[1]
PEROZZI B, ALRFOU R, SKIENA S. Deepwalk: Online learning of social representations [C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 701-710.
[本文引用: 1]
[2]
VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks [C]// International Conference on Learning Representations. Vancouver: IEEE, 2018: 164-175.
[本文引用: 2]
[3]
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [C]// International Conference on Learning Representations. Toulon: IEEE, 2017: 12-26.
[本文引用: 2]
[4]
FERRANTE J, OTTENSTEIN K J, WARREN J D The program dependence graph and its use in optimization
[J]. ACM Transactions on Programming Languages and Systems , 1987 , 9 (3 ): 319 - 349
DOI:10.1145/24039.24041
[本文引用: 1]
[5]
MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [C]// International Conference on Learning Representations. Scottsdale: IEEE, 2013: 1-12.
[本文引用: 2]
[6]
WHITE M, VENDOME C, LINARES-VASQUEZ M, et al. Toward deep learning software repositories [C]// IEEE/ACM 12th Working Conference on Mining Software Repositories. Florence: IEEE, 2015: 334-345.
[本文引用: 5]
[7]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// 31st Conference on Neural Information Processing Systems. Long Beach: IEEE. 2017: 5998-6008.
[本文引用: 1]
[8]
ALON U, ZILBERSTEIN M, LEVY O, et al. code2vec: learning distributed representations of code [C]// Proceedings of the ACM on Programming Languages. Phoenix: ACM, 2019: 1-29.
[本文引用: 3]
[9]
ALON U, BRODY S, LEVY O, et al. code2seq: generating sequences from structured representations of code [C]// International Conference on Learning Representations. New Orleans: IEEE, 2019: 1-22.
[本文引用: 3]
[10]
LI Y, WANG S, NGUYEN T N, et al. Improving bug detection via context-based code representation learning and attention-based neural networks [C]// Proceedings of the ACM on Programming Languages. Phoenix: ACM, 2019: 1-30.
[本文引用: 4]
[11]
VAGAVOLU D, SWARNA K C, CHIMALAKONDA S. A mocktail of source code representations [C]// International Conference on Automated Software Engineering. Melbourne: IEEE, 2021: 1269-1300.
[本文引用: 2]
[12]
SHI E, WANG Y, DU L, et al. Enhancing code summarization with hierarchical splitting and reconstruction of abstract syntax trees [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana: IEEE, 2021: 4053-4062.
[本文引用: 2]
[13]
ZHANG J, WANG X, ZHANG H, et al. A novel neural source code representation based on abstract syntax tree [C]// 41st International Conference on Software Engineering. Montreal: IEEE, 2019: 783-794.
[本文引用: 2]
[14]
BUI N D Q, YU Y, JIANG L. InferCode: self-supervised learning of code representations by predicting subtrees [C]// 43rd International Conference on Software Engineering. Madrid: IEEE, 2021: 1186-1197.
[本文引用: 2]
[15]
JAYASUNDARA M H V Y, BUI D Q N, JIANG L, et al. TreeCaps: tree-structured capsule networks for program source code processing [C]// Workshop on Machine Learning for Systems at the Conference on Neural Information Processing Systems. Vancouver: IEEE, 2019: 8-14.
[本文引用: 2]
[16]
BUCH L, ANDRZEJAK A. Learning-based recursive aggregation of abstract syntax trees for code clone detection [C]// International Conference on Software Analysis, Evolution and Reengineering. Hangzhou: IEEE, 2019: 95-104.
[本文引用: 2]
[17]
LIU C, WANG X, SHIN R, et al. Neural code completion [C]// International Conference on Learning Representations. Toulon: IEEE, 2017: 1-14.
[本文引用: 4]
[18]
HU X, LI G, XIA X, et al. Deep code comment generation [C]// International Conference on Program Comprehension. Gothenburg: IEEE, 2018: 200-210.
[本文引用: 4]
[19]
LECLAIR A, JIANG S, MCMILLANCM C. A neural model for generating natural language summaries of program subroutines [C]// 41st International Conference on Software Engineering. Montreal: IEEE, 2019: 795-806.
[本文引用: 1]
[20]
HAQUE S, LECLAIR A, WU L, et al. Improved automatic summarization of subroutines via attention to file context [C]// International Conference on Mining Software Repositories. New York: ACM, 2020: 300-310.
[本文引用: 1]
[21]
JIANG H, SONG L, GE Y, et al An AST structure enhanced decoder for code generation
[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing , 2021 , 30 : 468 - 476
[本文引用: 2]
[22]
ALLAMANIS M, BROCKSCHMIDT M, KHADEMI M. Learning to represent programs with graphs [C]// International Conference on Learning Representations. Vancouver: IEEE, 2018: 1-17.
[本文引用: 2]
[23]
WANG Y, LI H. Code completion by modeling flattened abstract syntax trees as graphs [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2021: 14015-14023.
[本文引用: 3]
[24]
YANG K, YU H, FAN G, et al A graph sequence neural architecture for code completion with semantic structure features
[J]. Journal of Software: Evolution and Process , 2022 , 34 (1 ): 1 - 22
[本文引用: 2]
[25]
BEN-NUN T, JAKOBOVITS A S, HOEFLER T Neural code comprehension: a learnable representation of code semantics
[J]. Advances in Neural Information Processing Systems , 2018 , 31 (1 ): 3589 - 3601
[本文引用: 1]
[26]
LATTNER C, ADVE V. LLVM: a compilation framework for lifelong program analysis and transformation [C]// International Symposium on Code Generation and Optimization. San Jose: IEEE, 2004: 75-86.
[本文引用: 1]
[27]
WANG Z, YU L, WANG S, et al. Spotting silent buffer overflows in execution trace through graph neural network assisted data flow analysis [EB/OL]. (2021-02-20). https://arxiv.org/abs/2102.10452.
[本文引用: 2]
[28]
SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks [C]// European Semantic Web Conference. Heraklion: IEEE, 2018: 593-607.
[本文引用: 1]
[29]
WANG W, ZHANG K, LI G, et al. Learning to represent programs with heterogeneous graphs [EB/OL]. (2020-12-08). https://arxiv.org/abs/2012.04188.
[本文引用: 1]
[30]
CUMMINS C, FISCHES Z V, BEN-NUN T, et al. PROGRAML: a graph-based program representation for data flow analysis and compiler optimizations [C]// International Conference on Machine Learning. Vienna: IEEE, 2021: 2244-2253.
[本文引用: 1]
[31]
TUFANO M, WATSON C, BAVOTA G, et al. Deep learning similarities from different representations of source code [C]// International Conference on Mining Software Repositories. Gothenburg: IEEE, 2018: 542-553.
[本文引用: 1]
[32]
OU M, WATSON C, PEI J, et al. Asymmetric transitivity preserving graph embedding [C]// International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 1105-1114.
[本文引用: 1]
[33]
SUI Y, CHENG X, ZHANG G, et al. Flow2vec: Value-flow-based precise code embedding [C]// Proceedings of the ACM on Programming Languages. [S. l.]: ACM, 2020: 1-27.
[本文引用: 1]
[34]
MEHROTRA N, AGARWAL N, GUPTA P, et al Modeling functional similarity in source code with graph-based Siamese networks
[J]. IEEE Transactions on Software Engineering , 2021 , 48 (10 ): 1 - 22
[本文引用: 2]
[35]
KARMAKAR A, ROBBES R. What do pre-trained code models know about code? [C]// International Conference on Automated Software Engineering. Melbourne: IEEE, 2021: 1332-1336.
[本文引用: 1]
[36]
HINDLE A, BARR E T, SU Z, et al. On the naturalness of software [C]// Proceedings of the 34th International Conference on Software Engineering. Zurich: IEEE, 2012: 837-847.
[本文引用: 2]
[37]
BIELIK P, RAYCHEV V, VECHEV M. Program synthesis for character level language modeling [C]// 5th International Conference on Learning Representations. Toulon: IEEE, 2017: 1-17.
[本文引用: 1]
[38]
HELLENDOORN V, DEVANBU P. Are deep neural networks the best choice for modeling source code? [C]// Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering. New York: IEEE, 2017: 763-773.
[本文引用: 2]
[39]
DAM H K, TRAN T, PHAM T T M. A deep language model for software code [C]// Proceedings of the Foundations Software Engineering International Symposium. Seattle: ACM, 2016: 1-4.
[本文引用: 3]
[40]
BHOOPCHAND A, ROCKTASCHEL T, BARR E, et al. Learning python code suggestion with a sparse pointer network [C]// International Conference on Learning Representations. Toulon: IEEE, 2017: 1-11.
[本文引用: 2]
[41]
LIU F, ZHANG L, JIN Z Modeling programs hierarchically with stack-augmented LSTM
[J]. Journal of Systems and Software , 2020 , 164 (11 ): 1 - 16
[本文引用: 1]
[42]
LI B, YAN M, XIA X, et al. DeepCommenter: a deep code comment generation tool with hybrid lexical and syntactical information [C]// Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York: ACM, 2020: 1571-1575.
[本文引用: 4]
[43]
LECLAIR A, HAQUE S, WU L, et al. Improved code summarization via a graph neural network [C]// International Conference on Program Comprehension. Seoul: ACM, 2020: 184-195.
[本文引用: 2]
[44]
PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Conference on Empirical Methods in Natural Language Processing. Doha: ACM, 2014: 1532-1543.
[本文引用: 1]
[45]
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2018-10-11). https://arxiv.org/abs/1810.04805.
[本文引用: 2]
[46]
FENG Z, GUO D, TANG D, et al. Codebert: a pre-trained model for programming and natural languages [C]. // Conference on Empirical Methods in Natural Language Processing. [S. l.]: ACM, 2020: 1536-1547.
[本文引用: 2]
[47]
JIANG N, LUTELLIER T, TAN L. CURE: code-aware neural machine translation for automatic program repair [C]// International Conference on Software Engineering. Madrid: IEEE, 2021: 1161-1173.
[本文引用: 3]
[48]
GAO S, CHEN C, XING Z, et al. A neural model for method name generation from functional description [C]// 26th IEEE International Conference on Software Analysis, Evolution and Reengineering. Hangzhou: IEEE, 2019: 414-421.
[本文引用: 2]
[49]
KARAMPATSIS R M, SUTTON C. Maybe deep neural networks are the best choice for modeling source code [EB/OL]. (2019-03-13). https://arxiv.org/abs/1903.05734.
[本文引用: 1]
[50]
YE G, TANG Z, WANG H, et al. Deep program structure modeling through multi-relational graph-based learning [C]// Proceedings of the ACM International Conference on Parallel Architectures and Compilation Techniques. Georgia: ACM, 2020: 111-123.
[本文引用: 2]
[51]
MA W, ZHAO M, SOREMEKUN E, et al. GraphCode2Vec: generic code embedding via lexical and program dependence analyses [EB/OL]. (2021-12-02). https://arxiv.org/abs/2112.01218.
[本文引用: 2]
[52]
ZHOU Y, LIU S, SIOW J K, et al. Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks [C]// Advances in Neural Information Processing Systems . Vancouver: IEEE, 2019: 1-11.
[本文引用: 2]
[53]
FANG C, LIU Z, SHI Y, et al. Functional code clone detection with syntax and semantics fusion learning [C]// Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM, 2020: 516-527.
[本文引用: 2]
[54]
WANG H, YE G, TANG Z, et al Combining graph-based learning with automated data collection for code vulnerability detection
[J]. IEEE Transactions on Information Forensics and Security , 2020 , 16 (1 ): 1943 - 1958
[本文引用: 2]
[55]
WU H, ZHAO H, ZHANG M. SIT3: code summarization with structure-induced transformer [C]// Annual Meeting of the Association for Computational Linguistics. [S. l.]: IEEE, 2021: 1078-1090.
[本文引用: 1]
[56]
GUO D, REN S, LU S, et al. GraphCodeBERT: pre-training code representations with data flow [C]// International Conference on Learning Representations. [S. l. ]: IEEE, 2021: 1-18.
[本文引用: 1]
[57]
GAO S, GAO C, HE Y, et al. Code structure guided transformer for source code summarization [EB/OL]. (2021-04-19). https://arxiv.org/abs/2104.09340.
[本文引用: 1]
[58]
RAY B, HELLENDOORN V, GODHANE S, et al. On the naturalness of buggy code [C]// 38th IEEE/ACM International Conference on Software Engineering. Austin: IEEE, 2016: 428-439.
[本文引用: 1]
[59]
张献, 贲可荣, 曾杰 基于代码自然性的切片粒度缺陷预测方法
[J]. 软件学报 , 2021 , 32 (7 ): 2219 - 2241
[本文引用: 2]
ZHANG Xian, BEN Ke-rong, ZENG Jie Slice granularity defect prediction method based on code naturalness
[J]. Journal of Software , 2021 , 32 (7 ): 2219 - 2241
[本文引用: 2]
[60]
陈皓, 易平 基于图神经网络的代码漏洞检测方法
[J]. 网络与信息安全学报 , 2021 , 7 (3 ): 37 - 40
[本文引用: 1]
CHEN Hao, YI Ping Code vulnerability detection method based on graph neural network
[J]. Journal of Network and Information Security , 2021 , 7 (3 ): 37 - 40
[本文引用: 1]
[61]
PHAN A V, LE NGUYEN M, BUI L T. Convolutional neural networks over control flow graphs for software defect prediction [C]// 29th International Conference on Tools with Artificial Intelligence. Boston: IEEE, 2017: 45-52.
[本文引用: 1]
[62]
WANG S, LIU T, NAM J, et al Deep semantic feature learning for software defect prediction
[J]. IEEE Transactions on Software Engineering , 2018 , 46 (12 ): 1267 - 1293
[本文引用: 1]
[63]
XU J, WANG F, AI J Defect prediction with semantics and context features of codes based on graph representation learning
[J]. IEEE Transactions on Reliability , 2020 , 70 (2 ): 613 - 625
[本文引用: 1]
[64]
WANG H, ZHUANG W, ZHANG X Software defect prediction based on gated hierarchical LSTMs
[J]. IEEE Transactions on Reliability , 2021 , 70 (2 ): 711 - 727
[本文引用: 1]
[65]
GROVER A, LESKOVEC J. node2vec: scalable feature learning for networks [C]// 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: ACM, 2016: 855-864.
[本文引用: 1]
[66]
HUO X, THUNG F, LI M, et al Deep transfer bug localization
[J]. IEEE Transactions on Software Engineering , 2019 , 47 (7 ): 1368 - 1380
[本文引用: 1]
[67]
ZHU Z, LI Y, TONG H, et al. CooBa: cross-project bug localization via adversarial transfer learning [C]// 29th International Joint Conference on Artificial Intelligence. Yokohama: IEEE, 2020: 3565-3571.
[本文引用: 1]
[68]
YANG S, CAO J, ZENG H, et al. Locating faulty methods with a mixed RNN and attention model [C]// 29th International Conference on Program Comprehension . Madrid: IEEE, 2021: 207-218.
[本文引用: 1]
[69]
LUTELLIER T, PHAM H V, PANG L, et al. Coconut: combining context-aware neural translation models using ensemble for program repair [C]// Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM, 2020: 101-114.
[本文引用: 1]
[70]
LI Y, WANG S, NGUYEN T N. Dlfix: context-based code transformation learning for automated program repair [C]// Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering. Seoul: IEEE, 2020: 602-614.
[本文引用: 1]
[71]
杨博, 张能, 李善平, 等 智能代码补全研究综述
[J]. 软件学报 , 2020 , 31 (5 ): 1435 - 1453
[本文引用: 1]
YANG Bo, ZHANG Neng, LI Shan-ping, et al Review of intelligent code completion
[J]. Journal of Software , 2020 , 31 (5 ): 1435 - 1453
[本文引用: 1]
[72]
LI J, WANG Y, LYU M R, et al. Code completion with neural attention and pointer networks [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: AAAI, 2018: 4159-4225.
[本文引用: 1]
[73]
LIU F, LI G, WEI B, et al. A self-attentional neural architecture for code completion with multi-task learning [C]// Proceedings of the 28th International Conference on Program Comprehension. Seoul: ACM, 2020: 37-47.
[本文引用: 1]
[74]
BROCKSCHMIDT M, ALLAMANIS M, GAUNT A L, et al. Generative code modeling with graphs [C]// International Conference on Learning Representations. New Orleans: IEEE, 2019: 1-24.
[本文引用: 1]
[75]
YONAI H, HAYASE Y, KITAGAWA H. Mercem: method name recommendation based on call graph embedding [C]// 26th Asia-Pacific Software Engineering Conference. Putrajaya: IEEE, 2019: 134-141.
[本文引用: 1]
[76]
ALLAMANIS M, PENG H, SUTTON C. A convolutional attention network for extreme summarization of source code [C]// International Conference on Machine Learning. New York: IEEE, 2016: 2091-2100.
[本文引用: 1]
[77]
ZHANG F, CHEN B, LI R, et al A hybrid code representation learning approach for predicting method names
[J]. Journal of Systems and Software , 2021 , 180 (16 ): 110 - 111
[本文引用: 1]
[78]
IYER S, KONSTAS I, CHEUNG A, et al. Summarizing source code using a neural attention model [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: ACM, 2016: 2073-2083.
[本文引用: 1]
[79]
YANG Z, KEUNG J, YU X, et al. A multi-modal transformer-based code summarization approach for smart contracts [C]// 29th International Conference on Program Comprehension. Madrid: IEEE, 2021: 1-12.
