[1]
LI L, CHU W, LANGFORD J, et al. A contextual-bandit approach to personalized news article recommendation [C]// Proceedings of the 19th International Conference on World Wide Web . Raleigh: ACM, 2010: 661-670.
[本文引用: 1]
[2]
KOREN Y, BELL R, VOLINSKY C Matrix factorization techniques for recommender systems
[J]. Computer , 2009 , 42 (8 ): 30 - 37
DOI:10.1109/MC.2009.263
[本文引用: 1]
[3]
SUN Z, GUO Q, YANG J, et al Research commentary on recommendations with side information: a survey and research directions
[J]. Electronic Commerce Research and Applications , 2019 , 37 (1 ): 1 - 30
[本文引用: 1]
[4]
WANG H, ZHANG F, XIE X, et al. DKN: deep knowledge-aware network for news recommendation [C]// Proceedings of the 2018 World Wide Web Conference . Lyon: ACM, 2018: 1835-1844.
[本文引用: 6]
[5]
WANG H, ZHANG F, ZHAO M, et al. Multi-task feature learning for knowledge graph enhanced recommendation [C]// Proceedings of the 2019 World Wide Web Conference . San Francisco: ACM, 2019: 2000-2010.
[本文引用: 3]
[6]
XIAN Y, FU Z, MUTHUKRISHNAN S, et al. Reinforcement knowledge graph reasoning for explainable recommendation [C]// Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval . Paris: ACM, 2019: 285-294.
[本文引用: 2]
[8]
WANG H, ZHAO M, XIE X, et al. Knowledge graph convolutional networks for recommender systems [C]// Proceedings of the 2019 World Wide Web Conference . San Francisco: ACM, 2019: 3307-3313.
[本文引用: 4]
[9]
WANG H, ZHANG F, WANG J, et al. Ripplenet: propagating user preferences on the knowledge graph for recommender systems [C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management . Torino: ACM, 2018: 417-426.
[本文引用: 4]
[10]
刘羽茜, 刘玉奇, 张宗霖, 等 注入注意力机制的深度特征融合新闻推荐模型
[J]. 计算机应用 , 2022 , 42 (2 ): 426 - 432
[本文引用: 2]
LIU Yu-xi, LIU Yu-qi, ZHANG Zong-lin, et al News recommendation model with deep feature fusion injecting attention mechanism
[J]. Computer Applications , 2022 , 42 (2 ): 426 - 432
[本文引用: 2]
[11]
CHEN Q, ZHAO H, LI W, et al. Behavior sequence transformer for e-commerce recommendation in Alibaba [C]// Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data . Anchorage: ACM, 2019: 1-4.
[本文引用: 1]
[12]
TANG J, WANG K. Personalized top-n sequential recommendation via convolutional sequence embedding [C]// Proceedings of the 11th ACM International Conference on Web Search and Data Mining . Marina Del Rey: ACM, 2018: 565-573.
[本文引用: 1]
[13]
冯永, 张备, 强保华, 等 MN-HDRM: 长短兴趣多神经网络混合动态推荐模型
[J]. 计算机学报 , 2019 , 42 (1 ): 16 - 28
[本文引用: 2]
FENG Yong, ZHANG Bei, QIANG Bao-hua, et al MN-HDRM: a novel hybrid dynamic recommendation model based on long-short-term interests multiple neural networks
[J]. Journal of Computer Science , 2019 , 42 (1 ): 16 - 28
[本文引用: 2]
[14]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Long Beach: MIT Press, 2017: 6000-6010.
[本文引用: 2]
[15]
BANSAL T, DAS M, BHATTACHARYYA C. Content driven user profiling for comment-worthy recommendations of news and blog articles [C]// Proceedings of the 9th ACM Conference on Recommender Systems . Vienna: ACM, 2015: 195-202.
[本文引用: 1]
[16]
KUMAR V, KHATTAR D, GUPTA S, et al. Deep neural architecture for news recommendation [C]// Proceedings of the 2017 Conference and Labs of the Evaluation Forum . Dublin: [s. n. ], 2017: 1-19.
[本文引用: 1]
[17]
ZHANG Q, LI J, JIA Q, et al. UNBERT: user-news matching BERT for news recommendation [C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence . Montreal: Morgan Kaufmann, 2021: 3356-3362.
[本文引用: 1]
[18]
WU C, WU F, QI T, et al. Feedrec: news feed recommendation with various user feedbacks [C]// Proceedings of the ACM Web Conference . Lyon: ACM, 2022: 2088-2097.
[本文引用: 1]
[19]
QI T, WU F, WU C, et al. Personalized news recommendation with knowledge-aware interactive matching [C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval . Canada: ACM, 2021: 61-70.
[本文引用: 1]
[20]
LIU D, LIAN J, LIU Z, et al. Reinforced anchor knowledge graph generation for news recommendation reasoning [C]// Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . Singapore: ACM, 2021: 1055-1065.
[本文引用: 1]
[21]
VRANDECIC D, KROTZSCH M Wikidata: a free collaborative knowledgebase
[J]. Communications of the ACM , 2014 , 57 (10 ): 78 - 85
DOI:10.1145/2629489
[本文引用: 1]
[22]
XU B, XU Y, LIANG J, et al. CN-DBpedia: a never-ending Chinese knowledge extraction system [C]// Proceedings of the 30th International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems . Arras: Springer, 2017: 428-438.
[本文引用: 1]
[23]
SUCHANEK F M, KASNECI G, WEIKUM G. Yago: a core of semantic knowledge [C]// Proceedings of the 16th International Conference on World Wide Web . Banff: ACM, 2007: 697-706.
