[1]
WANG J, XU C, ZHANG J, et al Big data analytics for intelligent manufacturing systems: a review
[J]. Journal of Manufacturing Systems , 2022 , 62 : 738 - 752
DOI:10.1016/j.jmsy.2021.03.005
[本文引用: 1]
[2]
ZHAO Y, LI T, ZHANG X, et al Artificial intelligence-based fault detection and diagnosis methods for building energy systems: advantages, challenges and the future
[J]. Renewable and Sustainable Energy Reviews , 2019 , 109 : 85 - 101
DOI:10.1016/j.rser.2019.04.021
[本文引用: 2]
[3]
ASKARIAN M, ESCUDERO G, GRAELLS M, et al Fault diagnosis of chemical processes with incomplete observations: a comparative study
[J]. Computers and Chemical Engineering , 2016 , 84 : 104 - 116
DOI:10.1016/j.compchemeng.2015.08.018
[本文引用: 1]
[4]
RAZAVI-FAR R, SAIF M, PALADE V, et al An integrated framework for diagnosing process faults with incomplete features
[J]. Knowledge and Information Systems , 2022 , 64 : 75 - 93
DOI:10.1007/s10115-021-01625-w
[本文引用: 1]
[5]
陈嘉宁, 杨翾, 叶承晋, 等 基于缺失数据修复的变压器在线故障诊断方法
[J]. 电力系统保护与控制 , 2019 , 47 (15 ): 86 - 92
DOI:10.7667/PSPC20191512
[本文引用: 1]
CHEN Jianing, YANG Xuan, YE Chengjin, et al On-line fault diagnosis method for power transformer based on missing data repair
[J]. Power System Protection and Control , 2019 , 47 (15 ): 86 - 92
DOI:10.7667/PSPC20191512
[本文引用: 1]
[6]
LIU R, MENG G, YANG B Y, et al Dislocated time series convolutional neural architecture: an intelligent fault diagnosis approach for electric machine
[J]. IEEE Transactions on Industrial Informatics , 2017 , 13 (3 ): 1310 - 1320
DOI:10.1109/TII.2016.2645238
[本文引用: 4]
[7]
DEVLIN J, CHANG M, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Minneapolis: Association for Computational Linguistics, 2019: 4171–4186.
[本文引用: 1]
[8]
LI B, HU Y, NIE X, et al. DropKey for Vision Transformer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 22700–22709.
[本文引用: 1]
[9]
WU Z, WU L, MENG Q, et al. UniDrop: a simple yet effective technique to improve Transformer without extra cost [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . [S.l.]: Association for Computational Linguistics, 2021: 3865–3878.
[本文引用: 1]
[10]
FENG Z, LIANG M, CHU F Recent advances in time–frequency analysis methods for machinery fault diagnosis: a review with application examples
[J]. Mechanical Systems and Signal Processing , 2013 , 38 (1 ): 165 - 205
DOI:10.1016/j.ymssp.2013.01.017
[本文引用: 1]
[11]
钟凯. 基于多元统计分析的故障检测与诊断研究[D]. 大连: 大连理工大学, 2020.
[本文引用: 2]
ZHONG Kai. Multivariate statistical analysis based fault detection and diagnosis [D]. Dalian: Dalian University of Technology, 2020.
[本文引用: 2]
[12]
SINGH V, GANGSAR P, PORWAL R, et al Artificial intelligence application in fault diagnostics of rotating industrial machines: a state-of-the-art review
[J]. Journal of Intelligent Manufacturing , 2021 , 34 (3 ): 931 - 960
[本文引用: 1]
[13]
VOS K, PENG Z, JENKINS C, et al Vibration-based anomaly detection using LSTM/SVM approaches
[J]. Mechanical Systems and Signal Processing , 2022 , 169 : 108752
DOI:10.1016/j.ymssp.2021.108752
[本文引用: 1]
[14]
李兵, 韩睿, 何怡刚, 等 改进随机森林算法在电机轴承故障诊断中的应用
[J]. 中国电机工程学报 , 2020 , 40 (4 ): 1310 - 1319
[本文引用: 1]
LI Bing, HAN Rui, HE Yigang, et al Applications of improved random forest algorithm in fault diagnosis of motor bearings
[J]. Proceedings of the CSEE , 2020 , 40 (4 ): 1310 - 1319
[本文引用: 1]
[15]
ZHU Z, LEI Y, QI G, et al A review of the application of deep learning in intelligent fault diagnosis of rotating machinery
[J]. Measurement , 2023 , 206 : 112346
DOI:10.1016/j.measurement.2022.112346
[本文引用: 2]
[16]
CUI M, WANG Y, LIN X, et al Fault diagnosis of rolling bearings based on an improved stack autoencoder and support vector machine
[J]. IEEE Sensors Journal , 2021 , 21 (4 ): 4927 - 4937
DOI:10.1109/JSEN.2020.3030910
[本文引用: 1]
[17]
GUO X, SHEN C, CHEN L Deep fault recognizer: an integrated model to denoise and extract features for fault diagnosis in rotating machinery
[J]. Applied Sciences , 2017 , 7 (1 ): 41
[本文引用: 1]
[18]
WEN L, LI X, GAO L, et al A new convolutional neural network-based data-driven fault diagnosis method
[J]. IEEE Transactions on Industrial Electronics , 2018 , 65 (7 ): 5990 - 5998
DOI:10.1109/TIE.2017.2774777
[本文引用: 2]
[19]
WANG P, ANANYA, YAN R, et al Virtualization and deep recognition for system fault classification
[J]. Journal of Manufacturing Systems , 2017 , 44 : 310 - 316
DOI:10.1016/j.jmsy.2017.04.012
[本文引用: 1]
[20]
CHEN X, ZHANG B, GAO D Bearing fault diagnosis base on multi-scale CNN and LSTM model
[J]. Journal of Intelligent Manufacturing , 2021 , 32 : 971 - 987
DOI:10.1007/s10845-020-01600-2
[本文引用: 2]
[21]
AN Z, LI S, WANG J, et al A novel bearing intelligent fault diagnosis framework under time-varying working conditions using recurrent neural network
[J]. ISA Transactions , 2020 , 100 : 155 - 170
DOI:10.1016/j.isatra.2019.11.010
[本文引用: 1]
[22]
LIU H, ZHOU J, ZHENG Y, et al Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders
[J]. ISA Transactions , 2018 , 77 : 167 - 178
DOI:10.1016/j.isatra.2018.04.005
[本文引用: 1]
[23]
ZHAO R, WANG D, YAN R, et al Machine health monitoring using local feature-based gated recurrent unit networks
[J]. IEEE Transactions on Industrial Electronics , 2018 , 65 (2 ): 1539 - 1548
DOI:10.1109/TIE.2017.2733438
[本文引用: 1]
[24]
BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [C]// 3rd International Conference on Learning Representations . San Diego: [s.n.], 2015.
[本文引用: 3]
[25]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . La Jolla: [s.n.], 2017: 6000–6010.
