

面对个性化的产品设计任务,如何有效利用企业大数据资源,建立可重用的数据管理形式,为个性化设计任务求解服务,已成为实现个性化产品设计任务快速、准确求解的关键.
在产品设计任务下,通过对大数据中蕴含的各类设计知识元进行有效抽取,建立产品设计知识库,可以实现数据资源的重用,为个性化产品设计问题求解奠定良好的知识服务基础. 近年来,有关知识元抽取的研究主要集中于抽取方法的性能比较,多采用深度学习模型. Qiao等[1]提出BERT-BiLSTM-LSTM模型,实现对农业实体关系的有效抽取. 余丽等[2]利用改进的Bootstrapping方法和LSTM-CRF模型,准确抽取文本中的多类型细粒度知识元. Liu等[3]提出新的面向细粒度中文知识元抽取的模型En2BiLSTM-CRF. Qin等[4]运用FT-CNN-BiLSTM-CRF方法,在网络安全实体知识识别中获得了较优的效果. 以上研究多以BiLSTM或CNN这2类模型为基础,通过融入预训练处理模型或者CRF模型,在不同领域下有效解决了多类型细粒度知识元抽取的问题. 考虑到产品设计样本数据集中的设计类知识元具有多样性强、粒度细、复杂性高、局部特征明显等特点,本文提出ALBERT-BiLSTM-IDCNN-CRF这一新的深度学习模型. 该模型的构建是以具备对设计类知识内容的语义特征识别、全局特征强化和知识语义标签关联功能的混合神经网络模型ALBERT-BiLSTM-CRF为基础,通过引入对设计知识元局部特征强化识别的IDCNN层,提升对英文、中文及中英文混合形式的多类型设计知识元的整体抽取效果.
为了利用产品设计知识库,实现个性化设计任务的高效求解,需要选择合适的知识推荐方法. 王志梅等[5]通过学习状态匹配和相似度计算方法,建立资源推荐系统. 密阮建驰等[6]提出知识情景模型,成功应用于企业知识推荐. Wang等[7]采用动态协同过滤相似度计算方法,实现个性化学习资源的高效推荐. Li等[8]以知识库的构建为基础,提出面向任务的知识相似度推荐方法. 上述研究聚焦于改进算法,以获得更优的推荐精度,在短期状态下取得了不错的效果. 从长远来看,尤其是在知识更新不及时或检索信息复杂的情况下,忽略对输出推荐结果有效性的考量,易产生多次检索仍为空值的死循环问题. 本文提出基于推理-情境感知激活模型的设计知识推荐服务模式. 该模式通过融合推理机作用、情境分析和知识激活模块,提升了知识推荐结果的准确性,保障了输出推荐结果的有效性.
综上所述,本文提出的个性化设计知识推荐服务模式以大数据下的产品设计知识抽取为基础,结合推理规则,构建完善的产品设计知识库. 基于产品设计知识库,运用推理-情境感知激活模型方法为个性化设计任务求解推荐合适的知识资源.
1. 知识推荐服务架构
图 1
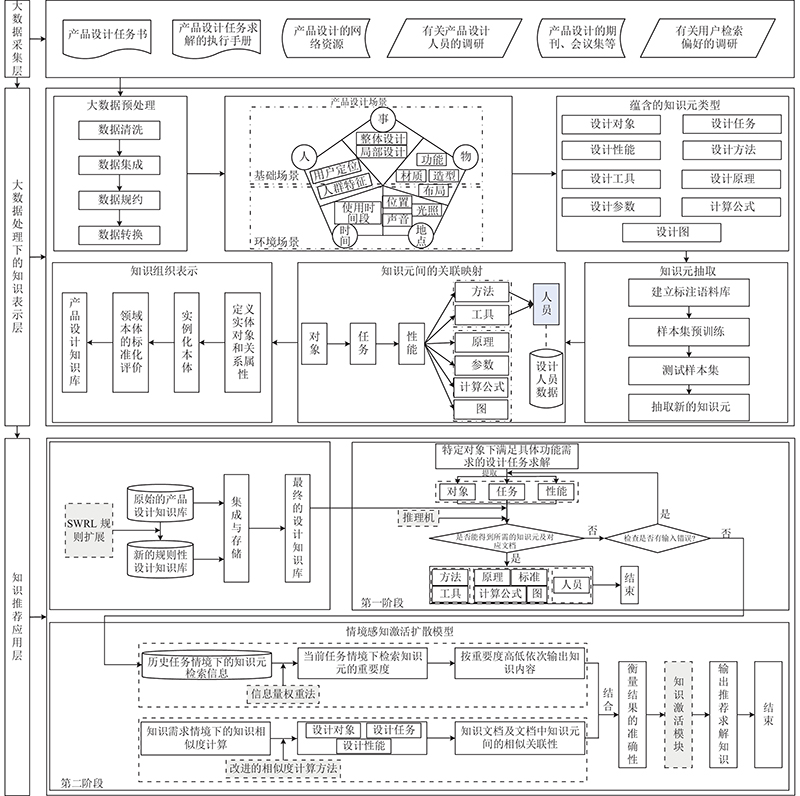
图 1 个性化设计知识推荐服务的架构
Fig.1 Architecture of personalized design knowledge recommendation service
1.1. 大数据采集层和大数据处理下的知识表示层
通过初步整合归纳采集的包括产品设计任务书、产品设计任务求解的执行手册、产品设计的期刊会议集等在内的多源数据,可以为后续知识抽取、知识表示和知识推荐应用环节奠定良好的基础.
1.1.1. 大数据预处理和产品设计场景分析
在统一建模、数据立方体、维度规约等技术步骤的指导下,逐步实现数据清洗、数据集成、数据规约和数据转换操作,为产品设计知识的提取提供标准化、可重用的数据语料.
