

随着网络通信技术的飞速发展,信息内容的接收与传播呈现高度对等状态,用户群体参与并驱动着产品形态设计发展,致使产品设计面临群决策问题[1]. 产品包含的感性意象集中反映用户的情感需求,并且意象的精准提取是设计创新的关键因素[2]. 稳定的用户决策体系尚未形成,导致决策过程存在较大的随机性,催生出大量离散复杂成分(决策意见). 得益于感性工学相关理论的发展,借助语义差分法、生理测量、深度学习等技术实现了产品意象的转译识别,使产品感性意象的提取及量化成为可能[3]. 其中语义差分法和生理测量技术可以完成产品意象的快速聚类,但它们高度依赖被试者,且实验设计前期需要大量人工成本投入;深度学习技术利用计算机编程手段,对数据进行自动化加工处理,有效拓展了分析数据的体量,提升了产品意象提取的泛化能力. 虽然在技术层面,基于算法的聚类研究将群决策问题进行降维处理,推动了产品意象研究发展,但仍存在以下不足:1) 意象的聚类局限于用户的浅层描述,特别是高频词汇极大地影响了聚类结果,对于用户的潜在关联需求描述不够深入;2) 简化了群体效应下时间维度对聚类结果的影响,针对设计需求的动态演化解释性不全面,难以实现用户需求转变结果的预测.
复杂网络模型具备小世界性[4]和无标度性[5]特征,可构建符合真实网络统计性质的演化模型. 精准的网络节点属性划分能够提高算法的社区发现质量[6]. 例如,杨延璞等[7]通过构建工业设计决策网络模型,模拟产品设计决策过程,析出噪声节点以缩减产品开发迭代历程;杨旭华等[8]提出无参数复杂网络社区发现算法,通过综合节点相似性和网络嵌入Node2Vec的方法实现自动化社区划分. 随着复杂网络相关研究的发展,大量的社区发现算法出现. 基于模块度优化的Louvain算法通迭代计算网络模块度增量,至增量收敛时完成网络结构社区划分,其聚类结果优于K均值聚类算法[9];Leiden算法通过节点的局部移动,利用非细化分区的方法建立模糊分区,加强了社区中节点与连边的关系,保证了社区内部的关联效果[10].重叠模块识别算法(overlapping community discriminated algorithm, OCDL)[11]通过计算连边相似度,获取最佳模块识别效果的同时,最大化地保留了网络聚类模块间的关联信息[12]. 链路预测为社区演变提供分析基础,如LSTM主题预测模型[13]. 在网络构建过程中,目标节点间具有明确的方向性(有向网络),用户评价属于模糊决策问题[14],不是统一的线性关系,可以采用链路预测的方法,解决仅以节点特征属性作为社区划分依据造成的节点关联信息缺失问题. 如刘琳岚等[15]提出基于网络表示学习的链路预测方法,并通过改进注意力机制循环神经网络模型实现整网链路预测. 因此,采用OCDL开展适用于产品评价的无向网络聚类研究,并融合用户信息交互的时序性,能够明晰用户需求动态转变关系,以加强设计师对用户群体特征的理解.
本研究引入复杂网络理论,结合社区子群聚类方法,提出复杂网络社区子群聚类模型,改进OCDL,并利用改进算法对用户评论特征词汇进行重叠社区检测,提升感性工学中意象聚类效果. 以用户评论时间序列为约束条件,通过多路径相似度计算结果开展网络链路预测,从而明确用户需求转化趋势,辅助设计师挖掘用户潜在需求.
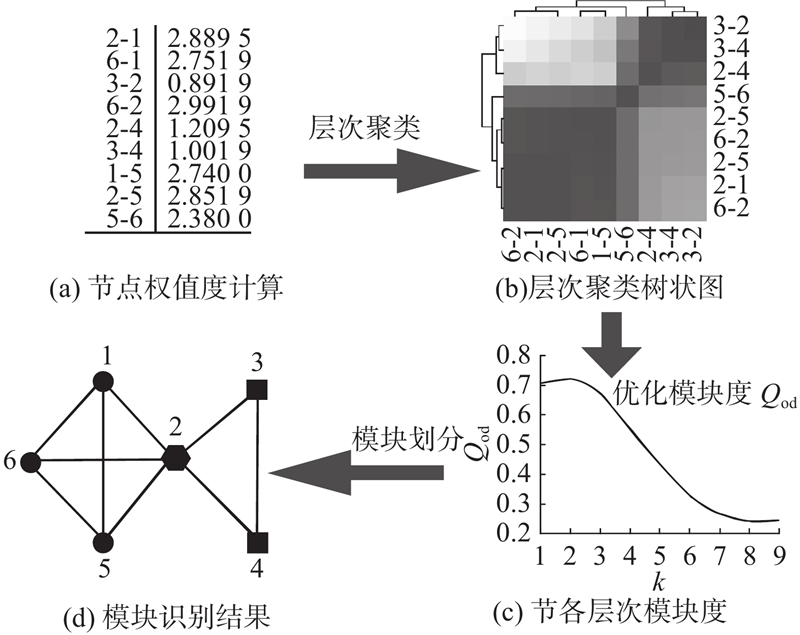
1. 用户社区子群需求聚类模型
如图1所示,基于复杂网络的用户社区子群需求聚类模型研究流程包含4个部分:1)确立目标产品研究对象,使用网络爬虫工具获取样本图文评论信息;依据词典方法对评论文本执行分词预处理,利用PageRank算法计算产品意象重要度并排序. 2)筛选同一词性下排名靠前的词汇构建特征词汇集,依据共现关系建立用户层面的无向加权网络;改进OCDL,利用改进算法计算用户社区集群相似度值;通过改进的模块度Qod检验网络模块划分;保留用户子群需求聚类结果. 3)对原始无向加权网络进行多路径节点链路预测,利用网络的拓扑结构及意见动力学分析,融合时间序列因素,开展用户子群需求聚类演化预测. 4)结合预测精度指标曲线下面积(area under curve, AUC)[16]及模块度Qod对预测结果进行验证,最终输出用户社区子群需求聚类演化结果.
