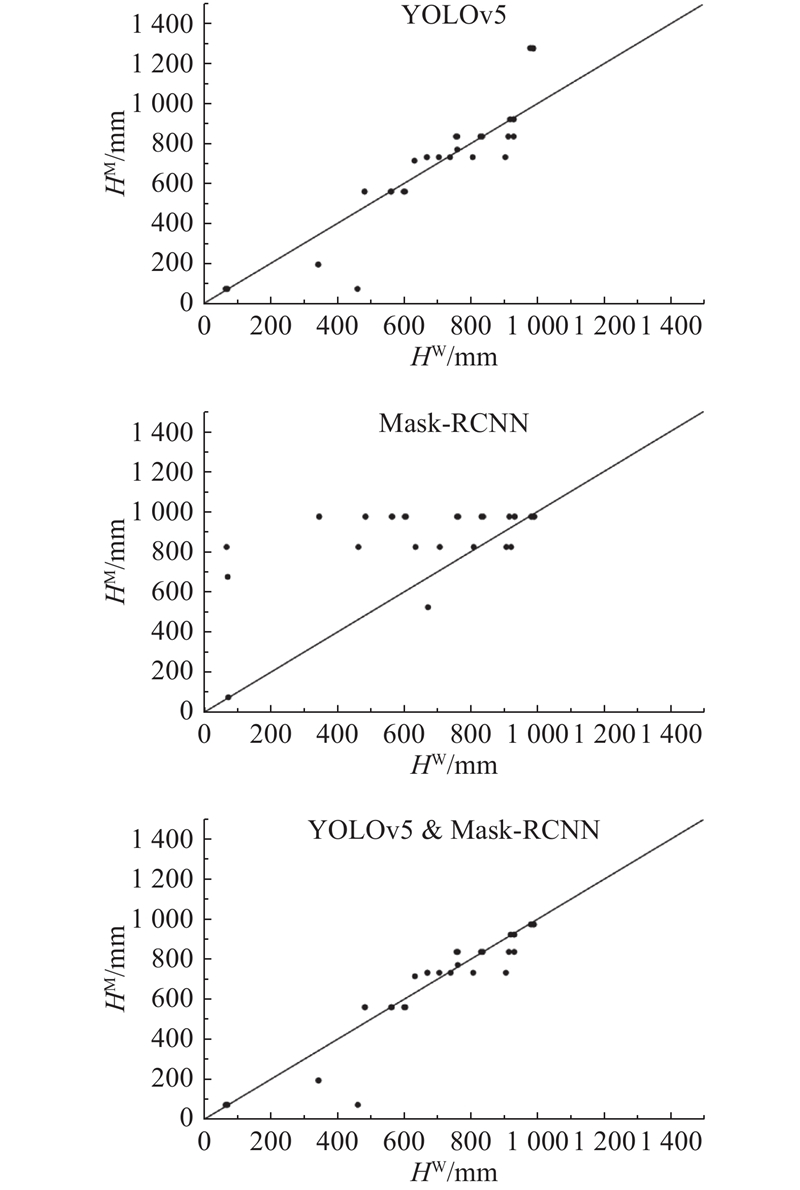
图 7 3种水深提取模型的模拟图像实验结果对比
Fig.7 Comparison of simulation experimental results of three water depth extraction models
对于YOLOv5模型,模型对各个关键部位的识别准确率各不相同,但未出现关键部位识别错误的问题,识别模型的准确度较高,转换为淹没深度后对内涝淹没深度的预测误差基本符合预期要求,说明各个关键部位的选取与高度标准制定较为合理. 同时,多个关键物体的存在并未使模型识别的精度与准确度降低,反而有利于交叉比对以弥补单一关键物体的关键部位识别漏缺,从而提高图像淹没深度的精确度. 在部分车体被遮挡后,即使关键部位未被遮挡,也会出现无法识别的结果,须在训练集中加入更多淹没情况下的车辆部位图像集. 若要进一步提高识别精度,可以增加关键物体或关键部位数量,从而弥补“淹没高度转换条带”的空缺.
对于Mask-RCNN模型,部分图像水深提取效果较好,由于比例划分更为细致,在某些情况下相比YOLOv5模型,精度有所增高. 可能是选用的训练集图像角度过于固定,对于俯视角的洪水图像识别效果较好,而对于其他视角的图像会出现识别误差较大甚至无法识别的情况,说明仍须进行更大数据量、更多图像情况的训练. 其在水位较高值时的提取精度远高于YOLOv5模型的,在组合模型中将其输出选为淹没深度上限值较合理.
整体而言,YOLOv5模型对图像的适用性较广,能够从图像中提取更多的数据,不容易出现深度信息的遗漏. Mask-RCNN模型的精度更高,但识别容易出现误差,对图像的要求也更高. 2个模型互相补充,能够更好地从淹没图像中提取淹没深度.