图 2
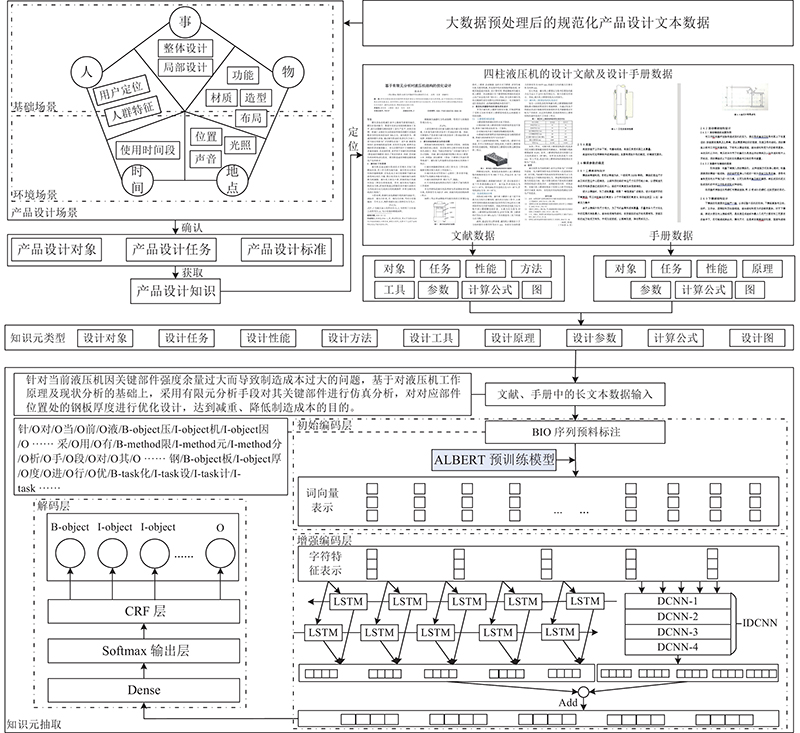
图 2 基于大数据和产品设计场景分析的知识元抽取模型
Fig.2 Knowledge element extraction model based on big data and product design scenario analysis
以预处理后的规范化设计文本数据为基础,通过产品设计场景分析,确定产品设计对象、设计任务和设计标准后,可以定位到以文献和手册数据为核心的相关产品设计知识. 通过设计知识元特征分析和相关特征词提取,整理得到以下9类细粒度设计知识元:设计对象、设计任务、设计性能、设计方法、设计工具、设计原理、设计参数、计算公式、设计图.
1.1.2. 设计知识元抽取
基于产品设计场景分析结果,借助YEDDA工具[11]对设计文献、设计手册数据进行高效的半自动化标注,建立BIO标注语料库. 采用由ALBERT初始编码层、BiLSTM、IDCNN增强编码层及CRF解码层组成的混合神经网络模型ALBERT-BiLSTM-IDCNN-CRF,对标注好的样本集进行训练和测试.
1)ALBERT初始编码层. 在初始编码层,采用ALBERT预训练模型[12]作为文本语义特征提取器,优点在于丰富输入的设计知识内容的语义表示,降低后期模型的训练成本. 用函数L作为ALBERT模型的特征编码计算,用e表示编码后的特征向量,可得
式中:n表示输入设计知识内容的第n个句子,xj表示每个输入句子的第j个字符,i表示每个k维知识字符向量中的第i维,∑表示向量维数的扩展.
2)BiLSTM、IDCNN增强编码层. BiLSTM由2层双向长短期记忆(long short-term memory, LSTM)神经网络构成. 该模型可以在解决传统递归神经网络训练存在的梯度消失和梯度爆炸问题的同时,保留冗余的上下文信息,因此对全局特征信息的识别能力较强.
IDCNN由4个结构相同的膨胀卷积神经网络(dilated convolutional neural network, DCNN)块拼接而成,每个膨胀卷积神经网络块都由膨胀宽度为1、1、2的3层膨胀卷积层构成[13]. 与传统CNN相比,DCNN的优势在于以避免池化损失信息为前提,通过增加感受野,使得每个卷积输出都包含较大范围的信息,因此能够较好地捕捉长序列特征,兼顾局部特征信息.
通过对BiLSTM和IDCNN这2部分的特征向量输出进行点对点融合,即对输出的特征向量值进行求和,输出的向量维度不变,增强了设计知识元的全局语义特征表示和局部语义特征表示. 若E1为初始编码层输出,W1为BiLSTM模块作用下的向量输出函数,W2为IDCNN模块作用下的向量输出函数,则增强编码层的设计知识表示总输出E2为
3)CRF解码层. 采用全连接(dense)使增强编码层的输出向量维度转换成标签向量维度后,经Softmax函数计算,输出单元数应与命名实体标签数相等. 运用条件随机场(conditional random field, CRF)[2]提取标签依赖关系,判断每个字符最有可能的命名实体识别类别,输出最终设计知识元标注与抽取结果.
1.1.3. 知识表示
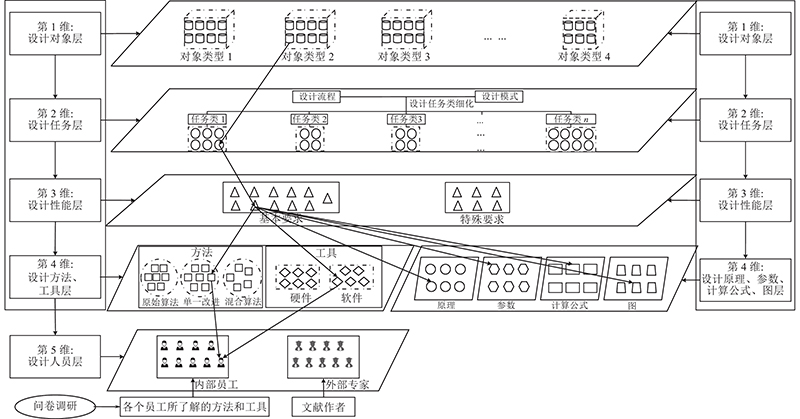
图 3
1.2. 知识推荐应用层
提出的基于推理-情境感知激活模型的个性化设计知识推荐服务模式在实际应用中具备优越的综合性能. 基于推理机作用的一阶段设计知识推荐服务依靠知识库中的显性语义关系和潜在语义关系,保证了推荐结果的准确性,但由于设计知识库内容有限,多数情况下难以在知识库中找到完全一致的知识映射关系,获得有效输出推荐结果的概率较低. 基于情境感知激活模型的二阶段设计知识推荐服务以多源关联数据和设计情境分析为基础,可以大幅提升输出有效结果的概率,弥补一阶段的不足.