[本文引用: 4]
[26]
KHAN S, NASEER M, HAYAT M, et al Transformers in vision: a survey
[J]. ACM Computing Surveys , 2022 , 54 (10s ): 200
[本文引用: 2]
[27]
PEI X, ZHENG X, WU J Rotating machinery fault diagnosis through a transformer convolution network subjected to transfer learning
[J]. IEEE Transactions on Instrumentation and Measurement , 2021 , 70 : 2515611
[本文引用: 1]
[28]
王誉翔, 钟智伟, 夏鹏程, 等 基于改进Transformer的复合故障解耦诊断方法
[J]. 浙江大学学报: 工学版 , 2023 , 57 (5 ): 855 - 864
[本文引用: 1]
WANG Yuxiang, ZHONG Zhiwei, XIA Pengcheng, et al Compound fault decoupling diagnosis method based on improved Transformer
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (5 ): 855 - 864
[本文引用: 1]
[29]
CHE Z, URUSHOTHAM S, CHO K, et al Recurrent neural networks for multivariate time series with missing values
[J]. Scientific Reports , 2018 , 8 : 6085
DOI:10.1038/s41598-018-24271-9
[本文引用: 3]
[30]
SONG L, GONG D, LI Z, et al. Occlusion robust face recognition based on mask learning with pairwise differential siamese network [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 773–782.
[本文引用: 1]
[31]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 1]
[32]
SMITH W A, RANDALL R B, et al Rolling element bearing diagnostics using the Case Western Reserve University data: a benchmark study
[J]. Mechanical Systems and Signal Processing , 2015 , 64/65 : 100 - 131
DOI:10.1016/j.ymssp.2015.04.021
[本文引用: 1]
[33]
LESSMEIER C, KIMOTHO J K, ZIMMER D, et al. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: a benchmark data set for data-driven classification [C]// European Conference of the Prognostics and Health Management Society . [S.l.]: Prognostics and Health Management Society, 2016.
[本文引用: 1]
[34]
SHAO S, MCALEER S, YAN R, et al Highly accurate machine gault diagnosis using deep transfer learning
[J]. IEEE Transactions on Industrial Informatics , 2019 , 15 (4 ): 2446 - 2455
DOI:10.1109/TII.2018.2864759
[本文引用: 1]
[35]
WANG B, LEI Y, LI N, et al A hybrid prognostics approach for estimating remaining useful life of rolling element bearings
[J]. IEEE Transactions on Reliability , 2020 , 69 (1 ): 401 - 412
DOI:10.1109/TR.2018.2882682
[本文引用: 1]
[36]
LIN W, TSAI C Missing value imputation: a review and analysis of the literature (2006–2017)
[J]. Artificial Intelligence Review , 2020 , 53 : 1487 - 1509
DOI:10.1007/s10462-019-09709-4
[本文引用: 1]
[37]
郭毅博, 牛猛, 王海迪, 等 基于生成对抗网络的飞机燃油数据缺失值填充方法
[J]. 浙江大学学报: 理学版 , 2021 , 48 (4 ): 402 - 409
[本文引用: 1]
GUO Yibo, NIU Meng, WANG Haidi, et al An aircraft fuel data missing value filling method with generative adversarial network
[J]. Journal of Zhejiang University: Science Edition , 2021 , 48 (4 ): 402 - 409
[本文引用: 1]
Big data analytics for intelligent manufacturing systems: a review
1
2022
... 随着传感器技术、新一代通信技术与人工智能的发展,生产制造业的各个环节逐步摆脱对专家经验的高度依赖,转向由数据驱动的发展模式[1 ] . 基于传感器数据的故障检测与诊断(detection and diagnosis of fault, FDD)在监测设备运行状态和保障系统稳定运行方面起到重要作用,是智能化生产的重点研究方向[2 ] . 作为数据驱动方法的一种,深度学习方法严重依赖设备的健康监测数据. 在实际生产中,由于传感器可靠性随时间推移下降,传感器失效的情况普遍存在,导致大量无效数据被采集. 传感器失效带来的观测样本的失真,破坏了数据原本的分布,影响了深度学习模型所提取特征的质量,为故障诊断带来了负面影响. 一种处理失效数据的方式是直接剔除[3 ] 或利用数据冗余性对失效部分进行预测[4 ] ,此类方法需要失效位置的指示信息,但从海量数据中精确标注出失效位置较为困难. 另一种方式是采取柔性策略提高模型的泛化能力和容错特性[5 ] ,深度模型〔如卷积神经网络(convolutional neural network,CNN)〕提取的表征包含故障分类的关键信息,因此具有容错特性,但受深度模型感受野的限制,这种表示学习能力往往难以融合全局信息[6 ] . 在传感器大范围失效的情况下,局部特征受失效数据干扰的可能性更大,不利于故障的诊断. ...
Artificial intelligence-based fault detection and diagnosis methods for building energy systems: advantages, challenges and the future
2
2019
... 随着传感器技术、新一代通信技术与人工智能的发展,生产制造业的各个环节逐步摆脱对专家经验的高度依赖,转向由数据驱动的发展模式[1 ] . 基于传感器数据的故障检测与诊断(detection and diagnosis of fault, FDD)在监测设备运行状态和保障系统稳定运行方面起到重要作用,是智能化生产的重点研究方向[2 ] . 作为数据驱动方法的一种,深度学习方法严重依赖设备的健康监测数据. 在实际生产中,由于传感器可靠性随时间推移下降,传感器失效的情况普遍存在,导致大量无效数据被采集. 传感器失效带来的观测样本的失真,破坏了数据原本的分布,影响了深度学习模型所提取特征的质量,为故障诊断带来了负面影响. 一种处理失效数据的方式是直接剔除[3 ] 或利用数据冗余性对失效部分进行预测[4 ] ,此类方法需要失效位置的指示信息,但从海量数据中精确标注出失效位置较为困难. 另一种方式是采取柔性策略提高模型的泛化能力和容错特性[5 ] ,深度模型〔如卷积神经网络(convolutional neural network,CNN)〕提取的表征包含故障分类的关键信息,因此具有容错特性,但受深度模型感受野的限制,这种表示学习能力往往难以融合全局信息[6 ] . 在传感器大范围失效的情况下,局部特征受失效数据干扰的可能性更大,不利于故障的诊断. ...
... 早期的由数据驱动的故障诊断方法(如短时傅里叶变换、小波变换的时频域分析方法[10 ] )实现复杂度低,在强噪声干扰、大面积故障和变速变载的情况下效果不理想[2 ] . 多元统计分析方法基于统计建模,且建模和诊断过程分开进行,有着较强的实时性. 实际数据不一定完全满足假定的统计特性,诊断结果可能会有所偏差[11 ] . 基于机器学习的故障诊断模型,学习从数据空间到标签空间的映射,表达式为 ...
Fault diagnosis of chemical processes with incomplete observations: a comparative study
1
2016
... 随着传感器技术、新一代通信技术与人工智能的发展,生产制造业的各个环节逐步摆脱对专家经验的高度依赖,转向由数据驱动的发展模式[1 ] . 基于传感器数据的故障检测与诊断(detection and diagnosis of fault, FDD)在监测设备运行状态和保障系统稳定运行方面起到重要作用,是智能化生产的重点研究方向[2 ] . 作为数据驱动方法的一种,深度学习方法严重依赖设备的健康监测数据. 在实际生产中,由于传感器可靠性随时间推移下降,传感器失效的情况普遍存在,导致大量无效数据被采集. 传感器失效带来的观测样本的失真,破坏了数据原本的分布,影响了深度学习模型所提取特征的质量,为故障诊断带来了负面影响. 一种处理失效数据的方式是直接剔除[3 ] 或利用数据冗余性对失效部分进行预测[4 ] ,此类方法需要失效位置的指示信息,但从海量数据中精确标注出失效位置较为困难. 另一种方式是采取柔性策略提高模型的泛化能力和容错特性[5 ] ,深度模型〔如卷积神经网络(convolutional neural network,CNN)〕提取的表征包含故障分类的关键信息,因此具有容错特性,但受深度模型感受野的限制,这种表示学习能力往往难以融合全局信息[6 ] . 在传感器大范围失效的情况下,局部特征受失效数据干扰的可能性更大,不利于故障的诊断. ...
