

随着时代的发展,新一代通用视频编码(versatile video coding, VVC)[1]应运而生. 相比上一代高效视频编码(high efficiency video coding, HEVC)[2],VVC的压缩效率提高了将近50%. 性能提升是由于VVC标准采用诸多新技术,包括帧内预测模式从HEVC使用的35个扩展到67个,多变换核选择[3]、低频不可分离变换[4]及多种划分模式[5]等. 在量化方面,从硬决策量化(hard decision quantization, HDQ)[6],到基于软决策量化(soft decision quantization, SDQ)[7]的率失真优化量化(rate distortion optimized quantization, RDOQ)[8],再到依赖性量化(dependent quantization, DQ)[9],这些新技术为VVC编码效率带来了显著提升,但编码复杂度急剧增加.
量化作为视频编码模块中较耗时的一个步骤,除了复杂的乘除法操作外,在RDOQ中还有更复杂的率失真优化(rate-distortion optimization, RDO)遍历操作,即每个预量化系数会有几个可选的量化值,通过RDO遍历过程得到最优的量化值. 乘除法和RDO遍历操作的计算复杂度非常高,许多变换单元(transform unit, TU)经常会被RDOQ量化为零系数块,即全零块(all zero block, AZB),且最终仅需传输一个全零编码标志位. 若能够在量化前将这些AZB提前判决出来,则可以省去RDOQ中复杂的乘除法、RDO代价计算比较和相关上下文模型更新等繁琐的步骤,达到减少编码复杂度的目的.
近年来,针对视频编码器中AZB的预判决已被广泛探索. 在H.264/AVC[10]上的研究,如Wang等[11]在H.264上应用高斯分布研究变换系数,提出利用绝对变换误差和检测AZB的方法. Zhao等[12]在H.264上,基于AZB的统计特征建立阈值查找表,通过阈值对AZB进行判决. Yang等[13]将软决策量化应用到H.264中. 在HEVC中的研究,如Lee等[14]通过对变换后的哈达玛系数再次进行哈达玛变换,通过比较系数与固定阈值来检测AZB. Cui等[15]提出混合的AZB检测方法,通过单个系数阈值和拉普拉斯分布建模,得到2个AZB检测阈值,取2个阈值中较小的作为最终阈值. Yin等[16]提出多阶段AZB检测方法,分多个阶段对AZB进行检测,通过阈值和机器学习对AZB进行判决.
已有的算法均是在H.264和HEVC上实现的,但在新一代视频编码标准VVC中,由于新的划分模式,导致多种不规则的非方形TU的存在而不再适用. 本文针对VVC,提出全新的VVC分步AZB判决快速算法,以加速量化的方式来减少编码器复杂度.
1. 算法简介
图 1
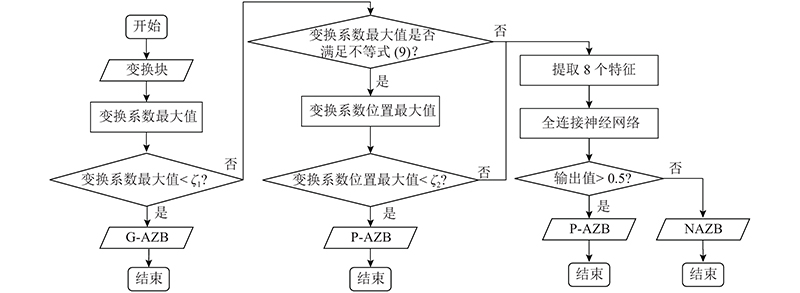
1)G-AZB:若TU在经过HDQ后,所有变换系数都被量化为零,则称为真全零块(genuine all zero block, G-AZB).
2) P-AZB:若TU中的所有非零系数被RDOQ进一步量化为零,则称为伪全零块(pseudo all zero block, P-AZB).
3) NAZB:若TU中的所有非零系数经过RDOQ后存在非零系数,则称为非全零块(non-all zero block, NAZB).
