

(1) 为了防止营商环境评估时企业原始数据被篡改,引入改进的哈希函数SHA256算法对企业原始数据进行加密. 通过在数据块哈希运算中增加运算次数,增大SHA256算法逻辑和压缩函数复杂度,进一步提高运算的抗碰撞性及Hash 结果的雪崩效应,从而提高数据安全性.
(2) 为了降低区块链系统的通信和存储压力,提出链上和链下相结合的存储模式. 引入改进的基于非易失性内存(non-volatile memory, NVM)的Key-Value型数据库Level DB,实现在链下存储企业原始数据. Key值为经过改进后的SHA256算法加密的Hash值,Value值为企业原始数据.
(3) 针对传统区块链存在交易确认速度慢、吞吐量小的问题,提出企业级复合区块链的构建方法. 公有链采用基于有向无环图(directed acyclic graph, DAG)的Conflux存储链下Level DB中企业原始数据对应的Key值,联盟链存储企业状态数据,确保企业原始数据去中心化存储,不可篡改和可追溯.
1. 相关工作
目前,国内外许多专家学者对区块链链上链下的存储优化方法进行研究,取得了一定的研究成果.
在Level DB优化方面,Lu等[16]针对Level DB写放大提出WiscKey方法,该方法将键从值中分离出来,同时只在Compaction时合并键,利用该方法可以大大降低写放大,但它使得垃圾回收和范围查询复杂化. Lepers等[17]提出的Kvell模型采取每一项键值在磁盘上乱序的方式,可以减轻基于NVMe SSD键值存储的写停顿,但不适用于通用的SSD系统. Kaiyrakhmet等[18]提出SLM-DB存储结构,该结构采用单级的 LSM-tree,适用于具有NVM-SSD存储的系统,通过NVM上的B+树来索引SSD上面的单层LSM-tree,以实现快速读,但该方式引入了维护B+树和LSM-tree一致性的额外开销. Kannan等[19]提出的NoveLSM在NVM 上采用持久化可变内存表,可以在某种程度上减少访问时延,但造成了更严重的写入停顿.
在结构链优化方面,Lewenberg等[20]提出构建Inclusive区块链,Inclusive将Nakamoto共识和GHOST规则扩展到DAG,设计了框架,以包括链外交易. Leonov等[21]提出PHANTOM平台,参与节点为本地区块DAG找到近似的k-cluster解决方案,以修剪潜在的恶意区块. 对剩余区块进行拓扑排序,获得最终的区块总顺序. 当区块生成率很高时,Inclusive和PHANTOM都很容易受到有效性攻击. Eyal等[22]提出构建Bitcoin-NG区块链,Bitcoin-NG通过定期选举一个Leader,并允许该Leader在一段时间内指定交易全序的方式提高吞吐量,但没有减少交易的确认时间. Derek等[23]提出Vault区块链,Vault选择分片技术对区块链进行构建,以便降低存储成本,权衡网络带宽成本的增加. 虽然所有分片的综合吞吐量很大,但分片间交易的吞吐量有限.
综上所述,现有方法存在读写性能差、存储效率低、交易确认速度慢和吞吐量小等问题. 本文综合考虑Level DB优化和区块链存储效率问题,提出营商环境评估的企业级复合区块链构建方法.
2. 企业原始数据链下存储
企业级复合区块链总体架构由Level DB、公有链和联盟链组成,以实现链上链下数据协同. 链上通过链下实现计算和存储能力的扩展,链下与链上对接实现异构信息的共享. 如图1所示,在企业级复合区块链架构中,Level DB数据库存储企业原始数据信息,Value为原始数据,Key为通过改进的哈希函数SHA256算法加密后的Hash值. 负责交易的公有链存储Level DB数据库中企业原始数据对应的Key值,负责状态的联盟链存储企业的状态数据.
