

时序知识图谱在生活中广泛存在[8],其存储问题具有重要的研究价值. 时序知识图谱本质上是随时间变化的动态资源描述框架 (resource description framework,RDF)图,其节点和边以及相关属性随时间不断变化. 当考虑RDF图上的时间维度时,很多RDF图上的问题变得更加复杂. 以往基于静态知识图谱提出的存储方法已不能有效地解决时序知识图谱上的存储问题.
时序知识图谱可以由若干个静态知识图谱按时间顺序组成,表示为一个RDF图数据集,RDF图可以存为快照或日志. 当时序知识图谱更新时,基于快照的存储方案会保存所有数据. 如果所有时段的快照都存储在内存,图处理系统只须通过指针重定向就可以在不同时段间快速切换. 然而,由于存储中的高冗余,快照存储方案效率较低. 基于日志的存储方案将相关的增量存储起来,添加到初始快照中获得目标快照,避免冗余存储. 然而,由于额外计算,它在快照切换时引入了更长的延迟.
为了提升时序知识图谱的存储与查询效率,本研究提出结合快照和日志模式的时序知识图谱存储模型SL-tgStore,能在保证高效查询的同时,有效地降低存储开销. 本研究的主要贡献如下. 1)针对当前时序知识图谱存储模型存在的不足,提出新的时序知识图谱存储模型SL-tgStore. 引入初始RDF快照图作为时序知识图谱存储和处理的基本单元;在接下来时段内捕获时序知识图谱的更新信息,并存储当前时段的每条RDF日志图;生成新的初始快照,然后存储日志. 所提模型平衡了内存开销大和查询效率低的问题. 2)针对初始快照数量过多导致存储空间开销大,增量日志数量多导致查询时间成本高的问题. 提出相应的阈值θ来确定初始快照的生成,以达到初始快照数量与增量日志数量的平衡,并提出临时快照生成算法. 3)为了高效地对时序知识图谱进行查询,基于新提出的存储模型SL-tgStore,进一步提出4种相应的索引结构Ttg-hash、Vtg-tree、Ptg-hash和Ltg-tree,以提高时序知识图谱的查询检索效率.
1. 相关工作
知识图谱领域的一个核心问题是如何有效地存储RDF数据集,目前对于静态知识图谱数据库的底层存储已经有了广泛的研究. 一种是基于关系型数据的RDF数据存储,包括三元组表、水平表、属性表、垂直划分、全索引策略和部分索引策略. Harris等[9]采用三元组表存储知识图谱,实现起来简单明了,但在查询时会产生大量自连接操作导致效率不高. Pan等[10]采用水平表存储知识图谱,这种方法使查询变得更为简单,但表中的列过多,存在大量空值. Wilkinson[11]采用属性表存储知识图谱,既克服了三元组表的自连接问题, 又解决了水平表中列过多的问题,但对大规模知识图谱,空值和多值问题仍然存在. Abadi等[12]采用垂直划分存储知识图谱,解决了空值和多值问题,但须建立等同于谓词数量的表,维护更新和查询开销都较大. Neumann等[13]采用全索引策略,生成主体、谓词和客体的6种顺序的冗余索引,以提升查询效率. Yuan等[14]提出2类索引结构,每个谓词对应一个2维位矩阵. 另一种是基于图模型的RDF数据存储,最具代表性的2种管理方案为面向属性图的Neo4j[15]存储和面向RDF图的gStore[16]存储.
现有的时序图建模形式主要有3类:第1类是时序图的边带有时间信息的标签;第2类以时间为节点构建副本,将时序图转换成静态图;第3类在离散的时间上为时序图构建相应的快照,如将知识图谱添加单独的时间维度构成时序知识图谱[17]. Han等[18]提出基于快照模型的时序图存储分析引擎,其核心设计包含时序图内存布局和计算调度. Khurana等[19]提出基于快照的存储模型,通过管理元素映射表,在有限的内存中存储所有时段的快照. Haubenschild等[20]提出基于日志的存储模型,将所有快照简化为4种操作:节点的增加和删除、边的增加和删除. Ying等[21]提出基于快照和日志组合的混合存储模型,通过偏斜性感知的策略将2种模型组合使用. Massri等[22]使用优化技术在时序图管理系统中实现复制+日志技术.
已有的时序图存储模型在使用快照存储时内存开销大,在使用日志存储时查询效率低. 为了弥补已有模型的不足,提出新的时序知识图谱存储模型SL-tgStore.
2. 主要定义
定义1 时序. ti为由特定的时间序列定义的最小不可分解的时间单位(可以是1 min,也可以是1 a,由系统分配的图形更新的事务时间来确定),也称为时段. 时序可以形式化表示为T={ti|i∈N},即为一组完全有序的时段.
