

随着我国法治建设的进步和发展,司法实务对类案检索任务愈发重视. 由于案件要素增多,找到目标相似类案变得较为困难. 类案检索任务通常被转化为文本相似度的计算任务,研究者利用自然语言处理与深度学习算法从各种角度提出准确率较高的模型,但忽略了模型应当蕴含的法律逻辑,同时这些模型也无法适应实际应用中案件相似标准的变化.
Bhattacharya等[1]提出2种计算法律文本相似度的方法,一种是分析判例引用网络,另一种对文本内容相似度进行计算. 计算法律文本内容相似度的研究难点在于须从内容较多、结构复杂、包含专业术语的法律文本中找到会影响法律效果的相似内容. 为了能够高效准确地衡量文本内容的相似性,研究者提出提取关键句、改变语义研究层和融合段落交互等多种方法. Wagh等[2]使用图方法提炼概念元素为代表性句子,这些概念使用平均排序权重集合操作获取相似值. Tran等[3]将给定文档的摘要编码映射到连续向量空间,在给定候选案件中提取不同部分的词汇特征. Jiang等[4]提出基于注意力分层的循环多深度神经网络匹配长文本. Shao等[5]提出使用基于Transformer的双向编码器表示技术来捕捉段落层次的语义关系,通过融合段落交互来推测2个案件之间的相似度. 除了利用法律文本的案情和判决,Ali等[6]提出弱监督技巧自动化识别包含证据的句子,将与证据相关的信息模型应用于类案检索. Ma等[7]认为已有数据集的相关性判断标准不适用于无引用关系的案件,为此构建法律类案匹配数据集LeCaRD. 此外,法律信息提炼/补充比赛(competition on legal information extraction entailment, COLIEE)可以评估信息匹配和补充效果[8]. 遗憾的是,法律信息提炼/补充比赛的数据集为非中文数据集,无法应用于中文语境下的法律类案分析.
在类案检索研究中,如果将法律裁判文书视为单纯的结构性文本,忽略法律领域的规则和逻辑,法律的专业性和特点将无法得到有效利用. 因此,如何提高检索的逻辑性和实现类案检索的精准化,成为亟须解决的问题. 本研究提出以法律逻辑为基础、有较强可解释性的类案检索模型,基于法律裁判文书的事实部分,结合事理和知识提取基本事实和要件事实(行为人的行为方式表述和给予定罪的决定性事件)构建案情事理图谱;以基本事实、要件事实以及罪名作为案件特征,将检索案件和候选案件的相应表示输入基于机器学习的评分器;在得到每个候选案件的相似分数后,获得候选案例的相似度排序;分别在法律数据集LeCaRD和专门针对类案检索构建的Confusing-LeCaRD数据集上进行所提模型的特性对比.
1. 相关工作
1.1. 文本表示学习
文本表示是指将文本转换为计算机可以理解和处理的数值形式. 表示学习是找到原始数据基于目标任务的更好表达[9]. 研究者利用表示学习方法较好地体现了文本的语言结构和语义信息. Wei等[10]引入能够为不同主体种类学习最具代表性特征的适应性特征表示策略. Lee等[11]将表示学习作为序列排序任务,通过卷积神经网络来分类打乱的序列. Suk等[12]提出基于深度学习、包含堆叠自动编码器的特征表示方法. 李松等[13]提出基于加权卷积神经网络和加权层次编码器的表示方法,该表示方法融入了层次信息. 针对法律任务,Zhong等[14]提出法律文本元素启发的多元表示模型,使用被标注过的法律文本元素提炼事实描述特征.
1.2. 事理知识图谱
1.3. 类案检索
2. 面向法条知识的事理型类案检索
2.1. 问题定义
基本事实是指案件发生的完整情节,包括起因、经过、结果. 要件事实是指能够影响案件定罪量刑问题的关键情节. 罪名是将案件进行归类的标准,在一定程度上代表案件适用的法律. 在司法实务中,一般采用关键词检索、法条关联案件检索、案例关联检索等方法来实现类案检索任务. 本研究采用案例关联检索,即根据案例本身的特征进行类案匹配,在分析数据的可利用部分并考虑模型的可拓展性之后,选取基本事实、要件事实和罪名为特征.