[本文引用: 1]
[24]
WU C, WU F, GE S, et al. Neural news recommendation with multi-head self-attention [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: ACL, 2019: 6389-6394.
[本文引用: 3]
[25]
WU F, QIAO Y, CHEN J H, et al. Mind: a large-scale dataset for news recommendation [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . Stroudsburg: ACL, 2020: 3597-3606.
[本文引用: 1]
[26]
MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [C]// Proceedings of the 1st International Conference on Learning Representations . Scottsdale: [s. n. ], 2013: 1-12.
[本文引用: 2]
[27]
HU L, XU S, LI C, et al. Graph neural news recommendation with unsupervised preference disentanglement [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . Stroudsburg: ACL, 2020: 4255-4264.
[本文引用: 2]
[28]
BORDES A, USUNIER N, GARCIA-DURAN A, et al. Translating embeddings for modeling multi-relational data [C]// Proceedings of the 26th Advances in Neural Information Processing Systems . Lake Tahoe: MIT Press, 2013: 2787-2795.
[本文引用: 1]
1
... 随着互联网的不断发展,用户阅读新闻的来源逐渐从传统的电视或者报纸转为互联网,导致线上新闻阅读量增加. 网上新闻平台从多个信息源获取新闻,在带来海量数据的同时,带来了信息过载的问题. 提高新闻推荐的准确性,改善用户的个性化体验在当前新闻阅读中变得日益重要[1 ] . ...
Matrix factorization techniques for recommender systems
1
2009
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
Research commentary on recommendations with side information: a survey and research directions
1
2019
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
6
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
... [4 ]采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
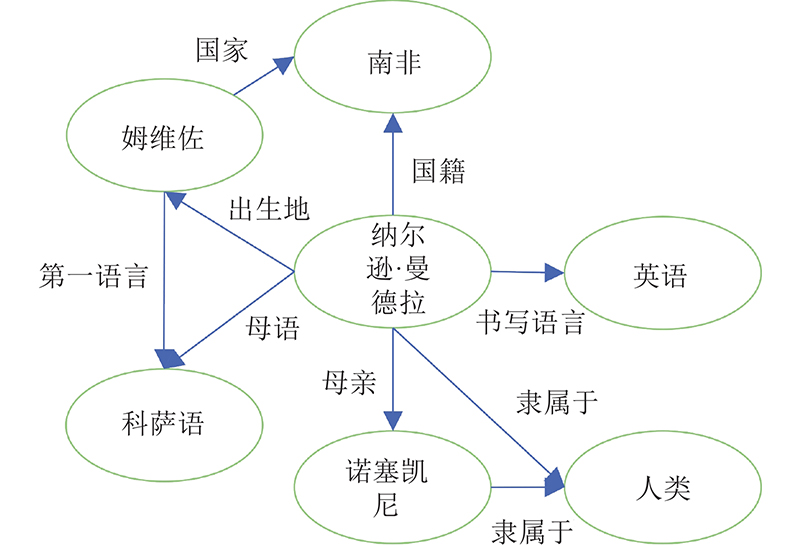
... 知识图谱[4 ] 是表示多领域的大规模实体之间关系的语义网络. 在知识图谱中,每2个实体间以关系连接,表示为三元组 $ (h,r,t) $ $h$ $r$ $ t $ 图1 所示为某知识图谱示例图,其中纳尔逊·曼德拉为新闻中包含的实体,姆维佐是邻接实体. 典型知识图谱包括Wikidata[21 ] 、CN-DBPedia[22 ] 和YAGO[23 ] 等. Wikidata是维基媒体提出的多语言辅助知识库,主要以文档形式存储,支持免费使用. CN-DBPedia是最大的中文知识图谱数据库,由复旦大学提出,能自动从百度百科、沪东百科和维基百科中提取知识. YAGO是开源知识库,从Wikipedia和WordNet提取知识,包含超千万的实体及上亿的知识. ...