图 1
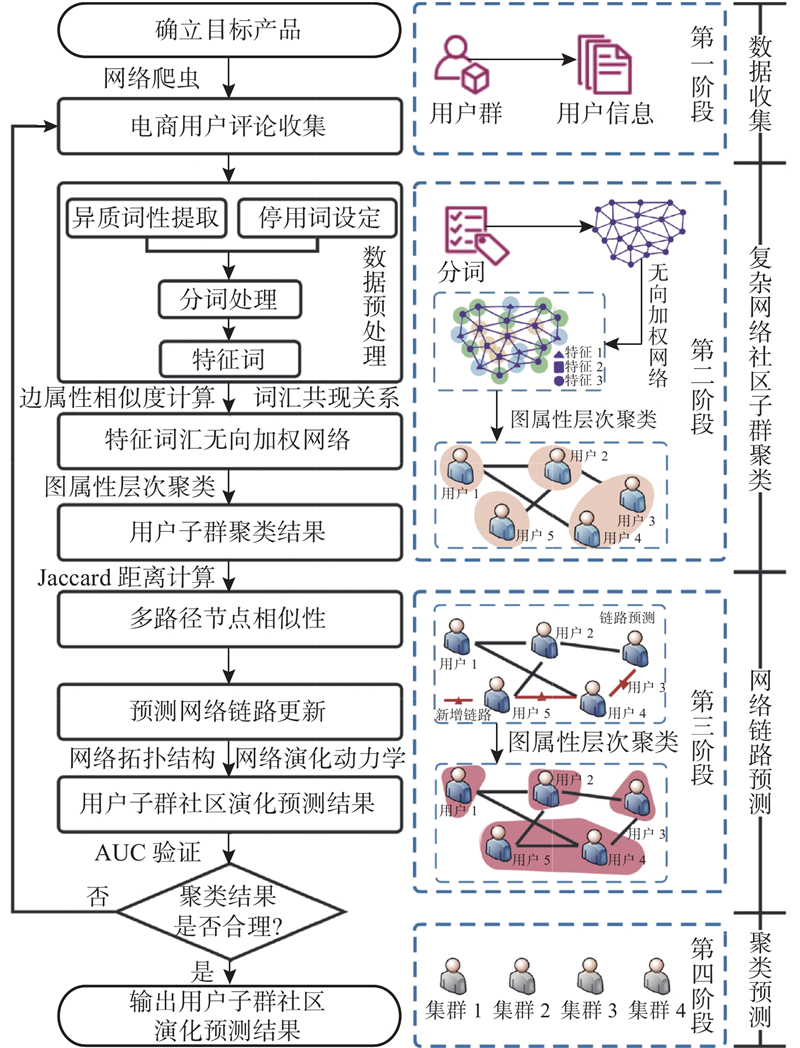
图 1 用户社区子群需求聚类模型的研究流程
Fig.1 Research process of user community subgroup demand clustering model based on complex networks
1.1. 用户评论数据获取及意象词汇甄选
图 2
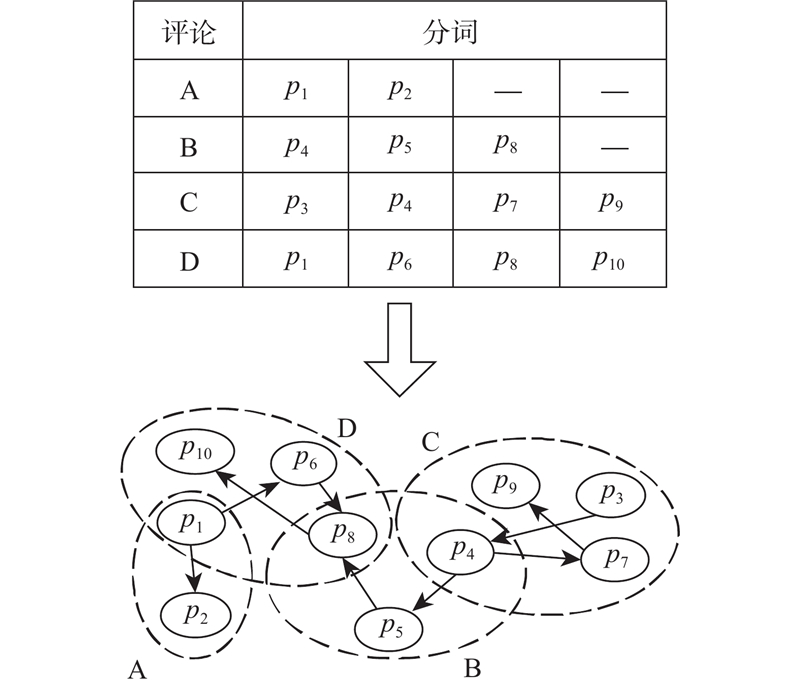
式中:X1-n为X1的第n条评论信息,S1为非空集. 全体用户评论信息域为
式中:Sm为第m个样本包含的用户评论信息. 在本研究中,取m的最大值为121,表示筛选的121款水壶样本. 用户在线评论具有非结构化文本属性(评论内容长短不一,且存在口语化表述特征),会产生大量离散化信息,基于词典的Jieba分词处理可以实现词性过滤,加速用户评论内容收敛. 为此,使用该方法对全体分析样本评论信息域S进行分词处理,处理结果存储于集合P,表示为
式中:i为分词处理结果编号,取i的最大值为14 657.
图 3
式中:S(pi)为分词i的重要度值,初始值设定为1;In(Vi)为指向分词i的邻接分词集合数量;Out(Vj)为分词j指向其他邻接分词集合的数量;d为阻尼系数,通常取d=0.8[22]. 迭代循环计算全体分词的PageRank值,满足收敛条件时,输出S(pi)作为词汇描述集的初始值,通过设定阈值筛选出用户需求的特征词汇集V={v1, v2, v3, ···, vz},其中z为筛选出的特征词汇个数,对应的PageRank值记作R={r1, r2, r3, ···, rz}.
1.2. 面向用户评论的需求聚类模型
传统K-Means算法可以高效、便捷地实现目标聚类,但随机选取初始化质心会产生限定用户的强局部收敛数据,因此初始质心的设定质量决定了聚类效果. 复杂网络社区利用网络连通图表示非线性的个体用户关系,通过图的网络指标属性量化用户聚类制约关系,聚类效果较K-Means更好,即利用网络中介中心性指标输出分类子群间协同因素,使用户大群体决策规律透明化.
图 4
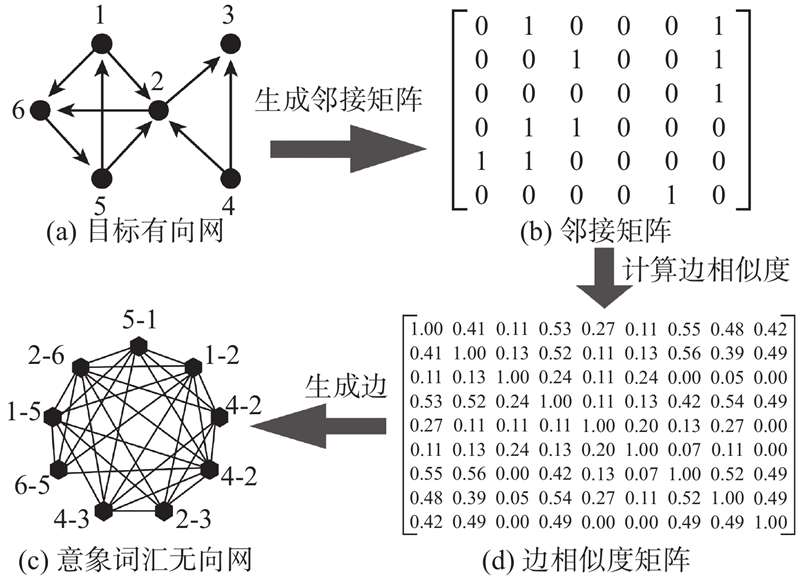
图 5
1) 构建目标有向网络. 有向网络G=(V, E),其中E为网络节点连边集合. 参考各用户评论分词结果排序建立有向评论链路, 组合全体用户评论链路构建目标有向网络,独立及重复节点不存在自身连接,仅记录出现频次.