针对序列为
2.2. 类案检索模型的整体架构
本研究所提模型主要包括基本事实提取器、要件事实提取器和评分器. 如图1所示,设检索案件为
图 1

2.3. 特征提取
以RoBERTa为转化模型将文本转化为向量. RoBERTa能够谨慎地衡量训练数据规模和关键参数的影响[23],使得到的向量深度融合前后文信息. 分析法律文本中蕴含的语义特征、关系特征和结构特征等是解决类案检索任务的重要构成,本研究结合非线性处理层和线性处理层进行特征提取,利用LSTM层和全连接层逐步学习向量中有用的信息,为案件评分作铺垫.
2.4. 法条知识库构建
《中华人民共和国刑法》(以下简称《刑法》)分则包含对各项罪名的具体规定,这些规定通常由罪状和法定刑构成. 在《刑法》中分别找到现有的各项刑事罪名对应的条文. 融入法条的目的在于提取要件事实,为此须从原始法条中删去关于刑罚的部分,仅保留罪状描述部分. 随后将定义转变为要件式结构,作为该项罪对应的法条知识. 在采用结构提取后对要件进行人工调整:先根据标点符号将内容分组,再从各组中提取出动宾短语、介宾短语和并列短语,这3种结构的选择是基于人工提取一部分条文之后的归纳总结. 之后,具有专业法律知识的人对初步获取的结构作删留决定和语序调整. 例如,“侵占罪”的相关法条为《刑法》第二百七十条,经处理转变为要件式定义:{将代为保管的他人财物非法占为己有,数额较大,拒不退还}. 对所有罪名的相关条文进行处理,最终形成完整的法条知识库,共计469条. 法条知识库中的部分条文如表1所示.
表 1 法条知识库的部分条文
Tab.1
| 罪名 | 要件式定义 |
| 虐待部属 | 滥用职权,虐待部署,致人重伤,造成其他严重后果 |
| 妨碍安全驾驶 | 对行驶中的交通工具的驾驶人员使用暴力,抢控驾驶操纵装置,干扰公共交通工具正常行驶,危及公共安全 |
| 重大责任事故 | 违反有关安全管理的规定,发生重大伤亡事故,造成其他严重后果 |
2.5. 案件事理图谱构建
如图2所示,案件事理图谱是以法律事件为节点、事件之间的关系为边构建的有向图. 这种形式的图能够表现发生的事件以及事件之间的发展趋势和变化关系. 在构建事理图谱前,须对法律事实的描述文本进行分词处理和句法分析. 使用句法分析是为了获得句子中的谓语动词,并使得到的谓语动词代表事件(形成事件图谱节点),因此在进行句法结构分析后提取主谓关系中的动词.现有法律文本倾向于按客观事件的发生规律进行记录,含有较少的因果关系词、转折关系词等,因此仅由事件发生的先后来提取顺承关系. 例如,“甲和乙发生争执,甲砸伤乙,乙反击”提取为{发生争执,砸伤,反击}3个事件. 由于“发生争执”先于“砸伤”出现,从这个案件中提取出这2个事件的边方向为由 “发生争执”指向“砸伤”,“砸伤”和“反击”之间的关系同理可得. 基于此方法,事理图谱可视为事理链,代表基本事实,蕴含案件的发生逻辑和犯罪人的行为特征.
图 2
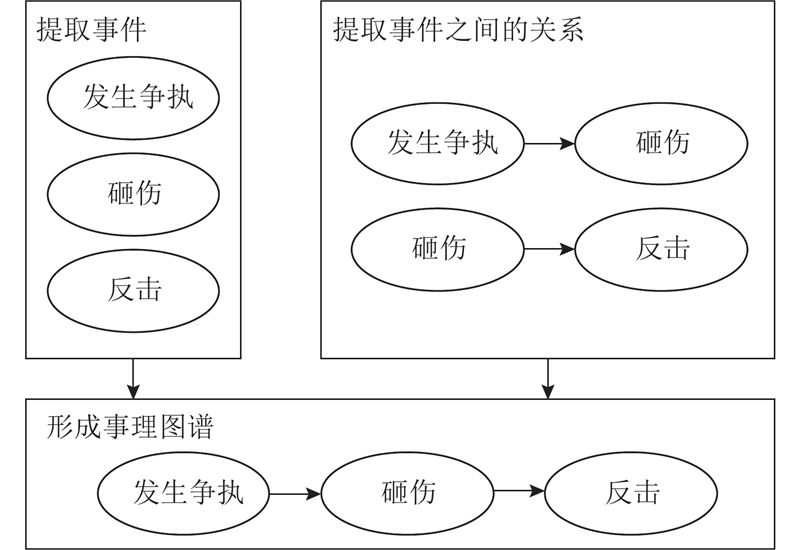
图 2 案件事理图谱的构建过程图
Fig.2 Construction process diagram of event logic graph of case
2.6. 基于法条知识的类案检索
在提取出检索案件和候选案件的基本事实和要件事实后,将2个部分的事实和罪名进行向量表示. 如图3所示,利用RoBERTa模型转化向量,基本事实、要件事实和罪名3个特征分别作为模型的输入. 其中
图 3

将LSTM用于基于法条知识的事理型类案检索. 为了得到每个案件的最终评分,将罪名分数、案件事实分数和要件事实分数综合相加. 在司法实践中,影响定罪量刑的要件事实是法律工作者进行类案检索时关注的重点,在设置权重时应当为要件事实赋予相较罪名和案件事实更大的值. 按这种大小标准设置初始值后,开展多次实验并根据结果进行逐步调整,确定使用的分数比为0.15∶0.35∶0.5. 设罪名相似度为
3. 实验与结果分析
使用中文法律数据集LeCaRD和自建数据集Confusing-LeCaRD评测本研究所提模型.