1.2.1. 推理-情境感知激活模型
推理-情境感知激活模型以特定设计对象属性、任务属性、性能要求属性知识元的输入为基础,搜索知识库中与输入知识元信息完全一致的知识路径,完成设计知识的有效输出推荐. 若知识库中不存在完全一致的知识关联路径,则对产品设计历史任务情境和知识需求情境进行分析,得到检索知识元与产品设计知识库中相似知识元节点间的关联性权值. 激活被检索且关联性权值较高的设计知识元节点,使设计知识网络中满足关联关系的知识元节点得以激活扩展,结合阈值设置,输出并推送合适的求解知识.
1.2.2. 一阶段设计知识推荐服务
根据图1可知,推理机的作用实现必须建立在产品设计知识库之上. 为了利用现有的知识关系属性,快速获得所需的知识资源,对知识库中的关系属性进行补充完善. 利用SWRL规则[15]对原始设计知识库中的潜在知识语义关系进行推理完善,得到新的规则性知识库. 通过集成原始设计知识库和规则性知识库,获得最终的产品设计知识库. 通过推理机作用实现对输入端的设计对象、设计任务和设计性能知识元的准确识别. 根据设计知识需求和输出推荐结果,判断是否获得所需的设计知识元和对应的文档内容. 若是,则保存结果,推荐过程终止;否则,先排查有关输入错误的问题,再判定一阶段设计知识推荐服务失效,无法获得所需的知识推荐结果,进入二阶段设计知识推荐服务的流程.
1.2.3. 二阶段设计知识推荐服务
作为对一阶段未能输出所需推荐结果的补充完善环节,二阶段设计知识推荐服务过程以提升输出推荐结果的有效性为目标. 采用融合设计情境分析、知识元重要度计算算法、改进知识相似度计算算法和知识激活模块的情境感知激活模型方法,为个性化设计任务求解推荐合适的知识资源. 知识激活模块通过激活知识节点与设计知识库中同级相似知识元的关联,建立以激活知识节点为中心的新知识检索路径[16].
在对知识元重要度和知识相似度计算前,分别加入历史任务情境和知识需求情境分析的主要原因在于相似的设计任务往往有着相似的设计情境. 以情境分析为基础,有助于理清不同设计任务的区别和知识需求的差异,强化相似设计任务间的知识联系,提升推荐结果的可靠性和准确性.
1)历史任务情境下的知识元重要度计算. 大数据背景下的产品设计知识库存在如图4所示的6种知识检索路径,对于同一个检索意图,不同路径下的同维度知识元间存在检索重要度的差异. 依据企业过往知识检索规律可知,历史任务情境下的知识元重复检索次数记录和检索时间序列能够有效地反映当前检索意图下的优先知识需求. 以历史设计任务情境下的知识关键词检索偏好和检索时间记录为数据基础,运用信息量权重法[17],得到第四维度下设计方法、设计工具、设计原理、设计参数、计算公式、设计图这6类知识元间的相对重要度,按照重要度从高到低的顺序推荐给设计管理人员. 依据路径中的知识关系,设计人员重要度可以用设计方法和设计工具重要度之和表示. 具体的知识元重要度定义计算如下.
图 4
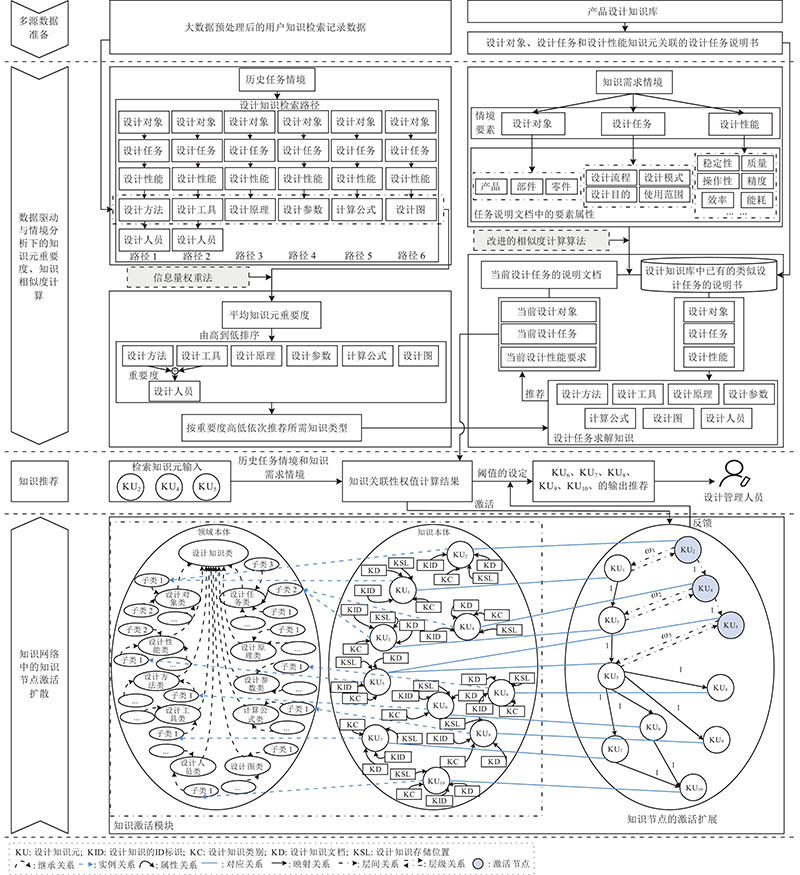
图 4 基于情境感知激活模型的二阶段设计知识推荐服务过程
Fig.4 Second stage of designing knowledge recommendation service process based on context-aware activation model
定义1 知识元重要度(knowledge unit importance, KUI) 用上述第4维度中6类知识元的检索顺序归一化值与检索偏好次数归一化值的乘积表示各类知识元的重要度,结果取n次历史任务情境下的知识元重要度均值:
式中:ω取1,2,···,6,依次象征设计方法、设计工具、设计原理、设计参数、计算公式、设计图知识元;q取1,2,···,6,表示知识元检索顺序分别为第1,2,···,6;qω,i为第i次历史任务情境下第ω类知识元的检索顺序值;Tω,i为第i次历史任务情境下第ω类知识元的检索偏好次数.