2) 转换特征词汇无向网络. 依据现有节点数量,判别各节点间无向网络的连边条件,能够为网络转换提供限定. 虽然有向网络借助实体链路的方向性反映信息传播路径,例如航空网络、合作网络、蛋白质网络等,但用户信息往往不具备明确的线性指向关系,而是以相对复杂的社区属性共存. 可以通过计算已构建的目标有向网络边相似度,将其转换为符合社区属性的无向网络. 通过目标有向网络中节点的指向关系建立邻接矩阵:
保留网络连接数据.如果vi指向vj,则记rij=1;否则记为0. 网络中边的链路距离反映边的相似度. 通过目标有向网络中边的链路距离可以计算节点间的关联程度,即链路距离路径越短,共现占比越高,隶属于相同模块的概率越高,其聚类效果越理想. 如图6所示为网络中的边相似度关系计算示意图,边相似度函数值越高,表示用户特征词汇连接越紧密,表示为
图 6
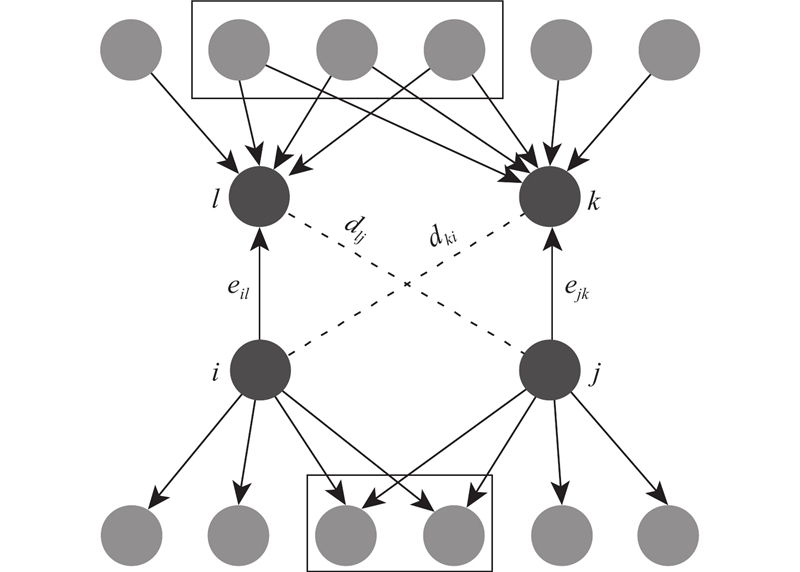
式中:Sn(eil, ejk)为边eil与边ejk的连接紧密度, d(eil, ejk)为eil到ejk的距离,
式中:
式中:ndia为网络直径内的节点数,即整体网络最短路径包含的词汇数;sij为词汇节点i到j的最短路径包含的词汇数量与直径的差值;dlj为词汇节点l与j的间距;
通过式(6)~(9)计算无向网络中节点的连边相似性,获得相应的用户特征词汇无向网络.
3) 更新无向网络中各节点权值. 在概率论中,Softmax函数通过对分类结果赋予概率值的方法,避免了仅以数据极大值进行线性判断的局限性,被广泛应用于非线性数据的标准化处理. 本研究将式(4)计算的各节点PageRank值作为网络中节点的权值,利用Softmax函数对PageRank数据集R进行标准化处理,表示为
式中:ri为节点vi的PageRank值,w(vi)为标准化处理后的节点权值. 通过连边相似性计算,用户特征词汇无向网络连边结构得以更新,结合新生成的连边计算更新节点权值.
式中:
4) 无向网络边权值计算. 网络连边强度反映节点之间的紧密关系,若2个词汇存在链路关系,则连边强度加1,统计全部链路强度信息.
式中:w(eij)为节点vi与vj连边的权值,f(eij)为节点vi与vj连边强度,
5) 检验社区集群划分信度. 模块度Q用于衡量传统无向网络的模块划分质量. 针对本研究提出的无向加权网络,在Q值计算基础上加入边权值计算,提升模块划分效果. 改进后的模块度判别函数表示为
式中:k为网络划分的模块数;
2. 聚类模型网络更新预测
2.1. 用户需求交互链路更新
节点链路关系的变更催生网络的动态演化特性,针对链路预测的相关研究为社区聚类演化提供了理论基础. 在加权社会网络链路预测中,通过多路径节点相似性(similarity based on transmission nodes of multipath, STNMP)[23]计算,增强量化相邻用户子群间的潜在关联,可以输出精准的更新链路,益于判断用户子群的发展趋势.
节点相似性是链路预测的重要度量指标之一. 相似度越高的节点间往往具有越大的连边可能性,其处于模块间重叠社区的概率也越高. 在网络节点路径的相似性计算中,为了解决数据的稀疏性问题,采用加权Jaccard距离[24]进行度量,
式中:lsim (vi, vj)为意象节点对(vi, vj)最短路径的边权相似度,Nij为连通vi与vj的节点集,N *(vi)为节点vi的邻居集. 网络链路包含传播路径信息. 考虑到非邻居节点间的链路具有复杂性和多样性,进行路径的相似度计算,以筛选符合网络更新的链路,避免过拟合状态下的无效链路预测. 依据式(14)计算边权相似度,
式中:SLk为由节点链路{vi, v1, v2, ···, vr, vj}组成的路径Lk(vi, vj)的路径相似性得分. 由于复杂的网络图具有较强的连通性,vi与vj间可能存在多条连接,路径k仅反映该路径对vi与vj的全局相似性的数值大小. 为了提高预测路线的精准性,须计算全局路线来确定预测链路,即进行多路径节点相似性计算. 将连接vi到vj的所有路径组成的集合记作L={l1, l2, ···, lp},计算多路径相似度
式中:ST(vi, vj)为连接vi与vj的所有路径对于节点(vi, vj)的相似性贡献总和. 利用式(15)、(16),可以得到总体路径与其中一条路径的相似性得分比值,以确立更新后的链路,实现用户社区子群需求聚类演化链路预测.
