

Wang等[10]提出并设计为交通信号控制自动提取有效特征的深度学习策略,使用基于事件的高分辨率数据来提取交叉口交通信息. 本质上,该方法只是采用新的输入数据来提高模型学习效率. 刘皓等[11]提出基于深度强化学习的交通信号控制方法,并利用交叉口各进口车道上总排队长度定义奖励函数. 该方法通过改进强化学习中的奖励函数来提高算法学习效率,但在一些复杂的实际交通场景中,车辆排队的长度通常难以准确测量. 郭梦杰等[12]提出基于深度Q网络 (deep Q-network, DQN)的单交叉口交通信号控制方法。该方法仅利用单个神经网络更新Q值,无法克服相邻状态所对应Q值的相关性,且采用平均等待时间定义奖励函数无法实时反映奖惩关系. 赖建辉[13]提出基于D3QN的交通信号控制策略,改进了Q值的计算公式和神经网络结构,提高了算法的收敛性. 该算法设计过于复杂,难以应用于实际交通信号控制中. Chu等[14]提出基于分散式多智能体强化学习的交通信号控制方法,利用多智能体结构解决了传统强化学习算法收敛性低下的问题. 该方法容易产生经验信息冗余,在对经验信息的处理上仍须改进.
上述基于强化学习的交通信号控制方法,其奖励函数一般是基于某个时段内的平均车辆等待时间或排队长度来定义的. 如果某个时段内的均值要有统计意义,则要求该时段长度至少是多个采样时间步. 显然,基于平均等待时间或平均排队长度定义的奖励函数难以有效反映交叉口在单个采样时间步内的实时交通状态及其变化趋势. 为了解决上述问题,本研究提出基于改进深度强化学习的交通信号控制方法. 该方法构建新的基于相邻采样时间步实时车辆数变化量的奖励函数,能够有效跟踪交叉口交通流实时动态变化过程并充分利用历史实时信息. 采用具有双网络结构的Nature DQN估计动作价值,提高算法学习效率. 在训练过程中设计经验回放策略改善算法收敛性. 基于交通仿真器SUMO开展仿真测试,并与传统定时控制、自适应控制,以及传统的基于全连接神经网络或卷积神经网络的DQN方法进行对比分析.
1. 交通信号控制中强化学习的要素定义
图 1
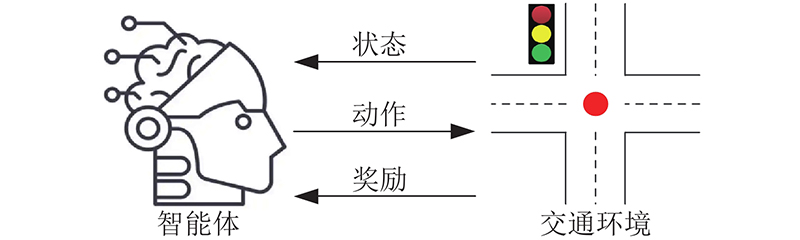
图 2
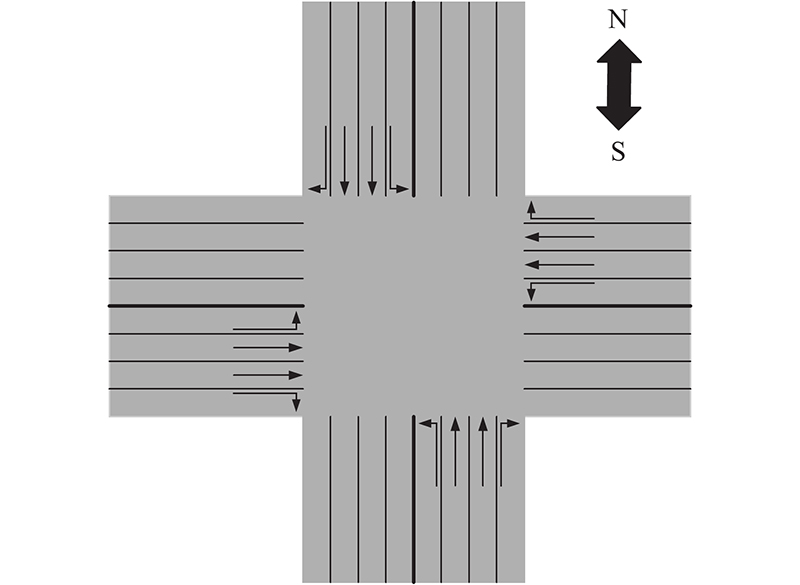
1.1. 状态
将上述车辆位置信息、速度信息以及交叉口当前正在运行绿灯的相位作为状态输入,能够更准确地反映交叉口实时交通状态[15]. 采用离散交通状态编码(discrete traffic state encode, DTSE)将交叉口实时交通状态转化为可处理的元素;包括该区间是否有车辆,有车辆时车辆的速度. 相较于直接利用图像信息进行信息输入,该方法能有效减少输入信息量,从数据端降低算法计算复杂度.