An integrated framework for diagnosing process faults with incomplete features
1
2022
... 随着传感器技术、新一代通信技术与人工智能的发展,生产制造业的各个环节逐步摆脱对专家经验的高度依赖,转向由数据驱动的发展模式[1 ] . 基于传感器数据的故障检测与诊断(detection and diagnosis of fault, FDD)在监测设备运行状态和保障系统稳定运行方面起到重要作用,是智能化生产的重点研究方向[2 ] . 作为数据驱动方法的一种,深度学习方法严重依赖设备的健康监测数据. 在实际生产中,由于传感器可靠性随时间推移下降,传感器失效的情况普遍存在,导致大量无效数据被采集. 传感器失效带来的观测样本的失真,破坏了数据原本的分布,影响了深度学习模型所提取特征的质量,为故障诊断带来了负面影响. 一种处理失效数据的方式是直接剔除[3 ] 或利用数据冗余性对失效部分进行预测[4 ] ,此类方法需要失效位置的指示信息,但从海量数据中精确标注出失效位置较为困难. 另一种方式是采取柔性策略提高模型的泛化能力和容错特性[5 ] ,深度模型〔如卷积神经网络(convolutional neural network,CNN)〕提取的表征包含故障分类的关键信息,因此具有容错特性,但受深度模型感受野的限制,这种表示学习能力往往难以融合全局信息[6 ] . 在传感器大范围失效的情况下,局部特征受失效数据干扰的可能性更大,不利于故障的诊断. ...
基于缺失数据修复的变压器在线故障诊断方法
1
2019
... 随着传感器技术、新一代通信技术与人工智能的发展,生产制造业的各个环节逐步摆脱对专家经验的高度依赖,转向由数据驱动的发展模式[1 ] . 基于传感器数据的故障检测与诊断(detection and diagnosis of fault, FDD)在监测设备运行状态和保障系统稳定运行方面起到重要作用,是智能化生产的重点研究方向[2 ] . 作为数据驱动方法的一种,深度学习方法严重依赖设备的健康监测数据. 在实际生产中,由于传感器可靠性随时间推移下降,传感器失效的情况普遍存在,导致大量无效数据被采集. 传感器失效带来的观测样本的失真,破坏了数据原本的分布,影响了深度学习模型所提取特征的质量,为故障诊断带来了负面影响. 一种处理失效数据的方式是直接剔除[3 ] 或利用数据冗余性对失效部分进行预测[4 ] ,此类方法需要失效位置的指示信息,但从海量数据中精确标注出失效位置较为困难. 另一种方式是采取柔性策略提高模型的泛化能力和容错特性[5 ] ,深度模型〔如卷积神经网络(convolutional neural network,CNN)〕提取的表征包含故障分类的关键信息,因此具有容错特性,但受深度模型感受野的限制,这种表示学习能力往往难以融合全局信息[6 ] . 在传感器大范围失效的情况下,局部特征受失效数据干扰的可能性更大,不利于故障的诊断. ...
基于缺失数据修复的变压器在线故障诊断方法
1
2019
... 随着传感器技术、新一代通信技术与人工智能的发展,生产制造业的各个环节逐步摆脱对专家经验的高度依赖,转向由数据驱动的发展模式[1 ] . 基于传感器数据的故障检测与诊断(detection and diagnosis of fault, FDD)在监测设备运行状态和保障系统稳定运行方面起到重要作用,是智能化生产的重点研究方向[2 ] . 作为数据驱动方法的一种,深度学习方法严重依赖设备的健康监测数据. 在实际生产中,由于传感器可靠性随时间推移下降,传感器失效的情况普遍存在,导致大量无效数据被采集. 传感器失效带来的观测样本的失真,破坏了数据原本的分布,影响了深度学习模型所提取特征的质量,为故障诊断带来了负面影响. 一种处理失效数据的方式是直接剔除[3 ] 或利用数据冗余性对失效部分进行预测[4 ] ,此类方法需要失效位置的指示信息,但从海量数据中精确标注出失效位置较为困难. 另一种方式是采取柔性策略提高模型的泛化能力和容错特性[5 ] ,深度模型〔如卷积神经网络(convolutional neural network,CNN)〕提取的表征包含故障分类的关键信息,因此具有容错特性,但受深度模型感受野的限制,这种表示学习能力往往难以融合全局信息[6 ] . 在传感器大范围失效的情况下,局部特征受失效数据干扰的可能性更大,不利于故障的诊断. ...
Dislocated time series convolutional neural architecture: an intelligent fault diagnosis approach for electric machine
4
2017
... 随着传感器技术、新一代通信技术与人工智能的发展,生产制造业的各个环节逐步摆脱对专家经验的高度依赖,转向由数据驱动的发展模式[1 ] . 基于传感器数据的故障检测与诊断(detection and diagnosis of fault, FDD)在监测设备运行状态和保障系统稳定运行方面起到重要作用,是智能化生产的重点研究方向[2 ] . 作为数据驱动方法的一种,深度学习方法严重依赖设备的健康监测数据. 在实际生产中,由于传感器可靠性随时间推移下降,传感器失效的情况普遍存在,导致大量无效数据被采集. 传感器失效带来的观测样本的失真,破坏了数据原本的分布,影响了深度学习模型所提取特征的质量,为故障诊断带来了负面影响. 一种处理失效数据的方式是直接剔除[3 ] 或利用数据冗余性对失效部分进行预测[4 ] ,此类方法需要失效位置的指示信息,但从海量数据中精确标注出失效位置较为困难. 另一种方式是采取柔性策略提高模型的泛化能力和容错特性[5 ] ,深度模型〔如卷积神经网络(convolutional neural network,CNN)〕提取的表征包含故障分类的关键信息,因此具有容错特性,但受深度模型感受野的限制,这种表示学习能力往往难以融合全局信息[6 ] . 在传感器大范围失效的情况下,局部特征受失效数据干扰的可能性更大,不利于故障的诊断. ...
