[1]
SOTO C, YOO S. Visual detection with context for document layout analysis [C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: ACL, 2019: 3464-3470.
[本文引用: 1]
[2]
WATANABE T, LUO Q, SUGIE N Structure recognition methods for various types of documents
[J]. Machine Vision and Applications , 1993 , 6 (2/3 ): 163 - 176
[本文引用: 1]
[3]
HIRAYAMA Y. A method for table structure analysis using DP matching[C]//Proceedings of 3rd International Conference on Document Analysis and Recognition . Montreal: IEEE, 1995: 583-586.
[本文引用: 1]
[4]
FANG J, GAO L, BAI K, et al. A table detection method for multipage pdf documents via visual seperators and tabular structures [C]//2011 International Conference on Document Analysis and Recognition . Beijing: IEEE, 2011: 779-783.
[本文引用: 1]
[5]
BUNKE H, RIESEN K Recent advances in graph-based pattern recognition with applications in document analysis
[J]. Pattern Recognition , 2011 , 44 (5 ): 1057 - 1067
DOI:10.1016/j.patcog.2010.11.015
[本文引用: 1]
[6]
HINTON G E, SALAKHUTDINOV R R Reducing the dimensionality of data with neural networks
[J]. Science , 2006 , 313 (5786 ): 504 - 507
DOI:10.1126/science.1127647
[本文引用: 1]
[8]
SAHA R, MONDAL A, JAWAHAR C V. Graphical object detection in document images [C]//International Conference on Document Analysis and Recognition . Sydney: IEEE, 2019: 51-58.
[本文引用: 1]
[9]
GIRSHICK R. Fast r-cnn [C]//Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440-1448.
[本文引用: 1]
[10]
HE K, GKIOXARI G, DOLLÁR P, et al. Mask r-cnn [C]//Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2961-2969.
[本文引用: 1]
[11]
RIBA P, DUTTA A, GOLDMANN L, et al. Table detection in invoice documents by graph neural networks [C]//2019 International Conference on Document Analysis and Recognition . Sydney: IEEE, 2019: 122-127.
[本文引用: 1]
[12]
XU Y, LI M, CUI L, et al. Layoutlm: pre-training of text and layout for document image understanding [C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . San Diego: ACM, 2020: 1192-1200.
[本文引用: 1]
[13]
LI J, XU Y, LV T, et al. Dit: self-supervised pre-training for document image transformer[C]//Proceedings of the 30th ACM International Conference on Multimedia . Lisson: ACM, 2022: 3530-3539.
[本文引用: 6]
[14]
APPALARAJU S, JASANI B, KOTA B U, et al. Docformer: end-to-end transformer for document understanding [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 993-1003.
[本文引用: 1]
[15]
PHAM V, PHAM C, DANG T. Road damage detection and classification with detectron2 and faster r-cnn [C]//2020 IEEE International Conference on Big Data . Atlanta: IEEE, 2020: 5592-5601.
[本文引用: 1]
[16]
CAI Z, VASCONCELOS N. Cascade r-cnn: delving into high quality object detection [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6154-6162.
[本文引用: 1]
[17]
RANFTL R, BOCHKOVSKIY A, KOLTUN V. Vision transformers for dense prediction [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 12179-12188.
[本文引用: 1]
[18]
KIM W, SON B, KIM I. Vilt: vision-and-language transformer without convolution or region supervision [C]// Proceedings of the 38th International Conference on Machine Learning . [S. l.]: PMLR, 2021: 5583-5594.
[本文引用: 1]
[19]
GHIASI G, LIN T Y, LE Q V. Nas-FPN: learning scalable feature pyramid architecture for object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE , 2019: 7036-7045.
[本文引用: 1]
[20]
KAWINTIRANON K, SINGH L. Knowledge enhanced masked language model for stance detection [C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Mexico: ACL, 2021: 4725-4735.
[本文引用: 1]
[21]
XIE Z, ZHANG Z, CAO Y, et al. Simmim: a simple framework for masked image modeling [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 9653-9663.
