为了降低全局聚合时的通信时延,优化簇头与基站通信的带宽资源分配方法以及提高全局模型的性能表现,需要确定合理的簇头选择方法. 簇头的本地模型能够精确地反映集群经过训练后得到的模型特征. 在全局聚合阶段,从每个簇内选择作为簇头设备的集合为 $\{ {H_1}, \cdots ,{H_C}\} $ . 用布尔变量 $ {w}_{k,i} $ $i \in {S_k}$ $k$ $ {w}_{k,i}=1 $ $ {w}_{k,i}=0 $ . 没有被选为簇头的设备不上传模型,上传时间为零,因此设备 $i \in {\mathcal{S}_k}$
当 ${w_{k,i}} = 0$ $T_{k,i}^{\text{u}} = 0$ ${w_{k,i}} = 1$ $T_{k,i}^{\text{u}} = {T^{{\text{Bound}}}}$ ${V_{k,i}} = \dfrac{Q}{{{T^{{\text{Bound}}}}{{\log }_2}\left( {1+{P_{k,i}}|{h_{k,i}}{|^2}/{N_0}} \right)}}$
[1]
CHEN M, YANG Z, SAAD W, et al A Joint learning and communications framework for federated learning over wireless networks
[J]. IEEE Transactions on Wireless Communications , 2020 , 20 (1 ): 269 - 283
[本文引用: 1]
[2]
ZHU G, LIU D, DU Y, et al Towards an intelligent edge: wireless communication meets machine learning
[J]. IEEE Communications Magazine , 2020 , 58 (1 ): 19 - 25
DOI:10.1109/MCOM.001.1900103
[本文引用: 1]
[3]
CHEN M, GUNDUZ D, HUANG K, et al Distributed learning in wireless networks: recent progress and future challenges
[J]. IEEE Journal on Selected Areas in Communications , 2021 , 39 (12 ): 3579 - 3605
DOI:10.1109/JSAC.2021.3118346
[本文引用: 1]
[4]
MCMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [C]// Artificial Intelligence and Statistics. Lauderdale: PMLR, 2017: 1273-1282.
[本文引用: 2]
[5]
LIM W Y B, LUONG N C, HOANG D T, et al Federated learning in mobile edge networks: a comprehensive survey
[J]. IEEE Communications Surveys and Tutorials , 2020 , 22 (3 ): 2031 - 2063
DOI:10.1109/COMST.2020.2986024
[本文引用: 1]
[6]
LIM W Y B, NG J S, XIONG Z, et al Decentralized edge intelligence: a dynamic resource allocation framework for hierarchical federated learning
[J]. IEEE Transactions on Parallel and Distributed Systems , 2021 , 33 (3 ): 536 - 550
[本文引用: 1]
[7]
WANG Z, XU H, LIU J, et al. Accelerating federated learning with cluster construction and hierarchical aggregation [EB/OL]. [2022-02-01]. https://www.computer.org/csdl/journal/tm/5555/01/09699080/1ADJeS80Gvm.
[本文引用: 2]
[8]
FENG D, LU L, YUANWU Y, et al Device-to-device communications in cellular networks
[J]. IEEE Communications Magazine , 2014 , 52 (4 ): 49 - 55
DOI:10.1109/MCOM.2014.6807946
[本文引用: 1]
[9]
ASADI A, WANG Q, MANCUSO V A survey on device-to-device communication in cellular networks
[J]. IEEE Communications Surveys and Tutorials , 2014 , 16 (4 ): 1801 - 1819
DOI:10.1109/COMST.2014.2319555
[本文引用: 1]
[10]
YU D, ZOU Z, CHEN S, et al Decentralized parallel sgd with privacy preservation in vehicular networks
[J]. IEEE Transactions on Vehicular Technology , 2021 , 70 (6 ): 5211 - 5220
DOI:10.1109/TVT.2021.3064877
[本文引用: 1]
[11]
XING H, SIMEONE O, BI S. Decentralized federated learning via SGD over wireless D2D networks [C]// 21st International Workshop on Signal Processing Advances in Wireless Communications. Atlanta: IEEE, 2020: 1-5.