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
... [6 ]. Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
... [6 ]提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
1
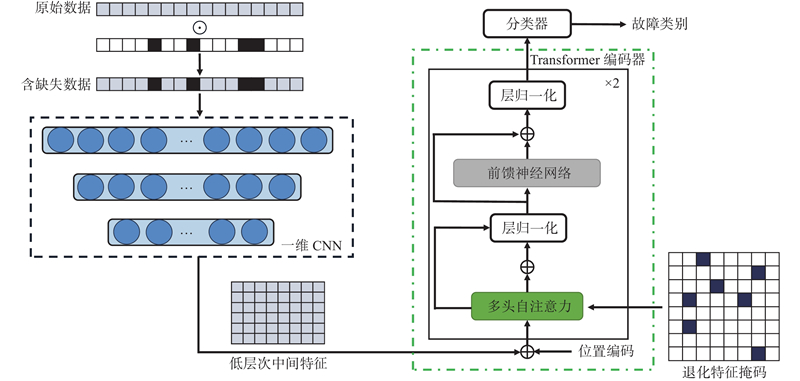
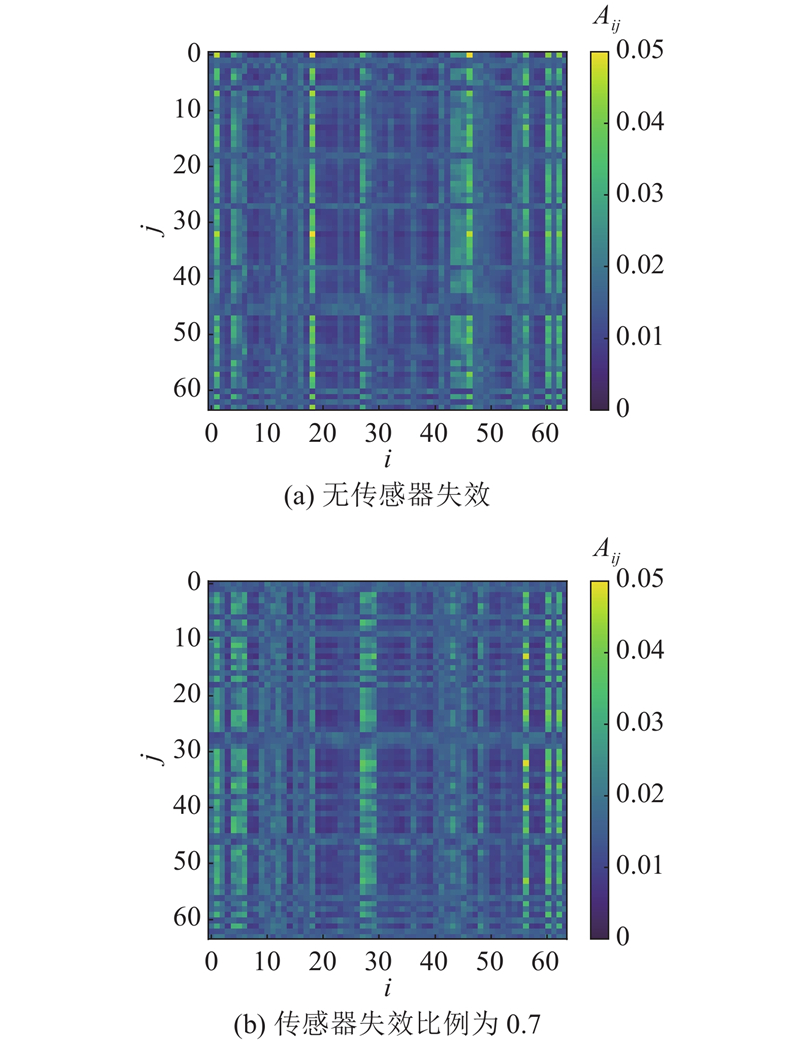
... 本研究提出带有退化特征惩罚机制的故障诊断方法(fault diagnosis method with corrupted feature penalties, FDCFP),使用自注意力机制来融合全局信息,提升FDCFP模型的失效传感器容错能力. 自注意力融合基于特征间相关性的加权求和机制,使输出具有全局性,能够平滑局部失效的影响. 自然语言处理领域的BERT模型[7 ] 在预训练中人为制造缺失,以此来提高模型的学习能力和泛化性能. 自注意力的核心在于特征相关性的表示,但传感器失效引入了不确定的特征关联关系,影响了特征的表示能力. 具体来说,大面积的传感器失效导致特征中的部分信息被损坏(出现特征退化),随着失效比例的增加,退化特征的相关性增大,退化特征与正常特征的相关性相应减小,在注意力层表现为退化特征的注意力权重增大,正常特征的权重减小. 在Transformer模型内,前次迭代权重较高的特征在下次迭代过程中倾向于被分配更大的注意力权重[8 ] ,这强化了退化特征的负面影响,加重了Transformer结构存在的过拟合问题[9 ] ,使得编码器更关注数据中的失效部分. 在注意力权重的计算过程中,本研究使用掩码操作来随机摒弃一部分注意力权重,对这种失效造成的特征间的伪关联性进行惩罚,缓解学习过程中退化特征相似性增大的问题,使模型更关注全局的优化目标. ...
1
... 本研究提出带有退化特征惩罚机制的故障诊断方法(fault diagnosis method with corrupted feature penalties, FDCFP),使用自注意力机制来融合全局信息,提升FDCFP模型的失效传感器容错能力. 自注意力融合基于特征间相关性的加权求和机制,使输出具有全局性,能够平滑局部失效的影响. 自然语言处理领域的BERT模型[7 ] 在预训练中人为制造缺失,以此来提高模型的学习能力和泛化性能. 自注意力的核心在于特征相关性的表示,但传感器失效引入了不确定的特征关联关系,影响了特征的表示能力. 具体来说,大面积的传感器失效导致特征中的部分信息被损坏(出现特征退化),随着失效比例的增加,退化特征的相关性增大,退化特征与正常特征的相关性相应减小,在注意力层表现为退化特征的注意力权重增大,正常特征的权重减小. 在Transformer模型内,前次迭代权重较高的特征在下次迭代过程中倾向于被分配更大的注意力权重[8 ] ,这强化了退化特征的负面影响,加重了Transformer结构存在的过拟合问题[9 ] ,使得编码器更关注数据中的失效部分. 在注意力权重的计算过程中,本研究使用掩码操作来随机摒弃一部分注意力权重,对这种失效造成的特征间的伪关联性进行惩罚,缓解学习过程中退化特征相似性增大的问题,使模型更关注全局的优化目标. ...
1
... 本研究提出带有退化特征惩罚机制的故障诊断方法(fault diagnosis method with corrupted feature penalties, FDCFP),使用自注意力机制来融合全局信息,提升FDCFP模型的失效传感器容错能力. 自注意力融合基于特征间相关性的加权求和机制,使输出具有全局性,能够平滑局部失效的影响. 自然语言处理领域的BERT模型[7 ] 在预训练中人为制造缺失,以此来提高模型的学习能力和泛化性能. 自注意力的核心在于特征相关性的表示,但传感器失效引入了不确定的特征关联关系,影响了特征的表示能力. 具体来说,大面积的传感器失效导致特征中的部分信息被损坏(出现特征退化),随着失效比例的增加,退化特征的相关性增大,退化特征与正常特征的相关性相应减小,在注意力层表现为退化特征的注意力权重增大,正常特征的权重减小. 在Transformer模型内,前次迭代权重较高的特征在下次迭代过程中倾向于被分配更大的注意力权重[8 ] ,这强化了退化特征的负面影响,加重了Transformer结构存在的过拟合问题[9 ] ,使得编码器更关注数据中的失效部分. 在注意力权重的计算过程中,本研究使用掩码操作来随机摒弃一部分注意力权重,对这种失效造成的特征间的伪关联性进行惩罚,缓解学习过程中退化特征相似性增大的问题,使模型更关注全局的优化目标. ...