定义2 时序知识图谱. 知识图谱为三元组G=<V、E、W>. 其中,V表示节点集合,对应所有的主体和客体;E
图 1
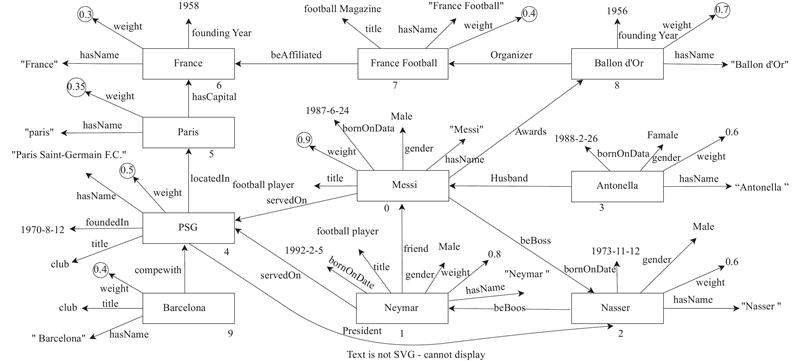
定义3 快照存储模型. 快照存储模型是指时序知识图谱由一系列离散时刻的静态快照图组成,每个静态快照包含一个节点集和一个边集组成的RDF数据集,其形式化定义为
定义4 日志存储模型. 日志存储模型由一系列日志组成,每个日志包含了该时段节点和边的更新数据,其形式化定义为
式中:Lti表示所在的时段ti的增量日志,Lti主要包括节点和边的增加和删除、属性值及权重的修改.
定义5 时间窗口. 时间窗口是每个时段ti所对应的知识图谱的相应检查点的逻辑容器,每个时间窗口存储RDF快照图或RDF日志图,在ti时段,将此时段的时序知识图谱(TGti)存储为Gti或Lti.
定义6 时间桶. 将时序知识图谱存储在时间上不相交的时间段序列中,每个时间桶由若干个时间窗口组成,在每个时间桶的第1个时间窗口存储初始快照,在其他时间窗口存储增量日志,其形式化定义为
3. 时序知识图谱存储方法
3.1. SL-tgStore模型总体结构
SL-tgStore由若干时间桶组成,每个时间桶由一系列的时间窗口组成,引入初始快照作为时序知识图谱的存储和处理的基本单元,即在1个时间桶中的第1个时间窗口存储初始快照. SL-tgStore在指定时间段内捕获时序知识图谱更新信息,然后在接下来的时间窗口存储增量日志,每条增量数据在被存于RDF日志的同时,也用于更新内存中的临时快照. 当临时快照满足阈值条件θ时,SL-tgStore创建一个新的时间桶,时间桶中的初始快照为该时段的临时快照. 时间桶随着时序知识图谱的不断发展而添加,时序知识图谱信息可以基于增量日志进行扩展.
基于SL-tgStore数据结构的时序知识图谱是由所有时间窗口中的初始快照和全部的日志合并而成的,其形式定义为
式中:TG[t1,tn]表示时段t1~tn的时序知识图谱;Gti表示为第i个时间桶的初始快照,Ltij表示第i个时间桶中第j个时间窗口的增量日志;n表示时间桶的数目,同时也是初始快照的数量;m表示时间窗口的数量.
如图2所示,在时段t1下,SL-tgStore创建一个新的时间桶,并采用初始快照Gt1存储,在之后的时段
图 2
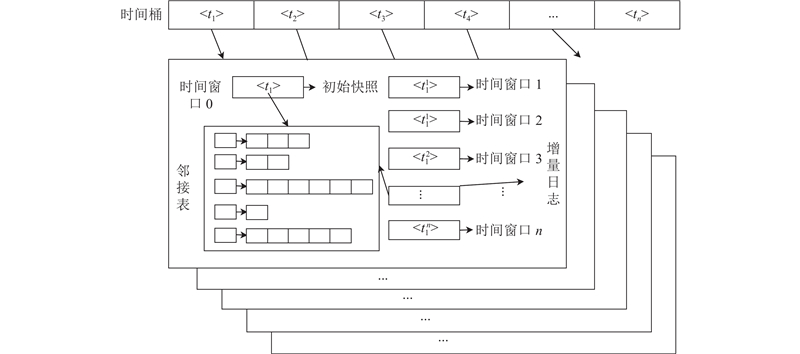
SL-tgStore存储模型采用基于时间属性排列的时间桶存储模型,保留了一个图的所有历史信息,既可以保证良好的存储开销,又具备较高的更新和查询效率. 初始快照组Gti包含足够的信息保证在时段ti可以有效地访问时序知识图谱,在存储开销方面相比完全快照存储具备更好的性能.
3.2. 时序知识图谱快照存储
为了在不牺牲性能的情况下创建紧凑的布局,SL-tgStore引入初始快照作为时序知识图谱每个时间桶的存储和处理的基本单元. 初始快照负责时间桶内的第1个时段,也是第1个时间窗口. 初始快照将时段t1的时序知识图谱存储为基于S、P、O索引结构的邻接表. 初始快照Gt1存储每个时间桶的开始时段t1的完整RDF图数据,包含足够的信息以在时段t1内的任何点都能访问RDF图形数据. 当目标查询时段为其他时间窗口时,通过时间桶内的初始快照和相邻的日志完成查询任务.
