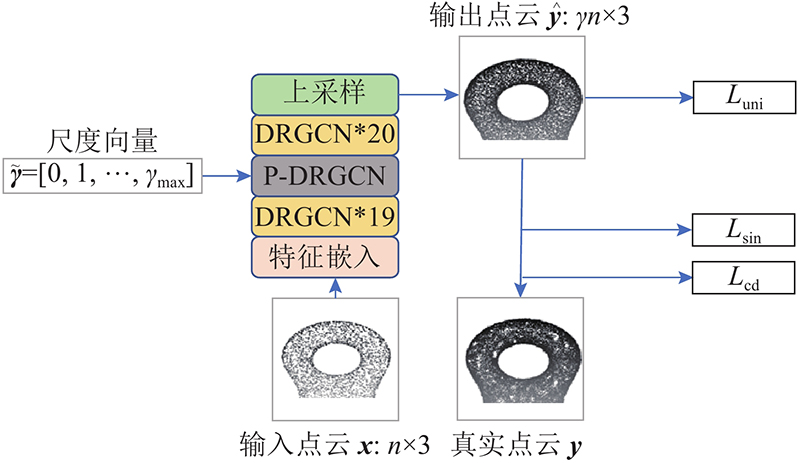
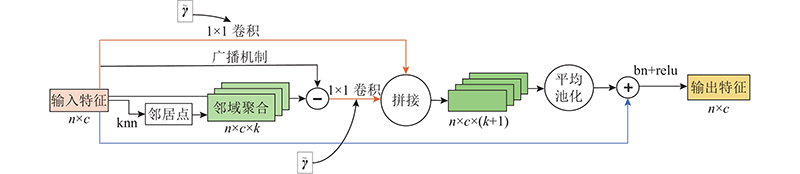
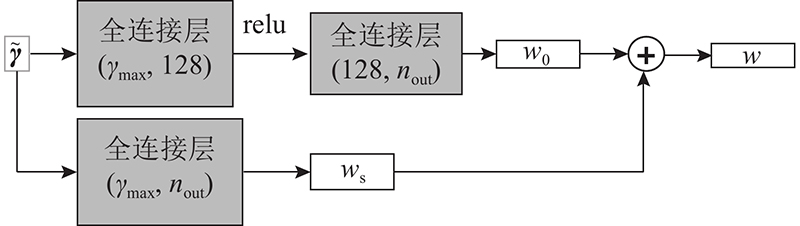
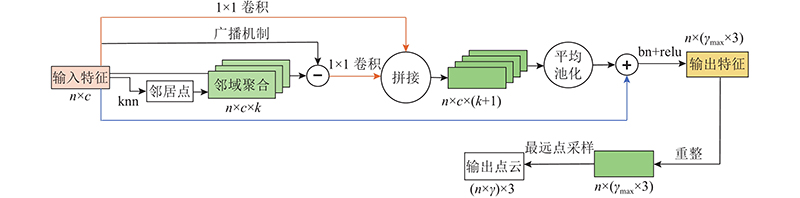
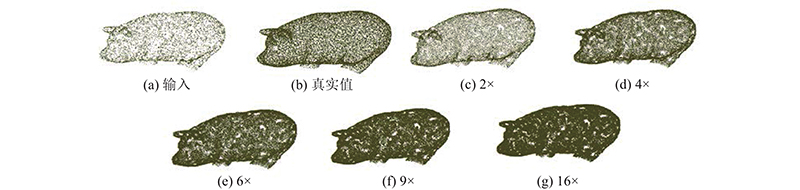
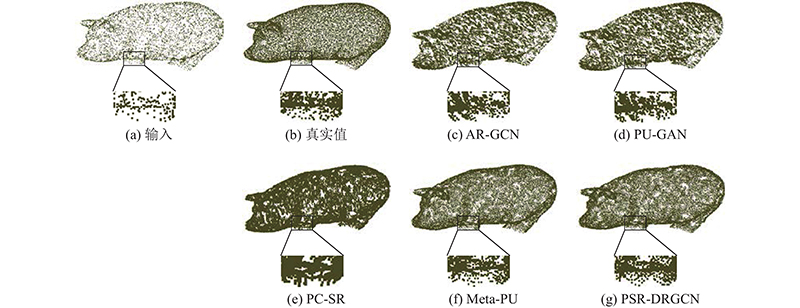
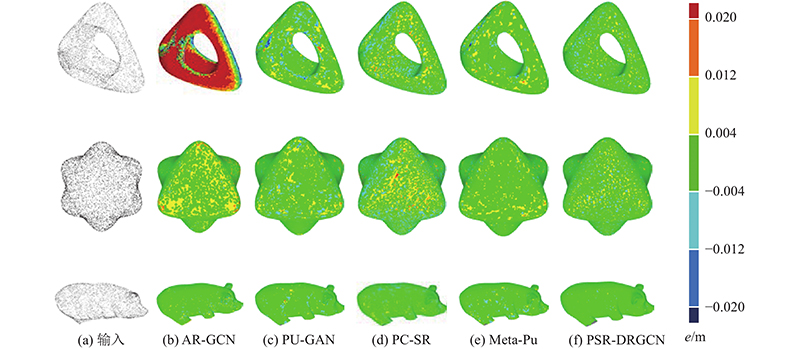
A 3D point cloud super-resolution network with dynamic residual graph convolution (PSR-DRGCN) was proposed to efficiently extract of local information from 3D point clouds of non-European data in super-resolution. The network includes feature extraction module, DRGCN module and upsampling module. For the input point cloud, the feature extraction module locates k nearest points of each point in 3D space by k-NN algorithm and then converts the local geometry information into the high dimensional feature space through a multi-layer pointwise convolution. The DRGCN module converts the local geometry feature of each point into the semantic feature through a multi-layer graph convolution. It dynamically adjusts the neighbor space of the point in each layer to increase the receptive field range and effectively fuse the semantic information of different levels through residual connection, which makes the extraction of local geometric information efficient. The upsampling module adds the number of points and maps them from feature space to 3D space. The results showed that at 2× magnification of the high-resolution point cloud generated by PSR-DRGCN, the similarity indexes CD, EMD and F-score compared with the second network were increased by 10.00%, 4.76% and 16.84% respectively. Compared with the second network, the similarity indexes at 6× magnification were increased by 2.35%, 40.00% and 0.58% respectively. In all cases, the optimal effect was achieved on the mean and the std indicators and the generated high-resolution point cloud quality was high.
