

随着人工智能技术的发展,行人目标检测在自动驾驶、安防监控领域都有广泛的应用[1]. 现阶段行人检测系统大部分只对中大型行人目标具有较好的检测效果,远处的小目标行人容易被忽略. 在自动驾驶领域中,大目标往往由小目标变化而来,及时准确检测出小目标可以使汽车提前规划路径,避开行人. 小目标行人检测的挑战主要源于小目标信息量少,包括小目标自身特征分辨率低、可利用特征少,并且在当前行人数据集中,小目标行人数量占比较少[2]. 在卷积网络中,小目标对象在经过多次下采样后会导致自身特征信息大量流失,故深层网络往往难以提取足够的小目标信息. 内外特征融合网络(inside-outside network,ION)[3]、亢奋特征网络(hyper network,hyperNet)[4]能从不同尺度特征图中提取特征并综合预测以增加小目标的信息量. 不同尺度之间往往存在大量重复计算及内存开销极大的问题,因此如何有效提取足够的小目标信息并保持较小的计算量在小目标行人检测中至关重要.
对数据集进行数据增强操作可以在不增加模型推理计算量的情况下,提高检测精度. Kisantal等[7]通过在图像中对小目标多次复制粘贴来提高小目标样本数量,但是该方法可能导致新生成的小目标背景大小与实际不符,甚至对网络推理产生误导. 特征图金字塔网络[8](feature pyramid networks, FPN)通过将相邻层的特征融合,可以做到仅提升少量计算量换取对小目标检测精度的提升. 加权双向特征金字塔网络(bi-directional feature pyramid network,Bi-FPN)[9]、循环特征金字塔网络(recursive feature pyramid network,Recursive-FPN)[10]也被提出,这些网络对小目标行人的检测精度都有所提升. 这些特征融合方式都存在容易融合噪声的问题,检测效果难以进一步提升,计算量也有所增加.
基于移动视觉网络的单阶段锚框网络(single shot multibox detector, SSD)[11]是 SSD算法的精简版,该模型使用MobileNet-V2网络[12]代替SSD骨干网络VGG,虽然满足了实时性要求,但是检测精度有限,尤其对于小目标物体的检测能力更差. 针对以上对小目标行人检测的问题,本研究从数据增强方面入手,根据射影几何和消隐点、消隐线的性质,设计自适应增殖小目标生成方法. 该方法能够有效地在合理区域生成尺寸匹配的行人目标,增加了小目标行人的数量和种类,避免了传统复制粘贴方法生成大小和背景不匹配的目标而误导训练. 本研究采用改进的MobileNeXt网络[13]替换MobileNet网络,在MobileNeXt的部分结构中基于通道分离与重排,改进沙漏结构并且添加小目标细节特征增强的坐标注意力机制. 在网络瓶颈层添加基于特征增强与重生成的上下文特征融合模块,以充分利用上下文信息弥补小目标自身特征不足的缺陷,同时也能充分利用本研究自适应数据增强方法生成新目标的背景和尺寸信息. 改进后的算法模型有效解决了MobileNet-SSD精度低的问题,并且能够满足移动端目标检测的实时性要求.
1. 基于消隐点性质和自适应增殖的数据增强方法
图 1

1.1. 行人可存在区域数据标注
为了使复制增强后的目标位置合理,需要区分图像中的行人可存在区域. 一般的目标检测数据集没有区域分割的标注,无法判断区域合理性,故需要对已有数据集进行标注,划分行人可存在区域. 对不同水平面上的行人可存在区域需要用不同标签标注,标注后的效果如图2所示.
图 2

1.2. 消隐点获取
为了使模型更好地利用数据增强后的目标上下文信息,避免复制增强后的目标错误尺寸影响分类器对目标种类的判断,需要计算原目标在图像中行人可存在区域内不同坐标处的大小,对目标进行复制粘贴并缩放,以符合其在图片中的位置.
