[1]
SECURESOFTWARE. Rough auditing tool for security(rats)[EB/OL]. [2021-12-23]. http://www.securesoftware.com/resources/download_rats.html.
[本文引用: 1]
[2]
WHEELER D A. Flawfinder software official website[EB/OL]. [2018-08-02]. https://www.dwheeler.com/flawfinder/.
[本文引用: 1]
[3]
JANG J, AGRAWAL A, BRUMLEY D. Redebug: finding unpatched code clones in entire os distributions[C]// IEEE Symposium on Security and Privacy . California: IEEE Computer Society, 2012: 48-62.
[本文引用: 1]
[4]
KIM S, WOO S, LEE H, et al. Vuddy: a scalable approach for vulnerable code clone discovery[C]// IEEE Symposium on Security and Privacy (SP) . San Jose: IEEE Computer Society, 2017: 595-614.
[本文引用: 1]
[5]
AVGERINOS T, CHA S K, REBERT A, et al Automatic exploit generation
[J]. Communications of the ACM , 2014 , 57 (2 ): 74 - 84
DOI:10.1145/2560217.2560219
[本文引用: 1]
[6]
RAMOS D A, ENGLER D. Under-constrained symbolic execution: correctness checking for real code[C]// Proceedings of the 24th USENIX Security Symposium (USENIX Security 15) . Washington: USENIX Association, 2015: 49-64.
[本文引用: 1]
[7]
NEUHAUS S, ZIMMERMANN T, HOLLER C, et al. Predicting vulnerable software components[C]// Proceedings of the 14th ACM Conference on Computer and Communications Security . Alexandria: ACM, 2007: 529-540.
[本文引用: 1]
[8]
SHIN Y, WILLIAMS L. An empirical model to predict security vulnerabilities using code complexity metrics[C]// Proceedings of the 2nd ACM-IEEE International Symposium on Empirical Software Engineering and Measurement . Kaiserslautern: ACM, 2008: 315-317.
[本文引用: 1]
[9]
SHIN Y, WILLIAMS L Can traditional fault prediction models be used for vulnerability prediction?
[J]. Empirical Software Engineering , 2013 , 18 (1 ): 25 - 59
DOI:10.1007/s10664-011-9190-8
[本文引用: 1]
[10]
PERL H, DECHAND S, SMITH M, et al. Vccfinder: finding potential vulnerabilities in open-source projects to assist code audits[C]// Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security . Denver: ACM, 2015: 426-437.
[本文引用: 1]
[11]
SHIN Y, MENEELY A, WILLIAMS L, et al Evaluating complexity, code churn and developer activity metrics as indicators of software vulnerabilities
[J]. IEEE Transactions on Software Engineering , 2010 , 37 (6 ): 772 - 787
[本文引用: 1]
[12]
GHAFFARIAN S M, SHAHRIARI H R Software vulnerability analysis and discovery using machine-learning and data-mining techniques: a survey
[J]. ACM Computing Surveys (CSUR) , 2017 , 50 (4 ): 1 - 36
[本文引用: 1]
[13]
LIU L, DE VEL O, HAN Q-L, et al Detecting and preventing cyber insider threats: a survey
[J]. IEEE Communications Surveys and Tutorials , 2018 , 20 (2 ): 1397 - 1417
DOI:10.1109/COMST.2018.2800740
[14]
SUN N, ZHANG J, RIMBA P, et al Data-driven cybersecurity incident prediction: a survey
[J]. IEEE Communications Surveys and Tutorials , 2018 , 21 (2 ): 1744 - 1772
[本文引用: 1]
[15]
JIANG J, WEN S, YU S, et al Identifying propagation sources in networks: state-of-the-art and comparative studies
[J]. IEEE Communications Surveys and Tutorials , 2016 , 19 (1 ): 465 - 481
[本文引用: 1]
[16]
WU T, WEN S, XIANG Y, et al Twitter spam detection: survey of new approaches and comparative study
[J]. Computers and Security , 2018 , 76 : 265 - 284
DOI:10.1016/j.cose.2017.11.013
[本文引用: 1]
[17]
GOODFELLOW I, BENGIO Y, COURVILLE A. Deep learning [M]. Cambridge, Massachusetts, USA: MIT press, 2016.
[本文引用: 1]
[18]
SESTILI C D, SNAVELY W S, VANHOUDNOS N M. Towards security defect prediction with AI [EB/OL]. [2018-08-29]. https://doi.org/10.48550/arXiv.1808.09897.
[本文引用: 1]
[19]
LI Z, ZOU D, XU S, et al Sysevr: a framework for using deep learning to detect software vulnerabilities
[J]. IEEE Transactions on Dependable and Secure Computing , 2021 , 19 (4 ): 2244 - 2258
[本文引用: 2]
[20]
DAM H K, TRAN T, PHAM T, et al. Automatic feature learning for vulnerability prediction [EB/OL]. [2017-08-08]. https://doi.org/10.48550/arXiv.1708.02368.
[本文引用: 2]
[21]
LIN G, XIAO W, ZHANG J, et al. Deep learning-based vulnerable function detection: A benchmark[C]// International Conference on Information and Communications Security . Beijing: Springer, 2019: 219-232.
[本文引用: 13]
[22]
LI Z, ZOU D, XU S, et al. Vuldeepecker: a deep learning-based system for vulnerability detection [EB/OL]. [2018-01-05]. https://doi.org/10.48550/arXiv.1801.01681.
[本文引用: 2]
[23]
LIN G, ZHANG J, LUO W, et al Cross-project transfer representation learning for vulnerable function discovery
[J]. IEEE Transactions on Industrial Informatics , 2018 , 14 (7 ): 3289 - 3297
DOI:10.1109/TII.2018.2821768
[本文引用: 1]
[24]
段旭, 吴敬征, 罗天悦, 等 基于代码属性图及注意力双向 LSTM 的漏洞挖掘方法
[J]. 软件学报 , 2020 , 31 (11 ): 3404 - 3420
[本文引用: 2]
DUAN Xu, WU Jing-zheng, LUO Tian-yue, et al Vulnerability mining method based on code property graph and attention BiLSTM
[J]. Journal of Software , 2020 , 31 (11 ): 3404 - 3420
[本文引用: 2]
[25]
PENG H, MOU L, LI G, et al. Building program vector representations for deep learning [C]// International Conference on Knowledge Science, Engineering and Management . Chongqing: Springer, 2015: 547-553.
[本文引用: 1]
[26]
LEE Y J, CHOI S H, KIM C, et al. Learning binary code with deep learning to detect software weakness[C]// KSII the 9th International Conference on Internet (ICONI). Vientiane: Symposium, 2017: 245-249.
[本文引用: 1]
[27]
RUSSELL R, KIM L, HAMILTON L, et al. Automated vulnerability detection in source code using deep representation learning [C]// 17th IEEE International Conference on Machine Learning and Applications (ICMLA) . Orlando: Institute of Electrical and Electronics Engineers, 2018: 757-762.
[本文引用: 1]
[28]
AL-ALYAN A, AL-AHMADI S Robust URL phishing detection based on deep learning
[J]. KSII Transactions on Internet and Information Systems (TIIS) , 2020 , 14 (7 ): 2752 - 2768
[本文引用: 1]
[29]
YAMAGUCHI F, LOTTMANN M, RIECK K. Generalized vulnerability extrapolation using abstract syntax trees[C]// Proceedings of the 28th Annual Computer Security Applications Conference . Orlando: ACM, 2012: 359-368.
[本文引用: 1]
[30]
SUNEJA S, ZHENG Y, ZHUANG Y, et al. Learning to map source code to software vulnerability using code-as-a-graph [EB/OL]. [2020-06-15]. https://arxiv.org/abs/2006.08614.
[本文引用: 1]
[31]
YAMAGUCHI F, GOLDE N, ARP D, et al. Modeling and discovering vulnerabilities with code property graphs[C]// IEEE Symposium on Security and Privacy . Berkeley: IEEE Computer Society, 2014: 590-604.
[本文引用: 4]
[32]
ZHOU Y, LIU S, SIOW J, et al. Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks [C]// Proceedings of the 33rd Conference on Neural Information Processing Systems. Vancouver: NIPS Foundation, 2019: 10197-10207.