Keywords:3D point cloud
;
super-resolution
;
dynamic GCN
;
semantic feature
;
deep learning
ZHONG Fan, BAI Zheng-yao. 3D point cloud super-resolution with dynamic residual graph convolutional networks. Journal of Zhejiang University(Engineering Science)[J], 2022, 56(11): 2251-2259 doi:10.3785/j.issn.1008-973X.2022.11.016
WU H, ZHANG J, HUANG K. Point cloud super resolution with adversarial residual graph networks [EB/OL]. [2019-08-06]. https://arxiv.org/pdf/1908.0211.pdf .
YU L, LI X, FU C W, et al. Pu-net: point cloud upsampling network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2790-2799.
LI R, LI X, FU C W, et al. Pu-gan: a point cloud upsampling adversarial network [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 7203-7212.
QI C R, SU H, MO K, et al. Pointnet: deep learning on point sets for 3d classification and segmentation [C]// Proceedings of the IEEE conference on computer vision and pattern recognition. Hawaii: IEEE, 2017: 652-660.
LI R, LI X, HENG P A, et al. Point cloud upsampling via Disentangled Refinement [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Online: IEEE, 2021: 344-353.
QI C R, YI L, SU H, et al. Pointnet++: deep hierarchical feature learning on point sets in a metric space [C]// Proceedings of Neural Information Processing Systems. Long Beach: NIPS, 2017: 5099-5108.
MATURANA D, SCHERER S. Voxnet: a 3d convolutional neural network for real-time object recognition [C]// Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems. Hamburg: IEEE, 2015: 922-928.
MAO J, XUE Y, NIU M, et al. Voxel transformer for 3d object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Online: IEEE, 2021: 3164-3173.
WANG G, XU G, WU Q, et al
Two-stage point cloud super resolution with local interpolation and readjustment via outer-product neural network
[J]. Journal of Systems Science and Complexity, 2021, 34 (1): 68- 82
SIMONOYSKY M, KOMODAKIS N. Dynamic edge-conditioned flters in convolutional neural networks on graphs [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017: 3693-3702.
TE G, HU W, ZHENG A, et al. Rgcnn: regularized graph cnn for point cloud segmentation [C]// Proceedings of the 26th ACM International Conference on Multimedia. Lisboa: ACM, 2018: 746-754.
QIAN G, ABUALSHOUR A, LI G, et al. Pu-gcn: point cloud upsampling using graph convolutional networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Online: IEEE, 2021: 11683-11692.
YU X, RAO Y, WANG Z, et al. Pointr: diverse point cloud completion with geometry-aware transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Online: IEEE, 2021: 12498-12507.
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE conference on computer vision and pattern recognition. Las Vegas: IEEE, 2016: 770-778.
LUO C, CHEN Y, WANG N, et al. Spectral feature transformation for person re-identification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 4976-4985.
HU X, MU H, ZHANG X, et al. Meta-SR: a magnification-arbitrary network for super-resolution [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 1575-1584.
CUTURI M. Sinkhorn distances: lightspeed computation of optimal transport [C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe: NIPS, 2013: 2292-2300.
BOLTZ S, NIELSEN F, SOATTO S. Earth mover distance on superpixels [C]// IEEE International Conference on Image Processing. Hong Kong: IEEE, 2010: 4597-4600.
SOKOLOVA M, JAPKOWICZ N, SZPAKOWICZ S. Beyond accuracy, F-score and ROC: a family of discriminant measures for performance evaluation [C]// Australasian Joint Conference on Artificial Intelligence. Berlin: Springer, 2006: 1015-1021.
DONG Y, CORDONNIER J B, LOUKAS A. Attention is not all you need: Pure attention loses rank doubly exponentially with depth[EB/OL]. [2021-05-05]. https://arxiv.org/pdf/2103.03404.pdf.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}