[1]
张德祥, 王俊, 袁培成 基于注意力机制的多尺度全场景监控目标检测方法
[J]. 电子与信息学报 , 2022 , 44 (9 ): 3249 - 3257
[本文引用: 1]
ZHANG De-xiang, WANG Jun, YUAN Pei-cheng Object detection method for multi-scale full-scene surveillance based on attention mechanism
[J]. Journal of Electronics and Information Technology , 2022 , 44 (9 ): 3249 - 3257
[本文引用: 1]
[2]
袁益琴, 何国金, 王桂周, 等 背景差分与帧间差分相融合的遥感卫星视频运动车辆检测方法
[J]. 中国科学院大学学报 , 2018 , 35 (1 ): 50 - 58
[本文引用: 1]
YUAN Yi-qin, HE Guo-jin, WANG Gui-zhou, et al A background subtraction and frame subtraction combined method for moving vehicle detection in satellite video data
[J]. Journal of University of Chinese Academy of Sciences , 2018 , 35 (1 ): 50 - 58
[本文引用: 1]
[4]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580-587.
[本文引用: 1]
[5]
GIRSHICK R. Fast R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440-1448.
[本文引用: 1]
[6]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[7]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 7263-7271.
[本文引用: 1]
[8]
王立辉, 杨贤昭, 刘惠康, 等 基于GhostNet与注意力机制的行人检测跟踪算法
[J]. 数据采集与处理 , 2022 , 37 (1 ): 108 - 121
DOI:10.16337/j.1004-9037.2022.01.009
[本文引用: 1]
WANG Li-hui, YANG Xian-zhao, LIU Hui-kang, et al Pedestrian detection and tracking algorithm based on GhostNet and attention mechanism
[J]. Journal of Data Acquisition and Processing , 2022 , 37 (1 ): 108 - 121
DOI:10.16337/j.1004-9037.2022.01.009
[本文引用: 1]
[9]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . [S.l.]: Springer, 2018: 3-19.
[本文引用: 1]
[10]
ZHANG H, ZU K, LU J, et al. EPSANet: an efficient pyramid squeeze attention block on convolutional neural network[C]// Proceedings of the Asian Conference on Computer Vision, 2022: 1161-1177.
[本文引用: 1]
[11]
TAN M, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks [C]// Proceedings of the 36th International Conference on Machine Learning . [S.l.]: PMLR, 2019: 6105-6114.
[本文引用: 1]
[12]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980-2988.
[本文引用: 1]
[13]
ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6848-6856.
[本文引用: 1]
[14]
HAN K, WANG Y, TIAN Q, et al. GhostNet: more features from cheap operations [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1580-1589.
[本文引用: 1]
[15]
FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector [EB/OL]. (2017-01-23). https://arxiv.org/pdf/1701.06659.pdf.
[本文引用: 1]
[16]
ZHANG Z, QIAO S, XIE C, et al. Single-shot object detection with enriched semantics [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 5813–5821
[本文引用: 1]
[17]
ZHANG S, WEN L, BIAN X, et al. Single-shot refinement neural network for object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4203-4212.
[本文引用: 1]
[18]
DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks [C]// Proceedings of the 30 th International Conference on Neural Information Processing Systems . [S.l.]: CAI, 2016: 379-387.
[本文引用: 1]
[20]
DUAN Q, PING K, LI F, et al. Method of safety helmet wearing detection based on key-point estimation without anchor [C]// 2020 17th International Computer Conference on Wavelet Active Media Technology and Information Processing . Chengdu: IEEE, 2020: 93-96
[本文引用: 2]
[21]
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017: 1137-1149.
[本文引用: 2]
[22]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-04-08). https://arxiv.org/pdf/1804.02767.
[本文引用: 2]
[23]
DUAN K, BAI S, XIE L, et al. CenterNet: keypoint triplets for object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6569-6578.
[本文引用: 2]
基于注意力机制的多尺度全场景监控目标检测方法
1
2022
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
基于注意力机制的多尺度全场景监控目标检测方法
1
2022
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
背景差分与帧间差分相融合的遥感卫星视频运动车辆检测方法
1
2018
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
背景差分与帧间差分相融合的遥感卫星视频运动车辆检测方法
1
2018
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
Multi-class AdaBoost
1
2009
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
1
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
1
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
1
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
1
... 目标检测作为计算机视觉领域的基础任务,被广泛应用在安防监控、自动驾驶领域[1 ] . 现实场景对目标检测方法的参数量和检测速度均有较高的要求,如何在优化目标检测算法、提高检测精度的同时既减少模型参数量又提高检测速度,成为该领域研究的主要任务. 传统目标检测算法主要包括基于像素分析的检测方法[2 ] 、基于识别的检测方法[3 ] ,缺点是时间复杂度高、实时性差. 基于深度学习的目标检测算法主要包括基于候选区域的双阶段目标检测算法、基于边界框回归的单阶段目标检测算法. 双阶段目标检测算法先生成一系列的候选区域,再对每个候选区域进行类别分类和位置回归,如R-CNN[4 ] 、Fast R-CNN[5 ] 算法. 单阶段目标检测算法在产生候选框的同时进行分类和边界框回归,将目标边界框的定位问题转化为回归问题,得到目标的位置信息和目标类别信息,相比双阶段算法检测速度更快,计算成本更低,更适合用于实时目标检测,如YOLO[6 -7 ] 系列算法. ...