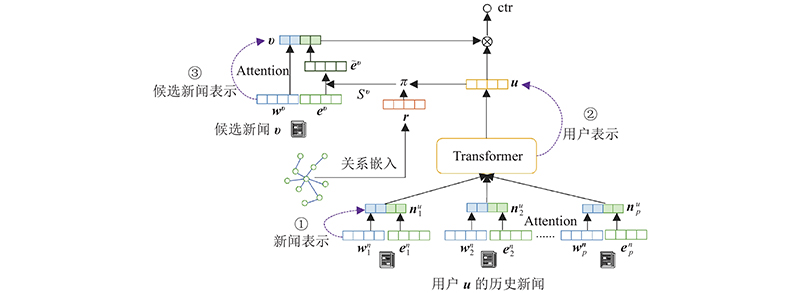
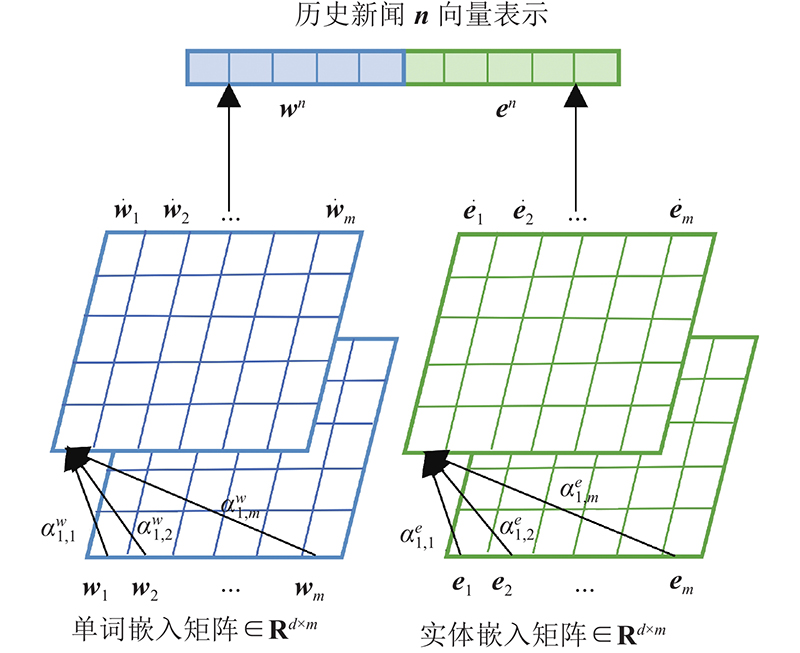
... 在以知识图谱作为辅助信息的新闻推荐中,新闻标题分为标题单词和标题实体2部分,分别为 ${{\boldsymbol{w}}^n} $ ${{\boldsymbol{e}}^n}$ . 传统新闻表示最常见的方式是直接拼接,即新闻 ${\boldsymbol{n}} = {{\boldsymbol{w}}^n} \oplus {{\boldsymbol{e}}^n} $ . 该方法没有考虑到新闻中单词间与实体间的互动关系. DKN[4 ] 虽然进行了改进,但忽略了不同单词和实体对句子的重要程度不同. NRMS[24 ] 考虑了单词的重要性,但未将实体作为辅助信息. 本文利用自注意力机制捕捉单词间和实体间的互动关系,如图3 所示,采用自注意力机制分别计算单词和实体的嵌入向量. 计算各单词在映射空间中的内积,进行归一化: ...
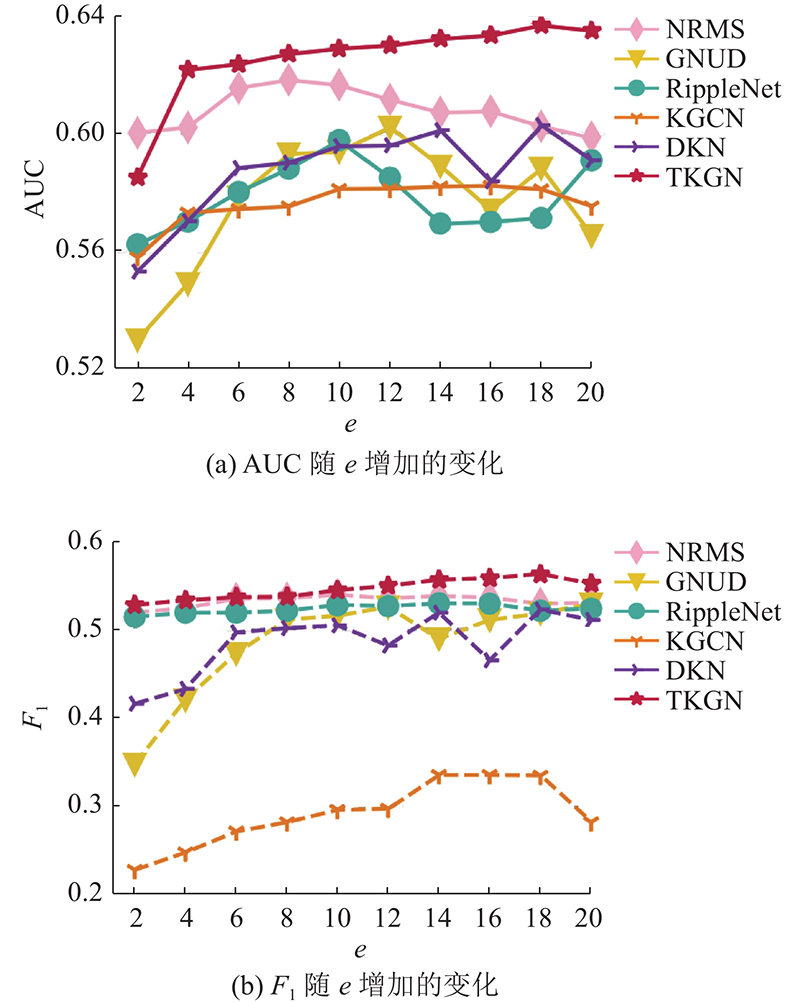
... 为了验证本文算法的有效性,将本文算法与DKN[4 ] 、KGCN[8 ] 、RippleNet[9 ] 、GNUD[27 ] 和NRMS[24 ] 进行比较. DKN[4 ] 用TransE[28 ] 作为获得知识图谱实体及上下文嵌入的学习方法,采用Word2Vec[26 ] 作为词向量嵌入,过滤器数量设置为128. 在KGCN[8 ] 中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
... [4 ]用TransE[28 ] 作为获得知识图谱实体及上下文嵌入的学习方法,采用Word2Vec[26 ] 作为词向量嵌入,过滤器数量设置为128. 在KGCN[8 ] 中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
3
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
... [5 ]用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
... MKR[5 ] 只对知识和新闻进行建模,忽略了不同时期用户兴趣的改变. 利用Transformer提取用户历史新闻的有效特征,捕捉用户对新闻的偏好信息. Transformer输入为用户点击新闻集合 $ {{\boldsymbol{U}}_n} = \left[ {{\boldsymbol{n}}_1^u,{\boldsymbol{n}}_2^u, \cdots ,{\boldsymbol{n}}_p^u} \right] $ $ {\boldsymbol{n}}_i^u $ $ i $ $ p $ $ {\boldsymbol{u}} $ $ {{\boldsymbol{Q}}_i} $ $ {{\boldsymbol{K}}_i} $ $ {{\boldsymbol{V}}_i} $
2
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
... [6 ]使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
基于知识图谱和标签感知的推荐算法
1
2021
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
基于知识图谱和标签感知的推荐算法
1
2021
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
4
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
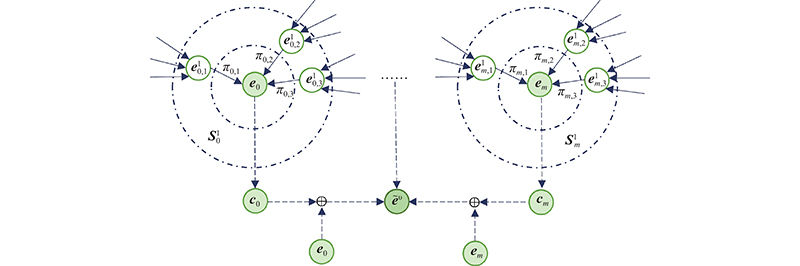
... KGCN[8 ] 在推荐中加入用户与知识图谱中关系的得分,但该方法的项目和知识图谱的实体对应,不适用于包含多个实体的新闻推荐问题. 对KGCN方法进行改进,具体步骤如下:1)计算用户与关系的得分;2)计算候选新闻实体表示;3)利用注意力机制,计算候选新闻表示. 在步骤1)中,由于不同实体由不同关系进行连接,通过计算用户与关系的得分得到用户对关系的偏好,因用户与关系嵌入维度不一致,增加转换函数 $ g$
... 为了验证本文算法的有效性,将本文算法与DKN[4 ] 、KGCN[8 ] 、RippleNet[9 ] 、GNUD[27 ] 和NRMS[24 ] 进行比较. DKN[4 ] 用TransE[28 ] 作为获得知识图谱实体及上下文嵌入的学习方法,采用Word2Vec[26 ] 作为词向量嵌入,过滤器数量设置为128. 在KGCN[8 ] 中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