图 3
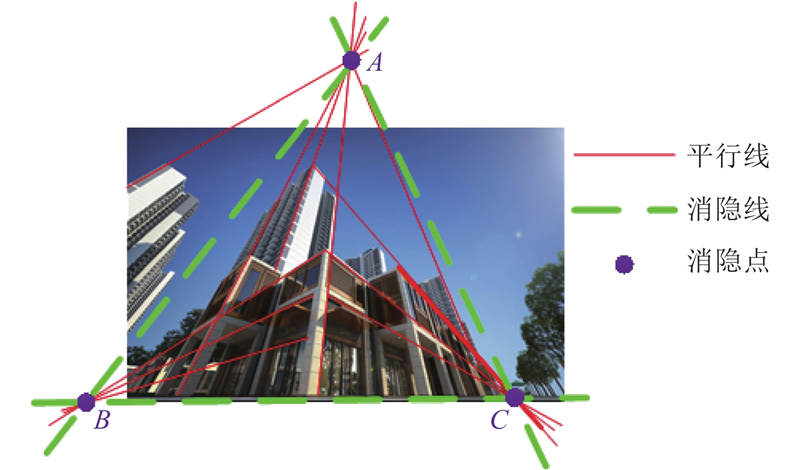
图 3 三消隐点模型中竖直方向消隐点A与水平方向消隐线BC
Fig.3 Vertical vanishing point A and horizontal vanishing line BC in the three vanishing points model
为了获得图像中的消隐点,采用基于极坐标的二线最小解集穷举的消隐点检测法[16]. 该方法的鲁棒性较好,能够应对消隐点数量不同的场景,同时时间复杂度较低,速度较快,穷举也能达成一定精度内的全局最优,其过程如下.
1)使用线段检测器(line segment detector,LSD)直线检测法,检测图像中的直线段.
2)构建极坐标网络. 将平面坐标根据光心与焦距转化成等效球体,建立以经纬度表示的极坐标,并以1°为间隔建立90×360的网格空间. 对于图像中的每个线段对
式中:
3)建立第1个消隐点的最小解集(minimal solution set,MSS),假设所有线段中有50%属于噪声,则第1个消隐点的选择迭代105次即可达到0.999 9的置信度[16]. 根据正交约束可知,第2个消隐点必定在第1个消隐点的正交圆上. 以1°为间隔在该圆上取360个点,将360个点作为每个第一消隐点对应的360种第2个消隐点可能. 第3个消隐点由前2个消隐点的向量正交即可获得.
4)对所有105×360种消隐点组合计算其网格权值的和,选择最高的一组,作为最终解. 根据每条线段与每个消隐点的角度偏差,可以对每条线段进行分类. 如图4所示为消隐点的检测效果,不同线型的线代表其归属于不同的消隐点.
图 4

1.3. 仿射变换矩阵
在获取图像的消隐点后,可以计算目标复制到新坐标的仿射变换矩阵,如图5所示.
图 5
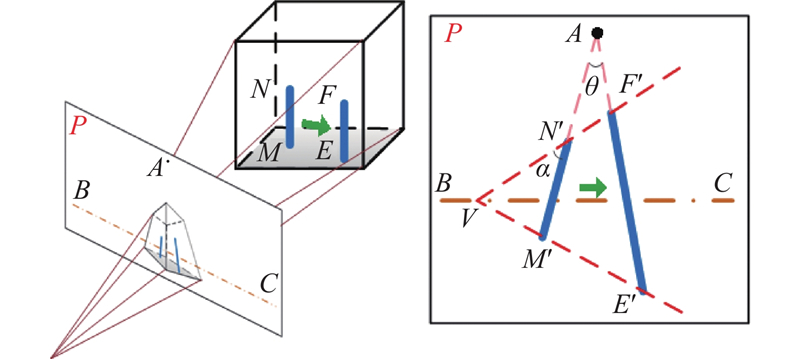
图 5 空间目标在平面上投影示意图
Fig.5 Schematic diagram of projection of space target on plane
已知空间中一条线段MN在平面P上的投影M'N',若是将MN水平移动至EF处,使其投影末端M'点落在E'处,为了获得移动后的投影另一端N'的位置,可在水平面P中找到该面的消隐线BC与竖直方向上的消隐点A. 使E'M'交BC于点V,VN'交AE'于点F',E'F'即为MN移动后在平面P的投影. 设M点坐标为
式中:rscale为待复制目标移动后的大小缩放比例.
