

振动信号分析是转盘轴承健康监测领域中研究较多、应用较广的技术[1]. 转盘轴承运行过程会出现滚道疲劳剥落、磨损、塑性变形,各故障成分互相叠加往往导致振动信号的非稳定性、不确定性和复杂性[2]. 封杨等[3-4]从轴承振动信号中提取时域统计参数,识别轴承的故障模式. Caesarendra等[5-6]采用时频域方法分析转盘轴承振动信号,对轴承进行状态监测. 虽然上述时域和时频域特征可以在不同程度上反映设备运行状态,但是单个领域的特征难以全面、准确地描述复杂恶劣环境下转盘轴承的状态信息. Lu等[7-8]以时域和时频域特征作为特征向量,评估了大型转盘轴承的健康状态. 封杨等[3-8]的研究表明,多领域特征更能够全面反映转盘轴承的性能退化过程.
如何有效利用多领域特征进行转盘轴承寿命状态识别是急需解决的问题. 基于自编码器(auto-encoder, AE)的深度神经网络结构利用逐层重构的思想,逐步提取样本的低维或高维特征进行高层次的抽象表示,具有极强的特征表达能力[9]. 由于传统的AE模型大部分采用反向传播(back propagation, BP)算法,模型的收敛速度缓慢,易陷入局部最优. Kasun等[10]将极限学习机(extreme learning machine, ELM)与AE结合,提出极限学习机自编码器(extreme learning machine based auto-encoder, ELM-AE)算法,该算法无需使用传统BP算法微调网络,减少了训练网络的时间成本. 虽然堆叠ELM-AE数量构成的深度学习模型[11-13]能够提取样本更深层的特征,但ELM存在以下缺点[14]. 1)稳定性较差. 直接利用最小二乘法计算输出权值极大地提高了算法的学习速度,但输入权值和隐藏层阈值随机产生,无法根据实际数据对参数进行微调训练. 2)鲁棒性较差. 没有考虑误差的权重,当数据集存在离群点或奇异点时,模型的性能可能会受到较大的影响. 3)易过拟合. 仅考虑经验性风险,忽略结构化风险. 邓万宇等[15]提出的正则化极限学习机(regularized extreme learning machine, RELM)将结构风险最小化理论和加权最小二乘法融入ELM中,既保留了ELM计算速度快的优点,还考虑到了经验性风险和结构化风险. 在此基础上,Huang[16]通过引入核函数提出的核极限学习机(kernel extreme learning machine, KELM)有效克服了ELM的固有缺点,不仅降低了计算复杂度,还提高了预测、分类模型的稳定性和鲁棒性[17-18].
针对以上问题,本研究提出结合多领域特征提取和改进多层核极限学习机自编码器(multi-layer kernel extreme learning machine based auto-encoder, MLKELM-AE)的转盘轴承寿命状态识别方法. 结合KELM和AE,构造核极限学习机自编码器(KELM-AE),堆叠多层KELM-AE构成深度学习模型,以KELM作为模型决策层,提出寿命状态识别模型. 采用新的飞蛾扑火算法(moth-flame optimization, MFO)优化多层核极限学习机自编码器(MFO-MLKELM-AE)的惩罚系数和核参数,提高MLKELM-AE模型的识别精度.
1. 基本算法
1.1. 多领域特征提取
转盘轴承全寿命过程包含大量的状态信息,常用的振动时域和时频域特征随着轴承的不同寿命阶段产生不同的表征性能. 峭度、均值、方差、均方根、波形指标、峰值指标、裕度指标和偏度指标等8个时域特征对转盘轴承的健康状态变化比较敏感. 小波变换是信号时频域分析领域的有效工具。其中基于小波包分解提取多尺度空间能量特征的原理是把不同分解尺度上的信号能量求解出来,反映出转盘轴承的健康状态. 某一尺度下的小波包能量为该尺度下小波系数的平方和,即,
1.2. 核极限学习机
ELM是高效、泛化性好的单隐层前馈神经网络算法. 对于给定的N个样本(xj, yj),含有L个隐藏节点的单隐层前馈神经网络表达式为
式中:
式中:Y为期望输出;H是隐藏层节点输出,H=[h(x1)T
式中:H+为矩阵H的Moore-Penrose广义逆.
为了解决传统ELM算法中计算结果容易受到随机设定值影响的问题,KELM引入核函数. 定义核矩阵为
式中:K(xi, xj)为核函数. 对于无先验知识的数据集,通常采用径向基核函数[19],即
式中:σ为核函数宽度. KELM网络输出表示为
式中:I为单位矩阵,C为惩罚系数.
作为ELM的非线性延伸,KELM在ELM中引入核函数,以核映射取代随机映射,直接采用内积的形式,不必提前确定隐藏层神经元个数,无需设定隐藏层初始权重和偏置,由核函数的具体形式就可以求出输出函数的值. 因此,与ELM相比KELM具有更好的泛化性、鲁棒性.
1.3. 自编码结构
AE是尽可能复现输入信号的单隐层神经网络,它假设自身的输入与输出相同. AE主要由2个网络构成:编码和解码. 编码与解码网络间的交叉部分为码字层,它是原始输入信号的近似表达,实现了无监督的特征提取. 如果模型得到的重构精度满足要求,那么隐藏层就能够代表原始输入层.
1.4. 飞蛾扑火算法
式中:Mi为第i个飞蛾;Fj为第j个火焰;S为螺旋线函数;Di为第i个飞蛾和第j个火焰的距离;b为常数;t为区间[r, 1]的任意值,其中r为在算法迭代更新过程中从−1至−2线性减小的收敛常数. 为了避免陷入局部最优,在每次迭代更新之后,火焰根据适应度大小排序,再更新飞蛾相对于火焰的位置. 自适应减少火焰数量的计算式为
式中:N为火焰数量的最大值,l为当前迭代次数,T为最大迭代次数.
MFO是基于种群的随机启发式搜索算法,与群智能优化算法最大的区别是,MFO的粒子搜索路径是螺旋形的,粒子围绕着更优解以螺旋而不是直线的方式移动. 因此,与传统群智能优化算法相比MFO具有更强的并行优化能力和全局搜索能力.