以图2所示交叉口西进车口方向各车道为例,将距离信号灯的一定长度的各条车道按预设间隔距离划分为若干“元胞”,每个“元胞”作为取样区域可容纳且最多容纳1辆车[16]. 如图3所示,通过获取各条车道上各“元胞”内车辆信息,建立交叉口西进口方向对应的位置矩阵和速度矩阵. 图3(b)中,元素取值为0,表示该位置对应的“元胞”内无车辆;取值为1,表示该位置对应的“元胞”内有车辆. 图3(c)中,元素取值大于0,表示该位置对应的“元胞”内有车辆且车辆速度等于该元素取值;元素取值等于0,表示该位置对应的“元胞”内无车辆. 通过位置矩阵可以判断进口车道上各“元胞”内有无车辆,由速度矩阵可以确定有车辆的那些“元胞”内的车辆行驶速度.
图 3

1.2. 动作空间
图 4
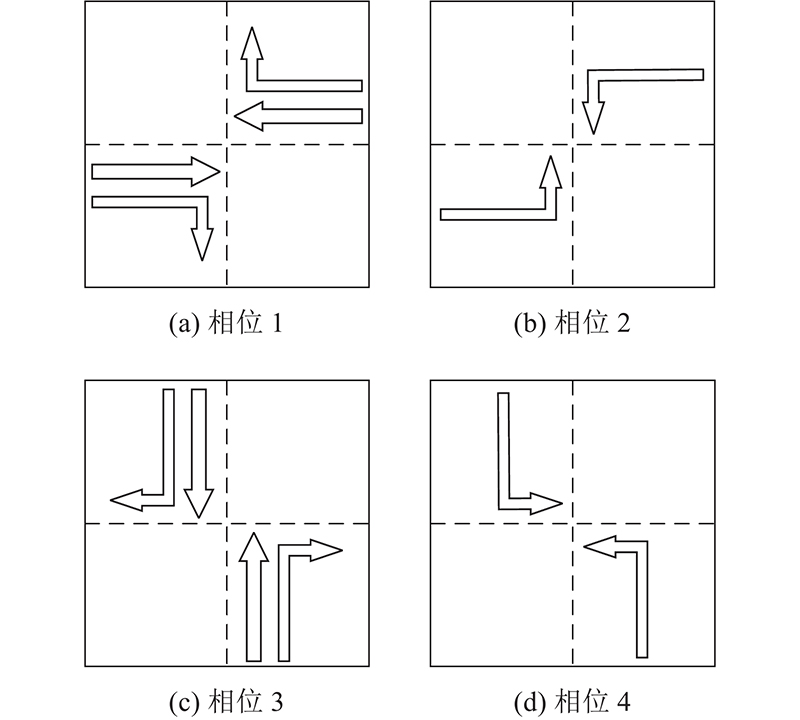
图 5
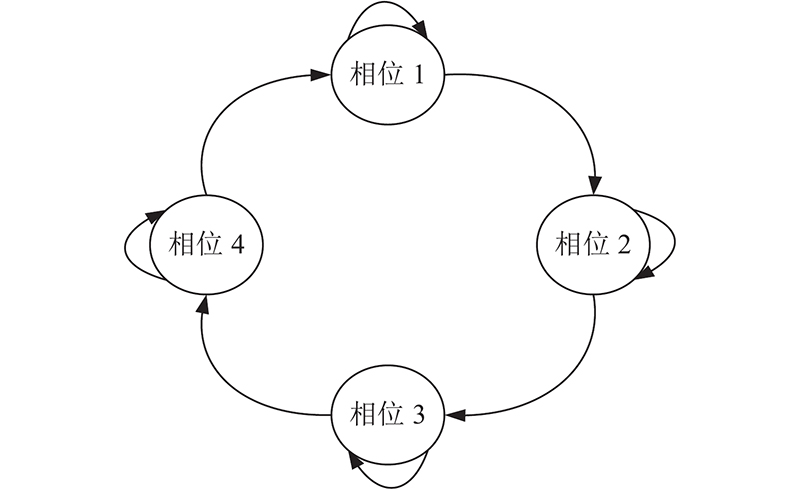
图 5 构建强化学习所需的动作空间
Fig.5 Construct action apace needed for reinforcement learning
1.3. 奖励函数
奖励也称反馈,是强化学习中的重要组成要素,也是对智能体执行动作优劣的评价指标. 在本研究中,每个控制步智能体依据上一步结束时制定的决策来执行相应的动作. 所采取的动作会对环境产生影响,同时环境据此对智能体给予奖励,该奖励又对智能体下一步选择待执行的动作决策产生影响.
利用Traci接口函数获取交叉口在各个采样时间步的实时车辆数建立奖励函数. 为了更准确地反应在各个采样时间步交叉口实时交通状态的变化趋势,将奖励函数R定义为相邻采样时间步的车辆数之差:
式中:Cnum (t)为第t个采样时间步时交叉口各车道上总的车辆数. R(t+1)>0表示相对于上个采样时间步,交叉口交通状况恶化,对当前步所采取的动作进行“惩罚”;R(t+1)<0表示相对于上个采样时间步,交叉口的交通状况有所改善,对当前步所采取的动作进行“奖励”.
2. 基于改进DQN的交通信号控制方法
在基于深度强化学习的交通信号控制方法中,交叉口交通信号控制问题被抽象为智能体根据交叉口实时交通状态选择最佳执行动作的决策过程. 智能体基于采集各类交通参与对象的信息、交叉口实时交通状态,从动作空间中选择1个动作执行. 存储设备记录执行该动作后给予智能体的奖励,并依据智能体采取不同动作所获得的奖励值计算Q值,为下一步选择能够获得长期期望最大总收益的动作提供指导. 在本研究中,每个控制步智能体可以采取的动作包括:保持当前相位、切换到下个相位.
所提基于改进DQN的交通信号控制方法在Q−学习算法中,状态−动作价值函数Q(s,a)被定义为
式中:
图 6
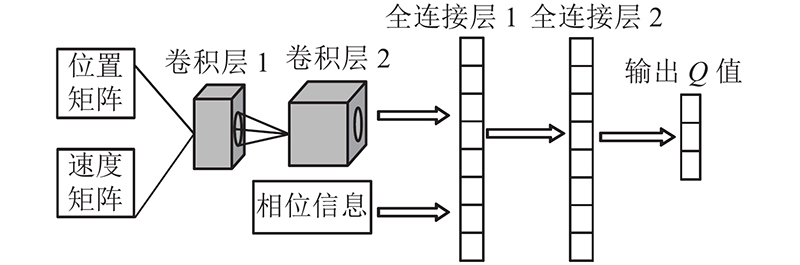
在DQN中,通常依据ε-贪婪规则选择智能体下一步要执行的动作:以ε的概率随机为智能体选择动作,以1-ε的概率选取神经网络输出的一系列Q值中最大Q值对应的动作为智能体下一步所需执行的动作. 一般情况下,在使用式(3) 迭代更新Q时,须准确的Q值即Q现实(利用公式(2)可得),还需要1个Q估计.
传统的DQN在利用Q现实和Q估计进行迭代更新时使用的是同个神经网络,导致Q现实和Q估计的依赖过强,不利于算法收敛. 本研究使用Nature DQN来解决这个问题[25]. Nature DQN有2个神经网络,其中target_net为计算Q现实的神经网络, eval_net为计算Q估计的神经网络. 在利用Nature DQN计算得到Q现实和Q估计后,计算神经网络eval_net的损失函数.