Recent advances in time–frequency analysis methods for machinery fault diagnosis: a review with application examples
1
2013
... 早期的由数据驱动的故障诊断方法(如短时傅里叶变换、小波变换的时频域分析方法[10 ] )实现复杂度低,在强噪声干扰、大面积故障和变速变载的情况下效果不理想[2 ] . 多元统计分析方法基于统计建模,且建模和诊断过程分开进行,有着较强的实时性. 实际数据不一定完全满足假定的统计特性,诊断结果可能会有所偏差[11 ] . 基于机器学习的故障诊断模型,学习从数据空间到标签空间的映射,表达式为 ...
2
... 早期的由数据驱动的故障诊断方法(如短时傅里叶变换、小波变换的时频域分析方法[10 ] )实现复杂度低,在强噪声干扰、大面积故障和变速变载的情况下效果不理想[2 ] . 多元统计分析方法基于统计建模,且建模和诊断过程分开进行,有着较强的实时性. 实际数据不一定完全满足假定的统计特性,诊断结果可能会有所偏差[11 ] . 基于机器学习的故障诊断模型,学习从数据空间到标签空间的映射,表达式为 ...
... 式中:$ {\boldsymbol{D}} = [{{\boldsymbol{d}}_1},{{\boldsymbol{d}}_2}, \cdots ,{{\boldsymbol{d}}_n}] $ ${\boldsymbol{H}}$ N $\tilde {\boldsymbol{y}}$ [11 ] . Che等[29 ] 提出GRU-D模型,利用缺失的位置掩码和缺失间隔预测缺失模式,构建了端到端的缺失值填充模型,并将填充结果运用到故障诊断中. 由于GRU-D要求提供失效传感器的位置信息,导致数据分析和处理的工作量大大增加. 传感器失效造成的数据失真可类比目标检测中的遮挡问题,Song等[30 ] 提出对遮挡位置进行学习,并将得到的指示遮挡位置的特征丢弃掩码(feature discarding mask, FDM)保存在字典中,以便在后续检测任务中检索并摒弃遮挡区域. 但这种方法是静态的,不能处理字典中不存在的失效模式. 本研究将利用自注意力机制,在进行深层特征融合转换时直接对深层次特征进行随机摒弃处理. 自注意力层避开失效数据位置信息,直接利用全局信息预测退化特征. ...
2
... 早期的由数据驱动的故障诊断方法(如短时傅里叶变换、小波变换的时频域分析方法[10 ] )实现复杂度低,在强噪声干扰、大面积故障和变速变载的情况下效果不理想[2 ] . 多元统计分析方法基于统计建模,且建模和诊断过程分开进行,有着较强的实时性. 实际数据不一定完全满足假定的统计特性,诊断结果可能会有所偏差[11 ] . 基于机器学习的故障诊断模型,学习从数据空间到标签空间的映射,表达式为 ...
... 式中:$ {\boldsymbol{D}} = [{{\boldsymbol{d}}_1},{{\boldsymbol{d}}_2}, \cdots ,{{\boldsymbol{d}}_n}] $ ${\boldsymbol{H}}$ N $\tilde {\boldsymbol{y}}$ [11 ] . Che等[29 ] 提出GRU-D模型,利用缺失的位置掩码和缺失间隔预测缺失模式,构建了端到端的缺失值填充模型,并将填充结果运用到故障诊断中. 由于GRU-D要求提供失效传感器的位置信息,导致数据分析和处理的工作量大大增加. 传感器失效造成的数据失真可类比目标检测中的遮挡问题,Song等[30 ] 提出对遮挡位置进行学习,并将得到的指示遮挡位置的特征丢弃掩码(feature discarding mask, FDM)保存在字典中,以便在后续检测任务中检索并摒弃遮挡区域. 但这种方法是静态的,不能处理字典中不存在的失效模式. 本研究将利用自注意力机制,在进行深层特征融合转换时直接对深层次特征进行随机摒弃处理. 自注意力层避开失效数据位置信息,直接利用全局信息预测退化特征. ...
Artificial intelligence application in fault diagnostics of rotating industrial machines: a state-of-the-art review
1
2021
... 式中:${{\boldsymbol{d}}_i}$ i 个数据样本,${\tilde {\boldsymbol{y}}_i}$ $\theta $ [12 ] . 支持向量机(support vector machine, SVM)能够在高维空间中学习不同类别间的最大间隔边界,被广泛用于故障分类[13 ] . 随机森林(random forest, RF)基于集成学习的思想,选择决策树的多数分类结果作为最终结果. 虽然RF的泛化能力很强,但决策树数量的增多会增加算法的复杂度[14 ] . ...
Vibration-based anomaly detection using LSTM/SVM approaches
1
2022
... 式中:${{\boldsymbol{d}}_i}$ i 个数据样本,${\tilde {\boldsymbol{y}}_i}$ $\theta $ [12 ] . 支持向量机(support vector machine, SVM)能够在高维空间中学习不同类别间的最大间隔边界,被广泛用于故障分类[13 ] . 随机森林(random forest, RF)基于集成学习的思想,选择决策树的多数分类结果作为最终结果. 虽然RF的泛化能力很强,但决策树数量的增多会增加算法的复杂度[14 ] . ...
改进随机森林算法在电机轴承故障诊断中的应用
1
2020
... 式中:${{\boldsymbol{d}}_i}$ i 个数据样本,${\tilde {\boldsymbol{y}}_i}$ $\theta $ [12 ] . 支持向量机(support vector machine, SVM)能够在高维空间中学习不同类别间的最大间隔边界,被广泛用于故障分类[13 ] . 随机森林(random forest, RF)基于集成学习的思想,选择决策树的多数分类结果作为最终结果. 虽然RF的泛化能力很强,但决策树数量的增多会增加算法的复杂度[14 ] . ...
改进随机森林算法在电机轴承故障诊断中的应用
1
2020
... 式中:${{\boldsymbol{d}}_i}$ i 个数据样本,${\tilde {\boldsymbol{y}}_i}$ $\theta $ [12 ] . 支持向量机(support vector machine, SVM)能够在高维空间中学习不同类别间的最大间隔边界,被广泛用于故障分类[13 ] . 随机森林(random forest, RF)基于集成学习的思想,选择决策树的多数分类结果作为最终结果. 虽然RF的泛化能力很强,但决策树数量的增多会增加算法的复杂度[14 ] . ...
A review of the application of deep learning in intelligent fault diagnosis of rotating machinery
2
2023
... 基于深度学习的故障诊断方法大体分为特征提取和故障分类2个阶段[15 ] . 在特征提取阶段,通过堆叠多个隐藏层来提高模型的感知能力. 深度学习第k 层的模型结构表达式为 ...