[本文引用: 4]
[33]
CAO S, SUN X, BO L, et al Bgnn4vd: constructing bidirectional graph neural-network for vulnerability detection
[J]. Information and Software Technology , 2021 , 136 : 106576
DOI:10.1016/j.infsof.2021.106576
[本文引用: 1]
[34]
CHAWLA N V, BOWYER K W, HALL L O, et al Smote: synthetic minority over-sampling technique
[J]. Journal of Artificial Intelligence Research , 2002 , 16 : 321 - 357
DOI:10.1613/jair.953
[本文引用: 1]
[35]
AGRAWAL A, MENZIES T. Is" better data" better than" better data miners"? [C]// IEEE/ACM 40th International Conference on Software Engineering. Gothenburg: ACM, 2018: 1050-1061.
[本文引用: 1]
[36]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st Conference on Neural Information Processing Systems (NISP). Long Beach: NIPS Foundation, 2017: 5998-6008.
[本文引用: 1]
1
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
1
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
1
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
1
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
Automatic exploit generation
1
2014
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
1
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
1
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
1
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
Can traditional fault prediction models be used for vulnerability prediction?
1
2013
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
1
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
Evaluating complexity, code churn and developer activity metrics as indicators of software vulnerabilities
1
2010
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
Software vulnerability analysis and discovery using machine-learning and data-mining techniques: a survey
1
2017
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
Detecting and preventing cyber insider threats: a survey
0
2018
Data-driven cybersecurity incident prediction: a survey
1
2018
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
Identifying propagation sources in networks: state-of-the-art and comparative studies
1
2016
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
Twitter spam detection: survey of new approaches and comparative study
1
2018
... 随着信息技术的飞速发展,计算机软件广泛应用于各行各业,使生活更加高效和便利. 然而,软件中潜在的漏洞对计算机安全构成了巨大威胁. 软件漏洞一旦被黑客利用来攻击软件系统,会造成严重的经济损失. 截止目前,公共漏洞和暴露数据(common vulnerabilities and exposures, CVE)中已存在165 238个条目. 近年来,软件漏洞数量增长迅速,如何准确地检测出软件中的潜在漏洞是一项十分重要且具有研究意义的课题. 漏洞检测方法主要分为静态、动态和混合3大类,其中静态方法占据主流. 静态方法主要通过分析软件源码进行代码漏洞检测. 传统的静态方法主要包含:基于规则/模板的分析方法[1 -2 ] 、代码相似性检测[3 -4 ] 以及符号执行[5 -6 ] 等,这类方法易存在较高的误报率. 相比传统方法,机器学习方法主要使用基于源码的特征如函数调用[7 ] 、软件复杂性度量[8 -9 ] 、代码改动和提交[10 -11 ] 等对软件漏洞进行检测,从而能够更加自动且高效地挖掘出软件中的漏洞[12 -14 ] . 机器学习方法仍需要专家来手动定义特征,因此特征的有效性主要取决于专家的经验和专业水平[15 -16 ] . 这导致特征工程十分耗时且容易出错,而产生的手工特征也只能应用于特定的任务,缺乏一定的泛化性. ...
1
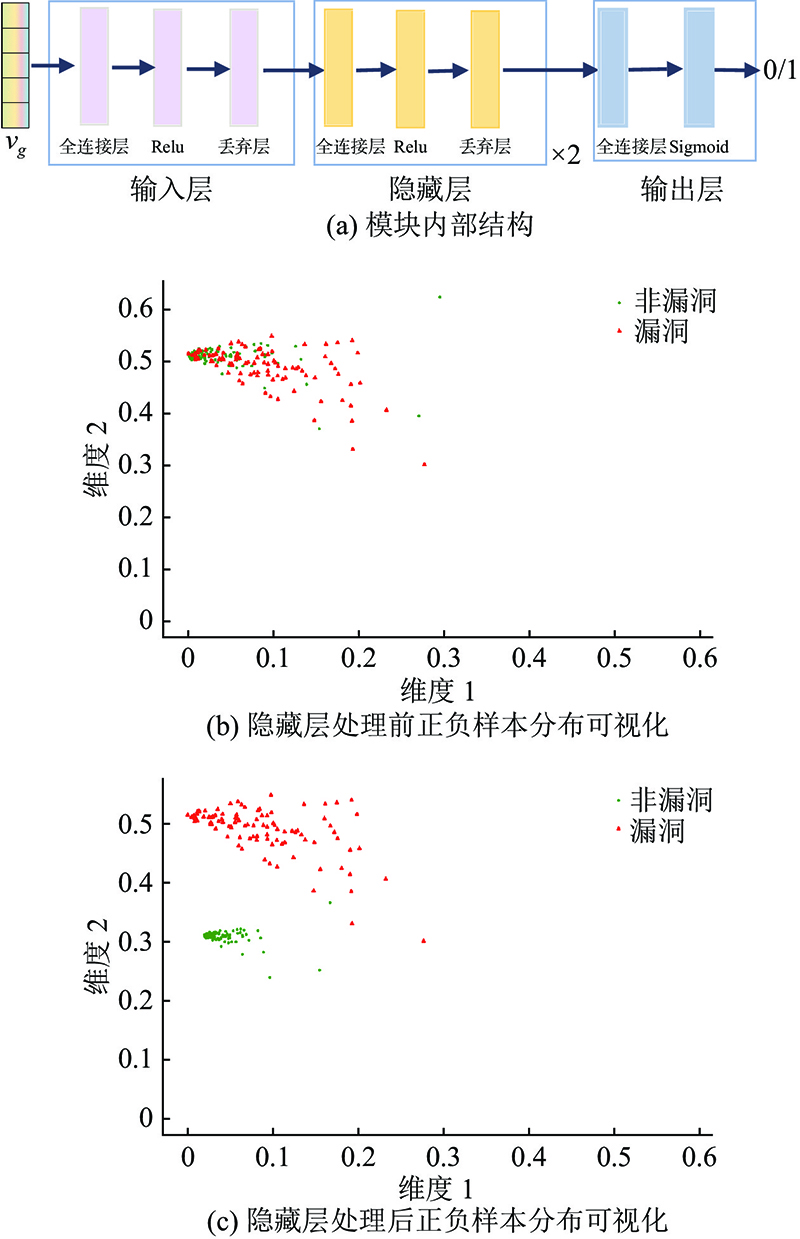
... 现如今,软件规模越来越庞大,内部代码越来越复杂,漏洞种类也越来越多样化. 深度神经网络因面对海量输入数据时具有自动提取特征的能力,被认为能够有效应对漏洞的多样性. 一方面,深度神经网络能够学习深度非线性编程模式,捕捉复杂代码的内在结构. 另一方面,深度神经网络能够理解代码上下文相关性并对特征进行多层概括和抽象,自动学习更高级的特征,从大量样本中发现和学习代码漏洞的潜在规律[17 -18 ] ,自动检测代码中类似的漏洞. 在实际应用中代码漏洞的编程模式可以与多个代码行相关联. 例如缓冲区溢出等类别的漏洞,通常与多个连续或间隔的代码行及其上下文相关. 而现有的深度学习方法大多基于递归神经网络(recurrent neural network, RNN)[19 ] 及变体如长短期记忆网络(long short-term memory, LSTM)[20 -21 ] 、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[22 -24 ] 等. 由于RNN自身结构的限制,模型只能按照关键词输入的顺序对代码关键词序列进行逐词处理,在特征提取过程中存在部分信息丢失,导致模型难以捕捉到多行代码的长距离依赖关系. 虽然LSTM等变体能够在一定程度上扩大模型捕捉依赖的范围,但是问题的本质仍与模型递归的结构有关,这些变体并不能真正有效解决长距离依赖丢失的问题. 真实数据集中漏洞样本与非漏洞样本差异较小,在特征空间中存在较大程度的重叠,正负样本间缺少明显的界限,模型很难正确地进行区分. 真实数据集中非漏洞样本与漏洞样本比例大于40∶1,存在严重的样本不平衡问题,使得训练后的模型更倾向于样本多的无漏洞类别. 上述问题共同导致了现有方法误报率和漏报率较高,漏洞检测效果不佳. ...