[本文引用: 1]
[80]
陈秋远, 李善平, 鄢萌, 等 代码克隆检测研究进展
[J]. 软件学报 , 2019 , 30 (4 ): 962 - 980
DOI:10.13328/j.cnki.jos.005711
[本文引用: 1]
CHEN Qiu-yuan, LI Shan-ping, YAN Meng, et al Research progress of code clone detection
[J]. Journal of Software , 2019 , 30 (4 ): 962 - 980
DOI:10.13328/j.cnki.jos.005711
[本文引用: 1]
[81]
BARCHI F, PARISI E, URGESE G, et al Exploration of convolutional neural network models for source code classification
[J]. Engineering Applications of Artificial Intelligence , 2021 , 97 (20 ): 104 - 175
[本文引用: 1]
[82]
PARISI E, BARCHI F, BARTOLINI A, et al Making the most of scarce input data in deep learning-based source code classification for heterogeneous device mapping
[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , 2021 , 41 (6 ): 1 - 12
[本文引用: 1]
[83]
XIAO Y, MA G, AHMED N K, et al. Deep graph learning for program analysis and system optimization [C]// Graph Neural Networks and Systems Workshop . [S. l. ]: IEEE, 2021: 1-8.
[本文引用: 1]
[84]
BRAUCKMANN A, GOENS A, ERTEL S, et al. Compiler-based graph representations for deep learning models of code [C]// Proceedings of the 29th International Conference on Compiler Construction. San Diego: ACM, 2020: 201-211.
[本文引用: 1]
[85]
JIAO J, PAL D, DENG C, et al. GLAIVE: graph learning assisted instruction vulnerability estimation [C]// Design, Automation and Test in Europe Conference and Exhibition. Grenoble: IEEE, 2021: 82-87.
[本文引用: 1]
[86]
HAMILTON W L, YING R, LESKOVEC J. Inductive representation learning on large graphs [J]. Advances in Neural Information Processing Systems , 2017, 30(1): 128-156.
[本文引用: 1]
[87]
MA J, DUAN Z, TANG L. GATPS: an attention-based graph neural network for predicting SDC-causing instructions [C]// 39th IEEE VLSI Test Symposium. San Diego: IEEE, 2021: 1-7.
[本文引用: 1]
[88]
WANG J, ZHANG C. Software reliability prediction using a deep learning model based on the RNN encoder–decoder [J]. Reliability Engineering and System Safety , 2018, 170(20): 73-82.
[本文引用: 1]
[89]
NIU W, ZHANG X, DU X, et al A deep learning based static taint analysis approach for IoT software vulnerability location
[J]. Measurement , 2020 , 32 (152 ): 107 - 139
[本文引用: 1]
[90]
XU X, LIU C, FENG Q, et al. Neural network-based graph embedding for cross-platform binary code similarity detection [C]// ACM SIGSAC Conference on Computer and Communications Security. Dallas: ACM, 2017: 363-376.
[本文引用: 1]
[91]
DAI H, DAI B, SONG L. Discriminative embeddings of latent variable models for structured data [C]// International Conference on Machine Learning. Dallas: IEEE, 2016: 2702-2711.
[本文引用: 1]
[92]
YU Z, CAO R, TANG Q, et al. Order matters: semantic-aware neural networks for binary code similarity detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2020, 34: 1145-1152.
[本文引用: 1]
[93]
DING S H H, FUNG B C M, CHARLAND P. Asm2vec: boosting static representation robustness for binary clone search against code obfuscation and compiler optimization [C]// IEEE Symposium on Security and Privacy. San Francisco: IEEE, 2019: 472-489.
[本文引用: 1]
[94]
LE Q, MIKOLOV T. Distributed representations of sentences and documents [C]// International Conference on Machine Learning. Dallas: IEEE, 2014: 1188-1196.
[本文引用: 1]
[95]
YANG J, FU C, LIU X Y, et al Codee: a tensor embedding scheme for binary code search
[J]. IEEE Transactions on Software Engineering , 2021 , 48 (7 ): 1 - 20
[本文引用: 2]
[96]
DUAN Y, LI X, WANG J, et al. Deepbindiff: learning program-wide code representations for binary diffing [C]// Network and Distributed System Security Symposium. San Diego: IEEE, 2020: 1-12.
[本文引用: 2]
[97]
TANG J, QU M, WANG M, et al. Line: large-scale information network embedding [C]// Proceedings of the 24th International Conference on World Wide Web. Florence: ACM, 2015: 1067-1077.
[本文引用: 1]
[98]
YANG C, LIU Z, ZHAO D, et al. Network representation learning with rich text information [C]// International Joint Conference on Artificial Intelligence. Buenos Aires: AAAI, 2015: 2111-2117.
[本文引用: 1]
[99]
BRAUCKMANN A, GOENS A, CASTRILLON J. ComPy-Learn: a toolbox for exploring machine learning representations for compilers [C]// 2020 Forum for Specification and Design Languages. Kiel: IEEE, 2020: 1-4.
[本文引用: 1]
[100]
CUMMINS C, WASTI B, GUO J, et al. CompilerGym: robust, performant compiler optimization environments for AI research [EB/OL]. (2021-09-17). https://arxiv.org/abs/2109.08267.
[本文引用: 1]
[101]
MOU L, LI G, ZHANG L, et al. Convolutional neural networks over tree structures for programming language processing [C]// AAAI Conference on Artificial Intelligence. Washington: AAAI, 2016: 1287-1293.
[本文引用: 1]
[102]
YE X, BUNESCU R, LIU C. Learning to rank relevant files for bug reports using domain knowledge [C]// Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering. Hong Kong: ACM, 2014: 689-699.
[本文引用: 1]
[103]
CUMMINS C, PETOUMENOS P, WANG Z, et al. End-to-end deep learning of optimization heuristics [C]// 26th International Conference on Parallel Architectures and Compilation Techniques. Portland: IEEE, 2017: 219-232.
[本文引用: 1]
[104]
KANG H J, BISSYANDE T F, LO D. Assessing the generalizability of code2vec token embeddings [C]// 34th IEEE/ACM International Conference on Automated Software Engineering. San Diego: IEEE, 2019: 1-12.
[本文引用: 1]
[105]
VENKATAKEERTHY S, AGGARWAL R, JAIN S, et al Ir2vec: LLVM ir based scalable program embeddings
[J]. ACM Transactions on Architecture and Code Optimization , 2020 , 17 (4 ): 1 - 27
[本文引用: 1]
[106]
HAJ-ALI A, AHMED N K, WILLKE T, et al. NeuroVectorizer: end-to-end vectorization with deep reinforcement learning [C]// Proceedings of the 18th ACM/IEEE International Symposium on Code Generation and Optimization. New York: ACM, 2020: 242-255.
[本文引用: 1]
1
... 基于图结构的程序表示学习的流程如图1 所示,一般先进行图的构建,定义图的节点与边,节点表示语句、指令或操作数等,边表示节点之间的依赖关系. 图的构建是程序表示学习的基础,因为所有的训练数据都映射在图结构上. 其次是程序语义嵌入提取,这一步是整个架构的核心. 程序语义嵌入提取是通过构建深度学习网络完成的,利用图结构提取节点的结构特征并聚合节点的属性信息,计算程序的表示向量. 常用的语义嵌入提取模型包括随机游走模型(random walk)[1 ] 、消息传递神经网络(message passing neural network,MPNN)[2 ] 、卷积神经网络(convolution neural network,CNN)[3 ] 等. 最后是下游的预测任务,利用程序的表示向量进行分类、回归或者生成序列. 在实际应用中,根据具体应用选取图的结构、语义嵌入提取和预测任务. 模型的构建过程包括训练、验证和测试. 通过训练,模型的梯度反向传播能够学到应用的特征与表示方法. 一般常用的表示程序的图结构主要包括抽象语法树(abstract syntax tree,AST)、依赖图. 抽象语法树是源代码的抽象语法结构的树状表示. 依赖图包含多种类型,常用的依赖图包括程序依赖图(program dependence graph, PDG)[4 ] 、数据流图(data flow graph, DFG)、控制流图(control flow graph,CFG)等. AST侧重于描述源代码语法信息,能够从AST中获取变量名、函数名的语法信息. 相比于AST,依赖图更加接近于底层,描述了计算机中数据如何存放及数据之间如何依赖,节点与源代码间找不到直接的对应关系. ...
2
... 基于图结构的程序表示学习的流程如图1 所示,一般先进行图的构建,定义图的节点与边,节点表示语句、指令或操作数等,边表示节点之间的依赖关系. 图的构建是程序表示学习的基础,因为所有的训练数据都映射在图结构上. 其次是程序语义嵌入提取,这一步是整个架构的核心. 程序语义嵌入提取是通过构建深度学习网络完成的,利用图结构提取节点的结构特征并聚合节点的属性信息,计算程序的表示向量. 常用的语义嵌入提取模型包括随机游走模型(random walk)[1 ] 、消息传递神经网络(message passing neural network,MPNN)[2 ] 、卷积神经网络(convolution neural network,CNN)[3 ] 等. 最后是下游的预测任务,利用程序的表示向量进行分类、回归或者生成序列. 在实际应用中,根据具体应用选取图的结构、语义嵌入提取和预测任务. 模型的构建过程包括训练、验证和测试. 通过训练,模型的梯度反向传播能够学到应用的特征与表示方法. 一般常用的表示程序的图结构主要包括抽象语法树(abstract syntax tree,AST)、依赖图. 抽象语法树是源代码的抽象语法结构的树状表示. 依赖图包含多种类型,常用的依赖图包括程序依赖图(program dependence graph, PDG)[4 ] 、数据流图(data flow graph, DFG)、控制流图(control flow graph,CFG)等. AST侧重于描述源代码语法信息,能够从AST中获取变量名、函数名的语法信息. 相比于AST,依赖图更加接近于底层,描述了计算机中数据如何存放及数据之间如何依赖,节点与源代码间找不到直接的对应关系. ...
... 2)利用孪生网络(siamese network). 孪生网络有2个输入,分别对应待比较的代码. 将2个输入送入2个共享权值的神经网络,形成输入在新的空间中的表示. 通过计算2个输入的相似度与真实的标签之间的损失函数来训练模型. 与第1种研究思路的区别在于采用孪生网络后,代码的向量表示与相似性度量2个阶段是贯通的,因此代码向量表示的神经网络能够接收到反馈. Buch等[16 ] 分别基于树结构的LSTM和基于树结构的CNN来计算AST的向量表示,利用孪生网络最小化余弦相似度与标签的差距. Mehrotra等[34 ] 提取PDG,通过图注意力网络(graph attention network,GAT)[2 ] 进行消息传递获取节点的向量表示,利用注意力机制聚合节点向量形成整图的向量表示,通过孪生网络训练GAT的参数. ...
2
... 基于图结构的程序表示学习的流程如图1 所示,一般先进行图的构建,定义图的节点与边,节点表示语句、指令或操作数等,边表示节点之间的依赖关系. 图的构建是程序表示学习的基础,因为所有的训练数据都映射在图结构上. 其次是程序语义嵌入提取,这一步是整个架构的核心. 程序语义嵌入提取是通过构建深度学习网络完成的,利用图结构提取节点的结构特征并聚合节点的属性信息,计算程序的表示向量. 常用的语义嵌入提取模型包括随机游走模型(random walk)[1 ] 、消息传递神经网络(message passing neural network,MPNN)[2 ] 、卷积神经网络(convolution neural network,CNN)[3 ] 等. 最后是下游的预测任务,利用程序的表示向量进行分类、回归或者生成序列. 在实际应用中,根据具体应用选取图的结构、语义嵌入提取和预测任务. 模型的构建过程包括训练、验证和测试. 通过训练,模型的梯度反向传播能够学到应用的特征与表示方法. 一般常用的表示程序的图结构主要包括抽象语法树(abstract syntax tree,AST)、依赖图. 抽象语法树是源代码的抽象语法结构的树状表示. 依赖图包含多种类型,常用的依赖图包括程序依赖图(program dependence graph, PDG)[4 ] 、数据流图(data flow graph, DFG)、控制流图(control flow graph,CFG)等. AST侧重于描述源代码语法信息,能够从AST中获取变量名、函数名的语法信息. 相比于AST,依赖图更加接近于底层,描述了计算机中数据如何存放及数据之间如何依赖,节点与源代码间找不到直接的对应关系. ...
... 1)异构性建模研究. Inst2vec模型构建的图是同构图(即只有一种类型的节点和边),边的关系可能有多种,比如读写依赖关系、寻址依赖关系、比较依赖关系等. 若用同构图模型来建模,则所有类型的边在消息传递中的影响是相同的,不能反映实际中程序多种关系的交互差异性. Wang等[27 ] 研究利用异构网络表示学习,建构多种类型的关系. BRGCN模型[27 ] 提取了指令级的异构数据流图,边包括数据流关系、变量邻接关系、读写关系等多种关系,利用R-GCN[28 ] 进行异构表示学习. R-GCN是同构网络表示学习GCN[3 ] 的变型,在对邻居节点进行卷积操作的时候考虑所连接边的类型,分别针对不同类型的边设计卷积函数,描述不同类型的边对节点交互的异构影响. Wang等[29 ] 采用transformer框架进行异构网络表示学习,所实现transformer的注意力机制的键值(key value)和查询值(query value)都与源节点和目标节点的类型相关,从而学到异构节点的交互特征. ...
The program dependence graph and its use in optimization
1
1987
... 基于图结构的程序表示学习的流程如图1 所示,一般先进行图的构建,定义图的节点与边,节点表示语句、指令或操作数等,边表示节点之间的依赖关系. 图的构建是程序表示学习的基础,因为所有的训练数据都映射在图结构上. 其次是程序语义嵌入提取,这一步是整个架构的核心. 程序语义嵌入提取是通过构建深度学习网络完成的,利用图结构提取节点的结构特征并聚合节点的属性信息,计算程序的表示向量. 常用的语义嵌入提取模型包括随机游走模型(random walk)[1 ] 、消息传递神经网络(message passing neural network,MPNN)[2 ] 、卷积神经网络(convolution neural network,CNN)[3 ] 等. 最后是下游的预测任务,利用程序的表示向量进行分类、回归或者生成序列. 在实际应用中,根据具体应用选取图的结构、语义嵌入提取和预测任务. 模型的构建过程包括训练、验证和测试. 通过训练,模型的梯度反向传播能够学到应用的特征与表示方法. 一般常用的表示程序的图结构主要包括抽象语法树(abstract syntax tree,AST)、依赖图. 抽象语法树是源代码的抽象语法结构的树状表示. 依赖图包含多种类型,常用的依赖图包括程序依赖图(program dependence graph, PDG)[4 ] 、数据流图(data flow graph, DFG)、控制流图(control flow graph,CFG)等. AST侧重于描述源代码语法信息,能够从AST中获取变量名、函数名的语法信息. 相比于AST,依赖图更加接近于底层,描述了计算机中数据如何存放及数据之间如何依赖,节点与源代码间找不到直接的对应关系. ...
2
... 基于token序列的程序表示学习的流程如图1 所示,提取源代码的token序列,通过神经网络提取token序列的程序语义嵌入,利用提取的语义嵌入执行下游的预测任务. 目前已有的工作主要基于N-gram模型[5 ] 、循环神经网络模型[6 ] 和序列到序列模型[7 ] ,提取token序列的程序语义嵌入. ...
... 利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
5
... 基于token序列的程序表示学习的流程如图1 所示,提取源代码的token序列,通过神经网络提取token序列的程序语义嵌入,利用提取的语义嵌入执行下游的预测任务. 目前已有的工作主要基于N-gram模型[5 ] 、循环神经网络模型[6 ] 和序列到序列模型[7 ] ,提取token序列的程序语义嵌入. ...
... 基于token序列的模型与相关文献如表2 所示. Hindle等[36 ] 认为程序是人类撰写的,和文字一样具备自然性,利用n-gram构造了源代码的语言模型. Bielik等[37 ] 提出基于特定领域语言(domain-specific language)的n-gram模型,以更好地学到局部信息. Hellendoorn等[38 ] 添加了局部的n-gram缓存,融合了全局和局部模型的预测结果. n-gram模型只能对定长的token片段序列(取决于窗口的长度N)进行分析,很难捕获token间长距离的依赖信息. White等[6 ] 利用循环神经网络(recurrent neural network,RNN)[6 ] 、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... [6 ]、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... [6 ]利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... Model based on token sequence
Tab.2 模型 相关文献 n-gram语言模型 文献[36 ~38 ] RNN 文献[6 , 39 ] LSTM 文献[40 , 41 ] GRU 文献[42 , 43 ]
利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
1
... 基于token序列的程序表示学习的流程如图1 所示,提取源代码的token序列,通过神经网络提取token序列的程序语义嵌入,利用提取的语义嵌入执行下游的预测任务. 目前已有的工作主要基于N-gram模型[5 ] 、循环神经网络模型[6 ] 和序列到序列模型[7 ] ,提取token序列的程序语义嵌入. ...
3
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 1)从词袋中选择最恰当的名字,计算词袋中每一个词被分配给该函数的概率,选出概率最大的一个. code2vec[8 ] 、code2seq[9 ] 均采用该思路,利用注意力机制聚合函数所包含的AST路径向量,形成该函数的向量表示;计算该向量与词袋中每一个词的点积,利用softmax函数计算分配概率. Yonai等[75 ] 提出Mercem模型,提取函数调用图,利用二阶邻接性提取函数的向量表示,计算词袋中的函数的名字向量与该函数向量的余弦相似度,选取余弦相似度最接近的名字作为函数名. 这种思路的缺点在于只能选择在词袋中已有的名字,只有词袋中存在与该函数很接近的函数时才能得到恰当函数名,命名存在一定的局限性. ...
