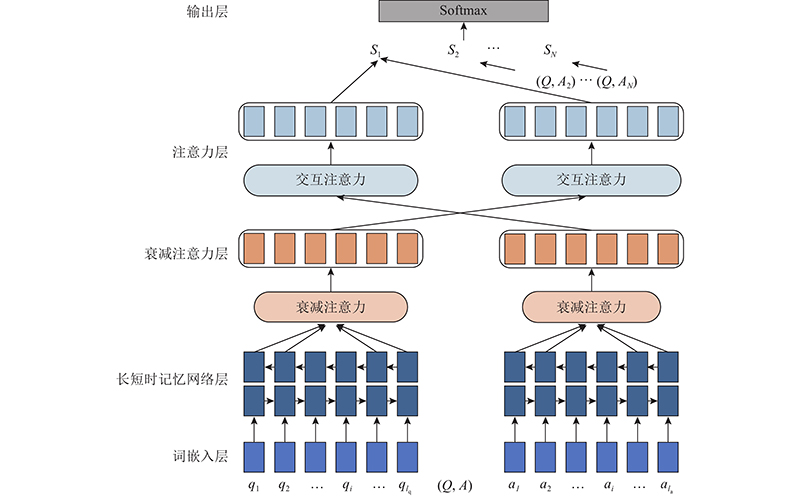
使用 $ q=\left\{{q}_{1},{q}_{2},\cdots ,{q}_{{{i}}},\cdots ,{q}_{{l}_{{\rm{q}}}}\right\} $ Q ,其中 $ {q}_{i} $ i 个单词, $ {l}_{{\rm{q}}} $ $ a=\left\{{a}_{1},{a}_{2},\cdots ,{a}_{i},\cdots {a}_{{l}_{{\rm{a}}}}\right\} $ A ,其中 $ {a}_{i} $ i 个单词, $ {l}_{{\rm{a}}} $ ${{\boldsymbol{E}}}\in {\bf{R}}^{V\times d} $ V 为词汇量的大小,d 为词嵌入的维度. 词嵌入技术为问答文本语料库中的每个词构建向量,即每个词生成k 维的向量表示,问题输入序列表示为矩阵 $ {{{\boldsymbol{X}}}}_{q}\in {\bf{R}}^{V\times d} $ ${\boldsymbol{X}}_{a} \in {\bf{R}}^{V\times d}$ . 以 q 为例进行描述, $\;{{{\boldsymbol{X}}}}_{q} = \left[ {{\boldsymbol{x}}}_{1},{{\boldsymbol{x}}}_{2},\cdots ,{{\boldsymbol{x}}}_{i},\cdots,{{\boldsymbol{x}}}_{{l}_{{\rm{q}}}} \right]$ $ {{\boldsymbol{x}}}_{i} $ q 中第i 个词的k 维向量表示. 使用预训练word2vec和Glove词向量初始化嵌入矩阵,使用[0, 0.5]的均匀采样对词汇表外的单词进行随机初始化.
[1]
ZHANG Y T, LU W P, OU W H, et al Chinese medical question answer selection via hybrid models based on CNN and GRU
[J]. Multimedia Tools and Applications , 2020 , 79 : 14751 - 14776
DOI:10.1007/s11042-019-7240-1
[本文引用: 1]
[2]
LIU D L, NIU Z D, ZHANG C X, et al Multi-scale deformable CNN for answer selection
[J]. IEEE Access , 2019 , 7 : 164986 - 164995
DOI:10.1109/ACCESS.2019.2953219
[4]
WAKCHAURE M, KULKARNI P. A scheme of answer selection in community question answering using machine learning techniques [C]// 2019 International Conference on Intelligent Computing and Control Systems . Madurai: IEEE, 2019: 879-883.