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
Fault diagnosis of rolling bearings based on an improved stack autoencoder and support vector machine
1
2021
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
Deep fault recognizer: an integrated model to denoise and extract features for fault diagnosis in rotating machinery
1
2017
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
A new convolutional neural network-based data-driven fault diagnosis method
2
2018
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
... [18 ]将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
Virtualization and deep recognition for system fault classification
1
2017
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
Bearing fault diagnosis base on multi-scale CNN and LSTM model
2
2021
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
... [20 ]则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
A novel bearing intelligent fault diagnosis framework under time-varying working conditions using recurrent neural network
1
2020
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders
1
2018
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
Machine health monitoring using local feature-based gated recurrent unit networks
1
2018
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
3
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
... [24 ]的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
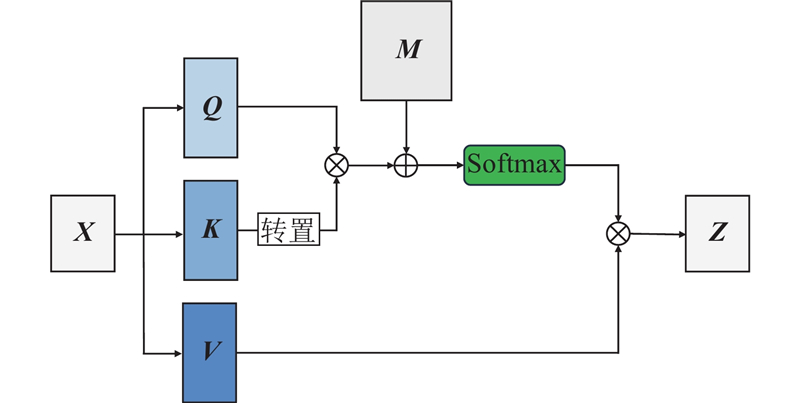
... 注意力机制[24 ] 的核心在于使用相关性度量函数计算注意力权重. 在进行注意力权重计算时,1)隐藏层状态分别作为查询(query)、键(key)和值(value);针对当前查询,量化所有键对当前查询的重要程度,作为注意力权重;2)计算下一个查询,直至得到描述所有查询和键之间关联的注意力权重矩阵;3)基于注意力权重矩阵对所有值进行加权求和,使模型动态聚焦输入的关键部分. 每个输入在作为查询的同时也要作为键和值,因此自注意力层首先对输入${\boldsymbol{X}}$
4
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
... 式中:矩阵${\boldsymbol{X}} = $ $ {[{{\boldsymbol{x}}_1},{{\boldsymbol{x}}_2}, \cdots ,{{\boldsymbol{x}}_n}]^{\text{T}}} \in {{{\bf{R}}}^{n \times d}} $ n 为输入特征的个数;d 为每个输入特征的维度;${\boldsymbol{Q}}$ ${\boldsymbol{K}}$ ${\boldsymbol{V}}$ $ {{\boldsymbol{W}}^Q} $ $ {{\boldsymbol{W}}^K} $ $ {{\boldsymbol{W}}^V} $ ${d_k}$ ${d_k} = 16$ . ${\boldsymbol{Q}}$ ${\boldsymbol{K}}$ [25 ] (scaled dot-product)进行量化处理,并通过Softmax层进行归一化处理,得到注意力权重矩阵${\boldsymbol{A}}$
... Transformer的编码器部分用于全局特征融合,主要结构包括多头自注意力层和前馈网络(feed-forward network, FFN)[25 ] ,它们都通过残差连接[31 ] . 在计算多头自注意力之前,FDCFP对CNN提取的低层特征进行层归一化,以稳定前向输入的分布. FFN由2层全连接层构成,是编码器拟合能力的核心. FFN层采用随机失活(dropout)避免过拟合,随机失活率设置为0.1. 多头自注意力用于捕获输出特征之间不同的关联, ...
... 式中:${{\boldsymbol{Z}}_i}$ i 个自注意力头的输出,$\hat {\boldsymbol{Z}}$ h 为多头自注意力的头数. 自注意力直接对特征的两两关联进行单独计算,突破了传统深度网络只能提取短距离依赖的局限性. 这种全局感知能力,有利于模型挖掘并利用多种关联对失效部分进行预测,提高了模型对失效传感器的鲁棒性. 两两关联计算忽略了数据的位置信息,可以通过位置编码[25 ] 来补偿. 由于模型缺失类似CNN和RNN的归纳偏置(如CNN的局部性和空间不变性,RNN的时间不变性),这些归纳偏置使模型的学习基于一定的先验性假设,避免了模型过度拟合的倾向,在一定程度上提高了模型的泛化性能. Transformer编码器的主要结构仍为全连接层,对数据特征的拟合完全依赖多头自注意力的引导,在传感器大范围失效的情况下,观测特征间的关联不代表真实数据间的关联,这为模型对数据特征的拟合提供了错误的导向,限制了模型性能的提升. ...
Transformers in vision: a survey
2
2022
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
... 卷积是CNN特征提取能力的核心,从频域角度来看,每个卷积核作为特定的滤波器,从原始信号中筛选出利于故障诊断目标的频谱特征,在反向传播过程中,对各滤波器进行优化调整,以训练出能够获得数据最优表示的特征提取模块. 受限于卷积核大小,CNN提取的关联具有局部性,对更长距离依赖关系的提取要依靠更深层网络的堆叠,这不利于处理长周期的机械振动信号,将CNN与Transformer相结合是解决该问题可行方法[26 ] . FDCFP将一维CNN用于学习数据的低维特征表示,再由Transformer对故障特征进行进一步融合. 如表1 所示,第1层CNN的卷积核大小设置为15,大卷积核有较大的感受野,能够以较低深度获取足够丰富的关联信息,确保不丢掉重要特征. 卷积层后跟随1个线性整流函数(rectified linear unit, ReLU)、批归一化层(batch normalization, BN)和最大池化层. 网络最后的池化层采用自适应最大池化层,以将输出特征保持在固定维度. 特征提取模块的最后通过全连接层与Transformer编码器相连接,最终输出特征图的大小为${\text{64}} \times {\text{8}}$ . ...
Rotating machinery fault diagnosis through a transformer convolution network subjected to transfer learning
1
2021
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
基于改进Transformer的复合故障解耦诊断方法
1
2023
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
基于改进Transformer的复合故障解耦诊断方法
1
2023
... 基于全连接的自动编码机(autoencoder, AE)[15 ] 及其改进,如堆叠自动编码机(stacked autoencoder, SAE)[16 ] 、去噪自动编码机(denoise autoencoder, DAE)[17 ] ,有着出色的特征提取能力,陆续被应用在故障诊断领域中. CNN能够感知空间局部关联,计算量比AE更少,许多方法基于CNN提取故障特征[6 ,18 -20 ] ,Wen等[18 ] 将一维信号截断拼接为二维,使用LeNet-5网络进行故障特征提取;Wang等[19 ] 将时频域方法与CNN结合,利用CNN对时频谱图进行特征提取. 这2种方法未考虑信号周期性带来的时频谱图与真实图片的差异,CNN的局部感知特性使模型只能利用全部关联关系的一部分[6 ] . Liu等[6 ] 提出错位时间序列卷积神经网络(dislocated time series convolutional neural network, DTS-CNN),以距离倍增的方式截取不同时间窗口的信号,并将截取信号拼接为矩阵作为CNN隐藏层的输入,提高了CNN对数据长距离关联的感知能力. 长短时记忆网络(long short term memory, LSTM)[21 ] 和门控循环单元(gate recurrent unit, GRU)[22 -23 ] 缓解了循环神经网络(recurrent neural network, RNN)结构固有的长距离依赖关联发掘能力不足的问题,在时序序列的特征提取中被广泛应用. Chen等[20 ] 则将CNN和LSTM相结合,利用2个不同核大小的CNN,提取不同尺度下的故障特征,并将融合后的特征输入LSTM,提高了故障诊断的精度. 注意力机制为长距离关联的利用带来了更多的可能性[24 ] . 自注意力是注意力机制[24 ] 的分支,基于自注意力的Transformer架构[25 ] ,在自然语言处理和计算机视觉领域被广泛应用[26 ] . Pei等[27 ] 提出将Transformer应用到故障诊断任务的迁移学习中;王誉翔等[28 ] 提出基于改进Transformer的复合故障诊断方法,利用单一故障标签和特征层间的交叉注意力实现复合故障的解耦. ...
