

海量的数据和日益复杂的事务处理给现代数据库管理带来巨大挑战,单个服务器难以应对由此所带来的性能下降. 故障频发以及可生存性低等各种问题,分布式数据库应运而生. 分布式数据库的重点在于保证主备节点之间的数据一致性[1-2],因此一致性协议便是研究的重点.早期方法多采用主从库,运用主备复制[3]将主节点的数据更改操作同步到副节点.主备复制实现相对简单,但很难平衡强一致性和性能,因此便有了基于仲裁的复制状态机[4]. 目前,在基于仲裁的复制中,经典协议有Paxos[5-8]和Raft[9]协议. Paxos是保证分布式共识的经典算法,但由于其高度复杂性难于理解,许多工作都致力于简化它,使其易于理解与实现. Raft便是其中之一,它可以像Paxos一样实现强大的一致性,而且更容易执行. 因此,Raft近年来被广泛应用于各种商业系统中.
Raft协议相对于Paxos增加了诸多限制,最大的限制便是日志复制的顺序提交以及顺序执行. 在Raft中,无论是Leader向Follower传输日志还是提交日志给状态机执行,均是以串行的方式,在日志传输过程中,任何一条日志出现故障,该日志后续的日志都将被阻塞,这将极大地限制系统的并发性. 因此,对于Raft协议的并行设计成为了研究热点.
在现有研究中,Parallel Raft和DP-Raft(dependency preserved Raft)都是采用乱序提交与乱序执行日志,这2种算法在依赖性不强的事务处理中有着较好的效果,但一旦事务之间的依赖关系严重,那么它们的性能会降低到不足Raft协议性能的一半. 因此,本研究设计了并行提交Raft(parallel commit Raft,PC-Raft),在Raft的基础上对日志提交过程作重新设计,使其能够并行提交,并保持串行执行,同时解决了Parallel Raft和DP-Raft都未曾提及的幽灵复现的问题. 主要创新点如下:1)针对Raft的严格串行约束进行改进,采用并行的方式来提高日志传输的并发性. 2)选用新硬件RDMA网络,对现有网络技术进行加速,加快传输速度. 3)针对并行提交出现的幽灵日志问题提出解决方案.
1. 相关工作
一致性协议的研究一直是分布式系统中的热点. 早期著名的算法有两阶段提交[10]、三阶段提交[11]和Quorum算法[12]. 1998年诞生的著名的Basic Paxos[4]算法是对之前的算法进行结合然后开创出的一种全新的算法,该算法在理论上已经被证明可以保证分布式共识,并且是公认解决分布式问题最有效的方法之一.但是Basic Paxos没有主节点,因此每个请求都是一个新的Paxos实例,必须经过2个阶段才能被大多数人接受,这使得它无法满足实际需要中的连续请求的问题. 为了解决这个问题,许多工作都致力于Basic Paxos的变体,如Fast Paxos[13]、Multi-Paxos[14]、ZAB[15]和Epaxos[16]等.
针对Paxos变体的研究一直在进行,但是目前的所有变体均是难以理解并正确执行的. Raft算法[9]便是为了易于理解而设计的,它将协议分为领导者选举和日志复制2个阶段,并加强了日志项之间的串行约束,从而简化了协议的设计. 这使得Raft比Paxos协议更易于理解,因此在业界得到广泛的应用. Raft算法最大的缺点是其严格约束的串行性限制了分布式系统的并发性,因此很多工作致力于改进Raft的并发性.
PloarFS[31]提出了支持并行日志提交与执行的Parallel Raft. Parallel Raft在每个日志条目中记录前N个日志条目修改的LBA(逻辑块地址)信息,从而在事务处理中避免了读写冲突,但LBA的存在使得内存与网络带宽有较大的损耗. DP-Raft[32]对Parallel Raft进行了改进,取消记录LBA信息,转而建立日志间的依赖关系,以此判断日志间的读写冲突. 该方法使得内存和网络带宽的消耗得到降低,从而提高了日志提交与执行时的速度,提升了整体性能. 该方法的缺点是,在事务依赖较严重的情况下,事务一直围绕着某些数据不停地做改动,如对公式中的变量不停赋值,此时Parallel Raft和DP-Raft的性能在此场景下都将严重降低,甚至远低于Raft的性能. 因此,Parallel Raft和DP-Raft都不适用于事务依赖严重的场景.
2. 并行提交与串行执行
Raft的日志复制过程如图1所示,在选出一个Leader之后,该Leader会向客户端请求服务.客户端的请求为具体的将交由状态机执行的指令,节点会将这些指令先存入日志,再交由状态机执行. Raft中Leader先将指令存入自己的本地日志中,再复制到Follower节点,Follower在接收时采用顺序执行的方式,将逐条日志写入自己的日志缓存中,得到多数派承认的则提交到状态机去执行具体的指令.