1
... 现如今,软件规模越来越庞大,内部代码越来越复杂,漏洞种类也越来越多样化. 深度神经网络因面对海量输入数据时具有自动提取特征的能力,被认为能够有效应对漏洞的多样性. 一方面,深度神经网络能够学习深度非线性编程模式,捕捉复杂代码的内在结构. 另一方面,深度神经网络能够理解代码上下文相关性并对特征进行多层概括和抽象,自动学习更高级的特征,从大量样本中发现和学习代码漏洞的潜在规律[17 -18 ] ,自动检测代码中类似的漏洞. 在实际应用中代码漏洞的编程模式可以与多个代码行相关联. 例如缓冲区溢出等类别的漏洞,通常与多个连续或间隔的代码行及其上下文相关. 而现有的深度学习方法大多基于递归神经网络(recurrent neural network, RNN)[19 ] 及变体如长短期记忆网络(long short-term memory, LSTM)[20 -21 ] 、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[22 -24 ] 等. 由于RNN自身结构的限制,模型只能按照关键词输入的顺序对代码关键词序列进行逐词处理,在特征提取过程中存在部分信息丢失,导致模型难以捕捉到多行代码的长距离依赖关系. 虽然LSTM等变体能够在一定程度上扩大模型捕捉依赖的范围,但是问题的本质仍与模型递归的结构有关,这些变体并不能真正有效解决长距离依赖丢失的问题. 真实数据集中漏洞样本与非漏洞样本差异较小,在特征空间中存在较大程度的重叠,正负样本间缺少明显的界限,模型很难正确地进行区分. 真实数据集中非漏洞样本与漏洞样本比例大于40∶1,存在严重的样本不平衡问题,使得训练后的模型更倾向于样本多的无漏洞类别. 上述问题共同导致了现有方法误报率和漏报率较高,漏洞检测效果不佳. ...
Sysevr: a framework for using deep learning to detect software vulnerabilities
2
2021
... 现如今,软件规模越来越庞大,内部代码越来越复杂,漏洞种类也越来越多样化. 深度神经网络因面对海量输入数据时具有自动提取特征的能力,被认为能够有效应对漏洞的多样性. 一方面,深度神经网络能够学习深度非线性编程模式,捕捉复杂代码的内在结构. 另一方面,深度神经网络能够理解代码上下文相关性并对特征进行多层概括和抽象,自动学习更高级的特征,从大量样本中发现和学习代码漏洞的潜在规律[17 -18 ] ,自动检测代码中类似的漏洞. 在实际应用中代码漏洞的编程模式可以与多个代码行相关联. 例如缓冲区溢出等类别的漏洞,通常与多个连续或间隔的代码行及其上下文相关. 而现有的深度学习方法大多基于递归神经网络(recurrent neural network, RNN)[19 ] 及变体如长短期记忆网络(long short-term memory, LSTM)[20 -21 ] 、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[22 -24 ] 等. 由于RNN自身结构的限制,模型只能按照关键词输入的顺序对代码关键词序列进行逐词处理,在特征提取过程中存在部分信息丢失,导致模型难以捕捉到多行代码的长距离依赖关系. 虽然LSTM等变体能够在一定程度上扩大模型捕捉依赖的范围,但是问题的本质仍与模型递归的结构有关,这些变体并不能真正有效解决长距离依赖丢失的问题. 真实数据集中漏洞样本与非漏洞样本差异较小,在特征空间中存在较大程度的重叠,正负样本间缺少明显的界限,模型很难正确地进行区分. 真实数据集中非漏洞样本与漏洞样本比例大于40∶1,存在严重的样本不平衡问题,使得训练后的模型更倾向于样本多的无漏洞类别. 上述问题共同导致了现有方法误报率和漏报率较高,漏洞检测效果不佳. ...
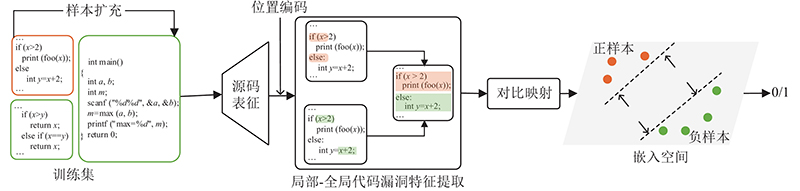
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
2
... 现如今,软件规模越来越庞大,内部代码越来越复杂,漏洞种类也越来越多样化. 深度神经网络因面对海量输入数据时具有自动提取特征的能力,被认为能够有效应对漏洞的多样性. 一方面,深度神经网络能够学习深度非线性编程模式,捕捉复杂代码的内在结构. 另一方面,深度神经网络能够理解代码上下文相关性并对特征进行多层概括和抽象,自动学习更高级的特征,从大量样本中发现和学习代码漏洞的潜在规律[17 -18 ] ,自动检测代码中类似的漏洞. 在实际应用中代码漏洞的编程模式可以与多个代码行相关联. 例如缓冲区溢出等类别的漏洞,通常与多个连续或间隔的代码行及其上下文相关. 而现有的深度学习方法大多基于递归神经网络(recurrent neural network, RNN)[19 ] 及变体如长短期记忆网络(long short-term memory, LSTM)[20 -21 ] 、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[22 -24 ] 等. 由于RNN自身结构的限制,模型只能按照关键词输入的顺序对代码关键词序列进行逐词处理,在特征提取过程中存在部分信息丢失,导致模型难以捕捉到多行代码的长距离依赖关系. 虽然LSTM等变体能够在一定程度上扩大模型捕捉依赖的范围,但是问题的本质仍与模型递归的结构有关,这些变体并不能真正有效解决长距离依赖丢失的问题. 真实数据集中漏洞样本与非漏洞样本差异较小,在特征空间中存在较大程度的重叠,正负样本间缺少明显的界限,模型很难正确地进行区分. 真实数据集中非漏洞样本与漏洞样本比例大于40∶1,存在严重的样本不平衡问题,使得训练后的模型更倾向于样本多的无漏洞类别. 上述问题共同导致了现有方法误报率和漏报率较高,漏洞检测效果不佳. ...
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
13
... 现如今,软件规模越来越庞大,内部代码越来越复杂,漏洞种类也越来越多样化. 深度神经网络因面对海量输入数据时具有自动提取特征的能力,被认为能够有效应对漏洞的多样性. 一方面,深度神经网络能够学习深度非线性编程模式,捕捉复杂代码的内在结构. 另一方面,深度神经网络能够理解代码上下文相关性并对特征进行多层概括和抽象,自动学习更高级的特征,从大量样本中发现和学习代码漏洞的潜在规律[17 -18 ] ,自动检测代码中类似的漏洞. 在实际应用中代码漏洞的编程模式可以与多个代码行相关联. 例如缓冲区溢出等类别的漏洞,通常与多个连续或间隔的代码行及其上下文相关. 而现有的深度学习方法大多基于递归神经网络(recurrent neural network, RNN)[19 ] 及变体如长短期记忆网络(long short-term memory, LSTM)[20 -21 ] 、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[22 -24 ] 等. 由于RNN自身结构的限制,模型只能按照关键词输入的顺序对代码关键词序列进行逐词处理,在特征提取过程中存在部分信息丢失,导致模型难以捕捉到多行代码的长距离依赖关系. 虽然LSTM等变体能够在一定程度上扩大模型捕捉依赖的范围,但是问题的本质仍与模型递归的结构有关,这些变体并不能真正有效解决长距离依赖丢失的问题. 真实数据集中漏洞样本与非漏洞样本差异较小,在特征空间中存在较大程度的重叠,正负样本间缺少明显的界限,模型很难正确地进行区分. 真实数据集中非漏洞样本与漏洞样本比例大于40∶1,存在严重的样本不平衡问题,使得训练后的模型更倾向于样本多的无漏洞类别. 上述问题共同导致了现有方法误报率和漏报率较高,漏洞检测效果不佳. ...