3.1. 数据集与实验环境
LeCaRD是中文法律数据集,来源于“中国裁判文书网”公开的刑事法律文书,每条数据均由案件名、案件基本情况、裁判分析过程、判决结果等要素组成. 数据集涉及的案由类型较为全面,包含107个检索案例和超过43 000个候选案例,每个检索案例的候选数据集大小为100. 法律专家将案件相似度分为4个等级,具体的标注规则如表2所示.
表 2 LeCaRD数据集的标注规则
Tab.2
| 要件事实 | 案情事实 | 相似度 |
| 相似 | 相似 | 3 |
| 相似 | 不相似 | 2 |
| 不相似 | 相似 | 1 |
| 不相似 | 不相似 | 0 |
Confusing-LeCaRD是本研究构建的,以易混淆罪名组危险驾驶罪和交通肇事罪为主要案由的数据集. 危险驾驶罪和交通肇事罪的案情描述使用相同的语言体系,特定事件高频地发生在这2个案由下的具体案件中(如“驾驶”“碰撞”“发生交通事故”等),这样的特性将使得数据集对模型的要求较高,若模型能够在Confusing-LeCaRD上获得较好的结果,表明该模型具有良好的适用性. Confusing-LeCaRD的构建过程如下. 1)搜集初始数据:数据集的初始数据主要源于中国裁判文书网. 从该网站获取各种案由下的刑事案件,每个案件形成一条数据,内容包括判决书原文、判决结果和原被告、法院、案号、审理程序等. 对每条数据进行处理,将数据属性调整为案情、罪名和编号. 其中案情从判决书原文中提取,主要是判决书中的事实部分;案由是从判决结果中识别出的专业罪名. 2)使用K均值聚类算法:检索案例和候选案例须有强度不同的关联性,以确保获得不同的相似度等级. 由于搜集到的初始数据范围较广、数量较多,从中直接确定检索案例和候选案例的难度大,为此采用K均值聚类算法对初始数据进行聚类. 通过该算法固定的中心点即为检索案例,与该案例同类别的其他案例均可作为候选案例. 将检索案例的候选数据集大小设置为100,将聚类得到的候选案例集打乱后取前100个. 3)标注相似度等级:采用与LeCaRD相似度等级规则相似的规则进行相似度标注(分别进行基本事实的相似度判断和要件事实相似度的判断);采用构建模型时使用的处理方法进行要件事实识别(融合法条知识、结合定义中的要件进行提取). 危险驾驶罪和交通肇事罪的具体要件如表3所示. 需要注意的是,要件中只要存在一个相似的元素,要件事实即视为相似. 针对交通肇事罪中“违反交通运输管理法规”要件,要求违反的具体法规相同才将该要件判断为相似. 最终Confusing-LeCaRD包含17个训练集检索案例和6个测试集检索案例,每个检索案例对应100个候选案例. 检索案例仅包含危险驾驶罪和交通肇事罪,候选案例包含丰富的多种罪名. Confusing-LeCaRD中检索案件和候选案件的数据结构分别如表4和表5所示.