基于GhostNet与注意力机制的行人检测跟踪算法
1
2022
... 目标检测算法将注意力模块嵌入现有的卷积神经网络,以显著提升网络的特征表示能力. 王立辉等[8 ] 提出基于GhostNet与注意力模块结合的模型,将压缩激励注意力(squeeze-and-excitation,SE)模块嵌入YOLOv3网络. 但该注意力模块仅考虑了通道注意力,忽略了空间注意力,导致多尺度特征提取能力不足. Woo等[9 ] 提出CBAM(convolutional block attention module),并将CBAM嵌入YOLOv3网络,融合空间注意力和通道注意力,提升了网络提取有效特征的能力,但CBAM仅考虑了局部信息,无法建立远距离依赖. Zhang等[10 ] 提出低成本但有效的金字塔分割注意力(pyramid split attention,PSA)模块,将其引入ResNet模型中,捕获不同尺度特征图的空间信息,提升了网络的多尺度特征表示能力. 卷积神经网络一般通过设计较深的卷积层、大量堆叠残差块与跳跃连接来丰富特征信息,提高目标检测精度,但该类方法在提高检测精度的同时,增加了网络的复杂度、计算量(如EfficientNet[11 ] 、RetinaNet[12 ] ),应用到移动端或嵌入式设备时有一定困难. 为了提高检测效率,研究者提出了各种减少目标检测网络参数量和计算量的方法. 如ShuffleNet[13 ] 通过逐点卷积和组卷积随机整合实现特征图“重组”,大幅度减少了模型参数量,提高了检测速度;GhostNet[14 ] 在不改变输出特征图尺度和通道大小的前提下,通过线性变换生成相似的特征图,减少了网络模型参数量与计算复杂度. ...
基于GhostNet与注意力机制的行人检测跟踪算法
1
2022
... 目标检测算法将注意力模块嵌入现有的卷积神经网络,以显著提升网络的特征表示能力. 王立辉等[8 ] 提出基于GhostNet与注意力模块结合的模型,将压缩激励注意力(squeeze-and-excitation,SE)模块嵌入YOLOv3网络. 但该注意力模块仅考虑了通道注意力,忽略了空间注意力,导致多尺度特征提取能力不足. Woo等[9 ] 提出CBAM(convolutional block attention module),并将CBAM嵌入YOLOv3网络,融合空间注意力和通道注意力,提升了网络提取有效特征的能力,但CBAM仅考虑了局部信息,无法建立远距离依赖. Zhang等[10 ] 提出低成本但有效的金字塔分割注意力(pyramid split attention,PSA)模块,将其引入ResNet模型中,捕获不同尺度特征图的空间信息,提升了网络的多尺度特征表示能力. 卷积神经网络一般通过设计较深的卷积层、大量堆叠残差块与跳跃连接来丰富特征信息,提高目标检测精度,但该类方法在提高检测精度的同时,增加了网络的复杂度、计算量(如EfficientNet[11 ] 、RetinaNet[12 ] ),应用到移动端或嵌入式设备时有一定困难. 为了提高检测效率,研究者提出了各种减少目标检测网络参数量和计算量的方法. 如ShuffleNet[13 ] 通过逐点卷积和组卷积随机整合实现特征图“重组”,大幅度减少了模型参数量,提高了检测速度;GhostNet[14 ] 在不改变输出特征图尺度和通道大小的前提下,通过线性变换生成相似的特征图,减少了网络模型参数量与计算复杂度. ...