[本文引用: 2]
[12]
POKHREL S R, CHOI J. A decentralized federated learning approach for connected autonomous vehicles [C]// IEEE Wireless Communications and Networking Conference Workshops. Seoul : IEEE, 2020: 1-6.
[本文引用: 1]
[13]
ZHU L, LIU C, YUAN J, et al. Machine learning-based resource optimization for D2D communication underlaying networks [C]// IEEE 92nd Vehicular Technology Conference (VTC2020-Fall). Victoria: IEEE, 2020: 1-6.
[本文引用: 1]
[14]
HOANG T D, LE L B, LENGOC T Resource allocation for D2D communication underlaid cellular networks using graph-based approach
[J]. IEEE Transactions on Wireless Communications , 2016 , 15 (10 ): 7099 - 7113
DOI:10.1109/TWC.2016.2597283
[本文引用: 1]
[15]
OZFATURA E, RINI S, GÜNDÜZ D. Decentralized SGD with over-the-air computation [C]// IEEE Global Communications Conference. Taipei: IEEE, 2020: 1-6.
[本文引用: 1]
[16]
NISHIO T, YONETANI R. Client selection for federated learning with heterogeneous resources in mobile edge [C]// IEEE International Conference on Communications. Shanghai: IEEE, 2019: 1-7.
[本文引用: 1]
[17]
WEN D, BENNIS M, HUANG K Joint parameter-and-bandwidth allocation for improving the efficiency of partitioned edge learning
[J]. IEEE Transactions on Wireless Communications , 2020 , 19 (12 ): 8272 - 8286
DOI:10.1109/TWC.2020.3021177
[本文引用: 2]
[18]
JIANG Z, YU G, CAI Y, Decentralized edge learning via unreliable device-to-device communications [J]. IEEE Transactions on Wireless Communications , 2022, 21(11): 9041-9055
[本文引用: 1]
[19]
WEN D, JEON K J, BENNIS M, et al Adaptive subcarrier, parameter, and power allocation for partitioned edge learning over broadband channels
[J]. IEEE Transactions on Wireless Communications , 2021 , 20 (12 ): 8348 - 8361
DOI:10.1109/TWC.2021.3092075
[本文引用: 1]
[20]
ZENG Q, DU Y, HUANG K, et al Energy-efficient resource management for federated edge learning with CPU-GPU heterogeneous computing
[J]. IEEE Transactions on Wireless Communications , 2021 , 20 (12 ): 7947 - 7962
DOI:10.1109/TWC.2021.3088910
[本文引用: 1]
[21]
KOLOSKOVA A, LOIZOU N, BOREIRI S, et al. A unified theory of decentralized sgd with changing topology and local updates [C]// International Conference on Machine Learning. Vienna: PMLR, 2020: 5381-5393.
[本文引用: 1]
[22]
MARTELLO S, PISINGER D, TOTH P Dynamic programming and strong bounds for the 0-1 knapsack problem
[J]. Management Science , 1999 , 45 (3 ): 414 - 424
DOI:10.1287/mnsc.45.3.414
[本文引用: 1]
A Joint learning and communications framework for federated learning over wireless networks
1
2020
... 在移动数据流量爆炸式增长的驱动下,机器学习在大量研究领域取得显著的成功,例如计算机视觉和自然语言处理. 随着越来越多的边缘设备接入互联网,无线网络中的训练数据可能会被各种设备收集,由于严格的隐私协议和稀缺的通信资源,这些数据无法被传输到中央服务器. 为了克服这些挑战,最近提出的联邦学习已经成为一种流行的分布式机器学习技术[1 -2 ] ,该技术使许得多设备能够训练本地模型并与服务器交换模型参数或梯度. 联邦学习系统中的设备通常是以星形拓扑连接[3 ] ,例如在典型的参数服务器架构中,每个设备根据自己的数据集训练一个局部模型后上传到服务器,服务器通常使用加权平均值将其聚合为全局模型[4 ] . 在大规模设备共同参与联邦学习训练的场景中,由于中央服务器需要聚合来自数百个设备的模型信息,通信资源成为影响联邦学习系统收敛速率的关键因素[5 ] . 当系统中可用的网络带宽较低时,中心化架构会导致网络中产生流量拥塞,模型训练的收敛速率会显著下降. ...