时间桶内每个初始快照存储形式由该时段的所有节点和边组成,并且加入该时段的节点权重信息,初始快照存储形式定义为
式中:Gti表示ti时的初始快照,Vi表示ti时的节点集合,对应于所有的主体和客体;Ei
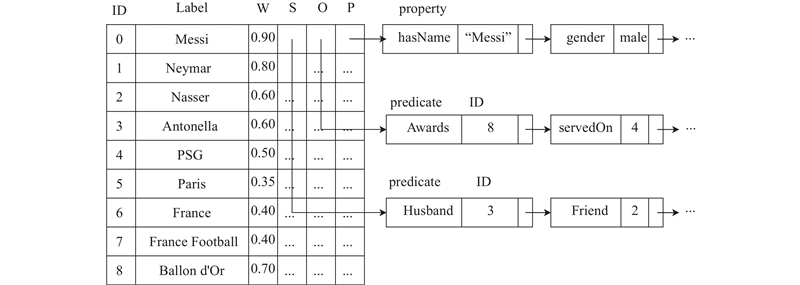
使用基于S、P、O索引的邻接表来存储初始快照Gti. 每个节点V由邻接表[ID,Label,W,S,O,P]表示,其中ID为节点ID,Label为其对应的URI,W为其对应的权重,S为输出边和对应相邻节点的列表,O为输入边和对应相邻节点的列表,P为自身属性列表. 首先将每个Label根据类型进行分类并存储在一个块中,然后再按每个Label的权重大小对其在块中排序. 每个谓词根据流行度(现实世界中被检索的频率)进行排序,以便在查询中更快定位到流行度更高的谓词链接的节点.
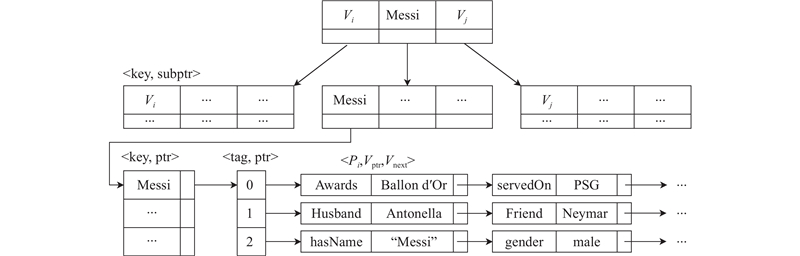
对时间桶为2021年的时序知识图谱初始快照的存储进行分析. 如图1为时序知识图谱快照Gti,如图3所示为其数据结构. 第1个存储的是类型为“person”的块,第2个存储的是类型为“club”的块,块中链表头按权重大小排序顺序. 从节点ID为“Messi”开始第1条边谓词为“Husband”,指向“Antonella”,然后以谓词“Friend”开始,指向“Neymar”,由S块指向. 从节点“Messi”开始的第2条边谓词为“Awards”,指向“Ballon d'Or”,然后以谓词“servedOn”开始,指向“PSG”,由O块指向. 节点Messi”的第3条边存储了“Messi”的属性集合如“hasName”,“gender”,由P块指向.
图 3
3.3. 时序知识图谱日志存储
日志存储模型在以时间属性为索引的RDF图中存储了所有增量日志,其支持更新节点和边的值直接插入,不涉及任何压缩和转换操作,具有较高的日志更新效率和存储效率. 日志组
式中:
每个操作方式由三元组组成,形式化定义如下:
式中:destination为操作的目的节点,op-type为5种操作类型,value为操作值.