根据以上变换规律与缩放比例,可以得出目标复制后的仿射变换矩阵. 对于目标内部,考虑到标记框的形状与图像投影关系无关,恒为矩形,且目标在图像中占比通常较小,故不考虑目标内部的相对变换. 对于任意目标,若底部中点坐标为
式中:
式中:
1.4. 目标映射坐标概率生成
为了能够生成更多小目标,并减少对原有目标特征的影响,新坐标被映射的概率应满足以下条件.
1) 新坐标被选择的概率随映射到该坐标上的新对象面积的减小而增大.
2) 若新坐标上映射的目标覆盖了其他目标,则该坐标被选择的概率应随覆盖面积的增长而快速下降.
为了满足以上条件,对于任意坐标点
式中:
对于
式中:T为阈值, β为系数. T、β的取值与数据集图像大小与图像中小目标尺寸占比有关.
在所使用的数据集中,自身面积占图像整体面积之比小于2%的目标占所有标注目标数量的75.51%,小于1%的占59.98%,小于0.5%的占43.99%,小于0.1%的占12.48%,可认为面积占比小于0.1%且边长不小于5个像素的目标为该数据集的合适小目标样本. 当数据集中取部分样本,输入尺寸为320×320时,对于多个T值和β值进行实验. 当T=0.01、β=10 000时,可以使得新生成的合适小目标样本最多.
对于
式中:
图 6
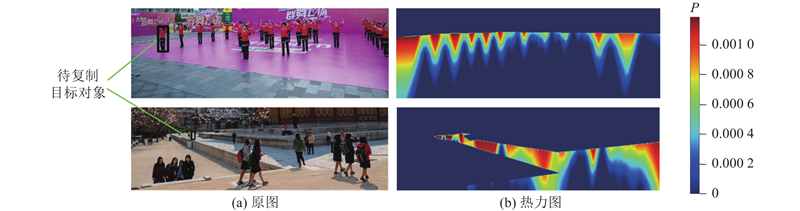
图 6 目标映射坐标概率的热力图
Fig.6 Thermodynamic diagram of target mapping coordinate probability
1.5. 增强图像生成
根据以上规则,对单个目标进行合理的增广. 对于图像中的多个目标,在选择需要复制的对象时,须选择未和其他目标重叠或重叠面积较小的目标. 对所有符合条件的目标进行至多2次复制粘贴,并在目标映射后使用高斯卷积核处理其边缘,使得新目标与背景过渡更加平滑. 最终生成的图像效果如图7所示,增强后的图像与原图比较增加了许多目标,其中大部分是小目标,并且新生成的目标基本没有对原有目标产生影响.
图 7

图 7 小目标行人数据增强的效果图
Fig.7 Rendering of data augmentation for small target pedestrians
2. 基于改进沙漏结构与上下文特征融合的网络结构
2.1. 小目标细节特征增强的坐标注意力机制
对于通道数为C,高与宽分别为H、W的输入特征图
图 8
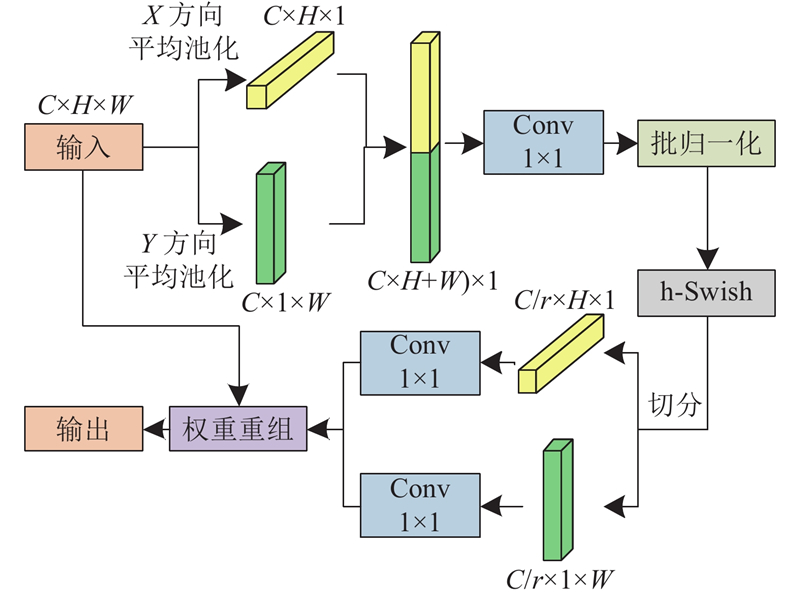
CA注意力机制本身的参数量较少,对于轻量化网络十分友好,CA注意力机制可以为重要特征分配较多的关注度,使得模型在骨干提取阶段可以更加关注轮廓细节信息,而这些特征都有利于小目标行人的检测. 在MobileNeXt的基础上添加坐标注意力机制,由于MobileNeXt本身具有20个卷积块,网络深度相比于大型网络还不成规模. 在所有带短接层的卷积块中添加坐标注意力机制,能很好地提升模型复杂度,一定程度上缓解了原网络欠拟合的问题.