[本文引用: 1]
[5]
MA W, LOU J, JI C, et al ACLSTM: a novel method for CQA answer quality prediction based on question-answer joint learning
[J]. Computers, Materials and Continua , 2021 , 66 (1 ): 179 - 193
[本文引用: 1]
[6]
石磊, 王毅, 成颖, 等 自然语言处理中的注意力机制研究综述
[J]. 数据分析与知识发现 , 2020 , 41 (5 ): 1 - 14
[本文引用: 1]
SHI Lei, WANG Yi, CHENG Ying, et al Review of attention mechanism in natural language processing
[J]. Data Analysis and Knowledge Discovery , 2020 , 41 (5 ): 1 - 14
[本文引用: 1]
[7]
YU A W, DOHAN D, LUONG M T, et al. QANet: combining local convolution with global self-attention for reading comprehension [EB/OL]. [2021-01-29]. https://arxiv.org/pdf/1804.09541.pdf.
[8]
CHEN X C, YANG Z Y, LIANG N Y, et al Co-attention fusion based deep neural network for Chinese medical answer selection
[J]. Applied Intelligence , 2021 , 51 : 6633 - 6646
DOI:10.1007/s10489-021-02212-w
[9]
TAY Y , TUAN L A , HUI S C . Multi-cast attention networks for retrieval-based question answering and response prediction [EB/OL]. [2022-01-07]. https://arxiv.org/pdf/1806.00778.pdf.
[10]
BAO G C, WEI Y, SUN X, et al Double attention recurrent convolution neural network for answer selection
[J]. Royal Society Open Science , 2020 , 7 : 191517
DOI:10.1098/rsos.191517
[11]
江龙泉. 基于Attentive LSTM网络模型的答案匹配技术的研究[D]. 上海: 上海师范大学, 2018.
[本文引用: 2]
JIANG Long-quan. Research on answer matching technology based on Attentive LSTM network model [D]. Shanghai: Shanghai Normal University, 2018.
[本文引用: 2]
[12]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL]. [2022-01-07]. https://arxiv.org/pdf/1706.03762.pdf.
[本文引用: 2]
[13]
YU A W, DOHAN D, LUONG M T, et al. QANet: combining local convolution with global self-attention for reading comprehension [EB/OL]. [2022-01-07]. https://arxiv.org/pdf/1804.09541.pdf.
[14]
SHAO T H, GUO Y P, CHEN H H, et al Transformer-based neural network for answer selection in question answering
[J]. IEEE Access , 2019 , 7 : 26146 - 26156
DOI:10.1109/ACCESS.2019.2900753
[本文引用: 1]
[15]
PETER M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics . [S.l.]: ACL, 2018: 2227–2237.
[本文引用: 1]
[16]
RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [R/OL]. [2022-01-07]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
[本文引用: 1]
[17]
DEBLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics . [S. l.]: ACL, 2019: 4171–4186.
[本文引用: 1]
[18]
BROMLEY J, BENTZ J W, BOTTOU L, et al Signature verification using a “Siamese” time delay neural network
[J]. International Journal of Pattern Recognition and Artificial Intelligence , 1993 , 7 (4 ): 669 - 688
DOI:10.1142/S0218001493000339
[本文引用: 1]
[21]
BIAN W J, LI S, YANG Z, et al. A compare-aggregate model with dynamic-clip attention for answer selection [C]// Proceedings of the 2017 ACM on Conference on Information and Knowledge Management . [S.l.]: ACM, 2017: 1987-1990.
[本文引用: 1]
[22]
YIN W P, SCHÜTZE H, XIANG B, et al ABCNN: attention-based convolutional neural network for modeling sentence pairs
[J]. Transactions of the Association for Computational Linguistics , 2016 , 4 : 259 - 272
DOI:10.1162/tacl_a_00097
[本文引用: 1]
[23]
LECUN Y, CHOPRA S, HADSELLl R, et al. A tutorial on energy-based learning [EB/OL]. [2022-01-07]. https://typeset.io/pdf/a-tutorial-on-energy-based-learning-2fj3lvviwy.pdf.
[本文引用: 1]
[24]
YANG Y, YIH W T, MEEK C. WikiQA: a challenge dataset for open-domain question answering [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing . [S. l.]: ACL, 2015: 2013-2018
[本文引用: 1]
[25]
WANG M Q, SMITH N A, MITAMURA T. What is the jeopardy model? A quasi-synchronous grammar for QA [C]// Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning . [S. l.]: ACL, 2007: 22-32.
[本文引用: 1]
[26]
FENG M W, XIANG B, GLASS M R, et al. Applying deep learning to answer selection: a study and an open task [EB/OL]. [2022-01-07]. https://arxiv.org/pdf/1508.01585.pdf.