图 1
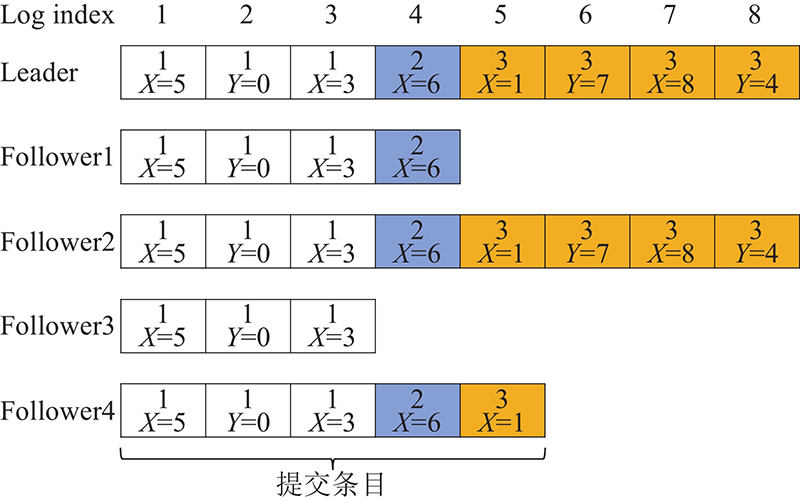
Follower的顺序接收日志必然会导致日志复制性能的下降,因此为了提高日志复制的性能,须更改其约束使其能够并行地接收日志. 在Raft协议的日志传输中引入流水线技术,并通过改变Raft协议原有串行设计使其能够并行传输日志,如图2所示. 在日志复制的过程中,Raft是串行复制的,因此不需要额外的操作,而在并行复制中,则须对日志的位置进行定位,以便在复制时保证最终Follower节点的日志顺序与Leader是一致的. 因此,在日志中还须加入每条日志的起始地址,在传统网络下必须要有这一步骤,但在RDMA网络下,由于RDMA执行write操作时是通过虚拟地址获取响应端物理地址,并直接写入响应端内存的,因此可以在日志中省去写入起始地址这一操作.
图 2
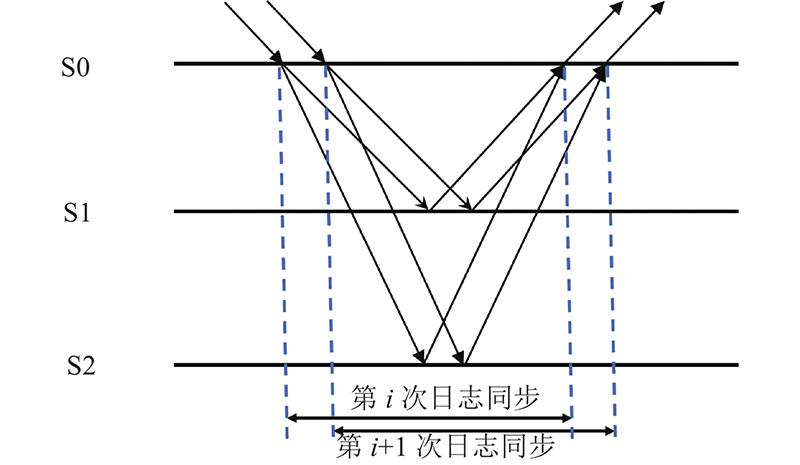
在日志的并行复制过程中,若客户端源源不断有日志写入而导致日志数量巨大,此时若开始位置的日志有缺失,则后面的日志将被阻塞得不到应用,必然会导致系统性能的下降. 因此,在日志复制过程中,对每一次复制的日志数量进行限制,若一次复制的日志量超过限定值,则对后面的日志阻塞,当前面的日志全部传输完成之后再恢复传输.
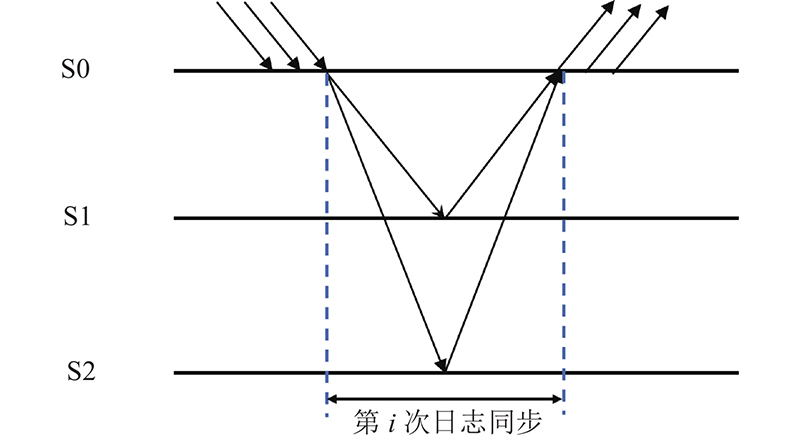
在日志执行的过程中,采用批处理的方式,如图3所示. 将传输完成的所有日志进行打包,通过批处理方式一次全部应用到状态机,交由状态机顺序执行.