2.2. 基于通道分离与重排的轻量化沙漏结构
图 9
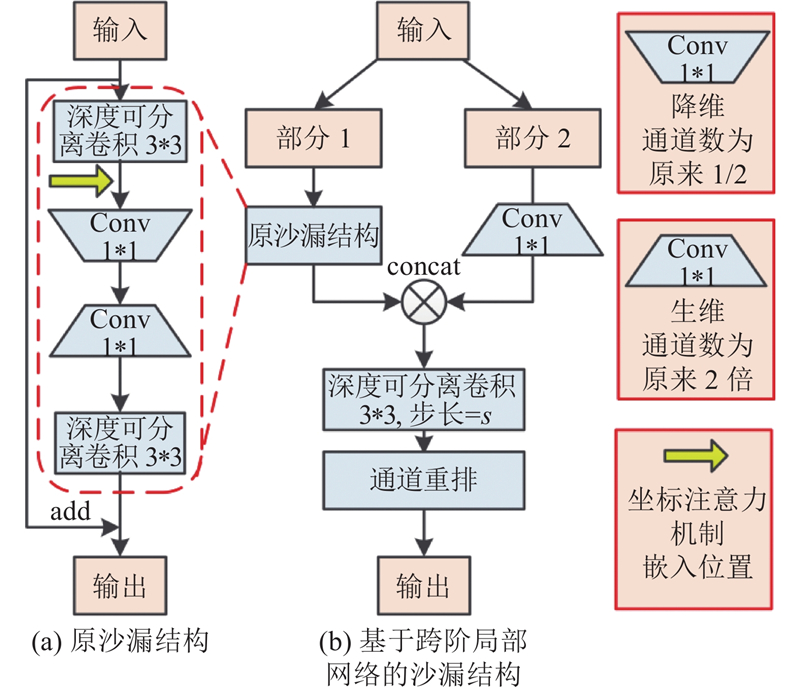
图 9 基于跨阶段局部网络的沙漏结构T-Sandglass
Fig.9 T-Sandglass structure based on cross stage local network
输入该结构的特征图,将其所有通道对半分割为part1和part2,分割后的两路是一路经过1
在改进的沙漏结构中,第1层3
2.3. 基于特征增强与重生成的上下文特征融合
小目标行人自身的特征信息少,通过上下文特征融合,可以利用背景和全局特征辅助模型训练[20]. 在原始的SSD骨干网络中,输出的2层特征与瓶颈输出的4层特征直接相连,6层特征之间以单路2倍放缩金字塔逐层传递信息,每层特征单独输出进行预测. 这种结构的预测网络感受野过于单一,不同大小的物体只能根据一层固定大小的检测层进行检测,模型无法从上下文判别背景信息. 单特征输出会导致瓶颈层对来自骨干层网络的语义信息的编码能力不足.