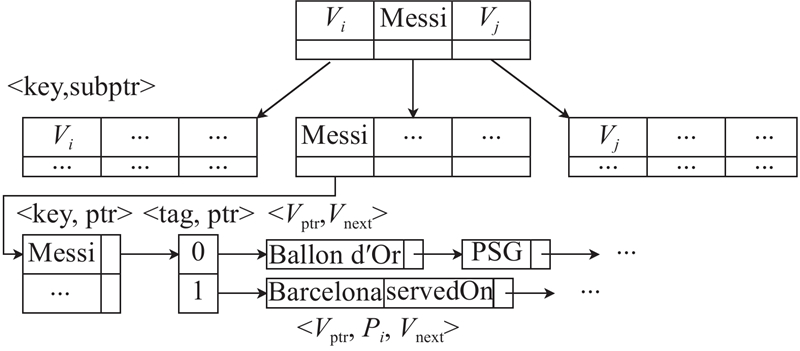
每个增量日志由邻接表构成,不需要存储边的源,因为链表只包含具有相同源节点的操作. 在具体实现中须将增量日志的2个实例组合在一起. 使用基于INS、DEL的邻接表来存储增量日志
基于以上论述,分析时段
图 4
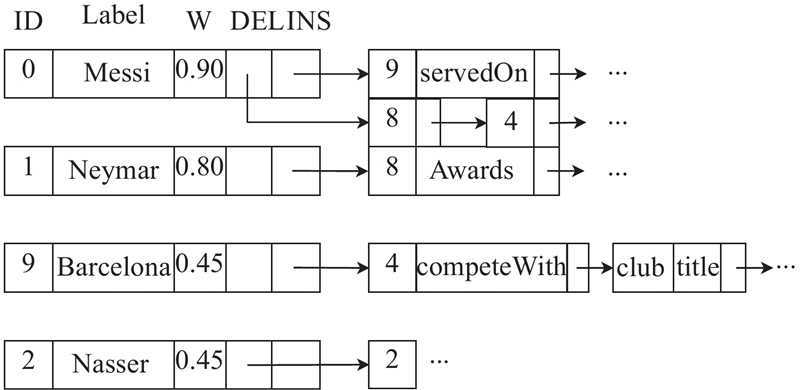
首先新建节点Barcelona,并将其权重更改为0.45,并插入节点ID为4的相关链接和自身属性;删除节点Messi与节点PSG的关系以及节点Messi与节点Ballon d'Or的关系,并增加节点Messi与节点Barcelona的servedOn关系以及节点Neymar与节点Ballon d'Or的Awards关系;最后删除ID为2的节点Nasser.
3.4. 时间桶生成
时序知识图谱由若干时间桶组成,SL-tgStore必须决定如何调度跨越多个时间桶的计算. 一个有效方法是为每个初始快照更新迭代计算,更新存储过程主要包括3个步骤:更新数据存储到增量日志;增量日志合并到初始快照形成临时快照;将合并完成的初始快照和日志组存储到时间桶中. 由于临时快照须在满足一定条件时被存于新的时间桶中作为初始快照,则初始快照的选取和相应的阈值设置尤为重要. 初始快照不仅决定了每个时间桶的规模,而且直接影响SL-tgStore的存储开销和查询成本. 如果相邻时间桶之间的时间跨度过大,则时间桶中的日志规模变大,导致查询检索的数据合并规模增大,进而增加了查询时间;如果时间跨度过小,则时间桶中初始快照数目增多,进而增加了存储空间开销.
基于日志规模的方法生成新的时间桶,即临时快照在满足一定条件时被存储于下一个时间桶中作为初始快照,初始快照存储的选取的相应阈值根据多个相邻日志中操作数总和与当前时间桶中的初始快照中边与节点总和的比值θ来设置.
当θ满足如下公式时,将生成的临时快照存储为初始快照Gti+1:
式中:|Gti|表示时段ti初始快照的节点和边的总数,|
为了更有效率地生成初始快照,提出临时快照生成算法. 时段
算法1 临时快照生成算法.
输入:初始快照Gti=<Vi、Ei、Wi>,日志
输出:生成临时快照Gti+1 = <Vi+1、Ei+1、Wi+1>
1. Gti+1← Gti
2. while
3. if op-type == NINS
4. 在Gti+1建立Vi节点;
5. else if op-type == NDEL
6. 在Gti+1中删除节点Vi及与其相关的边;
7. else if op-type == EINS
8. 在Gti+1中建立Vi和目标节点的边;
9. else if op-type == EDEL
10. 在Gti+1中删除Vi和目标节点的边;
11. else op-type == NMOD
12. 修改Gti+1中Vi节点的权重;
13. end if
14. operation = operation→next;
15. end while
16. return Gti+1;
3.5. 索引设计
为了更高效地对SL-tgStore进行查询,提出4种索引结构来支持查询操作. 第1种是基于时间窗口建立的哈希索引(Ttg-hash),用于索引对应查询图的初始快照和日志;第2种是结合哈希和B+树结构的索引(Vtg-tree),用于索引初始快照中已知节点的查询;第3种是基于谓词建立的哈希索引(Ptg-hash),用于对初始快照中的谓词进行索引;第4种索引类似于第2种,是结合哈希和B+树结构的索引(Ltg-tree),用于索引日志中已知节点的查询.
1)Ttg-hash索引是基于hash分块的索引结构,SL-tgStore结构为具有时间顺序的一系列时间窗口. 索引是一个hash块,其大小等于初始快照的数量,每个时间桶中的时间窗口映射到同一个hash块中,用来直接找到初始快照或相关增量日志在内存中的位置.
如图5所示为Ttg-hash索引的详细结构. 图中,t1表示在时段t1时的初始快照,
图 5

2)Vtg-tree是2层索引,第1层索引先通过哈希函数定位到具体的节点类型分块;索引的第2部分是类似B+树的结构,叶节点的格式为<key, ptr>,其中key为节点,可以是主体或客体,ptr为以key开头或以key结尾的谓词列表. 非叶节点的条目格式为<key, subptr>,其中key用于比较和路由,确定搜索方向,subptr是指向子树根节点的指针,指引搜索的下一层非叶子节点.