2. 基于MFO-MLKELM-AE的寿命状态识别
2.1. 多层核极限学习机自编码器
图 1
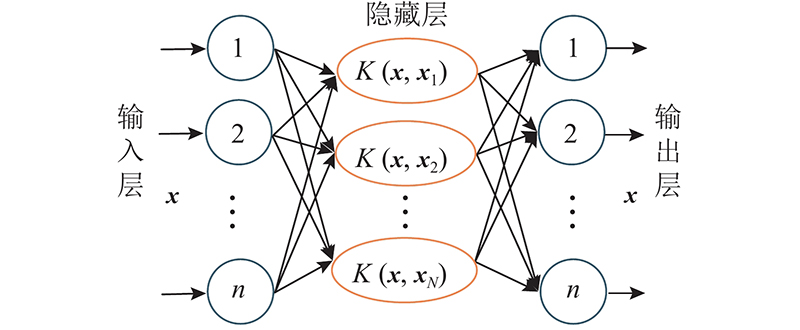
图 1 核极限学习机自编码器结构示意图
Fig.1 Structure diagram of kernel extreme learning machine based auto-encoder
图 2
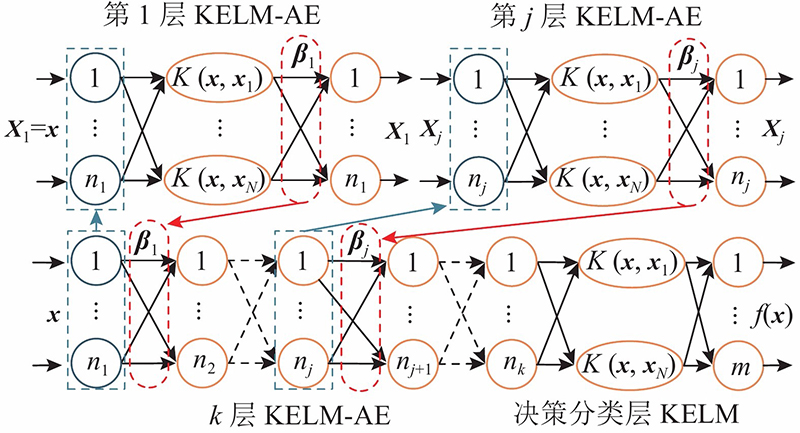
图 2 多层核极限学习机自编码器结构示意图
Fig.2 Structure diagram of multi-layer kernel extreme learning machine based auto-encoder
式中:Xj为第j层的输入,由Xj和βj可得第j层的输出并作为第j+1层的输入[22]. 将第k层KELM-AE的输出作为决策层KELM的输入,由式(6)得到MLKELM-AE模型输出. MLKELM-AE识别模型主要分为2个部分:1)多层网络提取样本高层次特征;2)寿命状态识别. MLKELM-AE模型的算法流程如下. 1)初始化参数:包括惩罚系数、核参数. 2)提取多层特征:采用KELM-AE逐层计算隐藏层权值和输出,确定多层模型中所有网络权值. 3)模式识别:将末层KELM-AE的隐藏层输出作为决策层KELM的输入,输出最终模式.
传统深度学习的训练过程包括无监督预训练和有监督微调,需要同时训练所有隐藏层,逐层贪婪迭代调整所有参数,不仅时间复杂度高,且系统偏差会逐层传递. MLKELM-AE由多层独立的KELM-AE组成,单层KELM-AE的权值和输出仅与其输入相关,无需微调. 同时,多层KELM-AE克服ELM-AE中因随机矩阵H导致模型输出的随机波动. 本研究所提MLKELM-AE转盘轴承寿命状态识别模型将非线性特征的映射能力提高,具有高效快速的优点.
2.2. 基于MFO的MLKELM-AE参数寻优
对于单层KELM-AE而言,核参数σ不仅控制着径向基核函数的径向作用范围,还反映非线性映射的本质. 当σ取较小值时,径向基核函数的性能类似多项式核函数;当σ取较大值时,径向基核函数的性能类似线性核函数. 惩罚系数C的作用是权衡结构风险最小化和经验风险最小化的比例,C越大表明经验风险最小化比重越大[23]. 在本研究所提MLKELM-AE结构中,须在每层KELM-AE以及决策层KELM分别设置C、σ. 因此,C、σ的组合取值对MLKELM-AE模型性能有较大影响. 利用MFO算法的并行优化能力优化MLKELM-AE模型中的参数,MFO-MLKELM-AE具体优化过程如所下.
1)初始化飞蛾数量、飞蛾种群维数、初始位置、迭代次数等.
2)由式(8)自适应减少火焰数量.
3)训练寿命状态识别模型,利用MFO优化MLKELM-AE模型的最优参数,以MLKELM-AE模型的识别结果作为适应度函数. 根据适应度函数评估飞蛾M的优化效果,寻找最佳位置时的飞蛾,记为火焰F.
4)由式(7)更新飞蛾在搜索空间的位置,并计算飞蛾对应的适应度数,根据最优的解更改火焰的顺序.
5)当迭代次数达到最大值或适应度函数不再减小时,循环结束;否则,返回步骤2)重复执行. 最终获得MLKELM-AE模型的最优超参数,建立寿命状态识别模型.
2.3. 转盘轴承寿命状态识别流程
本研究提出的MFO-MLKELM-AE模型由多个堆叠KELM-AE和决策层KELM分类器组成。如图3所示,多层KELM-AE无监督学习转盘轴承寿命信息的高层特征,由KELM进行寿命状态识别,再使用MFO优化MLKELM-AE模型参数. 转盘轴承寿命状态识别具体过程如下.
图 3
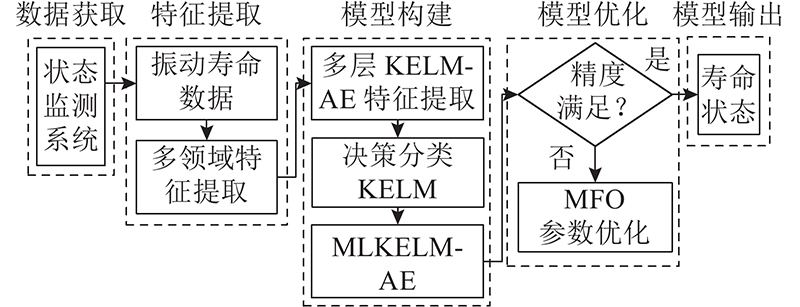
图 3 转盘轴承寿命状态识别流程图
Fig.3 Flowchart of slewing bearing life condition recognition
1)数据获取:获取转盘轴承实验台的全寿命数据,并划分为4个寿命状态.
2)特征提取:提取振动信号的8个时域特征和8个时频域特征,组成模型输入向量.
3)模型构建:对数据进行归一化处理,在每个寿命阶段提取连续特征值样本,按比例划分训练和测试样本.