[本文引用: 1]
[22]
HUANG Y, LV T, CUI L, et al. Layoutlmv3: pre-training for document ai with unified text and image masking [C]//Proceedings of the 30th ACM International Conference on Multimedia . Lisson: ACM, 2022: 4083-4091.
[本文引用: 1]
[23]
BAO H, DONG L, PIAO S, et al. Beit: Bert pre-training of image transformers [EB/OL]. [2022-09-03]. https://arxiv.org/abs/2106.08254.
[本文引用: 6]
[24]
ZHONG X, TANG J, YEPES A J. Publaynet: largest dataset ever for document layout analysis [C]//2019 International Conference on Document Analysis and Recognition . Sydney: IEEE, 2019: 1015-1022.
[本文引用: 5]
[25]
GU J, KUEN J, MORARIU V I, et al Unidoc: unified pretraining framework for document understanding
[J]. Advances in Neural Information Processing Systems , 2021 , 34 : 39 - 50
[本文引用: 4]
1
... 随着数字化时代的到来,大量的文档数据被生成和存储,涵盖了广泛的学科领域,有着重要的学术和实用价值. 文档通常具有复杂的结构,为了从非结构化文档中提取有价值的信息,首要任务是对文档进行结构分析,以确定文档中每个元素的类型、位置和排列方式,从而更好地理解文档的内容. 识别非结构化数字文档布局是将文档解析为结构化、机器可读的格式,进而支持下游应用程序的重要步骤[1 ] . ...
Structure recognition methods for various types of documents
1
1993
... 在早期的研究工作中,大多都基于图像处理和文本解析的方式对文档进行结构分析. Watanabe等[2 ] 提出基于水平垂直线的方法来识别定位文档中的表格区域. Hirayama[3 ] 将包含表格或图形的区域通过水平和垂直线的方式区分开来,使用DP匹配方法来分析区域结构. Fang等[4 ] 提出利用视觉分隔符和几何内容布局信息的文档区域检测方法. Bunke等[5 ] 提出图嵌入框架与最近邻分类器,对传统文档进行结构分析. 尽管这些方法取得了较好的成果,但对文档图像的质量要求较高,对文本复杂度较高的文档处理效果较差. ...
1
... 在早期的研究工作中,大多都基于图像处理和文本解析的方式对文档进行结构分析. Watanabe等[2 ] 提出基于水平垂直线的方法来识别定位文档中的表格区域. Hirayama[3 ] 将包含表格或图形的区域通过水平和垂直线的方式区分开来,使用DP匹配方法来分析区域结构. Fang等[4 ] 提出利用视觉分隔符和几何内容布局信息的文档区域检测方法. Bunke等[5 ] 提出图嵌入框架与最近邻分类器,对传统文档进行结构分析. 尽管这些方法取得了较好的成果,但对文档图像的质量要求较高,对文本复杂度较高的文档处理效果较差. ...
1
... 在早期的研究工作中,大多都基于图像处理和文本解析的方式对文档进行结构分析. Watanabe等[2 ] 提出基于水平垂直线的方法来识别定位文档中的表格区域. Hirayama[3 ] 将包含表格或图形的区域通过水平和垂直线的方式区分开来,使用DP匹配方法来分析区域结构. Fang等[4 ] 提出利用视觉分隔符和几何内容布局信息的文档区域检测方法. Bunke等[5 ] 提出图嵌入框架与最近邻分类器,对传统文档进行结构分析. 尽管这些方法取得了较好的成果,但对文档图像的质量要求较高,对文本复杂度较高的文档处理效果较差. ...
Recent advances in graph-based pattern recognition with applications in document analysis
1
2011
... 在早期的研究工作中,大多都基于图像处理和文本解析的方式对文档进行结构分析. Watanabe等[2 ] 提出基于水平垂直线的方法来识别定位文档中的表格区域. Hirayama[3 ] 将包含表格或图形的区域通过水平和垂直线的方式区分开来,使用DP匹配方法来分析区域结构. Fang等[4 ] 提出利用视觉分隔符和几何内容布局信息的文档区域检测方法. Bunke等[5 ] 提出图嵌入框架与最近邻分类器,对传统文档进行结构分析. 尽管这些方法取得了较好的成果,但对文档图像的质量要求较高,对文本复杂度较高的文档处理效果较差. ...