Towards an intelligent edge: wireless communication meets machine learning
1
2020
... 在移动数据流量爆炸式增长的驱动下,机器学习在大量研究领域取得显著的成功,例如计算机视觉和自然语言处理. 随着越来越多的边缘设备接入互联网,无线网络中的训练数据可能会被各种设备收集,由于严格的隐私协议和稀缺的通信资源,这些数据无法被传输到中央服务器. 为了克服这些挑战,最近提出的联邦学习已经成为一种流行的分布式机器学习技术[1 -2 ] ,该技术使许得多设备能够训练本地模型并与服务器交换模型参数或梯度. 联邦学习系统中的设备通常是以星形拓扑连接[3 ] ,例如在典型的参数服务器架构中,每个设备根据自己的数据集训练一个局部模型后上传到服务器,服务器通常使用加权平均值将其聚合为全局模型[4 ] . 在大规模设备共同参与联邦学习训练的场景中,由于中央服务器需要聚合来自数百个设备的模型信息,通信资源成为影响联邦学习系统收敛速率的关键因素[5 ] . 当系统中可用的网络带宽较低时,中心化架构会导致网络中产生流量拥塞,模型训练的收敛速率会显著下降. ...
Distributed learning in wireless networks: recent progress and future challenges
1
2021
... 在移动数据流量爆炸式增长的驱动下,机器学习在大量研究领域取得显著的成功,例如计算机视觉和自然语言处理. 随着越来越多的边缘设备接入互联网,无线网络中的训练数据可能会被各种设备收集,由于严格的隐私协议和稀缺的通信资源,这些数据无法被传输到中央服务器. 为了克服这些挑战,最近提出的联邦学习已经成为一种流行的分布式机器学习技术[1 -2 ] ,该技术使许得多设备能够训练本地模型并与服务器交换模型参数或梯度. 联邦学习系统中的设备通常是以星形拓扑连接[3 ] ,例如在典型的参数服务器架构中,每个设备根据自己的数据集训练一个局部模型后上传到服务器,服务器通常使用加权平均值将其聚合为全局模型[4 ] . 在大规模设备共同参与联邦学习训练的场景中,由于中央服务器需要聚合来自数百个设备的模型信息,通信资源成为影响联邦学习系统收敛速率的关键因素[5 ] . 当系统中可用的网络带宽较低时,中心化架构会导致网络中产生流量拥塞,模型训练的收敛速率会显著下降. ...
2
... 在移动数据流量爆炸式增长的驱动下,机器学习在大量研究领域取得显著的成功,例如计算机视觉和自然语言处理. 随着越来越多的边缘设备接入互联网,无线网络中的训练数据可能会被各种设备收集,由于严格的隐私协议和稀缺的通信资源,这些数据无法被传输到中央服务器. 为了克服这些挑战,最近提出的联邦学习已经成为一种流行的分布式机器学习技术[1 -2 ] ,该技术使许得多设备能够训练本地模型并与服务器交换模型参数或梯度. 联邦学习系统中的设备通常是以星形拓扑连接[3 ] ,例如在典型的参数服务器架构中,每个设备根据自己的数据集训练一个局部模型后上传到服务器,服务器通常使用加权平均值将其聚合为全局模型[4 ] . 在大规模设备共同参与联邦学习训练的场景中,由于中央服务器需要聚合来自数百个设备的模型信息,通信资源成为影响联邦学习系统收敛速率的关键因素[5 ] . 当系统中可用的网络带宽较低时,中心化架构会导致网络中产生流量拥塞,模型训练的收敛速率会显著下降. ...