在实际分析时,上述计算方法对文本语义特征考量较单一,忽略了包括词性特征和文本结构信息在内的其他细节特征. 本文提出改进的知识相似度计算方法,在计算TF-IDF权重的同时,算得词性权重和位置权重,将综合这3种特征的总权重纳入产品设计任务文档间的余弦相似度计算中. 具体计算流程如图5所示.
图 5
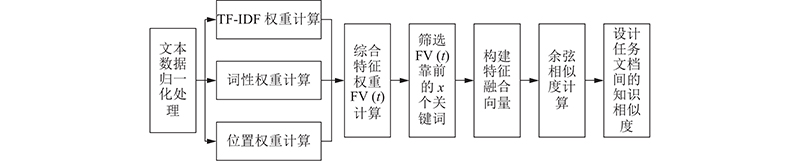
图 5 改进的知识相似度计算算法流程
Fig.5 Flow of improved knowledge similarity calculation algorithm
根据下式,计算得到产品设计任务文档中每个要素关键词t的TF-IDF权重S (t):
式中:tf(t,d)和idf(t)分别为每个要素关键词t的词频和逆文档频率.
表 1 词性权重的归纳表
Tab.1
| 词性 | 权重 |
| 名词 | 0.75 |
| 动词 | 0.65 |
| 形容词 | 0.40 |
| 其他 | 0.10 |
考虑到产品设计任务文档中标题和正文位置的同一关键词存在作用差异,须计算不同位置的关键词权重. 结合文献[21]得出的通常情况下文档标题位置权重高于正文位置权重这一研究成果,将标题位置权重和正文位置权重分别设为p1和p2,将关键词t在文档d中总的位置权重设为Wt,d,建立如下位置权重函数的计算关系式:
式中:k1、k2分别为关键词在设计任务文档标题、正文位置的评价权值. 若关键词在标题处出现,则k1=1;若关键词在正文中出现,则k2=1;否则,赋值为0. p1和p2可以在实验中进行个性化设置,也可以采用构建判断矩阵法确定.
结合上述3种关键文本特征,运用下式计算得到产品设计任务文档中每个要素关键词t的综合特征权值:
式中:α、β、γ分别为TF-IDF权重、词性权重、位置权重的相似度系数. 选出每篇文档中FV(t)靠前的若干个关键词,构建长度相等的特征融合向量. 系数值通过判断矩阵法量化分析得到:
利用下式计算得到当前设计任务文档dc与设计任务文档语料库中文档di的内容相似度:
式中:Ɩi,j、Ɩc,j 分别为文档di、dc下的特征融合向量的第j个元素.
3)知识网络中的知识节点激活扩散. 为了有效地利用现有知识库,实现新的强相似知识的关联性扩展,促进关联性设计知识重用,以输入的检索知识元为产品设计知识网络中的激活节点,通过知识激活模块[22]作用,扩展激活节点间的映射关系. 将相似知识的关联性权值作为同层级知识节点间的激活值,纳入知识网络中. 依据知识相似度阈值设定,输出推荐满足需求条件的设计知识,供设计管理人员进行浏览与选择.
知识激活模块内的每个设计知识元都可以表示为KU = (KID|KC, KD, KSL). 其中,KID为设计知识元唯一ID标识,KC为设计知识元类别,KD为相关设计知识文档,KSL为设计知识存储位置. 对于产品设计知识库或同一文档内的设计知识元,若存在不同层级间的知识关联映射,则关联权值必为1.
4)推荐结果的准确性衡量. 基于知识相似度计算结果,结合对输出结果的阈值设置,可得最终的推荐列表. 采用下式,完成对推荐结果的准确性衡量:
式中:
2. 实例分析
2.1. 液压机设计任务相关数据采集与处理
对采集的液压机设计任务书、液压机设计任务求解执行手册、液压机设计期刊会议集、有关液压机设计人员的调研数据等进行有效整合.
以“液压机设计”为关键词,对中国知网中2000年1月至2021年12月的相关文献进行检索和下载,经数据清洗、集成环节,得到关联性最高的100篇文献数据. 查找并下载多种型号的液压机设计手册,经大数据处理,得到规范化的设计手册数据集. 运用YEDDA工具,完成数据语料的标注工作.
2.2. 液压机设计知识元抽取
在对液压机设计知识元进行抽取前,需要完成实验环境的部署和模型超参的调试.
在实验环境方面,以Python3.6.2、Intel Core i9-9900H CPU@3.7 GHz的CPU、NVIDIA GeForce RTX 3070Ti(16 GB)的GPU为基础环境,基于Tensorflow1.15.0和Keras2.3.1架构进行仿真实验.
在模型超参设置方面,采用小型ALBERT预训练模型(albert_tiny),BiLSTM网络单元数为128,IDCNN中3层膨胀卷积层的宽度分别为1、1、2,CRF层采用维特比算法. 使用0.1的丢弃率(Dropout)、0.01的学习率,训练批数大小(batchsize)为None,循环迭代全数据集10次,输入文本长度不超过200.
在同样的实验环境和超参设置背景下,运用消融实验法,确定以ALBERT、ALBERT-BiLSTM、ALBERT-CRF和改进前的ALBERT-BiLSTM-CRF作为基准比较模型. 基于经典的人民日报数据集和液压机设计数据集下不同模型的准确率P、召回率R、F1仿真结果,验证了ALBERT-BiLSTM-IDCNN-CRF模型在抽取设计对象、设计任务、设计性能、设计方法、设计工具、设计原理、设计参数、计算公式和设计图知识元方面的良好性能.