图 1
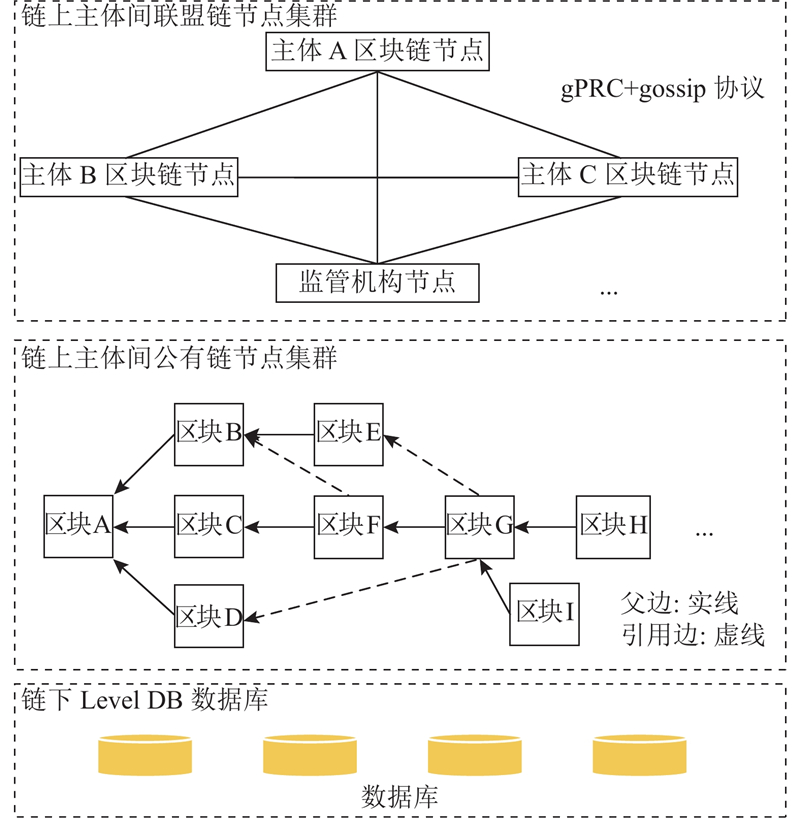
图 1 企业级复合区块链的架构图
Fig.1 Architecture diagram of enterprise composite blockchain
2.1. 企业原始数据的加密计算
为了进一步提高数据的安全性,在将原始数据存入链下Level DB前,采用改进的哈希函数SHA256算法对企业原始数据进行加密. SHA256算法采用6个逻辑函数和1组常数
1) 初始化.
2) 准备消息列表
逻辑函数的计算方式为
式中:
3) 根据
4) 当
逻辑函数的计算方式为
5) 计算每个分组的中间散列值:
式中:
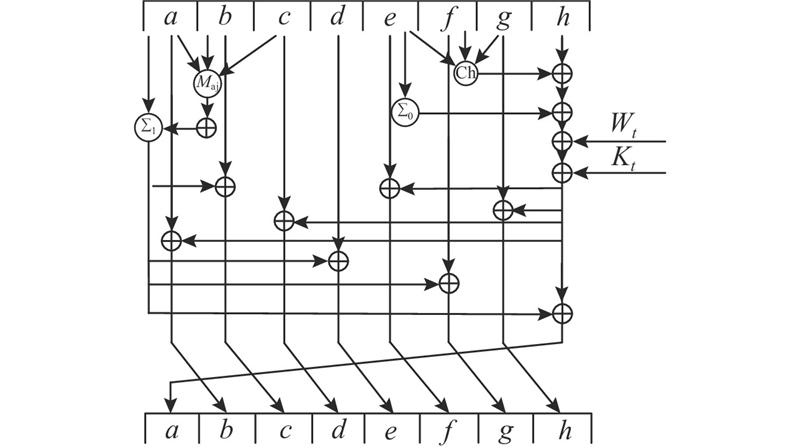
在对SHA256算法进行改进时,在每个512 bit的数据块哈希运算中增加16次运算,保证消息的每个bit可以影响到更多的bit位,进一步改善算法的非线性扩散性. 加大SHA256算法逻辑和压缩函数的复杂度,以加速消息的差分扩散程度,使得递推过程具有更强的随机性,消除局部碰撞的依从条件. 改进后SHA256算法过程如下.