从图1可以看出本文算法的流程. 1)比较变换系数最大值与阈值
G-AZB、P-AZB和NAZB在2个量化参数(quantization parameter, QP)下的不同M(TU中系数个数)的比例如图2所示,用P表示对应元素所占的百分比. 仅列出较具有代表性的M为64、128、256和512的3种AZB的占比情况,对于没有列出的M,即16、32、1 024、2 048和4 096的情况,AZB的占比情况类似.
图 2
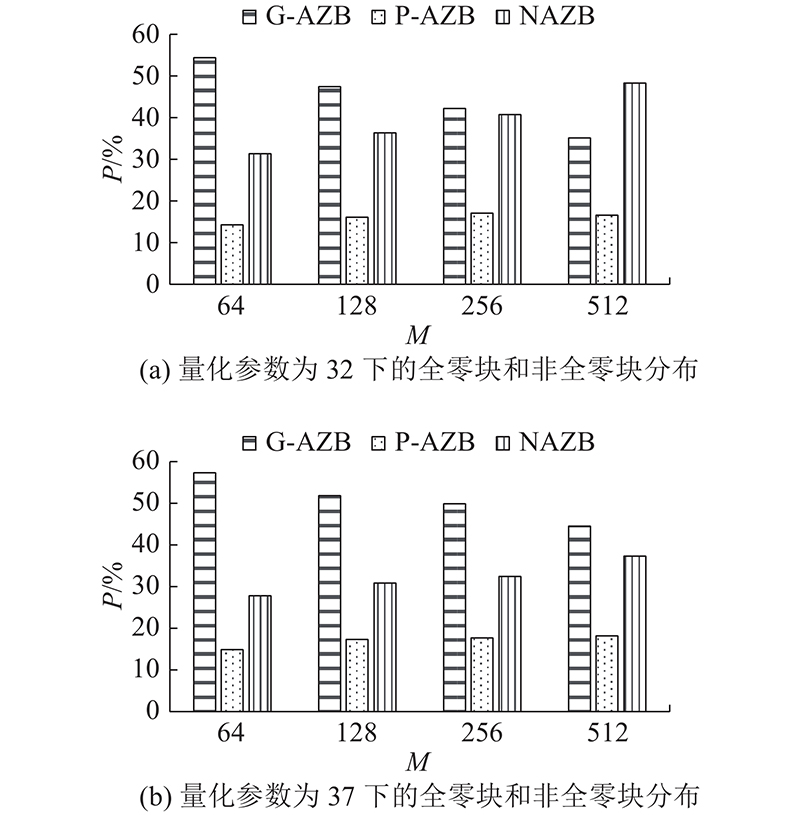
从图2可以看出,G-AZB的比例与QP呈正相关,与M呈负相关;NAZB的比例与QP呈负相关,与M呈正相关. G-AZB和P-AZB的比例相对较大,尤其是在QP较大的情况下,因此对这些AZB进行检测是非常有意义的.
2. G-AZB检测阈值模型
为了推导G-AZB检测阈值,从HDQ入手,带有死区的HDQ定义[6]为
式中:
式中:
G-AZB是TU经过死区HDQ后为全零的块,因此从提到的死区HDQ公式入手,考虑到向下取整,即只要是小于1的数,都会被向下取整为0. 对于G-AZB,每个量化系数一定小于1,即
将
进一步化简,可得
将式(6)的右端作为G-AZB的检测阈值,即
只要
由于
3. P-AZB检测阈值模型
通过阈值
若TU满足
则TU经过死区HDQ一定会被量化为G-AZB. 相应地,若变换块满足
则这样的TU虽然被死区HDQ量化为非零,但是有可能会被RDOQ进一步量化为AZB,即P-AZB.
对于变换系数最大值满足式(9)的TU,考虑满足下式的变换系数:
假设满足式(10)的变换系数位置分别为
式中:
4. 基于机器学习的P-AZB检测
尽管检测了部分P-AZB,但是剩余一些难以检测的P-AZB无法通过2)步的自适应阈值公式检测出来. 通过分析这些P-AZB,找寻8个影响TU量化为全零与否的影响因子. 这些影响因子涉及系数级、TU级和上下文级特征,基于机器学习对这些特征进行离线训练,训练的网络能够较好地检测出这些P-AZB.