... [8 ]中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
4
... 传统的基于协同过滤[2 ] 的推荐方法面临数据稀疏和冷启动两大问题[3 ] . 为了缓解信息不足带来的问题,可以考虑从新闻端和用户端2个方面增加辅助信息. 在新闻端增加辅助信息的研究如下. 1)基于知识图谱嵌入的方法[4 -5 ] :DKN方法[4 ] 采用知识感知卷积神经网络(knowledge-aware convolutional neural networks, KCNN),将新闻语义、新闻实体与实体上下文融合. MKR[5 ] 用交叉压缩单元学习推荐项目和知识图谱实体之间的高阶交互效应. 2)基于元路径的方法[6 ] :PGPR方法[6 ] 使用强化学习搜索知识图谱中用户与物品的合理路径. 3)基于混合的方法[7 -9 ] :KGCN方法[8 ] 以用户与关系的得分作为权重,将周围实体信息融入到候选实体. RippleNet[9 ] 与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
... [9 ]与KGCN类似,通过实体传播学习知识图谱高阶结构信息. 现有基于知识图谱的新闻推荐方法普遍具有以下问题. 1)只考虑新闻实体的上下文信息,没有考虑实体对新闻表示的重要程度. 2)没有同时从新闻端和用户端引入辅助信息,忽略了用户对新闻知识图谱实体间关系类型的偏好不同. 例如,在电影推荐中,有的用户基于导演关系选择电影,有的用户基于演员关系选择电影. ...
... 为了验证本文算法的有效性,将本文算法与DKN[4 ] 、KGCN[8 ] 、RippleNet[9 ] 、GNUD[27 ] 和NRMS[24 ] 进行比较. DKN[4 ] 用TransE[28 ] 作为获得知识图谱实体及上下文嵌入的学习方法,采用Word2Vec[26 ] 作为词向量嵌入,过滤器数量设置为128. 在KGCN[8 ] 中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
... [9 ]在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
注入注意力机制的深度特征融合新闻推荐模型
2
2022
... 在用户端引入用户的偏好变化,能够有效地捕捉用户在各时期的不同兴趣[10 -13 ] . 刘羽茜等[10 ] 利用神经网络提取新闻端的语义信息及新闻对不同用户的特征,但该方法忽略了外部信息的重要性. Chen等[11 ] 使用Transformer捕捉用户的点击序列信息,缺点是该方法中的辅助信息属于用户私密信息. Tang等[12 ] 采用卷积神经网络(convolutional neural networks, CNN)学习序列特征,隐因子模型(latent factor model, LFM)学习用户特征,但该方法在推荐中容易遇到冷启动和信息单薄的问题. 冯永等[13 ] 提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
... [10 ]利用神经网络提取新闻端的语义信息及新闻对不同用户的特征,但该方法忽略了外部信息的重要性. Chen等[11 ] 使用Transformer捕捉用户的点击序列信息,缺点是该方法中的辅助信息属于用户私密信息. Tang等[12 ] 采用卷积神经网络(convolutional neural networks, CNN)学习序列特征,隐因子模型(latent factor model, LFM)学习用户特征,但该方法在推荐中容易遇到冷启动和信息单薄的问题. 冯永等[13 ] 提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
注入注意力机制的深度特征融合新闻推荐模型
2
2022
... 在用户端引入用户的偏好变化,能够有效地捕捉用户在各时期的不同兴趣[10 -13 ] . 刘羽茜等[10 ] 利用神经网络提取新闻端的语义信息及新闻对不同用户的特征,但该方法忽略了外部信息的重要性. Chen等[11 ] 使用Transformer捕捉用户的点击序列信息,缺点是该方法中的辅助信息属于用户私密信息. Tang等[12 ] 采用卷积神经网络(convolutional neural networks, CNN)学习序列特征,隐因子模型(latent factor model, LFM)学习用户特征,但该方法在推荐中容易遇到冷启动和信息单薄的问题. 冯永等[13 ] 提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