Reducing the dimensionality of data with neural networks
1
2006
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
基于双向LSTM网络的流式文档结构识别
1
2020
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
基于双向LSTM网络的流式文档结构识别
1
2020
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
1
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
1
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
1
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
1
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
1
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
6
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
... 为了验证MCOD-Net模型在文档布局分析任务中的有效性,在PublayNet公开数据集上比较分析DiT[13 ] 、BEiT[23 ] 、PublayNet[24 ] 、UDoc[25 ] 模型与提出MCOD-Net模型的性能差异.实验结果表明,MCOD-Net模型在文档布局分析任务中表现出优异性能,具有更高的准确性和鲁棒性,证明了其在解决实际问题上的有效性. 对比试验结果如表2 所示. 表2 表明,提出的MCOD-Net模型在PublayNet数据集上的整体性能指标达到了95.1%的最优效果,识别精度较基于Mask R-CNN骨干网络的BEiT[23 ] 模型提升了2.5%.验证了MCOD-Net模型在文档分析任务中性能的有效性和可靠性. ...
... Overall performance of proposed model and existing models on PublayNet dataset
Tab.2 模型 主干网络 mAP/% PublayNet[24 ] Mask R-CNN 91.0 DiT[13 ] Mask R-CNN 91.6 DiT[13 ] Cascader R-CNN 92.5 UDoc[25 ] Faster R-CNN 91.7 BEiT[23 ] Mask R-CNN 92.6 MCOD-Net Cascader R-CNN 95.1
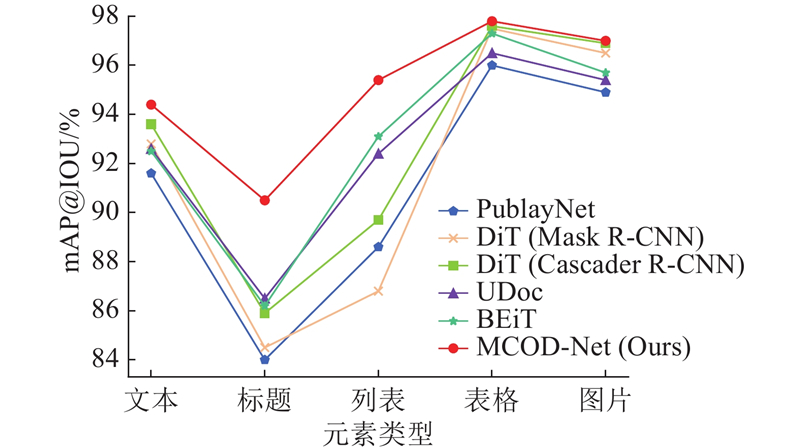
为了进一步体现所提出的MDOC-Net模型对文档图像中每类标签元素的识别能力,分别针对文档中的5类元素进行识别对比实验,实验结果如表3 所示.表3 和图3 表明,MDOC-Net模型在PubLayNet数据集上对文档中标题、文本、图片、列表和表格5类元素的总体平均精度都取得了较好的结果,特别在标题和列表元素识别上,所提模型的评估指标分别达到了90.5%和95.4%的最优效果,其中标题元素识别精度比UDoc[25 ] 模型提升了4%,列表元素识别精度比BEiT[23 ] 模型提升了2.3%.可知,所提模型较其他主流方法具有明显的优势. ...