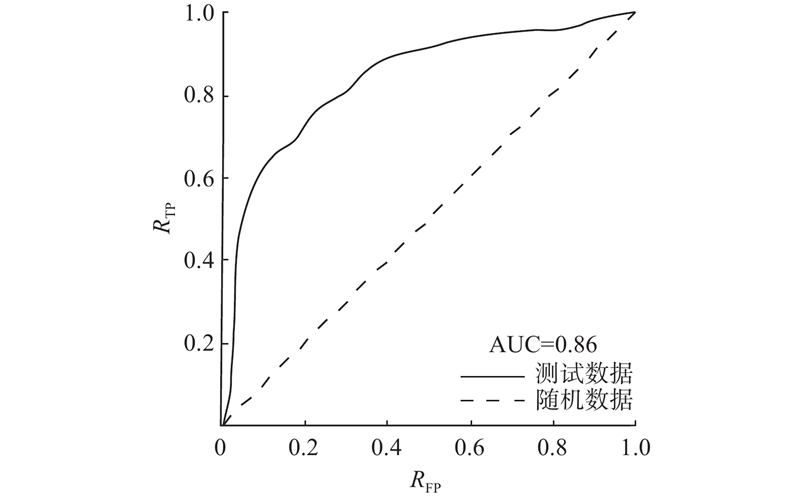
2.2. 链路精准度及网络社区更新结果验证
随机划分训练集和测试集的无监督评价模型验证方法能够快速地输出预测结果,但训练集在判别条件上受限于原有聚类主题,对更新网络预测适用性较差,即新连边概率难以验证AUC可以验证预测链路信度. 如果不考虑网络自身连接,n个节点的网络的边的上限集合U由
式中:
3. 实例验证
3.1. 水壶评论数据获取及特征词汇甄选
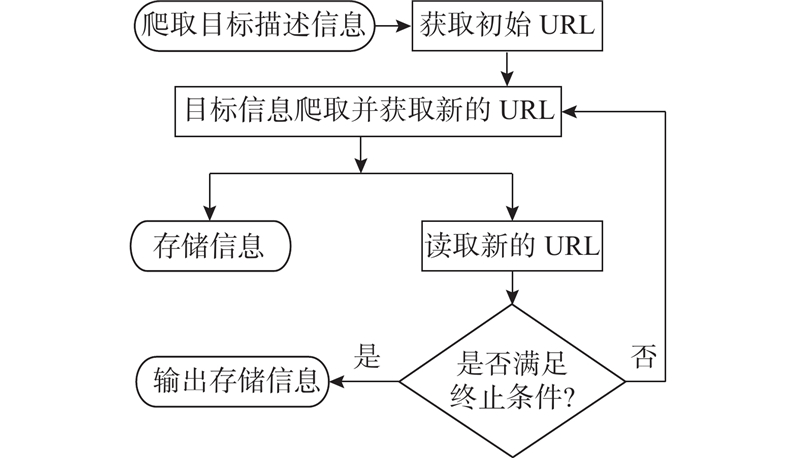
以水壶的用户在线评论为研究案例,详细阐述用户购买决策的聚类过程. 涉及水壶产品销售的线上平台较多,为了避免重复数据干扰实验结果,从淘宝、京东购物平台获取用户信息,选取上述电商平台的2022年度水壶销售数据. 采集内容包括评论文本、满意度打分、购买时间、产品款式、商品效果图等5类信息,涵盖影响用户购买行为发生的主要决策条件. 剔除重复产品后,甄选出121款水壶样本,保留17 811条有效评论,以“.CSV”格式存储表示用户需求信息,使用Jieba分词工具进行自动化分词处理,以构建用户需求词典. 部分商品效果图如图7所示. 部分爬取的原始用户评论数据包含评论文本、购买日期、样本编号m,如表1所示. 设定检索步长Max Len=5,部分评论分词处理结果如表2所示.
图 7

表 1 用户评论文本数据爬取结果(部分)
Tab.1
| 评论文本 | 购买日期 | m |
| 真的很好用,对商品非常满意,特别实用. | 2022-01-10 | 1 |
| 这个很小巧,烧水速度很快,几乎没啥声音自带的功能也很多. | 2022-03-01 | 1 |
| | | |
| 颜值挺高的,白色很耐看也很配居家使用,准备再入手一个放在办公室. | 2022-01-09 | 121 |
| 保温效果不错,容量的话稍微有点小,刚够自己一个人一早上的量. | 2022-05-02 | 121 |
表 2 用户评论文本分词结果(部分)
Tab.2
| 评论文本 | 分词结果 | m |
| 真的很好用,对商品非常满意, 特别实用. | 好用、满意、实用 | 1 |
| 这个很小巧,烧水速度很快,几乎没啥声音自带的功能也很多. | 养生壶、小巧、烧水、速度、功能 | 1 |
| | | |
| 颜值挺高的,白色很耐看也很配居家使用,准备再入手一个放在办公室 | 颜值、白色、居家、 办公室 | 121 |
| 保温效果不错,容量的话稍微有点小,刚够自己一个人一早上的量. | 保温、容量、小 | 121 |
为了筛选符合用户需求的特征词汇,结合语境对评论分词进行词性过滤,最终确定4类基本词性: 动词(Verb)、形容词或序数词(JJ)、形容词(Adj)、名词(Noun). 依据各评论中词汇出现次序的从属关系确立评论链路,逐条整合全部评论数据,构建各词性约束下的有向网络图,辅助进行下一步的特征词汇提取工作,如图8所示为所选4类词性的链路网络. 利用式(4)计算不同词性下的PageRank值,为了消除低频无意义词汇噪点,保留4类词性中排名前80%的词汇作为特征词汇,构建水壶用户评论描述特征集,部分筛选结果如表3所示. 依据表3构建用户描述特征集V,消除冗余词汇的同时保留了大量用户诉求信息,为构建特征词汇无向网络提供精准可靠的数据来源.
图 8

表 3 筛选后的特征词汇(部分)
Tab.3
| 词性 | 词汇数量 | 特征词汇 |
| 动词 (Verb) | 573 | 保温、购买、控制、清洗、···、 操作、优化、密封 |
| 形容词或序数词 (JJ) | 206 | 唯一、自动、实用、主要、···、 大、同样 |
| 形容词(Adj) | 306 | 方便、漂亮、简约、干净、···、 精致、透明、便捷 |
| 名词 (Noun) | 472 | 质量、功能、外观、速度、···、 价格、时尚、恒温 |
3.2. 水壶评论特征词汇无向加权网络模型
用户需求的量化受个体及环境的多维因素影响,须构建无向加权网络以明晰用户决策模式. 利用网络全局性及子群的收敛性消除单一属性划分导致的需求割裂问题. 通过设定检索步长为1,排除词汇自身连接,保留146个强链路关系节点,依据评论次序建立有向目标网络,利用式(5)计算得到146×146的邻接矩阵R,部分数据如表4所示. 将网络节点连边的相似度作为4类词性组建的意象词汇无向网络的连边条件,利用式(6)~(9)将特征词汇邻接矩阵转换为连边相似性矩阵,以反映连接强度. 相似度值较高的节点连边建立强连接,相似度值较低的建立弱连接,所建立的无向网络表征用户购买决策关联信息. 针对已确定的146个特征词汇,利用式(4)迭代计算输出收敛的PageRank值,使用式(10)对其进行标准化处理,部分数据如表5所示. 针对新构建的无向网络结构特征,利用式(11)更新节点权值,其结果如表6所示. 为了进一步量化网络信息关联属性,利用式(12)计算无向网络连边权值,保留146个特征词汇的1 000条连边信息,部分计算结果如表7所示,建立的评论特征词汇无向加权网络如图9所示.