1
... 目标检测算法将注意力模块嵌入现有的卷积神经网络,以显著提升网络的特征表示能力. 王立辉等[8 ] 提出基于GhostNet与注意力模块结合的模型,将压缩激励注意力(squeeze-and-excitation,SE)模块嵌入YOLOv3网络. 但该注意力模块仅考虑了通道注意力,忽略了空间注意力,导致多尺度特征提取能力不足. Woo等[9 ] 提出CBAM(convolutional block attention module),并将CBAM嵌入YOLOv3网络,融合空间注意力和通道注意力,提升了网络提取有效特征的能力,但CBAM仅考虑了局部信息,无法建立远距离依赖. Zhang等[10 ] 提出低成本但有效的金字塔分割注意力(pyramid split attention,PSA)模块,将其引入ResNet模型中,捕获不同尺度特征图的空间信息,提升了网络的多尺度特征表示能力. 卷积神经网络一般通过设计较深的卷积层、大量堆叠残差块与跳跃连接来丰富特征信息,提高目标检测精度,但该类方法在提高检测精度的同时,增加了网络的复杂度、计算量(如EfficientNet[11 ] 、RetinaNet[12 ] ),应用到移动端或嵌入式设备时有一定困难. 为了提高检测效率,研究者提出了各种减少目标检测网络参数量和计算量的方法. 如ShuffleNet[13 ] 通过逐点卷积和组卷积随机整合实现特征图“重组”,大幅度减少了模型参数量,提高了检测速度;GhostNet[14 ] 在不改变输出特征图尺度和通道大小的前提下,通过线性变换生成相似的特征图,减少了网络模型参数量与计算复杂度. ...
1
... 目标检测算法将注意力模块嵌入现有的卷积神经网络,以显著提升网络的特征表示能力. 王立辉等[8 ] 提出基于GhostNet与注意力模块结合的模型,将压缩激励注意力(squeeze-and-excitation,SE)模块嵌入YOLOv3网络. 但该注意力模块仅考虑了通道注意力,忽略了空间注意力,导致多尺度特征提取能力不足. Woo等[9 ] 提出CBAM(convolutional block attention module),并将CBAM嵌入YOLOv3网络,融合空间注意力和通道注意力,提升了网络提取有效特征的能力,但CBAM仅考虑了局部信息,无法建立远距离依赖. Zhang等[10 ] 提出低成本但有效的金字塔分割注意力(pyramid split attention,PSA)模块,将其引入ResNet模型中,捕获不同尺度特征图的空间信息,提升了网络的多尺度特征表示能力. 卷积神经网络一般通过设计较深的卷积层、大量堆叠残差块与跳跃连接来丰富特征信息,提高目标检测精度,但该类方法在提高检测精度的同时,增加了网络的复杂度、计算量(如EfficientNet[11 ] 、RetinaNet[12 ] ),应用到移动端或嵌入式设备时有一定困难. 为了提高检测效率,研究者提出了各种减少目标检测网络参数量和计算量的方法. 如ShuffleNet[13 ] 通过逐点卷积和组卷积随机整合实现特征图“重组”,大幅度减少了模型参数量,提高了检测速度;GhostNet[14 ] 在不改变输出特征图尺度和通道大小的前提下,通过线性变换生成相似的特征图,减少了网络模型参数量与计算复杂度. ...
1
... 目标检测算法将注意力模块嵌入现有的卷积神经网络,以显著提升网络的特征表示能力. 王立辉等[8 ] 提出基于GhostNet与注意力模块结合的模型,将压缩激励注意力(squeeze-and-excitation,SE)模块嵌入YOLOv3网络. 但该注意力模块仅考虑了通道注意力,忽略了空间注意力,导致多尺度特征提取能力不足. Woo等[9 ] 提出CBAM(convolutional block attention module),并将CBAM嵌入YOLOv3网络,融合空间注意力和通道注意力,提升了网络提取有效特征的能力,但CBAM仅考虑了局部信息,无法建立远距离依赖. Zhang等[10 ] 提出低成本但有效的金字塔分割注意力(pyramid split attention,PSA)模块,将其引入ResNet模型中,捕获不同尺度特征图的空间信息,提升了网络的多尺度特征表示能力. 卷积神经网络一般通过设计较深的卷积层、大量堆叠残差块与跳跃连接来丰富特征信息,提高目标检测精度,但该类方法在提高检测精度的同时,增加了网络的复杂度、计算量(如EfficientNet[11 ] 、RetinaNet[12 ] ),应用到移动端或嵌入式设备时有一定困难. 为了提高检测效率,研究者提出了各种减少目标检测网络参数量和计算量的方法. 如ShuffleNet[13 ] 通过逐点卷积和组卷积随机整合实现特征图“重组”,大幅度减少了模型参数量,提高了检测速度;GhostNet[14 ] 在不改变输出特征图尺度和通道大小的前提下,通过线性变换生成相似的特征图,减少了网络模型参数量与计算复杂度. ...