4)模型优化:初始化模型的超参数C、σ,使用训练样本对多层KELM-AE进行无监督预训练,选择带标签的训练样本采用KELM算法进行有监督的模型训练. 采用MFO优化MLKELM-AE模型参数,得到最优的超参数组合.
5)模型输出:将测试样本输入已训练好的MLKELM-AE模型中,得出测试精度.
3. 转盘轴承加速寿命实验
3.1. 转盘轴承实验台
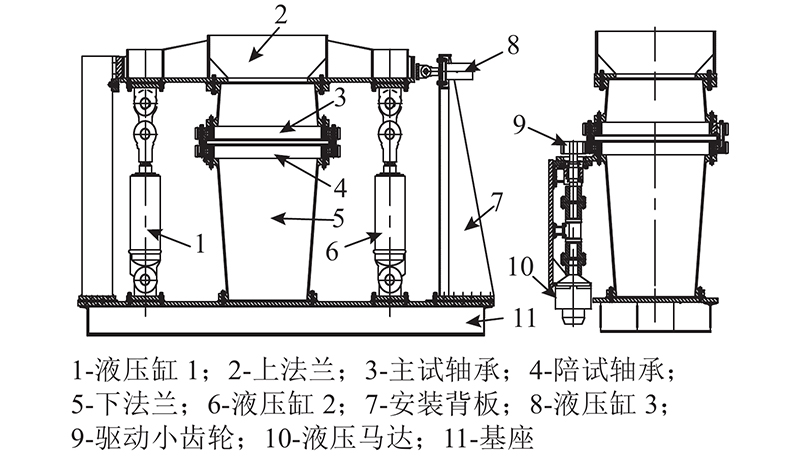
采用如图4所示的转盘轴承实验台对转盘轴承进行加速寿命实验. 转盘轴承实验台主要包括机械结构、液压加载、测试和控制部分等. 机械结构主要由基座、液压缸、法兰和驱动小齿轮等组成. 在实际运行过程中转盘轴承承受轴向力、径向力和倾覆力矩的合力,根据转盘轴承的实际受载情况,本实验装置分别采用3组正反向液压缸进行加载组合,其中液压缸1和液压缸2的加载组合实现轴向力和倾覆力矩的施加;液压缸3施加推力至上法兰并将载荷传递至转盘轴承,实现径向力的施加. 实验台采用背靠背安装方式,以便对转盘轴承施加组合力. 液压马达驱动小齿轮且与陪试转盘轴承啮合,带动主试转盘轴承旋转.
图 4
选取内齿式单排球四点接触转盘轴承为实验对象,其相关参数如表1所示. 如图5所示为转盘轴承结构及传感器安装示意图. 内齿式转盘轴承的内圈(带齿)通过螺栓与旋转件相连,带动机械设备回转运行,外圈与底座固定相连. 转盘轴承受到轴向力、径向力和倾覆力矩的合力作用,周向载荷呈对称方式分布,承载力最大位置处为磨损危险点,该位置的健康状态直接反映转盘轴承的工作性能. 为了避免滚道热处理导致重复淬火,滚道必然存在一处未处理区域,即软带,软带的承载能力较低. 综上考虑,在转盘轴承相隔90°处设置振动传感器,并安装在最大承载力所在位置和靠近软带的区域. 内齿式结构的外圈固定内圈旋转,因此振动传感器安装在外圈上. 振动传感器采用吸附式,温度传感器主要监测滚道内部润滑脂温度变化,安装在定圈注油口处. 对转盘轴承施加极限载荷,并以4 r/min的转速进行加速寿命实验,安装完成后的实验台装置,如图6所示.