3
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 1)从词袋中选择最恰当的名字,计算词袋中每一个词被分配给该函数的概率,选出概率最大的一个. code2vec[8 ] 、code2seq[9 ] 均采用该思路,利用注意力机制聚合函数所包含的AST路径向量,形成该函数的向量表示;计算该向量与词袋中每一个词的点积,利用softmax函数计算分配概率. Yonai等[75 ] 提出Mercem模型,提取函数调用图,利用二阶邻接性提取函数的向量表示,计算词袋中的函数的名字向量与该函数向量的余弦相似度,选取余弦相似度最接近的名字作为函数名. 这种思路的缺点在于只能选择在词袋中已有的名字,只有词袋中存在与该函数很接近的函数时才能得到恰当函数名,命名存在一定的局限性. ...
4
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... Model based on the fusion of grammar and semantics
Tab.3 相关文献 语法模型 语义模型 融合方式 代码token AST CDFG DFG CFG PDG 向量连接 向量均值 多层感知机 矩阵乘法 POEM[50 ] — √ √ — — — √ — — — GraphCode2Vec[51 ] √ — — — — √ √ — — — 文献[10 ] — √ — √ — √ — — — √ mocktail[11 ] — √ — — √ √ √ — — — Devign[52 ] — √ — √ √ — — √ — — 文献[53 ] — √ — — √ — √ — — — 文献[47 ] — √ √ — — — — — √ —
2)进行图的融合,形成单一图后进行表示学习[54 ] . FUNDED模型[54 ] 在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
... Li等[10 ] 通过融合AST、CFG和DFG等多种图的信息,更全面地描述缺陷及上下文语义. Devign模型[52 ] 提取语句级别的AST、CFG和DFG,利用GRU进行消息传递,通过卷积层获取所代表函数的子图向量. Li等[10 ] 通过GRU和卷积层从AST路径中获取目标函数的向量表示,形成局部视角的描述,利用node2vec[65 ] 获取PDG和DFG的向量表示,形成全局视角的描述,利用矩阵乘法融合局部视角和全局视角的向量进行预测. ...
... [10 ]通过GRU和卷积层从AST路径中获取目标函数的向量表示,形成局部视角的描述,利用node2vec[65 ] 获取PDG和DFG的向量表示,形成全局视角的描述,利用矩阵乘法融合局部视角和全局视角的向量进行预测. ...
2
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... Model based on the fusion of grammar and semantics
Tab.3 相关文献 语法模型 语义模型 融合方式 代码token AST CDFG DFG CFG PDG 向量连接 向量均值 多层感知机 矩阵乘法 POEM[50 ] — √ √ — — — √ — — — GraphCode2Vec[51 ] √ — — — — √ √ — — — 文献[10 ] — √ — √ — √ — — — √ mocktail[11 ] — √ — — √ √ √ — — — Devign[52 ] — √ — √ √ — — √ — — 文献[53 ] — √ — — √ — √ — — — 文献[47 ] — √ √ — — — — — √ —
2)进行图的融合,形成单一图后进行表示学习[54 ] . FUNDED模型[54 ] 在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
2
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 2)第2种研究思路是利用子树表示学习方法递归进行学习. 例如CAST模型[12 ] ,处理过程分为以下2步. 1)将原始AST按照复合语句分割为子树,利用基于树结构的表示学习算法RvNN(recursive neural network)获取每棵子树的向量. 2)将该子树看作节点,利用RvNN算法求得整树的向量. 采用子树表示学习方法,降低了单次表示学习时树的深度和模型训练时间. 与CAST类似思路的工作还有利用递归编码器[13 ] 、基于树的CNN算法[14 ] 、胶囊网络[15 ] 提取子树的编码. ...
2
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 2)第2种研究思路是利用子树表示学习方法递归进行学习. 例如CAST模型[12 ] ,处理过程分为以下2步. 1)将原始AST按照复合语句分割为子树,利用基于树结构的表示学习算法RvNN(recursive neural network)获取每棵子树的向量. 2)将该子树看作节点,利用RvNN算法求得整树的向量. 采用子树表示学习方法,降低了单次表示学习时树的深度和模型训练时间. 与CAST类似思路的工作还有利用递归编码器[13 ] 、基于树的CNN算法[14 ] 、胶囊网络[15 ] 提取子树的编码. ...
2
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 2)第2种研究思路是利用子树表示学习方法递归进行学习. 例如CAST模型[12 ] ,处理过程分为以下2步. 1)将原始AST按照复合语句分割为子树,利用基于树结构的表示学习算法RvNN(recursive neural network)获取每棵子树的向量. 2)将该子树看作节点,利用RvNN算法求得整树的向量. 采用子树表示学习方法,降低了单次表示学习时树的深度和模型训练时间. 与CAST类似思路的工作还有利用递归编码器[13 ] 、基于树的CNN算法[14 ] 、胶囊网络[15 ] 提取子树的编码. ...
2
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 2)第2种研究思路是利用子树表示学习方法递归进行学习. 例如CAST模型[12 ] ,处理过程分为以下2步. 1)将原始AST按照复合语句分割为子树,利用基于树结构的表示学习算法RvNN(recursive neural network)获取每棵子树的向量. 2)将该子树看作节点,利用RvNN算法求得整树的向量. 采用子树表示学习方法,降低了单次表示学习时树的深度和模型训练时间. 与CAST类似思路的工作还有利用递归编码器[13 ] 、基于树的CNN算法[14 ] 、胶囊网络[15 ] 提取子树的编码. ...
2
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 2)利用孪生网络(siamese network). 孪生网络有2个输入,分别对应待比较的代码. 将2个输入送入2个共享权值的神经网络,形成输入在新的空间中的表示. 通过计算2个输入的相似度与真实的标签之间的损失函数来训练模型. 与第1种研究思路的区别在于采用孪生网络后,代码的向量表示与相似性度量2个阶段是贯通的,因此代码向量表示的神经网络能够接收到反馈. Buch等[16 ] 分别基于树结构的LSTM和基于树结构的CNN来计算AST的向量表示,利用孪生网络最小化余弦相似度与标签的差距. Mehrotra等[34 ] 提取PDG,通过图注意力网络(graph attention network,GAT)[2 ] 进行消息传递获取节点的向量表示,利用注意力机制聚合节点向量形成整图的向量表示,通过孪生网络训练GAT的参数. ...
4
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 3)第3种研究思路是将AST扁平化处理(flattened AST),将AST转化为节点序列,利用序列表示学习的技术进行处理. 转化序列的方法包括中序深度优先遍历[17 ] 、前序深度优先遍历[21 ] 及基于结构的遍历(structure-based traversal)[18 ] . Liu等[17 ] 利用中序深度优先遍历AST,生成非终节点和终节点的节点对,节点对的向量是非终节点和终节点向量的加权和,通过LSTM来训练序列的向量. 前序优先遍历或中序优先遍历所产生的节点对序列存在语义损失,原因是AST与所产生的节点对序列不是一一对应的. 针对语义损失的问题,Hu等[18 ] 提出基于结构的遍历将AST扁平化的思路,通过添加括号将根节点与子树进行区分,所产生的序列可以无二义性地重建AST. ...
... [17 ]利用中序深度优先遍历AST,生成非终节点和终节点的节点对,节点对的向量是非终节点和终节点向量的加权和,通过LSTM来训练序列的向量. 前序优先遍历或中序优先遍历所产生的节点对序列存在语义损失,原因是AST与所产生的节点对序列不是一一对应的. 针对语义损失的问题,Hu等[18 ] 提出基于结构的遍历将AST扁平化的思路,通过添加括号将根节点与子树进行区分,所产生的序列可以无二义性地重建AST. ...
... 1)将AST扁平化处理(2.1节的第3种思路),利用序列表示学习技术预测下一个出现的节点. Liu等[17 ] 定义部分AST的概念,部分AST是指AST的一个子树,在AST中位于部分AST所有节点的左边节点都包含于该部分AST中. 给定部分AST,代码补全转化为预测部分AST位于最右侧节点的下一个节点. 利用前序深度优先遍历部分AST,生成非终节点和终节点的节点对,节点对的非终节点是终节点的父亲节点,节点对的向量是非终节点和终节点向量的加权和,通过LSTM来预测下一个出现的非终节点或终节点. 由于扁平化的AST失去了节点的父子关系表示,Li等[72 ] 提出增加父亲节点的向量表示,将上下文向量、父亲节点向量利用注意力机制融合后,输入LSTM模型中. 为了提取AST层次化的信息,Liu等[73 ] 提取从预测节点到根节点的路径序列,通过Bi-LSTM生成路径序列的向量表示. 将节点对的向量与路径序列向量连接,预测节点. ...
4
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 3)第3种研究思路是将AST扁平化处理(flattened AST),将AST转化为节点序列,利用序列表示学习的技术进行处理. 转化序列的方法包括中序深度优先遍历[17 ] 、前序深度优先遍历[21 ] 及基于结构的遍历(structure-based traversal)[18 ] . Liu等[17 ] 利用中序深度优先遍历AST,生成非终节点和终节点的节点对,节点对的向量是非终节点和终节点向量的加权和,通过LSTM来训练序列的向量. 前序优先遍历或中序优先遍历所产生的节点对序列存在语义损失,原因是AST与所产生的节点对序列不是一一对应的. 针对语义损失的问题,Hu等[18 ] 提出基于结构的遍历将AST扁平化的思路,通过添加括号将根节点与子树进行区分,所产生的序列可以无二义性地重建AST. ...
... [18 ]提出基于结构的遍历将AST扁平化的思路,通过添加括号将根节点与子树进行区分,所产生的序列可以无二义性地重建AST. ...
... 注释生成(comment generation)或代码总结(code summarization)是指为一段代码生成一句话用以总结代码的功能,可以帮助开发人员理解代码背后的语义,有利于提升代码的可读性和可维护性. 注释生成问题可以转化为文本序列生成问题,输入是源代码,输出是注释文本. 注释生成可以看作是神经机器翻译(neural machine translation,NMT)的一个应用. NMT采用编码器-解码器框架,编码器将源语言序列进行编码,提取源语言中的信息,通过解码器将该信息转换到另一种语言中,完成对语言的翻译. NMT将一段英文翻译成中文,生成注释可以看作是将源代码翻译为注释的过程. Hu等[18 ] 提出DeepCom模型,采用NMT框架,基于结构的遍历将AST扁平化(2.1节的思路3),编码器利用LSTM提取AST序列的上下文状态,通过注意力机制将每个时刻的上下文状态聚合,解码器利用上下文状态、隐藏状态和上一个时刻输出的token计算输出某一个token的概率,通过最小化交叉熵确定输出. Li等[42 ] 提出DeepCommenter模型,编码器利用GRU提取代码token序列和AST扁平化后的token序列的向量表示,利用注意力机制融合2组向量并送入解码器中,解码器根据上一个输出的token及融合后的向量,输出当前时刻的token. Iyer等[78 ] 提出CODE-NN模型,利用注意力机制建立代码token和输出之间的联系,将代码token和已输出的文本送入LSTM模型,选择最大概率出现的token作为当前输出. 为了捕获代码token的长距离依赖,Yang等[79 ] 提出MMTrans模型,在编码器的设计上,利用GCN学习到AST图结构的局部语义信息,利用自注意力机制学习到AST扁平化后token序列的全局语义信息. 在解码器的设计上,利用自注意力机制,将全局语义信息、局部语义信息和之前输出的注释token进行融合,计算注释token. ...
1
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
1
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
An AST structure enhanced decoder for code generation
2
2021
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 3)第3种研究思路是将AST扁平化处理(flattened AST),将AST转化为节点序列,利用序列表示学习的技术进行处理. 转化序列的方法包括中序深度优先遍历[17 ] 、前序深度优先遍历[21 ] 及基于结构的遍历(structure-based traversal)[18 ] . Liu等[17 ] 利用中序深度优先遍历AST,生成非终节点和终节点的节点对,节点对的向量是非终节点和终节点向量的加权和,通过LSTM来训练序列的向量. 前序优先遍历或中序优先遍历所产生的节点对序列存在语义损失,原因是AST与所产生的节点对序列不是一一对应的. 针对语义损失的问题,Hu等[18 ] 提出基于结构的遍历将AST扁平化的思路,通过添加括号将根节点与子树进行区分,所产生的序列可以无二义性地重建AST. ...
2
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 4)第4种研究思路是将AST看作特殊的图结构,利用消息传递方法提取AST的向量. 例如Allamanis等[22 ] 的目标是求取变量的名字,在所有该变量涉及的token节点替换为特殊token<SLOT>,将终节点对应的token分解为子词素,求得子词素的平均值作为token的向量,与节点类型连接形成节点的初始向量. 利用GRU(gate recurrent unit)进行消息传递,聚合<SLOT>节点的邻居信息;对子词素的向量求平均值并送入GRU输出子词素序列,组合成变量的名字. AST中可能存在很多重复的节点,CCAG[23 ] 将AST的树结构转化为图结构,通过遍历将AST转化为序列,将序列中的重复节点合并为一个节点,新生成的图结构中的边表示两端的节点在序列中相邻,消除了重复标识节点. 在新生成的图结构中,利用注意力机制进行消息传递. ...
3
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 4)第4种研究思路是将AST看作特殊的图结构,利用消息传递方法提取AST的向量. 例如Allamanis等[22 ] 的目标是求取变量的名字,在所有该变量涉及的token节点替换为特殊token<SLOT>,将终节点对应的token分解为子词素,求得子词素的平均值作为token的向量,与节点类型连接形成节点的初始向量. 利用GRU(gate recurrent unit)进行消息传递,聚合<SLOT>节点的邻居信息;对子词素的向量求平均值并送入GRU输出子词素序列,组合成变量的名字. AST中可能存在很多重复的节点,CCAG[23 ] 将AST的树结构转化为图结构,通过遍历将AST转化为序列,将序列中的重复节点合并为一个节点,新生成的图结构中的边表示两端的节点在序列中相邻,消除了重复标识节点. 在新生成的图结构中,利用注意力机制进行消息传递. ...
... 2)利用消息传递方法,提取AST的向量(2.1节的第4种思路). Yang等[24 ] 将AST转化为图,利用GRU进行消息传递,利用注意力机制聚合所有节点的向量,与对应的父亲节点向量连接后,利用该向量预测节点. Brockschmidt等[74 ] 采用序列到序列模型,在AST增加了继承节点和合成节点,反映上下文、已生成部分AST及子树的信息,编码器采用GRU进行消息传递,解码器采用属性文法驱动的AST产生策略生成节点和对应的边. Wang等[23 ] 通过序列化遍历,将AST的树结构转化为图结构,消除了重复标识节点. 利用注意力在图内节点和表示AST树结构的父子关系节点之间进行消息传递,利用注意力聚合所有的图内节点形成图的向量表示,将该向量映射到词袋的数值类型空间来预测节点. ...
A graph sequence neural architecture for code completion with semantic structure features
2
2022
... AST-based model
Tab.1 研究思路 相关文献 思路1:基于AST路径表示学习 Code2vec[8 ] 、code2seq[9 ] 、文献[10 ]、mocktail[11 ] 思路2:基于子树表示学习 CAST[12 ] 、ASTNN[13 ] 、InferCode[14 ] 、TreeCaps[15 ] 、文献[16 ] 思路3:扁平化AST 文献[17 ]、DeepCom[18 ] 、文献[19 ]、 20 ]、文献[21 ] 思路4:基于网络表示学习 文献[22 ]、CCAG[23 ] 、文献[24 ]
1)第1种研究思路是基于AST路径表示学习. 最早基于AST路径表示学习的研究是Alon等[8 ] 提出的code2vec模型. code2vec模型利用AST路径来表示语义,一条AST路径是从一个终节点到另一个终节点,一段代码可以表示为AST范围内所有路径的集合. 建立节点和路径的词库,可以从词库中查询得到节点和路径的向量. 定义上下文向量为起点节点向量、终点节点向量和路径向量的连接. 通过注意力机制分配各条AST路径对应的上下文向量的权重,生成代码的嵌入. 由于节点和路径都采用封闭的词库,code2vec不能用于预测训练集之外的程序. 为了解决该问题,在后续的工作中,Alon等[9 ] 提出的code2seq模型与code2vec不同,终节点被分解为子词素(subtoken),通过求和得到节点向量. 路径表示为所经过节点的序列,获取节点向量后,利用Bi-LSTM(bi-directional long short-term memory)模型,求得路径向量. Code2seq不再依赖于词库,可以用于对未见过的程序进行预测. ...
... 2)利用消息传递方法,提取AST的向量(2.1节的第4种思路). Yang等[24 ] 将AST转化为图,利用GRU进行消息传递,利用注意力机制聚合所有节点的向量,与对应的父亲节点向量连接后,利用该向量预测节点. Brockschmidt等[74 ] 采用序列到序列模型,在AST增加了继承节点和合成节点,反映上下文、已生成部分AST及子树的信息,编码器采用GRU进行消息传递,解码器采用属性文法驱动的AST产生策略生成节点和对应的边. Wang等[23 ] 通过序列化遍历,将AST的树结构转化为图结构,消除了重复标识节点. 利用注意力在图内节点和表示AST树结构的父子关系节点之间进行消息传递,利用注意力聚合所有的图内节点形成图的向量表示,将该向量映射到词袋的数值类型空间来预测节点. ...