式中:
算法1:Nature DQN算法
定义可配置参数:总迭代轮数N,每次迭代总时间步T,折扣因子
初始化eval_net网络的权重参数θ,target_net网络的权重参数θ′,贪婪系数ε,以及经验池存储空间M;
训练DQN网络:
1. for epochs=0 to N do;
2. 初始化神经网络的输入s1;
3. for t=1 to T do;
4. 在eval_net网络中使用
5. 以概率ε随机选择动作
6. 执行动作
7. 将{st, at, rt, st+1}存储到经验池中;
8. 从经验池中随机采样{sj, aj, rj, sj+1};
9. 若sj+1为最终状态,则
10. 利用式(5)和随机梯度下降法更新θ ;
11. 若t%x=1,则更新
12. end for
13. end for
为了提高算法的收敛性,使用动态贪婪策略和经验回放机制训练模型. 动态贪婪策略在训练过程中动态改变贪婪系数ε的大小,实现训练结果的快速收敛[26]. 训练开始时的ε取值较大,智能体会更加“大胆”地对未知探索动作,即更倾向于随机选取动作. 训练后期的ε取值越来越小,智能体倾向于充分利用已经探知的信息,即选择神经网络输出的一系列Q值中最大的Q值对应的动作. 为了解决传统Q−学习算法中训练样本相关性过大的问题,采用经验回放机制打破经验数据间的相关性. 在使用经验回放机制的过程中,智能体将探索环境所得到的经验,即相邻采样步的状态信息、动作和奖励{st, at, rt, st+1}存储在经验池中,并对经验池的信息随机采样以减少相邻训练步样本的相关性[27]. 如图7所示为基于深度强化学习Nature DQN的交通信号控制框架.
图 7
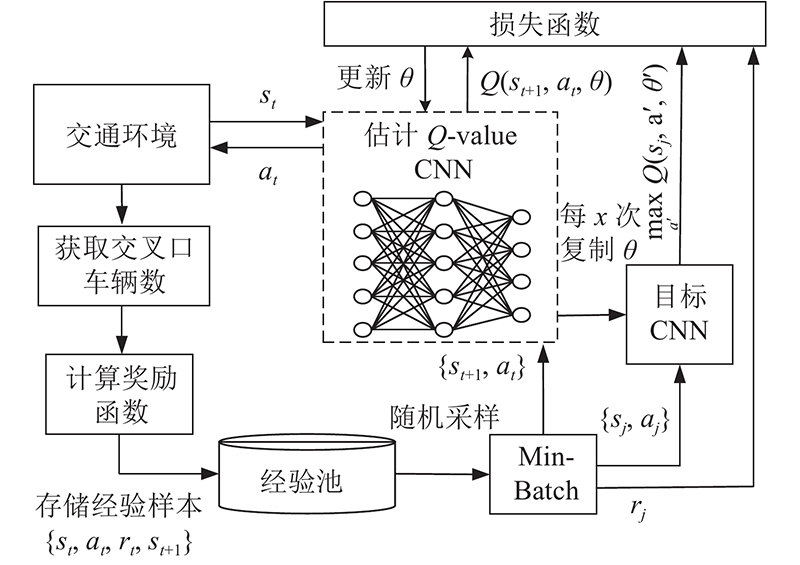
图 7 基于Nature DQN的交通信号控制框架
Fig.7 Traffic signal control framework based on nature DQN
3. 仿真与结果分析
3.1. 仿真环境与参数设置
以如图1所示的交叉口为测试对象,使用SUMO开展仿真测试. SUMO是具有开源、微观和多模态特性的仿真软件,可以模拟复杂交通状况. SUMO通过Traci接口获取车辆和道路信息,并在tensorflow机器学习框架下通过python编程实现仿真.
在DQN网络中,设置学习率
3.2. 实验结果与分析
将本研究所提的改进DQN与基于车辆平均延误时间定义奖励函数的传统DQN进行对比. 为了展示基于深度强化学习的交通信号控制方法相较于传统的交通信号控制方法的优越性,选取传统的定时控制方法和自适应控制方法作为对照组开展仿真测试.