... [
13 ]
Cascader R-CNN 92.5 UDoc[25 ] Faster R-CNN 91.7 BEiT[23 ] Mask R-CNN 92.6 MCOD-Net Cascader R-CNN 95.1 为了进一步体现所提出的MDOC-Net模型对文档图像中每类标签元素的识别能力,分别针对文档中的5类元素进行识别对比实验,实验结果如表3 所示.表3 和图3 表明,MDOC-Net模型在PubLayNet数据集上对文档中标题、文本、图片、列表和表格5类元素的总体平均精度都取得了较好的结果,特别在标题和列表元素识别上,所提模型的评估指标分别达到了90.5%和95.4%的最优效果,其中标题元素识别精度比UDoc[25 ] 模型提升了4%,列表元素识别精度比BEiT[23 ] 模型提升了2.3%.可知,所提模型较其他主流方法具有明显的优势. ...
... mAP values of proposed model and existing models for identification of various elements in PublayNet dataset
Tab.3 模型 mAP/% 文本 标题 列表 表格 图片 PublayNet[24 ] 91.6 84.0 88.6 96.0 94.9 DiT[13 ] (Mask R-CNN) 92.8 84.5 86.8 97.5 96.5 DiT[13 ] (Cascader R-CNN) 93.6 85.9 89.7 97.6 96.9 UDoc[25 ] 92.6 86.5 92.4 96.5 95.4 BEiT[23 ] 92.5 86.2 93.1 97.3 95.7 MCOD-Net 94.4 90.5 95.4 97.8 97.0
图 3 各类元素的识别结果 ...
... [
13 ](Cascader R-CNN)
93.6 85.9 89.7 97.6 96.9 UDoc[25 ] 92.6 86.5 92.4 96.5 95.4 BEiT[23 ] 92.5 86.2 93.1 97.3 95.7 MCOD-Net 94.4 90.5 95.4 97.8 97.0 图 3 各类元素的识别结果 ...
1
... 随着深度学习技术的迅速发展,该技术已被广泛应用到文档布局分析任务中[6 ] . 张真等[7 ] 提出基于双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)的流式文档结构识别方法,取得了较好的成果. Saha等[8 ] 使用Faster R-CNN[9 ] 和Mask R-CNN[10 ] 网络来提取各区域特征,精准识别出文档表格区域. Riba等[11 ] 通过图神经网络(graph neural network, GNN)来识别文本和图片区域,构建一个图来判别表格区域. Xu等[12 -13 ] 提出基于Transformer的文档布局分析模型LayoutLM和基于视觉Transformer架构的DiT(Document Image Transformer)模型. 前者不仅可以处理文本和布局信息,还可以处理多语言文档. Appalaraju等[14 ] 提出Docformer模型,将文档布局分析任务转化为序列标注问题. ...
1
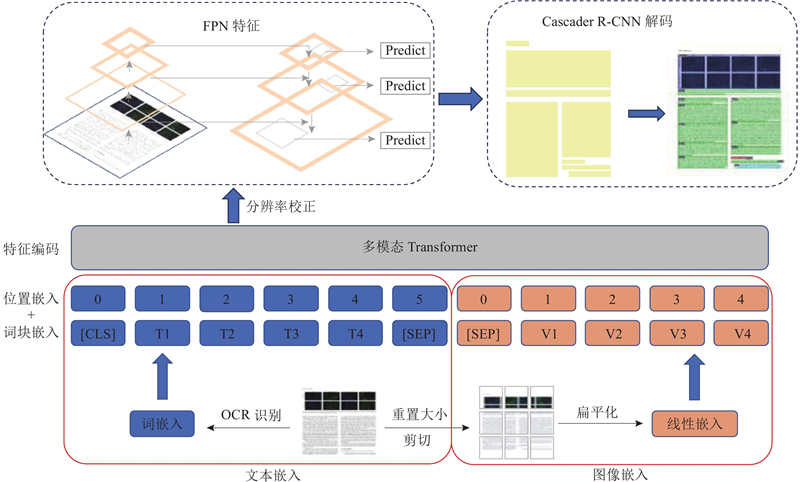
... Detectron2框架是Facebook AI研究院(Facebook AI Research, FAIR)于2018年初公开的目标检测平台,具有简洁高效、简单易用的特点,受到广泛关注[15 ] . 搭建Detectron2目标检测环境,基于Detectron2构建MCOD-Net模型,实现文档布局分析的任务. MCOD-Net模型是多级目标检测网络,该模型采用6层Transformer编码器进行特征提取,包含6个多头自注意力模块,隐藏层大小$D = 384$ [16 ] 作为目标检测模型的骨干网络进行解码. 模型从不同的Transformer层中提取单尺度特征,使用分辨率修正模块,将单尺度特征转换为多尺度的特征金字塔网络 (feature pyramid network, FPN)特征. 模型的整体结构如图1 所示. ...