Recurrent neural networks for multivariate time series with missing values
3
2018
... 式中:$ {\boldsymbol{D}} = [{{\boldsymbol{d}}_1},{{\boldsymbol{d}}_2}, \cdots ,{{\boldsymbol{d}}_n}] $ ${\boldsymbol{H}}$ N $\tilde {\boldsymbol{y}}$ [11 ] . Che等[29 ] 提出GRU-D模型,利用缺失的位置掩码和缺失间隔预测缺失模式,构建了端到端的缺失值填充模型,并将填充结果运用到故障诊断中. 由于GRU-D要求提供失效传感器的位置信息,导致数据分析和处理的工作量大大增加. 传感器失效造成的数据失真可类比目标检测中的遮挡问题,Song等[30 ] 提出对遮挡位置进行学习,并将得到的指示遮挡位置的特征丢弃掩码(feature discarding mask, FDM)保存在字典中,以便在后续检测任务中检索并摒弃遮挡区域. 但这种方法是静态的,不能处理字典中不存在的失效模式. 本研究将利用自注意力机制,在进行深层特征融合转换时直接对深层次特征进行随机摒弃处理. 自注意力层避开失效数据位置信息,直接利用全局信息预测退化特征. ...
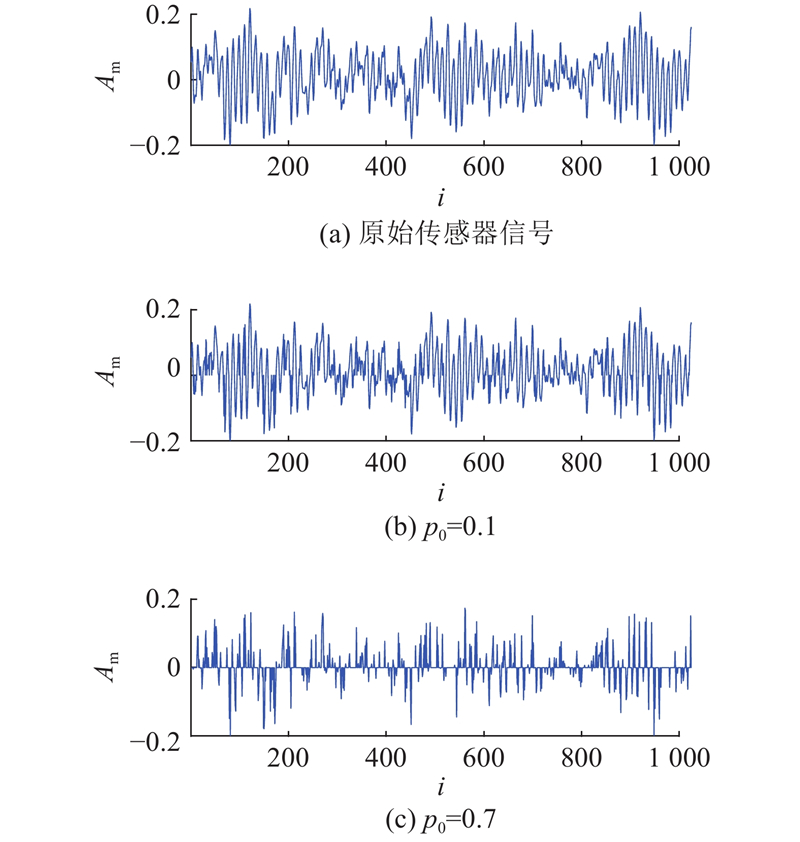
... 为了验证FDCFP在含有失效传感器数据时的诊断效果,将所有数据集重构,使重构后的数据集包含一定比例的缺失数据. 对于一维信号而言,传感器失效发生与否没有参考特征,为完全随机缺失(missing completely at random, MCAR)[36 ] . 参照 Che 等[29 ] 的方法,依概率${p_0}$ ${p_0}$ ${p_0}$ N 的向量$ {\boldsymbol{u}} $ $ {\boldsymbol{u}} $
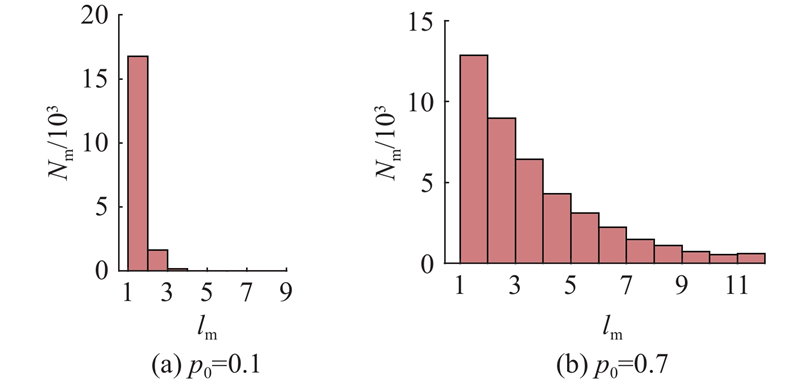
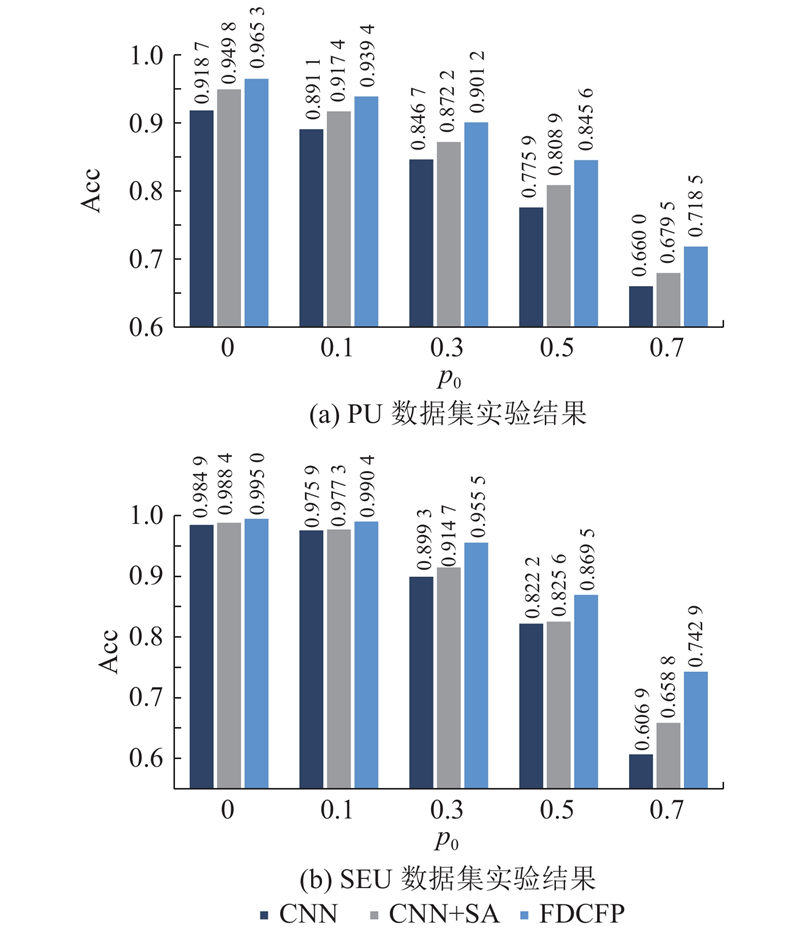
... 数据缺失可能随机发生在信号的任意时刻. 在实际生产中,一维时序信号的失效模式包括在某一时刻的单点失效(如网络丢包)和持续一段时间的连续失效(如传输中断,接触不良),且2种缺失模式往往共同存在. 如图5 所示,实验中采用的数据集缺失处理方法在模拟单点失效的同时,能够生成一定长度的连续失效. 图中,${l_{\text{m}}}$ ${N_{\text{m}}}$ [29 ,37 ] ,更高比例的缺失意味着更多的信息损失和更为复杂的缺失模式,对故障诊断模型的鲁棒性有着更高的要求. 因此,设置失效比例分别为0.1、0.3、0.5、0.7,验证模型在不同程度信息损失和不同缺失模式下的鲁棒性. 本实验设置固定的随机数种子确保实验的可重复性. 挑选验证集中准确率最高的3个模型,在测试集上进行测试,再基于不同的随机数种子模拟不同的失效数据分布,进行多次实验并统计结果,以克服随机因素对诊断结果的影响. ...