针对以上问题,为了尽可能使用较少的网络参数,获取较大的感受野以及可以有效融合特征瓶颈网络,设计了全局特征融合颈部网络(global feature fusion neck,GFF-neck),如图10所示. 该网络分为2个部分,分别为全局上下文特征增强部分与特征重生成部分. 在上下文特征增强网络中,设计单独的一层自适应池化层作用于最深层特征中,骨干网络输出二层不同大小的特征层
图 10
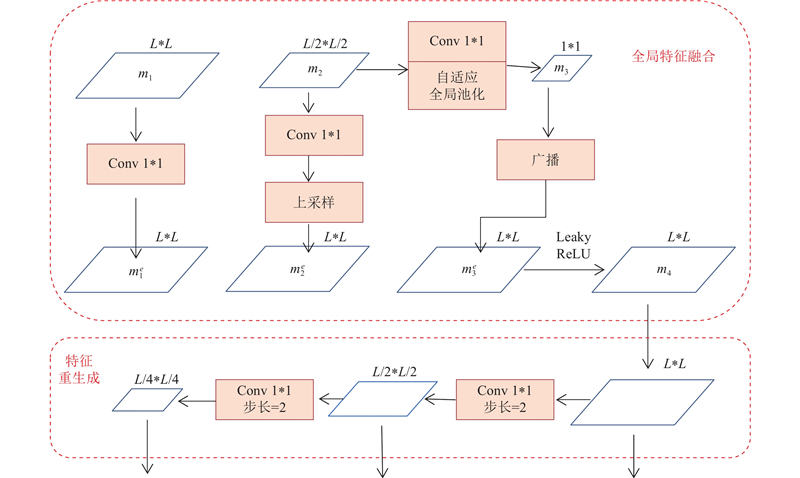
改进的瓶颈结构使用元素直接相加的方式,融合不同尺度的特征层. 与传统融合方法相比,融合时各尺度都以输入最大分辨率为依据,整体效率更高. 该网络对最后一个输入层进行全局自适应平均池化,输入的末尾层已经历过较多卷积层,感受信息范围跨越网络上下文,应用自适应平均池化可以在空间维度上总览全局,保留更多的前景以及背景信息,为小目标行人的检测识别提供额外信息. 特征重生成网络可以根据实际需求输出不同数量的特征图,同时全局上下文特征增强网络的输入也可以是多个不同尺度的特征. 重生成的特征包含更多细节信息,可以有效帮助网络对各类目标进行有效定位,从而有助于小目标的检测.
2.4. 改进骨干网络与上下文特征融合的整体网络结构
在骨干网络上使用MobileNeXt的基础上,添加T-Sandglass模块与坐标注意力机制,将改进后的骨干网络命名为MobileNeXt+. 搭配改进的GFF-neck作为瓶颈层,这种模型搭配方式可以使2个部分网络的学习潜力得到充分发挥,有利于梯度的平滑传播获得最佳的检测性能,整体网络模型结构如图11所示.
图 11
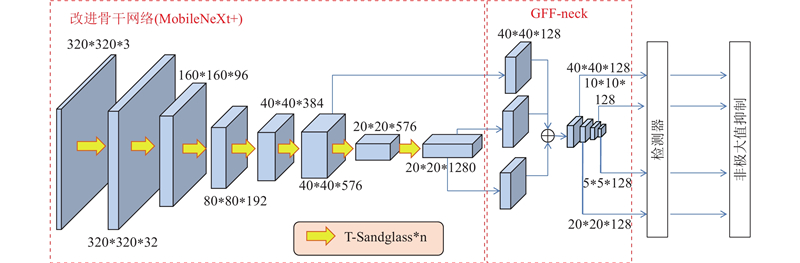
3. 实验及分析
3.1. 实验环境与数据集
实验硬件配置如下:Intel i5-9400CPU,英伟达RTX2070显卡,8G显存. 软件环境如下:Ubuntu18.04操作系统,python环境为python3.8,使用pytorch深度学习框架,版本为1.8.0. 针对行人检测任务有较多的公开数据集,选取众多数据集中检测难度较大、人群密集、包含多种尺度目标的WiderPerson数据集,其中包含5个类别,分别是行人、骑行者、遮挡人物、假人以及密集人群. 该数据集涉及公路、运动场、广场等多个常见的室外场景,包含的行人种类繁多,特别是有较多小目标人物以及遮挡目标人物,提取这些小目标行人的特征信息难度较大. 在训练过程中,共有8 000张图片用于训练,有1 000张图片用于测试. 数据集的部分图片如图12所示.
