

尽管现有的深度聚类方法已经从不同方面进行了改进,但它们仍然普遍存在以下一个或多个问题:1) 大多数的方法只考虑了图的全局表示和节点表示是否来自同一个网络,并未探索节点属性信息和节点表示之间的关系,而节点的属性信息往往包含着关于节点的核心信息,研究它们之间的关联性有助于学习到的低维表征捕获更多有用的判别信息. 2) 现有的大多数方法只考虑了直接相连的邻居节点,由于图的稀疏性,2个相似度较高的节点可能没有边直接相连,如果没有考虑它们之间的关系,将会削弱低维表征的可靠性[10]. 3)现有方法无法从不精准的预测标签中获益. 虽然部分预测标签存在错误,但具有高置信度的预测标签可以传播有用的信息,指导低维表征的学习.
针对深度聚类相关研究的局限性,本研究提出一种高阶互信息最大化与伪标签指导的深度聚类模型(high-order mutual information maximization and pseudo-label guided deep clustering, HMIPDC). 1) 该模型通过高阶互信息最大化策略和自注意力机制充分融合图中的多种信息,借此生成可靠的低维表征,进而利用基于深度散度的聚类损失函数(deep divergence-based clustering, DDC)[11]和伪标签来迭代优化聚类目标. 2)利用多跳邻近矩阵更为准确地捕捉节点之间的拓扑相关性,并结合自注意力机制帮助目标节点更加合理地聚合邻居节点. 然后采用一种动态信息融合机制对学到的低维表征中的图结构和属性信息进一步融合. 3) 提出一种新颖的自监督训练策略. 该策略首先使用DDC算法来衡量聚类损失,然后从模型迭代过程产生的预测标签中选择置信度较高的标签,并将其作为伪标签来对模型进行反向监督,从而提升聚类性能.
1. 相关工作
1.1. 深度聚类
1.2. 互信息
2. 相关符号及定义
给定一个具有
定义1 互信息[21]. 给定2个随机变量
式中:
定义2 高阶互信息[22]. 高阶互信息是对大于等于3个随机变量之间的互信息的一种描述. 可以用类似于互信息的定义来表示高阶互信息,其定义如下:
式中:
3. HMIPDC模型设计
HMIPDC模型首先利用互信息监督模块对高级特征表示
图 1
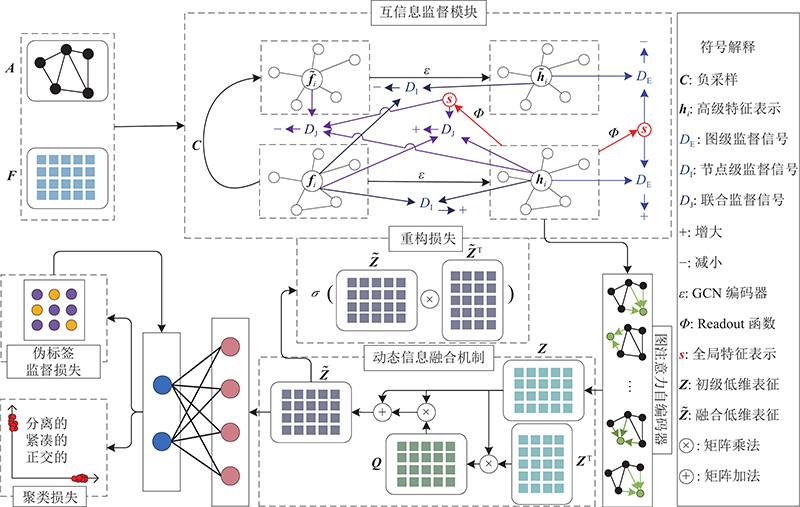
3.1. 互信息监督模块
为了充分挖掘图中节点之间的相关性,让网络提取到更适合下游任务的低维表征,采用一种高阶互信息最大化策略[21],通过将高级特征表示
3.1.1. 高级特征表示
通过不断聚合与目标节点
式中:
3.1.2. 全局特征表示
选择
式中:
3.1.3. 高阶互信息
由于考虑的是3个随机变量之间的互信息,故有
式中:
式中:
进一步考虑高阶互信息:
式中:
1)对于
式中:
2)对于
式中:
3)对于
式中:
4)最终的监督信号以最大化以下公式为目标:
3.2. 图注意力自编码器
为了判断每个邻居节点对于目标节点的重要程度,在逐层图注意力策略中对不同邻居节点表示赋予不同的权重:
式中:
1)拓扑距离. 邻居节点通过邻边来表示目标节点. 为了更好地挖掘图中节点之间的相关性,在图注意力自编码器中使用
式中:
2)属性信息. 注意力系数
式中:
为了使原来没有可比性的数据变得具有可比性,同时又能保持不同数据之间的相对关系,采用
再加上拓扑权重
3.3. 动态信息融合机制
为了进一步提炼从图注意力自编码器中学习到的初级低维表征
1)使用自相关学习机制让
计算自相关系数矩阵并进行归一化得到
探讨节点之间的全局相关性来修改
2)为了保证样本空间在进行多次变换后,仍能保持其核心特征,采用跳跃连接让节点信息可以通过动态信息融合机制顺利传递:
式中:
由于
式中:
3.4. 目标函数
HMIPDC的目标函数由3个部分组成,即图注意力自编码器的重构损失、聚类损失以及伪标签监督损失.