[本文引用: 1]
[27]
PENNINGTON J, SOCHER R, MANNING C. GloVe: global vectors for word representation [C]// Proceeding of the 2014 Conference on Empirical Methods in Natural Language Processing . [S. l.]: ACL, 2014: 1532-1543.
[本文引用: 1]
[28]
CHEN Z W, HE Z, LIU X W, et al Evaluating semantic relations in neural word embeddings with biomedical and general domain knowledge bases
[J]. BMC Medical Informatics and Decision Making , 2018 , 18 (Suppl.2 ): 65
[本文引用: 1]
Chinese medical question answer selection via hybrid models based on CNN and GRU
1
2020
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
Multi-scale deformable CNN for answer selection
0
2019
一种用于答案选择的知识增强混合神经网络
1
2021
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
一种用于答案选择的知识增强混合神经网络
1
2021
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
1
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
ACLSTM: a novel method for CQA answer quality prediction based on question-answer joint learning
1
2021
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
自然语言处理中的注意力机制研究综述
1
2020
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
自然语言处理中的注意力机制研究综述
1
2020
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
Co-attention fusion based deep neural network for Chinese medical answer selection
0
2021
Double attention recurrent convolution neural network for answer selection
0
2020
2
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
... 目前大多数模型仅使用RNN或LSTM对文本进行编码,这种方式无法捕获答案与问题之间的相关语义信息. 受Yin等[22 ] 提出的ABCNN的启发,使用colume-wise CNN学习从答案到问题的交叉信息,使用row-wise CNN学习从问题到答案的交叉信息. 注意力机制可以在每个时间步中按顺序对单词或短语进行加权,通过这种机制,实现在序列的任何位置之间建立关系. 注意力机制的出现减小了处理高维输入数据的计算负担,通过结构化选取输入子集来降低数据维度,同时,让任务处理系统更专注于找到输入数据中与当前输出相关的有用信息,从而提高输出的质量[11 ] . 注意力机制的具体过程如下:1)通过tanh函数计算注意力权重的分布,2)通过softmax函数得到归一化的注意力权重,3)将编码层输出的句子向量与归一化后的权重进行逐位相乘,得到注意力后的输出,计算式为 ...
2
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
... 目前大多数模型仅使用RNN或LSTM对文本进行编码,这种方式无法捕获答案与问题之间的相关语义信息. 受Yin等[22 ] 提出的ABCNN的启发,使用colume-wise CNN学习从答案到问题的交叉信息,使用row-wise CNN学习从问题到答案的交叉信息. 注意力机制可以在每个时间步中按顺序对单词或短语进行加权,通过这种机制,实现在序列的任何位置之间建立关系. 注意力机制的出现减小了处理高维输入数据的计算负担,通过结构化选取输入子集来降低数据维度,同时,让任务处理系统更专注于找到输入数据中与当前输出相关的有用信息,从而提高输出的质量[11 ] . 注意力机制的具体过程如下:1)通过tanh函数计算注意力权重的分布,2)通过softmax函数得到归一化的注意力权重,3)将编码层输出的句子向量与归一化后的权重进行逐位相乘,得到注意力后的输出,计算式为 ...