1
... Detectron2框架是Facebook AI研究院(Facebook AI Research, FAIR)于2018年初公开的目标检测平台,具有简洁高效、简单易用的特点,受到广泛关注[15 ] . 搭建Detectron2目标检测环境,基于Detectron2构建MCOD-Net模型,实现文档布局分析的任务. MCOD-Net模型是多级目标检测网络,该模型采用6层Transformer编码器进行特征提取,包含6个多头自注意力模块,隐藏层大小$D = 384$ [16 ] 作为目标检测模型的骨干网络进行解码. 模型从不同的Transformer层中提取单尺度特征,使用分辨率修正模块,将单尺度特征转换为多尺度的特征金字塔网络 (feature pyramid network, FPN)特征. 模型的整体结构如图1 所示. ...
1
... 对于图像嵌入部分,受到VIT[17 ] 和VILT[18 ] 的启发,使用图像块的线性投影特征来表示文档图像. 将图像块的线性嵌入序列作为多模态Transformer的输入. 给每个图像块添加可学习的一维位置嵌入. 具体来说,将整个文档图像大小调整为$H \times W$ $ {\boldsymbol{I}} \in {{\bf{R}}^{C \times H \times W}} $ $C$ $H$ $W$ $T \times T$ ${\boldsymbol{v}} \in {{\bf{R}}^{N \times ({T^2} \times C)}}$ $D$ $N = H W/{T^2}$ . ...
1
... 对于图像嵌入部分,受到VIT[17 ] 和VILT[18 ] 的启发,使用图像块的线性投影特征来表示文档图像. 将图像块的线性嵌入序列作为多模态Transformer的输入. 给每个图像块添加可学习的一维位置嵌入. 具体来说,将整个文档图像大小调整为$H \times W$ $ {\boldsymbol{I}} \in {{\bf{R}}^{C \times H \times W}} $ $C$ $H$ $W$ $T \times T$ ${\boldsymbol{v}} \in {{\bf{R}}^{N \times ({T^2} \times C)}}$ $D$ $N = H W/{T^2}$ . ...
1
... 特征编码模块如图1 的 Multimodel Transformer层所示,该模块包含6层Transformer编码器,包括6个多头自注意力块,其中5个自注意力块分别进行每一类元素的检测,另外一个自注意力块进行文本和图像位置对齐的检测. 每个Transformer层提取单尺度特征,利用分辨率校正模块将单尺度特征转换为多尺度的FPN特征. FPN模型的基本思想是通过跨层级连接来结合高层次语义信息与低层次的细节信息,构建金字塔式的特征层级结构[19 ] . 具体来说,FPN将下采样(池化)过程中的特征图上采样(插值)到原始分辨率,与原始特征图进行融合,生成高分辨率、高语义信息的特征图. 这些特征图可以用于不同尺度的目标检测任务. FPN的主要优点是能够在不引入额外参数的情况下,有效地提高目标检测模型的性能. ...
1
... 模型使用掩码语言模型(masked language modeling, MLM)、掩码图像模型(masked image modeling, MIM)和词块对齐(word-patch alignment, WPA)3个预训练目标进行训练,以自监督学习的方式学习多模态表示. 其中MLM的目标是通过遮盖输入文本中的一些词语,使得模型根据上下文信息来预测被遮盖的词语,以提高模型理解上下文的能力[20 ] . MIM是使模型通过联合处理上下文文本和图像表征,更好地理解视觉内容. 这种训练策略可以激励模型从多个视觉表征中解释视觉信息,提高模型的视觉推理能力[21 ] . WPA是为了训练得到词块对齐而专门做的预训练[22 ] . 整体预训练目标为 ...