3.4.1. 重构损失
通过二元交叉熵计算
通过降低重构误差可以尽可能地保留数据固有的局部结构.
3.4.2. 聚类损失
使用DDC[11]算法来衡量聚类损失,该算法用概率密度函数对每个簇进行建模并优化聚类分配,然后采用信息论中的CS散度(Cauchy-Schwarz divergence)来最大化它们的概率密度函数之间的差异,使得网络能够通过梯度下降方法优化其权重并学习输入图的内在簇结构.
其聚类损失函数主要由3个损失项组成.
1)第1个损失项主要考虑数据聚类在低维表征空间的可分离性和紧凑性约束,其源自CS散度的多重概率密度函数泛化,用来保证不同簇中的节点之间的相似度较小,而同一簇中的节点之间的相似度尽可能的大. 第1个损失项表达式如下:
式中:
2)第2个损失项要求不同节点的聚类分配在低维特征空间是向量正交的,从而避免聚类结果陷入局部最优解,防止聚类划分结构的退化;当且仅当矩阵的内积为零时,簇分配向量是正交的. 第2个损失项表达式如下:
式中:
3)第3个损失项试图把簇分配向量推向标准单纯形空间的拐角附近,通过位于标准单纯形拐角处的理想聚类中心中的相似点分组来分离数据点. 第3个损失项表达式如下:
式中:
4)模型训练期间的聚类损失可以表示为这3个损失项的总和:
3.4.3. 伪标签监督损失
伪标签监督损失函数[24]的设计同时兼顾了正伪标签和负伪标签.
1)获取伪标签.
直接从每次模型训练的预测标签中选择正伪标签:
式中:
用相似的方法从模型预测的结果中选择负伪标签:
式中:
使用
2)计算伪标签监督损失.
使用交叉熵损失来表示正伪标签监督损失:
式中:
借用正伪标签的交叉熵损失函数设计出负伪标签的损失函数:
结合式(29)、(30)的损失函数,得到最终的伪标签监督损失:
3.4.4. 优化
联合式(21)、(25)、(31),得到最终进行优化的目标函数:
式中:
4. 实验结果及分析
4.1. 数据集
表 1 4个基准数据集的统计信息
Tab.1
| 数据集 | | | | |
| ACM | 3 025 | 3 | 1 870 | 13 128 |
| Citeseer | 3 327 | 6 | 3 703 | 4 552 |
| DBLP | 4 057 | 4 | 334 | 3 528 |
| AMAP | 7 650 | 8 | 745 | 119 081 |
4.2. 基线方法
1)K-means[25]:一种基于原始数据的传统聚类方法,先为节点分配初始的聚类中心,并通过不断的迭代来优化聚类.
2)AE[5]:一种分2步走的深度聚类方法,先用自编码器学习到低维表征,再将其用于后续的聚类任务.
3)IDEC[4]:一种联合深度聚类方法,通过同时学习低维表征和聚类分配来迭代优化聚类目标.