在定时控制下,交叉口各相位配时在不同的交通状态下保持不变. 自适应控制在定时控制的基础上增加了检测器,并基于检测器所采集的实时交通状态,动态更新交叉口的交通信号配时方案. 如图8~10分别为不同类型的深度强化学习算法的累计奖励以及不同交通信号控制方法的平均等待时间和平均排队长度. 图中,
图 8
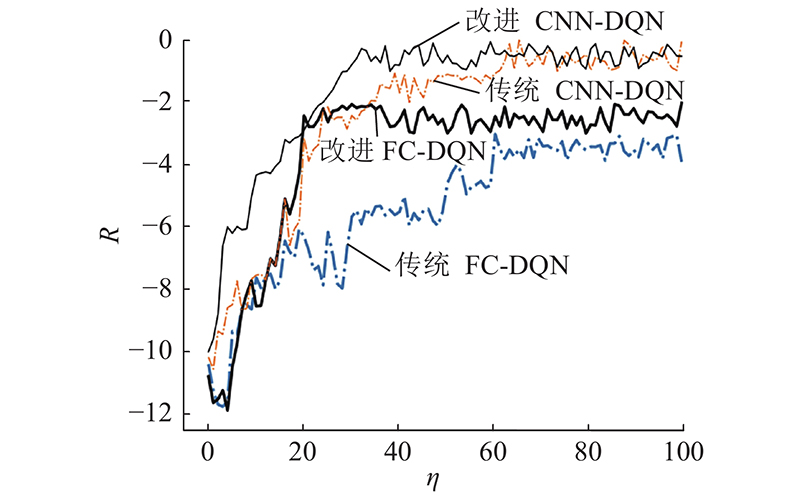
图 8 不同类型的深度强化学习算法的累计奖励
Fig.8 Cumulative rewards of different deep reinforcement learning algorithm
图 9
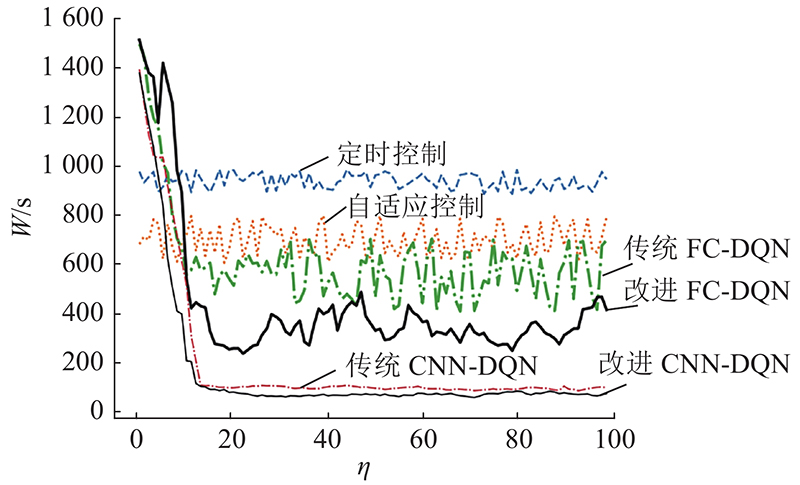
图 9 不同交通信号控制方法的平均等待时间
Fig.9 Average waiting time of different traffic signal control methods
图 10
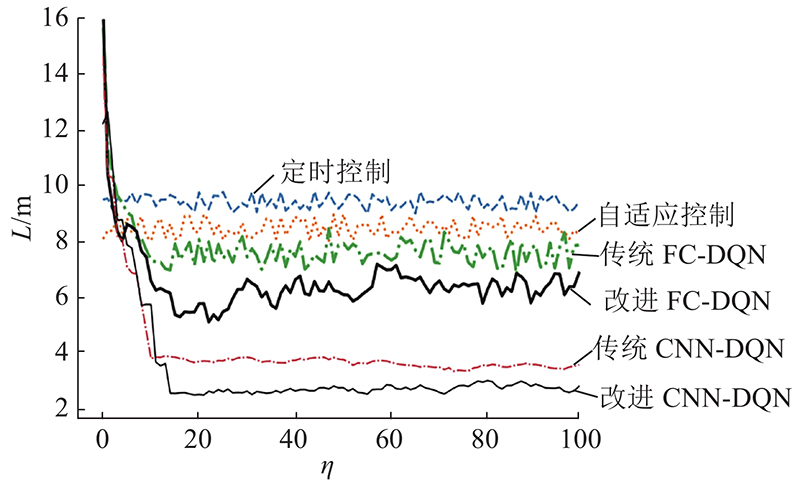
图 10 不同交通信号控制方法的平均排队长度
Fig.10 Average length of queue of different traffic signal control methods
由图8可知在使用相同神经网络的情况下,与传统的深度强化学习方法相比,使用本研究所设计新奖励函数和经验回放机制确实能够进一步提高算法的收敛性. 由图9~10可知,定时控制和自适应控制的平均等待时间和排队长度基本维持稳定,但自适应控制在平均等待时间和平均排队长度这2个交通效益指标上优于定时控制. 相比于定时控制和自适应控制方法,基于DQN的交通信号控制方法优势明显. 无论是基于全连接(full connection, FC)还是基于卷积神经网络(convolutional neural networks, CNN),相比传统基于车辆平均延误时间定义奖励函数的DQN,采用本研究所提DQN方法的控制效果明显更好.