... [10 ]利用神经网络提取新闻端的语义信息及新闻对不同用户的特征,但该方法忽略了外部信息的重要性. Chen等[11 ] 使用Transformer捕捉用户的点击序列信息,缺点是该方法中的辅助信息属于用户私密信息. Tang等[12 ] 采用卷积神经网络(convolutional neural networks, CNN)学习序列特征,隐因子模型(latent factor model, LFM)学习用户特征,但该方法在推荐中容易遇到冷启动和信息单薄的问题. 冯永等[13 ] 提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
1
... 在用户端引入用户的偏好变化,能够有效地捕捉用户在各时期的不同兴趣[10 -13 ] . 刘羽茜等[10 ] 利用神经网络提取新闻端的语义信息及新闻对不同用户的特征,但该方法忽略了外部信息的重要性. Chen等[11 ] 使用Transformer捕捉用户的点击序列信息,缺点是该方法中的辅助信息属于用户私密信息. Tang等[12 ] 采用卷积神经网络(convolutional neural networks, CNN)学习序列特征,隐因子模型(latent factor model, LFM)学习用户特征,但该方法在推荐中容易遇到冷启动和信息单薄的问题. 冯永等[13 ] 提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
1
... 在用户端引入用户的偏好变化,能够有效地捕捉用户在各时期的不同兴趣[10 -13 ] . 刘羽茜等[10 ] 利用神经网络提取新闻端的语义信息及新闻对不同用户的特征,但该方法忽略了外部信息的重要性. Chen等[11 ] 使用Transformer捕捉用户的点击序列信息,缺点是该方法中的辅助信息属于用户私密信息. Tang等[12 ] 采用卷积神经网络(convolutional neural networks, CNN)学习序列特征,隐因子模型(latent factor model, LFM)学习用户特征,但该方法在推荐中容易遇到冷启动和信息单薄的问题. 冯永等[13 ] 提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
MN-HDRM: 长短兴趣多神经网络混合动态推荐模型
2
2019
... 在用户端引入用户的偏好变化,能够有效地捕捉用户在各时期的不同兴趣[10 -13 ] . 刘羽茜等[10 ] 利用神经网络提取新闻端的语义信息及新闻对不同用户的特征,但该方法忽略了外部信息的重要性. Chen等[11 ] 使用Transformer捕捉用户的点击序列信息,缺点是该方法中的辅助信息属于用户私密信息. Tang等[12 ] 采用卷积神经网络(convolutional neural networks, CNN)学习序列特征,隐因子模型(latent factor model, LFM)学习用户特征,但该方法在推荐中容易遇到冷启动和信息单薄的问题. 冯永等[13 ] 提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
... [13 ]提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
MN-HDRM: 长短兴趣多神经网络混合动态推荐模型
2
2019
... 在用户端引入用户的偏好变化,能够有效地捕捉用户在各时期的不同兴趣[10 -13 ] . 刘羽茜等[10 ] 利用神经网络提取新闻端的语义信息及新闻对不同用户的特征,但该方法忽略了外部信息的重要性. Chen等[11 ] 使用Transformer捕捉用户的点击序列信息,缺点是该方法中的辅助信息属于用户私密信息. Tang等[12 ] 采用卷积神经网络(convolutional neural networks, CNN)学习序列特征,隐因子模型(latent factor model, LFM)学习用户特征,但该方法在推荐中容易遇到冷启动和信息单薄的问题. 冯永等[13 ] 提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
... [13 ]提出混合动态推荐方法,关注用户的短期特征和长期特征,缺点是该方法忽略了新闻的语义信息. ...
2
... 考虑到基于知识图谱的推荐方法和基于用户偏好变化的推荐方法各自的优缺点,本文提出基于Transformer和知识图谱的新闻推荐方法(Transformer and knowledge graph combined network, TKGN),主要贡献如下. 1)为了丰富新闻表示信息,提出利用注意力机制同时捕捉单词互动和实体互动两方面信息,学习单词和实体对新闻表示的重要性. 2)考虑到用户点击序列信息的重要性,在知识图谱推荐中,采用Transformer[14 ] 的位置编码学习用户的点击序列特征,利用自注意力机制捕捉用户对新闻类型的偏好. 3)基于用户对知识图谱中实体间关系的偏好不同,在候选新闻表示中引入知识图谱的高阶结构信息,提升候选新闻的表达精度. ...