4)GAE[14]:一种使用GCN来学习低维表征的深度图聚类方法.
5)DAEGC[8]:通过引入自注意力机制来学习低维表征,并使用聚类损失来监督图聚类过程.
6)SDCN[9]:有效地联合AE和GCN模块来更好地学习低维表征,并设计了一个双重自监督机制来监督聚类过程,指导整个模型的优化.
7)DFCN[16]:设计了一种基于相关性来学习结构与属性信息的融合模块,用来合并AE和GAE学到的低维表征,并提出了一种三重自监督机制为信息融合提供可靠的指导.
8)DCRN[17]:通过双重方式来降低信息的相关性,从而提升特征区分能力,并且引入了传播正则化来缓解表示崩溃,使得网络能够以浅层网络结构获得长距离信息.
4.3. 评价指标
4.4. 参数设置
所有的实验都是基于Pytorch深度学习框架实现并完成的,并且运行在Ubuntu 18.04.6上,使用的CPU是i9-11900K,GPU是NVIDIAGeForce RTX 3090. 对于DAEGC,按照原始论文[8]的设置处理论文实验所涉及的各种参数和实验环境,借此来重现源代码;为了防止出现极端情况,将该论文实验重复运行了10次并获得平均值和相应的标准差. 对于其他的基线方法,直接使用DCRN中列出的相应结果. 对于HMIPDC,ACM使用学习率为0.001的Adam[29]算法来优化高级特征表示,Citeseer、DBLP和AMAP使用的学习率为0.0001,并且都采用提前停止策略来避免过拟合,之后再将所有数据集的学习率修改为0.01来进一步优化模型. 根据参数敏感性测试的结果,将所有数据集里用于平衡损失函数的超参数
4.5. 聚类结果
表 2 HMIPDC和8种基线方法在4个数据集上的聚类结果
Tab.2
| % | |||||
| 数据集 | 方法 | ACC | NMI | ARI | F1 |
| ACM | K-means | 67.31±0.71 | 32.44±0.46 | 30.60±0.69 | 67.57±0.74 |
| AE | 81.83±0.08 | 49.30±0.16 | 59.64±0.16 | 82.01±0.08 | |
| IDEC | 85.12±0.52 | 56.61±1.16 | 62.16±1.50 | 85.11±0.48 | |
| GAE | 84.52±1.44 | 55.38±1.92 | 59.46±3.10 | 84.65±1.33 | |
| DAEGC | 88.24±0.02 | 63.01±0.04 | 68.70±0.04 | 88.11±0.01 | |
| SDCN | 90.45±0.18 | 68.31±0.25 | 73.91±0.40 | 90.42±0.19 | |
| DFCN | 90.90±0.20 | 64.40±0.40 | 74.90±0.40 | 90.80±0.20 | |
| DCRN | 91.93±0.20 | 71.56±0.61 | 77.56±0.52 | 91.94±0.20 | |
| HMIPDC | 92.12±0.15 | 72.18±0.52 | 78.04±0.39 | 92.13±0.14 | |
| Citeseer | K-means | 39.32±3.17 | 16.94±3.22 | 13.43±3.02 | 36.08±3.53 |
| AE | 57.08±0.13 | 27.64±0.08 | 29.31±0.14 | 53.80±0.11 | |
| IDEC | 60.49±1.42 | 27.17±2.40 | 25.70±2.65 | 61.62±1.39 | |
| GAE | 61.35±0.80 | 34.63±0.65 | 33.55±1.18 | 57.36±0.82 | |
| DAEGC | 64.90±0.07 | 38.71±0.08 | 39.21±0.09 | 59.56±0.06 | |
| SDCN | 65.96±0.31 | 38.71±0.32 | 40.17±0.43 | 63.62±0.24 | |
| DFCN | 69.50±0.20 | 43.90±0.20 | 45.50±0.30 | 64.30±0.20 | |
| DCRN | 70.86±0.18 | 45.86±0.35 | 47.64±0.30 | 65.83±0.21 | |
| HMIPDC | 71.93±0.31 | 46.07±0.23 | 48.28±0.50 | 66.96±0.26 | |