1
... 模型使用掩码语言模型(masked language modeling, MLM)、掩码图像模型(masked image modeling, MIM)和词块对齐(word-patch alignment, WPA)3个预训练目标进行训练,以自监督学习的方式学习多模态表示. 其中MLM的目标是通过遮盖输入文本中的一些词语,使得模型根据上下文信息来预测被遮盖的词语,以提高模型理解上下文的能力[20 ] . MIM是使模型通过联合处理上下文文本和图像表征,更好地理解视觉内容. 这种训练策略可以激励模型从多个视觉表征中解释视觉信息,提高模型的视觉推理能力[21 ] . WPA是为了训练得到词块对齐而专门做的预训练[22 ] . 整体预训练目标为 ...
1
... 模型使用掩码语言模型(masked language modeling, MLM)、掩码图像模型(masked image modeling, MIM)和词块对齐(word-patch alignment, WPA)3个预训练目标进行训练,以自监督学习的方式学习多模态表示. 其中MLM的目标是通过遮盖输入文本中的一些词语,使得模型根据上下文信息来预测被遮盖的词语,以提高模型理解上下文的能力[20 ] . MIM是使模型通过联合处理上下文文本和图像表征,更好地理解视觉内容. 这种训练策略可以激励模型从多个视觉表征中解释视觉信息,提高模型的视觉推理能力[21 ] . WPA是为了训练得到词块对齐而专门做的预训练[22 ] . 整体预训练目标为 ...
6
... 为了提高模型对上下文文本和图像的理解和表征能力,将BEiT[23 ] (bidiretional encoder representation from image transformers)中的MIM预训练目标改写为多模态Transformer模块. MIM采用顺时针遮盖策略,即在实验中随机对约40%的图像标记进行遮盖. 在MIM预训练中,利用交叉熵损失来引导模型学习文本和图像中被遮盖的部分,逐渐优化其预测能力. 对被掩盖的图像标记建模为 ...
... 为了验证MCOD-Net模型在文档布局分析任务中的有效性,在PublayNet公开数据集上比较分析DiT[13 ] 、BEiT[23 ] 、PublayNet[24 ] 、UDoc[25 ] 模型与提出MCOD-Net模型的性能差异.实验结果表明,MCOD-Net模型在文档布局分析任务中表现出优异性能,具有更高的准确性和鲁棒性,证明了其在解决实际问题上的有效性. 对比试验结果如表2 所示. 表2 表明,提出的MCOD-Net模型在PublayNet数据集上的整体性能指标达到了95.1%的最优效果,识别精度较基于Mask R-CNN骨干网络的BEiT[23 ] 模型提升了2.5%.验证了MCOD-Net模型在文档分析任务中性能的有效性和可靠性. ...
... [23 ]模型提升了2.5%.验证了MCOD-Net模型在文档分析任务中性能的有效性和可靠性. ...
... Overall performance of proposed model and existing models on PublayNet dataset
Tab.2 模型 主干网络 mAP/% PublayNet[24 ] Mask R-CNN 91.0 DiT[13 ] Mask R-CNN 91.6 DiT[13 ] Cascader R-CNN 92.5 UDoc[25 ] Faster R-CNN 91.7 BEiT[23 ] Mask R-CNN 92.6 MCOD-Net Cascader R-CNN 95.1
为了进一步体现所提出的MDOC-Net模型对文档图像中每类标签元素的识别能力,分别针对文档中的5类元素进行识别对比实验,实验结果如表3 所示.表3 和图3 表明,MDOC-Net模型在PubLayNet数据集上对文档中标题、文本、图片、列表和表格5类元素的总体平均精度都取得了较好的结果,特别在标题和列表元素识别上,所提模型的评估指标分别达到了90.5%和95.4%的最优效果,其中标题元素识别精度比UDoc[25 ] 模型提升了4%,列表元素识别精度比BEiT[23 ] 模型提升了2.3%.可知,所提模型较其他主流方法具有明显的优势. ...