... Vaswani等[14 ] 提出基于自注意力机制的深度学习框架Transformer. 不同于RNN的顺序处理方式,Transformer能够有效处理长距离输入且具有训练并行化的特点. Transformer编码器采用多头自注意力机制,运用缩放点积计算第 $i$ $ {{{\rm{head}}} _i} $
1
... 传统的新闻推荐方法基于协同过滤算法,如CCTM[15 ] 利用主题模型对文章和评论建模,采用协同过滤表示新闻和用户. 由于深度学习方法在推荐上的优秀表现,更多的研究致力于利用深度学习建立新闻推荐方法. Kumar等[16 ] 利用深度神经网络,将用户与新闻的互动和新闻内容融合学习,模拟用户和新闻的潜在特征. 仅依赖交互信息的方法存在信息不足的问题,增加辅助信息能够丰富新闻内容. UNBERT[17 ] 通过BERT捕捉新闻间的匹配信号,利用Transformer获取单词和新闻2个维度的信息. FeedRec[18 ] 融合隐式反馈和显式反馈特征,利用Transformer提取用户对新闻的反馈信息. 鉴于知识图谱能够带给推荐方法大量的外界知识,研究者在新闻推荐中融入知识图谱. Qi等[19 ] 借助知识图谱,采用知识感知新闻联合编码器,学习用户点击新闻和候选新闻之间的语义相关性和实体相关性. Anchor KG[20 ] 将知识图谱推理与新闻推荐联合训练,为每篇新闻创建子图,通过子图间的联系推理新闻间的联系. ...
1
... 传统的新闻推荐方法基于协同过滤算法,如CCTM[15 ] 利用主题模型对文章和评论建模,采用协同过滤表示新闻和用户. 由于深度学习方法在推荐上的优秀表现,更多的研究致力于利用深度学习建立新闻推荐方法. Kumar等[16 ] 利用深度神经网络,将用户与新闻的互动和新闻内容融合学习,模拟用户和新闻的潜在特征. 仅依赖交互信息的方法存在信息不足的问题,增加辅助信息能够丰富新闻内容. UNBERT[17 ] 通过BERT捕捉新闻间的匹配信号,利用Transformer获取单词和新闻2个维度的信息. FeedRec[18 ] 融合隐式反馈和显式反馈特征,利用Transformer提取用户对新闻的反馈信息. 鉴于知识图谱能够带给推荐方法大量的外界知识,研究者在新闻推荐中融入知识图谱. Qi等[19 ] 借助知识图谱,采用知识感知新闻联合编码器,学习用户点击新闻和候选新闻之间的语义相关性和实体相关性. Anchor KG[20 ] 将知识图谱推理与新闻推荐联合训练,为每篇新闻创建子图,通过子图间的联系推理新闻间的联系. ...
1
... 传统的新闻推荐方法基于协同过滤算法,如CCTM[15 ] 利用主题模型对文章和评论建模,采用协同过滤表示新闻和用户. 由于深度学习方法在推荐上的优秀表现,更多的研究致力于利用深度学习建立新闻推荐方法. Kumar等[16 ] 利用深度神经网络,将用户与新闻的互动和新闻内容融合学习,模拟用户和新闻的潜在特征. 仅依赖交互信息的方法存在信息不足的问题,增加辅助信息能够丰富新闻内容. UNBERT[17 ] 通过BERT捕捉新闻间的匹配信号,利用Transformer获取单词和新闻2个维度的信息. FeedRec[18 ] 融合隐式反馈和显式反馈特征,利用Transformer提取用户对新闻的反馈信息. 鉴于知识图谱能够带给推荐方法大量的外界知识,研究者在新闻推荐中融入知识图谱. Qi等[19 ] 借助知识图谱,采用知识感知新闻联合编码器,学习用户点击新闻和候选新闻之间的语义相关性和实体相关性. Anchor KG[20 ] 将知识图谱推理与新闻推荐联合训练,为每篇新闻创建子图,通过子图间的联系推理新闻间的联系. ...
1
... 传统的新闻推荐方法基于协同过滤算法,如CCTM[15 ] 利用主题模型对文章和评论建模,采用协同过滤表示新闻和用户. 由于深度学习方法在推荐上的优秀表现,更多的研究致力于利用深度学习建立新闻推荐方法. Kumar等[16 ] 利用深度神经网络,将用户与新闻的互动和新闻内容融合学习,模拟用户和新闻的潜在特征. 仅依赖交互信息的方法存在信息不足的问题,增加辅助信息能够丰富新闻内容. UNBERT[17 ] 通过BERT捕捉新闻间的匹配信号,利用Transformer获取单词和新闻2个维度的信息. FeedRec[18 ] 融合隐式反馈和显式反馈特征,利用Transformer提取用户对新闻的反馈信息. 鉴于知识图谱能够带给推荐方法大量的外界知识,研究者在新闻推荐中融入知识图谱. Qi等[19 ] 借助知识图谱,采用知识感知新闻联合编码器,学习用户点击新闻和候选新闻之间的语义相关性和实体相关性. Anchor KG[20 ] 将知识图谱推理与新闻推荐联合训练,为每篇新闻创建子图,通过子图间的联系推理新闻间的联系. ...
1
... 传统的新闻推荐方法基于协同过滤算法,如CCTM[15 ] 利用主题模型对文章和评论建模,采用协同过滤表示新闻和用户. 由于深度学习方法在推荐上的优秀表现,更多的研究致力于利用深度学习建立新闻推荐方法. Kumar等[16 ] 利用深度神经网络,将用户与新闻的互动和新闻内容融合学习,模拟用户和新闻的潜在特征. 仅依赖交互信息的方法存在信息不足的问题,增加辅助信息能够丰富新闻内容. UNBERT[17 ] 通过BERT捕捉新闻间的匹配信号,利用Transformer获取单词和新闻2个维度的信息. FeedRec[18 ] 融合隐式反馈和显式反馈特征,利用Transformer提取用户对新闻的反馈信息. 鉴于知识图谱能够带给推荐方法大量的外界知识,研究者在新闻推荐中融入知识图谱. Qi等[19 ] 借助知识图谱,采用知识感知新闻联合编码器,学习用户点击新闻和候选新闻之间的语义相关性和实体相关性. Anchor KG[20 ] 将知识图谱推理与新闻推荐联合训练,为每篇新闻创建子图,通过子图间的联系推理新闻间的联系. ...