1) 对消息块
a) 准备消息列表
b) 工作变量初始化:
式中:
2) 当
式中:
改进后的SHA256算法使用的6个逻辑函数基于32 bit的字(如
式中:
图 2
采用改进后的哈希函数SHA256算法,对企业原始数据加密生成相应的Hash值,作为链下Level DB数据库中的Key值,开展后续的存储操作.
2.2. 基于NVM的链下Level DB存储模型构建
将企业原始数据加密后的Hash值作为Key值,原始数据作为Value值,对应存入链下Level DB中. Level DB是基于LSM-tree(log-structured merge tree)架构的Key-Value非关系型数据库存储系统,它写入快,占用空间少,但LSM-tree架构有写停顿、写放大和不利于读的缺点. 在LSM-tree架构的基础上,提出基于NVM的LSM-tree存储模型. 利用该模型,可以提高访问速度、持久性、并发性和扩展性,同时具有更好的集成性. 链下Level DB存储模型架构如图3所示.
图 3
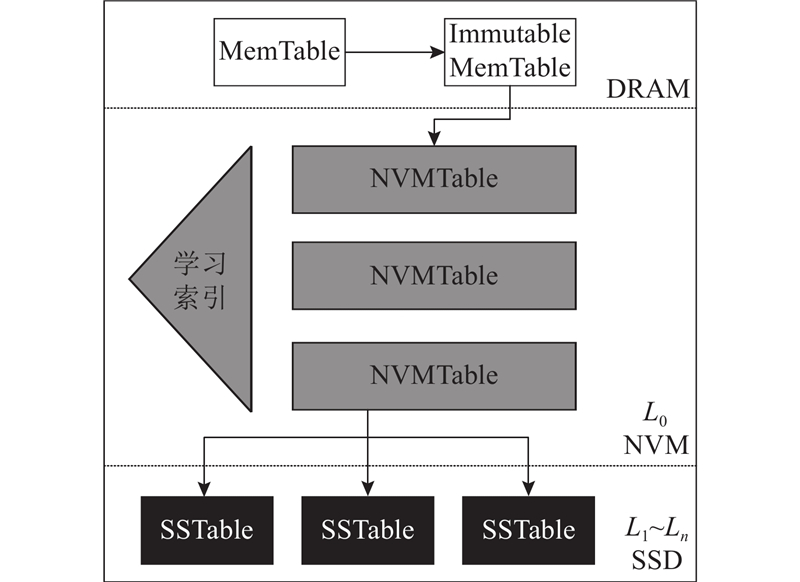
如图3所示,将原有LSM-tree架构中的
图 4
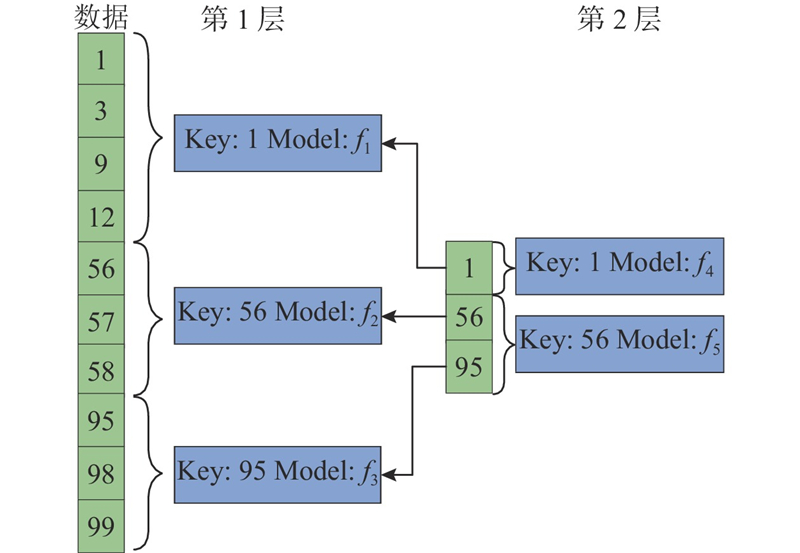
在PGM索引第1层,将数据分成3个分区,每个分区由简单的线性模型
3. 链上企业级复合区块链的构建
3.1. Conflux公有链构建
为了提高区块链的性能,从有向无环图(DAG)的特殊结构出发,采用基于主干链的DAG共识协议Conflux共识,构建企业级复合区块链中的Conflux公有链. Conflux公有链的架构如图5所示.