如图6所示为Vtg-tree第2层索引的详细结构. Vi为节点标签,当标签为0时,P为记录为<Pi,Vptr,Vnext>的项目列表,Pi为以Vi开头的边的谓词,Vptr为物理存储中的块,Vnext为下一项;当标签为1时,Pi为以Vi结尾的边的谓词;当标记为2时,Pi为与Vi相邻的所有属性.
图 6
3)如果一个查询想要知道所有人在给定时段内的俱乐部效力经历,那么只有相应查询图的谓词“serverdOn”是已知的. 显然,根据Vtg-tree索引结构不能快速找到谓词,因此提出能快速匹配谓词的哈希索引Ptg-hash. 链接边上的谓词标签被存放到哈希函数中,如图7所示为Ptg-hash的结构.
图 7
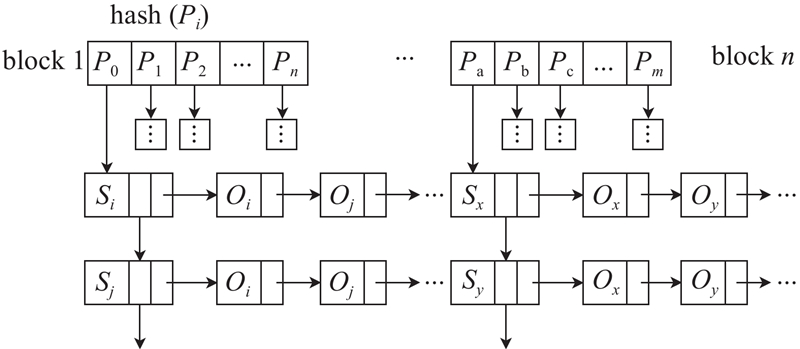
首先采用hashPJW算法为谓词建立哈希函数,Pi表示谓词,谓词键Pi与主体键{S1,S2,···,Sn}的排序列表相关联,每个主体Si链接到客体键{O1,O2,···,On}. 例如,f(servedOn)可以通过哈希函数找出包含键“servedOn”的块,可以从块中查询谓词“servedOn”. 很容易获得满足时间要求的快照中的主体和客体.
4)查询只在知识图谱的局部区域上进行,因此在查询存储日志的时间窗口时,直接基于快照查询结果在日志上查询. Ltg-tree索引与Vtg-tree索引类似,用于快速定位到日志中的节点,用以生成临时快照或直接进行查询. 第1层索引通过hash函数映射到节点的类型,如图8所示为Ltg-tree第2层索引的详细结构. 图中,Vi为节点标签.当标签为0时,P为删除的记录为<Vptr,Vnext>的项目列表,Vptr为物理存储中的块,Vnext为下一项;当标签为1时,P为插入的记录为<Vptr,Pi,Vnext>的项目列表,Pi为以Vi结尾的链接边的谓词.
图 8
4. 实验设计与分析
对所提出的时序知识图谱存储模型SL-tgStore的整体性能进行实验分析. 首先分析通过配置适当的参数θ来调整SL-tgStore的性能,接着分别在模型SL-tgStore的快照和日志模式下对索引性能进行实验分析,最后将SL-tgStore和现有存储模型在真实数据集上对查询时间和存储开销进行实验分析.
4.1. 实验配置和数据集
所使用的计算机操作系统为 Windows 10(64位),Intel® CoreTMi7-8550U CPU @1.80 GHz 2.0 GHz处理器,32 GB运行内存.
实验选用4个基准测试数据集:1)GDELT数据库,记录了1969年至今的每个国家的新闻,且每隔15 min更新一次数据;2)ICEWS数据库,涵盖100多个数据源以及250个国家和区域的政治事件,且每天更新一次数据;3)协作式多语言辅助知识库Wikidata;4)马克斯·普朗克研究所研制的链接数据库YAGO. 数据集的节点权重被定义为节点度数除以所有节点度数的最大值. 具体信息如表1所示. 表中,|V|、|E|、|T|分别表示节点个数、边条数、时序知识图谱的更新间隔.
表 1 实验数据集信息
Tab.1
| 数据集 | |V|/M | |E|/M | |T| |
| GDELT | 2.3 | 32.6 | 15 min |
| ICEWS | 1.2 | 25.2 | 每天 |
| Wikidata | 1.1 | 7.8 | 每年 |
| YAGO | 2.9 | 44.5 | 每年 |
4.2. 参数θ的设定
1)存储空间评估. 实验评估利用SL-tgStore模型在真实数据集上所获得的存储空间增益.如图9(a)所示,展示了通过SL-tgStore处理数据集Wikidata、ICEWS、GDELT、YAGO时的空间开销Mc情况. 可以看出,当参数θ从0.01增加到0.08时,数据集占用的空间显著减少. 随着θ的增大,SL-tgStore存储的增量日志增多,占用的空间较少. 在θ<0.01的情况下,因为此时存储的增量日志较少,占用的内存空间则会增加.
