

生物特征识别身份的系统非常有吸引力,它们易于使用且安全系数高,因此研究者们对这些人体固有的生理或行为特征的研究也日益增多. Wang等[1]提出动态类池化方法来存储和更新身份特征,在不牺牲性能的情况下,节省时间和成本. Zhu等[2]提出全局-局部交叉注意和成对交叉注意来实现各类图像间的信息交互,学习到细微特征可以提高行人识别准确率. Ye等[3]提出一种基于二维卷积神经网络(two dimensional convolutional neural network, 2D-CNN)和门控循环单元(gated recurrent unit,GRU) 的深度神经网络 (deep neural network,DNN) 模型,实现说话人的身份识别等. 当特征采集器获取特征出现误差时,由于现实场景的复杂性,仅仅采用单一生物特征很难维持身份识别的稳定性;当单一生物特征无法满足现实需求时,研究者们便尝试以多生物特征的丰富性来应对现实情况的复杂性. Ye等[4]使用可见图像生成辅助灰度模态,挖掘可见图片特征与对应图片的红外特征之间的结构关系,解决白天和夜间因存在光线差异的目标身份识别问题. Qian等[5]有效地结合人脸信息和语音信息,显著地提高个人身份验证系统的性能. Sarangi等[6]提出一种基于耳朵和人脸轮廓的多模态生物识别系统,组合2个有效的局部特征,产生高维特征向量. 在频域和空间域中保留互补信息,弥补了耳朵特征进行身份识别时的缺点,也提高了整体的身份识别准确率. 在社区安全问题中,指纹、语音、人脸、行人等则是需要特定的前端设备和安装角度的位置相互配合. 现有的监控设备大都不具备这种配合条件,因此在这种场景下动态的目标识别就变得比较困难. 目前尚未发现有研究通过人脸和行人特征的融合来解决类似的问题,如何组合人脸特征与行人特征并产生鲁棒性更强的目标身份特征是亟待解决的问题.
目前常用的多模态特征融合方法[7]有联合表示和协调表示等,联合表示常用的是Concat方法直接拼接产生维数更高的特征或Add方法将2个特征向量组合成复合向量,而协调表示则是学习协调子空间中的每个模态的分离但约束表示. Concat方法是简单拼接的方法,虽然丰富了目标身份特征信息,但是使得冗余信息增加,会对身份判决带来强干扰. 受多生物特征融合[8]的启发,本研究设计出门控特征融合网络(gated feature fusion network,GFFN),考虑各部分特征的融合程度,在丰富特征信息的同时,也避免冗余信息带来的误判. 针对本研究的目标多分类问题,交叉熵损失函数虽然能实现类间区分,但是类内的距离却没有进行约束. 当不同人的穿着或相貌相似时,类间距离减少;当同一人受拍摄角度或者光线强度等影响时,类内距离增大,则会出现类间距离小于类内距离的情况. Dickson等[9]发现将平方和误差损失函数与交叉熵损失函数混合使用可以提高网络性能,结合现实应用与Wen等[10]的损失函数融合思想,通过加入中心损失对分类网络进行类内距离约束,使得提取的特征判别性更强.
1. GFFN模型
由于摄像头角度、抓拍距离、目标活动及光线明暗程度等现实情况的影响,使得监控场景下人脸数据的有效性受限,从而导致人脸识别网络的准确率急剧下降. 受多模态特征融合的启发,在实际应用中考虑到人脸与行人特征各自的价值以及在不同场景下所受到的技术约束,对两者各自的优势进行融合应用,采用的门控融合网络可以指导神经网络去综合考虑人脸和行人特征的贡献量,有效地缓解因单生物特征信息模糊而导致识别准确率低的现象. GFFN模型的整体框架如图1所示.
图 1

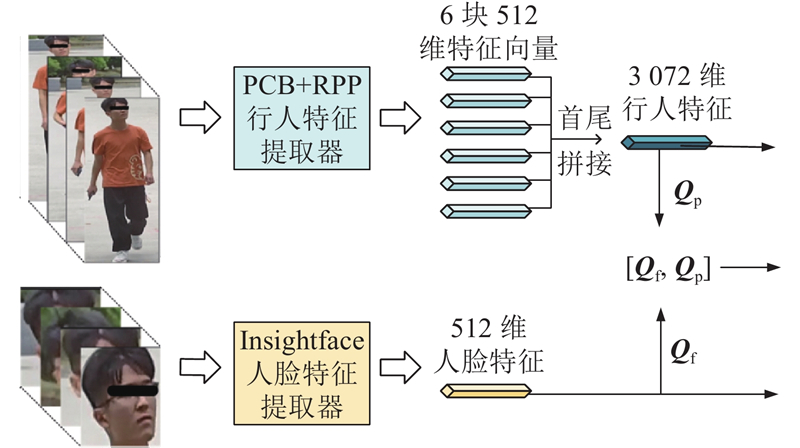
1.1. 模型的输入模块
图 2
1.2. 模型的特征融合模块
将得到的2个特征送入特征融合模块进行融合,组合出更加丰富且有效的身份特征.