图 5
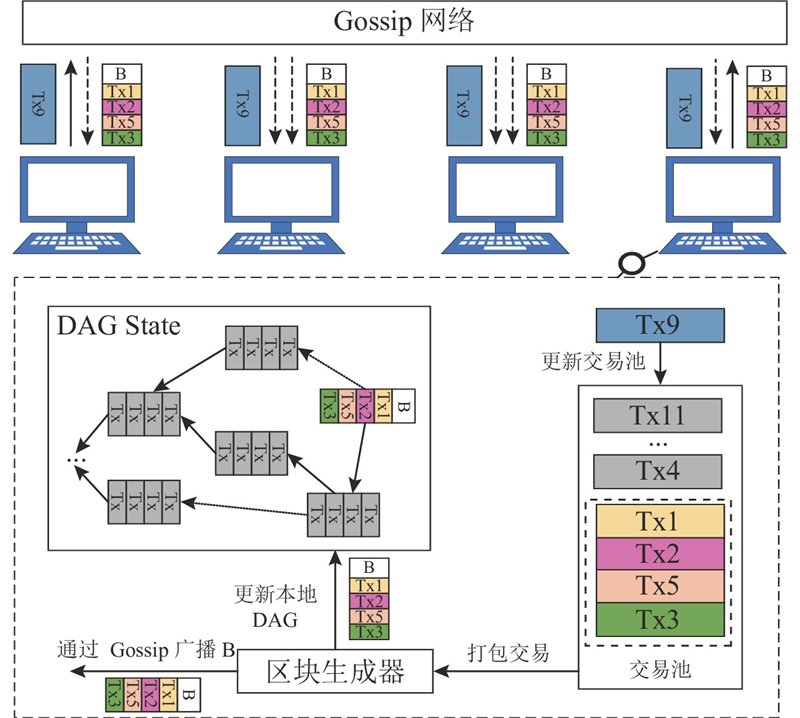
Conflux中的交易由2.2节链下Level DB中企业原始数据对应的Key值组成. Conflux从预定义的创世区块开始,确定区块链的初始状态,所有区块和边构成一个DAG结构. Conflux中的所有参与节点通过Gossip网络连接,每当一个节点发起一项交易或生成一个新区块,它将通过 Gossip网络将交易广播给所有其他节点. Conflux底层区块的数据结构如图6所示,采用树图的形式,通过并行处理方式加大出块速度,且不会因为链分叉问题降低安全性,使得每个企业都可以并行地上传交易,即企业原始数据对应的Hash值,使得整个系统可以更高效地处理区块和交易.
图 6
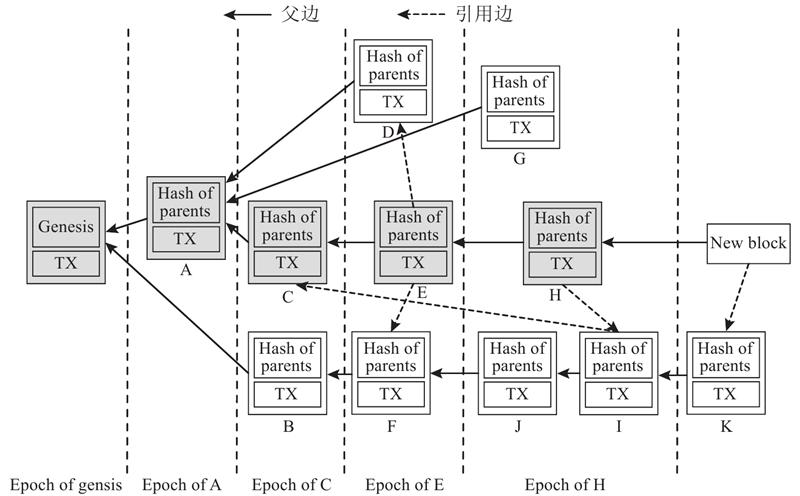
每当一个节点生成一个新的区块时,它首先计算其本地DAG状态下的主链,并将主链中的最后一个区块设置为新区块的父块. 在DAG中查找没有入度边的所有端区块,创建从新区块到每个端区块的引用边. 给定一个从创世区块开始、只包含父边的主链,排序算法利用主链将DAG中的所有区块划分为epoch,主链上的每个区块都对应一个epoch. 当进行共识确定区块总序时,Conflux对epoch进行排序,根据epoch的拓扑顺序对每个epoch中的区块进行排序. 当确定交易顺序时,交易的顺序由包含这笔交易的区块总序确定先后顺序.