表 1 转盘轴承实验台性能参数
Tab.1
| 参数 | 数值 | 参数 | 数值 | |
| 轴向力/kN | 0~750 | 滚道中心直径/mm | 730 | |
| 径向力/kN | 0~101.8 | 滚珠直径/mm | 22 | |
| 倾覆力矩/(kN·m) | 0~880 | 初始压力角/(°) | 45 | |
| 转速/(r·min−1) | 0.5~5.0 | 曲率比 | 1.06 | |
| 试件直径/mm | 600~2 000 | 滚珠数量 | 91 |
图 5
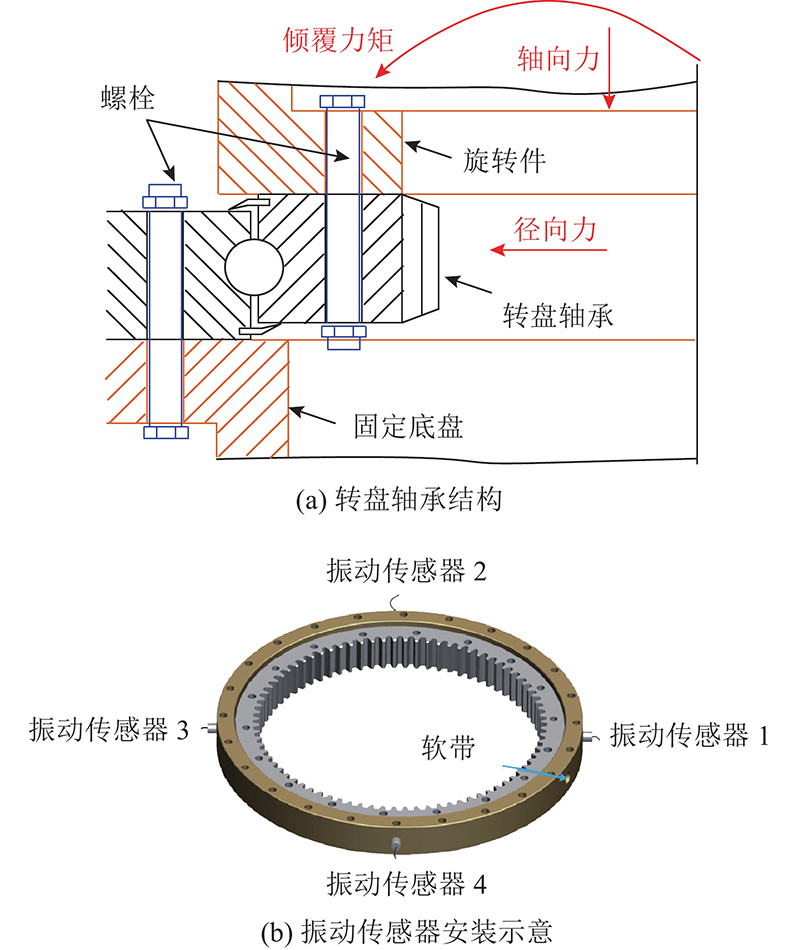
图 6

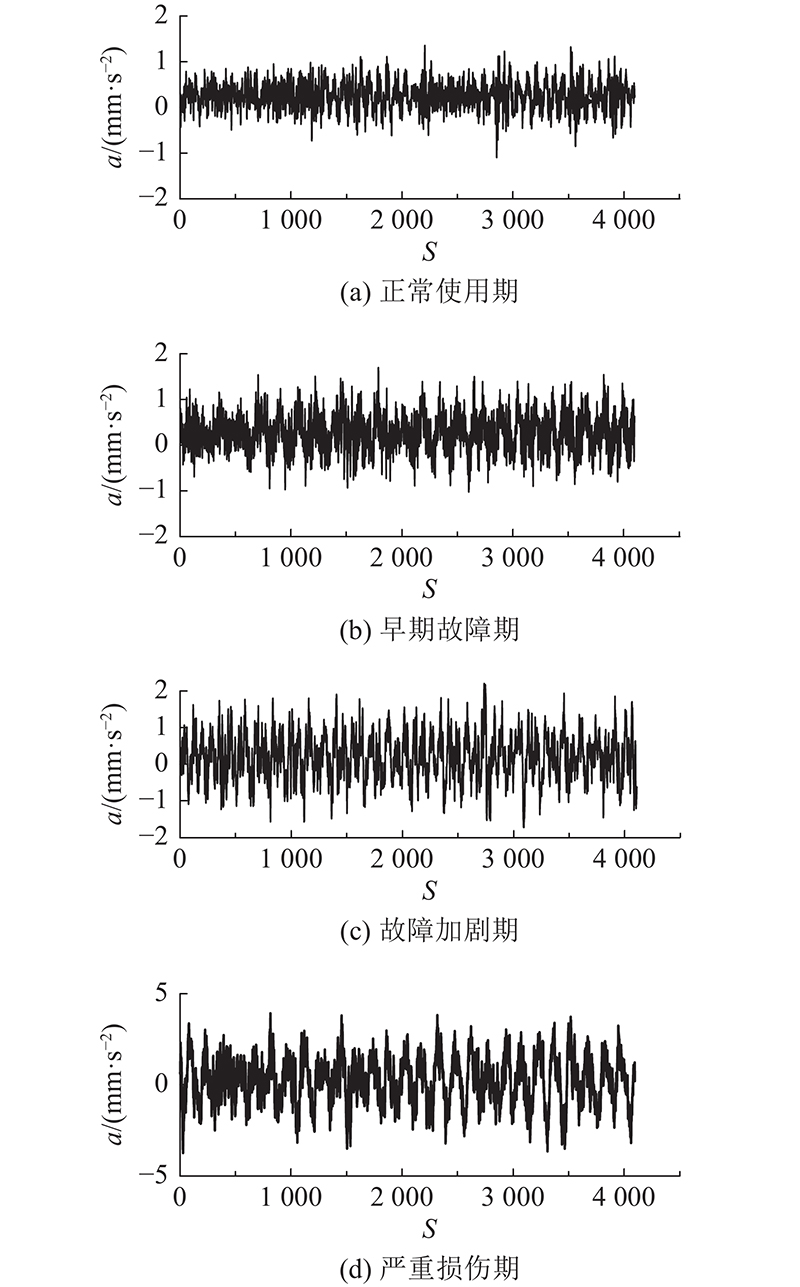
转盘轴承在加速疲劳载荷下完成全寿命实验,运行结束时,整个实验装置已经处于卡死状态,大部分连接螺栓断裂,此时转盘轴承已处于磨损失效状态,即为寿命失效点. 如图7所示为失效时刻的内外圈滚道、滚珠和隔离块损伤示意图,此时的外圈磨损点蚀十分严重,部分滚珠出现表面剥落的情况. 通过对比发现,靠近软带的4号振动信号的幅值最大,且全寿命变化最为明显,因此选用4号振动信号进行分析. 转盘轴承从正常运行使用到失效的过程中,转盘轴承的性能经历4个阶段:正常使用期、早期故障期、故障加剧期和严重损伤期。如图8所示为转盘轴承不同阶段的振动信号变化图(由于全寿命数据较为庞大,图中只显示部分数据). 图中,a为加速度,S为采样点数. 可以看出,振动信号随着转盘轴承故障的萌生和加剧不断增大. 在正常使用期的振动信号主要被高频噪声占据,进入故障后,可以从信号图中看出明显的周期性冲击现象,该现象在严重损伤期表现得最为明显. 因此振动信号可以反映出转盘轴承寿命周期的健康状态.