表2中,相较于经典的人民日报数据集,在液压机设计数据集中,ALBERT、ALBERT-BiLSTM、ALBERT-CRF和ALBERT-BiLSTM-CRF这4种具有代表性的基准模型的F1均出现大幅下降. ALBERT-BiLSTM-IDCNN-CRF模型下的F1虽然有所下降,但整体性能指标均优于其他基准模型.
表 2 2种文本语料下的不同模型仿真结果
Tab.2
| 模型 | 人民日报数据集 | 液压机设计数据集 | |||||
| P | R | F1 | P | R | F1 | ||
| ALBERT | 0.872 4 | 0.834 6 | 0.818 2 | 0.730 1 | 0.476 8 | 0.536 3 | |
| ALBERT-BiLSTM | 0.931 2 | 0.908 4 | 0.919 6 | 0.909 3 | 0.555 0 | 0.667 9 | |
| ALBERT-CRF | 0.831 5 | 0.697 4 | 0.758 0 | 0.434 4 | 0.417 3 | 0.423 0 | |
| ALBERT-BiLSTM-CRF | 0.964 4 | 0.919 9 | 0.941 6 | 0.841 7 | 0.618 0 | 0.681 9 | |
| ALBERT-BiLSTM-IDCNN-CRF | 0.973 4 | 0.925 6 | 0.945 8 | 0.915 3 | 0.627 1 | 0.718 7 | |
在图6所示的不同模型方法下各类液压机设计知识元的识别效果比较分析中,以准确率和召回率的调和平均数F1为衡量基准,基于ALBERT-BiLSTM-IDCNN-CRF模型的总体识别效果最佳,且该模型对Object(设计对象)类知识元的识别效果最佳,F1达到0.861 1. 对其他各类设计知识元的识别效果都大于0.6,仅Tool(设计工具)类知识元的识别效果略低于0.6. 主要原因在于Tool类知识元一般为较长的英文文本,有时该类知识元对应的上下文无明显特征,导致识别效果不理想.
图 6
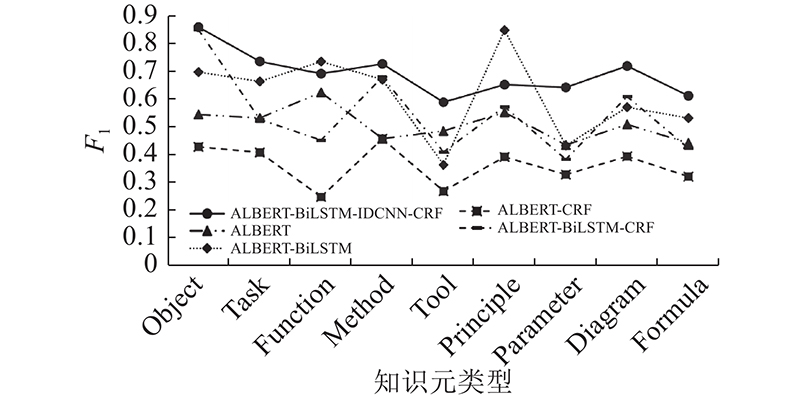
图 6 不同模型方法下的各类知识元识别F1
Fig.6 Identification of F1 of various knowledge elements under different model methods
基于液压机设计数据集,通过多次实验,计算得到不同模型方法下完成单个知识元抽取的平均耗时. 时间记录从模型编码开始,至循环迭代10次完成,输出最终的知识元抽取结果.
根据表3可知,单一ALBERT模型下的知识元抽取平均耗时t相对最短,抽取效率最高. ALBERT-BiLSTM-IDCNN-CRF模型下的知识元抽取平均耗时虽然比ALBERT模型约多3.8 ms,但在实际应用背景下,对测试文本中包含的多种知识元的网络识别速度无影响或影响较小.
表 3 单个知识元抽取的平均耗时
Tab.3
| 模型方法 | t/ms |
| ALBERT | 61.207 |
| ALBERT-BiLSTM | 63.145 |
| ALBERT-CRF | 64.685 |
| ALBERT-BiLSTM-CRF | 65.022 |
| ALBERT-BiLSTM-IDCNN-CRF | 64.893 |
综上可知,提出的混合神经网络模型ALBERT-BiLSTM-IDCNN-CRF的综合性能优越性在液压机设计知识元抽取实验中得到了验证.
2.3. 液压机设计知识库
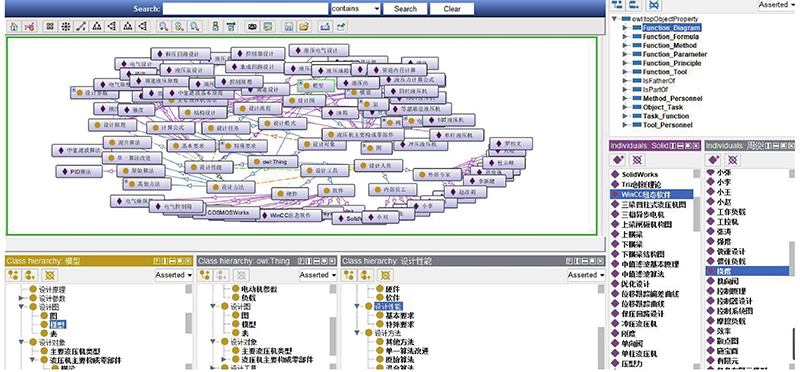
2.3.1. 原始设计知识库构建
基于液压机设计知识元抽取内容,对某液压机公司设计研发部门内的6位内部员工进行问卷调研,得到每个人掌握的设计方法和设计工具信息,构建内部人员与设计方法、设计工具间的关联映射.
以文献为单位,建立文献第一作者与设计方法、设计工具间的关联映射.