表 3 危险驾驶罪和交通肇事罪的要件
Tab.3
| 罪名 | 要件 |
| 危险驾驶 | 在道路上驾驶机动车追逐竞驶,醉酒驾驶机动车,从事校车业务或者旅客运输严重超过定额乘员载客,从事校车业务或者旅客运输严重超过规定时速行驶,违反化学品安全管理规定运输危险化学品 |
| 交通肇事 | 违反交通运输管理法规,致人重伤,致人死亡,造成重大公私财产损失 |
表 4 Confusing-LeCaRD数据集检索案件的数据结构
Tab.4
| 编号 | 罪名 | 案情 |
| 1 | 诈骗 | 2009年3月20日,被告甲为实施诈骗活动,通过中介注册成立了一家公司,并通过网络招聘了五名员工······ |
| 9 | 抢劫 | 2021年5月2日,被告甲见乙作为老年人独自一人行走在路上,便冲过去夺走乙手中的布包······ |
表 5 Confusing-LeCaRD数据集候选案件的数据结构
Tab.5
| 编号 | 罪名 | 案情 | 相似度等级 |
| 1307 | 抢劫 | 2018年8月27日,甲骑着电动车在路上行驶, 被告乙驾驶摩托车从旁快速经过,乙车后座 上的被告丙夺走甲的手提包······ | 3 |
| 2167 | 盗窃 | 2019年9月25日,被告甲见乙房屋门未关,便 偷偷潜入乙家中窃取一部手机和两百元现金······ | 0 |
在PyTorch 1.12.1和NVIDIA GeForce RTX 3090 GPU的Ubuntu服务器上开展类案检索实验.
3.2. 模型对比与参数设置
进行模型性能的对比分析,参与对比的包括TF-IDF、BM25和BERT-PLI模型. 根据模型具体特点,设置2组消融实验. 1)TF-IDF是文本表示领域的经典加权技术,该方法根据词频和逆文本频率来计算文本相似度. 2)BM25是基于概率检索模型的文本相似度算法,该方法检索文本中所有词和文档相关度. BM25改进了TF-IDF,在相关性计算的任务中表现优异. 3)BERT-PLI由 Shao等[5]提出,使用BERT捕捉段落层次的语义关系,是通过融合段落交互来推测2个案件相似度的模型,在COLIEE 2019的类案检索赛道取得较好成绩. 4)无知识消融实验:在本研究所提模型的基础上消除法条知识模块(去除要件事实分数的影响). 5)无事理消融实验:在本研究所提模型的基础上消除事理图谱模块(去除基本事实分数的影响).
模型训练参数如表6所示,其中Batch_size为一次训练时所使用的数据样本数量,Batch_size=1表示每次训练的数据包括1个检索案例和它的100个候选案例. Key_fact_threshold为提取要件事实时使用的相似度阈值. Max_len为所使用文本的最大长度. 训练时使用的优化器为Optimizer,优化算法为Adam.
表 6 模型训练参数
Tab.6
| 参数 | 数值 | 参数 | 数值 | |
| Learning_rate | 2×10−4 | Max_len | 192 | |
| Batch_size | 1 | Hidden_size | 128 | |
| Weight_decay | 0.005 | Key_fact_threshold | 0.15 |
3.3. 实验结果与分析
为了实现更好的训练效果,将相似度映射到[0, 1.0],相似度的等级越高越接近1.0. 训练误差使用二元交叉熵损失函数,设N为样本总数,第
归一化折损累计增益是评估排序的常用指标. 当获得的排序质量越好,归一化折损累计增益就会越高,数值范围为[0,1.0]. 设检索结果序列中第
2)将序列元素按相关度大小进行排列,如此形成的序列称为理想序列,理想序列折损累计增益(ideal discounted cumulative gain,IDCG)的计算式为
3)归一化折损累计增益(normalized discounted cumulative gain,NDCG),计算式为
LeCaRD源于CAIL 2022中的类案检索任务,比赛的举办方并未公布完整的数据集,因此使用该竞赛提供的评测系统进行评测,其设置的指标为NDCG@30.TF-IDF、BM25、BERT-PLI和所提模型的评测结果依次为69.90,85.73,75.10和90.95,所提模型得到的测试分数高于对比模型,排序效果较好. 分别将所提模型中法条知识模块或事理图谱模块消去,得到的评测结果分别为86.03、90.45,排序质量分别下降了4.92和0.50. 可以看出,消除法条知识模块的影响更大,说明该数据集对于事理逻辑的要求没有对法条知识的要求高.