图 7

图 8
如图9所示为转盘轴承在全寿命过程中润滑脂温度和驱动力矩的变化趋势图. 图中,
图 9
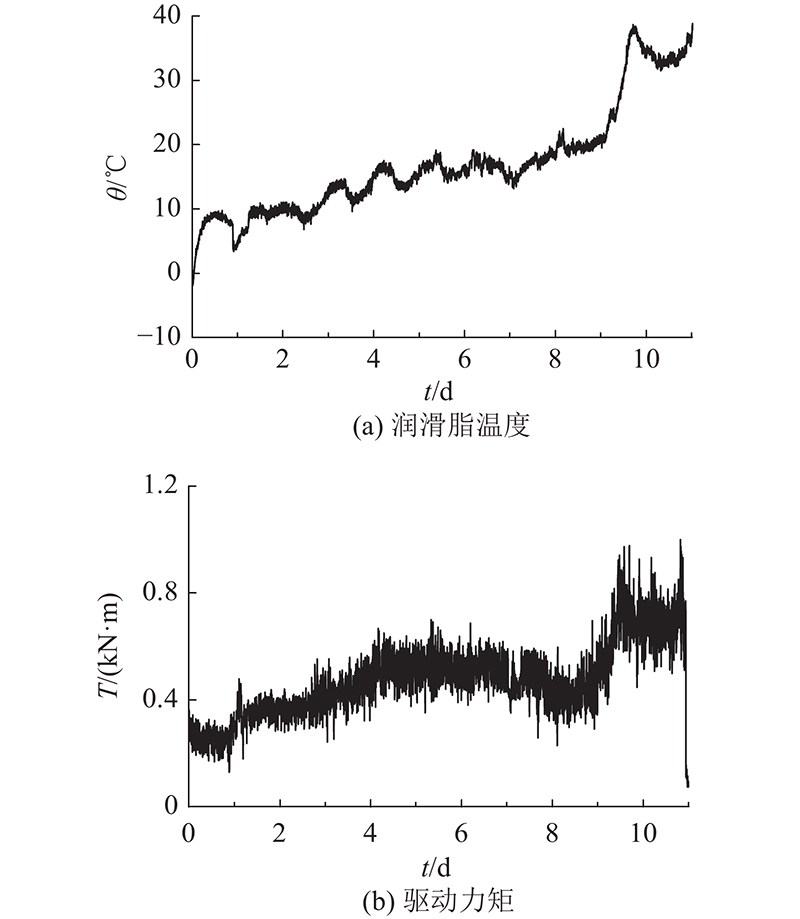
图 10
3.2. 实验数据处理与分析
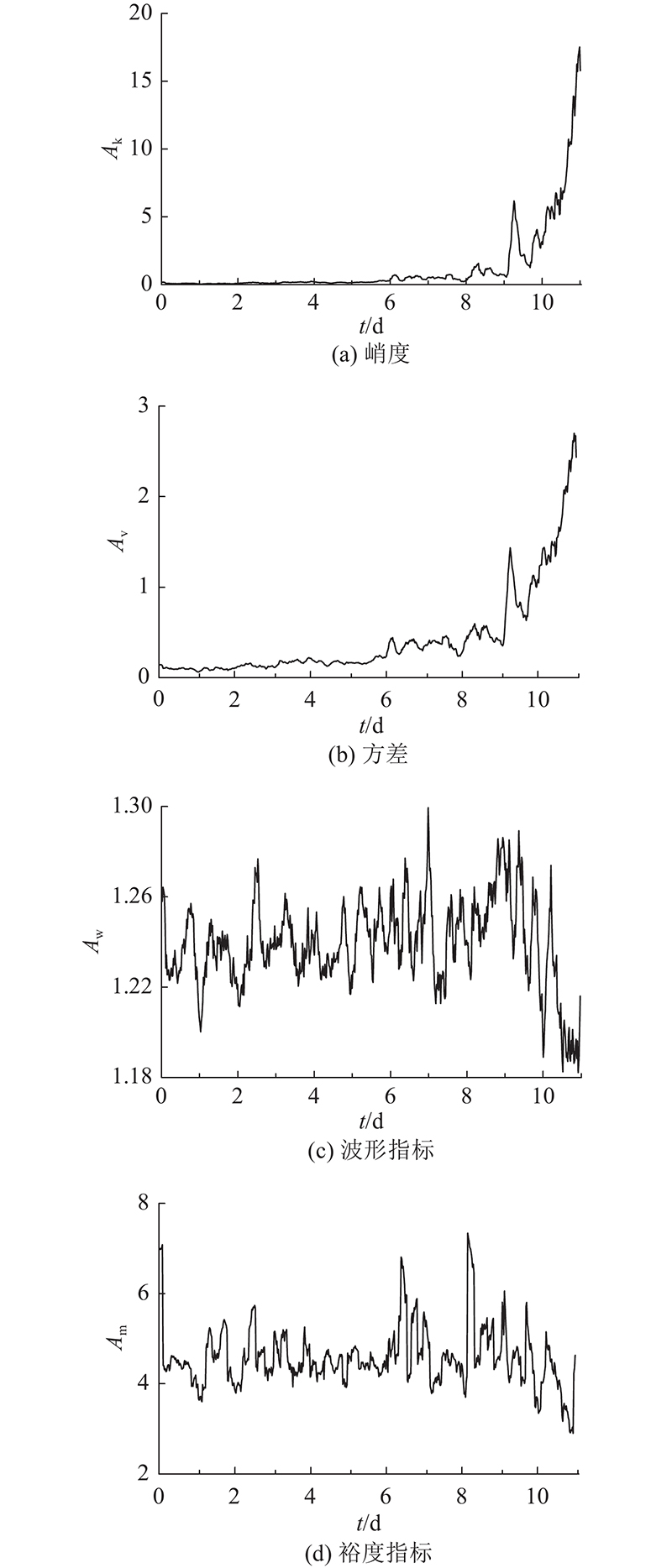
为了评估MLKELM-AE模型的寿命状态识别能力,分别从全寿命数据的4个阶段提取时域、时频域特征作为多领域特征输入. 时域方面选取节1.1所述的8个特征向量;时频域方面采用‘db3’小波包对振动信号进行小波分解,获得8个不同频带信号,分别计算每个频带的归一化小波包能量作为时频特征向量. 将8个时域特征和8个时频域特征组成16维特征向量集. 将4个寿命阶段的特征向量集归一化后划分成训练样本和测试样本,训练/测试样本的输入为16维特征向量集,输出为该时刻对应的寿命状态值,共600个样本数,每组状态分别设置150个样本,其中训练样本100个,测试样本50个. MLKELM-AE模型的选择惩罚系数C和核参数σ寻优范围分别为0.1~1 000.0和0.01~100.00.
MLKELM-AE模型由多层KELM-AE和决策层KELM组成,KELM-AE层数是影响模型精度的重要因素. 为了探究KELM-AE层数对MLKELM-AE识别精度和效率的影响,分别采用单层、多层网络模型进行寿命状态识别,结果如图11所示. 图中,P为识别精度,L为KELM-AE层数. 可以看出,当KELM-AE层数从1增加到3时,MLKELM-AE模型的识别精度保持在稳定状态,且在L=3时到达峰值,为99.5%;随后精度急剧下降,主要原因是随着模型层数的增加,模型出现过拟合现象. 此外,随着模型层数增加,训练时间也明显上升. 为了权衡训练精度和计算效率,选择3层KELM-AE构成MLKELM-AE寿命状态识别模型.