表 4 特征词汇无向网络邻接矩阵(部分)
Tab.4
| V | v1 | v2 | v3 | v4 | v5 | v6 | ··· | v146 |
| v1 | 0 | 1 | 1 | 1 | 1 | 1 | ··· | 0 |
| v2 | 1 | 0 | 1 | 1 | 1 | 1 | ··· | 0 |
| | | | | | | | | |
| v146 | 0 | 0 | 0 | 0 | 0 | 0 | ··· | 0 |
表 5 特征词汇PageRank值及标准化(部分)
Tab.5
| V | R | w(vi) |
| v1 | 0.012 261 | 0.006 886 |
| v2 | 0.018 427 | 0.006 929 |
| v3 | 0.012 443 | 0.006 887 |
| v4 | 0.018 449 | 0.006 929 |
| | | |
| v146 | 0.004 226 | 0.006 831 |
表 6 节点权值更新结果(部分)
Tab.6
| V | W(vi) | V | W(vi) | |
| v1 | 2.301 981 | v4 | 4.324 156 | |
| v2 | 3.901 660 | | | |
| v3 | 1.609 552 | v146 | 0.288 848 |
表 7 节点连边权值(部分)
Tab.7
| E | w(eij) | E | w(eij) | |
| v1-v2 | 0.240 561 | v1-v6 | 0.138 447 | |
| v1-v3 | 0.061 063 | v1-v7 | 0.043 440 | |
| v1-v4 | 0.236 022 | | | |
| v1-v5 | 0.072 965 | v146-v138 | 0.046 154 |
图 9
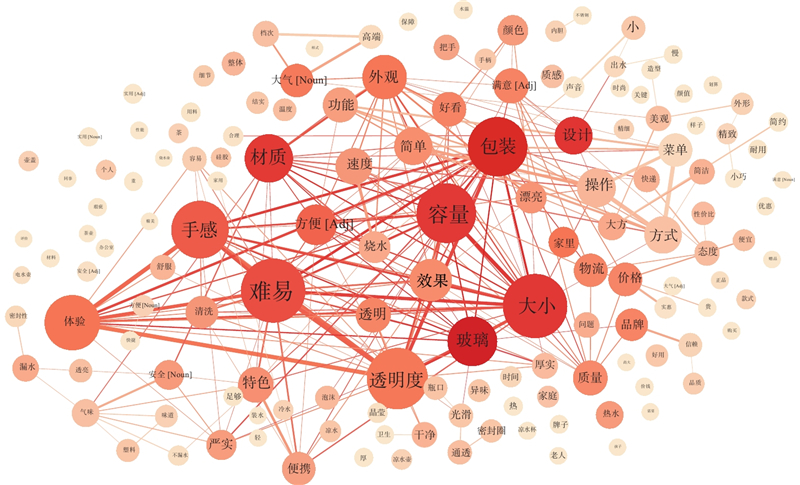
图 9 评论特征词汇无向加权网络
Fig.9 Undirected weighted network of comment feature vocabulary
基于图论的层次聚类能够实现评论特征词汇的快速聚类分析. 依据加权网络结构,结合最小生成树方法将146个特征词汇划分成7个评论社区,邀请5名工业设计专家和3名深度访谈用户对评论社区特征进行讨论,得出7类用户购买行为决策维度:产品质感、造型设计、服务性、实用性、操控性、安全性、体验感. 采用Jaccard距离计算连接强度. 其中社区内部采用实线连接,反映特征词汇间映射关系;社区间采用虚线连接,映射产品描述维度之间的制约关联条件,以此对完整的用户评论信息关系进行可视化描述. 使用最小生成树的方法,消除网络图中因连线数量过大导致聚类结果可读性差的问题. 无向加权网络特征词汇聚类结果如图10所示,用户购买行为发生的7类决策维度信息如表8所示.
图 10
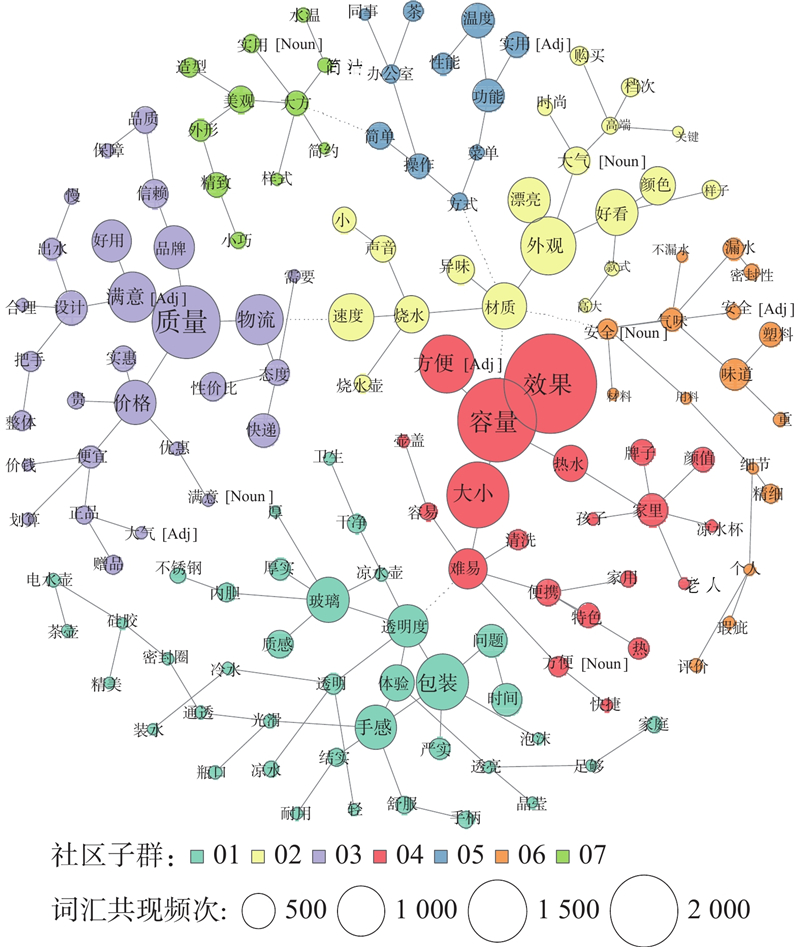
图 10 特征词汇无向加权网络聚类结果
Fig.10 Undirected weighted network clustering results of feature vocabulary
表 8 用户购买行为发生的决策维度
Tab.8
| 编号 | 用户购买行为 决策维度 | 特征词汇 |
| 01 | 产品质感(触觉) | 包装/透明度/手感/玻璃/质感/···/家 庭/通透 |
| 02 | 造型设计(视觉) | 材质/外观/款式/漂亮/大气/高端/···/ 时尚/样子 |
| 03 | 服务性(性价比) | 质量/物流/价格/品牌/品质/···/便宜/ 性价比 |
| 04 | 实用性 | 容量/效果/方便/难易/清洗/特色/···/ 快捷/热水 |
| 05 | 操控性 | 方式/菜单/操作/简单/温度/···/功能/ 性能 |
| 06 | 安全性 | 安全/气味/味道/塑料/密封性/用料/···/ 瑕疵/精细 |
| 07 | 体验感 | 大方/简洁/简约/美观/造型/精致/···/小 巧/样式 |
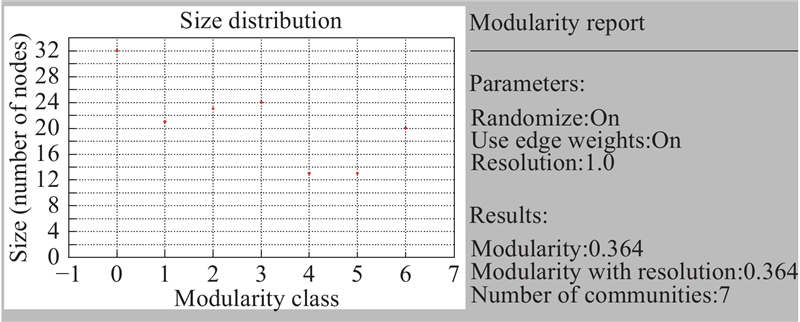
如图11所示,构建产品样本与决策维度映射关系,进行交叉汇总. 其中底部横坐标表示样本编号,顶部树状图反映各样本间树状聚类关系;右侧为7类决策维度,左侧表示决策维度树状聚类关系;图中色块纯度反映关联程度rda. 交叉汇总图可以辅助设计师筛选各决策维度的参考样本,以便他们进行方案优化设计. 以“操控性”为例,样本17在造型设计上可作为参考样本,借鉴其形态及要素特征开展产品形态设计能够极大满足用户“操控性”的需求. 利用式(13)计算网络社区划分的Qod值进行信度检验,其中模块1~7的内部边权值总和分别为4.417 533、0.964 068、9.773 802、5.658 013、1.543 370、4.207 739、3.153 114. 模块与模块间互连边权值的和如表9所示,计算得到Qod=0.72. 网络结构中模块度Q的计算结果截图如图12所示,其中解析度反映聚类数量的精准度,取值越接近1,结果越理想. 模块度反映聚类效果,当Q∈[0.3,0.7]时,认为达到理想的网络聚类效果[25]. 本实验设定解析度为1.0,Q=0.36,聚类结果为7类,与所构建的无向加权网络聚类结果一致. 采用改进后的OCDL,计算得Qod=0.72,相比模块度Q=0.36,检验数值精度增加0.36,能够较好地提升用户特征词汇的聚类效果.