按照上述过程,对企业上传的原始数据对应的Key值进行数据上链操作.
3.2. Fabric联盟链的构建
由于企业众多,为了进一步降低网络资源消耗,选取一定比例通过验证的企业节点构建联盟链,通过这些预选节点实现共识算法、公开验证、安全存储. 采用联盟链Hyperledger Fabric部署联盟链. 联盟链主要负责企业状态数据存储,存储过程中所使用的符号及其含义如表1所示. 在满足合约执行触发条件后,智能合约会自动地访问、共享和存储数据,根据预先定义的约束执行数据存储操作.
表 1 联盟链状态数据存储过程使用的符号及其含义
Tab.1
| 符号 | 含义 |
| 第 | |
| 第 | |
| 实体 | |
| 元素 | |
| 时间戳 | |
| 实体 | |
| 元素 | |
| 使用实体 | |
| 使用实体 | |
| 信息 |
企业状态数据存储的主要流程如下.
1) 系统初始化. 每个企业节点须通过监管机构节点身份认证,认证通过后成为合法的联盟链网络节点. 获取
2) 状态数据上传. 企业节点
其中,
3) 收集上传数据. 本地企业总部节点
4) 本地企业总部节点工作量证明.
每经过一个周期 ,
5) 企业总部节点间的区块共识.
在最短时间内计算出有效工作量证明的企业总部节点
a)
其中,
b)
c) 某个
其中,
d)
其中,
e) 若部分企业总部节点未验证通过,则
通过上述共识过程,企业状态数据将存入联盟链Fabric中,以便为后续对企业营商环境进行评估时提供关联数据溯源和分析支持.
4. 实验与分析
实验数据集来自区块链与智能金融研究中心InplusLab实验室开发的区块链数据智能平台XBlock中的数据集,所有数据集都进行了标准化的清洗和归类,并统一为标准的一致格式. 数据集的具体内容如表2所示.
表 2 实验数据集介绍
Tab.2
| 数据集 | 说明 |
| First-order Transaction Network of Phishing Nodes | 网络平均包含6万多个节点和20万条链路 |
| Bitcoin Partial Transaction Dataset | 对2014年11月至2016年1月的交易数据快照进行采样,采样间隔为6个月,每个快照包含对应月份的前150万条交易记录 |
| Second-order Transaction Network of Phishing Nodes | 包含1 660个目标钓鱼节点和1700个从Etherscan爬取的非钓鱼节点产生的交易数据 |
| Ethereum On-chain Data | 包含14 500 000个区块信息、区块数据生成的 1 524 325 653个交易信息 |
实验从链下Level DB读写性能、企业级复合区块链存储效率2个方面,对比分析营商环境评估的企业级复合区块链构建方法的有效性.