| DBLP | K-means | 38.65±0.65 | 11.45±0.38 | 6.97±0.39 | 31.92±0.27 |
| AE | 51.43±0.35 | 25.40±0.16 | 12.21±0.43 | 52.53±0.36 | |
| IDEC | 60.31±0.62 | 31.17±0.50 | 25.37±0.60 | 61.33±0.56 | |
| GAE | 61.21±1.22 | 30.80±0.91 | 22.02±1.40 | 61.41±2.23 | |
| DAEGC | 67.42±0.38 | 30.64±0.46 | 32.79±0.58 | 66.89±0.37 | |
| SDCN | 68.05±1.81 | 39.50±1.34 | 39.15±2.01 | 67.71±1.51 | |
| DFCN | 76.00±0.80 | 43.70±1.00 | 47.00±1.50 | 75.70±0.80 | |
| DCRN | 79.66±0.25 | 48.95±0.44 | 53.60±0.46 | 79.28±0.26 | |
| HMIPDC | 80.34±0.16 | 49.41±0.34 | 55.39±0.28 | 79.76±0.32 | |
| AMAP | K-means | 27.22±0.76 | 13.23±1.33 | 5.50±0.44 | 23.96±0.51 |
| AE | 48.25±0.08 | 38.76±0.30 | 20.80±0.47 | 47.87±0.20 | |
| IDEC | 47.62±0.08 | 37.83±0.08 | 19.24±0.07 | 47.20±0.11 | |
| GAE | 71.57±2.48 | 62.13±2.79 | 48.82±4.57 | 68.08±1.76 | |
| DAEGC | 75.52±0.01 | 63.31±0.01 | 59.98±0.84 | 70.02±0.01 | |
| SDCN | 53.44±0.81 | 44.85±0.83 | 31.21±1.23 | 50.66±1.49 | |
| DFCN | 76.88±0.80 | 69.21±1.00 | 59.98±0.84 | 71.58±0.31 | |
| DCRN | 79.94±0.13 | 73.70±0.24 | 63.69±0.20 | 73.82±0.12 | |
| HMIPDC | 80.83±0.78 | 69.47±0.46 | 65.23±1.64 | 75.87±2.08 | |
1)在4个数据集中,HMIPDC相较于其他基线方法在4个评价指标上都有较佳的性能表现. 例如在DBLP数据集中,HMIPDC在ACC、NMI、ARI和F1上分别超过了最佳基线方法0.68%、0.46%、1.79%和0.48%.
2)K-means、AE和IDEC方法在各个指标上都跟HMIPDC相距甚远. 这是因为它们仅仅考虑了节点属性信息来进行聚类,忽略了图结构对于后续聚类任务的影响. 相对而言,HMIPDC同时整合了图结构和节点属性信息,将其统一到一个框架中提取低维表征,并不断优化聚类目标,进而大大提升了聚类效果.
3)虽然SDCN和DFCN方法有效整合了图结构和节点属性信息,但是它们将编码器部分学到的属性信息过度引入到潜在空间中,使得低维表征包含了很多冗余信息,降低了低维表征的质量. 而HMIPDC则采用高阶互信息最大化策略来探索低维表征和节点属性信息之间的关系,使得获得的表征更具有辨别力.
4)相较于最佳的基线方法DCRN,HMIPDC在许多指标上也有不错的性能提升. DCRN虽然通过对齐软分配分布和目标分布来指导网络学习,但是它并没有对模型学习到的预测标签进行区分,导致很多错误的标签被用来指导学习,降低了聚类效果. 相反,HMIPDC使用伪标签技术将置信度较高的样本加入到自监督学习中,减少了错误的标签信息对于后续表征学习的影响,提高了聚类性能.
4.6. 消融研究
通过消融实验来证明互信息监督模块和伪标签技术在HMIPDC中的重要性,进一步表明HMIPDC模型的有效性. 首先以由图注意力自编码器和DDC聚类损失为主要部分构成的一个框架作为基线(AD),因为它是HMIPDC模型进行训练的一个主体框架. AD-MI、AD-PL和AD-MI-PL分别表示添加了互信息监督模块、伪标签技术和两者都添加的方法. 消融研究结果如表3所示. 表中,加粗的字体表示最优的结果.