... 为了进一步体现所提出的MDOC-Net模型对文档图像中每类标签元素的识别能力,分别针对文档中的5类元素进行识别对比实验,实验结果如表3 所示.表3 和图3 表明,MDOC-Net模型在PubLayNet数据集上对文档中标题、文本、图片、列表和表格5类元素的总体平均精度都取得了较好的结果,特别在标题和列表元素识别上,所提模型的评估指标分别达到了90.5%和95.4%的最优效果,其中标题元素识别精度比UDoc[25 ] 模型提升了4%,列表元素识别精度比BEiT[23 ] 模型提升了2.3%.可知,所提模型较其他主流方法具有明显的优势. ...
... mAP values of proposed model and existing models for identification of various elements in PublayNet dataset
Tab.3 模型 mAP/% 文本 标题 列表 表格 图片 PublayNet[24 ] 91.6 84.0 88.6 96.0 94.9 DiT[13 ] (Mask R-CNN) 92.8 84.5 86.8 97.5 96.5 DiT[13 ] (Cascader R-CNN) 93.6 85.9 89.7 97.6 96.9 UDoc[25 ] 92.6 86.5 92.4 96.5 95.4 BEiT[23 ] 92.5 86.2 93.1 97.3 95.7 MCOD-Net 94.4 90.5 95.4 97.8 97.0
图 3 各类元素的识别结果 ...
5
... 为了保证实验的可靠性和公平性,使用PubLayNet公开数据集进行实验,PubLayNet是大规模的文档布局分析数据集,通过自动解析PubMed XML文件来构建文档图像[24 ] . 生成的注释涵盖了典型的文档布局元素,具有丰富的布局结构和内容类型,如标题、正文、图片、表格、列表等. 该数据集包含335 703张训练集、11 245张验证集和11 405张测试集. 该数据集的目标是为基于机器学习的出版物智能化处理提供公开、可用的数据资源,促进出版物版面分析领域的研究和进展[24 ] . 该数据集及其标签如图2 所示. ...
... [24 ]. 该数据集及其标签如图2 所示. ...
... 为了验证MCOD-Net模型在文档布局分析任务中的有效性,在PublayNet公开数据集上比较分析DiT[13 ] 、BEiT[23 ] 、PublayNet[24 ] 、UDoc[25 ] 模型与提出MCOD-Net模型的性能差异.实验结果表明,MCOD-Net模型在文档布局分析任务中表现出优异性能,具有更高的准确性和鲁棒性,证明了其在解决实际问题上的有效性. 对比试验结果如表2 所示. 表2 表明,提出的MCOD-Net模型在PublayNet数据集上的整体性能指标达到了95.1%的最优效果,识别精度较基于Mask R-CNN骨干网络的BEiT[23 ] 模型提升了2.5%.验证了MCOD-Net模型在文档分析任务中性能的有效性和可靠性. ...
... Overall performance of proposed model and existing models on PublayNet dataset
Tab.2 模型 主干网络 mAP/% PublayNet[24 ] Mask R-CNN 91.0 DiT[13 ] Mask R-CNN 91.6 DiT[13 ] Cascader R-CNN 92.5 UDoc[25 ] Faster R-CNN 91.7 BEiT[23 ] Mask R-CNN 92.6 MCOD-Net Cascader R-CNN 95.1
为了进一步体现所提出的MDOC-Net模型对文档图像中每类标签元素的识别能力,分别针对文档中的5类元素进行识别对比实验,实验结果如表3 所示.表3 和图3 表明,MDOC-Net模型在PubLayNet数据集上对文档中标题、文本、图片、列表和表格5类元素的总体平均精度都取得了较好的结果,特别在标题和列表元素识别上,所提模型的评估指标分别达到了90.5%和95.4%的最优效果,其中标题元素识别精度比UDoc[25 ] 模型提升了4%,列表元素识别精度比BEiT[23 ] 模型提升了2.3%.可知,所提模型较其他主流方法具有明显的优势. ...