Neural code comprehension: a learnable representation of code semantics
1
2018
... 基于依赖图的模型一般直接利用消息传递神经网络、卷积神经网络模型进行节点的表示学习,将节点的向量进行聚合,生成图的向量表示. Inst2vec模型[25 ] 基于底层虚拟机(low level virtual machine, LLVM)框架[26 ] 构建语义流图,图的节点表示变量、基本块标识符、函数标识符,边表示数据依赖关系或控制依赖关系. 采用skip-gram算法进行训练,获取图的向量表示. ...
1
... 基于依赖图的模型一般直接利用消息传递神经网络、卷积神经网络模型进行节点的表示学习,将节点的向量进行聚合,生成图的向量表示. Inst2vec模型[25 ] 基于底层虚拟机(low level virtual machine, LLVM)框架[26 ] 构建语义流图,图的节点表示变量、基本块标识符、函数标识符,边表示数据依赖关系或控制依赖关系. 采用skip-gram算法进行训练,获取图的向量表示. ...
2
... 1)异构性建模研究. Inst2vec模型构建的图是同构图(即只有一种类型的节点和边),边的关系可能有多种,比如读写依赖关系、寻址依赖关系、比较依赖关系等. 若用同构图模型来建模,则所有类型的边在消息传递中的影响是相同的,不能反映实际中程序多种关系的交互差异性. Wang等[27 ] 研究利用异构网络表示学习,建构多种类型的关系. BRGCN模型[27 ] 提取了指令级的异构数据流图,边包括数据流关系、变量邻接关系、读写关系等多种关系,利用R-GCN[28 ] 进行异构表示学习. R-GCN是同构网络表示学习GCN[3 ] 的变型,在对邻居节点进行卷积操作的时候考虑所连接边的类型,分别针对不同类型的边设计卷积函数,描述不同类型的边对节点交互的异构影响. Wang等[29 ] 采用transformer框架进行异构网络表示学习,所实现transformer的注意力机制的键值(key value)和查询值(query value)都与源节点和目标节点的类型相关,从而学到异构节点的交互特征. ...
... [27 ]提取了指令级的异构数据流图,边包括数据流关系、变量邻接关系、读写关系等多种关系,利用R-GCN[28 ] 进行异构表示学习. R-GCN是同构网络表示学习GCN[3 ] 的变型,在对邻居节点进行卷积操作的时候考虑所连接边的类型,分别针对不同类型的边设计卷积函数,描述不同类型的边对节点交互的异构影响. Wang等[29 ] 采用transformer框架进行异构网络表示学习,所实现transformer的注意力机制的键值(key value)和查询值(query value)都与源节点和目标节点的类型相关,从而学到异构节点的交互特征. ...
1
... 1)异构性建模研究. Inst2vec模型构建的图是同构图(即只有一种类型的节点和边),边的关系可能有多种,比如读写依赖关系、寻址依赖关系、比较依赖关系等. 若用同构图模型来建模,则所有类型的边在消息传递中的影响是相同的,不能反映实际中程序多种关系的交互差异性. Wang等[27 ] 研究利用异构网络表示学习,建构多种类型的关系. BRGCN模型[27 ] 提取了指令级的异构数据流图,边包括数据流关系、变量邻接关系、读写关系等多种关系,利用R-GCN[28 ] 进行异构表示学习. R-GCN是同构网络表示学习GCN[3 ] 的变型,在对邻居节点进行卷积操作的时候考虑所连接边的类型,分别针对不同类型的边设计卷积函数,描述不同类型的边对节点交互的异构影响. Wang等[29 ] 采用transformer框架进行异构网络表示学习,所实现transformer的注意力机制的键值(key value)和查询值(query value)都与源节点和目标节点的类型相关,从而学到异构节点的交互特征. ...
1
... 1)异构性建模研究. Inst2vec模型构建的图是同构图(即只有一种类型的节点和边),边的关系可能有多种,比如读写依赖关系、寻址依赖关系、比较依赖关系等. 若用同构图模型来建模,则所有类型的边在消息传递中的影响是相同的,不能反映实际中程序多种关系的交互差异性. Wang等[27 ] 研究利用异构网络表示学习,建构多种类型的关系. BRGCN模型[27 ] 提取了指令级的异构数据流图,边包括数据流关系、变量邻接关系、读写关系等多种关系,利用R-GCN[28 ] 进行异构表示学习. R-GCN是同构网络表示学习GCN[3 ] 的变型,在对邻居节点进行卷积操作的时候考虑所连接边的类型,分别针对不同类型的边设计卷积函数,描述不同类型的边对节点交互的异构影响. Wang等[29 ] 采用transformer框架进行异构网络表示学习,所实现transformer的注意力机制的键值(key value)和查询值(query value)都与源节点和目标节点的类型相关,从而学到异构节点的交互特征. ...
1
... 2)偏序性建模研究. 一些研究构建节点偏序关系,描述数据计算过数据流图存在很多偏序关系,如除法指令与所参与运算的被除数、 除数的关系,被除数与除数都与除法指令相连,但是需要区分顺序才能准确地表达除法的语义. ProGraML[30 ] 利用正弦位置编码考虑了边的类型及操作数的顺序,利用哈达玛积计算消息传递函数. ...
1
... 3)传递性建模研究. 一些程序的应用中只考虑单向传递性(如调用关系),而消息传递模型一般都是对称传递的. 为了捕获图的非对称传递性,Tufano等[31 ] 采用HOPE算法[32 ] 对CFG进行表示学习. HOPE表示学习算法中,每个节点要学到源向量和目标向量2种向量,这些向量根据单向边的权重确定,有效地描述了控制流的单向依赖关系. Flow2vec[33 ] 提取了多种路径长度的数据流可达性,利用Katz指数转化为高阶的邻接矩阵,开展矩阵分解以提取每个节点的源向量和目标向量,节点之间的可达性可以通过源节点和目标节点的点积来衡量. ...
1
... 3)传递性建模研究. 一些程序的应用中只考虑单向传递性(如调用关系),而消息传递模型一般都是对称传递的. 为了捕获图的非对称传递性,Tufano等[31 ] 采用HOPE算法[32 ] 对CFG进行表示学习. HOPE表示学习算法中,每个节点要学到源向量和目标向量2种向量,这些向量根据单向边的权重确定,有效地描述了控制流的单向依赖关系. Flow2vec[33 ] 提取了多种路径长度的数据流可达性,利用Katz指数转化为高阶的邻接矩阵,开展矩阵分解以提取每个节点的源向量和目标向量,节点之间的可达性可以通过源节点和目标节点的点积来衡量. ...
1
... 3)传递性建模研究. 一些程序的应用中只考虑单向传递性(如调用关系),而消息传递模型一般都是对称传递的. 为了捕获图的非对称传递性,Tufano等[31 ] 采用HOPE算法[32 ] 对CFG进行表示学习. HOPE表示学习算法中,每个节点要学到源向量和目标向量2种向量,这些向量根据单向边的权重确定,有效地描述了控制流的单向依赖关系. Flow2vec[33 ] 提取了多种路径长度的数据流可达性,利用Katz指数转化为高阶的邻接矩阵,开展矩阵分解以提取每个节点的源向量和目标向量,节点之间的可达性可以通过源节点和目标节点的点积来衡量. ...
Modeling functional similarity in source code with graph-based Siamese networks
2
2021
... 4)消息传递范围研究. 节点间的消息传递只能获取一跳范围的邻居信息. 为了更大范围地进行消息传递,Mehrotra等[34 ] 采用基于LSTM的GeniePath,获取长距离的邻居信息 . transformer架构计算2个位置之间的关联所需的操作次数不随距离增长,Karmakar等[35 ] 利用transformer架构分析程序中的长距离依赖关系. ...
... 2)利用孪生网络(siamese network). 孪生网络有2个输入,分别对应待比较的代码. 将2个输入送入2个共享权值的神经网络,形成输入在新的空间中的表示. 通过计算2个输入的相似度与真实的标签之间的损失函数来训练模型. 与第1种研究思路的区别在于采用孪生网络后,代码的向量表示与相似性度量2个阶段是贯通的,因此代码向量表示的神经网络能够接收到反馈. Buch等[16 ] 分别基于树结构的LSTM和基于树结构的CNN来计算AST的向量表示,利用孪生网络最小化余弦相似度与标签的差距. Mehrotra等[34 ] 提取PDG,通过图注意力网络(graph attention network,GAT)[2 ] 进行消息传递获取节点的向量表示,利用注意力机制聚合节点向量形成整图的向量表示,通过孪生网络训练GAT的参数. ...
1
... 4)消息传递范围研究. 节点间的消息传递只能获取一跳范围的邻居信息. 为了更大范围地进行消息传递,Mehrotra等[34 ] 采用基于LSTM的GeniePath,获取长距离的邻居信息 . transformer架构计算2个位置之间的关联所需的操作次数不随距离增长,Karmakar等[35 ] 利用transformer架构分析程序中的长距离依赖关系. ...
2
... 基于token序列的模型与相关文献如表2 所示. Hindle等[36 ] 认为程序是人类撰写的,和文字一样具备自然性,利用n-gram构造了源代码的语言模型. Bielik等[37 ] 提出基于特定领域语言(domain-specific language)的n-gram模型,以更好地学到局部信息. Hellendoorn等[38 ] 添加了局部的n-gram缓存,融合了全局和局部模型的预测结果. n-gram模型只能对定长的token片段序列(取决于窗口的长度N)进行分析,很难捕获token间长距离的依赖信息. White等[6 ] 利用循环神经网络(recurrent neural network,RNN)[6 ] 、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... Model based on token sequence
Tab.2 模型 相关文献 n-gram语言模型 文献[36 ~38 ] RNN 文献[6 , 39 ] LSTM 文献[40 , 41 ] GRU 文献[42 , 43 ]
利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
1
... 基于token序列的模型与相关文献如表2 所示. Hindle等[36 ] 认为程序是人类撰写的,和文字一样具备自然性,利用n-gram构造了源代码的语言模型. Bielik等[37 ] 提出基于特定领域语言(domain-specific language)的n-gram模型,以更好地学到局部信息. Hellendoorn等[38 ] 添加了局部的n-gram缓存,融合了全局和局部模型的预测结果. n-gram模型只能对定长的token片段序列(取决于窗口的长度N)进行分析,很难捕获token间长距离的依赖信息. White等[6 ] 利用循环神经网络(recurrent neural network,RNN)[6 ] 、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
2
... 基于token序列的模型与相关文献如表2 所示. Hindle等[36 ] 认为程序是人类撰写的,和文字一样具备自然性,利用n-gram构造了源代码的语言模型. Bielik等[37 ] 提出基于特定领域语言(domain-specific language)的n-gram模型,以更好地学到局部信息. Hellendoorn等[38 ] 添加了局部的n-gram缓存,融合了全局和局部模型的预测结果. n-gram模型只能对定长的token片段序列(取决于窗口的长度N)进行分析,很难捕获token间长距离的依赖信息. White等[6 ] 利用循环神经网络(recurrent neural network,RNN)[6 ] 、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... Model based on token sequence
Tab.2 模型 相关文献 n-gram语言模型 文献[36 ~38 ] RNN 文献[6 , 39 ] LSTM 文献[40 , 41 ] GRU 文献[42 , 43 ]
利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
3
... 基于token序列的模型与相关文献如表2 所示. Hindle等[36 ] 认为程序是人类撰写的,和文字一样具备自然性,利用n-gram构造了源代码的语言模型. Bielik等[37 ] 提出基于特定领域语言(domain-specific language)的n-gram模型,以更好地学到局部信息. Hellendoorn等[38 ] 添加了局部的n-gram缓存,融合了全局和局部模型的预测结果. n-gram模型只能对定长的token片段序列(取决于窗口的长度N)进行分析,很难捕获token间长距离的依赖信息. White等[6 ] 利用循环神经网络(recurrent neural network,RNN)[6 ] 、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... [39 ]利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... Model based on token sequence
Tab.2 模型 相关文献 n-gram语言模型 文献[36 ~38 ] RNN 文献[6 , 39 ] LSTM 文献[40 , 41 ] GRU 文献[42 , 43 ]
利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
2
... 基于token序列的模型与相关文献如表2 所示. Hindle等[36 ] 认为程序是人类撰写的,和文字一样具备自然性,利用n-gram构造了源代码的语言模型. Bielik等[37 ] 提出基于特定领域语言(domain-specific language)的n-gram模型,以更好地学到局部信息. Hellendoorn等[38 ] 添加了局部的n-gram缓存,融合了全局和局部模型的预测结果. n-gram模型只能对定长的token片段序列(取决于窗口的长度N)进行分析,很难捕获token间长距离的依赖信息. White等[6 ] 利用循环神经网络(recurrent neural network,RNN)[6 ] 、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... Model based on token sequence
Tab.2 模型 相关文献 n-gram语言模型 文献[36 ~38 ] RNN 文献[6 , 39 ] LSTM 文献[40 , 41 ] GRU 文献[42 , 43 ]
利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
Modeling programs hierarchically with stack-augmented LSTM
1
2020
... Model based on token sequence
Tab.2 模型 相关文献 n-gram语言模型 文献[36 ~38 ] RNN 文献[6 , 39 ] LSTM 文献[40 , 41 ] GRU 文献[42 , 43 ]
利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
4
... 基于token序列的模型与相关文献如表2 所示. Hindle等[36 ] 认为程序是人类撰写的,和文字一样具备自然性,利用n-gram构造了源代码的语言模型. Bielik等[37 ] 提出基于特定领域语言(domain-specific language)的n-gram模型,以更好地学到局部信息. Hellendoorn等[38 ] 添加了局部的n-gram缓存,融合了全局和局部模型的预测结果. n-gram模型只能对定长的token片段序列(取决于窗口的长度N)进行分析,很难捕获token间长距离的依赖信息. White等[6 ] 利用循环神经网络(recurrent neural network,RNN)[6 ] 、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... [42 -43 ]利用GRU来加速token序列的表示学习过程. ...
... Model based on token sequence
Tab.2 模型 相关文献 n-gram语言模型 文献[36 ~38 ] RNN 文献[6 , 39 ] LSTM 文献[40 , 41 ] GRU 文献[42 , 43 ]
利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
... 注释生成(comment generation)或代码总结(code summarization)是指为一段代码生成一句话用以总结代码的功能,可以帮助开发人员理解代码背后的语义,有利于提升代码的可读性和可维护性. 注释生成问题可以转化为文本序列生成问题,输入是源代码,输出是注释文本. 注释生成可以看作是神经机器翻译(neural machine translation,NMT)的一个应用. NMT采用编码器-解码器框架,编码器将源语言序列进行编码,提取源语言中的信息,通过解码器将该信息转换到另一种语言中,完成对语言的翻译. NMT将一段英文翻译成中文,生成注释可以看作是将源代码翻译为注释的过程. Hu等[18 ] 提出DeepCom模型,采用NMT框架,基于结构的遍历将AST扁平化(2.1节的思路3),编码器利用LSTM提取AST序列的上下文状态,通过注意力机制将每个时刻的上下文状态聚合,解码器利用上下文状态、隐藏状态和上一个时刻输出的token计算输出某一个token的概率,通过最小化交叉熵确定输出. Li等[42 ] 提出DeepCommenter模型,编码器利用GRU提取代码token序列和AST扁平化后的token序列的向量表示,利用注意力机制融合2组向量并送入解码器中,解码器根据上一个输出的token及融合后的向量,输出当前时刻的token. Iyer等[78 ] 提出CODE-NN模型,利用注意力机制建立代码token和输出之间的联系,将代码token和已输出的文本送入LSTM模型,选择最大概率出现的token作为当前输出. 为了捕获代码token的长距离依赖,Yang等[79 ] 提出MMTrans模型,在编码器的设计上,利用GCN学习到AST图结构的局部语义信息,利用自注意力机制学习到AST扁平化后token序列的全局语义信息. 在解码器的设计上,利用自注意力机制,将全局语义信息、局部语义信息和之前输出的注释token进行融合,计算注释token. ...
2
... 基于token序列的模型与相关文献如表2 所示. Hindle等[36 ] 认为程序是人类撰写的,和文字一样具备自然性,利用n-gram构造了源代码的语言模型. Bielik等[37 ] 提出基于特定领域语言(domain-specific language)的n-gram模型,以更好地学到局部信息. Hellendoorn等[38 ] 添加了局部的n-gram缓存,融合了全局和局部模型的预测结果. n-gram模型只能对定长的token片段序列(取决于窗口的长度N)进行分析,很难捕获token间长距离的依赖信息. White等[6 ] 利用循环神经网络(recurrent neural network,RNN)[6 ] 、LSTM[39 ] 、GRU[42 ] 等模型,提取token的向量表示. RNN模型在捕获长距离依赖上比n-gram模型能力更强,因为RNN模型的隐藏状态能够描述更长距离的依赖关系. White等[6 ] 利用RNN提取token的向量表示,Bhoopchand等[40 ] 使用RNN提取token上下文,利用稀疏指针网络(sparse pointer network)捕获长距离依赖. Dam等[39 ] 利用LSTM模型提取token的向量表示,LSTM引入门控机制来控制信息传递的路径,因而LSTM比RNN捕获token长距离依赖的能力更强. GRU与LSTM结构类似,但门的数量和模型参数都更少,因而GRU比LSTM的训练收敛速度更快. Li等[42 -43 ] 利用GRU来加速token序列的表示学习过程. ...