1
... 目标检测算法将注意力模块嵌入现有的卷积神经网络,以显著提升网络的特征表示能力. 王立辉等[8 ] 提出基于GhostNet与注意力模块结合的模型,将压缩激励注意力(squeeze-and-excitation,SE)模块嵌入YOLOv3网络. 但该注意力模块仅考虑了通道注意力,忽略了空间注意力,导致多尺度特征提取能力不足. Woo等[9 ] 提出CBAM(convolutional block attention module),并将CBAM嵌入YOLOv3网络,融合空间注意力和通道注意力,提升了网络提取有效特征的能力,但CBAM仅考虑了局部信息,无法建立远距离依赖. Zhang等[10 ] 提出低成本但有效的金字塔分割注意力(pyramid split attention,PSA)模块,将其引入ResNet模型中,捕获不同尺度特征图的空间信息,提升了网络的多尺度特征表示能力. 卷积神经网络一般通过设计较深的卷积层、大量堆叠残差块与跳跃连接来丰富特征信息,提高目标检测精度,但该类方法在提高检测精度的同时,增加了网络的复杂度、计算量(如EfficientNet[11 ] 、RetinaNet[12 ] ),应用到移动端或嵌入式设备时有一定困难. 为了提高检测效率,研究者提出了各种减少目标检测网络参数量和计算量的方法. 如ShuffleNet[13 ] 通过逐点卷积和组卷积随机整合实现特征图“重组”,大幅度减少了模型参数量,提高了检测速度;GhostNet[14 ] 在不改变输出特征图尺度和通道大小的前提下,通过线性变换生成相似的特征图,减少了网络模型参数量与计算复杂度. ...
1
... 目标检测算法将注意力模块嵌入现有的卷积神经网络,以显著提升网络的特征表示能力. 王立辉等[8 ] 提出基于GhostNet与注意力模块结合的模型,将压缩激励注意力(squeeze-and-excitation,SE)模块嵌入YOLOv3网络. 但该注意力模块仅考虑了通道注意力,忽略了空间注意力,导致多尺度特征提取能力不足. Woo等[9 ] 提出CBAM(convolutional block attention module),并将CBAM嵌入YOLOv3网络,融合空间注意力和通道注意力,提升了网络提取有效特征的能力,但CBAM仅考虑了局部信息,无法建立远距离依赖. Zhang等[10 ] 提出低成本但有效的金字塔分割注意力(pyramid split attention,PSA)模块,将其引入ResNet模型中,捕获不同尺度特征图的空间信息,提升了网络的多尺度特征表示能力. 卷积神经网络一般通过设计较深的卷积层、大量堆叠残差块与跳跃连接来丰富特征信息,提高目标检测精度,但该类方法在提高检测精度的同时,增加了网络的复杂度、计算量(如EfficientNet[11 ] 、RetinaNet[12 ] ),应用到移动端或嵌入式设备时有一定困难. 为了提高检测效率,研究者提出了各种减少目标检测网络参数量和计算量的方法. 如ShuffleNet[13 ] 通过逐点卷积和组卷积随机整合实现特征图“重组”,大幅度减少了模型参数量,提高了检测速度;GhostNet[14 ] 在不改变输出特征图尺度和通道大小的前提下,通过线性变换生成相似的特征图,减少了网络模型参数量与计算复杂度. ...
1
... 目标检测算法将注意力模块嵌入现有的卷积神经网络,以显著提升网络的特征表示能力. 王立辉等[8 ] 提出基于GhostNet与注意力模块结合的模型,将压缩激励注意力(squeeze-and-excitation,SE)模块嵌入YOLOv3网络. 但该注意力模块仅考虑了通道注意力,忽略了空间注意力,导致多尺度特征提取能力不足. Woo等[9 ] 提出CBAM(convolutional block attention module),并将CBAM嵌入YOLOv3网络,融合空间注意力和通道注意力,提升了网络提取有效特征的能力,但CBAM仅考虑了局部信息,无法建立远距离依赖. Zhang等[10 ] 提出低成本但有效的金字塔分割注意力(pyramid split attention,PSA)模块,将其引入ResNet模型中,捕获不同尺度特征图的空间信息,提升了网络的多尺度特征表示能力. 卷积神经网络一般通过设计较深的卷积层、大量堆叠残差块与跳跃连接来丰富特征信息,提高目标检测精度,但该类方法在提高检测精度的同时,增加了网络的复杂度、计算量(如EfficientNet[11 ] 、RetinaNet[12 ] ),应用到移动端或嵌入式设备时有一定困难. 为了提高检测效率,研究者提出了各种减少目标检测网络参数量和计算量的方法. 如ShuffleNet[13 ] 通过逐点卷积和组卷积随机整合实现特征图“重组”,大幅度减少了模型参数量,提高了检测速度;GhostNet[14 ] 在不改变输出特征图尺度和通道大小的前提下,通过线性变换生成相似的特征图,减少了网络模型参数量与计算复杂度. ...