图 7
2.3.2. 规则性设计知识的发现
设计人员的合理选择在个性化设计任务求解中占据重要的地位. 为了更快、更准确地在知识路径中找到所需的设计人员,完成设计人员的推荐,定义如下SWRL规则:设计方法(?dm) ^ 设计工具(?dt) ^ 设计性能(?df) ^ Function_Method(?df, ?dm) ^ Function_Tool(?df, ?dt) ^ 设计人员(?dp) ^ Person_Method(?dp, ?dm) ^ Person_Tool(?dp, ?dt) -> Task_Give(?dt, ?dp). 具体含义为若当前产品设计任务下的特定设计性能要求可以用某种设计方法和设计工具实现,且某个设计人员掌握上述设计方法和设计工具,则该设计任务可以交由该设计人员完成.
图 8
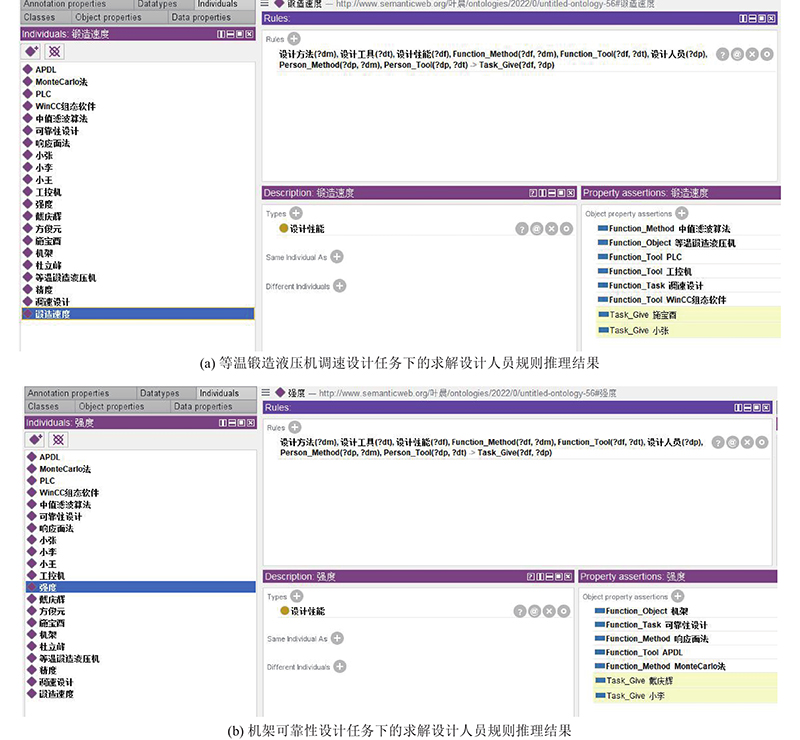
图 8 基于推理规则的隐性设计知识发现
Fig.8 Tacit design knowledge discovery based on inference rules
基于隐性设计知识的发现过程,建立设计人员与满足特定性能要求的设计任务之间的知识推理关联,完善现有产品设计知识库的不足,提升知识推荐结果的有效性.
2.4. 液压机设计知识推荐服务
2.4.1. 基于液压机设计知识库和Pellet推理机的设计知识推荐服务
提出的个性化设计知识推荐服务模式由2个推荐阶段组成. 基于液压机设计知识库和Pellet推理机的设计知识推荐服务为第1个推荐阶段. 如图9所示,围绕液压机设计知识库,经设计对象、设计任务和设计性能的检索信息输入及Pellet推理机的推理作用,可以得到满足检索条件的具体设计知识输出. 若无法获得所需的知识推荐结果,则判定一阶段推荐失效,将原输入的检索信息自动传送到二阶段下的设计知识推荐服务流程.
图 9
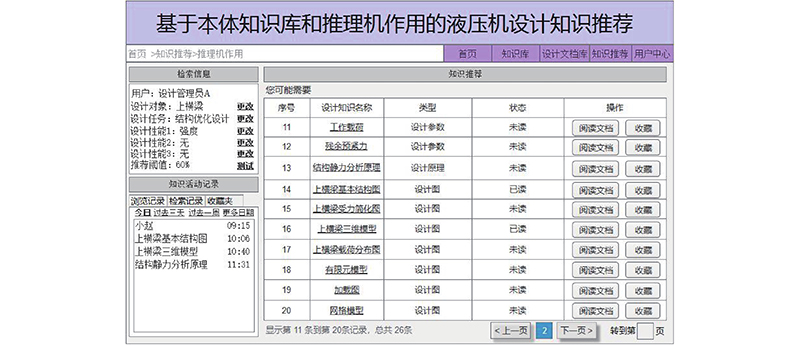
图 9 一阶段液压机设计知识推荐服务功能实现部分示例图
Fig.9 Partial example diagram of implementation of first-stage hydraulic press design knowledge recommendation service function
2.4.2. 基于情境感知激活模型的设计知识推荐服务
在二阶段的基于情境感知激活模型的设计知识推荐服务流程中,通过调研设计管理人员在近10次历史任务情境下的知识关键词检索偏好和检索顺序,结合式(3),获得表4所示的知识推荐优先级排序结果. 设计人员类知识元的重要度均值(mean of importance, MI)等于设计方法类和设计工具类知识元重要度均值之和.
表 4 知识推荐的优先级排序
Tab.4
| 类型 | MI | 排序 |
| 设计原理 | 0.019 5 | 6 |
| 设计参数 | 0.021 3 | 5 |
| 计算公式 | 0.014 8 | 7 |
| 设计图 | 0.039 0 | 2 |
| 设计方法 | 0.032 5 | 3 |
| 设计工具 | 0.030 8 | 4 |
| 设计人员 | 0.063 3 | 1 |
运用改进的知识相似度计算方法,即式(4)~(8),获得设计知识相似度的计算结果,与原有的结合TF-IDF和余弦相似度的计算方法进行比较. 将输出结果的阈值设定为0.6,可得如表5所示的具体结果.
