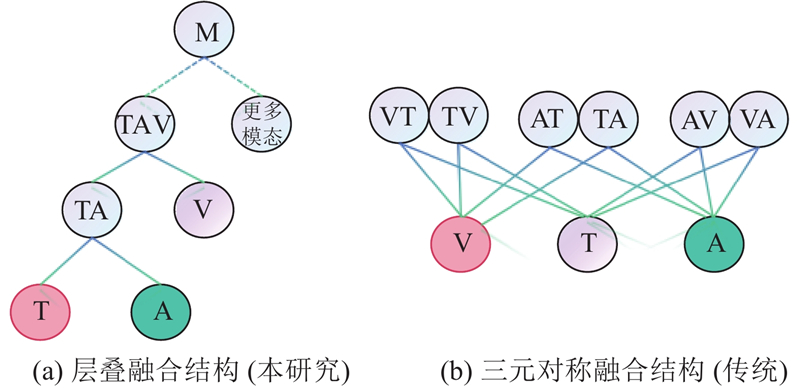
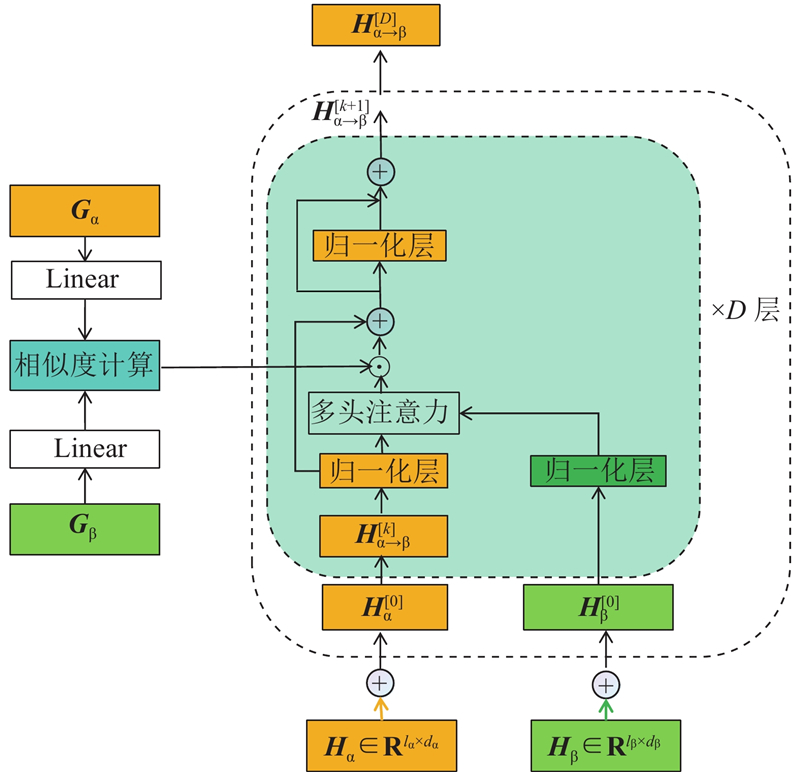
A new multimodal sentiment analysis model (MTSA) was proposed on the basis of cross-modal Transformer, aiming at the difficult retention of the modal feature heterogeneity for single-modal feature extraction and feature redundancy for cross-modal feature fusion. Long short-term memory (LSTM) and multi-task learning framework were used to extract single-modal contextual semantic information, the noise was removed and the modal feature heterogeneity was preserved by adding up auxiliary modal task losses. Multi-tasking gating mechanism was used to adjust cross-modal feature fusion. Text, audio and visual modal features were fused in a stacked cross-modal Transformer structure to improve fusion depth and avoid feature redundancy. MTSA was evaluated in the MOSEI and SIMS data sets, results show that compared with other advanced models, MTSA has better overall performance, the accuracy of binary classification reached 83.51% and 84.18% respectively.
CHEN Qiao-hong, SUN Jia-jin, LOU Yang-bo, FANG Zhi-jian. Multimodal sentiment analysis model based on multi-task learning and stacked cross-modal Transformer. Journal of Zhejiang University(Engineering Science)[J], 2023, 57(12): 2421-2429 doi:10.3785/j.issn.1008-973X.2023.12.009
HUANG Y, DU C, XUE Z, et al. What makes multi-modal learning better than single [C]// Advances in Neural Information Processing Systems. [S.l.]: NIPS, 2021: 10944-10956.