1.2.1. 特征相加融合
如图3(a)所示,相加融合是指特征值相加,通道数不变,将2个特征向量组合成复合向量.
图 3
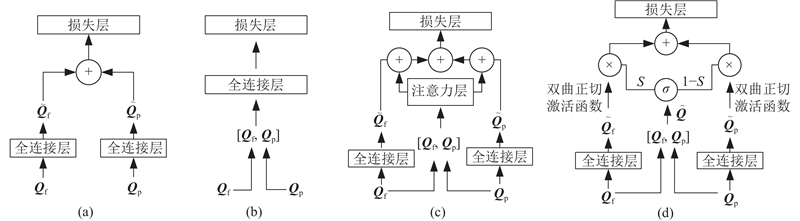
1.2.2. 特征拼接融合
如图3(b)所示,拼接融合是指将2个特征进行首尾拼接. 当通道数增加时,
1.2.3. 软注意力融合
式中:
式中:
1.2.4. 门控特征融合
如图3(d)所示,门控机制是应用在GRU或长短期记忆(long short term memory,LSTM)网络等循环网络中的流量控制部件,使用的门控特征融合结构[5]. 在结合特征融合优势的同时,重点在决策层面进行优化控制. GFFN设计的目的是将不同的生物特征数据进行组合并找到最优表示. 每个
式中:
为了不同特征的组合找到最优的表示,模型以人脸512维特征和行人3 072维特征作为输入,都经过一个FC层,该层还包括归一化层(batch normalization,BN)和Drop_out层. BN层的加入是为了加快网络的训练和收敛、控制梯度爆炸和防止梯度消失;Drop_out层则可以防止训练过拟合,整体是为了得到更加紧凑和区分性更强的特征. 人脸特征和行人特征的输出维度均为1 024,再用双曲正切函数进行激活. 最初输入的人脸特征和行人特征进行首尾拼接后,以及经过相同的FC层操作后,得到1 024维融合特征
1.3. 模型的损失函数模块
在一般的识别任务中,训练集和测试集的所有类别都会有对应标签,如著名的Mnist和ImageNet数据集,里面包含的每个类别是确定的. 大多网络最终采用Softmax损失函数进行监督训练,得到的深度特征都具有良好的类间区分性. 身份识别任务存在类间复杂及类内多样的问题,预先收集所有测试目标的信息是不切实际的,因此需要网络学习到的特征具有较强的判别性.
中心距离损失的设计主要是为了缓解类间距离小于类内距离导致识别有误的情况,通过寻找每一类特征的中心,以度量学习的形式惩罚所学特征与它类中心的距离即缩小同类样本之间的距离. Wen等[10]通过以手写数字分类任务为例(Mnist数据集),展示网络最终的输出特征在二维空间的分布. 类间距离虽然被区分,但是仍存在类内距离过大的情况,于是提出Center Loss来约束类内距离. 本研究借鉴减少类内距离的思想,将门控分类与中心损失结合产生新的损失函数为
式中:
图 4
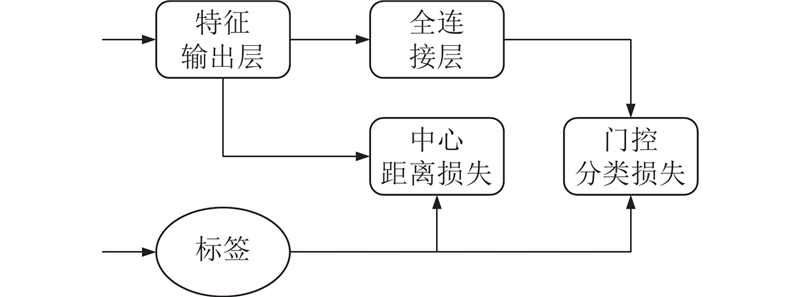
图 4 门控分类损失和中心距离损失的连接图
Fig.4 Connection diagram of gated classification loss and center distance loss
2. 实验处理与结果分析
2.1. 实验数据集的制作
为了抓拍到丰富的行人姿态,在某高校人口流动稳定的路段安装了12台监控抓拍设备. 在若干天的固定时间段下,收集到约
图 5

表 1 G-campus1392数据集的图片数量
Tab.1
| 数据集 | | ||
| 训练集 | 测试集 | 库 | |
| Randomdata1 | 15 138 | 16 486 | 3 480 |
| Randomdata2 | 15 846 | 15 778 | 3 480 |
| Randomdata3 | 15 354 | 16 270 | 3 480 |
2.2. 实验训练与测试说明
本研究以表征学习的形式来训练识别模型,最后的全连接层维数等于类别数. 在测试时,需要利用的是训练网络的特征提取能力,并且训练集和测试集的ID不能共享,因此会丢弃最后的全连接层. 为了保证实验的合理性,对单行人、单人脸、各种融合方法均采用ID分类网络进行训练. 将所有方法中网络的全连接层数和超参数进行统一,取全连接层之前的1 024维特征作为输出特征,便于后续的距离度量.