... Model based on token sequence
Tab.2 模型 相关文献 n-gram语言模型 文献[36 ~38 ] RNN 文献[6 , 39 ] LSTM 文献[40 , 41 ] GRU 文献[42 , 43 ]
利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
1
... 利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
2
... 利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
... [45 ]. Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
2
... 利用预训练技术,能够显著提升自然语言处理模型的预测效能. 预训练过程是通过无标注样本训练深层网络结构,使用标注样本进行模型参数微调. Mikolov等[5 , 44 ] 利用word2vec、GloVe、BERT[45 ] 进行token的预训练,提升模型性能. 其中BERT是双向Transformer的编码器,通过遮蔽语言模型和下一句预测2种预训练目标来调整模型参数[45 ] . Feng等[46 ] 提出多模态的预训练模型,利用不同模态的信息互补作用,有效提升了模型的整体表征能力. CodeBERT基于文档和代码,在自然语言和程序语言双模态下,利用BERT进行预训练,提取自然语言和程序语言之间的语义连接,为下游任务提供通用表示向量[46 ] . ...
... [46 ]. ...
3
... 程序中存在大量用户自己定义的标识符, 不同用户的命名习惯不同. 在对程序代码的token 建模时, 预先构建好的词库往往不能满足建模的需求. 无论定义多大的词库, 仍然会存在出现在词库之外(out of vocabulary,OoV)的token,如何提取词库之外的token的编码是需要解决的一个问题. 解决该问题的思路有字节对编码(byte pair encoding)[47 ] 、复制机制(copying mechanism)[48 ] 等. 字节对编码通过无监督学习找到词库中使用频率最高的子词,递归地合并高使用频率的字节对,压缩词库的容量并缓解OoV问题. Karampatsis等[49 ] 针对OoV问题,提出开放词库模型. 开放词库不受词库容量的限制,输出的是子词单元序列. 子词单元是训练集中token的子串. 子词的词库是通过字节对编码从训练集中推断出来的. ...
... Model based on the fusion of grammar and semantics
Tab.3 相关文献 语法模型 语义模型 融合方式 代码token AST CDFG DFG CFG PDG 向量连接 向量均值 多层感知机 矩阵乘法 POEM[50 ] — √ √ — — — √ — — — GraphCode2Vec[51 ] √ — — — — √ √ — — — 文献[10 ] — √ — √ — √ — — — √ mocktail[11 ] — √ — — √ √ √ — — — Devign[52 ] — √ — √ √ — — √ — — 文献[53 ] — √ — — √ — √ — — — 文献[47 ] — √ √ — — — — — √ —
2)进行图的融合,形成单一图后进行表示学习[54 ] . FUNDED模型[54 ] 在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
... 由于缺陷修复模型未涉及编程语言的语法知识,打过补丁的代码可能存在语法错误而无法通过编译. Jiang等[47 ] 提出CURE模型,提出新的补丁搜索策略,通过检查语句和标识符的语法以及过滤掉过长或过短的token序列,解决搜索策略忽视语法规则的问题. ExpTrans模型[59 ] 在产生代码的过程中动态地生成表示中间结果的AST. 基于预测的下一条指令对当前的AST最左边待扩展的节点进行扩展,直至生成最终的代码,以保证代码的可编译性. ...
2
... 程序中存在大量用户自己定义的标识符, 不同用户的命名习惯不同. 在对程序代码的token 建模时, 预先构建好的词库往往不能满足建模的需求. 无论定义多大的词库, 仍然会存在出现在词库之外(out of vocabulary,OoV)的token,如何提取词库之外的token的编码是需要解决的一个问题. 解决该问题的思路有字节对编码(byte pair encoding)[47 ] 、复制机制(copying mechanism)[48 ] 等. 字节对编码通过无监督学习找到词库中使用频率最高的子词,递归地合并高使用频率的字节对,压缩词库的容量并缓解OoV问题. Karampatsis等[49 ] 针对OoV问题,提出开放词库模型. 开放词库不受词库容量的限制,输出的是子词单元序列. 子词单元是训练集中token的子串. 子词的词库是通过字节对编码从训练集中推断出来的. ...
... 2)使用序列到序列模型直接生成token序列,将token序列拼接成函数名,这种思路生成的函数名不受已有函数名的限制. Allamanis等[76 ] 利用RNN生成当前输出序列的隐藏状态表示,通过卷积注意力神经网络在当前输出序列的状态向量下计算表示子词素在每个位置分布的注意力特征矩阵,获取子词素在某个位置的概率,选择概率最大的子词素作为输出. Meth2vec[77 ] 提取了PDG的路径、函数的中间表示(intermediate representation)和函数注释的向量表示,分别定义了位置编码,将向量表示与位置编码输入transformer模型编码器,解码器输出token序列,拼接后为预测函数名. Gao等[48 ] 利用文档中对函数的描述语句,生成函数名. 与传统的RNN不同,设计的解码器考虑了多个隐藏状态,通过注意力机制聚合多个隐藏状态,得到当前输出. ...
1
... 程序中存在大量用户自己定义的标识符, 不同用户的命名习惯不同. 在对程序代码的token 建模时, 预先构建好的词库往往不能满足建模的需求. 无论定义多大的词库, 仍然会存在出现在词库之外(out of vocabulary,OoV)的token,如何提取词库之外的token的编码是需要解决的一个问题. 解决该问题的思路有字节对编码(byte pair encoding)[47 ] 、复制机制(copying mechanism)[48 ] 等. 字节对编码通过无监督学习找到词库中使用频率最高的子词,递归地合并高使用频率的字节对,压缩词库的容量并缓解OoV问题. Karampatsis等[49 ] 针对OoV问题,提出开放词库模型. 开放词库不受词库容量的限制,输出的是子词单元序列. 子词单元是训练集中token的子串. 子词的词库是通过字节对编码从训练集中推断出来的. ...
2
... 1)在读出层得到整图的向量后,利用向量的连接、矩阵乘法和注意力机制(attention mechanism)进行融合. 读出层的融合模型如表3 所示. POEM模型[50 ] 融合了AST的6种关系和CDFG的4种关系,每一个关系对应一个子图,在每个子图上通过多层感知机(multilayer perceptron)进行消息传递,将10个子图的向量连接得到最终的图向量. GraphCode2Vec模型[51 ] 将图表示学习得到的向量与token序列表示学习得到的向量进行融合,利用Bi-LSTM得到指令的向量表示,将指令的向量叠加得到程序在语法层面的向量表示. 提取PDG并利用消息传递得到程序在语义层面的向量表示,将语法层面和语义层面的向量连接,得到最终的向量表示. ...
... Model based on the fusion of grammar and semantics
Tab.3 相关文献 语法模型 语义模型 融合方式 代码token AST CDFG DFG CFG PDG 向量连接 向量均值 多层感知机 矩阵乘法 POEM[50 ] — √ √ — — — √ — — — GraphCode2Vec[51 ] √ — — — — √ √ — — — 文献[10 ] — √ — √ — √ — — — √ mocktail[11 ] — √ — — √ √ √ — — — Devign[52 ] — √ — √ √ — — √ — — 文献[53 ] — √ — — √ — √ — — — 文献[47 ] — √ √ — — — — — √ —
2)进行图的融合,形成单一图后进行表示学习[54 ] . FUNDED模型[54 ] 在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
2
... 1)在读出层得到整图的向量后,利用向量的连接、矩阵乘法和注意力机制(attention mechanism)进行融合. 读出层的融合模型如表3 所示. POEM模型[50 ] 融合了AST的6种关系和CDFG的4种关系,每一个关系对应一个子图,在每个子图上通过多层感知机(multilayer perceptron)进行消息传递,将10个子图的向量连接得到最终的图向量. GraphCode2Vec模型[51 ] 将图表示学习得到的向量与token序列表示学习得到的向量进行融合,利用Bi-LSTM得到指令的向量表示,将指令的向量叠加得到程序在语法层面的向量表示. 提取PDG并利用消息传递得到程序在语义层面的向量表示,将语法层面和语义层面的向量连接,得到最终的向量表示. ...
... Model based on the fusion of grammar and semantics
Tab.3 相关文献 语法模型 语义模型 融合方式 代码token AST CDFG DFG CFG PDG 向量连接 向量均值 多层感知机 矩阵乘法 POEM[50 ] — √ √ — — — √ — — — GraphCode2Vec[51 ] √ — — — — √ √ — — — 文献[10 ] — √ — √ — √ — — — √ mocktail[11 ] — √ — — √ √ √ — — — Devign[52 ] — √ — √ √ — — √ — — 文献[53 ] — √ — — √ — √ — — — 文献[47 ] — √ √ — — — — — √ —
2)进行图的融合,形成单一图后进行表示学习[54 ] . FUNDED模型[54 ] 在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
2
... Model based on the fusion of grammar and semantics
Tab.3 相关文献 语法模型 语义模型 融合方式 代码token AST CDFG DFG CFG PDG 向量连接 向量均值 多层感知机 矩阵乘法 POEM[50 ] — √ √ — — — √ — — — GraphCode2Vec[51 ] √ — — — — √ √ — — — 文献[10 ] — √ — √ — √ — — — √ mocktail[11 ] — √ — — √ √ √ — — — Devign[52 ] — √ — √ √ — — √ — — 文献[53 ] — √ — — √ — √ — — — 文献[47 ] — √ √ — — — — — √ —
2)进行图的融合,形成单一图后进行表示学习[54 ] . FUNDED模型[54 ] 在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
... Li等[10 ] 通过融合AST、CFG和DFG等多种图的信息,更全面地描述缺陷及上下文语义. Devign模型[52 ] 提取语句级别的AST、CFG和DFG,利用GRU进行消息传递,通过卷积层获取所代表函数的子图向量. Li等[10 ] 通过GRU和卷积层从AST路径中获取目标函数的向量表示,形成局部视角的描述,利用node2vec[65 ] 获取PDG和DFG的向量表示,形成全局视角的描述,利用矩阵乘法融合局部视角和全局视角的向量进行预测. ...
2
... Model based on the fusion of grammar and semantics
Tab.3 相关文献 语法模型 语义模型 融合方式 代码token AST CDFG DFG CFG PDG 向量连接 向量均值 多层感知机 矩阵乘法 POEM[50 ] — √ √ — — — √ — — — GraphCode2Vec[51 ] √ — — — — √ √ — — — 文献[10 ] — √ — √ — √ — — — √ mocktail[11 ] — √ — — √ √ √ — — — Devign[52 ] — √ — √ √ — — √ — — 文献[53 ] — √ — — √ — √ — — — 文献[47 ] — √ √ — — — — — √ —
2)进行图的融合,形成单一图后进行表示学习[54 ] . FUNDED模型[54 ] 在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
... 1)求取代码的向量表示,度量向量的相似性. Fang等[53 ] 利用word2vec提取AST的语法向量,利用Graph2Vec提取CFG的语义向量,将语法向量和语义向量进行融合,融合后的向量送入深度神经网络,最终输出是否是代码克隆. ...
Combining graph-based learning with automated data collection for code vulnerability detection
2
2020
... 2)进行图的融合,形成单一图后进行表示学习[54 ] . FUNDED模型[54 ] 在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
... [54 ]在AST上添加新的边,以表示数据流、控制流信息,形成新的增强型AST(augmented AST),在该增强型AST上进行消息传递. 比如定义的computedfrom边连接赋值操作所涉及的token,描述了token之间的数据依赖关系,这些关系原本是在数据流图中进行描述,在AST中补充了数据流、控制流关系. ...
1
... 3)利用transformer中的注意力机制,自动融合多个图的向量. SiT[55 ] 提取了AST、控制流和数据流3个视图,3个视图的节点集相同,边集不同. 当进行注意力计算时,添加了每个视图的邻接矩阵并屏蔽掉不相连的边对应的注意力传播. GraphCodeBert[56 ] 将变量序列、代码token序列和注释序列送入transformer解码器,定义了代码token和变量之间的边来表示对应关系,变量与变量之间的边表示数据依赖关系,利用屏蔽注意力函数过滤未连接的节点之间的信号. SG-Trans[57 ] 在transformer架构中添加同一token的子词素、同一语句的token、数据流关联的token之间的自注意力机制,将语句层、代码token层和数据流层的向量进行融合. ...
1
... 3)利用transformer中的注意力机制,自动融合多个图的向量. SiT[55 ] 提取了AST、控制流和数据流3个视图,3个视图的节点集相同,边集不同. 当进行注意力计算时,添加了每个视图的邻接矩阵并屏蔽掉不相连的边对应的注意力传播. GraphCodeBert[56 ] 将变量序列、代码token序列和注释序列送入transformer解码器,定义了代码token和变量之间的边来表示对应关系,变量与变量之间的边表示数据依赖关系,利用屏蔽注意力函数过滤未连接的节点之间的信号. SG-Trans[57 ] 在transformer架构中添加同一token的子词素、同一语句的token、数据流关联的token之间的自注意力机制,将语句层、代码token层和数据流层的向量进行融合. ...
1
... 3)利用transformer中的注意力机制,自动融合多个图的向量. SiT[55 ] 提取了AST、控制流和数据流3个视图,3个视图的节点集相同,边集不同. 当进行注意力计算时,添加了每个视图的邻接矩阵并屏蔽掉不相连的边对应的注意力传播. GraphCodeBert[56 ] 将变量序列、代码token序列和注释序列送入transformer解码器,定义了代码token和变量之间的边来表示对应关系,变量与变量之间的边表示数据依赖关系,利用屏蔽注意力函数过滤未连接的节点之间的信号. SG-Trans[57 ] 在transformer架构中添加同一token的子词素、同一语句的token、数据流关联的token之间的自注意力机制,将语句层、代码token层和数据流层的向量进行融合. ...
1
... 缺陷检测(defect detection)的目的是提前预测可能存在缺陷的软件模块. 借助于缺陷检测技术,能够提高软件质量,节省软件维护成本. 缺陷检测输入是源代码,输出是源代码是否含有缺陷. 一类工作以代码的自然性为理论基础,自然性低的程序更可能包含缺陷,通过度量程序的自然性来进行缺陷检测. Ray等[58 ] 利用n-gram模型分析缺陷修复提交单,发现有缺陷的代码拥有更高的交叉熵(对应低自然性),修复缺陷后,交叉熵降低. CNDePor[59 ] 利用多层栈式LSTM网络,从输入的词向量序列中学习隐含的语义特征,结合该语义特征与其他特征(如代码行数),送入分类器进行预测. ...
基于代码自然性的切片粒度缺陷预测方法
2
2021
... 缺陷检测(defect detection)的目的是提前预测可能存在缺陷的软件模块. 借助于缺陷检测技术,能够提高软件质量,节省软件维护成本. 缺陷检测输入是源代码,输出是源代码是否含有缺陷. 一类工作以代码的自然性为理论基础,自然性低的程序更可能包含缺陷,通过度量程序的自然性来进行缺陷检测. Ray等[58 ] 利用n-gram模型分析缺陷修复提交单,发现有缺陷的代码拥有更高的交叉熵(对应低自然性),修复缺陷后,交叉熵降低. CNDePor[59 ] 利用多层栈式LSTM网络,从输入的词向量序列中学习隐含的语义特征,结合该语义特征与其他特征(如代码行数),送入分类器进行预测. ...
... 由于缺陷修复模型未涉及编程语言的语法知识,打过补丁的代码可能存在语法错误而无法通过编译. Jiang等[47 ] 提出CURE模型,提出新的补丁搜索策略,通过检查语句和标识符的语法以及过滤掉过长或过短的token序列,解决搜索策略忽视语法规则的问题. ExpTrans模型[59 ] 在产生代码的过程中动态地生成表示中间结果的AST. 基于预测的下一条指令对当前的AST最左边待扩展的节点进行扩展,直至生成最终的代码,以保证代码的可编译性. ...
基于代码自然性的切片粒度缺陷预测方法
2
2021
... 缺陷检测(defect detection)的目的是提前预测可能存在缺陷的软件模块. 借助于缺陷检测技术,能够提高软件质量,节省软件维护成本. 缺陷检测输入是源代码,输出是源代码是否含有缺陷. 一类工作以代码的自然性为理论基础,自然性低的程序更可能包含缺陷,通过度量程序的自然性来进行缺陷检测. Ray等[58 ] 利用n-gram模型分析缺陷修复提交单,发现有缺陷的代码拥有更高的交叉熵(对应低自然性),修复缺陷后,交叉熵降低. CNDePor[59 ] 利用多层栈式LSTM网络,从输入的词向量序列中学习隐含的语义特征,结合该语义特征与其他特征(如代码行数),送入分类器进行预测. ...
... 由于缺陷修复模型未涉及编程语言的语法知识,打过补丁的代码可能存在语法错误而无法通过编译. Jiang等[47 ] 提出CURE模型,提出新的补丁搜索策略,通过检查语句和标识符的语法以及过滤掉过长或过短的token序列,解决搜索策略忽视语法规则的问题. ExpTrans模型[59 ] 在产生代码的过程中动态地生成表示中间结果的AST. 基于预测的下一条指令对当前的AST最左边待扩展的节点进行扩展,直至生成最终的代码,以保证代码的可编译性. ...