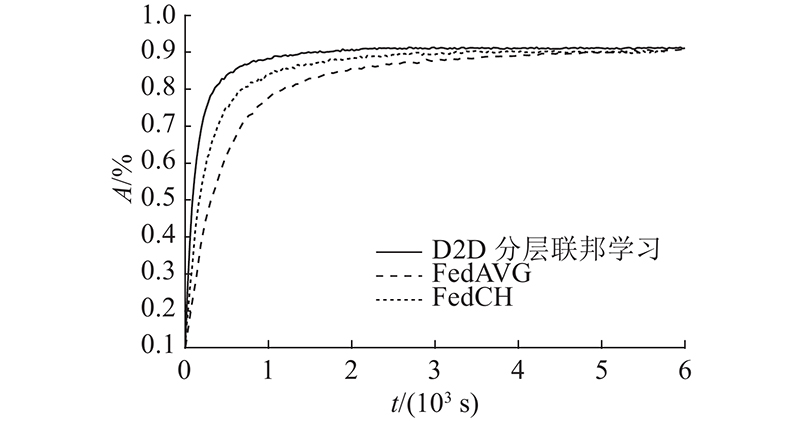
... 为了验证所提利用D2D通信的分层联邦学习可以节约通信开销,加快收敛速率,对所提算法与传统的联邦学习算法FedAVG[4 ] 和现有的分簇联邦学习算法FedCH[7 ] 的性能进行对比. 在作为基线的FedAVG算法中,系统带宽 $B = 20$ $\varphi = 20$ ${B^{(1)}} = 10$ ${B^{(2)}} = 10$ $\varphi = 20$
Federated learning in mobile edge networks: a comprehensive survey
1
2020
... 在移动数据流量爆炸式增长的驱动下,机器学习在大量研究领域取得显著的成功,例如计算机视觉和自然语言处理. 随着越来越多的边缘设备接入互联网,无线网络中的训练数据可能会被各种设备收集,由于严格的隐私协议和稀缺的通信资源,这些数据无法被传输到中央服务器. 为了克服这些挑战,最近提出的联邦学习已经成为一种流行的分布式机器学习技术[1 -2 ] ,该技术使许得多设备能够训练本地模型并与服务器交换模型参数或梯度. 联邦学习系统中的设备通常是以星形拓扑连接[3 ] ,例如在典型的参数服务器架构中,每个设备根据自己的数据集训练一个局部模型后上传到服务器,服务器通常使用加权平均值将其聚合为全局模型[4 ] . 在大规模设备共同参与联邦学习训练的场景中,由于中央服务器需要聚合来自数百个设备的模型信息,通信资源成为影响联邦学习系统收敛速率的关键因素[5 ] . 当系统中可用的网络带宽较低时,中心化架构会导致网络中产生流量拥塞,模型训练的收敛速率会显著下降. ...
Decentralized edge intelligence: a dynamic resource allocation framework for hierarchical federated learning
1
2021
... Lim等[6 ] 提出分层联邦学习架构来缓解参数服务器的带宽压力,利用簇内聚合避免频繁地全局聚合,减轻中央节点的通信成本. Wang等[7 ] 提出一种称为FedCH的联邦学习机制,通过构建一个特殊的集群拓扑并执行分层聚合进行训练. 一个集群中的设备将本地更新同步发送到中心节点进行聚合,而所有中心节点采用异步的方式进行全局聚合. 大多数的分层联邦学习工作主要是以模型平均的方式进行簇内聚合,这需要在每个簇中存在一个中心节点来收集模型参数或梯度,集中式架构会在中心节点造成拥塞. 在簇内无服务器的实际场景中,往往难以找到与簇内其他设备间都有良好通信链路的中心节点. ...
2
... Lim等[6 ] 提出分层联邦学习架构来缓解参数服务器的带宽压力,利用簇内聚合避免频繁地全局聚合,减轻中央节点的通信成本. Wang等[7 ] 提出一种称为FedCH的联邦学习机制,通过构建一个特殊的集群拓扑并执行分层聚合进行训练. 一个集群中的设备将本地更新同步发送到中心节点进行聚合,而所有中心节点采用异步的方式进行全局聚合. 大多数的分层联邦学习工作主要是以模型平均的方式进行簇内聚合,这需要在每个簇中存在一个中心节点来收集模型参数或梯度,集中式架构会在中心节点造成拥塞. 在簇内无服务器的实际场景中,往往难以找到与簇内其他设备间都有良好通信链路的中心节点. ...