4.1. 链下Level DB数据读写性能对比
当进行Level DB读写性能测试对比时,设置
图 7
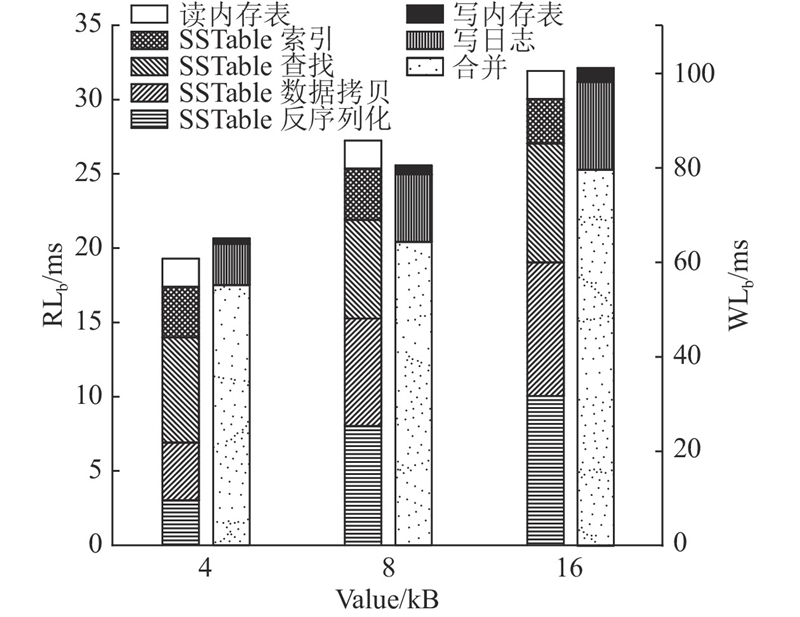
图 7 修改前LevelDB读、写时延的对比图
Fig.7 Comparison of reading and writing latency of LevelDB before modification
图 8
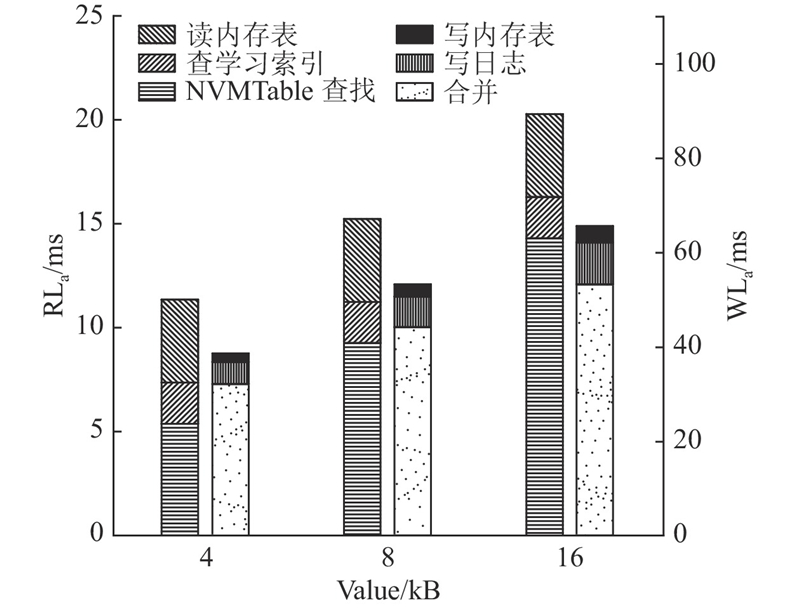
图 8 修改后LevelDB读、写时延的对比图
Fig.8 Comparison of reading and writing latency of LevelDB after modification
4.2. 链上企业级复合区块链的存储效率对比
实验环境为20台服务器、32核CPU、128 GB内存、10 TB存储空间. 区块链采用Docker虚拟化技术部署,使用Kubernetes管理Docker集群. 对比存储模型为公有链以太坊Ethereum和联盟链Hyperledger Fabric. 实验结果如图9所示. 图中,de为存储的企业实体数据集大小,t为存储所需的时间.