1
... 式中:$ {\boldsymbol{D}} = [{{\boldsymbol{d}}_1},{{\boldsymbol{d}}_2}, \cdots ,{{\boldsymbol{d}}_n}] $ ${\boldsymbol{H}}$ N $\tilde {\boldsymbol{y}}$ [11 ] . Che等[29 ] 提出GRU-D模型,利用缺失的位置掩码和缺失间隔预测缺失模式,构建了端到端的缺失值填充模型,并将填充结果运用到故障诊断中. 由于GRU-D要求提供失效传感器的位置信息,导致数据分析和处理的工作量大大增加. 传感器失效造成的数据失真可类比目标检测中的遮挡问题,Song等[30 ] 提出对遮挡位置进行学习,并将得到的指示遮挡位置的特征丢弃掩码(feature discarding mask, FDM)保存在字典中,以便在后续检测任务中检索并摒弃遮挡区域. 但这种方法是静态的,不能处理字典中不存在的失效模式. 本研究将利用自注意力机制,在进行深层特征融合转换时直接对深层次特征进行随机摒弃处理. 自注意力层避开失效数据位置信息,直接利用全局信息预测退化特征. ...
1
... Transformer的编码器部分用于全局特征融合,主要结构包括多头自注意力层和前馈网络(feed-forward network, FFN)[25 ] ,它们都通过残差连接[31 ] . 在计算多头自注意力之前,FDCFP对CNN提取的低层特征进行层归一化,以稳定前向输入的分布. FFN由2层全连接层构成,是编码器拟合能力的核心. FFN层采用随机失活(dropout)避免过拟合,随机失活率设置为0.1. 多头自注意力用于捕获输出特征之间不同的关联, ...
Rolling element bearing diagnostics using the Case Western Reserve University data: a benchmark study
1
2015
... 1)凯斯西储大学轴承数据集CWRU [32 ] 提供了4种电机转速下不同滚动轴承故障信号. 本实验基于12 kHz驱动端的故障数据,根据故障位置、负载大小、故障尺寸,划分9种故障类别,加上正常样本,构成十分类任务,每个样本长度N= 256. ...
1
... 2)帕德博恩大学轴承数据集PU [33 ] 基于6203型号滚动轴承,包括人为损伤和加速寿命实验获取的真实损伤. 本实验将数据划分为18个类别,包括3类不同工况下的健康数据、6类人为故障数据和9类真实故障数据,每个样本长度N =1024. ...
Highly accurate machine gault diagnosis using deep transfer learning
1
2019
... 3)东南大学齿轮箱数据集SEU [34 ] 包括2种不同转速负载下的轴承数据和齿轮数据,分为4种不同类型的故障数据和1类正常数据,共20个类别,每个样本长度N =1024. ...
A hybrid prognostics approach for estimating remaining useful life of rolling element bearings
1
2020
... 4)西安交通大学轴承数据集XJTU-SY[35 ] 记录了加速寿命实验中3类工况下5种不同轴承的振动信号. 本实验截取轴承彻底损坏前一定时间内的数据用于故障诊断,共15个类别,每个样本长度N =1024. ...
Missing value imputation: a review and analysis of the literature (2006–2017)
1
2020
... 为了验证FDCFP在含有失效传感器数据时的诊断效果,将所有数据集重构,使重构后的数据集包含一定比例的缺失数据. 对于一维信号而言,传感器失效发生与否没有参考特征,为完全随机缺失(missing completely at random, MCAR)[36 ] . 参照 Che 等[29 ] 的方法,依概率${p_0}$ ${p_0}$ ${p_0}$ N 的向量$ {\boldsymbol{u}} $ $ {\boldsymbol{u}} $
基于生成对抗网络的飞机燃油数据缺失值填充方法
1
2021
... 数据缺失可能随机发生在信号的任意时刻. 在实际生产中,一维时序信号的失效模式包括在某一时刻的单点失效(如网络丢包)和持续一段时间的连续失效(如传输中断,接触不良),且2种缺失模式往往共同存在. 如图5 所示,实验中采用的数据集缺失处理方法在模拟单点失效的同时,能够生成一定长度的连续失效. 图中,${l_{\text{m}}}$ ${N_{\text{m}}}$ [29 ,37 ] ,更高比例的缺失意味着更多的信息损失和更为复杂的缺失模式,对故障诊断模型的鲁棒性有着更高的要求. 因此,设置失效比例分别为0.1、0.3、0.5、0.7,验证模型在不同程度信息损失和不同缺失模式下的鲁棒性. 本实验设置固定的随机数种子确保实验的可重复性. 挑选验证集中准确率最高的3个模型,在测试集上进行测试,再基于不同的随机数种子模拟不同的失效数据分布,进行多次实验并统计结果,以克服随机因素对诊断结果的影响. ...
基于生成对抗网络的飞机燃油数据缺失值填充方法
1
2021
... 数据缺失可能随机发生在信号的任意时刻. 在实际生产中,一维时序信号的失效模式包括在某一时刻的单点失效(如网络丢包)和持续一段时间的连续失效(如传输中断,接触不良),且2种缺失模式往往共同存在. 如图5 所示,实验中采用的数据集缺失处理方法在模拟单点失效的同时,能够生成一定长度的连续失效. 图中,${l_{\text{m}}}$ ${N_{\text{m}}}$ [29 ,37 ] ,更高比例的缺失意味着更多的信息损失和更为复杂的缺失模式,对故障诊断模型的鲁棒性有着更高的要求. 因此,设置失效比例分别为0.1、0.3、0.5、0.7,验证模型在不同程度信息损失和不同缺失模式下的鲁棒性. 本实验设置固定的随机数种子确保实验的可重复性. 挑选验证集中准确率最高的3个模型,在测试集上进行测试,再基于不同的随机数种子模拟不同的失效数据分布,进行多次实验并统计结果,以克服随机因素对诊断结果的影响. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}