基于图神经网络的代码漏洞检测方法
1
2021
... 缺陷检测问题可以转换成为图分类问题. 提取代码的CFG、AST进行语义分析,获取整图的向量表示,输入分类器中对代码是否有缺陷进行判定. CFG反映了程序的调用关系,基于CFG的工作的主要思路是通过检测程序调用关系的异常来识别缺陷. 一般利用CNN的平移不变性来提取基本块的调用顺序信息. 陈皓等[60 ] 使用多层图卷积和池化层,完成CFG图级别上的缺陷判别. Phan等[61 ] 提取指令级的CFG,经过卷积层、池化层和全连接层输出整图的向量表示. ...
基于图神经网络的代码漏洞检测方法
1
2021
... 缺陷检测问题可以转换成为图分类问题. 提取代码的CFG、AST进行语义分析,获取整图的向量表示,输入分类器中对代码是否有缺陷进行判定. CFG反映了程序的调用关系,基于CFG的工作的主要思路是通过检测程序调用关系的异常来识别缺陷. 一般利用CNN的平移不变性来提取基本块的调用顺序信息. 陈皓等[60 ] 使用多层图卷积和池化层,完成CFG图级别上的缺陷判别. Phan等[61 ] 提取指令级的CFG,经过卷积层、池化层和全连接层输出整图的向量表示. ...
1
... 缺陷检测问题可以转换成为图分类问题. 提取代码的CFG、AST进行语义分析,获取整图的向量表示,输入分类器中对代码是否有缺陷进行判定. CFG反映了程序的调用关系,基于CFG的工作的主要思路是通过检测程序调用关系的异常来识别缺陷. 一般利用CNN的平移不变性来提取基本块的调用顺序信息. 陈皓等[60 ] 使用多层图卷积和池化层,完成CFG图级别上的缺陷判别. Phan等[61 ] 提取指令级的CFG,经过卷积层、池化层和全连接层输出整图的向量表示. ...
Deep semantic feature learning for software defect prediction
1
2018
... 缺陷会影响上下文语法及语义联系,基于AST的工作的主要思路是通过深度神经网络提取上下文语法及语义信息来识别缺陷. Wang等[62 ] 提取了程序的AST的token序列,利用深度置信网络生成多层抽象与上层语义特征,进行缺陷分类. Xu等[63 ] 构建AST并抽取代码中的变量名、函数名语义信息,通过主题模型选出最高概率的词来描述上下文信息,利用word2vec模型生成嵌入表示,融合AST和上下文信息进行缺陷的预测. Wang等[64 ] 利用层次化LSTM从AST的嵌入表示中提取语义特征,与传统的代码特征(如代码行数)进行融合来识别缺陷. ...
Defect prediction with semantics and context features of codes based on graph representation learning
1
2020
... 缺陷会影响上下文语法及语义联系,基于AST的工作的主要思路是通过深度神经网络提取上下文语法及语义信息来识别缺陷. Wang等[62 ] 提取了程序的AST的token序列,利用深度置信网络生成多层抽象与上层语义特征,进行缺陷分类. Xu等[63 ] 构建AST并抽取代码中的变量名、函数名语义信息,通过主题模型选出最高概率的词来描述上下文信息,利用word2vec模型生成嵌入表示,融合AST和上下文信息进行缺陷的预测. Wang等[64 ] 利用层次化LSTM从AST的嵌入表示中提取语义特征,与传统的代码特征(如代码行数)进行融合来识别缺陷. ...
Software defect prediction based on gated hierarchical LSTMs
1
2021
... 缺陷会影响上下文语法及语义联系,基于AST的工作的主要思路是通过深度神经网络提取上下文语法及语义信息来识别缺陷. Wang等[62 ] 提取了程序的AST的token序列,利用深度置信网络生成多层抽象与上层语义特征,进行缺陷分类. Xu等[63 ] 构建AST并抽取代码中的变量名、函数名语义信息,通过主题模型选出最高概率的词来描述上下文信息,利用word2vec模型生成嵌入表示,融合AST和上下文信息进行缺陷的预测. Wang等[64 ] 利用层次化LSTM从AST的嵌入表示中提取语义特征,与传统的代码特征(如代码行数)进行融合来识别缺陷. ...
1
... Li等[10 ] 通过融合AST、CFG和DFG等多种图的信息,更全面地描述缺陷及上下文语义. Devign模型[52 ] 提取语句级别的AST、CFG和DFG,利用GRU进行消息传递,通过卷积层获取所代表函数的子图向量. Li等[10 ] 通过GRU和卷积层从AST路径中获取目标函数的向量表示,形成局部视角的描述,利用node2vec[65 ] 获取PDG和DFG的向量表示,形成全局视角的描述,利用矩阵乘法融合局部视角和全局视角的向量进行预测. ...
Deep transfer bug localization
1
2019
... 缺陷定位问题(bug localization)是指获取缺陷报告后,快速定位与该缺陷相关的代码及所在的文件. 缺陷定位与缺陷检测的区别在于缺陷定位已明确出现了缺陷,缺陷检测不确定是否有缺陷. 由于一个软件可能包含海量的代码文件,利用缺陷定位技术可以极大地减轻程序员的代码排查任务量. 缺陷定位问题可以转化为子图分类问题,输入是源代码文件集合和缺陷报告集合,输出是每一个源代码文件是否与缺陷报告相关. TRANP-CNN[66 ] 利用word2vec模型提取源代码文件和缺陷报告的向量表示,利用CNN模型从源代码文件和缺陷报告提取语义特征,利用全连接层学到两者之间的关联,最终输出分类. Zhu等[67 ] 提出COOBA模型,利用GloVe模型生成缺陷报告单词的向量表示,利用Bi-LSTM生成缺陷报告的向量表示;提取源代码文件的AST,利用GloVe生成token的初始向量,通过GCN提取AST的私有语义特征,利用对抗训练生成公有语义特征,融合私有语义特征和公有语义特征,形成源代码的最终向量,计算缺陷报告和源代码向量的距离. Yang等[68 ] 提出MRAM模型,利用双向RNN从token序列、API调用序列和函数注释中提取特征,利用注意力机制聚合这3个视图得到的源代码特征,利用双向RNN提取缺陷报告的特征,通过多层感知机计算缺陷报告和源代码特征的相关性得分,通过多层感知机融合相关性得分与从代码修订图(code revision graph)中提取的特征,得到该段源代码与缺陷报告相关的概率. ...
1
... 缺陷定位问题(bug localization)是指获取缺陷报告后,快速定位与该缺陷相关的代码及所在的文件. 缺陷定位与缺陷检测的区别在于缺陷定位已明确出现了缺陷,缺陷检测不确定是否有缺陷. 由于一个软件可能包含海量的代码文件,利用缺陷定位技术可以极大地减轻程序员的代码排查任务量. 缺陷定位问题可以转化为子图分类问题,输入是源代码文件集合和缺陷报告集合,输出是每一个源代码文件是否与缺陷报告相关. TRANP-CNN[66 ] 利用word2vec模型提取源代码文件和缺陷报告的向量表示,利用CNN模型从源代码文件和缺陷报告提取语义特征,利用全连接层学到两者之间的关联,最终输出分类. Zhu等[67 ] 提出COOBA模型,利用GloVe模型生成缺陷报告单词的向量表示,利用Bi-LSTM生成缺陷报告的向量表示;提取源代码文件的AST,利用GloVe生成token的初始向量,通过GCN提取AST的私有语义特征,利用对抗训练生成公有语义特征,融合私有语义特征和公有语义特征,形成源代码的最终向量,计算缺陷报告和源代码向量的距离. Yang等[68 ] 提出MRAM模型,利用双向RNN从token序列、API调用序列和函数注释中提取特征,利用注意力机制聚合这3个视图得到的源代码特征,利用双向RNN提取缺陷报告的特征,通过多层感知机计算缺陷报告和源代码特征的相关性得分,通过多层感知机融合相关性得分与从代码修订图(code revision graph)中提取的特征,得到该段源代码与缺陷报告相关的概率. ...
1
... 缺陷定位问题(bug localization)是指获取缺陷报告后,快速定位与该缺陷相关的代码及所在的文件. 缺陷定位与缺陷检测的区别在于缺陷定位已明确出现了缺陷,缺陷检测不确定是否有缺陷. 由于一个软件可能包含海量的代码文件,利用缺陷定位技术可以极大地减轻程序员的代码排查任务量. 缺陷定位问题可以转化为子图分类问题,输入是源代码文件集合和缺陷报告集合,输出是每一个源代码文件是否与缺陷报告相关. TRANP-CNN[66 ] 利用word2vec模型提取源代码文件和缺陷报告的向量表示,利用CNN模型从源代码文件和缺陷报告提取语义特征,利用全连接层学到两者之间的关联,最终输出分类. Zhu等[67 ] 提出COOBA模型,利用GloVe模型生成缺陷报告单词的向量表示,利用Bi-LSTM生成缺陷报告的向量表示;提取源代码文件的AST,利用GloVe生成token的初始向量,通过GCN提取AST的私有语义特征,利用对抗训练生成公有语义特征,融合私有语义特征和公有语义特征,形成源代码的最终向量,计算缺陷报告和源代码向量的距离. Yang等[68 ] 提出MRAM模型,利用双向RNN从token序列、API调用序列和函数注释中提取特征,利用注意力机制聚合这3个视图得到的源代码特征,利用双向RNN提取缺陷报告的特征,通过多层感知机计算缺陷报告和源代码特征的相关性得分,通过多层感知机融合相关性得分与从代码修订图(code revision graph)中提取的特征,得到该段源代码与缺陷报告相关的概率. ...
1
... 软件缺陷修复的任务耗费大量的人力资源和时间,利用自动程序修复(automated program repair)技术,可以辅助开发人员完成代码的修改任务. 自动程序修复的目标是针对存在缺陷的程序寻找最少的补丁,使得程序能够通过测试. 自动程序修复可以转换为由存在缺陷的源代码到正确源代码的翻译问题,输入是有缺陷的源代码,输出是修复后的代码. 思路是利用序列到序列模型进行源代码的语义提取,在上下文环境下利用解码器输出代码token序列. Lutellier等[69 ] 利用卷积层对缺陷行、缺陷行上下文提取向量表示,利用注意力机制来连接各卷积层输出与解码器输入,解码器利用缺陷行和上下文环境生成token序列. DLFix[70 ] 针对存在缺陷的源代码和修复后的源代码分别构建AST,利用基于树结构的RNN模型学习缺陷及修复代码的上下文向量. 将缺陷子树、修复代码子树及相应的上下文送入基于树结构的编码器-解码器模型,学习到缺陷修复的对应转换,基于CNN对生成的候选补丁进行排序. ...
1
... 软件缺陷修复的任务耗费大量的人力资源和时间,利用自动程序修复(automated program repair)技术,可以辅助开发人员完成代码的修改任务. 自动程序修复的目标是针对存在缺陷的程序寻找最少的补丁,使得程序能够通过测试. 自动程序修复可以转换为由存在缺陷的源代码到正确源代码的翻译问题,输入是有缺陷的源代码,输出是修复后的代码. 思路是利用序列到序列模型进行源代码的语义提取,在上下文环境下利用解码器输出代码token序列. Lutellier等[69 ] 利用卷积层对缺陷行、缺陷行上下文提取向量表示,利用注意力机制来连接各卷积层输出与解码器输入,解码器利用缺陷行和上下文环境生成token序列. DLFix[70 ] 针对存在缺陷的源代码和修复后的源代码分别构建AST,利用基于树结构的RNN模型学习缺陷及修复代码的上下文向量. 将缺陷子树、修复代码子树及相应的上下文送入基于树结构的编码器-解码器模型,学习到缺陷修复的对应转换,基于CNN对生成的候选补丁进行排序. ...
智能代码补全研究综述
1
2020
... 代码补全(code completion)是自动化软件开发的重要功能之一,是大多数现代集成开发环境和源代码编辑器的重要组件[71 ] . 代码补全提供即时类名、方法名和关键字等预测,辅助开发人员编写程序,提高软件开发效率. 通过程序表示学习的方式来进行代码补全的研究思路主要有以下2种. ...
智能代码补全研究综述
1
2020
... 代码补全(code completion)是自动化软件开发的重要功能之一,是大多数现代集成开发环境和源代码编辑器的重要组件[71 ] . 代码补全提供即时类名、方法名和关键字等预测,辅助开发人员编写程序,提高软件开发效率. 通过程序表示学习的方式来进行代码补全的研究思路主要有以下2种. ...
1
... 1)将AST扁平化处理(2.1节的第3种思路),利用序列表示学习技术预测下一个出现的节点. Liu等[17 ] 定义部分AST的概念,部分AST是指AST的一个子树,在AST中位于部分AST所有节点的左边节点都包含于该部分AST中. 给定部分AST,代码补全转化为预测部分AST位于最右侧节点的下一个节点. 利用前序深度优先遍历部分AST,生成非终节点和终节点的节点对,节点对的非终节点是终节点的父亲节点,节点对的向量是非终节点和终节点向量的加权和,通过LSTM来预测下一个出现的非终节点或终节点. 由于扁平化的AST失去了节点的父子关系表示,Li等[72 ] 提出增加父亲节点的向量表示,将上下文向量、父亲节点向量利用注意力机制融合后,输入LSTM模型中. 为了提取AST层次化的信息,Liu等[73 ] 提取从预测节点到根节点的路径序列,通过Bi-LSTM生成路径序列的向量表示. 将节点对的向量与路径序列向量连接,预测节点. ...
1
... 1)将AST扁平化处理(2.1节的第3种思路),利用序列表示学习技术预测下一个出现的节点. Liu等[17 ] 定义部分AST的概念,部分AST是指AST的一个子树,在AST中位于部分AST所有节点的左边节点都包含于该部分AST中. 给定部分AST,代码补全转化为预测部分AST位于最右侧节点的下一个节点. 利用前序深度优先遍历部分AST,生成非终节点和终节点的节点对,节点对的非终节点是终节点的父亲节点,节点对的向量是非终节点和终节点向量的加权和,通过LSTM来预测下一个出现的非终节点或终节点. 由于扁平化的AST失去了节点的父子关系表示,Li等[72 ] 提出增加父亲节点的向量表示,将上下文向量、父亲节点向量利用注意力机制融合后,输入LSTM模型中. 为了提取AST层次化的信息,Liu等[73 ] 提取从预测节点到根节点的路径序列,通过Bi-LSTM生成路径序列的向量表示. 将节点对的向量与路径序列向量连接,预测节点. ...
1
... 2)利用消息传递方法,提取AST的向量(2.1节的第4种思路). Yang等[24 ] 将AST转化为图,利用GRU进行消息传递,利用注意力机制聚合所有节点的向量,与对应的父亲节点向量连接后,利用该向量预测节点. Brockschmidt等[74 ] 采用序列到序列模型,在AST增加了继承节点和合成节点,反映上下文、已生成部分AST及子树的信息,编码器采用GRU进行消息传递,解码器采用属性文法驱动的AST产生策略生成节点和对应的边. Wang等[23 ] 通过序列化遍历,将AST的树结构转化为图结构,消除了重复标识节点. 利用注意力在图内节点和表示AST树结构的父子关系节点之间进行消息传递,利用注意力聚合所有的图内节点形成图的向量表示,将该向量映射到词袋的数值类型空间来预测节点. ...
1
... 1)从词袋中选择最恰当的名字,计算词袋中每一个词被分配给该函数的概率,选出概率最大的一个. code2vec[8 ] 、code2seq[9 ] 均采用该思路,利用注意力机制聚合函数所包含的AST路径向量,形成该函数的向量表示;计算该向量与词袋中每一个词的点积,利用softmax函数计算分配概率. Yonai等[75 ] 提出Mercem模型,提取函数调用图,利用二阶邻接性提取函数的向量表示,计算词袋中的函数的名字向量与该函数向量的余弦相似度,选取余弦相似度最接近的名字作为函数名. 这种思路的缺点在于只能选择在词袋中已有的名字,只有词袋中存在与该函数很接近的函数时才能得到恰当函数名,命名存在一定的局限性. ...
1
... 2)使用序列到序列模型直接生成token序列,将token序列拼接成函数名,这种思路生成的函数名不受已有函数名的限制. Allamanis等[76 ] 利用RNN生成当前输出序列的隐藏状态表示,通过卷积注意力神经网络在当前输出序列的状态向量下计算表示子词素在每个位置分布的注意力特征矩阵,获取子词素在某个位置的概率,选择概率最大的子词素作为输出. Meth2vec[77 ] 提取了PDG的路径、函数的中间表示(intermediate representation)和函数注释的向量表示,分别定义了位置编码,将向量表示与位置编码输入transformer模型编码器,解码器输出token序列,拼接后为预测函数名. Gao等[48 ] 利用文档中对函数的描述语句,生成函数名. 与传统的RNN不同,设计的解码器考虑了多个隐藏状态,通过注意力机制聚合多个隐藏状态,得到当前输出. ...