图 9
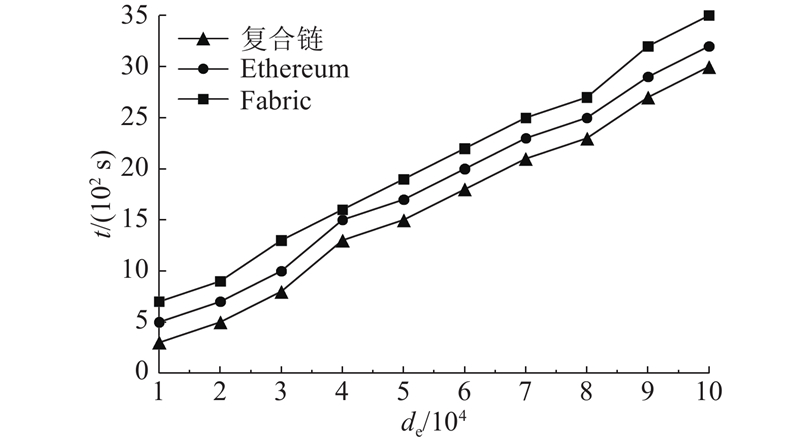
图 9 企业级复合区块链的存储效率对比
Fig.9 Storage efficiency comparison of enterprise composite blockchain
从图9可知,提出的企业级复合区块链存储结构的存储效率高于Ethereum和Fabric,复合区块链中的公有链采用基于DAG的区块结构和Conflux共识,加快了区块构建和共识过程,提高了存储效率.
5. 结 语
营商环境的好坏直接影响企业的经营状况和当地的经济发展. 针对营商环境评估时面临的企业原始数据质量不高的问题,本文提出营商环境评估的企业级复合区块链构建方法,采用链上和链下相结合的存储模式,对企业原始数据进行存储. 引入改进的哈希函数SHA256算法对企业原始数据进行加密,并将其存入链下基于非易失性内存的Level DB数据库中,以降低系统的通信和存储压力. 将数据上链存储,分别将Level DB中的Key值对应存储到基于DAG的Conflux公有链,将企业状态数据对应存入联盟链Hyperledger Fabric,为营商环境评估提供可信的存证数据. 通过实验对比分析,验证了所提方法的有效性.
参考文献
Business environment distance and innovation performance of EMNEs: the mediating effect of R&D internationalization
[J].DOI:10.1016/j.jik.2022.100241 [本文引用: 1]
The joint effects of financial development and the business environment on firm growth: evidence from Vietnam
[J].
Bouncing back in turbulent business environments: exploring resilience in business networks
[J].DOI:10.1016/j.indmarman.2022.10.022 [本文引用: 1]
Predicting production-output performance within a complex business environment: from singular to multi-dimensional observations in evaluation
[J].DOI:10.1080/00207543.2020.1841316 [本文引用: 1]
Anomaly detection in blockchain networks: a comprehensive survey
[J].
The application of the blockchain technology in voting systems: a review
[J].
Information representation of blockchain technology: risk evaluation of investment by personalized quantifier with cubic spline interpolation
[J].
Blockchain applications for the internet of things: systematic review and challenges
[J].DOI:10.1016/j.micpro.2022.104632 [本文引用: 1]
A survey on blockchain for information systems management and security
[J].DOI:10.1016/j.ipm.2020.102397 [本文引用: 1]
Integrated model-driven engineering of blockchain applications for business processes and asset management
[J].DOI:10.1002/spe.2931 [本文引用: 1]
Applications of blockchains in the internet of things: a comprehensive survey
[J].
Blockchain applications for climate protection: a global empirical investigation
[J].DOI:10.1016/j.rser.2021.111378 [本文引用: 1]
Key-Value型NoSQL本地存储系统研究
[J].
A survey on local key-value store of NoSQL system
[J].
基于DAG的分布式账本共识机制研究
[J].
State-of-the-art survey of consensus mecha-nisms on DAG-based distributed ledger
[J].
Wisckey: separating keys from values in SSD-conscious storage
[J].
Design and validation of a phantom for transcranial ultrasonography
[J].DOI:10.1007/s11548-022-02614-2 [本文引用: 1]
Vault: fast bootstrapping for cryptocurrencies
[J].
单向Hash函数SHA256的研究与改进
[J].
One-way Hash function research and improved SHA-256
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}