图 11
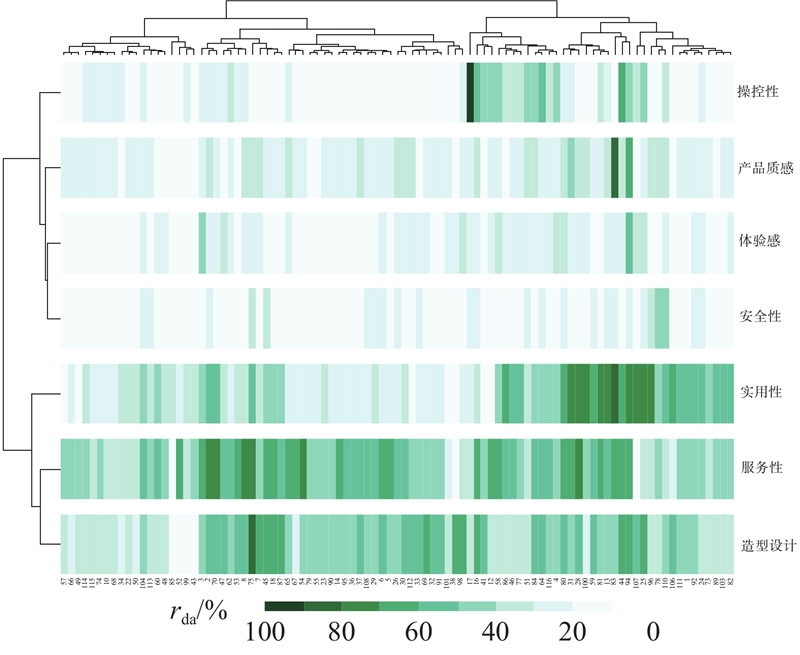
表 9 模块间互连边权值
Tab.9
| 模块编号 | ψij | ||||||
| 模块1 | 模块2 | 模块3 | 模块4 | 模块5 | 模块6 | 模块7 | |
| 模块1 | — | 0.016 668 619 | 0.086 354 438 | 0.069 068 441 | 0.016 313 308 | 0.087 846 043 | 0.006 154 762 |
| 模块2 | 0.016 668 619 | — | 0.013 357 219 | 0.004 687 216 | 0.006 308 408 | 0.016 572 784 | 0.022 698 338 |
| 模块3 | 0.086 354 438 | 0.013 357 219 | — | 0254 936 1 | 0.047 531 501 | 0.039 625 591 | 0.013 705 564 |
| 模块4 | 0.069 068 441 | 0.004 687 216 | 0.254 936 1 | — | 0.031 339 468 | 0.101 056 076 | 0.038 998 219 |
| 模块5 | 0.016 313 308 | 0.006 308 408 | 0.047 531 501 | 0.031 339 468 | — | 0.019 495 627 | 0.003 386 003 |
| 模块6 | 0.087 846 043 | 0.016 572 784 | 0.039 625 591 | 0.101 056 076 | 0.019 495 627 | — | 0.046 899 991 |
| 模块7 | 0.006 154 762 | 0.022 698 338 | 0.013 705 564 | 0.038 998 219 | 0.003 386 003 | 0.046 899 991 | — |
图 12
3.3. 水壶用户子群演化聚类结果
表 10 新增链路权值(部分)
Tab.10
| E* | w(eij) | E* | w(eij) | |
| v1-v24 | 0.05 | v2-v72 | 0.09 | |
| v1-v100 | 0.43 | v2-v102 | 0.08 | |
| v1-v107 | 0.24 | | | |
| v2-v9 | 0.07 | v130-v134 | 0.03 |
图 13

图 13 特征词汇无向加权预测网络聚类结果
Fig.13 Undirected weighted prediction network clustering results of feature vocabulary
表 11 用户购买行为决策维度的预测结果
Tab.11
| 编号 | 用户购买行为决策维度 | 特征词汇 |
| 01 | 产品质感(触觉) | 手感/透明度/包装/质量/ 买/···/密封/干净 |
| 02 | 实用性 | 大小/容量/方便/烧水/ 购买/···/实用/声音 |
| 03 | 衍生功能 | 保温/效果/时间/温度/ 手机/···/蓝牙/手机 |
| 04 | 造型设计(视觉) | 外观/好看/做工/材质/ 功能/···/精致/大气 |
| 05 | 体验感 | 便携/特色/设计/安装/ 过滤/···/塑料/把手 |
3.4. 水壶用户社区子群需求演化结果对比验证
图 14
4. 讨 论
由实验结果可知,改进后的OCDL对无向加权网络具有更精准的模块识别能力. 原因是传统模块度Q反映网络划分后的模块集团边占比问题,忽略了网络边权值信息,仅以连边数量比值验证聚类效果. 本研究构建的评论特征词汇无向加权网络隶属于社会网络,考虑到将用户评论特征词汇作为网络节点会导致连边数量繁多且存在重复连边的情况,若采用无权模块
在自然语言处理的研究领域,无监督的机器学习借助特征词汇的上下文关系,开展主题的提取和聚类,揭示分析文本内的潜在变量及隐藏结构. 其中基于潜在狄利克雷分布(latent Dirichlet allocation, LDA)的主题模型,无论是对文本潜在主题的解释层面还是数据运算能力方面,都具有优异的处理效果[27]. 为了验证特征词汇无向加权网络聚类结果的可靠性,使用LDA主题模型对用户购买行为决策维度聚类结果进行一致性检验,LDA主题模型聚类结果如图15所示. 图中,NT为主题聚类数量,η为困惑度值,η越小聚类效果越理想;圆圈面积反映模块成分占比,深色柱状条代表选中模块的主要特征词统计结果;利用“手肘图”方法确定当NT=7时,主题聚类效果最佳,与特征词汇无向加权网络聚类结果在主题数量上具有一致性. 对比分析表8中的各决策维度与LDA各聚类主题发现,二者存在大量相近的特征词汇,表明改进的OCDL可以针对用户购买行为输出较为准确的决策维度.