4.1. 网络结构
表 1 支持向量机与全连接神经网络算法的对比
Tab.1
| M | | | |
| SVM | FCNN | ||
| 64 | 87.17 | 95.43 | 3.535 |
| 128 | 83.79 | 91.65 | 3.535 |
| 256 | 82.97 | 93.28 | 3.535 |
| 512 | 80.62 | 93.43 | 3.535 |
从表1可以看出,2种算法在判决AZB的时间复杂度方面基本无差异,但是FCNN的检测精度优于SVM. 由于在实际判决过程中,不同序列在不同QP下的样本存在一定差异,FCNN能够比SVM更好地应对所带来的差异. 一段视频序列的样本数据较大,FCNN更适合对较大样本进行训练. 综合以上几点原因,使用FCNN算法进行第3步的AZB判决.
图 3
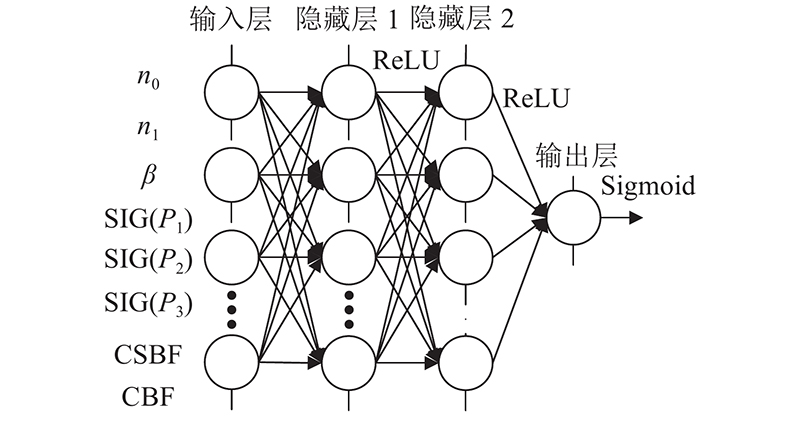
4.2. 相关特征
4.2.1. 系数级特征
经过大量统计发现,若某个TU的预量化系数s大于或等于2,则这个TU极大概率是NAZB.
图 4
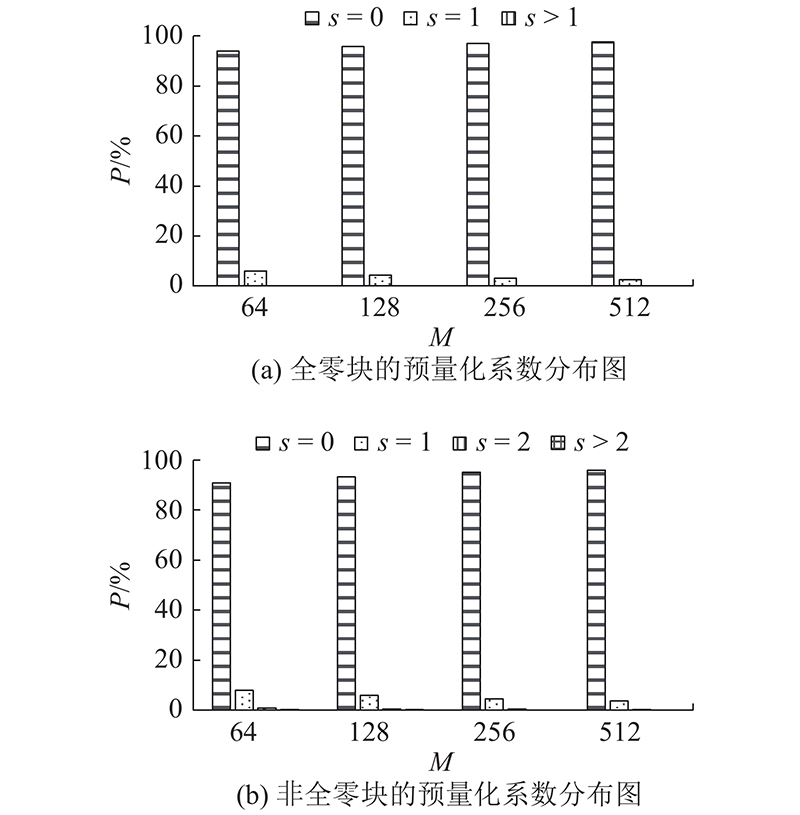
式中:
由于VVC新加入了“高频置零”操作,即对采用DCT-II变换且宽或高为64的TU,仅保留左上角宽或高为32的部分,对其他系数进行“置零”操作.
