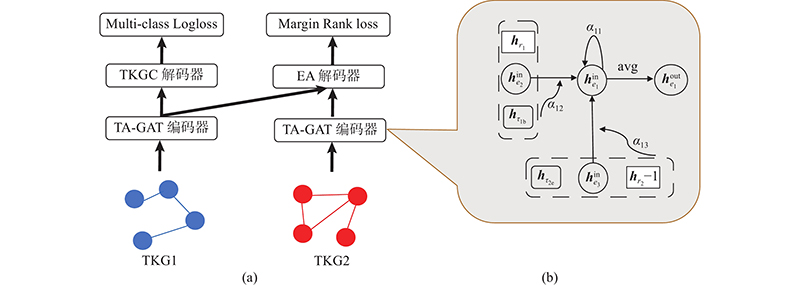
Aiming at the limitation that static knowledge graph representation learning methods cannot model time, a temporal graph representation learning method based on relational aggregation was designed to describe and reason about the temporal information of dynamic knowledge graphs from the demand of practical applications. Different from the discrete snapshot temporal neural networks, temporal information was treated as a link property among entities. A time-aware relational graph attention encoder was used to learn entity representations of temporal knowledge graphs, while the neighborhood relations and time stamps of central nodes were incorporated into the graph structure, and then different weights were assigned to aggregate temporal knowledge efficiently. Results of running on public datasets showed that, compared with traditional temporal graph encoder frameworks, the attention aggregation network had a strong competitive advantage in the performance of both the complementation and alignment tasks, especially for highly time-sensitive entities, reflecting the superiority and strong robustness of the algorithm.
MAO X, WANG W T, LAN M, et al. MRAEA: an efficient and robust entity alignment approach for cross-lingual knowledge graph [C]// The 13th ACM International Conference on Web Search and Data Mining. Houston: ACM, 2020: 420-428.
WANG Z, LV Q, LAN X, et al. Cross-lingual knowledge graph alignment via graph convolutional networks [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: Association for Computational Linguistics, 2018: 349-357.
WU Y, LIU X, FENG Y, et al. Jointly learning entity and relation representations for entity alignment [M]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Hong Kong: Association for Computational Linguistics, 2019: 240-249.
DASGUPTA S S, RAY S N, TALUKDAR P P. Hyte: hyperplane-based temporally aware knowledge graph embedding [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: Association for Computational Linguistics, 2018: 2001-2011.
BORDES A, USUNIER N, GARCÍA-DURÁN A, et al. Translating embeddings for modeling multi-relational data [C]// 27th Annual Conference on Neural Information Processing Systems. Lake Tahoe: [s.n.], 2013: 2787-2795.
GARCÍA-DURÁN A, DUMANCIC S, NIEPERT M. Learning sequence encoders for temporal knowledge graph completion [M]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: Association for Computational Linguistics, 2018: 4816-4821.
LACROIX T, OBOZINSKI G, USUNIER N. Tensor decompositions for temporal knowledge base completion [C]// 8th International Conference on Learning Representations. Addis Ababa: [s.n.], 2020.
GOEL R, KAZEMI S M, BRUBAKER M A, et al. Diachronic embedding for temporal knowledge graph completion [C]// The 34th AAAI Conference on Artificial Intelligence. New York: AAAI Press, 2020: 3988-3995.
XU C, NAYYERI M, ALKHOURY F, et al. Temporal knowledge graph embedding model based on additive time series decomposition [EB/OL]. [2022-07-15]. https://arXiv.org/abs/1911.07893v1.
WU J, CAO M, CHEUNG J C K, et al. Temp: temporal message passing for temporal knowledge graph completion [M]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. [s.l.]: Association for Computational Linguistics, 2020: 5730-5746.
CHEN M, TIAN Y, YANG M, et al. Multilingual knowledge graph embeddings for cross-lingual knowledge alignment [C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne: [s.n.], 2017: 1511-1517.
ZHU H, XIE R, LIU Z, et al. Iterative entity alignment via joint knowledge embeddings [C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne: [s.n.], 2017: 4258-4264.
GUO L, SUN Z, HU W. Learning to exploit long-term relational dependencies in knowledge graphs [C]// Proceedings of the 36th International Conference on Machine Learning. Long Beach: PMLR, 2019: 2505-2514.
CHEN M, TIAN Y, CHANG K, et al. Co-training embeddings of knowledge graphs and entity descriptions for cross-lingual entity alignment [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: [s.n.], 2018: 3998-4004.
LAMPLE G, CONNEAU A, RANZATO M, et al. Word translation without parallel data [C]// 6th International Conference on Learning Representations. Vancouver: ICML, 2018.
SADEGHIAN A, ARMANDPOUR M, COLAS A, et al. Chronor: rotation based temporal knowledge graph embedding [M]// 35th AAAI Conference on Artificial Intelligence. [s.l.]: AAAI Press, 2021 : 6471-6479.
SUN Z, HU W, LI C. Cross-lingual entity alignment via joint attribute-preserving embedding [C]// 16th International Semantic Web Conference. Vienna: Springer, 2017: 628-644.
SUN Z, HU W, ZHANG Q, et al. Bootstrapping entity alignment with knowledge graph embedding [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: [s.n.], 2018: 4396-4402.
CAO Y, LIU Z, LI C, et al. Multi-channel graph neural network for entity alignment [M]// Proceedings of the 57th Conference of the Association for Computational Linguistics. Florence: Association for Computational Linguistics, 2019: 1452-1461.
MAO X, WANG W, XU H, et al. Relational reflection entity alignment[C]// The 29th ACM International Conference on Information and Knowledge Management. [s.l.]: ACM, 2020: 1095-1104.



{kind=link}
{kind=link}