如表1所示为基于不同交通信号控制方法控制效果的测试结果. 可知,与基于全连接神经网络的控制方法相比,基于卷积神经网络的控制方法效果更好. 当采用全连接神经网络时,与基于传统DQN的控制方法相比,基于改进DQN控制方法的车辆平均等待时间减少28.8%,平均排队长度减少15.8%. 当采用基于卷积神经网络时,与基于传统DQN的控制方法相比,基于改进DQN控制方法的车辆平均等待时间和平均排队长度分别减少36.8% 、18.1%. 实验结果表明,与传统DQN方法相比,基于改进DQN的方法具有更好的控制效果.
表 1 不同交通信号控制方法的测试结果
Tab.1
| 控制方法 | R | W/s | L/m |
| 定时控制 | — | 937.85 | 9.64 |
| 自适应控制 | — | 694.08 | 8.48 |
| 传统FC-DQN | −5.40 | 607.05 | 7.82 |
| 改进FC-DQN | −3.66 | 431.85 | 6.58 |
| 传统CNN-DQN | −2.54 | 168.59 | 4.14 |
| 改进CNN-DQN | −1.63 | 106.47 | 3.39 |
各强化学习模型在
表 2 模型训练时间和算法实时响应时间
Tab.2
| 控制方法 | S/min | V/s |
| 传统FC-DQN | 116 | < 2.0 |
| 改进FC-DQN | 105 | < 2.0 |
| 传统CNN-DQN | 88 | < 2.0 |
| 改进CNN-DQN | 75 | < 2.0 |
综上所述,以交叉口车辆平均排队长度和平均等待时间为评价指标,基于深度强化学习的交通信号控制方法明显优于传统定时控制、自适应控制方法. 相比于使用平均延误时间定义奖励函数的深度强化学习方法,本研究所提改进深度强化学习方法的交通信号控制效果更好.
4. 结 语
本研究提出的基于改进深度强化学习的交通信号控制方法,能够及时利用实时交通状态信息训练深度神经网络模型,并基于训练好的模型确定交叉口最优信号配时方案. 不同于现有基于深度强化学习的方法主要依据某个时段内的平均交通效益指标构建奖励函数,所提方法构建的基于相邻采样时间步实时车辆数变化量的奖励函数,能够更有效地跟踪和利用交叉口实时交通状态信息. 实验结果表明,所提方法能明显提高交叉口通行效率. 所提方法虽然较好地解决了单交叉口交通信号控制问题,但本研究并未讨论目标交叉口交通信号控制策略的改变对相邻交叉口的影响. 相比对各个交叉口进行单独控制,考虑到路网中距离相近的交叉口间通常具有较强的相互关联作用,对由若干相邻交叉口构成的区域进行协调控制能够产生更大的交通管控效益. 下一步将从区域总的交通效益出发,重点研究如何应用深度强化学习方法解决区域交通信号协调控制问题.