... 针对现有方法存在的上述问题,提出基于上下文特征融合的代码漏洞检测方法,对软件源码以函数为单位进行漏洞检测. 主要贡献如下:1)提出从局部到全局的代码漏洞特征提取方法,提升模型的长距离特征学习能力,使得模型能够更好的理解代码语义信息,更加精确地挖掘出代码漏洞的编程模式. 2)提出代码漏洞对比映射模块,将高度重叠的漏洞样本与非漏洞样本映射到嵌入空间中,并利用距离损失对模型进行约束,使得训练后的模型尽可能拉大漏洞样本与非漏洞样本在嵌入空间中的距离,从而更好地对正负样本进行区分. 3)与基线方法[21 ] 中漏洞检测效果最佳的模型相比,本研究在9个软件源代码混合的真实数据集上取得了更好的漏洞检测效果,其中精确率最大提升了29%,召回率最大提升了16%. ...
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
... 1)数据集 实验在Lin等[21 ] 构建的漏洞数据集上进行,漏洞数据集包含9个用C语言编写的开源软件项目. Lin等[21 ] 将这些项目按函数和文件2种粒度进行切分,并根据美国国家漏洞数据库和公共漏洞数据库网站的数据对切分好的函数和文件进行标记. 当代码漏洞存在于一个函数内部时,将该函数标记为漏洞函数,并将包含该函数的文件标记为漏洞文件. 当代码漏洞跨越多个函数时则仅将该漏洞所在文件标记为漏洞文件. 函数级别的语义可以提供范围较小的细粒度的上下文语义信息,而文件级别的语义提供的是范围较大的相对粗粒度的上下文语义信息. 基于函数级别的漏洞样本可以在函数级别上构建漏洞检测模型,从而实现比文件级别更细粒度的漏洞检测能力,本研究选择使用函数级别的样本对模型进行训练. 在数据集中所有漏洞函数的文件名中都包含对应漏洞的CVE编号,即所有文件名中含有“CVE”字符串的函数标记为漏洞函数,其余函数则全部标记为非漏洞函数,所有的函数文件如表1 所示,N vul 为漏洞函数数量,N non 为非漏洞函数数量. 数据集包含59 297个非漏洞函数,1 471个漏洞函数. 在实验时将整个数据集按照6∶2∶2的比例随机划分为训练集、验证集和测试集. 由于静态分析工具Joern无法对其中的11个函数文件进行正确解析,导致实际可用的函数数量略微少于原数据集中的函数数量. 为了与基线方法[21 ] 进行比较,实验使用的训练集和测试集的函数数量保持一致,验证集中的漏洞函数减少了5个,非漏洞函数减少了6个. 训练集、测试集和验证集中的函数数量如表2 所示,表中训练集正负样本比例为883∶35 575,经过样本平衡后正负样本比例由883∶35 575变为1∶1,验证集和测试集与基线方法[21 ] 保持一致,不进行样本平衡操作. ...
... [21 ]将这些项目按函数和文件2种粒度进行切分,并根据美国国家漏洞数据库和公共漏洞数据库网站的数据对切分好的函数和文件进行标记. 当代码漏洞存在于一个函数内部时,将该函数标记为漏洞函数,并将包含该函数的文件标记为漏洞文件. 当代码漏洞跨越多个函数时则仅将该漏洞所在文件标记为漏洞文件. 函数级别的语义可以提供范围较小的细粒度的上下文语义信息,而文件级别的语义提供的是范围较大的相对粗粒度的上下文语义信息. 基于函数级别的漏洞样本可以在函数级别上构建漏洞检测模型,从而实现比文件级别更细粒度的漏洞检测能力,本研究选择使用函数级别的样本对模型进行训练. 在数据集中所有漏洞函数的文件名中都包含对应漏洞的CVE编号,即所有文件名中含有“CVE”字符串的函数标记为漏洞函数,其余函数则全部标记为非漏洞函数,所有的函数文件如表1 所示,N vul 为漏洞函数数量,N non 为非漏洞函数数量. 数据集包含59 297个非漏洞函数,1 471个漏洞函数. 在实验时将整个数据集按照6∶2∶2的比例随机划分为训练集、验证集和测试集. 由于静态分析工具Joern无法对其中的11个函数文件进行正确解析,导致实际可用的函数数量略微少于原数据集中的函数数量. 为了与基线方法[21 ] 进行比较,实验使用的训练集和测试集的函数数量保持一致,验证集中的漏洞函数减少了5个,非漏洞函数减少了6个. 训练集、测试集和验证集中的函数数量如表2 所示,表中训练集正负样本比例为883∶35 575,经过样本平衡后正负样本比例由883∶35 575变为1∶1,验证集和测试集与基线方法[21 ] 保持一致,不进行样本平衡操作. ...
... [21 ]进行比较,实验使用的训练集和测试集的函数数量保持一致,验证集中的漏洞函数减少了5个,非漏洞函数减少了6个. 训练集、测试集和验证集中的函数数量如表2 所示,表中训练集正负样本比例为883∶35 575,经过样本平衡后正负样本比例由883∶35 575变为1∶1,验证集和测试集与基线方法[21 ] 保持一致,不进行样本平衡操作. ...
... [21 ]保持一致,不进行样本平衡操作. ...
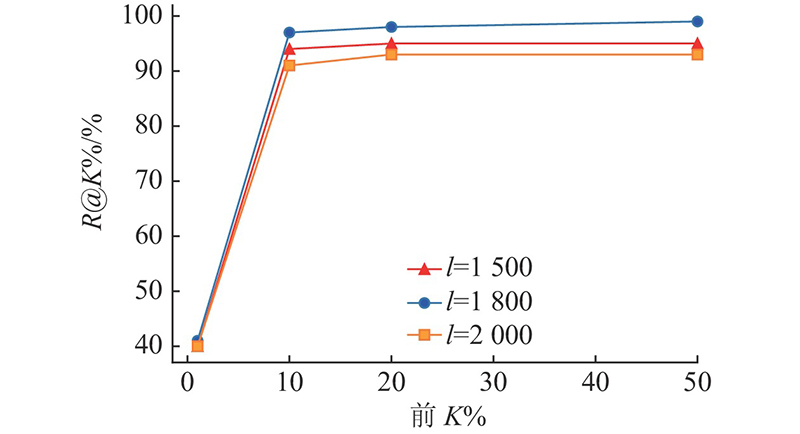
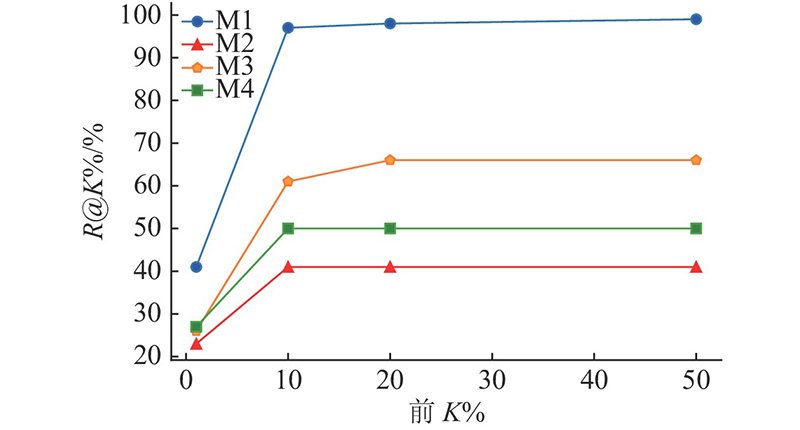
... 使用Lin等[21 ] 提出的漏洞数据集进行实验,并选取同样基于该数据集的Bi-LSTM、Text-CNN、DNN等模型作为基线进行对比实验,实验结果如表5 所示. 从表5 中可以看出:与其他模型相比,提出的模型在测试集上的P @1%、P @10%、P @50%均高于其他3种模型,P @20%与Text-CNN相等,相比Bi-LSTM和DNN提升了1%. 在top 1%中,精确率相较表现最好的模型Text-CNN提升了29%. 提出的模型在测试集上的R @1%、R @10% 、R @20%同样均高于其他3种模型. 在top 10%中,召回率相较表现最好的模型Text-CNN提升了16%. R @50%和Bi-LSTM一样都达到了99%,比Text-CNN提升了2%,比DNN提升了3%. 所提出的模型仅从漏洞概率排在前10%的函数中就能检测出整个测试集中97%的漏洞函数,仅剩3%的漏洞函数未被检出,表明所提模型能够更准确地检测出代码漏洞. 未能检出的漏洞函数其漏洞类型包括内存泄漏,OpenSSL中间人安全绕过漏洞等,这些类型的漏洞多在代码运行时发生且与用户的具体操作有关. 要检测这些漏洞需要对函数进行实际运行,而本文方法属于静态方法,通过模型对函数进行静态分析检测代码中的漏洞,因此无法有效地检测出这些运行时漏洞. ...