图 9
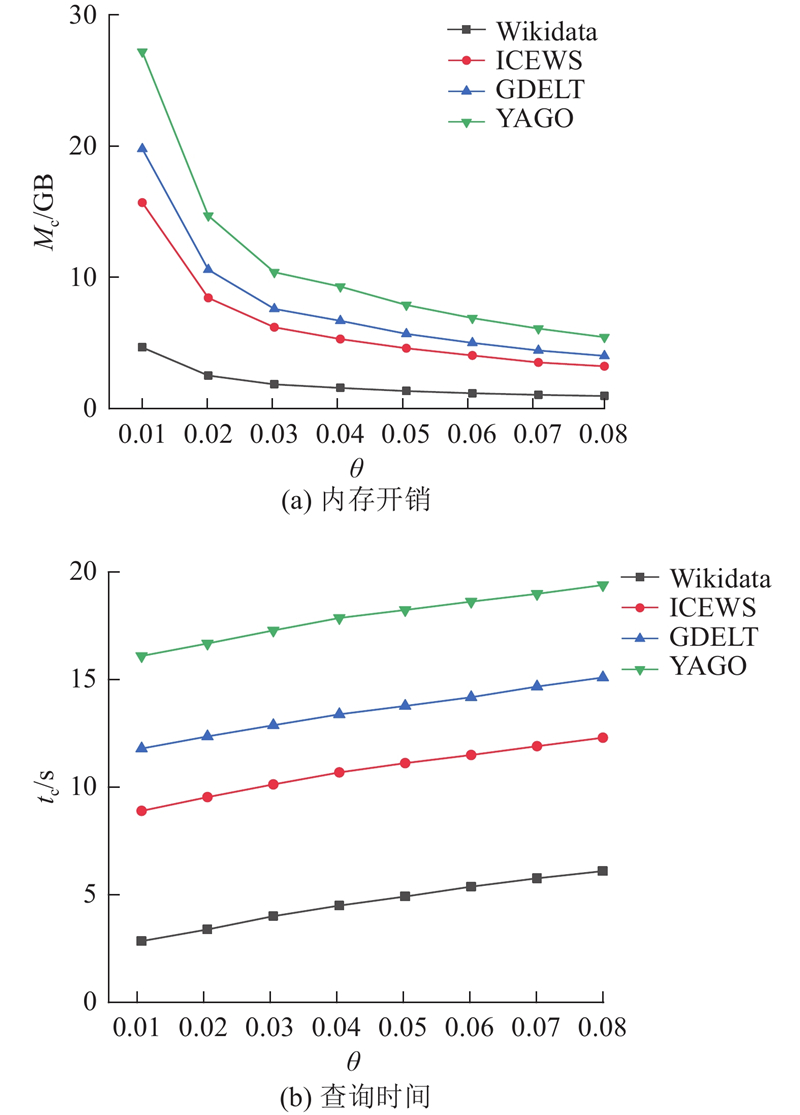
图 9 不同θ下的内存开销与查询时间对比
Fig.9 Comparison of memory overhead and query time under different θ
2)查询时间评估. 进一步评估模型在真实数据集上的查询时间. 如图9(b)所示为θ对查询时间开销tc的影响,结果验证了随着参数θ从0.01增加到0.08,查询时间开销轻微增加,这是因为随着θ的增大,SL-tgStore存储的增量日志增多,须生成查询时刻的临时快照才能得出查询结果. 在θ>0.08的情况下,此时存储的增量日志较多,查询所消耗的时间较多.
对 SL-tgStore 更新过程中,何时生成初始快照,即相应的参数 θ 的选取合理性进行验证分析. 在 SL-tgStore 处理不同真实数据集时,不同参数 θ 下的内存开销和查询时间成本之间对比情况如图 9 所示.可以看出,虽然处理的数据集规模不同,但是内存开销和查询时间随着参数 θ 变化的趋势基本一致,SL-tgStore 存储模型的内存开销随着 θ 的增加呈下降趋势,而查询时间成本随着 θ 的增加呈上升趋势. 可以看出,在处理不同时序知识图谱真实数据集时,SL-tgStore 存储模型的内存开销和查询时间在参数 θ ≈ 0.03时为明显拐点,此时SL-tgStore存储模型的效率最优,因此,选取参数 θ=0.03 作为新时间桶生成条件.