3.3. 社交媒体实验评价
图 8

图 8 两模型的社交媒体图像识别实验结果示例
Fig.8 Examples of social media image recognition experiment using two models
表 5 城市市区地点内涝水深示例
Tab.5
| 地点 | |||||
| 图像1 | 图像2 | 图像3 | 图像4 | 图像5 | |
| 郑州·祝福红城 | 75.0 | 75.0 | 562.0 | 718.0 | 737.0 |
| 郑州·富田太阳城 | 75.0 | 562.0 | 562.0 | 197.0 | — |
| 郑州·火车站 | 562 | 75.0 | 75.0 | 75.0 | — |
| 郑州·商都嘉园穆庄小区东院 | 75.0 | 75.0 | 75.0 | 75.0 | 737.0 |
作为验证数据的淹没水深反演模型,其数据为郑州市各个地点在0~2.00 m范围内,以0.25 m为间隔的淹没水深. 在本研究方法与验证数据重合的12个淹没地点中,本研究方法提取得到的淹没水深准确度达到75%,取得了较好的效果.
3.4. 讨论
通过观察模拟实验与社交媒体图像实验结果可以得出,整体而言,2种模型的识别准确度均较高,精度基本符合应用要求,且识别速度较快,平均每张图片识别时间为0.005 s. 由此可以看出,本研究所提出的水深提取方法效果较好、速度较快,具有实用价值. 但是,所提方法也存在一些不足之处,后续还可以在以下几个方面进行改进.
对于YOLOv5模型识别结果转换方法: 1)须增加关键物体与关键部位的识别模型数量,如不同的轿车品牌与型号、更多的部位与拍摄角度. 目前内涝水深转换条带仍存在空缺段,水深提取精度仍存在较大提升空间;2)解决了社交媒体中物体不完整入照导致的难以根据淹没像素比例提取内涝水深的问题. 但关键部位的选取往往需要特征性,而具有显著特征且易于识别的关键部位往往存在较大的底部与顶部高度差,还须对关键部位进行淹没比例识别来进行代表水深的进一步划分;3)存在关键部位被非内涝水体,如倒下的树木遮挡导致水深提取错误的情况,须对遮挡物体是否为水体进行识别筛选以防止误判,可通过水体的颜色识别判断是否为内涝水体,或者直接剔除异常高度的遮挡.
对于Mask-RCNN模型识别结果转换方法:1)探究进行更细致的淹没等级划分训练的可行性,以实现模型精度最大化;2)需要更多的不同类型的图像用于训练以提高模型的泛用度,包括添加更多无识别对象的噪声图. 3)在图像中存在多个关键物体时,模型的识别往往会出现较大误差甚至无法识别出淹没等级的问题,须进一步优化.
4. 结 语
提出全新的城市内涝水深提取方法,使用发布在“新浪微博”社交媒体平台上的文字与图像信息,针对淹没图像中常见的物体,通过关键部位与淹没等级转换标准提取地点的内涝水深,并将识别率与误差率作为实验精度评价指标.
解决了市区洪水全过程数据量易缺失、难以进行城市洪水物理模型精度验证的重大问题. 通过模拟与室内实验证明了本研究所提方法具有较好的识别准确性与可靠度,能够实现厘米级别误差的水深估计,纳什效率系数达到了0.982. 后续可通过增加关键物体识别模型的数量进一步提升水深识别精度.
基于YOLOv5 和 Mask-RCNN组合模型的图像水深提取算法兼具较快的识别速度与较好的识别精度. 对郑州“7.20”事件进行验证,淹没水深精度达到75%,且越是人口密集的城市、经济损失越大的市区内涝灾害,社交媒体平台越能提供更多的图像数据,识别的地点范围与精度也就越高.
参考文献
从郑州“2021.7. 20”水灾模型推演看城市洪涝风险管理
[J].
Thoughts and inspirations: urban flood risk management inferred from Zhengzhou flood model
[J].
2001—2020年中国洪涝灾害损失与致灾危险性研究
[J].
Floods losses and hazards in China from 2001 to 2020
[J].
郑州“7·20”特大暴雨内涝成因及灾害防控
[J].
Waterlogging cause and disaster prevention and control of “7·20” torrential rain in Zhengzhou
[J].
A geographic approach for combining social media and authoritative data towards identifying useful information for disaster management
[J].DOI:10.1080/13658816.2014.996567 [本文引用: 1]
Rapid flood inundation mapping using social media, remote sensing and topographic data
[J].
Social network analysis: characteristics of online social networks after a disaster
[J].DOI:10.1016/j.ijinfomgt.2017.08.003 [本文引用: 1]
大数据时代的社交媒体与自然灾害治理
[J].
Social media and natural disaster management in the era of big data
[J].
面向不同用户群体的社交媒体台风舆情演化分析及对比研究
[J].
Analysis and comparative study of the evolution of public opinion on social media during typhoon for different user groups
[J].
Why do people share fake news? Associations between the dark side of social media use and fake news sharing behavior
[J].
基于两阶段深度学习的水位智能识别方法
[J].
Intelligent recognition algorithm for water level measurement based on improved YOLOX-S algorithm
[J].
南方平原河网区城市内涝的全过程监测与特征分析
[J].
Monitoring and characterization of the entire urban flooding process in the typical southern plain river network area
[J].
Real-time water level monitoring using live cameras and computer vision techniques
[J].DOI:10.1016/j.cageo.2020.104642 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}