图 3
3. Parallel Commit Raft
本研究提出一个Raft协议的改进版, PC-Raft,对Raft的串行提交策略进行并行化改进.在日志提交的过程中,由Raft的串行化设计改为并行化设计,并在应用执行的过程中依旧遵循Raft的串行应用原则. PC-Raft对日志复制的并行化设计,使得服务器之间的传输更高效,更有利于网络带宽的利用,因此,对于日志复制延迟的降低有着显著的提升. PC-Raft的详细设计包括日志复制与领导者选举.
3.1. PC-Raft结构
在PC-Raft中,首先为每一条日志分配一个日志序号. 针对事务处理中会出现的幽灵复现问题,对日志序号采取二维数组的方式记录. 所谓幽灵复现即分布式系统中的第三态问题,也就是事务处理在成功与失败之间诞生了一个未知的状态.
如表1所示为幽灵复现的示例. 在第1轮,A成为指定Leader,发出第1~8条日志,但只成功了前3条,后面第4~8条没有形成多数派,随后A宕机. 在第2轮,B成为指定Leader,继续发出第4~10的日志(此时B不会看到有之前A发出的第4~8日志的存在),这次,只有第4、5以及第10这3条日志形成了多数派,提交之后B也宕机. 在第3轮,节点A再次当选为Leader,从多数派中接收到的最大日志序号为10,因此需要补空洞,此时第1~5和第10条日志填补没有问题,第9条日志因为没有多数派确认,会以空洞填补;但第6~8条日志会出问题,在没有限制的情况下A会以自己第1轮的第6~8条日志进行填补,而之前的日志已经过期了,因此填补之后势必会出问题. 这便是所谓的幽灵复现,也称为幽灵日志.
表 1 幽灵复现示例
Tab.1
| 轮次 | Leader | A | B | C |
| Round 1 | A | 1~8 | 1~3 | 1~3 |
| Round 2 | B | Down | 1~5,10 | 1~5,10 |
| Round 3 | C | 1~10 | 1~10 | 1~10 |
在Raft协议中,针对幽灵复现采取栏杆日志的方式,如图4所示. 在第2轮中,Leader宕机,此时所有Follower节点将在日志中加入一条栏杆日志以作区分,此时原先的Leader将无法再次竞选Leader,除非它将栏杆日志后面的日志全部删除掉.
图 4
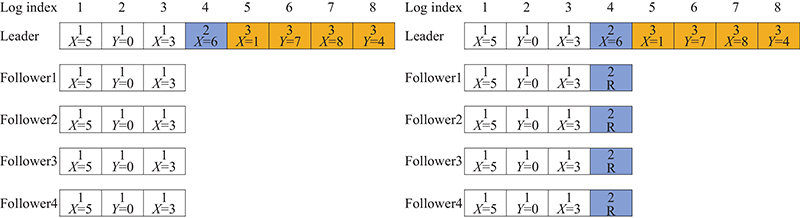
在Parallel Raft和DP-Raft中,均未对幽灵复现的问题加以描述,而在PC-Raft中,为了解决幽灵复现问题,在日志条目中,采用二维数组的方式对日志进行编号. DP-Raft中简单列出了一个递增的日志编号LSN对日志编号,本研究在此基础上加上节点的任期号,以二维数组(任期号,LSN)的方式为每一条日志分配一个唯一的日志序号. 每一个事务在进入提交阶段时,都将获得一个日志序号. 当面临幽灵复现的问题时,首先会对比日志的任期号,若任期号落后,则表明这是条旧日志. 此时面对新的任期时,则须将旧的任期的日志进行删除,以此来避免幽灵复现的问题.
PC-Raft的日志缓冲区采用环形Buffer结构设计,即环形设计. 在每个节点中都拥有这样一个日志缓冲区. 在日志存储时按照各自的地址位置进行存储,在Raft协议中,日志传输是按照串行的方式进行传输的,因此传输过程中只须记录整个日志块的首尾地址信息以及已提交的日志地址和已经应用的日志地址. 在日志并行传输中,Follower节点在接收日志的过程中会出现日志空洞,为了确保日志空洞不会影响系统整体的安全性,此时会出现如下2个问题. 1)在日志传输过程中,当日志量剧增时,复制大量存在,如果某条前面的日志传输失败,从而在Follower中留下日志空洞,而后面的日志仍在继续复制,那么将导致日志应用阻塞;2)在日志传输完成时,若日志中存在日志空洞,系统未经检查就整体打包提交给状态机执行,将会导致日志执行时出错.
为了解决这2个问题,对日志缓冲区的结构进行重新设计. 如图5所示,在Leader节点中,采取5个指针:L-Head、L-Tail、L-Commit、L-Apply和L-Lock来帮助完成这一过程. L-Head为头指针,用于记录第1条日志的起始地址;L-Tail为尾指针,用于记录最后一条日志的起始地址;L-Commit为提交指针,用于记录已经提交的日志的起始地址,即已经发送给Follower节点的日志中的最后一条日志;L-Apply为应用指针,用于记录已经应用的日志的起始地址,即已经提交给状态机执行的日志中的最后一条日志;L-Lock指针则是为了应对之前提出的第1个问题,当日志量巨大时,为了阻止因前面的日志空洞而出现日志应用阻塞的问题,采取对日志一次传输的数量进行限制的方法.