2
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
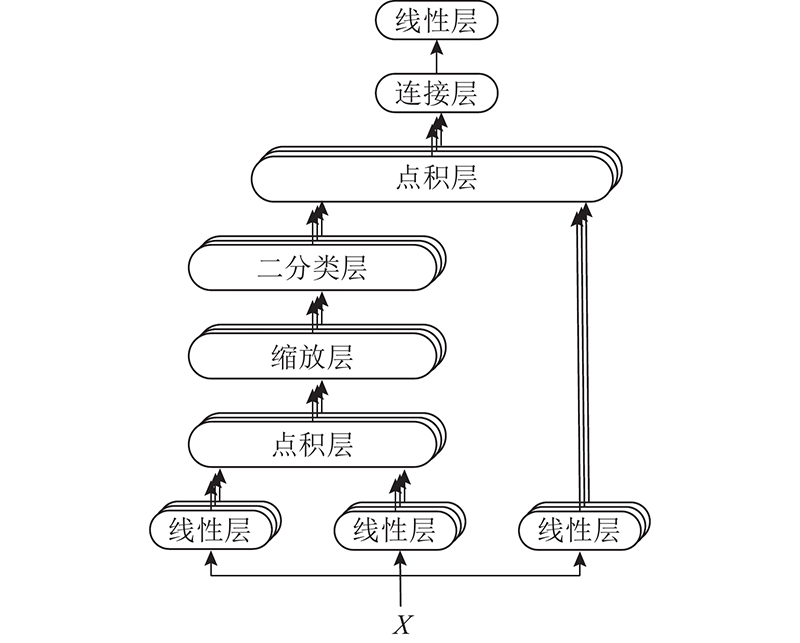
... 自注意力[12 ] 作为Transformer的核心模块,对提取文本自身的全局特征表现出较好的性能. 自注意力机制能带来性能提升的关键是,将其任意2个单词间的距离看作“1”,没有网络隐藏状态不同时间步输入的依赖关系,并行计算能力也将得到大大提升,这对解决自然语言处理(natural language processing,NLP)中常见的长期依赖问题非常有效. 通过计算每个询问词与句子中所有关键词的相关性和权重,得到序列中所有词的输出. 在自注意力层中,每个自注意力被切割成多个头部注意力,多头注意力结构如图3 所示. 通过多头注意力机制,让语句中每个词语在不同的特征表示空间中获取语句中所有词的信息,使DALSTM能够提取更细粒度的特征信息. ...
Transformer-based neural network for answer selection in question answering
1
2019
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
1
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
1
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
1
... 答案选择工作中的模型大多基于RNN和CNN. CNN擅长从短文本中提取局部特征,Zhang等[1 -3 ] 提出的基于CNN的模型已经被验证在处理答案选择问题时很有效. 虽然RNN能够比CNN更有效地提取语义信息,但存在梯度消失和梯度爆炸问题. Wakchaure等[4 ] 结合CNN和RNN的优势,提出基于LSTM的模型,缓解了RNN的梯度消失,解决了一般神经网络存在的长期依赖问题[5 ] . 上述神经网络模型主要通过优化策略,将句子编码为向量,可能会忽略部分问题和答案间的复杂语义关系. 虽然注意力机制[6 -11 ] 擅长捕获关联语义信息,但是通常难以获取全局特征,而Transformer模型[12 -14 ] 结合全连接和自注意力机制擅长提取全局特征,提取的语义信息更丰富. 随着Transformer模型的发展,ELMo[15 ] 、GPT[16 ] 、BERT[17 ] 等预训练模型逐渐被应用在自然语言处理任务中. 其中ELMo采用2个双向LSTM结构,GPT、BERT则采用Transformer的解码器结构,通过大量数据构造特征表示模型以及有监督的微调,得到的有效的学习上下文表示能够提升答案选择任务的准确性. 但是微调的预训练模型参数量大、占内存量大、训练成本高,抛弃RNN和CNN,将使模型丧失捕捉局部特征的能力. 以上文献分析表明,向量表示的有效性在问答任务中至关重要. 答案选择仍然存在以下2个问题:1)单纯获取浅层特征或深层特征不能有效表达句子信息;2)反复使用注意力机制,不仅时间成本高,还会影响局部特征提取,导致关键词相似但语义不匹配. 比如:当肯定答案与问题间相似词比否定答案与问题间相似词少时,否定答案更容易被注意力模型识别成正确答案. ...
Signature verification using a “Siamese” time delay neural network
1
1993
... 如图1 所示,基于LSTM与衰减自注意力的答案选择模型(answer selection model based on LSTM and decay self-attention,DALSTM)采用Siamese框架[18 ] ,由向量表示、特征提取、语义匹配和答案预测4个部分组成. DALSTM 1)使用词嵌入技术构建问答文本语料库的向量表示. 2)通过BiLSTM层和衰减自注意力层提取上下文语义特征,并通过计算文本序列中语义信息的注意力概率,使正确答案更加关注问题相关信息,忽略答案文本中与问题无关的信息,以保证最终特征向量表示的有效性. 3)采用余弦相似度衡量问题和答案间的语义匹配程度,采用softmax层预测候选答案正确与否. ...