图 11
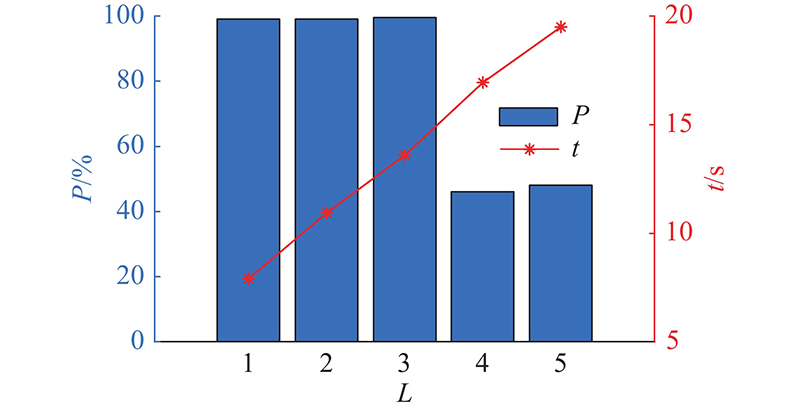
图 11 不同核极限学习机自编码器层数的识别结果
Fig.11 Recognition result of different layers of kernel extreme learning machine based auto-encoder
从转盘轴承振动信号中提取的16维多领域特征通过多层KELM-AE学习后,寿命状态信息被不断提取出来. 通过矩阵运算,第3层KELM-AE输出为高层次的抽象特征. 如图12所示,为了量化多层KELM-AE中学习后的特征信息,将第3层KELM-AE的输出特征执行核主元分析(kernel principal component analysis,KPCA),取前3个特征向量进行三维可视化操作. 图中,f1为降维后第1维特征数据,f2为降维后第2维特征数据,f3为降维后第3维特征数据. 可以看出,通过多层KELM-AE学习后,基本可以区分转盘轴承的4个寿命阶段. 为了进一步对比多层KELM-AE的逐层学习能力,分别对原始多领域特征及多层KELM-AE的逐层输出特征进行KPCA量化. 引入类内距离Sw、类间距离Sb来比较不同特征的分类能力[24],表达式分别为
图 12
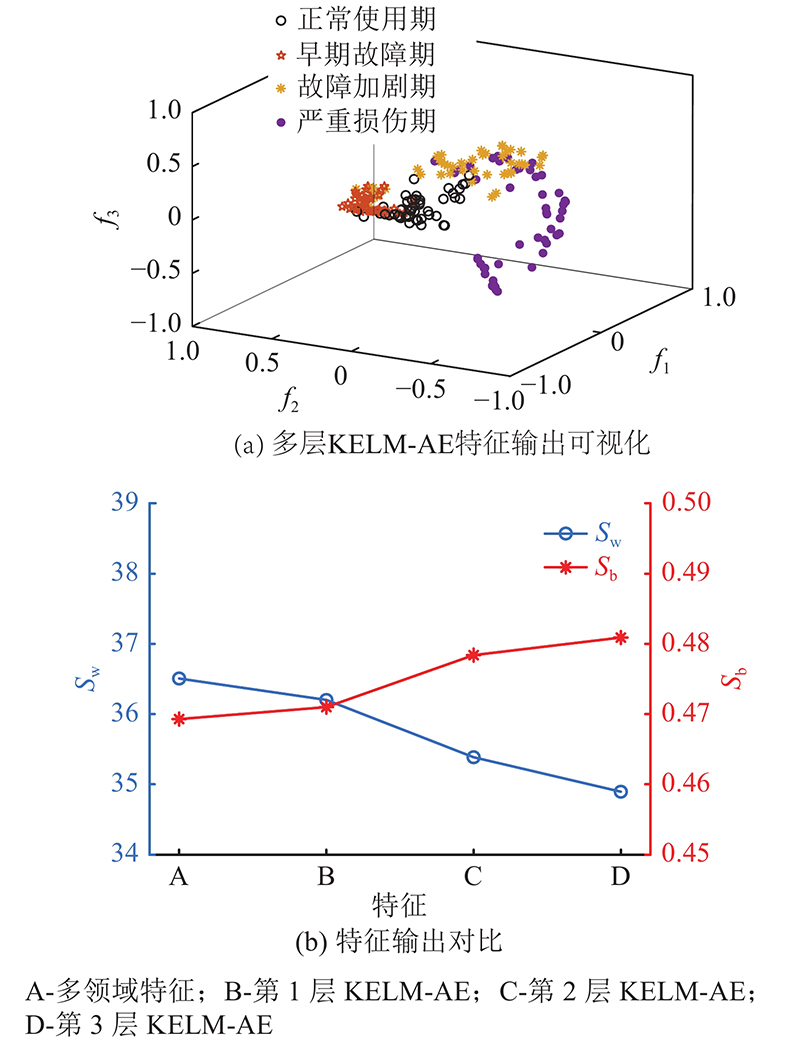
图 12 多层核极限学习机自编码器学习后的特征输出
Fig.12 Feature output after learning of multi-layer kernel extreme learning machine based auto-encoder
式中: f为类别Ci(i=1, 2,···, c)中的特征,
为了验证本研究所提多领域特征提取的有效性,分别将时域、时频域和多领域特征作为MLKELM-AE模型输入计算识别结果. 如图13所示为MLKELM-AE模型在最优超参数组合下,不同领域特征的寿命识别结果混淆矩阵. 可以看出,时域−时频域特征的寿命识别率为99.5%,仅寿命状态2中的1个样本被误分为状态3中,其余寿命状态2、3和4的识别率都达到100%.时频域特征模型总的识别率为97%,寿命状态1、2和4中各有1个样本被误分,状态3有3个样本被误分. 时域特征模型的识别率最低,为96.5%,尽管寿命状态3识别率达到100%,但其余状态都不同程度地存在误分现象. 结果表明,相比单领域特征,多领域特征更能全面反映转盘轴承的寿命状态.