... 为了验证所提利用D2D通信的分层联邦学习可以节约通信开销,加快收敛速率,对所提算法与传统的联邦学习算法FedAVG[4 ] 和现有的分簇联邦学习算法FedCH[7 ] 的性能进行对比. 在作为基线的FedAVG算法中,系统带宽 $B = 20$ $\varphi = 20$ ${B^{(1)}} = 10$ ${B^{(2)}} = 10$ $\varphi = 20$
Device-to-device communications in cellular networks
1
2014
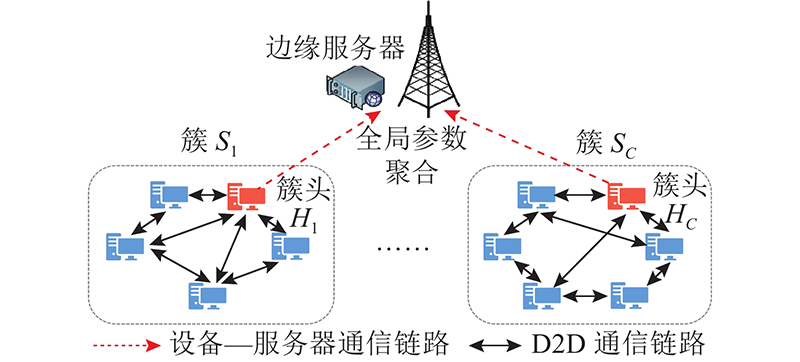
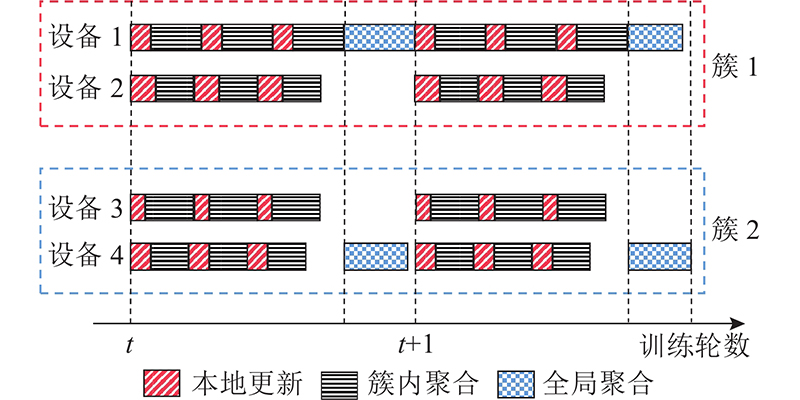
... 为了实现通信高效的联邦学习,将传统的设备到服务器通信与设备直通(device-to-device, D2D)通信相结合[8 -9 ] ,提出一种基于无线D2D网络的分层联邦学习. 依据所处的地理位置将边缘设备划分为多个簇,各个簇同时进行去中心化学习[10 ] ,通过共同训练机器学习模型来确保实现共同的学习目标. 在训练的2个全局聚合间隔期间,设备在各自的数据集上执行若干次随机梯度下降(stochastic gradient descent, SGD)迭代,通过簇内的无线D2D通信网络,设备定期地与邻居设备交换模型参数进行簇内模型聚合. 在全局聚合时,每个簇中只有一个设备需要将模型上传到服务器,这个设备被定义为簇头. 服务器根据模型平均算法,对所有簇头的本地模型进行全局聚合. 簇头的模型反映其集群经过去中心化训练后得到的本地模型的特征[11 -12 ] . ...
A survey on device-to-device communication in cellular networks
1
2014
... 为了实现通信高效的联邦学习,将传统的设备到服务器通信与设备直通(device-to-device, D2D)通信相结合[8 -9 ] ,提出一种基于无线D2D网络的分层联邦学习. 依据所处的地理位置将边缘设备划分为多个簇,各个簇同时进行去中心化学习[10 ] ,通过共同训练机器学习模型来确保实现共同的学习目标. 在训练的2个全局聚合间隔期间,设备在各自的数据集上执行若干次随机梯度下降(stochastic gradient descent, SGD)迭代,通过簇内的无线D2D通信网络,设备定期地与邻居设备交换模型参数进行簇内模型聚合. 在全局聚合时,每个簇中只有一个设备需要将模型上传到服务器,这个设备被定义为簇头. 服务器根据模型平均算法,对所有簇头的本地模型进行全局聚合. 簇头的模型反映其集群经过去中心化训练后得到的本地模型的特征[11 -12 ] . ...