Long short-term memory
1
1997
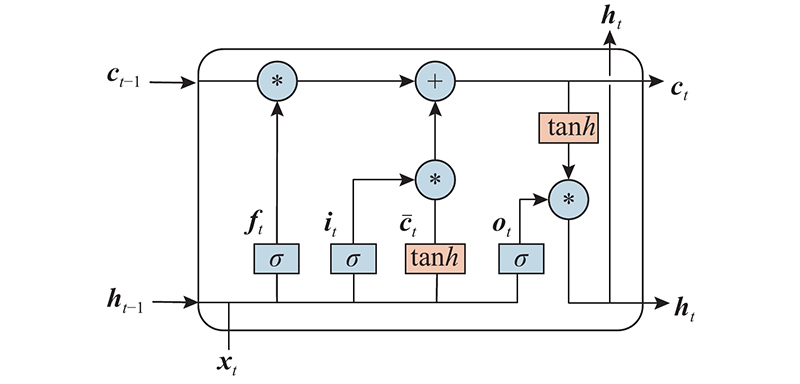
... LSTM由Hochreiter等[19 ] 提出. LSTM使用自适应门控机制,可以选择性通过sigmoid神经网络层,决定要遗忘和更新的信息. 本研究采用双向长短时记忆网络(Bi-directional LSTM, BiLSTM)对输入向量进行特征提取,通过正向和反向的处理,解决句子前后时序信息的问题,有助于模型对文本语义的理解[20 ] . BiLSTM由2层LSTM网络构成,第一层以句子的左边作为序列的起始输入,第二层以句子的右边作为序列的起始输入. 如图2 所示为LSTM网络的单元结构,该结构由3个门控单元组成,分别为遗忘门、输入门和输出门. ...
结合双层多头自注意力和BiLSTM-CRF的军事武器实体识别
1
2022
... LSTM由Hochreiter等[19 ] 提出. LSTM使用自适应门控机制,可以选择性通过sigmoid神经网络层,决定要遗忘和更新的信息. 本研究采用双向长短时记忆网络(Bi-directional LSTM, BiLSTM)对输入向量进行特征提取,通过正向和反向的处理,解决句子前后时序信息的问题,有助于模型对文本语义的理解[20 ] . BiLSTM由2层LSTM网络构成,第一层以句子的左边作为序列的起始输入,第二层以句子的右边作为序列的起始输入. 如图2 所示为LSTM网络的单元结构,该结构由3个门控单元组成,分别为遗忘门、输入门和输出门. ...
结合双层多头自注意力和BiLSTM-CRF的军事武器实体识别
1
2022
... LSTM由Hochreiter等[19 ] 提出. LSTM使用自适应门控机制,可以选择性通过sigmoid神经网络层,决定要遗忘和更新的信息. 本研究采用双向长短时记忆网络(Bi-directional LSTM, BiLSTM)对输入向量进行特征提取,通过正向和反向的处理,解决句子前后时序信息的问题,有助于模型对文本语义的理解[20 ] . BiLSTM由2层LSTM网络构成,第一层以句子的左边作为序列的起始输入,第二层以句子的右边作为序列的起始输入. 如图2 所示为LSTM网络的单元结构,该结构由3个门控单元组成,分别为遗忘门、输入门和输出门. ...