WANG H, MEGHAWAT A, MORENCY L P, et al. Select-additive learning: improving generalization in multimodal sentiment analysis [C]// 2017 IEEE International Conference on Multimedia and Expo. Hong Kong: IEEE, 2017: 949-954.
WILLIAMS J, COMANESCU R, RADU O, et al. DNN multimodal fusion techniques for predicting video sentiment [C]// Proceedings of Grand Challenge and Workshop on Human Multimodal Language. [S.l.]: ACL, 2018: 64-72.
NOJAVANASGHARI B, GOPINATH D, KOUSHIK J, et al. Deep multimodal fusion for persuasiveness prediction [C]// Proceedings of the 18th ACM International Conference on Multimodal Interaction. Tokyo: ACM, 2016: 284-288.
WANG Y, SHEN Y, LIU Z, et al. Words can shift: dynamically adjusting word representations using nonverbal behaviors [C]// Proceedings of the Thirty-third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence. [S.l.]: AAAI, 2019: 7216-7223.
ZADEH A, CHEN M, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: ACL, 2017: 1103-1114.
YU W, XU H, MENG F, et al. CH-SIMS: a chinese multimodal sentiment analysis dataset with fine-grained annotation of modality [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2020: 3718-3727.
TSAI Y H H, BAI S, LIANG P P, et al. Multimodal Transformer for unaligned multimodal language sequences [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: ACL, 2019: 6558-6569.
WU J, MAI S, HU H. Graph capsule aggregation for unaligned multimodal sequences [C]// Proceedings of the 2021 International Conference on Multimodal Interaction. [S.l.]: ACM, 2021: 521-529.
MA H, HAN Z, ZHANG C, et al. Trustworthy multimodal regression with mixture of normal-inverse gamma distributions [C]// Advances in Neural Information Processing Systems. [S.l.]: NIPS, 2021: 6881-6893.
SIRIWARDHANA S, KALUARACHCHI T, BILLINGHURST M, et al
Multimodal emotion recognition with Transformer-based self supervised feature fusion
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume1 (Long and Short Papers). Minneapolis: ACL, 2019: 4171-4186.
MCFEE B, RAFFEL C, LIANG D, et al. librosa: audio and music signal analysis in python [C]// Proceedings of the Python in Science Conference (SCIPY 2015). Austin: SciPy, 2015.
BALTRUSAITIS T, ZADEH A, LIM Y C, et al. OpenFace 2.0: facial behavior analysis toolkit [C]// 2018 13th IEEE International Conference on Automatic Face and Gesture Recognition. Xi’an: IEEE, 2018: 59-66.
HAN W, CHEN H, GELBUKH A, et al. Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis [C]// Proceedings of the 2021 International Conference on Multimodal Interaction. [S.l.]: ACM, 2021: 6-15.
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. [S.l.]: NIPS, 2017: 6000-6010.
CHEN Z, BADRINARAYANAN V, LEE C Y, et al. GradNorm: gradient normalization for adaptive loss balancing in deep multitask networks [C]// Proceedings of the 35th International Conference on Machine Learning. [S.l.]: PMLR, 2018: 794-803.
ZADEH A, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne: ACL, 2018: 2236-2246.
ZADEH A, ZELLERS R, PINCUS E, et al. MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos [EB/OL]. (2016-08-12)[2022-11-25]. https://arxiv.org/ftp/arxiv/papers/1606/1606.06259.pdf.
LIU Z, SHEN Y, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2018: 2247-2256.
ZADEH A, LIANG P P, PORIA S, et al. Multi-attention recurrent network for human communication comprehension [EB/OL]. (2018-02-03)[2022-11-29]. https://arxiv.org/pdf/1802.00923.pdf.
HAZARIKA D, ZIMMERMANN R, PORIA S. MISA: modality-invariant and-specific representations for multimodal sentiment analysis [C]// Proceedings of the 28th ACM International Conference on Multimedia. Nice: ACM, 2020: 1122-1131.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}