1
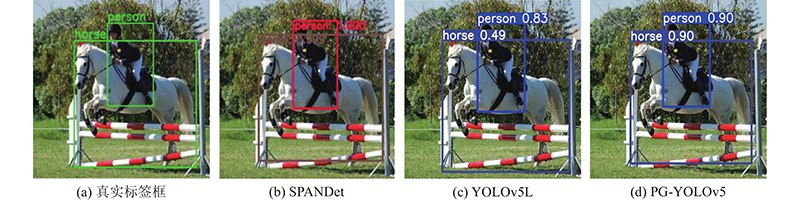
... 为了验证PG-YOLOv5的有效性,将本研究算法与经典目标检测算法进行对比实验,平均精度均值及部分类别的平均精度如表2 所示. 其中部分类别为在Pascal VOC数据集的20个类别中随机挑选的9个类别,分别为bike、bird、bottle、bus、car、cat、person、sheep、tv. 3种算法的检测结果图如图8 所示. 由表2 可知,和DSSD[15 ] 、DES[16 ] 相比,RefineDet[17 ] 、R-FCN[18 ] 的mAP低;相较于DSSD、DES、RefineDet、R-FCN,SPANDet[19 ] 的mAP均有所提升,但对于尺度变化大的目标检测效果不佳;PG-YOLOv5的mAP从SPANDet的82.6%提高到85.7%,特别是bottle类,本研究算法mAP提高最多,说明PG-YOLOv5对小目标具有较好的检测效果. 由图8 可以看出,输入图像中的对象具有不同的尺度,且尺度差异大. SPANDet未检测出马,该算法关注到了小尺度目标,但是单尺度变化较大导致该算法漏检了大尺度目标,因此SPANDet对尺度变化较大的图像的检测效果不佳. YOLOv5L对于尺度变化较大的图像检测效果较好,未出现漏检情况,但检测精确度较低. PG-YOLOv5可以准确检测出人和马,可以很好地适应不同尺度的目标,在尺度变化较大的情况下,未出现漏检情况,且检测精确度高. 实验结果表明,本研究算法引入的PSA模块能够有效提高网络对于不同尺度目标的检测能力. ...
1
... 为了验证PG-YOLOv5的有效性,将本研究算法与经典目标检测算法进行对比实验,平均精度均值及部分类别的平均精度如表2 所示. 其中部分类别为在Pascal VOC数据集的20个类别中随机挑选的9个类别,分别为bike、bird、bottle、bus、car、cat、person、sheep、tv. 3种算法的检测结果图如图8 所示. 由表2 可知,和DSSD[15 ] 、DES[16 ] 相比,RefineDet[17 ] 、R-FCN[18 ] 的mAP低;相较于DSSD、DES、RefineDet、R-FCN,SPANDet[19 ] 的mAP均有所提升,但对于尺度变化大的目标检测效果不佳;PG-YOLOv5的mAP从SPANDet的82.6%提高到85.7%,特别是bottle类,本研究算法mAP提高最多,说明PG-YOLOv5对小目标具有较好的检测效果. 由图8 可以看出,输入图像中的对象具有不同的尺度,且尺度差异大. SPANDet未检测出马,该算法关注到了小尺度目标,但是单尺度变化较大导致该算法漏检了大尺度目标,因此SPANDet对尺度变化较大的图像的检测效果不佳. YOLOv5L对于尺度变化较大的图像检测效果较好,未出现漏检情况,但检测精确度较低. PG-YOLOv5可以准确检测出人和马,可以很好地适应不同尺度的目标,在尺度变化较大的情况下,未出现漏检情况,且检测精确度高. 实验结果表明,本研究算法引入的PSA模块能够有效提高网络对于不同尺度目标的检测能力. ...