1
... 传统的新闻推荐方法基于协同过滤算法,如CCTM[15 ] 利用主题模型对文章和评论建模,采用协同过滤表示新闻和用户. 由于深度学习方法在推荐上的优秀表现,更多的研究致力于利用深度学习建立新闻推荐方法. Kumar等[16 ] 利用深度神经网络,将用户与新闻的互动和新闻内容融合学习,模拟用户和新闻的潜在特征. 仅依赖交互信息的方法存在信息不足的问题,增加辅助信息能够丰富新闻内容. UNBERT[17 ] 通过BERT捕捉新闻间的匹配信号,利用Transformer获取单词和新闻2个维度的信息. FeedRec[18 ] 融合隐式反馈和显式反馈特征,利用Transformer提取用户对新闻的反馈信息. 鉴于知识图谱能够带给推荐方法大量的外界知识,研究者在新闻推荐中融入知识图谱. Qi等[19 ] 借助知识图谱,采用知识感知新闻联合编码器,学习用户点击新闻和候选新闻之间的语义相关性和实体相关性. Anchor KG[20 ] 将知识图谱推理与新闻推荐联合训练,为每篇新闻创建子图,通过子图间的联系推理新闻间的联系. ...
Wikidata: a free collaborative knowledgebase
1
2014
... 知识图谱[4 ] 是表示多领域的大规模实体之间关系的语义网络. 在知识图谱中,每2个实体间以关系连接,表示为三元组 $ (h,r,t) $ $h$ $r$ $ t $ 图1 所示为某知识图谱示例图,其中纳尔逊·曼德拉为新闻中包含的实体,姆维佐是邻接实体. 典型知识图谱包括Wikidata[21 ] 、CN-DBPedia[22 ] 和YAGO[23 ] 等. Wikidata是维基媒体提出的多语言辅助知识库,主要以文档形式存储,支持免费使用. CN-DBPedia是最大的中文知识图谱数据库,由复旦大学提出,能自动从百度百科、沪东百科和维基百科中提取知识. YAGO是开源知识库,从Wikipedia和WordNet提取知识,包含超千万的实体及上亿的知识. ...
1
... 知识图谱[4 ] 是表示多领域的大规模实体之间关系的语义网络. 在知识图谱中,每2个实体间以关系连接,表示为三元组 $ (h,r,t) $ $h$ $r$ $ t $ 图1 所示为某知识图谱示例图,其中纳尔逊·曼德拉为新闻中包含的实体,姆维佐是邻接实体. 典型知识图谱包括Wikidata[21 ] 、CN-DBPedia[22 ] 和YAGO[23 ] 等. Wikidata是维基媒体提出的多语言辅助知识库,主要以文档形式存储,支持免费使用. CN-DBPedia是最大的中文知识图谱数据库,由复旦大学提出,能自动从百度百科、沪东百科和维基百科中提取知识. YAGO是开源知识库,从Wikipedia和WordNet提取知识,包含超千万的实体及上亿的知识. ...
1
... 知识图谱[4 ] 是表示多领域的大规模实体之间关系的语义网络. 在知识图谱中,每2个实体间以关系连接,表示为三元组 $ (h,r,t) $ $h$ $r$ $ t $ 图1 所示为某知识图谱示例图,其中纳尔逊·曼德拉为新闻中包含的实体,姆维佐是邻接实体. 典型知识图谱包括Wikidata[21 ] 、CN-DBPedia[22 ] 和YAGO[23 ] 等. Wikidata是维基媒体提出的多语言辅助知识库,主要以文档形式存储,支持免费使用. CN-DBPedia是最大的中文知识图谱数据库,由复旦大学提出,能自动从百度百科、沪东百科和维基百科中提取知识. YAGO是开源知识库,从Wikipedia和WordNet提取知识,包含超千万的实体及上亿的知识. ...
3
... 在以知识图谱作为辅助信息的新闻推荐中,新闻标题分为标题单词和标题实体2部分,分别为 ${{\boldsymbol{w}}^n} $ ${{\boldsymbol{e}}^n}$ . 传统新闻表示最常见的方式是直接拼接,即新闻 ${\boldsymbol{n}} = {{\boldsymbol{w}}^n} \oplus {{\boldsymbol{e}}^n} $ . 该方法没有考虑到新闻中单词间与实体间的互动关系. DKN[4 ] 虽然进行了改进,但忽略了不同单词和实体对句子的重要程度不同. NRMS[24 ] 考虑了单词的重要性,但未将实体作为辅助信息. 本文利用自注意力机制捕捉单词间和实体间的互动关系,如图3 所示,采用自注意力机制分别计算单词和实体的嵌入向量. 计算各单词在映射空间中的内积,进行归一化: ...