实验的评价指标是重识别任务(re-identification, ReID)中常用的识别准确率(accuracy,ACC)和平均准确率(mean average precision,mAP). 为了真实刻画目标识别的合理性与真实性,计算库中每个ID的5张图片与待测试的图片之间的欧式距离,采用加和求平均数的方法得到平均距离. 当平均距离最小的库ID与待测试图片ID相同时,则该测试图片识别正确,所有测试图片(总数记为
ACC指标则是统计识别正确个数占总ID数的比重. 为了能够更加全面的衡量ReID算法的性能,采用mAP指标来反映检索的人在数据库中所有正确图片排在序列表前面的程度,其计算式为
式中:
2.3. 实验方法
为了验证所提方法的有效性,实验部分对比了图3中的3种特征融合方法,也将单一特征的分类识别结果与各融合方法进行对比. 在现实监控场景下,人脸和行人的特征融合,能够弥补单一特征信息丢失的不足.
2.4. 实验分析
在试验中,通过对比单一特征识别结果、多特征识别结果以及是否加入中心距离损失来验证所提方法的有效性.
2.4.1. 各识别方法的实验结果分析
表 2 多种识别方法的结果对比
Tab.2
| 方法 | Randomdata1 | Randomdata2 | Randomdata3 | |||||
| ACC/% | mAP/% | ACC/% | mAP/% | ACC/% | mAP/% | |||
| 人脸分类 | 40.659 | 35.532 | 41.615 | 36.089 | 39.447 | 34.389 | ||
| 行人分类 | 55.265 | 52.275 | 55.451 | 51.527 | 53.737 | 50.626 | ||
| 特征相加融合 | 59.878 | 55.585 | 60.235 | 55.961 | 57.367 | 54.146 | ||
| 首尾拼接融合 | 61.749 | 57.890 | 61.313 | 57.091 | 59.939 | 55.851 | ||
| 软注意力融合 | 64.582 | 59.835 | 63.519 | 58.936 | 62.698 | 56.261 | ||
| 门控特征融合 | 73.893 | 69.342 | 73.305 | 68.583 | 71.807 | 67.280 | ||
以上2种融合方法都是静态的特征融合,而软注意力融合与本研究的门控特征融合都是动态的特征融合方式,两者的平均准确率分别为63.6%、73.0%. 从实验结果看,多特征的动态组合不仅能弥补单一特征信息缺失的不足,也能缓解多特征融合存在冗余的问题. 两者虽都为动态融合,但两者在动态程度上存在差别,软注意力机制会重点关注某一特征,并且会综合考虑所有特征,最终所得的权值系数很难取到极端值. 在现实应用场景下,人脸往往模糊到无法获取有用的特征甚至是干扰的信息. 本研究的门控方法采用sigmoid函数进行权值分配,由于该函数的平滑性和取值特征,考虑到的因素更多,更适合现实场景下的应用. 不难发现,本研究的门控特征融合方法带来的提升效果是显著且稳定的.