... Precision and recall rate of comparative experiment with Bi-LSTM、Text-CNN、DNN
Tab.5 % 模型 K =1 K =10 K =20 K =50 P @K % R @K % P @K % R @K % P @K % R @K % P @K % R @K % Bi-LSTM[21 ] 54 22 18 75 10 87 5 99 Text-CNN[21 ] 70 29 20 81 11 90 5 97 DNN[21 ] 44 18 15 62 10 80 5 96 本研究方法 99 41 23 97 11 98 6 99
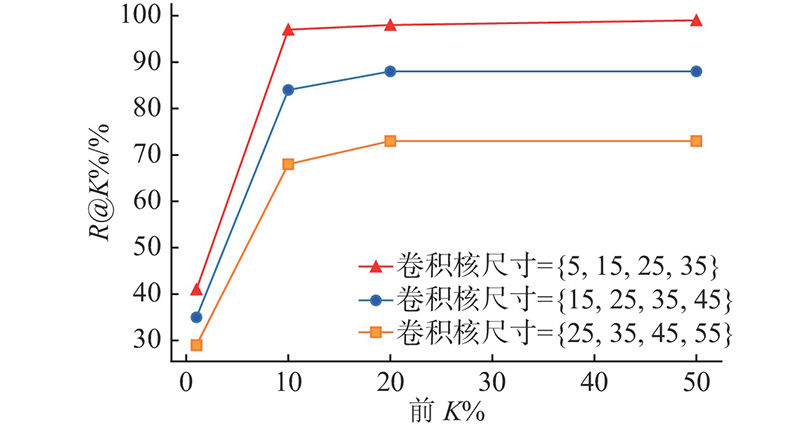
模型输出测试集中每个函数存在漏洞的概率,再将所有函数按概率从大到小排列,后分别取前K %的函数计算模型在测试集上的精确率和召回率. K 依次取值1、10、20、50,K 的取值越大模型检测出的漏洞方法越多则召回率逐渐上升,相应地精确率则会逐渐下降. 本模型的代码漏洞检测效果明显优于基线方法[21 ] 的3种模型. ...
... [
21 ]
70 29 20 81 11 90 5 97 DNN[21 ] 44 18 15 62 10 80 5 96 本研究方法 99 41 23 97 11 98 6 99 模型输出测试集中每个函数存在漏洞的概率,再将所有函数按概率从大到小排列,后分别取前K %的函数计算模型在测试集上的精确率和召回率. K 依次取值1、10、20、50,K 的取值越大模型检测出的漏洞方法越多则召回率逐渐上升,相应地精确率则会逐渐下降. 本模型的代码漏洞检测效果明显优于基线方法[21 ] 的3种模型. ...
... [
21 ]
44 18 15 62 10 80 5 96 本研究方法 99 41 23 97 11 98 6 99 模型输出测试集中每个函数存在漏洞的概率,再将所有函数按概率从大到小排列,后分别取前K %的函数计算模型在测试集上的精确率和召回率. K 依次取值1、10、20、50,K 的取值越大模型检测出的漏洞方法越多则召回率逐渐上升,相应地精确率则会逐渐下降. 本模型的代码漏洞检测效果明显优于基线方法[21 ] 的3种模型. ...
... 模型输出测试集中每个函数存在漏洞的概率,再将所有函数按概率从大到小排列,后分别取前K %的函数计算模型在测试集上的精确率和召回率. K 依次取值1、10、20、50,K 的取值越大模型检测出的漏洞方法越多则召回率逐渐上升,相应地精确率则会逐渐下降. 本模型的代码漏洞检测效果明显优于基线方法[21 ] 的3种模型. ...
... 针对现有漏洞检测方法在代码特征提取过程中存在部分信息丢失,难以有效捕捉到代码中长距离的依赖关系,长距离特征学习能力不够强,在真实数据集上的进行漏洞检测时精确率和召回率低的问题,提出了一种基于上下文特征融合的代码漏洞检测方法. 本方法能够有效捕捉代码行上下文长距离依赖关系,利用上下文全局信息指导各代码块局部特征进行融合,通过局部信息与全局信息的配合学习,提升了模型的特征学习能力. 使模型能够更好地理解代码语义,更精确地挖掘出判别代码漏洞的关键信息,检测出潜在的代码漏洞. 本方法在9个软件源代码混合的真实数据集上进行实验,与基线方法[21 ] 中漏洞检测效果最佳的模型相比,精确率和召回率显著提升,其中精确率最大提升了29%,召回率最大提升了16%. ...
2
... 现如今,软件规模越来越庞大,内部代码越来越复杂,漏洞种类也越来越多样化. 深度神经网络因面对海量输入数据时具有自动提取特征的能力,被认为能够有效应对漏洞的多样性. 一方面,深度神经网络能够学习深度非线性编程模式,捕捉复杂代码的内在结构. 另一方面,深度神经网络能够理解代码上下文相关性并对特征进行多层概括和抽象,自动学习更高级的特征,从大量样本中发现和学习代码漏洞的潜在规律[17 -18 ] ,自动检测代码中类似的漏洞. 在实际应用中代码漏洞的编程模式可以与多个代码行相关联. 例如缓冲区溢出等类别的漏洞,通常与多个连续或间隔的代码行及其上下文相关. 而现有的深度学习方法大多基于递归神经网络(recurrent neural network, RNN)[19 ] 及变体如长短期记忆网络(long short-term memory, LSTM)[20 -21 ] 、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[22 -24 ] 等. 由于RNN自身结构的限制,模型只能按照关键词输入的顺序对代码关键词序列进行逐词处理,在特征提取过程中存在部分信息丢失,导致模型难以捕捉到多行代码的长距离依赖关系. 虽然LSTM等变体能够在一定程度上扩大模型捕捉依赖的范围,但是问题的本质仍与模型递归的结构有关,这些变体并不能真正有效解决长距离依赖丢失的问题. 真实数据集中漏洞样本与非漏洞样本差异较小,在特征空间中存在较大程度的重叠,正负样本间缺少明显的界限,模型很难正确地进行区分. 真实数据集中非漏洞样本与漏洞样本比例大于40∶1,存在严重的样本不平衡问题,使得训练后的模型更倾向于样本多的无漏洞类别. 上述问题共同导致了现有方法误报率和漏报率较高,漏洞检测效果不佳. ...
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
Cross-project transfer representation learning for vulnerable function discovery
1
2018
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
基于代码属性图及注意力双向 LSTM 的漏洞挖掘方法
2
2020
... 现如今,软件规模越来越庞大,内部代码越来越复杂,漏洞种类也越来越多样化. 深度神经网络因面对海量输入数据时具有自动提取特征的能力,被认为能够有效应对漏洞的多样性. 一方面,深度神经网络能够学习深度非线性编程模式,捕捉复杂代码的内在结构. 另一方面,深度神经网络能够理解代码上下文相关性并对特征进行多层概括和抽象,自动学习更高级的特征,从大量样本中发现和学习代码漏洞的潜在规律[17 -18 ] ,自动检测代码中类似的漏洞. 在实际应用中代码漏洞的编程模式可以与多个代码行相关联. 例如缓冲区溢出等类别的漏洞,通常与多个连续或间隔的代码行及其上下文相关. 而现有的深度学习方法大多基于递归神经网络(recurrent neural network, RNN)[19 ] 及变体如长短期记忆网络(long short-term memory, LSTM)[20 -21 ] 、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[22 -24 ] 等. 由于RNN自身结构的限制,模型只能按照关键词输入的顺序对代码关键词序列进行逐词处理,在特征提取过程中存在部分信息丢失,导致模型难以捕捉到多行代码的长距离依赖关系. 虽然LSTM等变体能够在一定程度上扩大模型捕捉依赖的范围,但是问题的本质仍与模型递归的结构有关,这些变体并不能真正有效解决长距离依赖丢失的问题. 真实数据集中漏洞样本与非漏洞样本差异较小,在特征空间中存在较大程度的重叠,正负样本间缺少明显的界限,模型很难正确地进行区分. 真实数据集中非漏洞样本与漏洞样本比例大于40∶1,存在严重的样本不平衡问题,使得训练后的模型更倾向于样本多的无漏洞类别. 上述问题共同导致了现有方法误报率和漏报率较高,漏洞检测效果不佳. ...