式中:W和H分别为TU的宽和高;
图 5
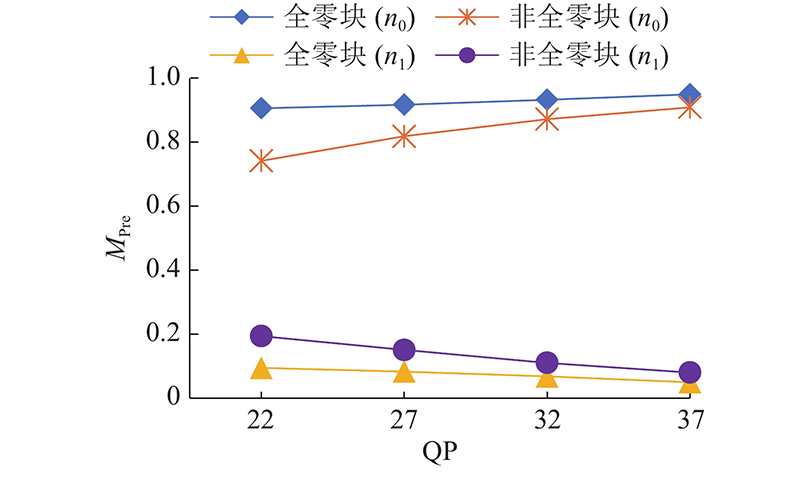
预量化系数等于0或1的数量可以作为区分P-AZB和NAZB的有用特征.
4.2.2. TU级特征
残差块经过变换后,能量会集中在TU的左上角低频区域. 考虑绝对变换系数和:
式中:
对于量化结果是非零的残差块来说,变换后集中在左上角低频区域的能量较大;对于量化结果是全零的残差块来说,变换后集中在左上角低频区域的能量较小.
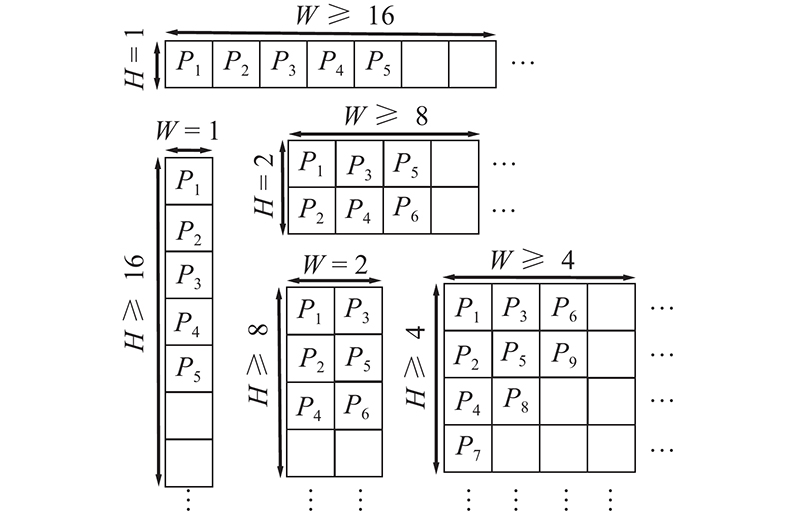
如图6所示,对各种大小的TU中的系数位置进行标注. 为了更加准确地表示低频区域的能量,对于4×4、2×8、1×16这样较小的TU,取低频区域
图 6
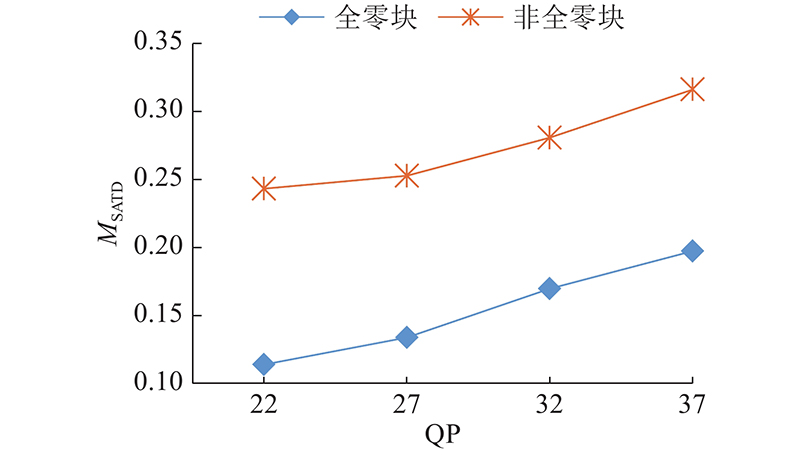
不同M的部分能量表示为
式中:
图 7
4.2.3. 上下文级特征