表 3 HMIPDC和3种变种算法在4个数据集上的聚类结果
Tab.3
| % | |||||
| 数据集 | 方法 | ACC | NMI | ARI | F1 |
| ACM | AD | 91.87±0.12 | 70.92±0.29 | 77.49±0.32 | 91.67±0.29 |
| AD-MI | 91.94±0.15 | 71.50±0.33 | 77.57±0.36 | 91.95±0.15 | |
| AD-PL | 92.07±0.12 | 72.08±0.23 | 77.92±0.28 | 92.08±0.12 | |
| AD-MI-PL | 92.12±0.15 | 72.18±0.52 | 78.04±0.39 | 92.13±0.14 | |
| Citeseer | AD | 64.80±0.98 | 39.25±0.92 | 40.28±0.69 | 62.86±0.64 |
| AD-MI | 70.65±0.89 | 44.82±0.50 | 47.47±0.68 | 66.56±0.38 | |
| AD-PL | 70.67±0.58 | 43.90±0.73 | 46.08±0.91 | 64.57±0.78 | |
| AD-MI-PL | 71.93±0.31 | 46.07±0.23 | 48.28±0.50 | 66.96±0.26 | |
| DBLP | AD | 78.30±0.62 | 46.94±0.45 | 52.07±0.75 | 77.72±0.59 |
| AD-MI | 79.05±0.35 | 47.83±0.57 | 52.96±0.61 | 78.60±0.34 | |
| AD-PL | 79.21±0.80 | 48.66±0.71 | 54.24±0.53 | 78.83±0.57 | |
| AD-MI-PL | 80.34±0.16 | 49.41±0.34 | 55.39±0.28 | 79.76±0.32 | |
| AMAP | AD | 72.67±1.19 | 61.62±1.15 | 54.17±1.05 | 66.25±2.35 |
| AD-MI | 76.68±0.98 | 65.53±0.85 | 58.84±0.89 | 73.17±2.47 | |
| AD-PL | 74.36±0.91 | 64.11±0.95 | 57.23±1.36 | 71.64±2.16 | |
| AD-MI-PL | 80.83±0.78 | 69.47±0.46 | 65.23±1.64 | 75.87±2.08 | |
由表3可以看出:1)AD-MI和AD-PL在4个数据集上的所有指标都优于AD. 这表明互信息监督模块和伪标签技术确实能提升聚类效果. 2)AD-MI-PL在4个数据集上的所有指标都优于AD、AD-MI和AD-PL. 原因在于AD-MI-PL在利用高阶互信息学到低维表征后,选取了高置信度的预测标签作为伪标签来进行自监督学习,通过不断地迭代优化,使得生成的低维表征更易于后续的聚类任务. 3)特别地,在AMAP数据集中,AD-MI-PL相较于AD在ACC、NMI、ARI和F1这4个评价指标上分别有了8.16%、7.85%、11.06%和9.62%的提升,这主要得益于AD-MI-PL通过高阶互信息和伪标签有效地整合了图结构和节点属性信息,使得提取到的低维表征拥有原始图的核心特征,从而让聚类性能在大规模图上有极大的提升.