图 5
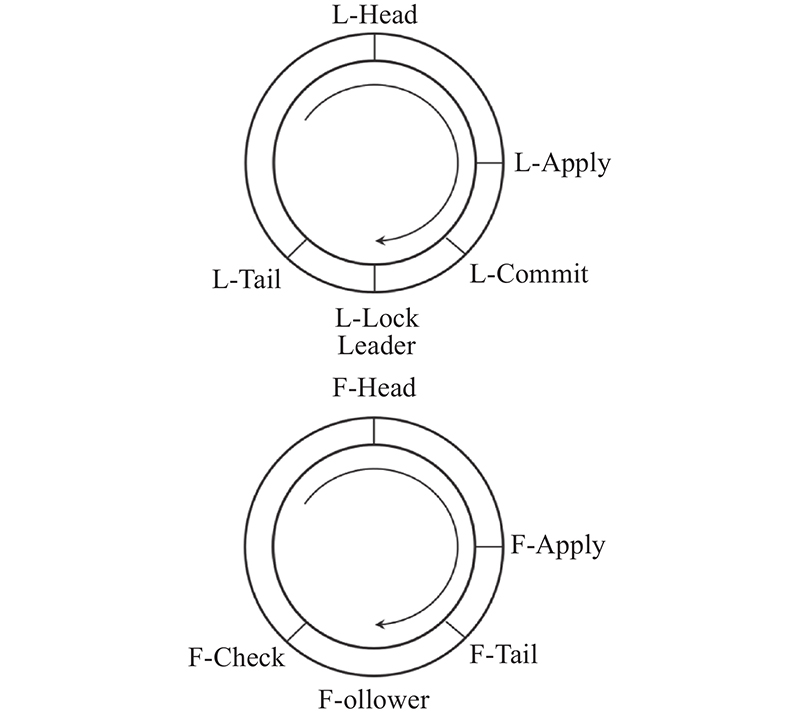
当Leader发送日志时,一次只发送N条日志,而L-Lock则指向这N条日志中的最后一条日志起始地址. L-Lock指针的指向在即将开始发送日志的时候便计算出来,然后迅速指向环形Buffer中的地址,当日志传输到这时,将起到一个锁的作用,阻止Leader继续发送下面的日志. 在Leader节点中,因为Leader是日志复制的发送方,用5个指针来记录Leader日志复制的整个过程.
在Follower中,因为它与Leader的属性不同,在其日志结构中删去L-Commit和L-Lock指针,同时加入F-Check指针. 删去L-Commit指针是因为Follower节点无须发送日志,也就无须记录日志已经提交了多少.删去L-Lock指针也是因为Follower节点无须发送日志,无须对其采取锁的措施. 加入F-Check指针则是为了应对之前提出的第2个问题,即日志整体打包发送给状态机执行时日志之间可能存在日志空洞的问题. 针对日志的串行执行,采用批处理的方式,将一次复制完成的日志整体打包提交给状态机去执行,同时须对此时日志间存在的日志问题进行规避. 采取措施为加入F-Check指针, 当Leader一次传输的日志结束后,Follower节点在2个心跳内未接收到日志信息时,F-Check便开始挨个检查每一条日志,当发现日志没有缺失时,F-Check指针指向最后一条日志,否则将告知Leader某一条日志缺失,请求重新发送. 当大多数Follower节点F-Check指针均指向最后一条日志时,Leader将这一次发送的所有日志全部提交给状态机执行.
3.2. 日志复制
在Raft协议的日志复制过程中,Leader在每次传输日志时会将commitIndex一并发送给Follower,用于告知该条日志目前的提交状态,即是否已经提交给状态机. 因为Raft的串行提交与执行,commitIndex一般为逐条递增.在PC-Raft中,同样以commitIndex来记录日志的提交状态,不同的是,PC-Raft并行提交日志且批量应用,因此commitIndex一般一次增加多个数值. 如图6所示. 在Raft中,当一个Follower收到一个新的日志条目的请求时,须先检查最后一个日志条目是否与Leader中相同位置的日志条目相同,以此来确保它与Leader的一致性. 检查成功后,Follower将接受新的日志条目,否则,前一条日志条目丢失,它将一直等到前一条日志被确认. 这种检查确保了Raft的Log Matching属性,这是保证Raft安全的属性之一.