... mAP values of proposed model and existing models for identification of various elements in PublayNet dataset
Tab.3 模型 mAP/% 文本 标题 列表 表格 图片 PublayNet[24 ] 91.6 84.0 88.6 96.0 94.9 DiT[13 ] (Mask R-CNN) 92.8 84.5 86.8 97.5 96.5 DiT[13 ] (Cascader R-CNN) 93.6 85.9 89.7 97.6 96.9 UDoc[25 ] 92.6 86.5 92.4 96.5 95.4 BEiT[23 ] 92.5 86.2 93.1 97.3 95.7 MCOD-Net 94.4 90.5 95.4 97.8 97.0
图 3 各类元素的识别结果 ...
Unidoc: unified pretraining framework for document understanding
4
2021
... 为了验证MCOD-Net模型在文档布局分析任务中的有效性,在PublayNet公开数据集上比较分析DiT[13 ] 、BEiT[23 ] 、PublayNet[24 ] 、UDoc[25 ] 模型与提出MCOD-Net模型的性能差异.实验结果表明,MCOD-Net模型在文档布局分析任务中表现出优异性能,具有更高的准确性和鲁棒性,证明了其在解决实际问题上的有效性. 对比试验结果如表2 所示. 表2 表明,提出的MCOD-Net模型在PublayNet数据集上的整体性能指标达到了95.1%的最优效果,识别精度较基于Mask R-CNN骨干网络的BEiT[23 ] 模型提升了2.5%.验证了MCOD-Net模型在文档分析任务中性能的有效性和可靠性. ...
... Overall performance of proposed model and existing models on PublayNet dataset
Tab.2 模型 主干网络 mAP/% PublayNet[24 ] Mask R-CNN 91.0 DiT[13 ] Mask R-CNN 91.6 DiT[13 ] Cascader R-CNN 92.5 UDoc[25 ] Faster R-CNN 91.7 BEiT[23 ] Mask R-CNN 92.6 MCOD-Net Cascader R-CNN 95.1
为了进一步体现所提出的MDOC-Net模型对文档图像中每类标签元素的识别能力,分别针对文档中的5类元素进行识别对比实验,实验结果如表3 所示.表3 和图3 表明,MDOC-Net模型在PubLayNet数据集上对文档中标题、文本、图片、列表和表格5类元素的总体平均精度都取得了较好的结果,特别在标题和列表元素识别上,所提模型的评估指标分别达到了90.5%和95.4%的最优效果,其中标题元素识别精度比UDoc[25 ] 模型提升了4%,列表元素识别精度比BEiT[23 ] 模型提升了2.3%.可知,所提模型较其他主流方法具有明显的优势. ...
... 为了进一步体现所提出的MDOC-Net模型对文档图像中每类标签元素的识别能力,分别针对文档中的5类元素进行识别对比实验,实验结果如表3 所示.表3 和图3 表明,MDOC-Net模型在PubLayNet数据集上对文档中标题、文本、图片、列表和表格5类元素的总体平均精度都取得了较好的结果,特别在标题和列表元素识别上,所提模型的评估指标分别达到了90.5%和95.4%的最优效果,其中标题元素识别精度比UDoc[25 ] 模型提升了4%,列表元素识别精度比BEiT[23 ] 模型提升了2.3%.可知,所提模型较其他主流方法具有明显的优势. ...
... mAP values of proposed model and existing models for identification of various elements in PublayNet dataset
Tab.3 模型 mAP/% 文本 标题 列表 表格 图片 PublayNet[24 ] 91.6 84.0 88.6 96.0 94.9 DiT[13 ] (Mask R-CNN) 92.8 84.5 86.8 97.5 96.5 DiT[13 ] (Cascader R-CNN) 93.6 85.9 89.7 97.6 96.9 UDoc[25 ] 92.6 86.5 92.4 96.5 95.4 BEiT[23 ] 92.5 86.2 93.1 97.3 95.7 MCOD-Net 94.4 90.5 95.4 97.8 97.0
图 3 各类元素的识别结果 ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}