在上一代的视频编码标准HEVC中,上下文自适应二进制算术编码(context-based adaptive binary arithmetic coding, CABAC)[19]基于概率转换表,在64种不同的概率状态之间进行转换. 在VVC中,涉及上下文的所有计算都通过公式完成,无须查表运算. 采用多假设概率更新模型[5],使用2个与上下文模型相关联的概率,这2个概率分别以不同的自适应速率独立更新. 在更新过程中,某一语法元素在较小可能出现的符号(least probability symbol, LPS)和较大可能出现的符号(most probability symbol, MPS)之间进行切换.
为了推导出LPS和MPS的概率与码率之间的关系,从信息论出发,基于香农信源编码定理,可以得到概率为
即
对这一组MPS和LPS的概率进行归一化,有
式中:
在RDOQ中涉及众多的语法元素,只利用部分语法元素来区分P-AZB和NAZB.
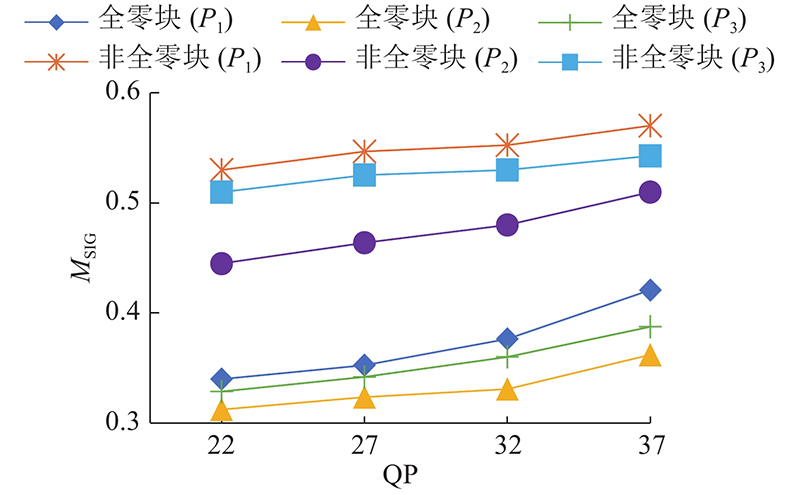
当前TU内的某个系数采用LPS符号或者MPS符号进行编码,与周围系数有很大关系. 考虑语法元素量化系数标识(significant coefficient flag, SIG)所对应的概率.