图 6
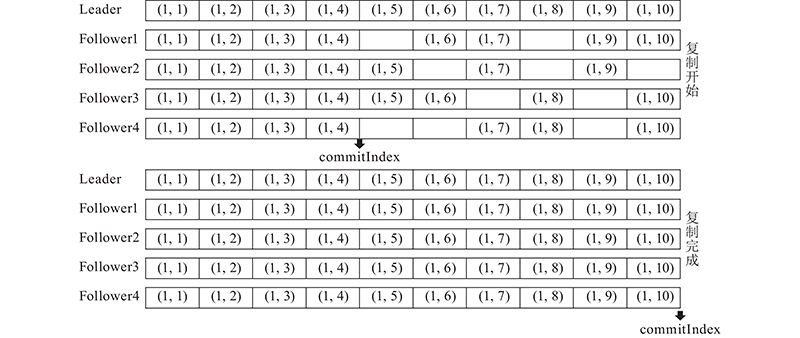
在PC-Raft中,不允许出现日志空洞的约束将被取消,因为日志复制的并行执行允许该过程中Follower中存在日志空洞. 在日志复制过程中,只须在开始第1条日志复制时对比Follower的最后1条日志与Leader中的对应位置是否一致,其余时刻,当Follower节点的日志复制成功后,便迅速反馈给Leader一个确认,即便前面的日志有缺失. 在日志传输中断后,重新开始传输时,再一次检查Follower的最后1条日志与Leader中的对应位置是否一致.在此过程中,Raft采取逐条检查的方式,而PC-Raft则采取隔N条日志条目检查一次的方式,因此日志复制的延迟会显著降低.
Parallel Raft和DP-Raft均采用并行执行的方式,在事务依赖较弱条件下,并行执行更快,但数据库的事务之间往往存在着各种联系,在Parallel Raft中采用记录日志条目的前N个日志的写块地址来分辨日志间是否存在联系,DP-Raft则是采用对日志建立依赖关系的方式来分辨日志间是否有联系.这些操作会增加系统的计算量,同时增加日志的长度,在传输时会牺牲带宽. 在数据库事务之间依赖性较弱的情况下,其损耗相比于其提升的性能可以忽略不计,但在事务之间存在强依赖性的情况下,其性能下降明显. 因此, PC-Raft采用Raft串行执行的方式,确保在无论事务依赖性强或者弱的应用场景下,PC-Raft的性能相对于Raft和Parallel Raft以及DP-Raft依然有显著的提升.
3.3. 领导者选举
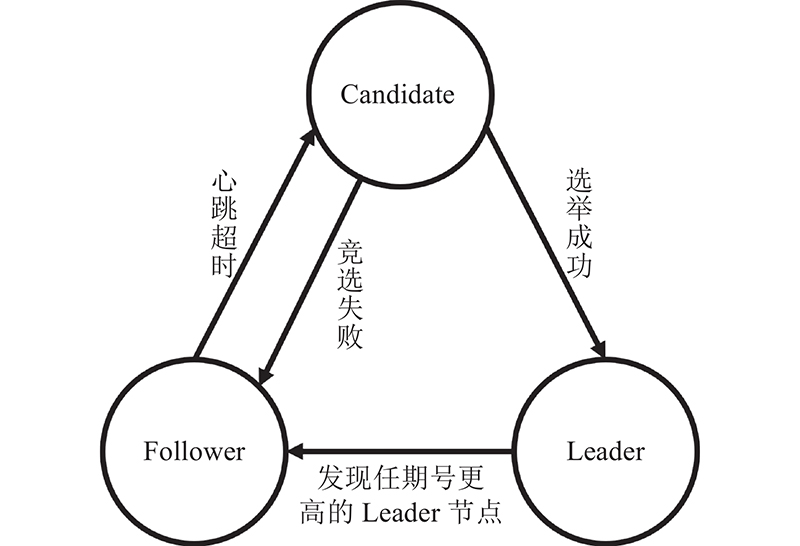
在Raft协议中,Leader节点永远拥有着最新的以及完整的日志,这个特性在领导者选举的过程中也有着显著的帮助. 当领导者宕机时,将在Follower中选出一个新的Leader,此时,拥有最多最新日志的Follower将成功被选举为Leader,而新选出的Leader也将拥有最新且完整的日志,中间不会存在日志空洞.在PC-Raft中,由于并行提交的原因,当Leader宕机时,Follower中可能会出现日志空洞. 此时,Leader的选举将变得较复杂,且当新的Leader选出时,有可能因其存在日志空洞而无法立刻提供Leader的服务. 此时的Leader将会是一个不完整的临时Leader. 因此,须先对新选出的Leader进行日志恢复,等到它成为一个完整的Leader时,再让它提供真正的Leader服务. 节点的状态变迁如图7所示.
图 7
Leader竞选如图8所示. 在Leader宕机之后,Follower节点接收不到Leader的心跳信息,此时会有多个Follower开始竞选Leader. 为了避免多个Follower同时竞选Leader,系统会为每个Follower随机分配一个election timeout,当一个Follower等待时长超过election timeout之后,它便转化为Candidate开始竞选Leader.