4.3. 索引评估
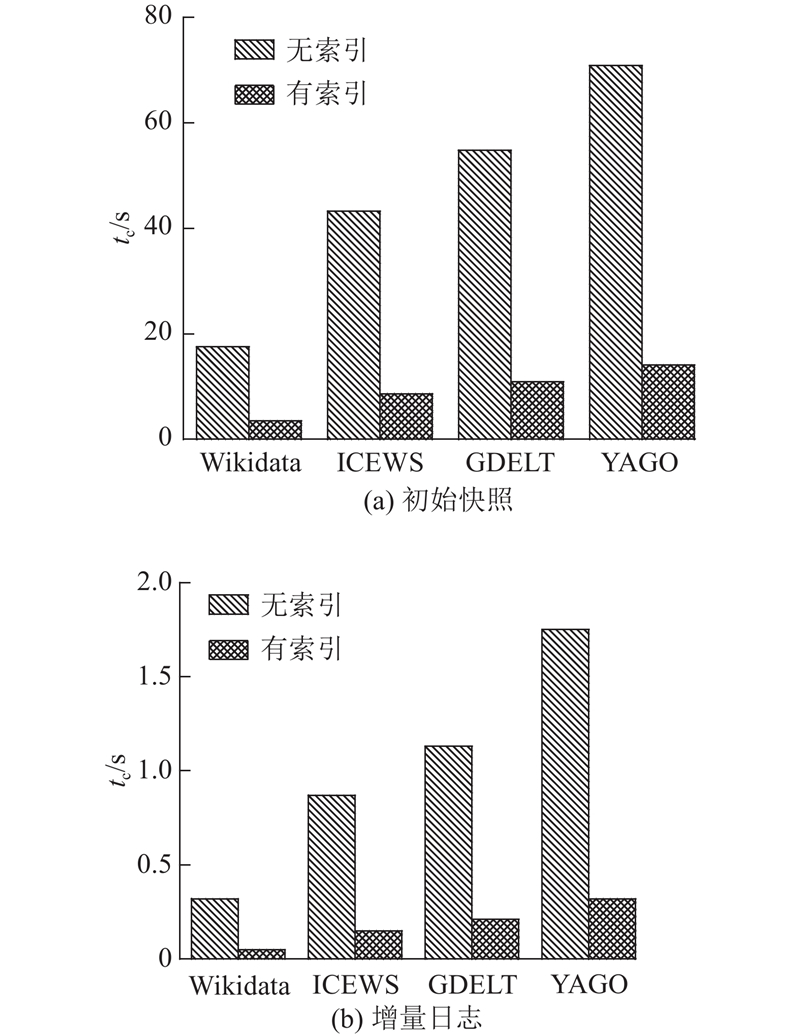
从基于快照查询和日志查询2个角度来评估使用索引的查询性能. 如图10所示为不同数据集上的查询时间开销. 可以看出,基于初始快照的查询在4个数据集上都具有一定的查询成本,但在使用本研究提出的Ttg-hash和Ptg-hash索引结构的情况下,基于快照查询的时间开销有大幅度的降低;在使用本研究提出的Ltg-tree索引结构的情况下,基于日志查询的时间开销有了大幅度的降低.
图 10
4.4. 模型对比与分析
将SL-tgStore的存储开销和查询时间与其他存储模型的进行对比与分析,比较对象包括快照和日志结合的混合存储模型Pensieve和Copy+Log,以及面向知识图谱的商业图形数据库Neo4j. 其中,在Neo4j上开发了一个时间层,以实现时序知识图谱的存储和评估. 如图11所示为各个系统在不同真实数据集上的总体性能对比情况.
图 11
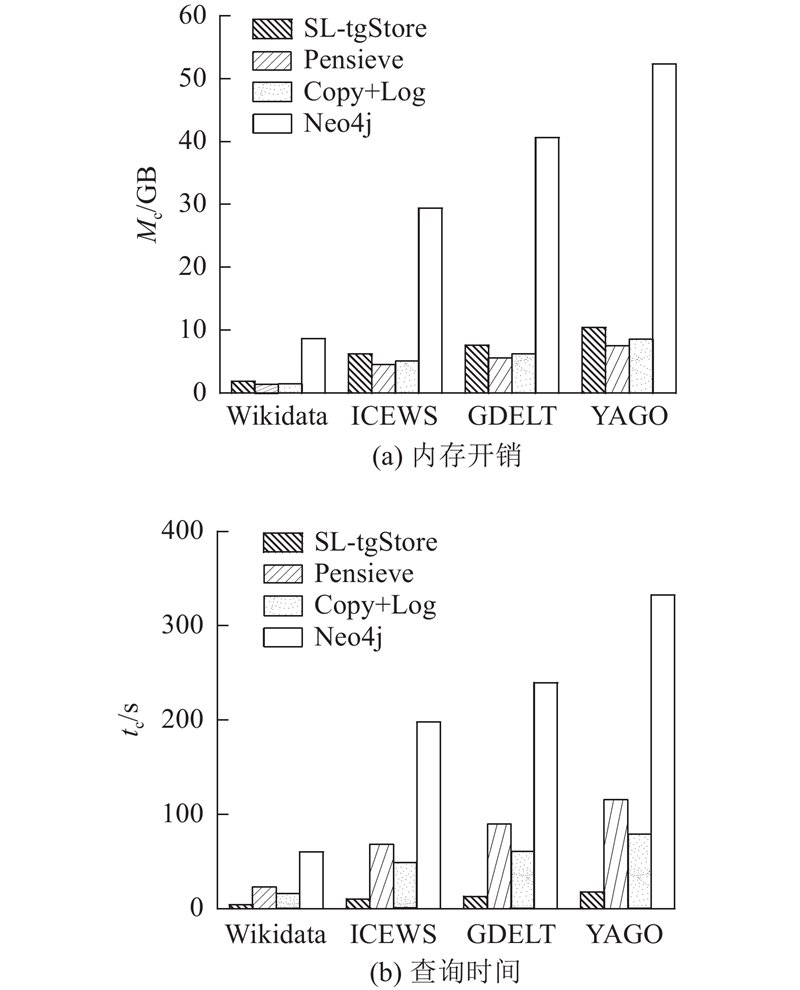
图 11 不同模型的内存开销和查询时间对比
Fig.11 Comparison of memory overhead and query time of different models
1)内存开销对比. 如图11(a)所示为处理不同图数据集时各个系统的内存开销情况. Neo4j的内存开销明显大于SL-tgStore、Pensieve和Copy+Log的,主要原因是Neo4j并没有考虑事务时间上的问题,只是存储静态知识图谱,每个时刻都以快照形式存储数据,造成了存储的冗余. 相比于固定快照和日志数量的Copy+Log模型和通过偏斜性感知组合快照和日志的Pensieve模型,SL-tgStore模型的内存开销略高,主要是由于SL-tgStore模型为了优化查询速度采用了索引结构,增加了一定的存储开销.
2)查询时间对比. 如图11(b)所示,在处理不同数据集时,SL-tgStore的查询效率明显优于Copy+Log、Pensieve和Neo4j,其中Neo4j的效率最差. 当在SL-tgStore中评估查询时间时,搜索空间被修剪为多个选定的时间窗口,这些时间窗口的时间间隔与查询的时间范围相交,可以直接在这些时间窗口的临时快照上查询. SL-tgStore模型在查询效率上相比Copy+Log和Pensieve模式有大幅度的提升,主要因为Copy+Log和Pensieve模式并未采用有效的索引形式来降低查询检索时间. Neo4j是基于属性图存储开发出的图形数据库,相比于存储RDF三元组<S、P、O>类型的关系型数据库,所需要的查询时间开销更大.
5. 结 语
针对时序知识图谱的存储模型和查询方法进行深入研究,提出结合快照和日志存储模式的RDF动态图存储模型SL-tgStore. 该模型存储RDF快照和RDF日志,并设定参数θ作为生成初始RDF快照的条件. 为了有效地对SL-tgStore进行查询,提出4种索引结构来支持后续的查询操作.进一步在真实数据集上进行评估测试. 实验结果表明,SL-tgStore模型在内存消耗和查询时间方面具有较大的优势. 下一步研究重点将主要集中在时序知识图谱上的查询优化方面.
参考文献