A hybrid code representation learning approach for predicting method names
1
2021
... 2)使用序列到序列模型直接生成token序列,将token序列拼接成函数名,这种思路生成的函数名不受已有函数名的限制. Allamanis等[76 ] 利用RNN生成当前输出序列的隐藏状态表示,通过卷积注意力神经网络在当前输出序列的状态向量下计算表示子词素在每个位置分布的注意力特征矩阵,获取子词素在某个位置的概率,选择概率最大的子词素作为输出. Meth2vec[77 ] 提取了PDG的路径、函数的中间表示(intermediate representation)和函数注释的向量表示,分别定义了位置编码,将向量表示与位置编码输入transformer模型编码器,解码器输出token序列,拼接后为预测函数名. Gao等[48 ] 利用文档中对函数的描述语句,生成函数名. 与传统的RNN不同,设计的解码器考虑了多个隐藏状态,通过注意力机制聚合多个隐藏状态,得到当前输出. ...
1
... 注释生成(comment generation)或代码总结(code summarization)是指为一段代码生成一句话用以总结代码的功能,可以帮助开发人员理解代码背后的语义,有利于提升代码的可读性和可维护性. 注释生成问题可以转化为文本序列生成问题,输入是源代码,输出是注释文本. 注释生成可以看作是神经机器翻译(neural machine translation,NMT)的一个应用. NMT采用编码器-解码器框架,编码器将源语言序列进行编码,提取源语言中的信息,通过解码器将该信息转换到另一种语言中,完成对语言的翻译. NMT将一段英文翻译成中文,生成注释可以看作是将源代码翻译为注释的过程. Hu等[18 ] 提出DeepCom模型,采用NMT框架,基于结构的遍历将AST扁平化(2.1节的思路3),编码器利用LSTM提取AST序列的上下文状态,通过注意力机制将每个时刻的上下文状态聚合,解码器利用上下文状态、隐藏状态和上一个时刻输出的token计算输出某一个token的概率,通过最小化交叉熵确定输出. Li等[42 ] 提出DeepCommenter模型,编码器利用GRU提取代码token序列和AST扁平化后的token序列的向量表示,利用注意力机制融合2组向量并送入解码器中,解码器根据上一个输出的token及融合后的向量,输出当前时刻的token. Iyer等[78 ] 提出CODE-NN模型,利用注意力机制建立代码token和输出之间的联系,将代码token和已输出的文本送入LSTM模型,选择最大概率出现的token作为当前输出. 为了捕获代码token的长距离依赖,Yang等[79 ] 提出MMTrans模型,在编码器的设计上,利用GCN学习到AST图结构的局部语义信息,利用自注意力机制学习到AST扁平化后token序列的全局语义信息. 在解码器的设计上,利用自注意力机制,将全局语义信息、局部语义信息和之前输出的注释token进行融合,计算注释token. ...
1
... 注释生成(comment generation)或代码总结(code summarization)是指为一段代码生成一句话用以总结代码的功能,可以帮助开发人员理解代码背后的语义,有利于提升代码的可读性和可维护性. 注释生成问题可以转化为文本序列生成问题,输入是源代码,输出是注释文本. 注释生成可以看作是神经机器翻译(neural machine translation,NMT)的一个应用. NMT采用编码器-解码器框架,编码器将源语言序列进行编码,提取源语言中的信息,通过解码器将该信息转换到另一种语言中,完成对语言的翻译. NMT将一段英文翻译成中文,生成注释可以看作是将源代码翻译为注释的过程. Hu等[18 ] 提出DeepCom模型,采用NMT框架,基于结构的遍历将AST扁平化(2.1节的思路3),编码器利用LSTM提取AST序列的上下文状态,通过注意力机制将每个时刻的上下文状态聚合,解码器利用上下文状态、隐藏状态和上一个时刻输出的token计算输出某一个token的概率,通过最小化交叉熵确定输出. Li等[42 ] 提出DeepCommenter模型,编码器利用GRU提取代码token序列和AST扁平化后的token序列的向量表示,利用注意力机制融合2组向量并送入解码器中,解码器根据上一个输出的token及融合后的向量,输出当前时刻的token. Iyer等[78 ] 提出CODE-NN模型,利用注意力机制建立代码token和输出之间的联系,将代码token和已输出的文本送入LSTM模型,选择最大概率出现的token作为当前输出. 为了捕获代码token的长距离依赖,Yang等[79 ] 提出MMTrans模型,在编码器的设计上,利用GCN学习到AST图结构的局部语义信息,利用自注意力机制学习到AST扁平化后token序列的全局语义信息. 在解码器的设计上,利用自注意力机制,将全局语义信息、局部语义信息和之前输出的注释token进行融合,计算注释token. ...
代码克隆检测研究进展
1
2019
... 代码克隆按照相似性可以分为4个档次,从Type-1(除缩进、注释外完全一致)到Type-4(功能一致但代码不同). 利用已有的方法可以准确地检测Type-1~Type-3的代码克隆,目前难点是检测Type-4的代码克隆. 代码克隆检测问题(code clone detection)[80 ] 可以转换为2个程序向量的相似性比较问题,主要包含以下2种研究思路. ...
代码克隆检测研究进展
1
2019
... 代码克隆按照相似性可以分为4个档次,从Type-1(除缩进、注释外完全一致)到Type-4(功能一致但代码不同). 利用已有的方法可以准确地检测Type-1~Type-3的代码克隆,目前难点是检测Type-4的代码克隆. 代码克隆检测问题(code clone detection)[80 ] 可以转换为2个程序向量的相似性比较问题,主要包含以下2种研究思路. ...
Exploration of convolutional neural network models for source code classification
1
2021
... 近些年来,异构多核系统的应用越来越广泛. CPU、GPU、DSP等处理器擅长的任务通常不同,如何将程序分配给更合适的设备以获得更好的执行性能是异构设备映射(heterogeneous device mapping)要解决的问题. 异构设备映射的输入是源代码,输出是该源代码在何种处理器上计算性能高. 异构设备映射可以转化为分类问题,即预测测试集标签,标签指示了实验中程序运行在何种处理器上计算性能更高. 一类研究基于token序列进行异构设备映射. Barchi等[81 ] 将程序的LLVM中间表示进行分词化,使用CNN模型对token序列进行卷积操作和分类. 针对小数据集的训练,Parisi等[82 ] 在后续的工作中引入对比学习,将CNN模型的输出送入孪生网络,定义对比损失函数. 另一类研究基于图结构进行预测. PGL针对复杂程序的应用场景,将程序分为程序段,为每一个程序段分别预测执行设备. 以实际执行的指令构造动态数据流图,利用图自编码器(graph auto-encoder)提取节点的向量,根据节点之间的距离将图分割为子图,在每个子图上进行消息传递和子图向量的提取,预测映射的设备[83 ] . Brauckmann等[84 ] 提取AST和CDFG,分别在各图上利用GRU模型进行消息传递,通过注意力机制融合节点向量形成图向量,利用多层感知机融合图向量与附加信息(如数据规模)形成最终向量来预测设备. ...
Making the most of scarce input data in deep learning-based source code classification for heterogeneous device mapping
1
2021
... 近些年来,异构多核系统的应用越来越广泛. CPU、GPU、DSP等处理器擅长的任务通常不同,如何将程序分配给更合适的设备以获得更好的执行性能是异构设备映射(heterogeneous device mapping)要解决的问题. 异构设备映射的输入是源代码,输出是该源代码在何种处理器上计算性能高. 异构设备映射可以转化为分类问题,即预测测试集标签,标签指示了实验中程序运行在何种处理器上计算性能更高. 一类研究基于token序列进行异构设备映射. Barchi等[81 ] 将程序的LLVM中间表示进行分词化,使用CNN模型对token序列进行卷积操作和分类. 针对小数据集的训练,Parisi等[82 ] 在后续的工作中引入对比学习,将CNN模型的输出送入孪生网络,定义对比损失函数. 另一类研究基于图结构进行预测. PGL针对复杂程序的应用场景,将程序分为程序段,为每一个程序段分别预测执行设备. 以实际执行的指令构造动态数据流图,利用图自编码器(graph auto-encoder)提取节点的向量,根据节点之间的距离将图分割为子图,在每个子图上进行消息传递和子图向量的提取,预测映射的设备[83 ] . Brauckmann等[84 ] 提取AST和CDFG,分别在各图上利用GRU模型进行消息传递,通过注意力机制融合节点向量形成图向量,利用多层感知机融合图向量与附加信息(如数据规模)形成最终向量来预测设备. ...
1
... 近些年来,异构多核系统的应用越来越广泛. CPU、GPU、DSP等处理器擅长的任务通常不同,如何将程序分配给更合适的设备以获得更好的执行性能是异构设备映射(heterogeneous device mapping)要解决的问题. 异构设备映射的输入是源代码,输出是该源代码在何种处理器上计算性能高. 异构设备映射可以转化为分类问题,即预测测试集标签,标签指示了实验中程序运行在何种处理器上计算性能更高. 一类研究基于token序列进行异构设备映射. Barchi等[81 ] 将程序的LLVM中间表示进行分词化,使用CNN模型对token序列进行卷积操作和分类. 针对小数据集的训练,Parisi等[82 ] 在后续的工作中引入对比学习,将CNN模型的输出送入孪生网络,定义对比损失函数. 另一类研究基于图结构进行预测. PGL针对复杂程序的应用场景,将程序分为程序段,为每一个程序段分别预测执行设备. 以实际执行的指令构造动态数据流图,利用图自编码器(graph auto-encoder)提取节点的向量,根据节点之间的距离将图分割为子图,在每个子图上进行消息传递和子图向量的提取,预测映射的设备[83 ] . Brauckmann等[84 ] 提取AST和CDFG,分别在各图上利用GRU模型进行消息传递,通过注意力机制融合节点向量形成图向量,利用多层感知机融合图向量与附加信息(如数据规模)形成最终向量来预测设备. ...
1
... 近些年来,异构多核系统的应用越来越广泛. CPU、GPU、DSP等处理器擅长的任务通常不同,如何将程序分配给更合适的设备以获得更好的执行性能是异构设备映射(heterogeneous device mapping)要解决的问题. 异构设备映射的输入是源代码,输出是该源代码在何种处理器上计算性能高. 异构设备映射可以转化为分类问题,即预测测试集标签,标签指示了实验中程序运行在何种处理器上计算性能更高. 一类研究基于token序列进行异构设备映射. Barchi等[81 ] 将程序的LLVM中间表示进行分词化,使用CNN模型对token序列进行卷积操作和分类. 针对小数据集的训练,Parisi等[82 ] 在后续的工作中引入对比学习,将CNN模型的输出送入孪生网络,定义对比损失函数. 另一类研究基于图结构进行预测. PGL针对复杂程序的应用场景,将程序分为程序段,为每一个程序段分别预测执行设备. 以实际执行的指令构造动态数据流图,利用图自编码器(graph auto-encoder)提取节点的向量,根据节点之间的距离将图分割为子图,在每个子图上进行消息传递和子图向量的提取,预测映射的设备[83 ] . Brauckmann等[84 ] 提取AST和CDFG,分别在各图上利用GRU模型进行消息传递,通过注意力机制融合节点向量形成图向量,利用多层感知机融合图向量与附加信息(如数据规模)形成最终向量来预测设备. ...
1
... 程序可能由于外界扰动,导致不能正常工作. 程序本身具备一定屏蔽或检测错误的能力,可靠性评估(reliability assessment)的目标是量化程序的容错能力. 可靠性评估的输入是源代码,输出是指令级或系统级的可靠性指标. 可靠性评估问题可以转化为节点分类问题或整图分类问题. 这一问题的研究思路是利用消息传递神经网络对程序内部的错误传播进行建模,通过消息传递量化邻居节点的影响,提取语义向量来反映程序的容错能力. Jiao等[85 ] 提出基于图神经网络的GLAIVE模型,构造二进制位级CDFG,使用GraphSage[86 ] 进行消息传递和节点更新,对指令可靠性进行预测. GLAIVE模型只有一种边类型,不能反映指令间不同类型的交互. Ma等[87 ] 提出异构注意力网络,表示指令间的读写关系、寻址关系、逻辑关系和分支关系,通过注意力机制量化邻居节点的差异化影响,捕获与错误传播相关的隐性结构特征. Wang等[88 ] 利用RNN模型从故障时间序列数据中学习,预测下一时刻软件的故障数. Niu等[89 ] 基于静态污点分析生成污点传播路径,利用word2vec模型将污点传播路径转化为符号向量表示,通过CNN进行卷积和最大池化,利用Bi-LSTM进行序列处理,以判断软件是否脆弱. ...
1
... 程序可能由于外界扰动,导致不能正常工作. 程序本身具备一定屏蔽或检测错误的能力,可靠性评估(reliability assessment)的目标是量化程序的容错能力. 可靠性评估的输入是源代码,输出是指令级或系统级的可靠性指标. 可靠性评估问题可以转化为节点分类问题或整图分类问题. 这一问题的研究思路是利用消息传递神经网络对程序内部的错误传播进行建模,通过消息传递量化邻居节点的影响,提取语义向量来反映程序的容错能力. Jiao等[85 ] 提出基于图神经网络的GLAIVE模型,构造二进制位级CDFG,使用GraphSage[86 ] 进行消息传递和节点更新,对指令可靠性进行预测. GLAIVE模型只有一种边类型,不能反映指令间不同类型的交互. Ma等[87 ] 提出异构注意力网络,表示指令间的读写关系、寻址关系、逻辑关系和分支关系,通过注意力机制量化邻居节点的差异化影响,捕获与错误传播相关的隐性结构特征. Wang等[88 ] 利用RNN模型从故障时间序列数据中学习,预测下一时刻软件的故障数. Niu等[89 ] 基于静态污点分析生成污点传播路径,利用word2vec模型将污点传播路径转化为符号向量表示,通过CNN进行卷积和最大池化,利用Bi-LSTM进行序列处理,以判断软件是否脆弱. ...
1
... 程序可能由于外界扰动,导致不能正常工作. 程序本身具备一定屏蔽或检测错误的能力,可靠性评估(reliability assessment)的目标是量化程序的容错能力. 可靠性评估的输入是源代码,输出是指令级或系统级的可靠性指标. 可靠性评估问题可以转化为节点分类问题或整图分类问题. 这一问题的研究思路是利用消息传递神经网络对程序内部的错误传播进行建模,通过消息传递量化邻居节点的影响,提取语义向量来反映程序的容错能力. Jiao等[85 ] 提出基于图神经网络的GLAIVE模型,构造二进制位级CDFG,使用GraphSage[86 ] 进行消息传递和节点更新,对指令可靠性进行预测. GLAIVE模型只有一种边类型,不能反映指令间不同类型的交互. Ma等[87 ] 提出异构注意力网络,表示指令间的读写关系、寻址关系、逻辑关系和分支关系,通过注意力机制量化邻居节点的差异化影响,捕获与错误传播相关的隐性结构特征. Wang等[88 ] 利用RNN模型从故障时间序列数据中学习,预测下一时刻软件的故障数. Niu等[89 ] 基于静态污点分析生成污点传播路径,利用word2vec模型将污点传播路径转化为符号向量表示,通过CNN进行卷积和最大池化,利用Bi-LSTM进行序列处理,以判断软件是否脆弱. ...
1
... 程序可能由于外界扰动,导致不能正常工作. 程序本身具备一定屏蔽或检测错误的能力,可靠性评估(reliability assessment)的目标是量化程序的容错能力. 可靠性评估的输入是源代码,输出是指令级或系统级的可靠性指标. 可靠性评估问题可以转化为节点分类问题或整图分类问题. 这一问题的研究思路是利用消息传递神经网络对程序内部的错误传播进行建模,通过消息传递量化邻居节点的影响,提取语义向量来反映程序的容错能力. Jiao等[85 ] 提出基于图神经网络的GLAIVE模型,构造二进制位级CDFG,使用GraphSage[86 ] 进行消息传递和节点更新,对指令可靠性进行预测. GLAIVE模型只有一种边类型,不能反映指令间不同类型的交互. Ma等[87 ] 提出异构注意力网络,表示指令间的读写关系、寻址关系、逻辑关系和分支关系,通过注意力机制量化邻居节点的差异化影响,捕获与错误传播相关的隐性结构特征. Wang等[88 ] 利用RNN模型从故障时间序列数据中学习,预测下一时刻软件的故障数. Niu等[89 ] 基于静态污点分析生成污点传播路径,利用word2vec模型将污点传播路径转化为符号向量表示,通过CNN进行卷积和最大池化,利用Bi-LSTM进行序列处理,以判断软件是否脆弱. ...
A deep learning based static taint analysis approach for IoT software vulnerability location
1
2020
... 程序可能由于外界扰动,导致不能正常工作. 程序本身具备一定屏蔽或检测错误的能力,可靠性评估(reliability assessment)的目标是量化程序的容错能力. 可靠性评估的输入是源代码,输出是指令级或系统级的可靠性指标. 可靠性评估问题可以转化为节点分类问题或整图分类问题. 这一问题的研究思路是利用消息传递神经网络对程序内部的错误传播进行建模,通过消息传递量化邻居节点的影响,提取语义向量来反映程序的容错能力. Jiao等[85 ] 提出基于图神经网络的GLAIVE模型,构造二进制位级CDFG,使用GraphSage[86 ] 进行消息传递和节点更新,对指令可靠性进行预测. GLAIVE模型只有一种边类型,不能反映指令间不同类型的交互. Ma等[87 ] 提出异构注意力网络,表示指令间的读写关系、寻址关系、逻辑关系和分支关系,通过注意力机制量化邻居节点的差异化影响,捕获与错误传播相关的隐性结构特征. Wang等[88 ] 利用RNN模型从故障时间序列数据中学习,预测下一时刻软件的故障数. Niu等[89 ] 基于静态污点分析生成污点传播路径,利用word2vec模型将污点传播路径转化为符号向量表示,通过CNN进行卷积和最大池化,利用Bi-LSTM进行序列处理,以判断软件是否脆弱. ...