Confusing-LeCaRD的数据结构完整,能够使用多种指标来进行评估. 在该数据集上的评测指标包括NDCG@5、NDCG@10、NDCG@20和NDCG@30,使用TF-IDF、BM25、BERT-PLI和所提模型得到的评测结果如表7所示,所提模型的消融实验结果如表8所示. 本研究所提模型在各项指标上均优于对比模型. 当所提模型分别消除2个模块之后,排序质量有所下降,在NDCG@10、NDCG@20和NDCG@30的指标下消除事理图谱模块的影响更大,说明事理逻辑在模型完成该数据集上的任务时发挥了更重要的作用. BERT-PLI相较TF-IDF和BM25有更好的效果,说明Confusing-LeCaRD要求实现更深层次的文本特征提取和语义理解.
表 7 不同模型基于Confusing-LeCaRD数据集的评测结果
Tab.7
| 模型 | NDCG@5 | NDCG@10 | NDCG@20 | NDCG@30 |
| TF-IDF | 67.23 | 73.46 | 78.36 | 83.40 |
| BM25 | 72.08 | 73.84 | 81.97 | 87.41 |
| BERT-PLI | 83.19 | 85.66 | 91.01 | 91.17 |
| 本研究 | 92.04 | 94.64 | 92.60 | 91.51 |
表 8 基于Confusing-LeCaRD数据集的消融实验结果
Tab.8
| 消除的 模块 | NDCG@5 | NDCG@10 | NDCG@20 | NDCG@30 |
| 法条知识 | 88.00 (↓3.64) | 90.34 (↓4.30) | 88.22 (↓4.38) | 89.82 (↓1.69) |
| 事理图谱 | 88.53 (↓3.51) | 89.08 (↓5.56) | 87.97 (↓4.63) | 88.26 (↓3.25) |
3.4. 案例分析
以Confusing-LeCaRD中编号为“+17011”案件为例进行演示说明. 该案件内容如下:“公诉机关指控,2013年11月24日8时40分许,被告人何某某驾驶某重型仓栏式货车到货站处,倒车过程中与行人刘某相撞,致其受伤,经医院抢救无效于2013年11月26日死亡,经认定,被告人何某某负该起事故的全部责任. 案发后,被告人何某某主动到公安机关投案. 经审理查明,2013年11月24日8时40分许,被告人何某某驾驶自己所有的重型仓栏式货车在货站处,车头朝南往货站门前倒车,未注意瞭望,与行人刘某相撞,造成被害人刘某受伤,被害人刘某因肺挫伤导致失血性休克经医院抢救无效于2013年11月26日死亡,市交警大队认定,被告人何某某负该起事故的全部责任. 2013年11月26日,被告人何某某主动到公安机关投案. 2013年11月27日,被害人刘某家属与被告人何某某家属达成赔偿协议,被告人何某某赔偿被害人家属经济损失人民币58万元. 被害人家属不再追究被告人何某某的法律责任,并对被告人何某某表示谅解.”该检索案例的判决罪名是交通肇事罪,与之相关的法律文本为“违反交通运输管理法规,因而发生重大事故,致人重伤、死亡或者使公私财产遭受重大损失的,交通运输肇事后逃逸或者有其他特别恶劣情节的,因逃逸致人死亡的. ”对法条文本进行要件化处理后处理得到{违反法规,发生事故,致人重伤,致人死亡,遭受损失,逃逸,因逃逸致人死亡},据此提取出检索案件的要件事实为{死亡,造成肺挫伤,受伤,相撞,休克}. 案情文本经固定结构提取、事件及关系提取之后形成事理图谱,即提取出的基本事实如下:驾驶→倒车→相撞→受伤→抢救无效→死亡→驾驶→未注意瞭望→造成受伤→导致休克→经抢救无效→死亡→达成赔偿.
选取候选集中编号为“+17189”和“+717”的案例进行相同处理. 如表9所示为Confusing-LeCaRD数据集中编号为“+17011”、“+17189”和“+717”的3个案件对应的罪名、要件事实和基本事实. 将检索案例和2个候选案例的罪名、基本事实与要件事实转化为向量表示后分别进行拼接,放入评分器. 最终得到的2个案例的相似度等级分别为3、0. 模型判断“+17189”与检索案例在基本事实和要件事实上都相似,“+717”与检索案例在基本事实和要件事实上都不相似. 本研究所提模型得出的判断符合实际情况,检索案例和“+17189”的基本事实都存在“驾驶”、“受伤”、“死亡”、“达成赔偿”等,在案情发展和事件发生上有较高的相似性,要件事实都包括“死亡”和“受伤”,符合相似标准,检索案例和“+17189”在定罪量刑时要件依据一致.“+717”基本事实和要件事实与检索案例存在着较大差别,重合之处较少,不属于实际应用中须参考的类案.