图 12

WiderPerson数据集的RGB 3个通道均值分别为131.64、120.22、115.58,方差分别为71.03、70.35、72.83,数据集输入端首先统计均值与方差,然后进行随机色彩抖动、随机翻转操作以增强模型泛化性能. 模型优化器选为SGD,初始学习率设置为0.015,初始动量设置为0.9,应用余弦退火学习策略. 在WiderPerson数据集中,对密集人群、遮挡人物的标注标准不一,对这些类的判断难以有效果,故在实验时仅对行人一类进行训练和推理.
3.2. 网络改进有效性实验
3.2.1. 骨干网络改进模块消融实验
表 1 输入尺寸为320时不同骨干网络性能
Tab.1
| 网络 | Np/106 | Flops/109 | v/(帧·s−1) | AP/% |
| VGG | 26.35 | 31.44 | 72.2 | 74.25 |
| MobileNet-V2 | 3.43 | 0.72 | 378.1 | 69.03 |
| MobileNeXt | 3.48 | 0.76 | 360.3 | 70.55 |
| MobileNeXt+CA | 3.82 | 0.76 | 326.5 | 70.63 |
| MobileNeXt+T-Sandglass | 3.46 | 0.73 | 369.4 | 70.92 |
| MobileNeXt+CA+T-Sandglass | 3.80 | 0.73 | 332.4 | 71.46 |
表 2 输入尺寸为512时不同骨干网络的性能
Tab.2
| 网络 | Np/106 | Flops/109 | v/(帧·s−1) | AP/% |
| VGG512 | 27.19 | 90.39 | 44.3 | 77.93 |
| MobileNet-V2 | 3.43 | 1.85 | 203.2 | 75.02 |
| MobileNeXt | 3.48 | 1.93 | 145.8 | 74.89 |
| MobileNeXt+CA | 3.82 | 1.94 | 142.6 | 75.13 |
| MobileNeXt+T-Sandglass | 3.46 | 1.90 | 177.8 | 75.52 |
| MobileNeXt+CA+T-Sandglass | 3.80 | 1.91 | 161.6 | 76.03 |
从表中对比结果可以看出,在相同的SSD检测器下,对MobileNeXt骨干网络单独添加坐标注意力后,当输入分辨率为320、512时,模型整体精度分别提升了0.08%和0.24%. 由于坐标注意力模型产生轻微的过拟合,导致在单独骨干网络中,添加坐标注意力机制对模型整体效果提升十分有限. 在MobileNeXt的基础上,改进原沙漏结构为T-Sandglass后,当输入分辨率为320、512时,模型整体精度分别提升了0.37%和0.63%,参数量与计算量均有所下降. 这说明跨阶段局部网络有效拓展梯度传播路径,并且通道重排将特征之间的信息进行充分交换,使得模型整体性能得到优化,另外改进的卷积块融合方式使得模型结构得到缩减.
在MobileNeXt基础上同时添加坐标注意力机制以及T-Sandglass结构,2种尺寸下的精度都高于单独添加其中一项或原版MobileNeXt. 这说明T-Sandglass结构提升了模型的可学习潜力,帮助注意力机制发挥了本身的优越性. 从整体来看,同时添加坐标注意力与T-Sandglass结构后相对于MobileNeXt参数量增加了约9%,2种分辨率输入时精度分别提升了0.91%、1.14%,在精度上有较大优势.
3.2.2. 瓶颈网络性能对比实验
表 3 2种瓶颈结构在不同骨干网络中的性能
Tab.3
| 骨干网络 | 颈部网络 | Np/106 | Flops/109 | v/(帧·s−1) | AP/% |
| ShuffleNet-V2 | SSD-neck | 1.70 | 0.71 | 123.5 | 68.21 |
| GFF-neck | 1.44 | 1.32 | 100.6 | 74.62 | |
| MobileNet-V2 | SSD-neck | 3.43 | 0.76 | 378.1 | 69.03 |
| GFF-neck | 3.04 | 2.95 | 151.0 | 76.31 | |
| MobileNeXt | SSD-neck | 3.48 | 0.76 | 360.3 | 70.55 |
| GFF-neck | 3.14 | 3.14 | 138.5 | 77.28 |
从表3可以看出,在使用改进的GFF-neck后,相对于原SSD颈部网络,3种不同的骨干网络基线精度分别提升了6.41%,7.28%以及6.73%. GFF-neck参数量与SSD-neck相比要略小,但计算量较大,导致模型计算速度下降较多,但是仍符合实时性要求. 总体来看,所提的GFF-neck瓶颈网络以一定的计算量代价换取巨大的精度增益,并且具有较低的参数量,因此以GFF-neck单独作为瓶颈网络可以为整体检测网络带来明显的性能提升.