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
基于代码属性图及注意力双向 LSTM 的漏洞挖掘方法
2
2020
... 现如今,软件规模越来越庞大,内部代码越来越复杂,漏洞种类也越来越多样化. 深度神经网络因面对海量输入数据时具有自动提取特征的能力,被认为能够有效应对漏洞的多样性. 一方面,深度神经网络能够学习深度非线性编程模式,捕捉复杂代码的内在结构. 另一方面,深度神经网络能够理解代码上下文相关性并对特征进行多层概括和抽象,自动学习更高级的特征,从大量样本中发现和学习代码漏洞的潜在规律[17 -18 ] ,自动检测代码中类似的漏洞. 在实际应用中代码漏洞的编程模式可以与多个代码行相关联. 例如缓冲区溢出等类别的漏洞,通常与多个连续或间隔的代码行及其上下文相关. 而现有的深度学习方法大多基于递归神经网络(recurrent neural network, RNN)[19 ] 及变体如长短期记忆网络(long short-term memory, LSTM)[20 -21 ] 、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[22 -24 ] 等. 由于RNN自身结构的限制,模型只能按照关键词输入的顺序对代码关键词序列进行逐词处理,在特征提取过程中存在部分信息丢失,导致模型难以捕捉到多行代码的长距离依赖关系. 虽然LSTM等变体能够在一定程度上扩大模型捕捉依赖的范围,但是问题的本质仍与模型递归的结构有关,这些变体并不能真正有效解决长距离依赖丢失的问题. 真实数据集中漏洞样本与非漏洞样本差异较小,在特征空间中存在较大程度的重叠,正负样本间缺少明显的界限,模型很难正确地进行区分. 真实数据集中非漏洞样本与漏洞样本比例大于40∶1,存在严重的样本不平衡问题,使得训练后的模型更倾向于样本多的无漏洞类别. 上述问题共同导致了现有方法误报率和漏报率较高,漏洞检测效果不佳. ...
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
1
... 随着人工智能的不断发展,深度学习有了越来越广泛的应用. 深度学习在语音识别和机器翻译等领域的突出表现显示出神经网络理解自然语言的巨大潜力. 越来越多的研究人员使用基于深度学习的方法理解代码漏洞的语义,学习代码漏洞的编程模式. 目前主流的方法使用基于深度学习的神经网络模型对软件源码进行静态分析,检测代码中的漏洞. 全连接网络(deep neural network, DNN)是可以作为高度非线性的分类器,拟合复杂抽象的代码编程模式. Peng等[25 ] 将java源文件转化为关键词(token)列表,使用N-gram方法将关键词转化为向量,并使用威尔科克森符号秩进行特征选择,过滤掉无关特征,降低特征向量的维度. 将降维后的特征送入DNN网络中进行处理输出最终的预测结果. 卷积神经网络(convolutional neural network, CNN)是应用于上下文窗口中,将窗口内的关键词映射到上下文特征空间中,语义相近的关键词在向量空间中距离更近,捕捉代码漏洞的上下文语义. Lee等[26 ] 从C语言源程序的汇编指令中检测隐藏的代码漏洞. 首先将C语言源程序转化为包含n 条指令的汇编代码,提出基于Word2Vec的Instruction2Vec方法,通过将操作码、寄存器、指针值和库函数等4种类型的汇编代码映射成固定长度的密集向量,生成汇编代码查找表. 将汇编代码转换成9×m n [27 ] 利用CNN进行函数级别的漏洞检测,首先使用C/C++ 词法分析器将函数代码转换为关键词序列,忽略除了C/C++关键字、操作符和分隔符外不影响编译的代码,以捕捉主要关键词的语义. 使用可训练的词嵌入方法将关键词序列的每个关键词转换为k 维的向量,得到的特征矩阵送入CNN网络中进一步提取特征,最后输出检测结果. Al-Alyan等[28 ] 提出一种基于CNN的纯网址钓鱼检测方法. 以纯URL文本作为输入,而不使用URL长度等预定义的特征. 将原URL中每个字母使用词嵌入方法转换为128维的向量,再进行一维卷积,最后经过全局最大池化层和密集层,输出检测结果. 由于网络深度和上下文窗口大小的限制,上述模型仅能学习到较小范围内代码的语义及其局部依赖关系,模型难以捕捉代码上下文长距离依赖关系,长距离特征学习能力差. ...
1
... 随着人工智能的不断发展,深度学习有了越来越广泛的应用. 深度学习在语音识别和机器翻译等领域的突出表现显示出神经网络理解自然语言的巨大潜力. 越来越多的研究人员使用基于深度学习的方法理解代码漏洞的语义,学习代码漏洞的编程模式. 目前主流的方法使用基于深度学习的神经网络模型对软件源码进行静态分析,检测代码中的漏洞. 全连接网络(deep neural network, DNN)是可以作为高度非线性的分类器,拟合复杂抽象的代码编程模式. Peng等[25 ] 将java源文件转化为关键词(token)列表,使用N-gram方法将关键词转化为向量,并使用威尔科克森符号秩进行特征选择,过滤掉无关特征,降低特征向量的维度. 将降维后的特征送入DNN网络中进行处理输出最终的预测结果. 卷积神经网络(convolutional neural network, CNN)是应用于上下文窗口中,将窗口内的关键词映射到上下文特征空间中,语义相近的关键词在向量空间中距离更近,捕捉代码漏洞的上下文语义. Lee等[26 ] 从C语言源程序的汇编指令中检测隐藏的代码漏洞. 首先将C语言源程序转化为包含n 条指令的汇编代码,提出基于Word2Vec的Instruction2Vec方法,通过将操作码、寄存器、指针值和库函数等4种类型的汇编代码映射成固定长度的密集向量,生成汇编代码查找表. 将汇编代码转换成9×m n [27 ] 利用CNN进行函数级别的漏洞检测,首先使用C/C++ 词法分析器将函数代码转换为关键词序列,忽略除了C/C++关键字、操作符和分隔符外不影响编译的代码,以捕捉主要关键词的语义. 使用可训练的词嵌入方法将关键词序列的每个关键词转换为k 维的向量,得到的特征矩阵送入CNN网络中进一步提取特征,最后输出检测结果. Al-Alyan等[28 ] 提出一种基于CNN的纯网址钓鱼检测方法. 以纯URL文本作为输入,而不使用URL长度等预定义的特征. 将原URL中每个字母使用词嵌入方法转换为128维的向量,再进行一维卷积,最后经过全局最大池化层和密集层,输出检测结果. 由于网络深度和上下文窗口大小的限制,上述模型仅能学习到较小范围内代码的语义及其局部依赖关系,模型难以捕捉代码上下文长距离依赖关系,长距离特征学习能力差. ...