1
... 为了验证PG-YOLOv5的有效性,将本研究算法与经典目标检测算法进行对比实验,平均精度均值及部分类别的平均精度如表2 所示. 其中部分类别为在Pascal VOC数据集的20个类别中随机挑选的9个类别,分别为bike、bird、bottle、bus、car、cat、person、sheep、tv. 3种算法的检测结果图如图8 所示. 由表2 可知,和DSSD[15 ] 、DES[16 ] 相比,RefineDet[17 ] 、R-FCN[18 ] 的mAP低;相较于DSSD、DES、RefineDet、R-FCN,SPANDet[19 ] 的mAP均有所提升,但对于尺度变化大的目标检测效果不佳;PG-YOLOv5的mAP从SPANDet的82.6%提高到85.7%,特别是bottle类,本研究算法mAP提高最多,说明PG-YOLOv5对小目标具有较好的检测效果. 由图8 可以看出,输入图像中的对象具有不同的尺度,且尺度差异大. SPANDet未检测出马,该算法关注到了小尺度目标,但是单尺度变化较大导致该算法漏检了大尺度目标,因此SPANDet对尺度变化较大的图像的检测效果不佳. YOLOv5L对于尺度变化较大的图像检测效果较好,未出现漏检情况,但检测精确度较低. PG-YOLOv5可以准确检测出人和马,可以很好地适应不同尺度的目标,在尺度变化较大的情况下,未出现漏检情况,且检测精确度高. 实验结果表明,本研究算法引入的PSA模块能够有效提高网络对于不同尺度目标的检测能力. ...
1
... 为了验证PG-YOLOv5的有效性,将本研究算法与经典目标检测算法进行对比实验,平均精度均值及部分类别的平均精度如表2 所示. 其中部分类别为在Pascal VOC数据集的20个类别中随机挑选的9个类别,分别为bike、bird、bottle、bus、car、cat、person、sheep、tv. 3种算法的检测结果图如图8 所示. 由表2 可知,和DSSD[15 ] 、DES[16 ] 相比,RefineDet[17 ] 、R-FCN[18 ] 的mAP低;相较于DSSD、DES、RefineDet、R-FCN,SPANDet[19 ] 的mAP均有所提升,但对于尺度变化大的目标检测效果不佳;PG-YOLOv5的mAP从SPANDet的82.6%提高到85.7%,特别是bottle类,本研究算法mAP提高最多,说明PG-YOLOv5对小目标具有较好的检测效果. 由图8 可以看出,输入图像中的对象具有不同的尺度,且尺度差异大. SPANDet未检测出马,该算法关注到了小尺度目标,但是单尺度变化较大导致该算法漏检了大尺度目标,因此SPANDet对尺度变化较大的图像的检测效果不佳. YOLOv5L对于尺度变化较大的图像检测效果较好,未出现漏检情况,但检测精确度较低. PG-YOLOv5可以准确检测出人和马,可以很好地适应不同尺度的目标,在尺度变化较大的情况下,未出现漏检情况,且检测精确度高. 实验结果表明,本研究算法引入的PSA模块能够有效提高网络对于不同尺度目标的检测能力. ...
Stacked pyramid attention network for object detection
1
2022
... 为了验证PG-YOLOv5的有效性,将本研究算法与经典目标检测算法进行对比实验,平均精度均值及部分类别的平均精度如表2 所示. 其中部分类别为在Pascal VOC数据集的20个类别中随机挑选的9个类别,分别为bike、bird、bottle、bus、car、cat、person、sheep、tv. 3种算法的检测结果图如图8 所示. 由表2 可知,和DSSD[15 ] 、DES[16 ] 相比,RefineDet[17 ] 、R-FCN[18 ] 的mAP低;相较于DSSD、DES、RefineDet、R-FCN,SPANDet[19 ] 的mAP均有所提升,但对于尺度变化大的目标检测效果不佳;PG-YOLOv5的mAP从SPANDet的82.6%提高到85.7%,特别是bottle类,本研究算法mAP提高最多,说明PG-YOLOv5对小目标具有较好的检测效果. 由图8 可以看出,输入图像中的对象具有不同的尺度,且尺度差异大. SPANDet未检测出马,该算法关注到了小尺度目标,但是单尺度变化较大导致该算法漏检了大尺度目标,因此SPANDet对尺度变化较大的图像的检测效果不佳. YOLOv5L对于尺度变化较大的图像检测效果较好,未出现漏检情况,但检测精确度较低. PG-YOLOv5可以准确检测出人和马,可以很好地适应不同尺度的目标,在尺度变化较大的情况下,未出现漏检情况,且检测精确度高. 实验结果表明,本研究算法引入的PSA模块能够有效提高网络对于不同尺度目标的检测能力. ...