3.2.3. 经典网络与改进整体网络对比
为了验证本研究改进的整体网络有效性,与不同的经典算法MobileNetV2-SSD、MobileNetV2-YOLOv3进行对比实验,检测结果如图13所示. 可以看出,原始MobileNetV2-SSD网络检测效果相对于其他2种网络稍显逊色,远景中有较多的小目标行人出现漏检的情况,部分中型大小目标并未检出. 改进网络与MobileNetV2-YOLOv3在检测效果上较为相近,对中大型目标基本没有出现漏检的情况,然而MobileNetV2-YOLOv3网络遗漏了一小部分小目标行人,且锚框的定位精度稍差. 从比较结果来看,所提算法具有一定的优势. 不同网络的精度如表4所示. 所提的整体网络(MobileNeXt+GFF-neck)与其他经典网络相比有极高的精度,与MobileNetV2-SSD网络相比提升了9.02%的AP,同时有最小的参数量,十分适合布置到移动端,检测速度也符合实时性要求,具有较大的优势.
图 13

图 13 经典网络与改进网络检测效果对比
Fig.13 Comparison of detection effect between classical network and improved network
表 4 经典网络与改进网络的检测效果
Tab.4
| 骨干网络 | 颈部网络 | 输入大小 | Np/106 | v/(帧·s−1) | AP/% |
| VGG | SSD-neck | 300×300 | 26.35 | 72.2 | 74.25 |
| MobileNetV2 | YOLOv3 | 320×320 | 22.02 | 140.3 | 74.07 |
| MobileNetV2 | SSD-neck | 320×320 | 3.43 | 378.1 | 69.03 |
| MobileNeXt+ | GFF-neck | 320×320 | 3.18 | 128.6 | 78.05 |
3.2.4. 其他公开数据集实验
为了进一步比较所提方法的性能,在目标检测常用公开数据集VOC中进行实验,结果如表5所示. 从实验结果可以看出,改进网络与其他经典网络相比,精度大幅度提高,MobileNetV2-SSD网络提升了8.64%的mAP,且参数量较少. 虽然速度有所减缓,但是仍满足实时性要求,证明所提网络具有较好的鲁棒性.
表 5 VOC数据集中不同网络的检测结果
Tab.5
| 骨干网络 | 颈部网络 | 输入大小 | Np/106 | v/(帧·s−1) | mAP/% |
| VGG | SSD-neck | 300×300 | 26.35 | 72.2 | 76.82 |
| MobileNetV2 | YOLOv3 | 320×320 | 22.02 | 140.3 | 76.13 |
| MobileNetV2 | SSD-neck | 320×320 | 3.43 | 378.1 | 71.64 |
| MobileNeXt+ | GFF-neck | 320×320 | 3.18 | 128.6 | 80.28 |
3.3. 数据增强有效性实验
3.3.1. 数据集实验
为了验证本研究数据增强效果的有效性,针对所使用的WiderPerson数据集,对其使用传统的随机复制增强与自适应增殖数据增强,并使用经典网络(MobileNetV2-SSD)与所改进网络(MobileNeXt+-GGF)进行训练,比较测试集的测试效果,结果如表6所示. 可以看出,在使用2个复制增强方法后,训练后的网络模型准确率都有上升. 当输入尺寸分别为320、512时,所提的自适应增殖数据增强方法的AP值在经典网络上与未使用复制增强比较提升了1.22%与1.87%,对比传统的随机复制增强提升了0.47%与0.84%. 在使用改进网络模型时,对于2种输入尺寸,自适应数据增殖方法AP值与未使用增殖方法的比较提升了1.56%和2.48%,与随机复制的比较提升了0.80%和1.12%. 所提的数据增强方法与图1所示的传统随机复制方法比较有一定的提升,并且输入尺寸较大时提升更明显,当应用小目标检测的改进网络时,其提升幅度更加明显.