Decentralized parallel sgd with privacy preservation in vehicular networks
1
2021
... 为了实现通信高效的联邦学习,将传统的设备到服务器通信与设备直通(device-to-device, D2D)通信相结合[8 -9 ] ,提出一种基于无线D2D网络的分层联邦学习. 依据所处的地理位置将边缘设备划分为多个簇,各个簇同时进行去中心化学习[10 ] ,通过共同训练机器学习模型来确保实现共同的学习目标. 在训练的2个全局聚合间隔期间,设备在各自的数据集上执行若干次随机梯度下降(stochastic gradient descent, SGD)迭代,通过簇内的无线D2D通信网络,设备定期地与邻居设备交换模型参数进行簇内模型聚合. 在全局聚合时,每个簇中只有一个设备需要将模型上传到服务器,这个设备被定义为簇头. 服务器根据模型平均算法,对所有簇头的本地模型进行全局聚合. 簇头的模型反映其集群经过去中心化训练后得到的本地模型的特征[11 -12 ] . ...
2
... 为了实现通信高效的联邦学习,将传统的设备到服务器通信与设备直通(device-to-device, D2D)通信相结合[8 -9 ] ,提出一种基于无线D2D网络的分层联邦学习. 依据所处的地理位置将边缘设备划分为多个簇,各个簇同时进行去中心化学习[10 ] ,通过共同训练机器学习模型来确保实现共同的学习目标. 在训练的2个全局聚合间隔期间,设备在各自的数据集上执行若干次随机梯度下降(stochastic gradient descent, SGD)迭代,通过簇内的无线D2D通信网络,设备定期地与邻居设备交换模型参数进行簇内模型聚合. 在全局聚合时,每个簇中只有一个设备需要将模型上传到服务器,这个设备被定义为簇头. 服务器根据模型平均算法,对所有簇头的本地模型进行全局聚合. 簇头的模型反映其集群经过去中心化训练后得到的本地模型的特征[11 -12 ] . ...
... 式中:常数 $\alpha $ [11 ] . ...
1
... 为了实现通信高效的联邦学习,将传统的设备到服务器通信与设备直通(device-to-device, D2D)通信相结合[8 -9 ] ,提出一种基于无线D2D网络的分层联邦学习. 依据所处的地理位置将边缘设备划分为多个簇,各个簇同时进行去中心化学习[10 ] ,通过共同训练机器学习模型来确保实现共同的学习目标. 在训练的2个全局聚合间隔期间,设备在各自的数据集上执行若干次随机梯度下降(stochastic gradient descent, SGD)迭代,通过簇内的无线D2D通信网络,设备定期地与邻居设备交换模型参数进行簇内模型聚合. 在全局聚合时,每个簇中只有一个设备需要将模型上传到服务器,这个设备被定义为簇头. 服务器根据模型平均算法,对所有簇头的本地模型进行全局聚合. 簇头的模型反映其集群经过去中心化训练后得到的本地模型的特征[11 -12 ] . ...
1
... 考虑具有一个边缘服务器和 $N$ 图1 所示. 所有设备根据地理位置的相近性被划分为 $C$ $ \left\{ {{S_1}, \cdots ,{S_C}} \right\} $ $k$ ${S_k}$ ${n_k} = |{S_k}|$ [13 -14 ] . 簇 ${S_k}$ $ {G_k} = ({S_k},{E_k}) $ ${E_k}$ ${G_k}$ [15 ] . ...
Resource allocation for D2D communication underlaid cellular networks using graph-based approach
1
2016
... 考虑具有一个边缘服务器和 $N$ 图1 所示. 所有设备根据地理位置的相近性被划分为 $C$ $ \left\{ {{S_1}, \cdots ,{S_C}} \right\} $ $k$ ${S_k}$ ${n_k} = |{S_k}|$ [13 -14 ] . 簇 ${S_k}$ $ {G_k} = ({S_k},{E_k}) $ ${E_k}$ ${G_k}$ [15 ] . ...