图 13
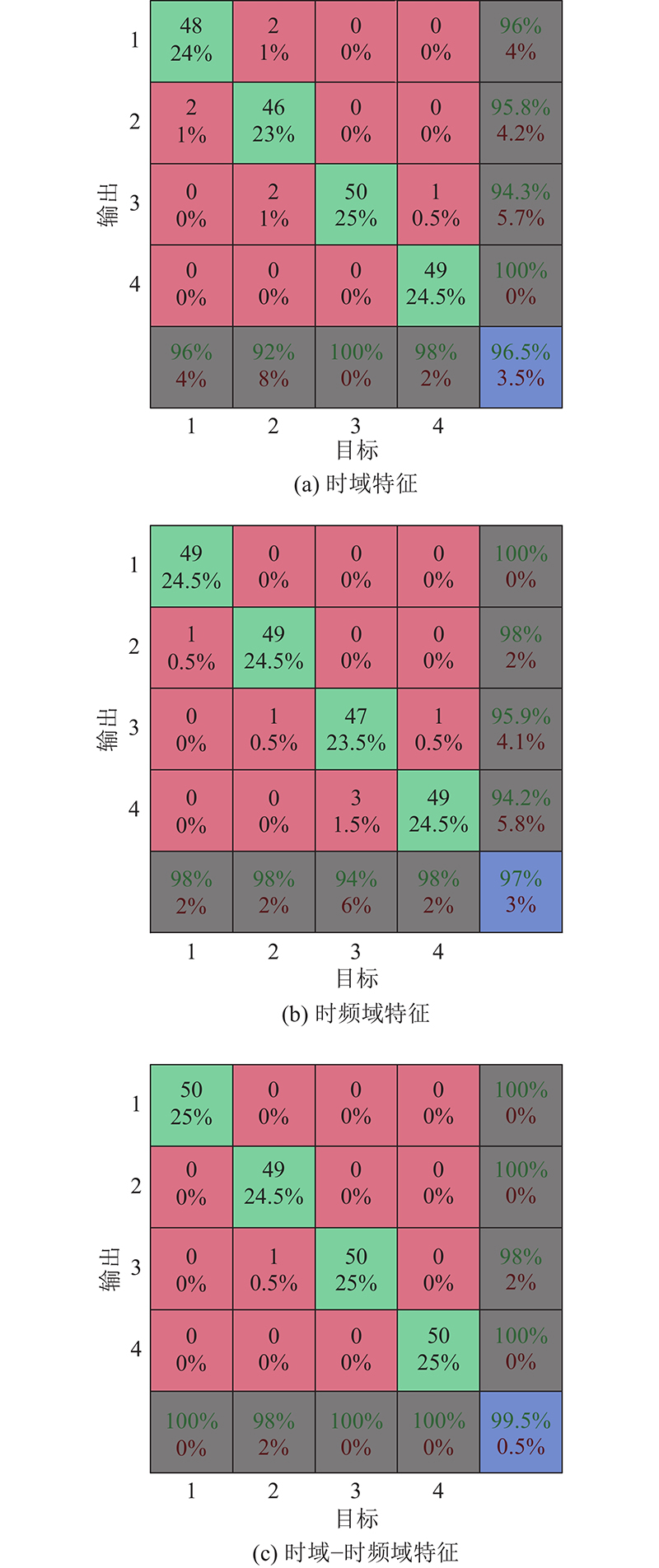
图 13 不同领域特征下寿命状态识别结果的混淆矩阵
Fig.13 Confusion matrix of life condition recognition result under different domain features
为了探究本研究所提MFO的参数寻优性能,将粒子群优化算法(particle swarm optimization, PSO)、遗传算法(genetic algorithm, GA)和蝙蝠算法(bat algorithm, BA)作为对比算法,种群数量设置为50,4种模型对转盘轴承寿命状态的识别结果如表2所示. 表中,tT为训练时间. 本研究所提MFO-MLKELM-AE识别方法的预测精度优于PSO-MLKELM-AE和BA-MLKELM-AE,且模型的训练时间最短. 尽管GA-MLKELM-AE识别精度与MFO-MLKELM-AE相同,但在训练时间上慢于MFO-MLKELM-AE. 因此,与PSO、GA和BA相比,本研究所提方法能够在保证识别准确性的同时较快地达到最优适应度值,具有更好的稳定性和鲁棒性. 为了验证参数优化的有效性,对MLKELM-AE模型中的惩罚系数C和核参数σ进行随机取值,不同领域特征的寿命状态识别精度如表3所示. 表中,Pt为时域特征输入的识别精度,Ptf为时频域特征输入的识别精度,Pttf为时域−时频域特征输入的识别精度. 如表2所示,尽管MLKELM-AE的训练时间远低于参数优化MLKELM-AE模型,但前者识别准确率远不如后者. 一方面说明KELM-AE层与层相互独立,单层KELM-AE的权值和输出仅与输入相关,验证了MLKELM-AE具有高效快速的优点;另一方面说明C、σ的组合取值对MLKELM-AE模型性有较大影响,验证了本研究利用群智能算法来优化MLKELM-AE模型中超参数的必要性.
表 2 多领域特征下不同优化算法的寿命识别结果
Tab.2
| 模型 | P/% | tT/s |
| MFO-MLKELM-AE | 99.5 | 13.596 |
| PSO-MLKELM-AE | 99.0 | 13.796 |
| GA-MLKELM-AE | 99.5 | 14.920 |
| BA-MLKELM-AE | 98.5 | 20.414 |
| MLKELM-AE | 90.5 | 0.124 |
表 3 不同领域特征下参数优化与未优化的寿命状态识别精度
Tab.3
| % | |||
| 模型 | Pt | Ptf | Pttf |
| MFO-MLKELM-AE | 96.5 | 97.0 | 99.5 |
| MLKELM-AE | 85.5 | 86.5 | 90.5 |
将MLKELM-AE寿命识别模型的分类性能分别与多层极限学习机自编码器(multi-layer extreme learning machine based auto-encoder, MLELM-AE)、单层KELM和ELM模型进行对比。其中MLELM-AE模型由多层ELM-AE和决策层ELM构成. MLKELM-AE模型参数采用上述最佳参数,为了进行准确比较,分别采用MFO优化MLELM-AE和ELM的权重和偏置、KELM的惩罚系数和核参数,结果如表4所示. 表中,tt为测试时间. 可以看出,本研究所提改进MFO-MLKELM-AE比其他3种传统模型识别精度高。MFO-MLKELM-AE和MFO-MLELM-AE识别精度优于MFO-KELM和MFO-ELM。加入核函数使KELM克服了ELM中因随机矩阵H导致模型输出的随机波动,MFO-MLKELM-AE和MFO-KELM识别精度分别优于MFO-MLELM-AE和MFO-ELM模型。多层KELM-AE结构提高了多维非线性特征的映射能力,使MFO-MLKELM-AE模型具有更好的泛化性和鲁棒性. 尽管核函数和多层结构导致MFO-MLKELM-AE的训练负担沉重,但是4种方法的测试时间相差不大,说明本研究所提方法能够在满足预测精度的同时进行在线应用. 为了进一步比较多领域特征对不同寿命识别模型的影响,将时域和时频特征分别作为模型输入进行比较,结果如表5所示. 可以看出,多领域特征识别精度明显高于单领域特征;无论是单领域特征还是多领域特征,MFO-MLKELM-AE识别精度都高于MFO-MLELM-AE、MFO-KELM和MFO-ELM模型. 说明本研究所提的多领域特征结合MFO-MLKELM-AE模型能够有效识别转盘轴承的寿命状态,满足实际工程需求.