由于低频区域的变换系数经过RDOQ很难量化为0,SIG = 1的情况在低频区域有着非常大的概率作为MPS符号进行编码. 相应地,SIG = 0的情况在低频区域有着非常大的概率作为LPS符号进行编码. 取图6中
图 8
TU中当前系数组(coefficient group, CG)是否为全零CG,与周围CG有关. 考虑语法元素整个CG的编码标识(coded sub-block flag, CSBF)所对应的概率.
类似上文提到的量化系数标识SIG,语法元素CSBF=1的情况在低频区域有很大概率作为MPS符号进行编码. 选取TU左上角第1个CG的语法元素CSBF进行研究.
由于VVC的划分模式会产生很多类型的不规则TU,所选取的CG不都是规则的4×4的CG,如下所示:
式中:L为CG的尺寸.
当前TU是否被量化为全零,与周围TU有关,即考虑语法元素整个TU的编码标识(coded block flag, CBF)所对应的概率.
P-AZB和NAZB在不同QP下的CSBF和CBF所对应概率的对比情况与系数级特征、TU级特征和SIG的分布均类似,即AZB与NAZB均存在一定的可区分度. 将语法元素CSBF和语法元素CBF所对应的概率分别作为第4个和第5个上下文级特征.
表 2 全零块和非全零块的不同特征比较
Tab.2
| 量化块 | M | 系数级特征 | TU级特征 | 上下文级特征 | |||||||
| | | | SIG( | SIG( | SIG( | CSBF | CBF | ||||
| AZB | 64 | 0.9258 | 0.0742 | 0.1537 | 0.3725 | 0.3323 | 0.3546 | 0.0789 | 0.2932 | ||
| AZB | 128 | 0.9383 | 0.0617 | 0.1051 | 0.3729 | 0.3516 | 0.3621 | 0.0826 | 0.3922 | ||
| AZB | 256 | 0.9488 | 0.0512 | 0.0677 | 0.3870 | 0.3586 | 0.3783 | 0.0939 | 0.4193 | ||
| AZB | 512 | 0.9530 | 0.0470 | 0.0426 | 0.3946 | 0.3622 | 0.3825 | 0.0948 | 0.4244 | ||
| NAZB | 64 | 0.8350 | 0.1337 | 0.2734 | 0.5499 | 0.4958 | 0.5371 | 0.1340 | 0.6625 | ||
| NAZB | 128 | 0.8602 | 0.1141 | 0.2046 | 0.5467 | 0.4944 | 0.5284 | 0.1267 | 0.6523 | ||
| NAZB | 256 | 0.8696 | 0.1088 | 0.1473 | 0.5334 | 0.4891 | 0.5209 | 0.1235 | 0.6200 | ||
| NAZB | 512 | 0.8725 | 0.1061 | 0.1006 | 0.5323 | 0.4879 | 0.5155 | 0.1200 | 0.5648 | ||
5. 实验结果与分析
5.1. 实验结果
5.1.1. 性能评估
介绍提出的VVC分步AZB判决快速算法在RD性能和编码复杂度方面的表现. 所有实验均是在关闭DQ且打开RDOQ的条件下,在VVC测试平台VTM-10.0上实现的. 仿真是根据联合视频探索小组(joint video exploration team, JVET)通用测试条件(common test conditions,CTC)[20]来进行的,通过每个阶段对AZB的判决,以此来加速量化进程,减少计算复杂度. QP值设定为
式中:
表 3 LDB配置下的编码性能对比
Tab.3
| 类别 | 文献[14]方法 | 文献[15]方法 | 文献[16]方法 | 本文算法 | |||||||