1
... 考虑具有一个边缘服务器和 $N$ 图1 所示. 所有设备根据地理位置的相近性被划分为 $C$ $ \left\{ {{S_1}, \cdots ,{S_C}} \right\} $ $k$ ${S_k}$ ${n_k} = |{S_k}|$ [13 -14 ] . 簇 ${S_k}$ $ {G_k} = ({S_k},{E_k}) $ ${E_k}$ ${G_k}$ [15 ] . ...
1
... 边缘设备 $i \in {S_k}$ $ {{D}_i} = \{ d_i^1,d_i^2, \cdots ,d_i^{{m_i}}\} $ . 由于簇内不存在可以与所有设备通信的中央节点,考虑在每个簇内以去中心化学习的方式训练模型. 对于边缘设备 $i \in {S_k}$ $ {N_i} \subseteq {S_k} $ ${G_k}$ [16 ] 和带宽资源分配联合优化算法. ...
Joint parameter-and-bandwidth allocation for improving the efficiency of partitioned edge learning
2
2020
... 2)簇内聚合:簇内设备进行 $\varphi $ $i \in {S_k}$ [17 ] 的方式发送到每个相邻设备 $j \in {N_i}$ ${N_i}$ $l$ $\varphi $
... 1)本地模型的计算时延:设备进行 $\varphi $ [17 ] . 计算能力越差,该计算时延越大. ...
1
... 2)D2D通信时延:为了利用设备的接近性并缩短通信时间,D2D链路用于簇内设备之间的数据传输. 设备向邻居集合 ${N_i}$ [18 ] . 所有簇内的D2D通信共用带宽 ${B^{(1)}}$ [19 ] . 假设D2D通信是使用正交频分技术进行的,不考虑簇内通信的干扰, 将 ${B^{(1)}}$ ${n_k}$ ${S_k}$ $i$ $j$ $ {h}_{i,j} $ . 设备 $i$
Adaptive subcarrier, parameter, and power allocation for partitioned edge learning over broadband channels
1
2021
... 2)D2D通信时延:为了利用设备的接近性并缩短通信时间,D2D链路用于簇内设备之间的数据传输. 设备向邻居集合 ${N_i}$ [18 ] . 所有簇内的D2D通信共用带宽 ${B^{(1)}}$ [19 ] . 假设D2D通信是使用正交频分技术进行的,不考虑簇内通信的干扰, 将 ${B^{(1)}}$ ${n_k}$ ${S_k}$ $i$ $j$ $ {h}_{i,j} $ . 设备 $i$