1
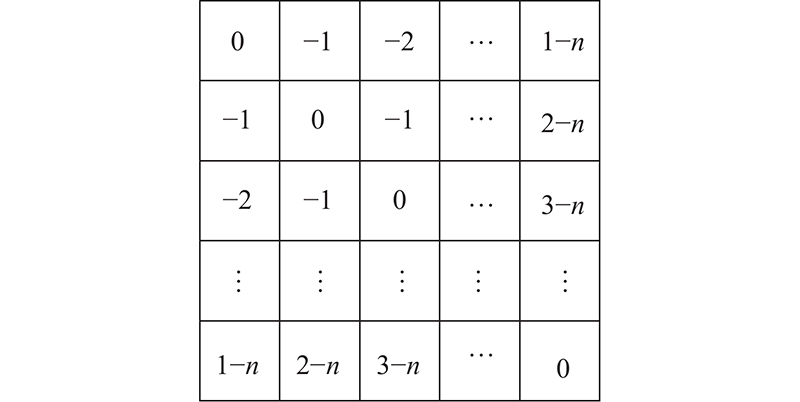
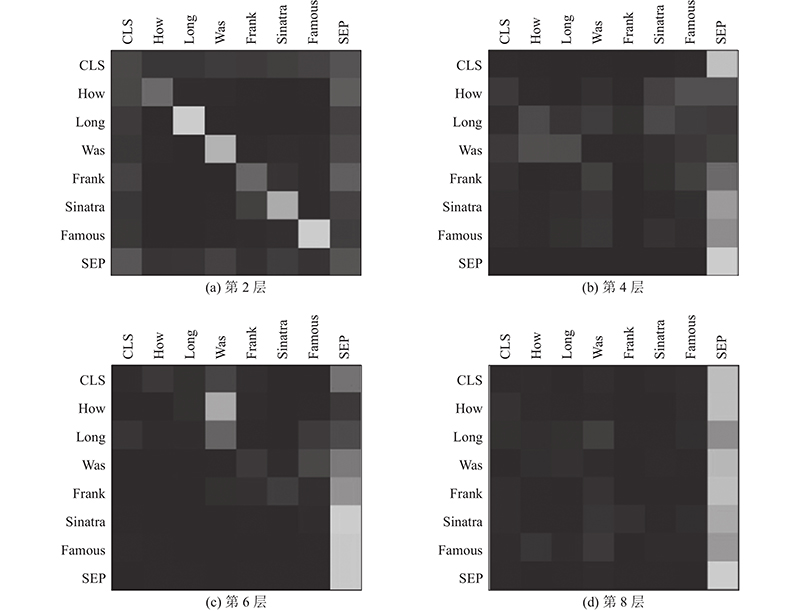
... 由于每次使用注意力机制都要学习每个单词的权重,关键词信息在最终表示中会占据过多的比例,使模型过于集中于关键词,降低全局语义表示的权重,造成关键词相似但语义不匹配的问题. 受到Bian等[21 ] 提出的动态裁剪注意力的启发,本研究设计衰减矩阵, 通过将注意力权值随着词与词之间的距离增加而衰减,使距离查询词位置越远的词分配越少的权重,以此使得模型更加关注周围词,解决反复使用注意力机制导致输出过于集中关键词的问题. ...
ABCNN: attention-based convolutional neural network for modeling sentence pairs
1
2016
... 目前大多数模型仅使用RNN或LSTM对文本进行编码,这种方式无法捕获答案与问题之间的相关语义信息. 受Yin等[22 ] 提出的ABCNN的启发,使用colume-wise CNN学习从答案到问题的交叉信息,使用row-wise CNN学习从问题到答案的交叉信息. 注意力机制可以在每个时间步中按顺序对单词或短语进行加权,通过这种机制,实现在序列的任何位置之间建立关系. 注意力机制的出现减小了处理高维输入数据的计算负担,通过结构化选取输入子集来降低数据维度,同时,让任务处理系统更专注于找到输入数据中与当前输出相关的有用信息,从而提高输出的质量[11 ] . 注意力机制的具体过程如下:1)通过tanh函数计算注意力权重的分布,2)通过softmax函数得到归一化的注意力权重,3)将编码层输出的句子向量与归一化后的权重进行逐位相乘,得到注意力后的输出,计算式为 ...
1
... 式中:v q 、v a 分别为问题和候选答案的特征向量,v qi 、v ai 分别为问题和候选答案的各分量. 使用最大边距Hinge损失[23 ] 作为DALSTM的损失函数,对于给定候选答案,用 $ {a}^{+} $ $ {a}^{-} $
1
... 为了验证本研究提出的模型,采用3个常用的问答数据集进行实验研究,3个数据集的详细统计信息如表1 所示. 表中,N 为问题数,NA为平均候选答案数,LA为平均答案长度. 1) WiKiQA[24 ] 来自维基百科文章,对数据集进行预处理,删除不包含基本事实的数据,删除没有正确答案的问题,只采用有正确答案的问题进行评估. 2) TrecQA[25 ] 来自文本检索会议,包含2个训练集,即Train和Train-all. Train中每个正确答案都经过人工标注,Train-all中通过正则表达式标识正确答案. Train-all中的噪声大,因此本研究选择Train进行实验. 3)InsuranceQA[26 ] 来自保险库网站,对语料做了分词和去标、去停、添加标签的操作. 部分否定答案是根据问题使用检索的方式建立的,它们可能和问题相关但并非正确答案,本研究用此数据集来验证衰减自注意力机制的作用. ...