1
... 随着人工智能的不断发展,深度学习有了越来越广泛的应用. 深度学习在语音识别和机器翻译等领域的突出表现显示出神经网络理解自然语言的巨大潜力. 越来越多的研究人员使用基于深度学习的方法理解代码漏洞的语义,学习代码漏洞的编程模式. 目前主流的方法使用基于深度学习的神经网络模型对软件源码进行静态分析,检测代码中的漏洞. 全连接网络(deep neural network, DNN)是可以作为高度非线性的分类器,拟合复杂抽象的代码编程模式. Peng等[25 ] 将java源文件转化为关键词(token)列表,使用N-gram方法将关键词转化为向量,并使用威尔科克森符号秩进行特征选择,过滤掉无关特征,降低特征向量的维度. 将降维后的特征送入DNN网络中进行处理输出最终的预测结果. 卷积神经网络(convolutional neural network, CNN)是应用于上下文窗口中,将窗口内的关键词映射到上下文特征空间中,语义相近的关键词在向量空间中距离更近,捕捉代码漏洞的上下文语义. Lee等[26 ] 从C语言源程序的汇编指令中检测隐藏的代码漏洞. 首先将C语言源程序转化为包含n 条指令的汇编代码,提出基于Word2Vec的Instruction2Vec方法,通过将操作码、寄存器、指针值和库函数等4种类型的汇编代码映射成固定长度的密集向量,生成汇编代码查找表. 将汇编代码转换成9×m n [27 ] 利用CNN进行函数级别的漏洞检测,首先使用C/C++ 词法分析器将函数代码转换为关键词序列,忽略除了C/C++关键字、操作符和分隔符外不影响编译的代码,以捕捉主要关键词的语义. 使用可训练的词嵌入方法将关键词序列的每个关键词转换为k 维的向量,得到的特征矩阵送入CNN网络中进一步提取特征,最后输出检测结果. Al-Alyan等[28 ] 提出一种基于CNN的纯网址钓鱼检测方法. 以纯URL文本作为输入,而不使用URL长度等预定义的特征. 将原URL中每个字母使用词嵌入方法转换为128维的向量,再进行一维卷积,最后经过全局最大池化层和密集层,输出检测结果. 由于网络深度和上下文窗口大小的限制,上述模型仅能学习到较小范围内代码的语义及其局部依赖关系,模型难以捕捉代码上下文长距离依赖关系,长距离特征学习能力差. ...
Robust URL phishing detection based on deep learning
1
2020
... 随着人工智能的不断发展,深度学习有了越来越广泛的应用. 深度学习在语音识别和机器翻译等领域的突出表现显示出神经网络理解自然语言的巨大潜力. 越来越多的研究人员使用基于深度学习的方法理解代码漏洞的语义,学习代码漏洞的编程模式. 目前主流的方法使用基于深度学习的神经网络模型对软件源码进行静态分析,检测代码中的漏洞. 全连接网络(deep neural network, DNN)是可以作为高度非线性的分类器,拟合复杂抽象的代码编程模式. Peng等[25 ] 将java源文件转化为关键词(token)列表,使用N-gram方法将关键词转化为向量,并使用威尔科克森符号秩进行特征选择,过滤掉无关特征,降低特征向量的维度. 将降维后的特征送入DNN网络中进行处理输出最终的预测结果. 卷积神经网络(convolutional neural network, CNN)是应用于上下文窗口中,将窗口内的关键词映射到上下文特征空间中,语义相近的关键词在向量空间中距离更近,捕捉代码漏洞的上下文语义. Lee等[26 ] 从C语言源程序的汇编指令中检测隐藏的代码漏洞. 首先将C语言源程序转化为包含n 条指令的汇编代码,提出基于Word2Vec的Instruction2Vec方法,通过将操作码、寄存器、指针值和库函数等4种类型的汇编代码映射成固定长度的密集向量,生成汇编代码查找表. 将汇编代码转换成9×m n [27 ] 利用CNN进行函数级别的漏洞检测,首先使用C/C++ 词法分析器将函数代码转换为关键词序列,忽略除了C/C++关键字、操作符和分隔符外不影响编译的代码,以捕捉主要关键词的语义. 使用可训练的词嵌入方法将关键词序列的每个关键词转换为k 维的向量,得到的特征矩阵送入CNN网络中进一步提取特征,最后输出检测结果. Al-Alyan等[28 ] 提出一种基于CNN的纯网址钓鱼检测方法. 以纯URL文本作为输入,而不使用URL长度等预定义的特征. 将原URL中每个字母使用词嵌入方法转换为128维的向量,再进行一维卷积,最后经过全局最大池化层和密集层,输出检测结果. 由于网络深度和上下文窗口大小的限制,上述模型仅能学习到较小范围内代码的语义及其局部依赖关系,模型难以捕捉代码上下文长距离依赖关系,长距离特征学习能力差. ...
1
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
1
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
4
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
... [31 ](code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
... 为了解决正负样本不平衡问题,结合随机下采样方法和人工少数类过采样法[34 ] (synthetic minority over-sampling technique, SMOTE). 使用随机下采样方法对非漏洞负样本进行随机剔除,再使用SMOTE对漏洞正样本进行扩充,平衡后的正负样本比例为1∶1. 在特征学习过程中,输入的数据比学习模型的选择更加重要[35 ] . 代码表征是对程序源码进行表示的重要步骤,直接决定后续输入模型中数据的质量和后续模型进行特征学习的难易程度. 代码属性图[31 ] 是一种基于图的特殊数据结构,整合代码的语法结构、控制依赖及数据依赖等信息,可以有效地对代码漏洞进行表征. 本研究使用静态分析工具Joern[31 ] 生成函数的代码属性图,从代码属性图中提取出原函数的抽象语法树序列和控制流序列,将二者拼接后得到函数的关键词序列T = [METHOD, foo, PARAM, int, x ,···]以这种方式最大程度地保留代码的语法、语义和内部结构信息,尽可能减少代码表征过程中的信息损失. 其次使用Tokenizer分词器对关键词序列T 中的每一个关键词进行编码得到函数的数值向量表示V l 对数值向量进行截断或者末尾补零保证每个函数的数值向量长度相等. 使用预先训练好的Word2Vector模型选择词嵌入维度d 对数值向量V F F D l ×d l 为关键词序列长度,d 为词嵌入维度,D
... [31 ]生成函数的代码属性图,从代码属性图中提取出原函数的抽象语法树序列和控制流序列,将二者拼接后得到函数的关键词序列T = [METHOD, foo, PARAM, int, x ,···]以这种方式最大程度地保留代码的语法、语义和内部结构信息,尽可能减少代码表征过程中的信息损失. 其次使用Tokenizer分词器对关键词序列T 中的每一个关键词进行编码得到函数的数值向量表示V l 对数值向量进行截断或者末尾补零保证每个函数的数值向量长度相等. 使用预先训练好的Word2Vector模型选择词嵌入维度d 对数值向量V F F D l ×d l 为关键词序列长度,d 为词嵌入维度,D
4
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
... 为了测试本方法在其他数据集上的漏洞检测效果,使用Zhou等[32 ] 公开的漏洞数据集QEMU进行实验并与同样基于该数据集的模型Devign[32 ] 进行对比,实验设置和评价指标与其保持一致. 为了模拟真实数据集中正负样本不平衡的情况,调整正负样本比例为9∶1并按照8∶1∶1的比例将实验数据集随机划分为训练集、验证集和测试集. 实验结果如表6 所示. 从表6 可以看出,所提模型在测试集上的准确率(ACC)和平衡F 分数(F 1)分别为96.62%和79.83%,在这2个评估指标上明显优于Devign. ...
... [32 ]进行对比,实验设置和评价指标与其保持一致. 为了模拟真实数据集中正负样本不平衡的情况,调整正负样本比例为9∶1并按照8∶1∶1的比例将实验数据集随机划分为训练集、验证集和测试集. 实验结果如表6 所示. 从表6 可以看出,所提模型在测试集上的准确率(ACC)和平衡F 分数(F 1)分别为96.62%和79.83%,在这2个评估指标上明显优于Devign. ...
... Accuracy and
F 1 score results of comparative experiment with Devign
Tab.6 模型 ACC/% F 1/% Devign[32 ] 89.27 41.12 本研究方法 96.62 79.83
实验结果表明,相比Devign使用图神经网络通过融合各节点间的信息来提取代码特征,所提模型首先提取代码块局部特征再利用上下文全局信息指导局部特征进行特征融合,具有更强的长距离依赖捕获能力和特征学习能力,能够更有效地挖掘出代码漏洞实现了更好的漏洞检测效果. ...