表 9 检索案例和候选案例的特征信息
Tab.9
| 案件编号 | 罪名 | 要件事实 | 基本事实 |
| +17011 | 交通肇事 | {死亡,造成肺挫伤,受伤,相撞,休克} | 驾驶→倒车→相撞→受伤→抢救无效→死亡→驾驶→未注意瞭望→ 造成受伤→导致休克→经抢救无效→死亡→达成赔偿 |
| +17189 | 交通肇事 | {损伤,受伤,死亡,肇事,有死亡,损伤, 安全法违反} | 驾驶→行驶→适逢→驾驶→行驶→相撞→受伤→拨打→送往救治→ 肇事→治疗→死亡→损伤→死亡→达成赔偿→接受赔偿 |
| +717 | 盗窃 | {财物盗窃,占有,盗得,实施盗窃,入户} | 乘坐→驾驶→到达→盗窃→进入→盗得→进入→盗得→占有→入户 盗窃→追缴违法所得 |
4. 结 语
本研究提出基于法律知识的事理型类案检索模型,实现法律逻辑. 从实验对比可以看出,不管是涉及所有案由的数据集,还是以易混淆案由组为基础的数据集,所提模型在类案检索任务上较TF-IDF、BM25和BERT-PLI有更好结果. 所提模型能够提取每个检索案件和候选案件的基本事实和案情事实,在呈现结果时有较TF-IDF、BM25和BERT-PLI更强的可解释性和逻辑性. 由性能对比实验结果观察得到所提模型的评测分数高于对比模型的评测分数,较对比模型更加具有优势,证明了法条知识和事理图谱在提高类案检索任务性能上的必要性. 本研究构建的数据集能够作为类案检索任务的评测基础,可用性和专业度较高.
本文的主要贡献如下:1)构建案情事理图谱. 针对案情提取事件及事件间的关系,形成案情事理图谱. 该图谱能够更好地结合犯罪模式和人类行为逻辑,在提高检索准确性的同时丰富检索结果的可解释性. 2)设计法条知识的模型嵌入. 要件化处理法条中各项罪名的定义作为提取案例要件事实的标准融入模型,从法律专业的角度判定各项罪名是否成立和细化区分确认罪名的关键要件. 3)构建数据集与评估实验. 以易混淆罪名组“危险驾驶罪”和“交通肇事罪”为主,构建针对类案检索任务的训练集和测试集. 详细展示模型在数据集上的性能和效果,证明了所提模型在各项指标上均优于对比模型. 以Confusing-LeCaRD数据集的示例案件进行演示和说明,所提模型在呈现结果时表现了更强的可解释性和逻辑性.
未来工作一方面考虑细化要件事实的提取标准(要件式定义),以实现要件可选式的类案检索,进一步提高模型的可解释性;另一方面考虑丰富易混淆罪名组,提高数据集的质量和评测价值. 在实际应用该模型时,还应当从法条知识库的角度进行优化. 本研究选取《中华人民共和国刑法》作为法律依据,实践中的类案检索还应当考虑司法解释、指导性案例以及其他法律文件影响. 所提模型在完整地确定每项罪名的要件之后,可以实现基于所有要件的类案检索. 如果能够将判断检索案件和候选案件是否相似的决定性要件进行具体明确,所提模型还可以满足根据实际需求来选择特定的要件进行检索.
参考文献
Legal document similarity: a multi-criteria decision-making perspective
[J].DOI:10.7717/peerj-cs.262 [本文引用: 1]
自然语言处理中的文本表示研究
[J].
Research on text representation in natural language processing
[J].
PEPred-Suite: improved and robust prediction of therapeutic peptides using adaptive feature representation learning
[J].DOI:10.1093/bioinformatics/btz246 [本文引用: 1]
融合文本描述和层次类型的知识表示学习方法
[J].
Knowledge representation learning method integrating textual description and hierarchical type
[J].
Understanding relevance judgments in legal case retrieval
[J].
BERT_LF: a similar case retrieval method based on legal facts
[J].
A BERT-based two-stage model for Chinese chengyu recommendation
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}