2.4.2. 中心距离损失效果分析
表 3 分类网络增加中心距离损失后的ACC值
Tab.3
| 方法 | Randomdata1 | Randomdata2 | Randomdata3 | |||||
| L1 | L2 | L1 | L2 | L1 | L2 | |||
| 人脸分类 | 40.659 | 43.989 | 41.615 | 44.219 | 39.447 | 42.612 | ||
| 行人分类 | 55.265 | 61.197 | 55.451 | 60.698 | 53.737 | 59.213 | ||
| 特征相加融合 | 59.878 | 65.235 | 60.235 | 67.593 | 57.367 | 66.326 | ||
| 首尾拼接融合 | 61.749 | 71.430 | 61.313 | 70.681 | 59.939 | 69.490 | ||
| 软注意力融合 | 64.582 | 72.298 | 63.519 | 71.796 | 62.698 | 71.008 | ||
| 门控特征融合 | 73.893 | 75.798 | 73.305 | 76.347 | 71.807 | 74.714 | ||
表 4 分类网络增加中心距离损失后的mAP值
Tab.4
| 方法 | Randomdata1 | Randomdata2 | Randomdata3 | |||||
| L1 | L2 | L1 | L2 | L1 | L2 | |||
| 人脸分类 | 35.532 | 37.925 | 36.089 | 37.993 | 34.389 | 36.665 | ||
| 行人分类 | 52.275 | 56.777 | 51.527 | 56.182 | 50.626 | 54.934 | ||
| 特征相加融合 | 55.585 | 61.623 | 55.961 | 61.962 | 54.146 | 59.247 | ||
| 首尾拼接融合 | 57.890 | 65.642 | 57.091 | 64.684 | 55.851 | 62.271 | ||
| 软注意力融合 | 59.835 | 67.234 | 58.936 | 66.039 | 56.261 | 64.915 | ||
| 门控特征融合 | 69.342 | 71.461 | 68.583 | 71.257 | 67.280 | 69.715 | ||
通过观察表3、4的实验结果可以发现,ACC值和mAP值在加入中心距离损失后均有提升,各方法的平均准确率分别提高3.0%、5.6%、7.2%、9.5%、8.1%、2.6%. 各方法在加上中心距离损失训练后,随着类中心距离在训练过程中不断更新调整,有效缓解样本由于类间距离小于类内距离而导致判决错误的情况. 6类方法的平均准确率先上升后下降,当2个特征进行融合后,融合特征的类内距离会随之增加. 为了使得融合后的类内特征距离更加紧凑,加入中心距离损失,改善因类内距离过大而出现误判的情况,单特征改善情况则不会那么显著. 本研究的门控方法加入损失后的提升效果虽不如其他方法明显,是因为特征的有效性已经接近上限,同时也反映出本研究特征融合方式是紧凑的.
2.4.3. 错误样本分析
图 6

由于本研究数据集由项目合作方提供,暂时没有取得公开权限,读者可以搜集多个公开数据集如Market1501等. 在使用能够看到人脸和行人的数据时,可以与本研究相当的数据量进行重现测试,也可以根据介绍的数据集制作流程,重新制作数据集进行复现.
3. 结 语
本研究提出了一种基于门控多特征融合与中心损失的动态目标识别方法. 以门控的方式将行人特征与人脸特征进行动态融合,产生更强的类间区分性特征,可以弥补单一特征在现实场景下由于信息丢失导致识别准确率下降的问题. 将中心距离损失与门控分类损失结合,随着类中心距离的更新,类内距离不断缩小,使得特征更具判别能力. 在自制数据集实验结果中,监控场景下的特征融合方法可以有效降低目标识别的误判概率. 在实际场景下,会出现待识别目标被遮挡、更换衣服或监控环境光强变化等复杂情况,这样会导致特征融合产生不了更强的特征,反而会组合产生干扰特征,因此进一步的研究可从如何提取强鲁棒性的特征或训练出带有记忆的识别网络2个方向来展开.
参考文献
A deep neural network model for speaker identification
[J].DOI:10.3390/app11083603 [本文引用: 1]
Visible-infrared person re-identification via homogeneous augmented tri-modal learning
[J].
Audio visual deep neural network for robust person verification
[J].DOI:10.1109/TASLP.2021.3057230 [本文引用: 2]
A feature-level fusion based improved multimodal biometric recognition system using ear and profile face
[J].
Deep multimodal representation learning: a survey
[J].DOI:10.1109/ACCESS.2019.2916887 [本文引用: 1]
Gated multimodal networks
[J].DOI:10.1007/s00521-019-04559-1 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}