表 5 当前设计任务书与任务书库中其他任务书间的相似度计算
Tab.5
| 任务书的下标索引 | TF-IDF+余弦相似度方法 | 改进的知识相似度计算方法 | |||
| 相似度 | 输出结果 | 相似度 | 输出结果 | ||
| 0 | 0.794 | √ | 0.838 | √ | |
| 1 | 0.331 | × | 0.304 | × | |
| 2 | 0.089 | × | 0.012 | × | |
| 3 | 0.608 | √ | 0.585 | × | |
| 4 | 0.620 | √ | 0.636 | √ | |
| 5 | 0.152 | × | 0.016 | × | |
| 6 | 0.506 | × | 0.486 | × | |
| 7 | 0.302 | × | 0.310 | × | |
| 8 | 0.076 | × | 0.031 | × | |
| 9 | 0.213 | × | 0.189 | × | |
| 10 | 0.144 | × | 0.103 | × | |
与结合TF-IDF和余弦相似度的计算方法相比,引入词性权重和位置权重的改进知识相似度计算方法的计算精度更高,区分了高度相似和不相似的情况,符合实际状况. 高度相似的任务书0与当前设计任务书间的相似度由“0.794”上升至“0.838”,不相似的任务书1与当前设计任务书间的相似度由“0.331”下降至“0.304”.
基于改进的知识相似度计算方法发现,设计任务书库中的任务书0和任务书4符合相似度要求. 结合图10所示的当前设计任务书与任务书0、任务书4内的设计对象、设计任务和设计性能这3类关键词的语义相似度计算结果,优先推荐任务书0在液压机设计知识库中对应的关联性设计知识.
图 10
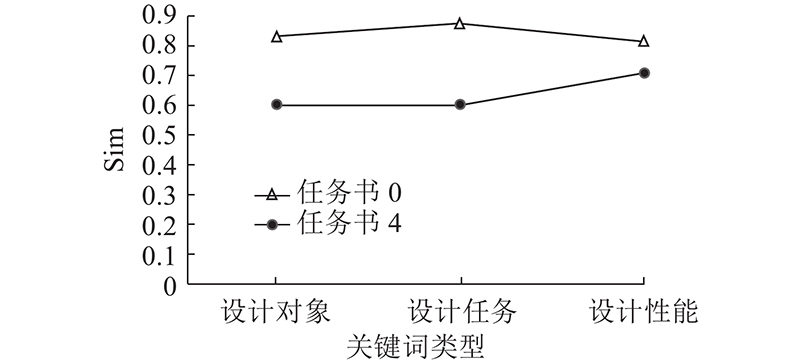
图 10 任务关键词间的语义相似度计算
Fig.10 Semantic similarity calculation between task keywords
设定激活节点的激活阈值为0.8,通过液压机设计知识库下的知识激活模块作用,得到如图11所示的液压机设计知识节点的激活扩展结果. 图中,阴影部分表示激活的输入检索知识元,边对应的数值表示知识关联映射的权重.
图 11
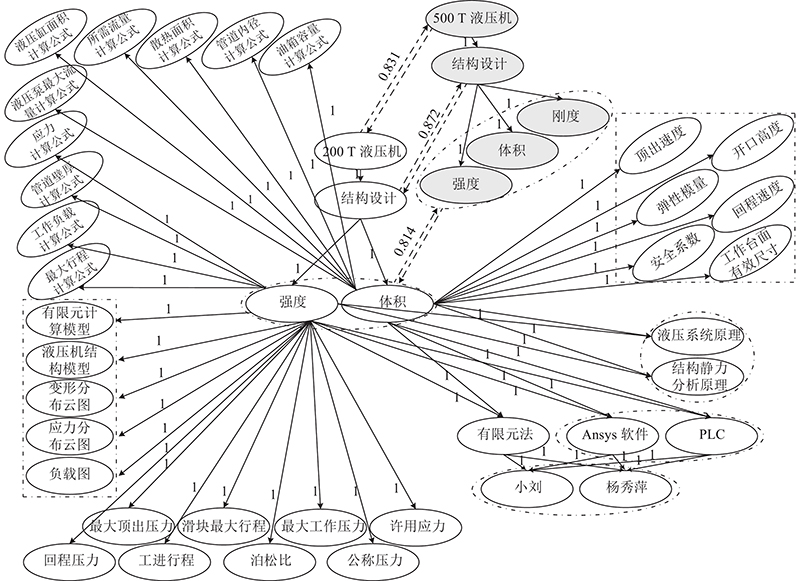
图 11 液压机设计知识节点的激活扩展
Fig.11 Activation and expansion of hydraulic press design knowledge node
设计如图12所示的二阶段液压机设计知识推荐服务功能. 1)基于知识需求情境下设计任务书间的相似度计算和阈值设置,获得相似任务方案的知识推荐结果. 2)基于知识激活模块的激活作用,实现检索性设计知识元与液压机设计知识库中相似知识节点间的双向关联映射. 3)基于历史任务情境下知识元优先级排序和液压机设计知识库中相似任务书对应的知识关联映射,实现液压机设计知识的高效推荐. 4)若设计管理人员多次浏览或收藏推荐的某个知识元的关联知识文档,则更新当前设计知识节点与激活知识节点间的关联性权值,存储于液压机设计知识库中.