1
... 二进制代码是指在编译后产生的可执行机器码. 与源代码相比,二进制代码丢失了大量的语法信息,不能构建代码token序列和AST,所以面向二进制代码的模型与面向源代码的模型有较大的区别. 二进制代码的相关应用主要包括剽窃检测、恶意代码检测、二进制溯源分析等. 这些相关应用均可以转化为二进制代码相似性比较问题(binary code similarity detection),即在代码库中寻找与给定二进制代码语义相等或相似的二进制代码. 这一类研究工作的基本思路是提取二进制代码的CFG的向量表示,再进行向量的相似性计算. Xu等[90 ] 利用Structure2Vec[91 ] 提取ACFG(attributed control flow graph)的向量表示,通过孪生网络最小化两图的余弦相似度与标签的差距. Yu等[92 ] 利用CNN的平移不变性来提取基本块的调用顺序信息,通过多层感知机进行消息传递提取CFG的结构信息,结合结构信息与调用顺序信息,得到二进制代码的向量表示. Asm2vec模型[93 ] 在CFG中提取指令序列,将函数看作一个文件,将指令操作数和操作码看作文件中的单词,利用PV-DM模型[94 ] 求取函数的向量表示. ...
1
... 二进制代码是指在编译后产生的可执行机器码. 与源代码相比,二进制代码丢失了大量的语法信息,不能构建代码token序列和AST,所以面向二进制代码的模型与面向源代码的模型有较大的区别. 二进制代码的相关应用主要包括剽窃检测、恶意代码检测、二进制溯源分析等. 这些相关应用均可以转化为二进制代码相似性比较问题(binary code similarity detection),即在代码库中寻找与给定二进制代码语义相等或相似的二进制代码. 这一类研究工作的基本思路是提取二进制代码的CFG的向量表示,再进行向量的相似性计算. Xu等[90 ] 利用Structure2Vec[91 ] 提取ACFG(attributed control flow graph)的向量表示,通过孪生网络最小化两图的余弦相似度与标签的差距. Yu等[92 ] 利用CNN的平移不变性来提取基本块的调用顺序信息,通过多层感知机进行消息传递提取CFG的结构信息,结合结构信息与调用顺序信息,得到二进制代码的向量表示. Asm2vec模型[93 ] 在CFG中提取指令序列,将函数看作一个文件,将指令操作数和操作码看作文件中的单词,利用PV-DM模型[94 ] 求取函数的向量表示. ...
1
... 二进制代码是指在编译后产生的可执行机器码. 与源代码相比,二进制代码丢失了大量的语法信息,不能构建代码token序列和AST,所以面向二进制代码的模型与面向源代码的模型有较大的区别. 二进制代码的相关应用主要包括剽窃检测、恶意代码检测、二进制溯源分析等. 这些相关应用均可以转化为二进制代码相似性比较问题(binary code similarity detection),即在代码库中寻找与给定二进制代码语义相等或相似的二进制代码. 这一类研究工作的基本思路是提取二进制代码的CFG的向量表示,再进行向量的相似性计算. Xu等[90 ] 利用Structure2Vec[91 ] 提取ACFG(attributed control flow graph)的向量表示,通过孪生网络最小化两图的余弦相似度与标签的差距. Yu等[92 ] 利用CNN的平移不变性来提取基本块的调用顺序信息,通过多层感知机进行消息传递提取CFG的结构信息,结合结构信息与调用顺序信息,得到二进制代码的向量表示. Asm2vec模型[93 ] 在CFG中提取指令序列,将函数看作一个文件,将指令操作数和操作码看作文件中的单词,利用PV-DM模型[94 ] 求取函数的向量表示. ...
1
... 二进制代码是指在编译后产生的可执行机器码. 与源代码相比,二进制代码丢失了大量的语法信息,不能构建代码token序列和AST,所以面向二进制代码的模型与面向源代码的模型有较大的区别. 二进制代码的相关应用主要包括剽窃检测、恶意代码检测、二进制溯源分析等. 这些相关应用均可以转化为二进制代码相似性比较问题(binary code similarity detection),即在代码库中寻找与给定二进制代码语义相等或相似的二进制代码. 这一类研究工作的基本思路是提取二进制代码的CFG的向量表示,再进行向量的相似性计算. Xu等[90 ] 利用Structure2Vec[91 ] 提取ACFG(attributed control flow graph)的向量表示,通过孪生网络最小化两图的余弦相似度与标签的差距. Yu等[92 ] 利用CNN的平移不变性来提取基本块的调用顺序信息,通过多层感知机进行消息传递提取CFG的结构信息,结合结构信息与调用顺序信息,得到二进制代码的向量表示. Asm2vec模型[93 ] 在CFG中提取指令序列,将函数看作一个文件,将指令操作数和操作码看作文件中的单词,利用PV-DM模型[94 ] 求取函数的向量表示. ...
1
... 二进制代码是指在编译后产生的可执行机器码. 与源代码相比,二进制代码丢失了大量的语法信息,不能构建代码token序列和AST,所以面向二进制代码的模型与面向源代码的模型有较大的区别. 二进制代码的相关应用主要包括剽窃检测、恶意代码检测、二进制溯源分析等. 这些相关应用均可以转化为二进制代码相似性比较问题(binary code similarity detection),即在代码库中寻找与给定二进制代码语义相等或相似的二进制代码. 这一类研究工作的基本思路是提取二进制代码的CFG的向量表示,再进行向量的相似性计算. Xu等[90 ] 利用Structure2Vec[91 ] 提取ACFG(attributed control flow graph)的向量表示,通过孪生网络最小化两图的余弦相似度与标签的差距. Yu等[92 ] 利用CNN的平移不变性来提取基本块的调用顺序信息,通过多层感知机进行消息传递提取CFG的结构信息,结合结构信息与调用顺序信息,得到二进制代码的向量表示. Asm2vec模型[93 ] 在CFG中提取指令序列,将函数看作一个文件,将指令操作数和操作码看作文件中的单词,利用PV-DM模型[94 ] 求取函数的向量表示. ...
Codee: a tensor embedding scheme for binary code search
2
2021
... Yang等[95 -96 ] 采用层次化结构表示二进制代码,按照自底向上的顺序生成向量表示. Yang等[95 ] 提出Codee模型,采用从指令到基本块再到函数依次求取向量表示的思路. 利用skip-gram求得指令操作码和操作数的向量表示并进行连接操作,形成指令的向量表示,利用line算法[97 ] 聚合指令向量表示求得基本块的向量表示,采用张量奇异值分解算法生成函数的向量表示,利用局部敏感哈希算法找到top-k相似的函数. Deepbindiff[96 ] 采用从操作码到指令再到基本块的向量求取顺序,利用word2vec生成操作码的向量表示,聚合指令向量形成基本块的向量表示,通过TADW算法[98 ] 计算基本块的向量及相似性. ...
... [95 ]提出Codee模型,采用从指令到基本块再到函数依次求取向量表示的思路. 利用skip-gram求得指令操作码和操作数的向量表示并进行连接操作,形成指令的向量表示,利用line算法[97 ] 聚合指令向量表示求得基本块的向量表示,采用张量奇异值分解算法生成函数的向量表示,利用局部敏感哈希算法找到top-k相似的函数. Deepbindiff[96 ] 采用从操作码到指令再到基本块的向量求取顺序,利用word2vec生成操作码的向量表示,聚合指令向量形成基本块的向量表示,通过TADW算法[98 ] 计算基本块的向量及相似性. ...
2
... Yang等[95 -96 ] 采用层次化结构表示二进制代码,按照自底向上的顺序生成向量表示. Yang等[95 ] 提出Codee模型,采用从指令到基本块再到函数依次求取向量表示的思路. 利用skip-gram求得指令操作码和操作数的向量表示并进行连接操作,形成指令的向量表示,利用line算法[97 ] 聚合指令向量表示求得基本块的向量表示,采用张量奇异值分解算法生成函数的向量表示,利用局部敏感哈希算法找到top-k相似的函数. Deepbindiff[96 ] 采用从操作码到指令再到基本块的向量求取顺序,利用word2vec生成操作码的向量表示,聚合指令向量形成基本块的向量表示,通过TADW算法[98 ] 计算基本块的向量及相似性. ...
... [96 ]采用从操作码到指令再到基本块的向量求取顺序,利用word2vec生成操作码的向量表示,聚合指令向量形成基本块的向量表示,通过TADW算法[98 ] 计算基本块的向量及相似性. ...
1
... Yang等[95 -96 ] 采用层次化结构表示二进制代码,按照自底向上的顺序生成向量表示. Yang等[95 ] 提出Codee模型,采用从指令到基本块再到函数依次求取向量表示的思路. 利用skip-gram求得指令操作码和操作数的向量表示并进行连接操作,形成指令的向量表示,利用line算法[97 ] 聚合指令向量表示求得基本块的向量表示,采用张量奇异值分解算法生成函数的向量表示,利用局部敏感哈希算法找到top-k相似的函数. Deepbindiff[96 ] 采用从操作码到指令再到基本块的向量求取顺序,利用word2vec生成操作码的向量表示,聚合指令向量形成基本块的向量表示,通过TADW算法[98 ] 计算基本块的向量及相似性. ...
1
... Yang等[95 -96 ] 采用层次化结构表示二进制代码,按照自底向上的顺序生成向量表示. Yang等[95 ] 提出Codee模型,采用从指令到基本块再到函数依次求取向量表示的思路. 利用skip-gram求得指令操作码和操作数的向量表示并进行连接操作,形成指令的向量表示,利用line算法[97 ] 聚合指令向量表示求得基本块的向量表示,采用张量奇异值分解算法生成函数的向量表示,利用局部敏感哈希算法找到top-k相似的函数. Deepbindiff[96 ] 采用从操作码到指令再到基本块的向量求取顺序,利用word2vec生成操作码的向量表示,聚合指令向量形成基本块的向量表示,通过TADW算法[98 ] 计算基本块的向量及相似性. ...
1
... 常用的程序表示学习集成工具集包括ComPy-Learn[99 ] 、CompilerGym[100 ] 等. ComPy-Learn工具集实现了从图构建、语义嵌入提取到读出的全流程,能够提取AST,集成了多种RNN、GNN表示学习模型,读出层可以完成图级别或序列级别的分类和回归任务. CompilerGym提供编译器优化工具集,可以定制化编译器的优化策略,分析优化任务的性能. ...
1
... 常用的程序表示学习集成工具集包括ComPy-Learn[99 ] 、CompilerGym[100 ] 等. ComPy-Learn工具集实现了从图构建、语义嵌入提取到读出的全流程,能够提取AST,集成了多种RNN、GNN表示学习模型,读出层可以完成图级别或序列级别的分类和回归任务. CompilerGym提供编译器优化工具集,可以定制化编译器的优化策略,分析优化任务的性能. ...
1
... Benchmarks for program representation learning
Tab.5 应用名称 测试集 缺陷检测 SARD,Defects4J,POJ-104[101 ] 缺陷定位 文献[102 ]的测试集 缺陷修复 DeepFix,ManySStuBs4J 命名推荐 CodeSearchNet 代码补全 WikiSQL,CodeXGLUE,CoNaLa 注释生成 CodeSearchNet,PyTorrent,DeepCom 代码克隆检测 POJ-104,BigCloneBench 异构设备映射 文献[103 ]的测试集
4.3. 原型产品 目前知名度较高的原型产品为Copilot、IntelliCode、Cosy等,IntelliCode和Cosy提供了代码补全功能,这与原有的集成开发环境配备的代码补全有很大区别. 原有的集成开发环境提示的只是token(如类名、变量名),IntelliCode和Cosy基于序列到序列模型可以提示长序列的代码片段,提高了代码效率. Copilot能够根据描述函数功能的函数名或注释自动生成函数代码,适合生成通用工具代码. 这些原型产品均可从网站下载,在常见的集成开发环境中配置与使用,提高了软件开发的效率. 基于程序表示学习的原型产品目前正处于快速迭代阶段. ...
1
... Benchmarks for program representation learning
Tab.5 应用名称 测试集 缺陷检测 SARD,Defects4J,POJ-104[101 ] 缺陷定位 文献[102 ]的测试集 缺陷修复 DeepFix,ManySStuBs4J 命名推荐 CodeSearchNet 代码补全 WikiSQL,CodeXGLUE,CoNaLa 注释生成 CodeSearchNet,PyTorrent,DeepCom 代码克隆检测 POJ-104,BigCloneBench 异构设备映射 文献[103 ]的测试集
4.3. 原型产品 目前知名度较高的原型产品为Copilot、IntelliCode、Cosy等,IntelliCode和Cosy提供了代码补全功能,这与原有的集成开发环境配备的代码补全有很大区别. 原有的集成开发环境提示的只是token(如类名、变量名),IntelliCode和Cosy基于序列到序列模型可以提示长序列的代码片段,提高了代码效率. Copilot能够根据描述函数功能的函数名或注释自动生成函数代码,适合生成通用工具代码. 这些原型产品均可从网站下载,在常见的集成开发环境中配置与使用,提高了软件开发的效率. 基于程序表示学习的原型产品目前正处于快速迭代阶段. ...
1
... Benchmarks for program representation learning
Tab.5 应用名称 测试集 缺陷检测 SARD,Defects4J,POJ-104[101 ] 缺陷定位 文献[102 ]的测试集 缺陷修复 DeepFix,ManySStuBs4J 命名推荐 CodeSearchNet 代码补全 WikiSQL,CodeXGLUE,CoNaLa 注释生成 CodeSearchNet,PyTorrent,DeepCom 代码克隆检测 POJ-104,BigCloneBench 异构设备映射 文献[103 ]的测试集
4.3. 原型产品 目前知名度较高的原型产品为Copilot、IntelliCode、Cosy等,IntelliCode和Cosy提供了代码补全功能,这与原有的集成开发环境配备的代码补全有很大区别. 原有的集成开发环境提示的只是token(如类名、变量名),IntelliCode和Cosy基于序列到序列模型可以提示长序列的代码片段,提高了代码效率. Copilot能够根据描述函数功能的函数名或注释自动生成函数代码,适合生成通用工具代码. 这些原型产品均可从网站下载,在常见的集成开发环境中配置与使用,提高了软件开发的效率. 基于程序表示学习的原型产品目前正处于快速迭代阶段. ...
1
... 1)模型的泛化性能较差. 一些模型虽然在实验中性能表现较好,但在训练集外的数据上表现欠佳;一些文献虽然声称提出的模型是通用模型,但在别的应用上效果不佳. Kang等[104 ] 指出code2Vec模型不能迁移到别的预测任务上,在代码注释生成任务上,code2Vec的总体性能指标不如其他简单模型. 未来可以引入生成对抗网络、深度迁移学习技术,强化模型的泛化能力. ...
Ir2vec: LLVM ir based scalable program embeddings
1
2020
... 2)模型的可解释性较差. 现有的程序表示学习模型一般基于深度神经网络,虽然模型取得了很好的训练效果,但是很难直接找到模型取得该结果的原因. 虽然一些模型中设计了表征模块之间的影响(如注意力机制中的注意力系数)的参数,但是缺乏对影响机制的挖掘与归因. 针对应用需求,选用何种模型及模型的参数如何设置没有普适的方法. 目前已有一些基于知识推理的工作,如基于TransE的ir2vec模型[105 ] ,运用知识图谱、认知图谱进行推理和成因分析可能是未来的发展方向之一. ...
1
... 3)模型对数据的要求较高. 由于采用了深度网络,模型一般需要大量的训练集数据,使得模型参数在训练中能够收敛. 对于分类任务,模型需要带标签的数据作为输入. 现实中,一些任务很难提供带标签数据或者大规模的训练集. 这方面可以借鉴强化学习、半监督学习、对比学习、主动学习等方式,提高数据效益. Haj-Ali等[106 ] 提出结合强化学习模型与深度学习模型,使用code2vec生成代码的嵌入,输入到深度强化学习模型中,捕获不同指令的依赖关系和数据结构. 未来可以利用模型无关的强化学习技术,捕获系统或程序的交互信息,计算回报函数的期望,通过迭代状态值函数完成模型训练,减轻模型对大量标签数据的依赖. ...


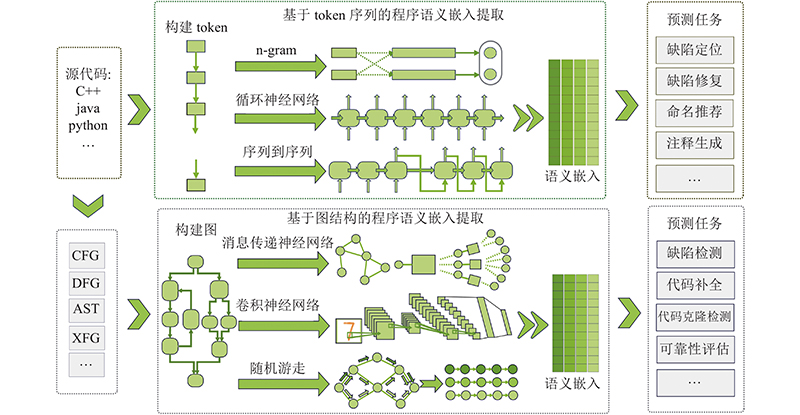

{kind=link}
{kind=link}