4.7. 参数敏感性分析
通过4个数据集中的ACC来探讨HMIPDC对目标函数的权衡超参数
图 2
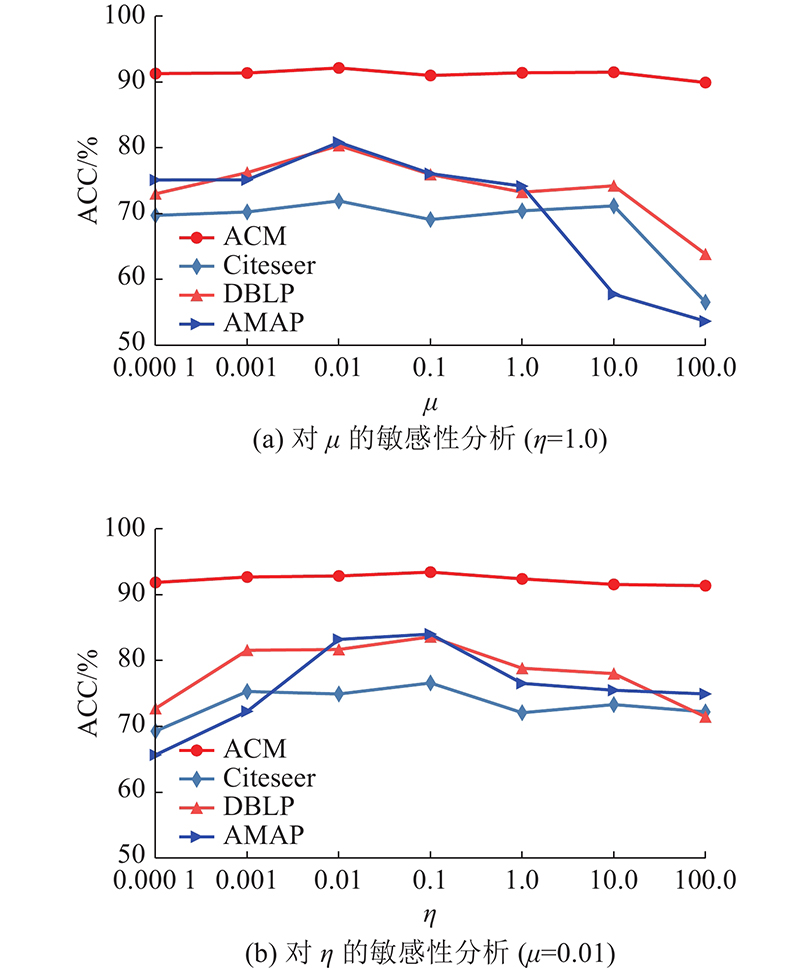
图 2 不同超参数下4个数据集上的聚类准确率
Fig.2 Clustering accuracy on four datasets with different hyperparameters
4.8. 实验时间分析
为了探究模型的训练时间对于聚类效果的影响,在ACM数据集中,记录了IDEC、DAEGC、DFCN、DCRN和HMIPDC这5种方法在不同训练时间t的ACC,结果如图3所示. 可以看出,相较于其他4种方法,HMIPDC在所有的训练时间都能保持较高的ACC. 特别地,如果训练时间不足30 s,由于其他4种方法都须先耗费一定的时间对模型进行不同程度的预训练,导致模型的ACC在训练初期表现不佳;而HMIPDC并不需要进行预训练,模型能有更多时间进行本身的优化,从而获得较高的ACC.
图 3
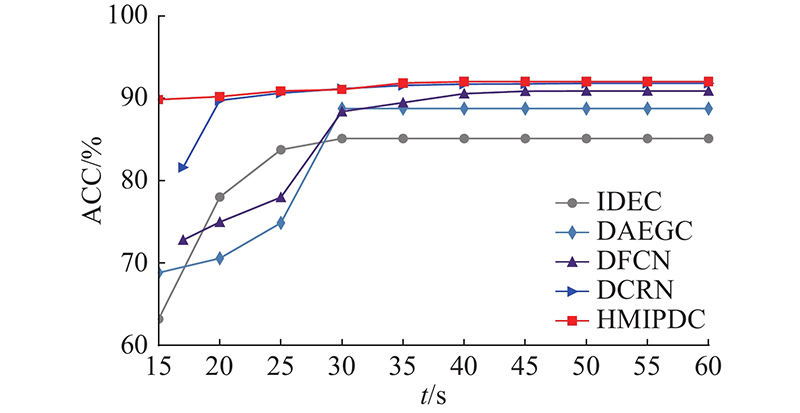
图 3 不同训练时间下5种方法在ACM数据集上的聚类准确率
Fig.3 Clustering accuracy of five methods with different training time on ACM dataset
4.9. 聚类可视化分析
为了更加直观地验证HMIPDC的有效性,在ACM数据集上,将IDEC、SDCN、DFCN、DCRN和HMIPDC使用t-分布随机邻域嵌入(t-distributed stochastic neighbor embedding, t-SNE)[30]算法将模型学习到的低维表征投影到二维空间并进行可视化,可视化结果如图4所示. 图中,不同的颜色表示不同的簇. 可以看出,较于原始数据,每种模型方法都有不错的可视化结果. 对于图4(b)、(c),虽然不同颜色之间有明显的边界,但是它们每种颜色的内部混杂了许多其他颜色的节点,说明它们生成的低维表征还不能较好地区分不同类别的节点. 对于图4(d)、(e),虽然同一颜色的点能彼此靠近,但是每种颜色的边界却不清晰,导致它们不能较好地区分不同类别的相似节点. 图4(f)的可视化结果最好,同种颜色的点紧密地聚集在一起,不同颜色的点彼此分离,表明HMIPDC生成的低维表征具有更清晰的结构,可以更好地揭示数据之间的内在聚类结构.