图 8
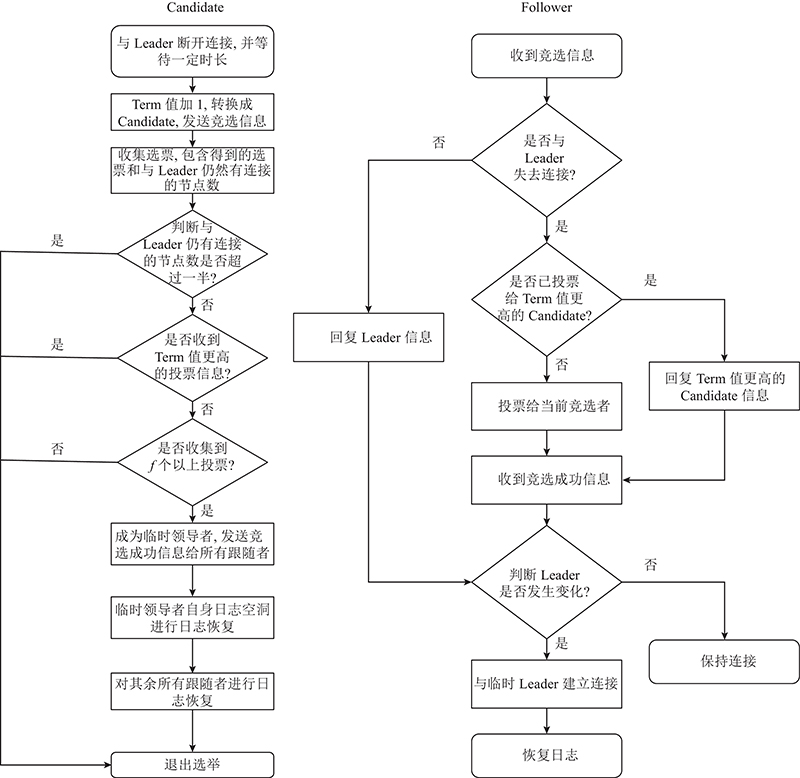
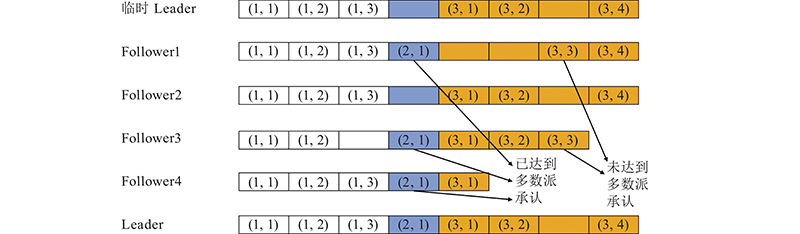
1)当其他Follower接收到Candidate的竞选请求时,Follower先比较自己和Candidate的日志条目数量以及任期号,任期号显示Candidate的日志是否为最新的. 若Candidate的任期号更新且日志条目数量更多,Follower便将自己的选票投给Candidate. 2)当Follower与Candidate的日志条目的数量一样多时,则比较双方最新接收到的一条日志的序号,如Candidate更新,则Follower投票,否则拒绝. 以此循环选举,最终选出一个任期号最新,且拥有的日志条目最多的Follower成为临时Leader. 经过这2步选举之后,成功当选临时Leader的日志条目最多且足够新,此时进行日志恢复时所需要的时间更短,效率更高.
在选出临时Leader之后,须对其进行日志恢复,即对临时Leader中可能存在的日志空洞进行修复. 在PC-Raft的并行日志传输过程中,所有正在传输的日志必然都是未曾应用到状态机的,因为PC-Raft规定在一定数量日志都复制完成后统一打包发送给状态机. 因此,在日志恢复过程中,本研究采取日志多数派确认的策略. 首先对于临时Leader已有的日志条目都将予以保留,对于空洞的部分,则在Follower中寻找,若有一半Follower中拥有该条日志,则将该条日志复制过来,否则不复制,临时Leader中以空洞保留.
如图9所示,日志条目(2,1)达到了多数派确认,因此将其复制到临时Leader. 而日志条目(3,3)未达到多数派确认,因此不进行复制,最终Leader中的(3,3)位置的日志以空洞存在. 最后,对于空洞内的日志,Leader会请求客户端对该条日志内的指令重新发送一次,以此完善整个日志存储.
图 9
4. 实验与结果分析
在实验中,将数据库原型机部署在5台机器上面,每台机器都配备了2插槽的Intel Xeon Silver 4110 @ 2.10 GHz处理器和256 G的DRAM,由10 GB交换机连接. 对比Raft协议、Parallel Raft协议与DP-Raft协议,并采用YCSB[33]对3种方法进行评价. 最后,选取其中有代表性的场景进行选举对比,并选取其中有代表性的数据进行分析.
4.1. 复制性能对比
首先是对YCSB工作负载下的吞吐量和延迟进行测量. 所有方法都有3个副本,通过改变客户机号来查看复制性能.