Energy-efficient resource management for federated edge learning with CPU-GPU heterogeneous computing
1
2021
... 簇头通过无线链路与基站相互通信,进行模型参数的传输,基站收集到所有簇头上传的数据后才能进行全局参数聚合. 为了避免链路质量差的设备被选为簇头进而限制整体的收敛速率,根据所有设备的上传时间确定一个常量 ${T^{{\text{Bound}}}}$ [20 ] ,上传时间超过上界的设备禁止被选择. 决定簇头选择的布尔变量 $ {w}_{k,i} $ ${B^{(2)}}$ ${B_k}$
1
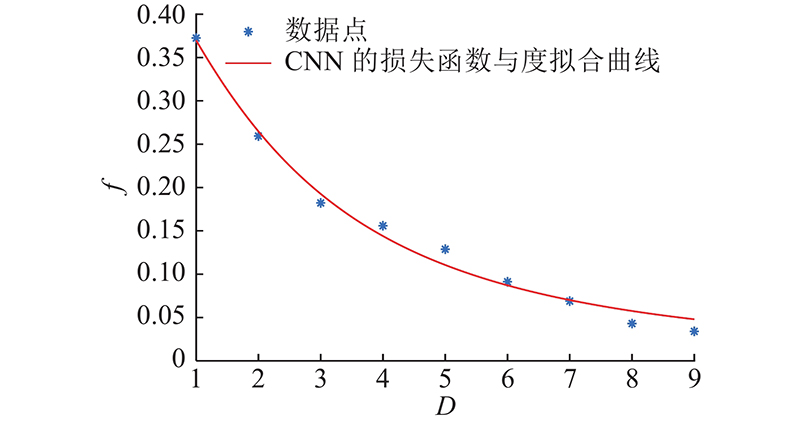
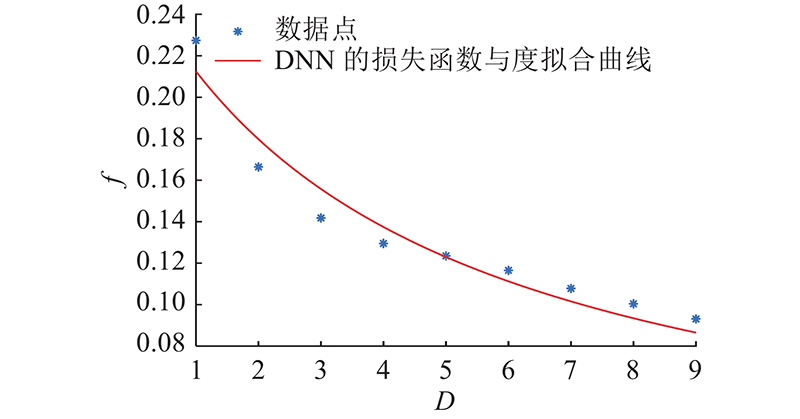
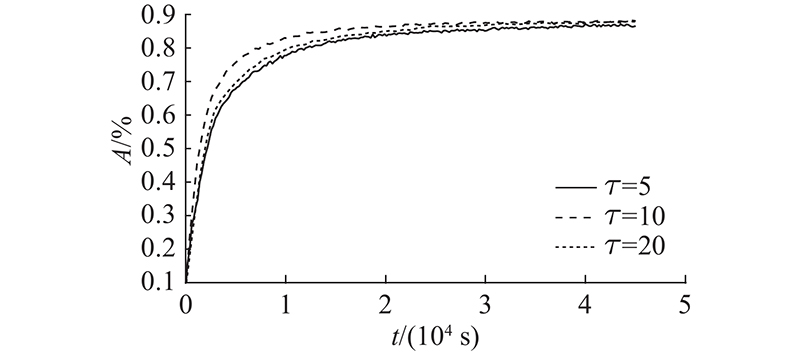
... 经过若干轮簇内去中心化训练后,选择性能好的模型上传有利于加快全局收敛. 为了提高算法的收敛速率,通过联合优化簇头的选择问题与簇头上行链路带宽分配,最大化收敛速率. 在给定的传输时间上界 ${T^{{\text{Bound}}}}$ $i \in {S _k}$ ${G_k} = ({S _k},{E_k})$ $ {D}_{k,i} $ $i$ ${D_{k,i}} = |{N_i}|$ . 设备的度越大表示在D2D网络中与该设备相连通的其他设备数量越多,在进行簇内参数聚合时可以与更多设备交换模型数据. 经过式(4)的邻域参数平均后,度越大的设备得到的本地模型越接近于簇内所有模型的参数平均值 $\dfrac{1}{{{n_k}}}\displaystyle \sum\limits_{i = 1}^{{n_k}} {\hat \omega _i^{t,l}} $ [21 ] . ...
Dynamic programming and strong bounds for the 0-1 knapsack problem
1
1999
... $ \mathcal{P}3 $ $N$ ${B^{(2)}}$ $C$ $k$ ${n_k}$ . 第 $k$ $i$ $ {D}_{k,i} $ $ {V}_{k,i} $ . 每个组中的物品只能选一件,目标是求解将某些物品装入背包使得在不超过背包容量的情况下,物品的价值最大. 使用动态规划算法对 $ \mathcal{P}3 $ [22 ] . 建立大小为 $C{{ \times }}{B^{(2)}}$ $F$ $G$ $F[k,v]$ $k$ $v$ $G(k,v)$







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}