表 4 多领域特征下不同识别模型的寿命状态识别结果
Tab.4
| 模型 | P/% | tT/s | tt/s |
| MFO-MLKELM-AE | 99.5 | 13.596 | 0.016 |
| MFO-KELM | 97.0 | 5.223 | 0.015 |
| MFO-MLELM-AE | 91.5 | 4.763 | 0.012 |
| MFO-ELM | 88.5 | 1.872 | 0.002 |
表 5 不同领域特征下不同识别模型的寿命状态识别精度
Tab.5
| % | |||
| 模型 | Pt | Ptf | Pttf |
| MFO-MLKELM-AE | 96.5 | 97 | 99.5 |
| MFO-KELM | 94.5 | 95 | 97.0 |
| MFO-MLELM-AE | 84.5 | 88 | 91.5 |
| MFO-ELM | 82.5 | 85 | 88.5 |
除了振动特征信号,转盘轴承损伤还能通过特征信号(如润滑脂温度、驱动力矩)形成可感知表现. 为了满足状态识别对信号丰富性的要求,充分利用多传感器信息,融合多个特征指标来表达转盘轴承的运行状态,利用上述16维振动特征和2维辅助参数(润滑脂温度、驱动力矩均值特征)作为模型输入,建立寿命状态识别模型,结果如表6所示. 表中,Pv为振动特征输入的识别精度,Pf为振动和辅助参数融合特征输入的识别精度. 可以看出,4组识别模型在辅助参数加入后识别结果都得到提高,说明辅助参数能够从不同角度提供更多的转盘轴承状态特征信息,从而提高状态识别模型的精度.
表 6 多传感器特征融合下不同识别模型的寿命状态识别精度
Tab.6
| % | ||
| 模型 | Pv | Pf |
| MFO-MLKELM-AE | 99.5 | 100.0 |
| MFO-KELM | 97.0 | 100.0 |
| MFO-MLELM-AE | 91.5 | 93.5 |
| MFO-ELM | 88.5 | 92.0 |
4. 结 论
(1)本研究所提基于时域和时频域的多领域特征提取方法,能够完整反映转盘轴承运行状态信息,提高寿命识别模型精度. 辅助参数(如润滑脂温度、驱动力矩)有利于进一步提高模型精度,说明辅助参数能提供更多的转盘轴承健康状态信息.
(2)堆叠多层KELM-AE的深度学习模型随着层数增多,类内距离不断减小,类间距离不断增加,多层KELM-AE学习后的特征区分效果优于原始多领域特征. 提出基于MFO的MLKELM-AE模型参数优化方法,有效减小模型参数对识别精度的影响,优化效果优于传统的群智能优化算法.
(3)相比于单层MFO-ELM和MFO-KELM,多层MFO-MLELM-AE、MFO-MLKELM-AE在处理非线性微弱特征时具有更强大的表征能力和分类优势;KELM采用核映射代替随机映射,提高了非线性特征映射能力.
(4)后续计划开展转盘轴承故障类型识别研究,提高算法对各类故障的普遍适用性和对复合故障的识别准确性.
参考文献
A review on data-driven fault severity assessment in rolling bearings
[J].DOI:10.1016/j.ymssp.2017.06.012 [本文引用: 1]
基于Wavelet leader和优化的等距映射算法的回转支承自适应特征提取
[J].
Adaptive feature extraction method for slewing bearing based on Wavelet leader and optimized isometric mapping method
[J].
基于数据驱动的回转支承性能退化评估方法
[J].
A multi-dimensional data-driven method for large-size slewing bearings performance degradation assessment
[J].
GEETHANJALI P. Analysis of statistical time-domain features effectiveness in identification of bearing faults from vibration signal
[J].DOI:10.1109/JSEN.2017.2727638 [本文引用: 1]
Condition monitoring of naturally damaged slow speed slewing bearing based on ensemble empirical mode decomposition
[J].DOI:10.1007/s12206-013-0608-7 [本文引用: 1]
Vibration analysis for large-scale wind turbine blade bearing fault detection with an empirical wavelet thresholding method
[J].DOI:10.1016/j.renene.2019.06.094 [本文引用: 1]
Degradation trend estimation of slewing bearing based on LSSVM model
[J].DOI:10.1016/j.ymssp.2016.02.031 [本文引用: 1]
基于改进模糊C均值的回转支承寿命状态识别
[J].DOI:10.13196/j.cims.2018.11.010 [本文引用: 2]
Life state recognition of slewing bearing based on improved fuzzy C-means
[J].DOI:10.13196/j.cims.2018.11.010 [本文引用: 2]
深度学习原理及应用综述
[J].DOI:10.11896/j.issn.1002-137X.2018.Z6.002 [本文引用: 1]
Review of principle and application of deep learning
[J].DOI:10.11896/j.issn.1002-137X.2018.Z6.002 [本文引用: 1]
Representational learning with ELMs for big data
[J].
Learning deep representations via extreme learning machines
[J].DOI:10.1016/j.neucom.2014.03.077 [本文引用: 1]
Denoising Laplacian multi-layer extreme learning machine
[J].DOI:10.1016/j.neucom.2015.07.058
Generalized extreme learning machine autoencoder and a new deep neural network
[J].DOI:10.1016/j.neucom.2016.12.027 [本文引用: 1]
神经网络极速学习方法研究
[J].DOI:10.3724/SP.J.1016.2010.00279 [本文引用: 1]
Research on extreme learning of neural networks
[J].DOI:10.3724/SP.J.1016.2010.00279 [本文引用: 1]
An insight into extreme learning machines: Random neurons, random features and kernels
[J].DOI:10.1007/s12559-014-9255-2 [本文引用: 1]
基于变量选择和核极限学习机的交通事件检测
[J].
Traffic incident detection based on variable selection and kernel extreme learning machine
[J].
滚动轴承多工况故障的特征自动选择核极限学习机智能识别方法
[J].
Intelligent identification method using kernel extreme learning machine for rolling bearing multi-working condition multi-feature automatic selection
[J].
Moth-flame optimization algorithm: a novel nature-inspired heuristic paradigm
[J].DOI:10.1016/j.knosys.2015.07.006 [本文引用: 1]
一种新颖的群智能算法: 飞蛾扑火优化算法
[J].
A novel swarm intelligence optimization algorithm: moth-flame optimization algorithm
[J].
Multi-label learning with kernel extreme learning machine autoencoder
[J].DOI:10.1016/j.knosys.2019.04.002 [本文引用: 1]
基于支持向量免疫集成预测的电信网络性能监控
[J].
Telecom networks performance monitoring based on artificial immune support vector regression
[J].
Subspace-based gearbox condition monitoring by kernel principal component analysis
[J].DOI:10.1016/j.ymssp.2006.07.014 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}