2
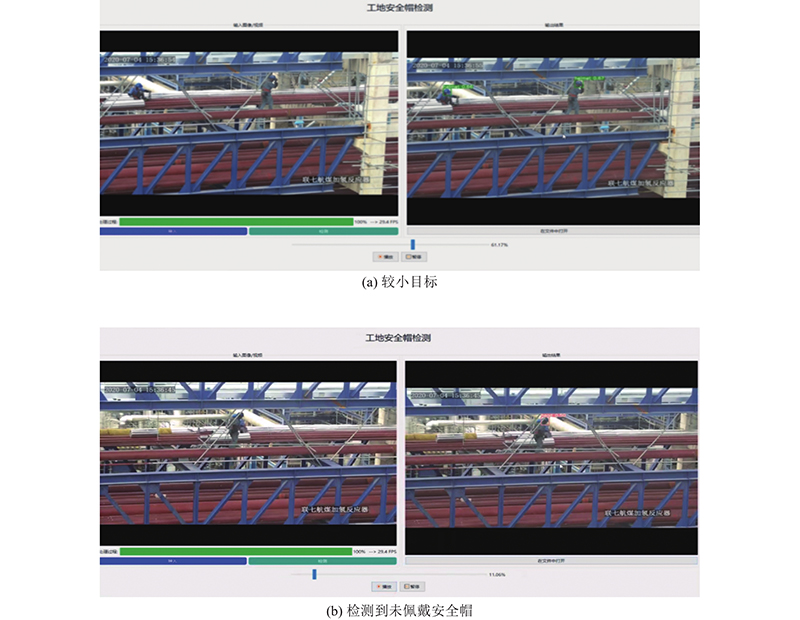
... 基于SHWD数据集将Duan等[20 ] 所提算法、Faster-RCNN[21 ] 、CenterNet[23 ] 、YOLOv3[22 ] 与PG-YOLOv5进行目标检测实验对比,各算法的平均精度均值如表4 所示,检测结果图如图10 所示. 由表4 可知,Faster-RCNN算法的mAP比YOLOv3、CenterNet的低,PG-YOLOv5的mAP是5种算法的mAP中最高的,为95.7%. 由图10 可以看出,PG-YOLOv5能够准确检测出是否佩戴安全帽. ...
... Mean average precisions of different target detection algorithms on SHWD dataset
Tab.4 算法 mAP/% Faster-RCNN[21 ] 85.0 YOLOv3[22 ] 88.5 CenterNet[23 ] 90.0 Duan等[20 ] 92.0 本研究 95.7
图 10 PG-YOLOv5在SHWD数据集上的检测结果图 ...
2
... 基于SHWD数据集将Duan等[20 ] 所提算法、Faster-RCNN[21 ] 、CenterNet[23 ] 、YOLOv3[22 ] 与PG-YOLOv5进行目标检测实验对比,各算法的平均精度均值如表4 所示,检测结果图如图10 所示. 由表4 可知,Faster-RCNN算法的mAP比YOLOv3、CenterNet的低,PG-YOLOv5的mAP是5种算法的mAP中最高的,为95.7%. 由图10 可以看出,PG-YOLOv5能够准确检测出是否佩戴安全帽. ...
... Mean average precisions of different target detection algorithms on SHWD dataset
Tab.4 算法 mAP/% Faster-RCNN[21 ] 85.0 YOLOv3[22 ] 88.5 CenterNet[23 ] 90.0 Duan等[20 ] 92.0 本研究 95.7
图 10 PG-YOLOv5在SHWD数据集上的检测结果图 ...
2
... 基于SHWD数据集将Duan等[20 ] 所提算法、Faster-RCNN[21 ] 、CenterNet[23 ] 、YOLOv3[22 ] 与PG-YOLOv5进行目标检测实验对比,各算法的平均精度均值如表4 所示,检测结果图如图10 所示. 由表4 可知,Faster-RCNN算法的mAP比YOLOv3、CenterNet的低,PG-YOLOv5的mAP是5种算法的mAP中最高的,为95.7%. 由图10 可以看出,PG-YOLOv5能够准确检测出是否佩戴安全帽. ...
... Mean average precisions of different target detection algorithms on SHWD dataset
Tab.4 算法 mAP/% Faster-RCNN[21 ] 85.0 YOLOv3[22 ] 88.5 CenterNet[23 ] 90.0 Duan等[20 ] 92.0 本研究 95.7
图 10 PG-YOLOv5在SHWD数据集上的检测结果图 ...
2
... 基于SHWD数据集将Duan等[20 ] 所提算法、Faster-RCNN[21 ] 、CenterNet[23 ] 、YOLOv3[22 ] 与PG-YOLOv5进行目标检测实验对比,各算法的平均精度均值如表4 所示,检测结果图如图10 所示. 由表4 可知,Faster-RCNN算法的mAP比YOLOv3、CenterNet的低,PG-YOLOv5的mAP是5种算法的mAP中最高的,为95.7%. 由图10 可以看出,PG-YOLOv5能够准确检测出是否佩戴安全帽. ...