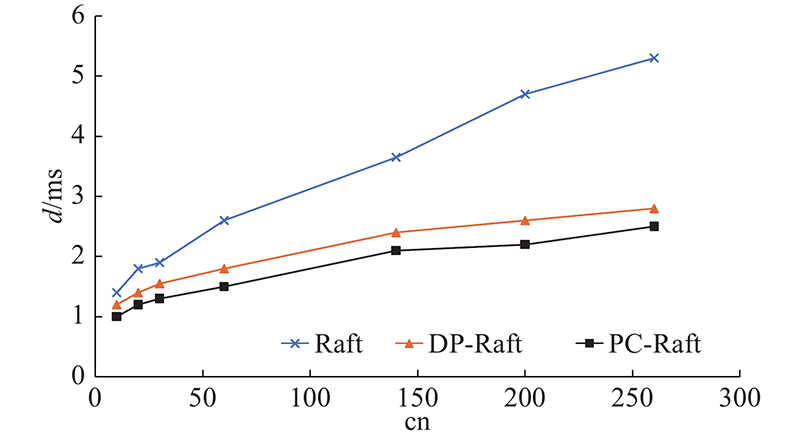
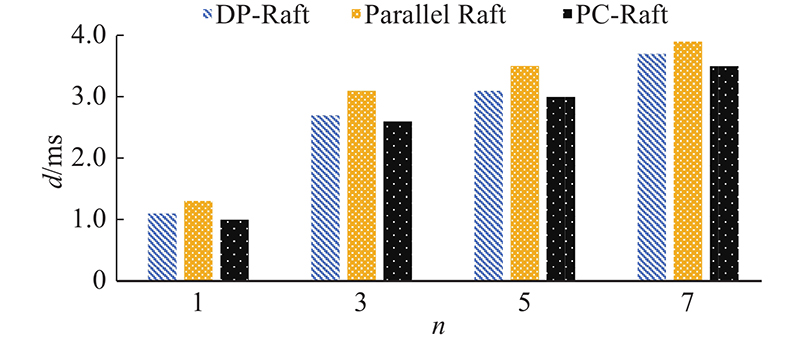
在客户端数量cn增加之后, Raft、DP-Raft和PC-Raft的吞吐量b变化如图10所示. 在客户端数量增加后,以上3种算法的复制延迟d的变化如图11所示. 在复制性能上,PC-Raft要明显好于Raft与DP-Raft. 因为在复制的过程中采用了并行复制,PC-Raft的性能好于Raft. 在与DP-Raft的比较中,因为PC-Raft无须建立依赖项,在日志中无须存储依赖性信息,从而节省了建立依赖项所需的计算和传输时的带宽,降低了传输过程中的网络消耗.所以在复制的过程中,相对于DP-Raft也同样性能优越. 在延迟方面,PC-Raft也比Raft和DP-Raft更优一些. 原因如下:传输时PC-Raft无须像Raft一样按严格地顺序执行,延迟比Raft的更低;PC-Raft无须像DP-Raft一样事先建立依赖项,且在日志中也不会加入依赖项,省去了一些计算与网络传输的开销,因此延迟比DP-Raft的更低.
图 10
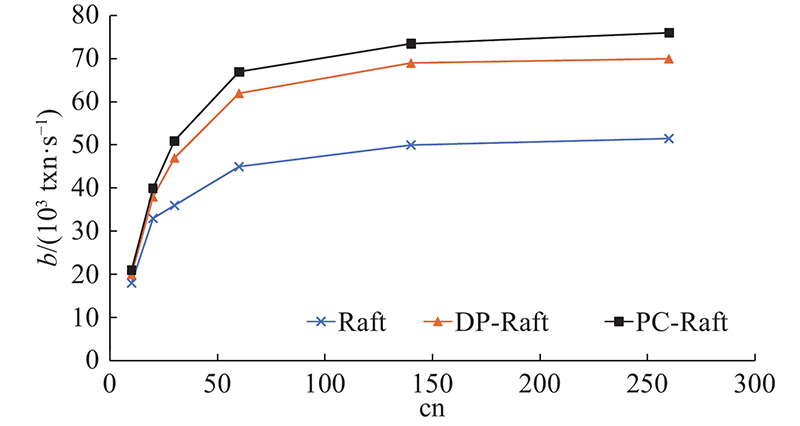
图 11
4.2. 倾斜负载对比
PC-Raft重点是针对高并发的依赖性较强的事务环境,在事务依赖性一般的环境下不如并行执行的DP-Raft. 在依赖性较强的环境下的吞吐量如图12所示.可以看出,随着倾斜负载θ的不断增加,PC-Raft的性能更加优于Raft和DP-Raft的.