图 4

图 4 不同方法的低维表征在ACM数据集上的2维可视化结果
Fig.4 2D visualization results of low-dimensional representations of different methods on ACM dataset
5. 结 语
提出一种高阶互信息最大化与伪标签指导的深度聚类模型HMIPDC,该模型通过高阶互信息最大化策略充分利用图的拓扑结构和节点的属性信息,从原始图中获得更有价值的节点特征. 采用了一种结合多跳邻近矩阵的自注意力机制,驱使目标节点在进行聚合操作时能够关注重要的邻居节点,从而有效克服数据稀疏性和复杂性对聚类结果的影响. 为了减少训练过程出现的噪声影响,HMIPDC使用DDC聚类损失函数来衡量聚类性能,并从模型的聚类预测结果中选取置信度较高的样本作为伪标签,用于指导低维表征的学习,进而实现更优的聚类性能. 在4个数据集上进行的聚类任务、消融研究、参数敏感性分析、实验时间分析和聚类可视化分析,充分表明了HMIPDC聚类性能的有效性和优越性.
本研究只是在同质属性网络中进行深度聚类研究. 在未来的工作中,将会进一步考虑拥有不同类型节点的异质信息网络[31],尝试利用异质信息网络中丰富的语义信息来完成聚类任务. 另外,现实世界中的图数据大多数都存在缺失,如何在有缺失的数据中有效地进行聚类任务也将是下一步的研究重点.
参考文献
Evolutionary deep learning: a survey
[J].DOI:10.1016/j.neucom.2022.01.099 [本文引用: 1]
Online deep learning based on auto-encoder
[J].DOI:10.1007/s10489-020-02058-8 [本文引用: 3]
A comprehensive survey on graph neural networks
[J].DOI:10.1109/TNNLS.2020.2978386 [本文引用: 1]
基于两级权重的多视角聚类
[J].DOI:10.7544/issn1000-1239.20200897 [本文引用: 1]
Multi-view clustering based on two-level weights
[J].DOI:10.7544/issn1000-1239.20200897 [本文引用: 1]
Deep divergence-based approach to clustering
[J].DOI:10.1016/j.neunet.2019.01.015 [本文引用: 2]
Deep node clustering based on mutual information maximization
[J].DOI:10.1016/j.neucom.2021.03.020 [本文引用: 2]
基于复合关系图卷积的属性网络嵌入方法
[J].DOI:10.7544/issn1000-1239.2020.20200206 [本文引用: 1]
Exploiting composite relation graph convolution for attributed network embedding
[J].DOI:10.7544/issn1000-1239.2020.20200206 [本文引用: 1]
Self-supervised graph convolutional clustering by preserving latent distribution
[J].DOI:10.1016/j.neucom.2021.01.082 [本文引用: 2]
Multivariate information transmission
[J].DOI:10.1109/TIT.1954.1057469 [本文引用: 1]
A K-means clustering algorithm
[J].
Pseudo-supervised deep subspace clustering
[J].DOI:10.1109/TIP.2021.3079800 [本文引用: 1]
LSMD: a fast and robust local community detection starting from low degree nodes in social networks
[J].DOI:10.1016/j.future.2020.07.011 [本文引用: 1]
Visualizing data using t-SNE
[J].
异质信息网络表征学习综述
[J].DOI:10.11897/SP.J.1016.2022.00160 [本文引用: 1]
Heterogeneous information network representation learning: a survey
[J].DOI:10.11897/SP.J.1016.2022.00160 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}