图 15
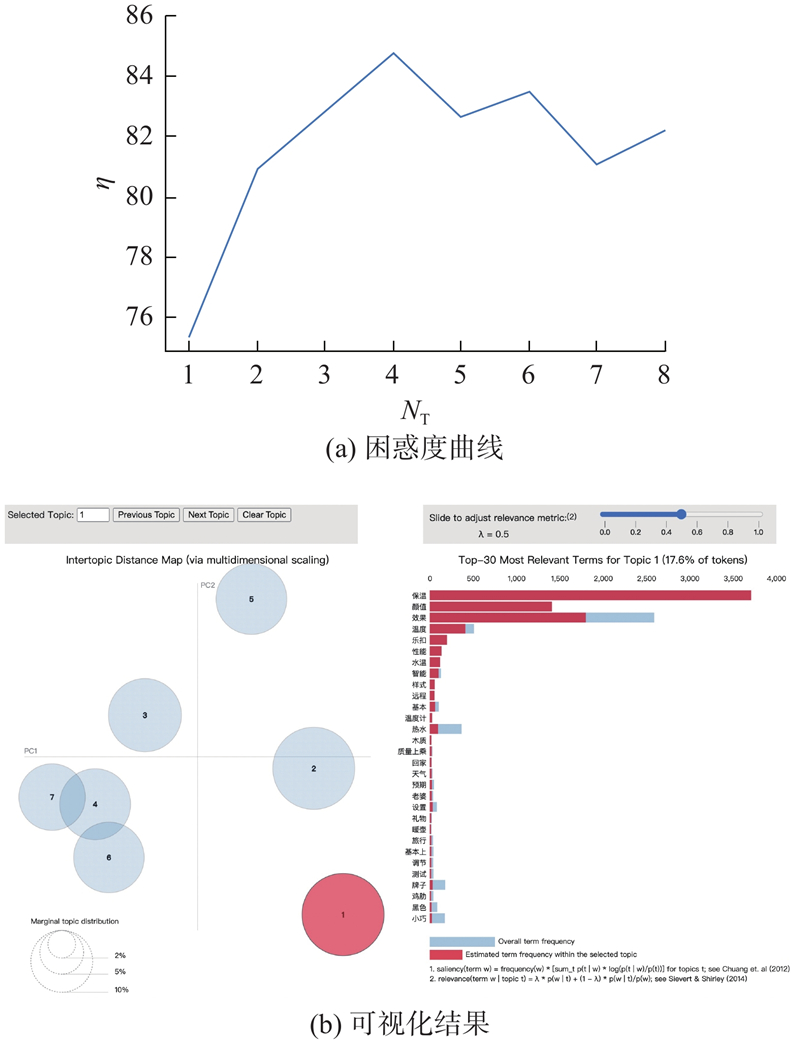
图 15 潜在狄利克雷分布主题模型验证决策维度聚类结果
Fig.15 Latent Dirichlet allocation topic model verifies decision dimension clustering results
特征词汇无向加权网络的Q=0.36,Qod=0.72,二者均高于预测网络的Q=0.33,Qod=0.69. 分析导致预测数据偏低的原因:作为检验社区聚类效果的重要衡量指标之一,模块度的数值越大,网络中社区结构越趋于“内紧外松”. 本研究对现有节点基于网络边相似性进行链路预测,侧重挖掘由群体间信息交流导致聚类主题发生变化的因素,随着用户的意见交换,预测网络“内紧”结构将会削弱,产生新的网络结构,即用户群将析出潜在需求组成新的购买决策维度. 因此预测网络中Q、Qod是对新网络社区聚类效果的检验,不涉及原始网络,其Q、Qod在数值上的降低不代表预测网络聚类效果低于特征词汇无向加权网络聚类效果.
网络图结构包含的信息数据具有明确的权值关系,可以反映各聚类结果间的非线性关系,研究结果有助于设计师多角度全面把握具有突出贡献的特征词汇. 例如,由图10中“造型设计(视觉)”聚类结果可知,在“造型设计(视觉)”购买决策维度的宏观层面,用户的直接需求集中于产品的“外观、颜色、材质”层面,设计师应着力于产品外观样式的变化,以满足用户对“大气”“高端”“时尚”等感性词汇的理解,引导购买决策行为的发生;“造型设计(视觉)”购买决策维度同时以“材质”为连接枢纽,综合产品“材质—操作方式”“材质—安全”“材质—容量”的协同价值,分别与“操控性”“安全性”“实用性”购买决策之间存在跨维度微观关联.本研究提出的加权网络链路预测,是对实际购买用户之间的需求信息传播的模拟,目的是探究当下用户需求信息的聚类效果以及需求发展趋势. 与现有方法对比,本研究方法具备丰富的数据基数,网络连边结构保留了潜在需求关联特性, 为需求动态发展提供预测. 例如,由图10、13可知,用户购买行为决策维度由初始的7类转化为5类,其中产品质感、造型设计、实用性、体验感等4个购买决策维度得以延续,属于相对稳定的需求,产品的服务性(性价比)、操控性、安全性决策维度转变为衍生功能需求,属于待开发的需求. 未来在开展水壶设计时,可以在优化4个稳定需求的基础上,将衍生功能维度作为创新设计的切入点,例如开发智能温控、手机交互及智慧监测等功能,推进产品的智能化设计.
STNMP算法受初始节点数量限制,本研究主要针对现有网络的新、旧链路的产生与消失进行集群聚类的动态预测. 考虑流行元素对产品造型设计的时效性价值,其延续周期较短,不利于用户深层次需求的转化预测. 因此,本研究在构建预测网络时未加入新节点,面向用户短期购买决策维度的预测效果有待进一步验证. 在用户需求交互链路更新中,对于用户评论按月份建立时间序列集合D={D1, D2, ···, Dn},其中Dn为第n月份用户评论中所包含的特征词汇. 利用式(14)~(16)计算时序集不同时间段的各节点相似度,并对计算结果进行均值化处理,以获取完整的链路更新结果,避免主观设定预测时序范围造成的用户显性需求集中表达而隐性需求表达不完全的问题. 为了精准判断预测结果的有效期限,使用爬虫工具重新爬取2018—2021年的水壶购买评价信息,并按季度存储. 以1—3月、1—6月、1—9月、1—12月作为时间跨度,利用LDA主题模型计算不同时间跨度内的用户需求数量,用户需求预测结果有效期检验结果如表12所示. 表中,NTP为预测网络主题聚类数量。当时间跨度为1年(1—12月)时,除2020年实际需求聚类数量和预测数量存在差异外,其余结果均一致,整体预测效果具有良好的解释性. 线上评论数据还受商业环境影响,伪用户评论会对聚类结果造成严重影响,甚至使用户需求预测失去价值. 前期甄选数据的真实性制约着聚类模型的可靠性,本研究对伪用户评论的判别主要采用一致性文本、指定词汇、人工判别相结合的方法. 随着数据量的增加,今后的研究将开发自动化数据处理程序,以减轻工作任务并提升数据信度.