... Mean average precisions of different target detection algorithms on SHWD dataset
Tab.4 算法 mAP/% Faster-RCNN[21 ] 85.0 YOLOv3[22 ] 88.5 CenterNet[23 ] 90.0 Duan等[20 ] 92.0 本研究 95.7
图 10 PG-YOLOv5在SHWD数据集上的检测结果图 ...


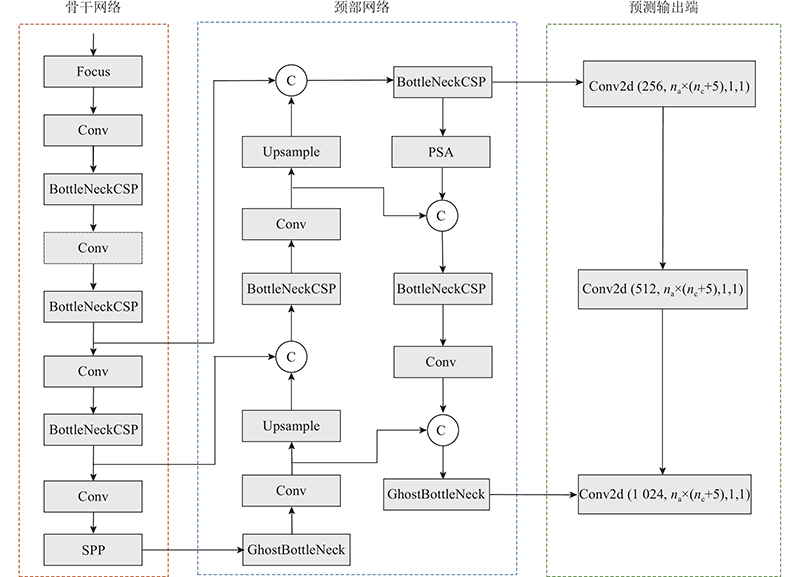
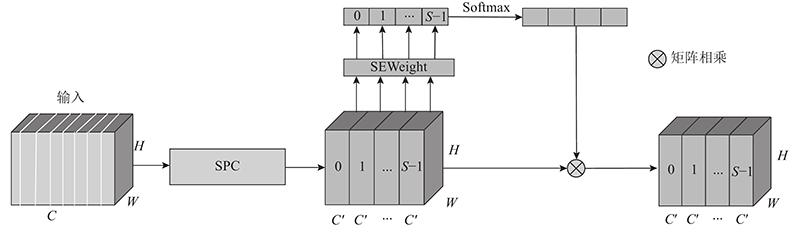

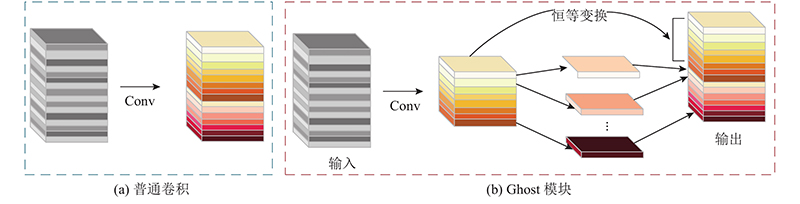
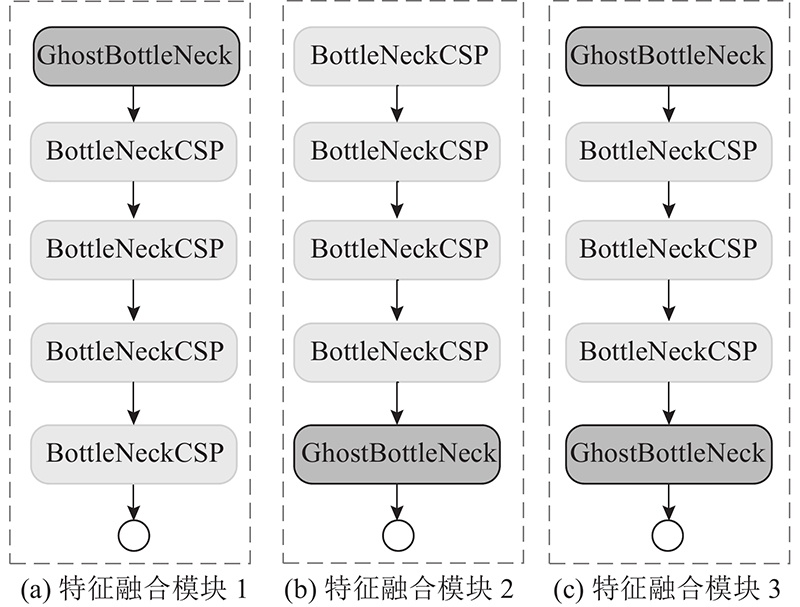




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}