图 12
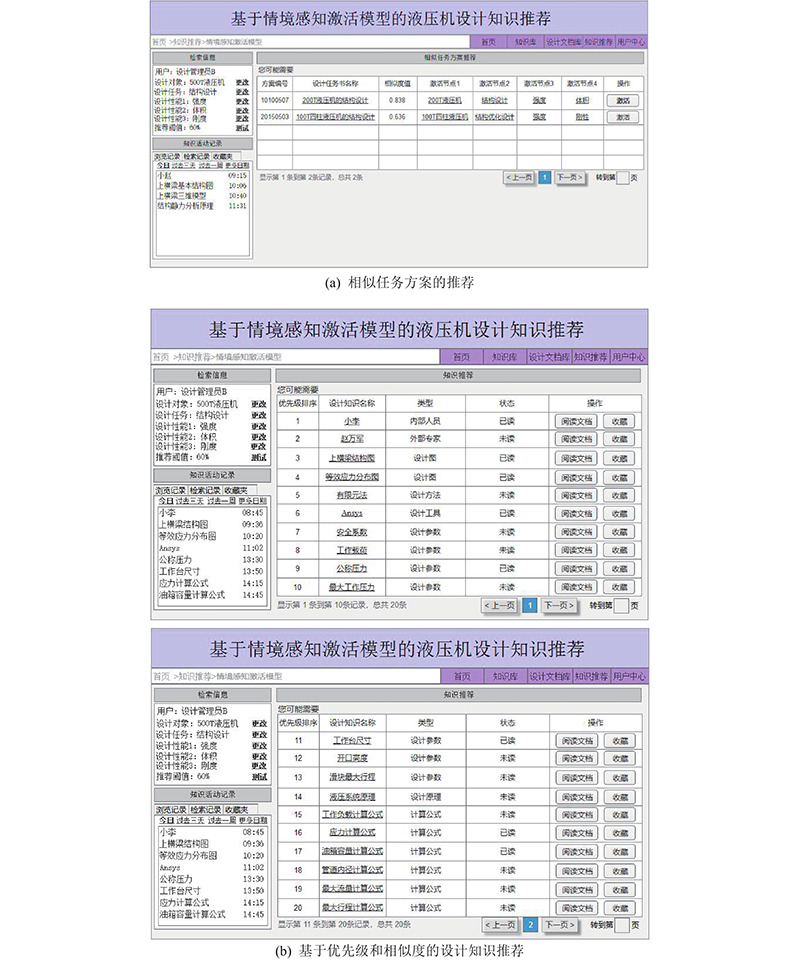
图 12 二阶段液压机设计知识推荐服务功能
Fig.12 Second stage hydraulic press design knowledge recommendation service function
2.4.3. 个性化设计知识推荐模式的应用效果分析
为了证明提出的推理-情境感知激活模型在液压机设计知识推荐应用中的优越性,对推理机、知识激活模型、情境感知激活模型、推理-情境感知激活模型在30次随机输入检索下的输出有效结果的平均概率Qs、平均推荐结果的准确性Ps、是否有优先度和相似度排序性能和输出推荐结果加浏览无用文档总耗时Ts进行比较. 平均推荐结果的准确性衡量以式(11)的计算结果为基础,结合设计管理人员的经验进行综合判定.
表6中,推理-情境感知激活模型的所有性能指标排名皆位于前二,综合推荐性能最佳.
表 6 不同方法的推荐性能
Tab.6
| 方法 | Qs | Ps | 优先度和相似度排序性能 | Ts |
| 推理机 | 20% | 100% | 无 | 短 |
| 知识激活模型 | 70% | 50% | 无 | 长 |
| 情境感知激活模型 | 70% | 60% | 有 | 较长 |
| 推理-情境感知激活模型 | 70% | 80% | 有 | 较短 |
综合以上分析内容,基于推理-情境感知激活模型的个性化设计知识推荐服务模式可以为个性化液压机设计任务求解快速、准确地推送所需知识资源.
3. 结 论
(1)分析企业大数据资源中蕴含的设计知识类型,提出ALBERT-BiLSTM-IDCNN-CRF这一新的模型方法. 以ALBERT-BiLSTM-CRF为基础,通过引入IDCNN层,强化对中文、英文、中英文混合等形式下设计知识元的局部特征识别能力,解决了设计知识元抽取效率低、准确性差的问题.
(2)根据抽取的9类设计知识元和设计人员数据中的人员知识元,建立知识元间的逻辑关联映射,得到5维映射知识模型. 运用本体方法和推理规则,构建并完善了产品设计知识库.
(3)提出基于推理-情境感知激活模型的个性化设计知识推荐服务模式,通过液压机设计实例,验证了该模式方法的可靠性和先进性.
下一步研究工作将立足于其他设计实例,探讨提出的新方法、新模式的普遍适用性.
参考文献
A joint model for entity and relation extraction based on BERT
[J].
基于深度学习的文本中细粒度知识元抽取方法研究
[J].
Extracting fine-grained knowledge units from texts with deep learning
[J].
Innovative deep neural network modeling for fine-grained Chinese entity recognition
[J].DOI:10.3390/electronics9061001 [本文引用: 1]
A network security entity recognition method based on feature template and CNN-BiLSTM-CRF
[J].DOI:10.1631/FITEE.1800520 [本文引用: 1]
基于相似学习者发现的资源推荐系统
[J].
Resource recommendation system based on similar learners exploitation
[J].
面向企业知识推荐的知识情景建模方法研究
[J].DOI:10.16353/j.cnki.1000-7490.2016.04.014 [本文引用: 1]
Research on knowledge scenario modeling method for enterprise knowledge recommendation
[J].DOI:10.16353/j.cnki.1000-7490.2016.04.014 [本文引用: 1]
Personalized learning resource recommendation method based on dynamic collaborative filtering
[J].
An approach to task-oriented knowledge recommendation based on multi-granularity fuzzy linguistic method
[J].DOI:10.1108/K-10-2014-0207 [本文引用: 1]
Development of an integrated-collaborative decision making framework for product top-down design process
[J].DOI:10.1016/j.rcim.2008.01.005 [本文引用: 1]
基于场景思维的家具产品设计策略研究
[J].DOI:10.19531/j.issn1001-5299.202012013 [本文引用: 1]
Research about furniture product design strategies based on scene thinking
[J].DOI:10.19531/j.issn1001-5299.202012013 [本文引用: 1]
BIBC: a Chinese named entity recognition model for diabetes research
[J].
面向航天产品研制的知识网络本体建模方法
[J].
Modeling ontological knowledge network for aerospace equipment development
[J].
基于本体的物品属性类人认知及推理
[J].
Ontology-based humanoid cognition and reasoning of object attributes
[J].
基于变权分层激活模型的产品设计知识动态推送技术
[J].
Product design knowledge dynamic push technology based on variable-weight layered spreading activation model
[J].
A blog ranking algorithm using analysis of both blog influence and characteristics of blog posts
[J].
Product design and manufacturing process based ontology for manufacturing knowledge reuse
[J].DOI:10.1007/s10845-016-1290-2 [本文引用: 1]
Cosine similarity measures for intuitionistic fuzzy sets and their applications
[J].
A universal part-of-speech tagset
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}