| | BD-Rate/% | | BD-Rate/% | | BD-Rate/% | | BD-Rate/% | ||||
| B | 5.02 | 1.86 | 4.76 | 1.56 | 5.82 | 1.45 | 9.15 | 0.62 | |||
| C | 4.91 | 1.75 | 4.06 | 1.59 | 4.37 | 1.64 | 7.06 | 0.51 | |||
| D | 4.82 | 1.82 | 4.47 | 1.62 | 4.42 | 1.31 | 6.91 | 0.40 | |||
| E | 4.89 | 1.82 | 3.64 | 1.52 | 4.26 | 1.33 | 6.66 | 0.41 | |||
| F | 4.81 | 1.80 | 4.37 | 1.54 | 4.91 | 1.22 | 7.13 | 0.35 | |||
| 平均值 | 4.890 | 1.810 | 4.260 | 1.566 | 4.756 | 1.390 | 7.382 | 0.458 | |||
表 4 RA配置下的编码性能对比
Tab.4
| 类别 | 文献[14]方法 | 文献[15]方法 | 文献[16]方法 | 本文算法 | |||||||
| | BD-Rate/% | | BD-Rate/% | | BD-Rate/% | | BD-Rate/% | ||||
| A1 | 5.92 | 1.98 | 6.18 | 1.34 | 6.90 | 1.37 | 8.90 | 0.59 | |||
| A2 | 5.67 | 1.82 | 5.45 | 1.45 | 6.21 | 1.37 | 9.15 | 0.53 | |||
| B | 4.48 | 1.89 | 4.17 | 1.53 | 4.33 | 1.43 | 6.54 | 0.58 | |||
| C | 4.33 | 1.73 | 3.93 | 1.56 | 4.19 | 1.75 | 6.97 | 0.61 | |||
| D | 4.36 | 1.82 | 4.36 | 1.55 | 4.09 | 1.59 | 6.14 | 0.52 | |||
| F | 3.13 | 1.87 | 2.90 | 1.53 | 3.08 | 1.51 | 5.72 | 0.62 | |||
| 平均值 | 4.648 | 1.852 | 4.498 | 1.493 | 4.800 | 1.503 | 7.237 | 0.575 | |||
在LDB配置下,提出的方案在性能平均损失仅为0.458%的前提下,节省了7.382%的编码时间;将文献[14~16]方法用于VTM10.0的方案,平均分别节省了4.890%、4.260%、4.756%的编码时间,性能平均分别损失了1.810%、1.566%、1.390%. 在RA配置下,本文方案的编码时间平均节省了7.237%,性能仅平均损失0.575%. 将文献[14~16]方法用于VTM10.0的方案在编码时间可以分别减少4.648%、4.498%、4.800%的情况下,性能分别损失了1.852%、1.493%、1.503%. 与将文献[14~16]的部分方法用于VTM10.0的实验结果进行比较. 可以看出,提出的方案在LDB和RA 2个配置下,总编码节省时间和编码性能方面均有较大的优势,在性能损失几乎可以忽略的情况下时间复杂度有了较大的降低, 这对编码器优化有着重要的意义.
5.1.2. AZB检测精度
在提出的AZB判决快速算法中,对于AZB的检测存在一定的误差,即有可能会将AZB判决为NAZB,或者将NAZB判决为AZB.
AZB检测精度一般使用2个参数进行评估,即FNR(false negative rate)和FPR(false positive rate). 通常,这2个参数定义如下:
式中:TP为AZB被检测为AZB的数量,FN为AZB被检测为NAZB的数量,FP为NAZB被检测为AZB的数量,TN为NAZB被检测为NAZB的数量.