... 为了验证本文算法的有效性,将本文算法与DKN[4 ] 、KGCN[8 ] 、RippleNet[9 ] 、GNUD[27 ] 和NRMS[24 ] 进行比较. DKN[4 ] 用TransE[28 ] 作为获得知识图谱实体及上下文嵌入的学习方法,采用Word2Vec[26 ] 作为词向量嵌入,过滤器数量设置为128. 在KGCN[8 ] 中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
... [24 ]在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
1
... 分别采用MIND[25 ] 和Wikidata知识库作为实验数据集和知识图谱. MIND数据是从微软新闻网站的匿名行为日志中收集,包含100万名用户在2019年10月12日至11月22日的新闻点击数据. MIND数据集包含以下2个版本,分别是MIND-small与MIND-large. 如表1 所示为数据集的细节分析. 表中,S n 为新闻总数,S e 为新闻总实体数,M n 为用户平均点击数,M w 为新闻平均单词数,M e 为新闻平均实体数,M r 为新闻实体平均重复值,P s 为正样本数. 以MIND-small为例,执行去缺失值和去重操作后,新闻有93698条,用户平均点击新闻历史个数为22.5,新闻总实体数为108 497,平均每条新闻所含的单词数为10.8,大多数新闻单词个数小于15,所含实体的个数集中在0~2,单个新闻实体重复值为6.4,包含正样本339 498条. 在MIND-small中,将验证集的一半划分为测试集;在MIND-large中,将验证集作为测试集,训练集的1/5作为验证集. 实验中,将MIND-small数据集的实验作为超参数调节的依据. ...
2
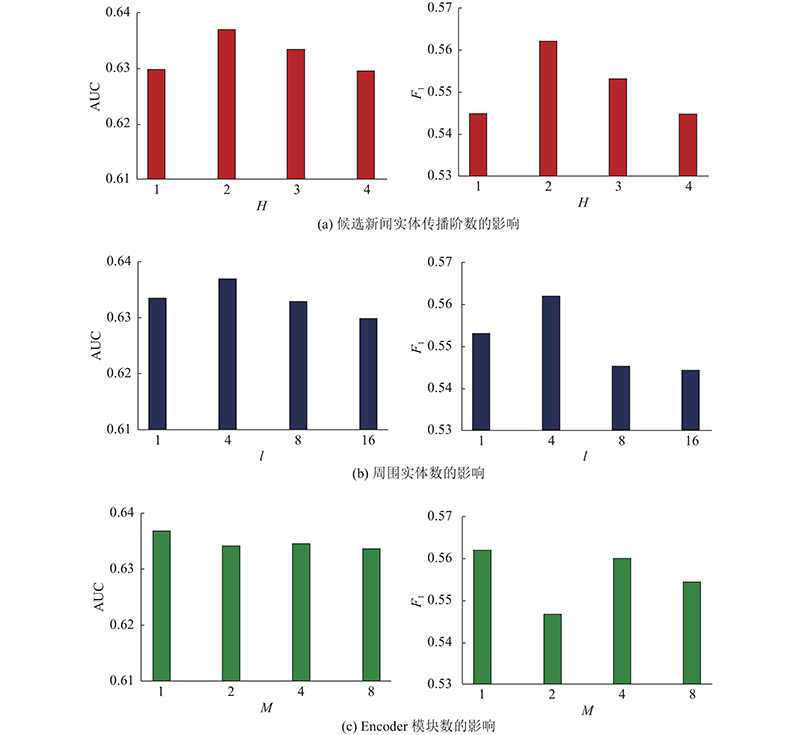
... 采用Word2Vec[26 ] 初始化单词嵌入向量,由于显存的限制,确定单词维度为200,实体维度为100. 为了验证H 、l 和Encoder模块数M 对算法表现的影响,针对上述超参数取不同值,分别计算对应的AUC和F 1 . ...
... 为了验证本文算法的有效性,将本文算法与DKN[4 ] 、KGCN[8 ] 、RippleNet[9 ] 、GNUD[27 ] 和NRMS[24 ] 进行比较. DKN[4 ] 用TransE[28 ] 作为获得知识图谱实体及上下文嵌入的学习方法,采用Word2Vec[26 ] 作为词向量嵌入,过滤器数量设置为128. 在KGCN[8 ] 中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
2
... 为了验证本文算法的有效性,将本文算法与DKN[4 ] 、KGCN[8 ] 、RippleNet[9 ] 、GNUD[27 ] 和NRMS[24 ] 进行比较. DKN[4 ] 用TransE[28 ] 作为获得知识图谱实体及上下文嵌入的学习方法,采用Word2Vec[26 ] 作为词向量嵌入,过滤器数量设置为128. 在KGCN[8 ] 中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
... [27 ]利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...
1
... 为了验证本文算法的有效性,将本文算法与DKN[4 ] 、KGCN[8 ] 、RippleNet[9 ] 、GNUD[27 ] 和NRMS[24 ] 进行比较. DKN[4 ] 用TransE[28 ] 作为获得知识图谱实体及上下文嵌入的学习方法,采用Word2Vec[26 ] 作为词向量嵌入,过滤器数量设置为128. 在KGCN[8 ] 中,聚合方法采用加法聚合,实体表示的迭代次数为2,采样的实体邻接数为4. RippleNet[9 ] 在新闻嵌入中引入新闻的内容信息,多跳数为3,水波集的大小设置为32. GNUD[27 ] 利用交互矩阵建立网络图,以利用高阶交互信息,将偏好特征映射到多个子空间,以学习潜在偏好因素. 子空间数设为7,传播层数为2. NRMS[24 ] 在新闻端和用户端采用多头自注意力,分别建立新闻单词间的联系和用户点击新闻间的联系. 自注意力头数及各头的嵌入维度均为16,查询向量维度为200. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}