参考文献
城市道路交通控制概述与展望
[J].DOI:10.3969/j.issn.1671-1815.2020.16.002 [本文引用: 1]
Urban road traffic control overview and prospect
[J].DOI:10.3969/j.issn.1671-1815.2020.16.002 [本文引用: 1]
车路协同下基于交通密度的交叉口交通信号控制方法与仿真
[J].DOI:10.3969/j.issn.1007-7375.2014.04.020 [本文引用: 1]
Traffic signal control method and simulation based on traffic density in cooperative vehicle infrastructure system
[J].DOI:10.3969/j.issn.1007-7375.2014.04.020 [本文引用: 1]
城市交通信号自组织控制规则的邻域重构
[J].DOI:10.11918/201906054 [本文引用: 1]
Neighborhood reconstruction of urban traffic signal self-organizing control rules
[J].DOI:10.11918/201906054 [本文引用: 1]
面向混合交通的感应式交通信号控制方法
[J].
Traffic signal actuated control at isolated intersections for heterogeneous traffic
[J].
A survey of model predictive control methods for traffic signal control
[J].DOI:10.1109/JAS.2019.1911471 [本文引用: 1]
A hierarchical model predictive control approach for signal splits optimization in large-scale urban road networks
[J].DOI:10.1109/TITS.2016.2517079 [本文引用: 1]
A deep reinforcement learning network for traffic light cycle control
[J].DOI:10.1109/TVT.2018.2890726 [本文引用: 1]
Urban traffic control in software defined internet of things via a multi-agent deep reinforcement learning approach
[J].
Cooperative deep reinforcement learning for large-scale traffic grid signal control
[J].DOI:10.1109/TCYB.2019.2904742 [本文引用: 1]
Deep reinforcement learning-based traffic signal control using high-resolution event-based data
[J].DOI:10.3390/e21080744 [本文引用: 1]
基于深度强化学习的单路口交通信号控制
[J].
Deep reinforcement learning for traffic signal control of isolated signalized intersections
[J].
基于深度强化学习的单路口信号控制算法
[J].
Single control algorithm at isolated urban intersections based on deep reinforcement learning
[J].
基于D3QN的交通信号控制策略
[J].
Traffic signal control based on double deep Q-learning network with dueling architecture
[J].
Multi-agent deep reinforcement learning for large-scale traffic signal control
[J].DOI:10.1109/TITS.2019.2901791 [本文引用: 1]
Multi-agent deep reinforcement learning for urban traffic light control in vehicular networks
[J].DOI:10.1109/TVT.2020.2997896 [本文引用: 1]
Deep reinforcement learning for multimedia traffic control in software defined networking
[J].DOI:10.1109/MNET.2018.1800097 [本文引用: 1]
Deep reinforcement learning based conflict detection and resolution in air traffic control
[J].DOI:10.1049/iet-its.2018.5357 [本文引用: 1]
Fuzzy inference enabled deep reinforcement learning-based traffic light control for intelligent transportation system
[J].DOI:10.1109/TITS.2020.2984033 [本文引用: 1]
Deep reinforcement learning overview of the state of the art
[J].
Deep reinforcement learning: a brief survey
[J].DOI:10.1109/MSP.2017.2743240 [本文引用: 1]
On deep reinforcement learning for traffic engineering in SD-WAN
[J].DOI:10.1109/JSAC.2020.3041385 [本文引用: 1]
Traffic engineering in partially deployed segment routing over IPv6 network with deep reinforcement learning
[J].
Deep reinforcement learning-based vehicle driving strategy to reduce crash risks in traffic oscillations
[J].DOI:10.1177/0361198120937976 [本文引用: 1]
Deep reinforcement learning with spatio-temporal traffic forecasting for data-driven base station sleep control
[J].DOI:10.1109/TNET.2021.3053771 [本文引用: 1]
Human-level control through deep reinforcement learning
[J].DOI:10.1038/nature14236 [本文引用: 1]
Joint traffic control and multi-channel reassignment for core backbone network in SDN-IoT: a multi-agent deep reinforcement learning approach
[J].DOI:10.1109/TNSE.2020.3036456 [本文引用: 1]
Robust deep reinforcement learning for traffic signal control
[J].DOI:10.1007/s42421-020-00029-6 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}