图 12
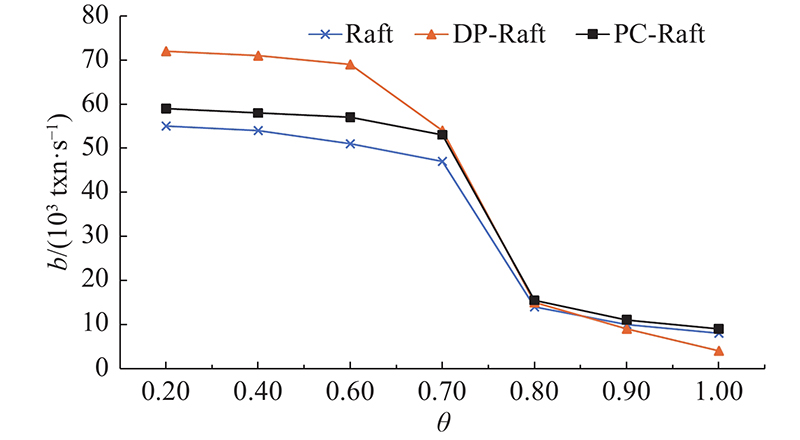
当事务依赖性越来越强,3个协议的性能均出现大幅度下滑,而DP-Raft下滑最严重,因为事务之间的依赖性越来越重,只能串行执行事务.当倾斜接近1的时候,DP-Raft的性能只剩下PC-Raft的约30%. 如图13所示为数据倾斜对性能的影响. 图中,bs为吞吐率. 可以看出,DP-Raft与PC-Raft的性能差异,在倾斜负载达到0.7以后,DP-Raft的性能下滑越发明显,与PC-Raft的差距显著增大. 此时PC-Raft的性能是优于Raft的,因此在事务依赖性极强的环境下,PC-Raft有着较好的效果.
图 13
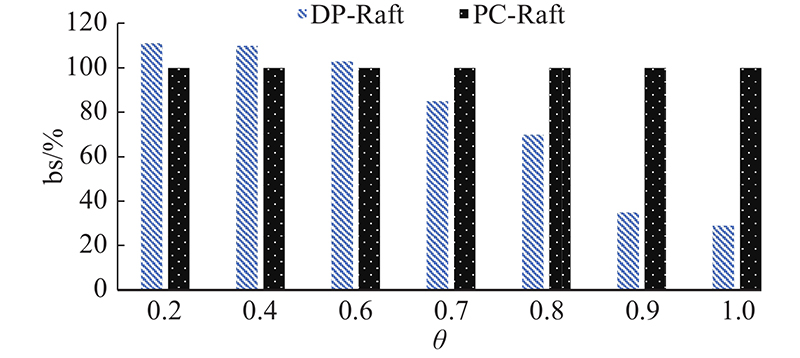
图 14
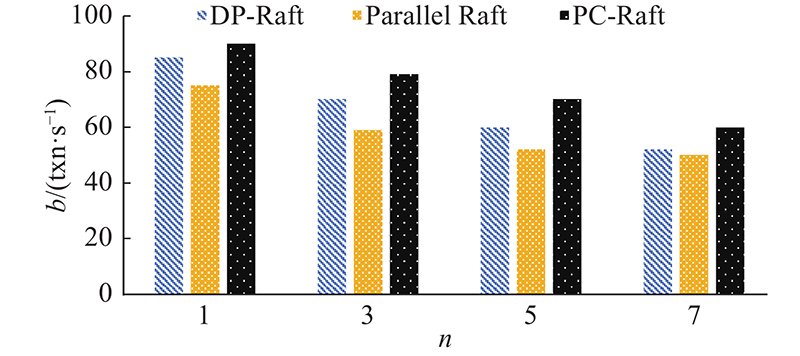
图 15
5. 结 语
针对Raft的串行化设计提出并行提交的改进措施,以此提出了新的Raft变体,PC-Raft. PC-Raft针对Raft只能串行提交日志的缺点进行改进,在Raft的基础上实现日志的并行提交. 该协议针对特定场景设计,实现并行提交之后的串行执行. 实验证明PC-Raft在日志复制的过程中有着较好的性能,并且在事务依赖性较强的条件下,比现有的其他Raft变体的协议性能更好.
不过,在数据依赖性并不强的情况下,PC-Raft的性能依然有巨大的提升空间. 很多时候,Raft的限制主要源于对安全性的考虑,即保证读写时的正确执行. 若是能将读写分离,便可去除读写依赖所带来的性能影响,这将是进一步研究的热点问题.
参考文献
Concurrency control and consistency of multiple copies of data in distributed INGRES
[J].
Implementing fault-tolerant services using the state machine approach: a tutorial
[J].DOI:10.1145/98163.98167 [本文引用: 2]
PaxosStore: high-availability storage made practical in WeChat
[J].DOI:10.14778/3137765.3137778 [本文引用: 1]
Fast paxos
[J].DOI:10.1007/s00446-006-0005-x [本文引用: 1]
Rethinking database high availability with RDMA networks
[J].DOI:10.14778/3342263.3342639 [本文引用: 1]
Research on the consensus of big data systems based on RDMA and NVM
[J].
Phase change memory for automotive grade embedded NVM applications
[J].
A review of emerging non-volatile memory (NVM) technologies and applications
[J].
PolarFS: an ultra-low latency and failure resilient distributed file system for shared storage cloud database
[J].DOI:10.14778/3229863.3229872 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}