表 5 LDB配置下的检测精度对比
Tab.5
| 类别 | 文献[14]方法 | 文献[15]方法 | 文献[16]方法 | 本文算法 | |||||||
| FNR | FPR | FNR | FPR | FNR | FPR | FNR | FPR | ||||
| B | 0.333 | 0.101 | 0.081 | 0.090 | 0.082 | 0.076 | 0.043 | 0.040 | |||
| C | 0.388 | 0.111 | 0.089 | 0.087 | 0.102 | 0.090 | 0.060 | 0.051 | |||
| D | 0.426 | 0.116 | 0.084 | 0.092 | 0.080 | 0.110 | 0.040 | 0.078 | |||
| E | 0.481 | 0.096 | 0.098 | 0.084 | 0.101 | 0.109 | 0.066 | 0.073 | |||
| F | 0.469 | 0.099 | 0.097 | 0.089 | 0.087 | 0.087 | 0.074 | 0.061 | |||
| 平均值 | 0.419 | 0.105 | 0.090 | 0.088 | 0.090 | 0.094 | 0.057 | 0.061 | |||
表 6 RA配置下的检测精度对比
Tab.6
| 类别 | 文献[14]方法 | 文献[15]方法 | 文献[16]方法 | 本文算法 | |||||||
| FNR | FPR | FNR | FPR | FNR | FPR | FNR | FPR | ||||
| A1 | 0.457 | 0.108 | 0.093 | 0.109 | 0.105 | 0.094 | 0.071 | 0.076 | |||
| A2 | 0.355 | 0.105 | 0.096 | 0.110 | 0.098 | 0.104 | 0.074 | 0.078 | |||
| B | 0.508 | 0.115 | 0.107 | 0.100 | 0.087 | 0.089 | 0.053 | 0.071 | |||
| C | 0.456 | 0.124 | 0.108 | 0.103 | 0.086 | 0.077 | 0.067 | 0.052 | |||
| D | 0.536 | 0.099 | 0.090 | 0.105 | 0.083 | 0.086 | 0.048 | 0.063 | |||
| F | 0.655 | 0.105 | 0.088 | 0.087 | 0.095 | 0.097 | 0.057 | 0.067 | |||
| 平均值 | 0.495 | 0.109 | 0.097 | 0.102 | 0.092 | 0.091 | 0.062 | 0.068 | |||
5.2. 结果分析
在第1步的G-AZB判决模型中,对于G-AZB的判决正确率是100%,主要是因为HDQ公式是向下取整,小于1的数都将被向下取整为0,所以基于该理论反向推导的G-AZB阈值具有100%的正确率(即FNR = 0). 在第2步的P-AZB检测模型中,对于满足
总的来说,提出的分步AZB判决算法凭借较低的判决错误率在性能损失可以忽略的情况下,节省了一定的编码时间,降低了编码器复杂度.
6. 结 语
本文提出VVC分步AZB判决快速算法,从固定阈值到自适应阈值,再到机器学习,对AZB进行周密的检测. 实验结果表明,在LDB和RA配置下,提出的方案在性能基本不变的情况下分别平均节省了7.382%和7.237%的编码时间. VVC作为最新一代的视频编码标准,压缩效率得到极大的提升,但是存在许多值得改进的地方. 随着机器学习的兴起,可以考虑在视频编码的其他模块中引入机器学习,采取更加智能化的方式来减少计算复杂度.
参考文献
Overview of the versatile video coding (VVC) standard and its applications
[J].DOI:10.1109/TCSVT.2021.3101953 [本文引用: 1]
Overview of the high efficiency video coding (HEVC) standard
[J].DOI:10.1109/TCSVT.2012.2221191 [本文引用: 1]
Trellis-based RD optimal quantization in H.263+
[J].DOI:10.1109/83.855437 [本文引用: 1]
Low complexity trellis-coded quantization in versatile video coding
[J].DOI:10.1109/TIP.2021.3051460 [本文引用: 1]
Overview of the H. 264/AVC video coding standard
[J].DOI:10.1109/TCSVT.2003.815165 [本文引用: 1]
Prediction of zero quantized DCT coefficients in H. 264/AVC using Hadamard transformed information
[J].DOI:10.1109/TCSVT.2008.918553 [本文引用: 1]
Soft decision quantization for H. 264 with main profile compatibility
[J].
A novel algorithm for zero block detection in high efficiency video coding
[J].DOI:10.1109/JSTSP.2013.2272772 [本文引用: 13]
Hybrid all zero soft quantized block detection for HEVC
[J].DOI:10.1109/TIP.2018.2837351 [本文引用: 6]
Multi-stage all-zero block detection for HEVC coding using machine learning
[J].DOI:10.1016/j.jvcir.2020.102945 [本文引用: 13]
Context-based adaptive binary arithmetic coding in the H. 264/AVC video compression standard
[J].DOI:10.1109/TCSVT.2003.815173 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}