Bgnn4vd: constructing bidirectional graph neural-network for vulnerability detection
1
2021
... 与DNN和CNN相比,递归神经网络(RNN)是更擅长处理序列化的数据. 大量研究应用RNN及变体学习代码漏洞的语义和上下文相关性,以检测代码中的隐藏漏洞. Dam等[20 ] 利用seq2seq模型中的LSTM网络,对Java源代码进行文件级别的漏洞检测. 从源文件的抽象语法树(abstract syntax tree, AST)中提取出关键词序列,通过预先构建的查找表将每个关键词转换为固定长度的词向量. 将每个词向量依次输入LSTM网络中进行漏洞检测. Lin等[23 ] 利用Code Sensor[29 ] 工具生成函数源码的抽象语法树,并对抽象语法树进行深度优先遍历得到函数的关键词序列. 通过Word2Vec将序列中的关键词映射为固定维度的向量得到函数的特征矩阵,将矩阵输入到Bi-LSTM网络中得到函数的向量表示,再使用函数向量训练随机森林,输出漏洞检测结果. Lin等[21 ] 提出9个C语言软件源代码混合的漏洞数据集,并基于该数据集分别训练基于DNN、Text-CNN和Bi-LSTM等漏洞检测模型,其中基于Bi-LSTM的模型在该数据集上取得最佳的漏洞检测效果. Li等[22 ] 提出VulDeePecker方法,基于程序的API调用对源码进行切片,并使用词嵌入方法将切片后的代码映射为词嵌入向量输入到由2个不同尺度的Bi-LSTM构成的网络中,检测源代码中的漏洞. Li等[19 ] 提出了SySeVR方法,模型自动化提取语法漏洞候选(SyVCs)和语义漏洞候选(SeVCs)特征. SySeVR训练了CNN、RNN、Bi-RNN和Bi-GRU等多种神经网络. 实验结果表明,在这些模型中Bi-GRU取得最好的漏洞检测效果. Duan等[24 ] 提出一种面向源代码漏洞挖掘的漏洞检测方法. 首先将源程序表示为代码属性图,然后以敏感操作作为切片准则对代码属性图进行切片后将其编码为张量,再输入到Bi-LSTM 网络中学习源码的上下文信息,并利用注意力机制捕获源码的关键特征,最终输出检测结果. 由于RNN在顺序计算的过程中存在信息丢失,模型难以有效地捕捉到代码上下文长距离的依赖关系,这些依赖关系对于模型理解代码漏洞的语义至关重要. 尽管使用Bi-LSTM等变体能在一定程度上缓解却仍无法有效解决长距离依赖丢失的问题,限制模型的长距离特征学习能力、误报率和漏报率较高. 图神经网络(graph neural networks, GNN)是将代码看作图形,整合代码中不同的语法和语义信息,能够更好地表示代码内部的逻辑和结构. Suneja等[30 ] 使用Joern[31 ] 工具生成函数的代码属性图[31 ] (code property graph, CPG),然后将代码属性图作为函数表征输入到图神经网络中进行漏洞检测. Zhou等[32 ] 提出基于图神经网络的漏洞检测模型Devign,通过对源代码进行编码,将函数转化为包含多个语法和语义表示的联合图结构,从中提取有效的特征识别代码中的漏洞. Cao等[33 ] 提出基于双向图神经网络的BGNN4VD漏洞检测方法,通过在传统图神经网络中引入反向边来学习漏洞代码与非漏洞代码的不同特征,检测代码中的漏洞. 通过对上述方法进行研究和分析,发现这些方法难以有效捕捉代码上下文长距离的依赖关系,模型长距离特征学习能力不够强,缺少理解代码漏洞语义所需要的关键信息,导致在真实数据集上进行漏洞检测时,精确率与召回率较低. 针对现有漏洞检测方法存在的问题,提出基于上下文特征融合的代码漏洞检测方法,模型整体框架如图1 所示. ...
Smote: synthetic minority over-sampling technique
1
2002
... 为了解决正负样本不平衡问题,结合随机下采样方法和人工少数类过采样法[34 ] (synthetic minority over-sampling technique, SMOTE). 使用随机下采样方法对非漏洞负样本进行随机剔除,再使用SMOTE对漏洞正样本进行扩充,平衡后的正负样本比例为1∶1. 在特征学习过程中,输入的数据比学习模型的选择更加重要[35 ] . 代码表征是对程序源码进行表示的重要步骤,直接决定后续输入模型中数据的质量和后续模型进行特征学习的难易程度. 代码属性图[31 ] 是一种基于图的特殊数据结构,整合代码的语法结构、控制依赖及数据依赖等信息,可以有效地对代码漏洞进行表征. 本研究使用静态分析工具Joern[31 ] 生成函数的代码属性图,从代码属性图中提取出原函数的抽象语法树序列和控制流序列,将二者拼接后得到函数的关键词序列T = [METHOD, foo, PARAM, int, x ,···]以这种方式最大程度地保留代码的语法、语义和内部结构信息,尽可能减少代码表征过程中的信息损失. 其次使用Tokenizer分词器对关键词序列T 中的每一个关键词进行编码得到函数的数值向量表示V l 对数值向量进行截断或者末尾补零保证每个函数的数值向量长度相等. 使用预先训练好的Word2Vector模型选择词嵌入维度d 对数值向量V F F D l ×d l 为关键词序列长度,d 为词嵌入维度,D
1
... 为了解决正负样本不平衡问题,结合随机下采样方法和人工少数类过采样法[34 ] (synthetic minority over-sampling technique, SMOTE). 使用随机下采样方法对非漏洞负样本进行随机剔除,再使用SMOTE对漏洞正样本进行扩充,平衡后的正负样本比例为1∶1. 在特征学习过程中,输入的数据比学习模型的选择更加重要[35 ] . 代码表征是对程序源码进行表示的重要步骤,直接决定后续输入模型中数据的质量和后续模型进行特征学习的难易程度. 代码属性图[31 ] 是一种基于图的特殊数据结构,整合代码的语法结构、控制依赖及数据依赖等信息,可以有效地对代码漏洞进行表征. 本研究使用静态分析工具Joern[31 ] 生成函数的代码属性图,从代码属性图中提取出原函数的抽象语法树序列和控制流序列,将二者拼接后得到函数的关键词序列T = [METHOD, foo, PARAM, int, x ,···]以这种方式最大程度地保留代码的语法、语义和内部结构信息,尽可能减少代码表征过程中的信息损失. 其次使用Tokenizer分词器对关键词序列T 中的每一个关键词进行编码得到函数的数值向量表示V l 对数值向量进行截断或者末尾补零保证每个函数的数值向量长度相等. 使用预先训练好的Word2Vector模型选择词嵌入维度d 对数值向量V F F D l ×d l 为关键词序列长度,d 为词嵌入维度,D
1
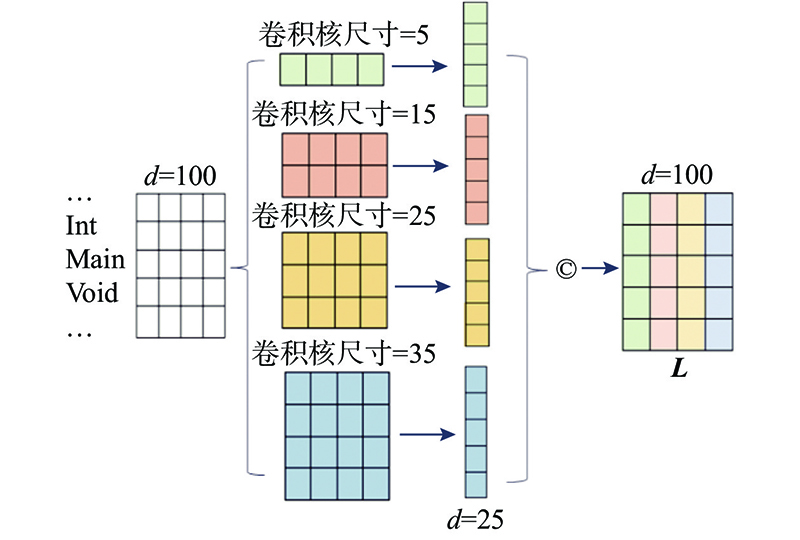
... 函数整体由多个代码块组成,提取的全局特征是函数的上下文全局描述. 上下文全局特征融合阶段基于自注意力机制[36 ] 经过计算得到各个局部代码块之间的全局依赖关系,为属于不同代码块的关键词设置不同大小的全局依赖权重,从而得到局部代码块的加权表示并进行融合,突出重要代码块及核心关键词间的依赖关系,对重要代码块和核心关键词的信息进行增强. 利用全局信息指导各个代码块局部特征进行融合最终得到上下文全局特征矩阵,整合所有代码块的语义信息,使得模型能够理解整个函数的语义,提升模型的长距离特征学习能力和代码语义理解能力. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}