基于互联网群体智能的知识图谱构造方法
[J].DOI:10.13328/j.cnki.jos.006313 [本文引用: 1]
Knowledge graph construction method via internet-based collective intelligence
[J].DOI:10.13328/j.cnki.jos.006313 [本文引用: 1]
Neighbor affinity based algorithm for discovering temporal protein complex from dynamic PPI network
[J].DOI:10.1016/j.ymeth.2016.06.010 [本文引用: 1]
Can data-driven precision marketing promote user AD clicks? evidence from advertising in WeChat moments
[J].DOI:10.1016/j.indmarman.2019.05.001 [本文引用: 1]
融合文本描述和层次类型的知识表示学习方法
[J].
Knowledge representation learning method integrating textual description and hierarchical type
[J].
Wikidata: a free collaborative knowledge base
[J].
YAGO: a large ontology from Wikipedia and Wordnet
[J].
Dbpedia-a crystallization point for the web of data
[J].DOI:10.1016/j.websem.2009.07.002 [本文引用: 1]
A survey on knowledge graphs: representation, acquisition, and applications
[J].
SW-Store: a vertically partitioned DBMS for semantic web data management
[J].
Triple Bit: a fast and compact system for large scale RDF data
[J].
Efficient processing of shortest path queries in evolving graph sequences
[J].DOI:10.1016/j.is.2017.05.004 [本文引用: 1]
知识图谱嵌入技术研究综述
[J].DOI:10.13328/j.cnki.jos.006429 [本文引用: 1]
Overview on knowledge graph embedding technology research
[J].DOI:10.13328/j.cnki.jos.006429 [本文引用: 1]
SPARQL 1.1 query language
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}