表 12 用户需求预测结果有效期检验结果
Tab.12
| 年度 | 时间跨度 | NT | NTP |
| 2022 | 1—3月 | 7 | 4 |
| 1—6月 | 5 | 7 | |
| 1—9月 | 6 | 5 | |
| 1—12月 | — | — | |
| 2021 | 1—3月 | 7 | 4 |
| 1—6月 | 5 | 3 | |
| 1—9月 | 6 | 3 | |
| 1—12月 | 4 | 4 | |
| 2020 | 1—3月 | 3 | 6 |
| 1—6月 | 7 | 5 | |
| 1—9月 | 6 | 8 | |
| 1—12月 | 7 | 6 | |
| 2019 | 1—3月 | 4 | 6 |
| 1—6月 | 6 | 8 | |
| 1—9月 | 5 | 6 | |
| 1—12月 | 5 | 5 | |
| 2018 | 1—3月 | 5 | — |
| 1—6月 | 6 | — | |
| 1—9月 | 6 | — | |
| 1—12月 | 4 | — |
5. 结 语
本研究针对用户购买行为决策的多指标非线性融合特质,借助复杂网络重叠模块识别和链路预测相关理论,模拟用户固有特性与群体效应相互作用推动设计需求动态变化的规律,实现用户社区聚类结果输出及其动态演变结果预测. 1)利用评论大数据信息构建无向加权网络,确定用户购买行为决策维度,提升了决策维度的一致性和聚类模型的泛化能力. 2)利用网络多路径相似度计算,更新网络链路结构,输出用户决策维度动态调整结果,为明晰用户需求转变提供关键特征词汇量化数据,辅助设计师精准判断市场需求. 3)通过案例研究验证预测预网络的精度,输出用户决策转变结果,为用户需求预测提供新的思路及研究方法. 下一步研究工作:1)本研究分别利用Matlab和Gephi软件进行基于图属性的层次聚类和网络参数计算,后续将整合开发操作环境,优化操作界面并内嵌数据转换模块,提升数据处理的连贯性与可读性,通过参数调节快速输出可视化结果. 2)在用户子群演化聚类结果预测中,借助现有节点调整新旧连边,更新网络结构,模拟用户需求的变化发展;实际决策过程受井喷流行元素影响,须进一步结合时效性热点验证短期消费决策预测维度的信度.
参考文献
社会网络环境下基于群体一致性的概率语言多属性大群体决策方法
[J].
Probabilistic language multi-attribute large group decision-making method based on group consistency in social network analysis
[J].
产品设计中的用户隐性知识研究现状与进展
[J].DOI:10.13196/j.cims.2010.04.3.luoshj.009 [本文引用: 1]
Statues and progress of research on users’ tacit knowledge in product design
[J].DOI:10.13196/j.cims.2010.04.3.luoshj.009 [本文引用: 1]
基于改进加权协同过滤的集群用户黑箱个性意象预测
[J].
Prediction of black-box personality image of cluster users based on improved weighted collaborative filtering
[J].
Collective dynamics of ‘small-world’ networks
[J].
Emergence of scaling in random networks
[J].DOI:10.1126/science.286.5439.509 [本文引用: 1]
一种基于节点稳定性和邻域相似性的社区发现算法
[J].DOI:10.11896/jsjkx.220400146 [本文引用: 1]
Community detection algorithm based on node stability and neighbor similarity
[J].DOI:10.11896/jsjkx.220400146 [本文引用: 1]
工业设计决策网络构建及其动态演化仿真
[J].
Construction of industrial design decision-making network and its dynamic evolution simulation
[J].
基于节点相似性和网络嵌入的复杂网络社区发现算法
[J].DOI:10.11896/jsjkx.210200009 [本文引用: 1]
Complex network community detection algorithm based on node similarity and network embedding
[J].DOI:10.11896/jsjkx.210200009 [本文引用: 1]
Louvain算法与K均值聚类算法的比较研究
[J].DOI:10.3969/j.issn.1001-4268.2022.05.010 [本文引用: 1]
A comparative study of Louvain algorithm and K-means clustering algorithm
[J].DOI:10.3969/j.issn.1001-4268.2022.05.010 [本文引用: 1]
基于突变—融合视角的颠覆性技术主题演化研究
[J].DOI:10.3969/j.issn.1003-2053.2022.12.003 [本文引用: 1]
Topic evolution research of disruptive technology based on mutation and fusion perspective
[J].DOI:10.3969/j.issn.1003-2053.2022.12.003 [本文引用: 1]
Detecting the overlapping and hierarchical community structure in complex networks
[J].DOI:10.1088/1367-2630/11/3/033015 [本文引用: 1]
A survey of density based clustering algorithms
[J].
基于LSTM模型与加权链路预测的学科新兴主题成长性识别研究
[J].DOI:10.3969/j.issn.1008-0821.2022.09.004 [本文引用: 1]
Identifying growth of discipline topics using LSTM and weighted link prediction
[J].DOI:10.3969/j.issn.1008-0821.2022.09.004 [本文引用: 1]
基于犹豫模糊语言术语集和粒子群优化算法的产品造型设计感性评价方法
[J].
Kansei evaluation method of product form design based on hesitant fuzzy linguistic term sets and particle swarm optimization
[J].
基于网络表示学习的机会网络链路预测
[J].
Link prediction in opportunistic networks based on network representation learning
[J].
半监督AUC优化的Boosting算法及理论
[J].DOI:10.11897/SP.J.1016.2022.01598 [本文引用: 1]
Boosting-based semi-supervised AUC optimization: theory and algorithm
[J].DOI:10.11897/SP.J.1016.2022.01598 [本文引用: 1]
基于Kano模型的B2C电商平台信息服务功能研究
[J].DOI:10.3969/j.issn.1008-0821.2021.04.004 [本文引用: 1]
Research on information service function of B2C E-commerce platform based on Kano model
[J].DOI:10.3969/j.issn.1008-0821.2021.04.004 [本文引用: 1]
基于群体智能挖掘的个性化商品评论呈现方法
[J].
CrowdReview: personalized product review presentation based on crowd intelligence mining
[J].
用户评论数据驱动的产品优化设计方法
[J].
User review data-driven product optimization design method
[J].
网络爬虫的演变及其合法性限定
[J].
Evolution of web crawling and conditions for its legitimacy
[J].
Signed pageRank on online rating systems
[J].DOI:10.1007/s11424-021-0124-2 [本文引用: 1]
基于限定中文自然语言需求的SysML模型自动生成方法
[J].DOI:10.7544/issn1000-1239.2021.20200757 [本文引用: 1]
An automated approach to generate SysML models from restricted natural language requirements in chinese
[J].DOI:10.7544/issn1000-1239.2021.20200757 [本文引用: 1]
加权网络中基于多路径节点相似性的链接预测
[J].
Link prediction based on similarity of nodes of multipath in weighted social networks
[J].
稀疏数据下基于用户偏好的协同过滤算法
[J].
Collaborative filtering algorithm based on user preference in sparse data
[J].
多节点多关系的混合网络社团划分研究综述
[J].DOI:10.13266/j.issn.0252-3116.2021.19.014 [本文引用: 1]
A review of community detection in hybrid networks with multiple nodes and multiple relationships
[J].DOI:10.13266/j.issn.0252-3116.2021.19.014 [本文引用: 1]
基于异质模体特征的社交网络链路预测
[J].DOI:10.12178/1001-0548.2021181 [本文引用: 1]
Link prediction by hetergeneous motifs in social networks
[J].DOI:10.12178/1001-0548.2021181 [本文引用: 1]
基于LDA主题模型的社交媒体倦怠研究: 以微信为例
[J].DOI:10.13833/j.issn.1007-7634.2019.12.012 [本文引用: 1]
Social media fatigue research based on LDA topic model: take WeChat as an example
[J].DOI:10.13833/j.issn.1007-7634.2019.12.012 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}