1
... 为了验证本研究提出的模型,采用3个常用的问答数据集进行实验研究,3个数据集的详细统计信息如表1 所示. 表中,N 为问题数,NA为平均候选答案数,LA为平均答案长度. 1) WiKiQA[24 ] 来自维基百科文章,对数据集进行预处理,删除不包含基本事实的数据,删除没有正确答案的问题,只采用有正确答案的问题进行评估. 2) TrecQA[25 ] 来自文本检索会议,包含2个训练集,即Train和Train-all. Train中每个正确答案都经过人工标注,Train-all中通过正则表达式标识正确答案. Train-all中的噪声大,因此本研究选择Train进行实验. 3)InsuranceQA[26 ] 来自保险库网站,对语料做了分词和去标、去停、添加标签的操作. 部分否定答案是根据问题使用检索的方式建立的,它们可能和问题相关但并非正确答案,本研究用此数据集来验证衰减自注意力机制的作用. ...
1
... 为了验证本研究提出的模型,采用3个常用的问答数据集进行实验研究,3个数据集的详细统计信息如表1 所示. 表中,N 为问题数,NA为平均候选答案数,LA为平均答案长度. 1) WiKiQA[24 ] 来自维基百科文章,对数据集进行预处理,删除不包含基本事实的数据,删除没有正确答案的问题,只采用有正确答案的问题进行评估. 2) TrecQA[25 ] 来自文本检索会议,包含2个训练集,即Train和Train-all. Train中每个正确答案都经过人工标注,Train-all中通过正则表达式标识正确答案. Train-all中的噪声大,因此本研究选择Train进行实验. 3)InsuranceQA[26 ] 来自保险库网站,对语料做了分词和去标、去停、添加标签的操作. 部分否定答案是根据问题使用检索的方式建立的,它们可能和问题相关但并非正确答案,本研究用此数据集来验证衰减自注意力机制的作用. ...
1
... 实验在WiKiQA和TrecQA数据集上使用300维Glove[27 ] 词向量,在InsuranceQA数据集上使用100维word2vec[28 ] 词向量. 在语义特征提取层中,BiLSTM的隐藏层将隐藏维度设置为128;衰减自注意力的层数为6,头部数量为6. 使用随机梯度下降(SGD)算法作为模型参数优化器,动量参数为0.9;训练周期(epoch)均为50次,批大小均设置为32;初始学习率为0.001,学习率调整采用等间隔更新策略,每训练5个epoch更新一次,通过学习率的动态调整,使得模型训练的参数更加稳定. 对于Hinge损失函数中的参数m ,根据肯定答案和否定答案的相似度确定,越相似边际m 越小,因此对WiKiQA、TrecQA、InsuranceQA分别将m 设置为0.15、0.10、0.05. ...
Evaluating semantic relations in neural word embeddings with biomedical and general domain knowledge bases
1
2018
... 实验在WiKiQA和TrecQA数据集上使用300维Glove[27 ] 词向量,在InsuranceQA数据集上使用100维word2vec[28 ] 词向量. 在语义特征提取层中,BiLSTM的隐藏层将隐藏维度设置为128;衰减自注意力的层数为6,头部数量为6. 使用随机梯度下降(SGD)算法作为模型参数优化器,动量参数为0.9;训练周期(epoch)均为50次,批大小均设置为32;初始学习率为0.001,学习率调整采用等间隔更新策略,每训练5个epoch更新一次,通过学习率的动态调整,使得模型训练的参数更加稳定. 对于Hinge损失函数中的参数m ,根据肯定答案和否定答案的相似度确定,越相似边际m 越小,因此对WiKiQA、TrecQA、InsuranceQA分别将m 设置为0.15、0.10、0.05. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}