表 6 小目标行人数据增强对识别精度的提升效果
Tab.6
| 输入大小 | 数据增强 | AP/% | |
| MobileNetV2-SSD | MobileNeXt+-GGF | ||
| 320×320 | 未使用复制 | 69.03 | 78.05 |
| 320×320 | 随机复制 | 69.78 | 78.81 |
| 320×320 | 自适应增殖 | 70.25 | 79.61 |
| 512×512 | 未使用复制 | 75.02 | 81.86 |
| 512×512 | 随机复制 | 76.05 | 83.32 |
| 512×512 | 自适应增殖 | 76.89 | 84.34 |
3.3.2. 其他数据集实验
为了验证所提数据增强方法的泛化性能,使用常用行人公开数据集CityPersons与Caltech进行实验. CityPersons包含2 975张训练集图片与500张验证集图片;Caltech数据集在set00-set05选择3 000张图片用于训练,并在set06-set08选择1 000张用于验证. 2个数据集的输入尺寸皆为512×512. 结果如表7所示.
表 7 CityPersons及CalTech进行数据增强的效果
Tab.7
| 数据集 | 数据增强 | AP/% |
| CityPersons | 未使用复制 | 45.04 |
| 随机复制 | 46.61 | |
| 自适应增殖 | 48.43 | |
| Caltech | 未使用复制 | 68.34 |
| 随机复制 | 69.52 | |
| 自适应增殖 | 71.13 |
3.4. 实际环境测试
图 14

图 14 实际环境的实验平台及测试
Fig.14 Experimental platform and testing of detection effect
图 15

图 15 实际环境下行人的检测效果
Fig.15 Detection effect of pedestrian under actual environment
表 8 实际环境下的检测准确率
Tab.8
| 网络模型 | AP/% |
| MobileNetV2-SSD | 81.13 |
| MobileNetV2-YOLOv3 | 85.53 |
| MobileNeXt+-GGF | 88.26 |
| MobileNeXt+-GGF(自适应数据增强) | 90.07 |
4. 结 语
本研究提出基于消隐点自适应增殖数据增强的上下文特征融合小目标行人检测方法. 采用数据增强方法,能够有效生成大小符合当前位置的目标,并能将大目标转化为小目标,有效解决了小目标自身特征不足的问题. 当输入尺寸为320和512时,该方法应用在WiderPerson数据集中的AP值分别提高了1.55%和2.48%. 在骨干网络中使用跨阶段局部网络优化了沙漏结构,并进行了轻量化处理,能够有效提升模型的可学习潜力,借助坐标注意力机制融合通道和空间信息,进一步提升模型精度. 本研究设计了全局特征融合颈部网络,极大地提高了整体网络精度. 改进的整体网络在WiderPerson数据集上的AP值与SSD-MobileNetV2网络比较提升了9.02%. 在公开数据集上,所提算法相对于经典算法也取得了最高的精度及较小的参数量. 在实际环境测试中,所提算法相比其他算法也能识别出更多的小目标行人,体现出了较强的鲁棒性.
参考文献
基于优化预测定位的单阶段目标检测算法
[J].
Single-stage object detection algorithm based on optimizing position prediction
[J].
改进的YOLOV3算法及其在小目标检测中的应用
[J].DOI:10.3788/AOS201939.0715004 [本文引用: 1]
Improved YOLOV3 algorithm and its application in small target detection
[J].DOI:10.3788/AOS201939.0715004 [本文引用: 1]
基于CBD-YOLOv3的小目标检测算法
[J].DOI:10.20009/j.cnki.21-1106/TP.2021-0183 [本文引用: 1]
Small object detection algorithm based on CBD-YOLOv3
[J].DOI:10.20009/j.cnki.21-1106/TP.2021-0183 [本文引用: 1]
基于轻量级MobileNet-SSD和MobileNetV2-DeeplabV3+的绝缘子故障识别方法
[J].
Fault identification method for high voltage power grid insulator based on lightweight mobileNet-SSD and mobileNetV2-DeeplabV3+ network
[J].
PTZ camera calibration based on improved DLT transformation model and vanishing point constraints
[J].
旋转框定位的多尺度再生物品目标检测算法
[J].
Multi-scale object detection algorithm for recycled objects based on rotating block positioning
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}