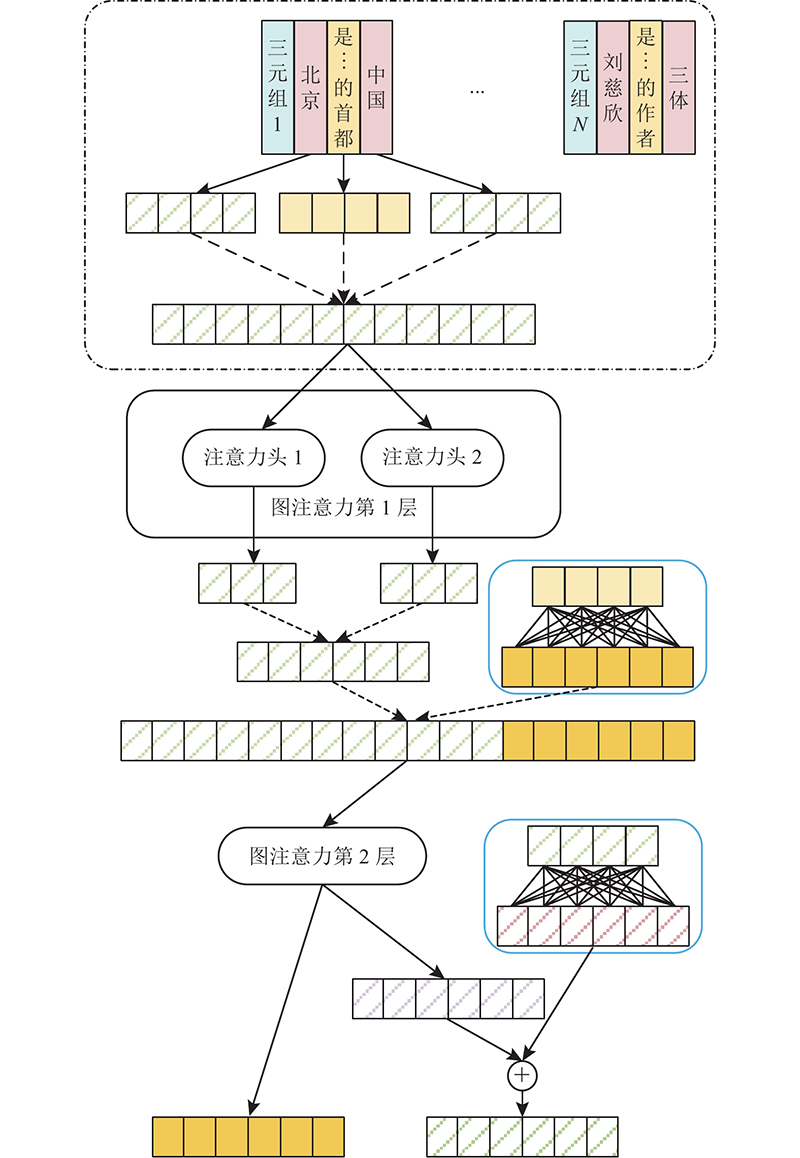
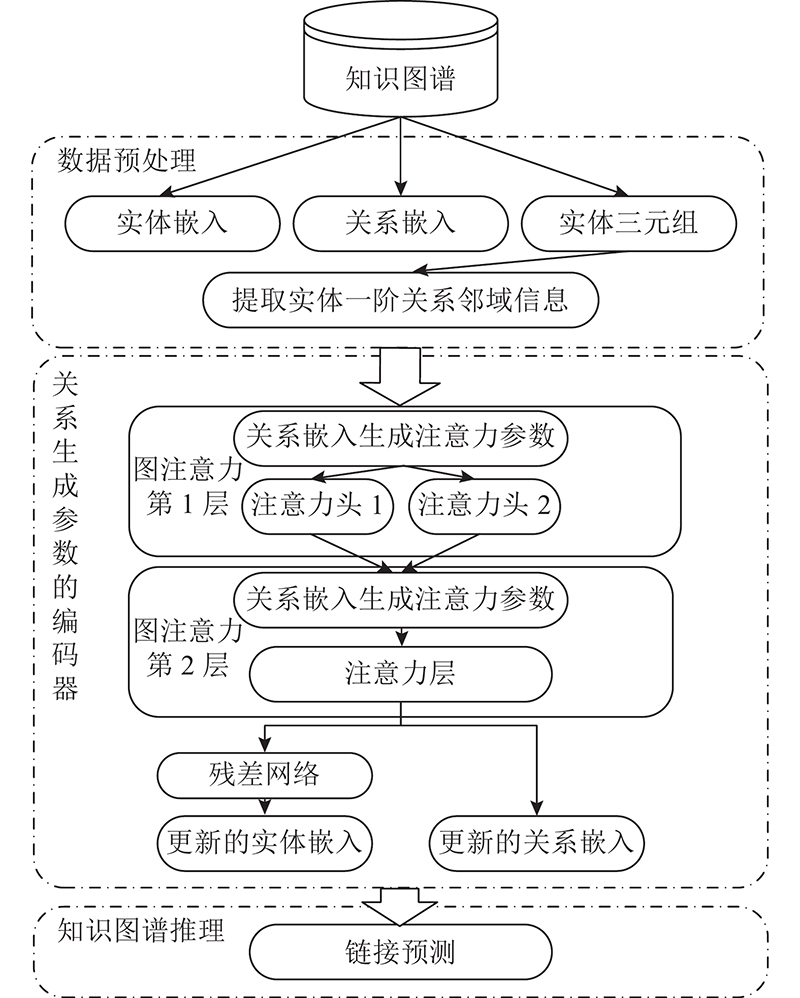
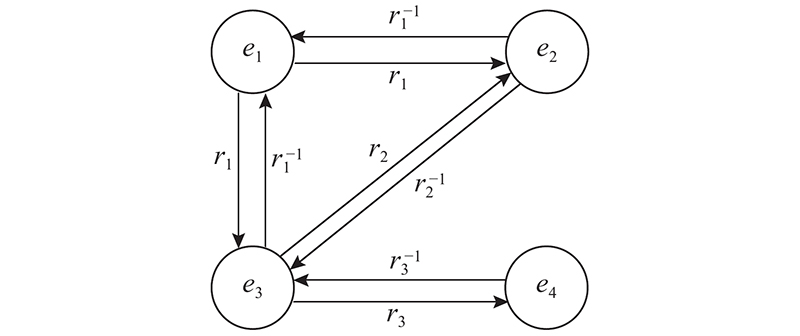
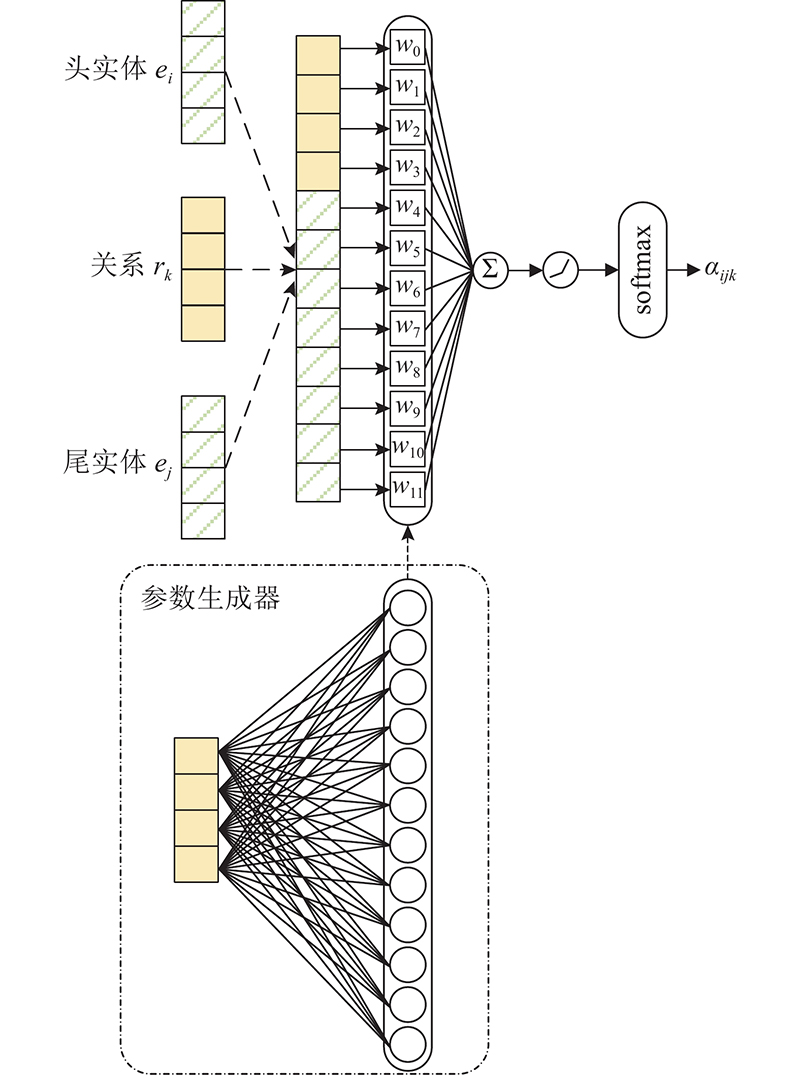
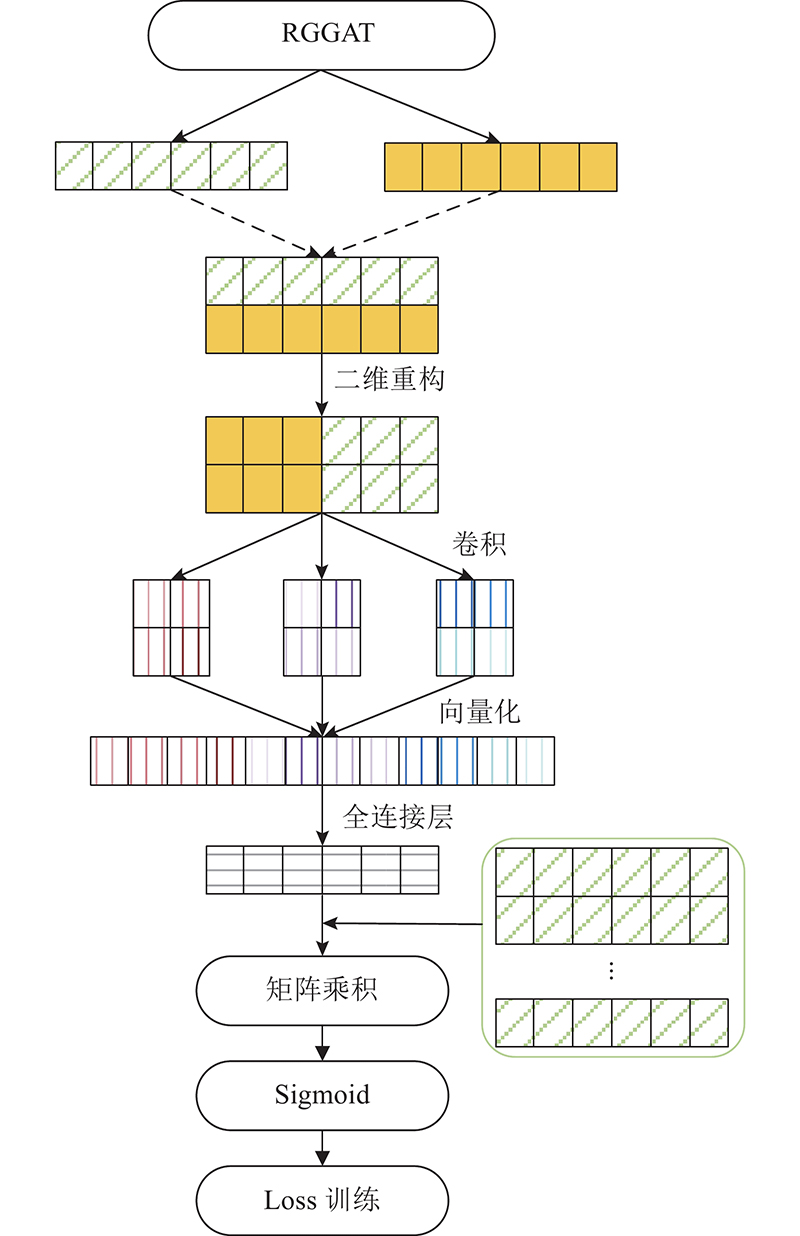
A knowledge graph link prediction method for relational generative graph attention network (RGGAT) was proposed to address the problem of missing links in entity neighborhood triples. Different types of relation were used to generate the corresponding attention mechanism parameters, and the attention coefficient was calculated by the neighborhood triples through the corresponding parameters according to the relation types. The entity got a richer embedding vector by aggregating the relation-dominated neighborhood triples information. The encoder and the decoder were jointly trained during the training process, and the entity vector and relation vector updated by the encoder were directly input into the decoder to ensure that the training objectives of the encoder and the decoder were consistent. The link prediction experiment was carried out on three public datasets, and five current mainstream models were selected as the baseline for the comparison experiment. The Hits@10 of RGGAT method on the three datasets were 0.519 8, 0.510 4 and 0.973 9, higher than that of the traditional graph attention network embedding method. In the comparison experiment of neighborhood aggregation order, the Hits@10 of the neighborhood aggregation method for one-hop relation was improved by 3.59% compared with the method for two-hop relation.
基于距离平移的模型以能量函数为基础,通过能量函数的计算来判断建立的三元组是否正确,即正确三元组能量较低,而无效三元组能量较高. TransE[6]模型考虑头实体和尾实体之间的转换操作,但在处理一对多和多对一关系时存在一定的问题. 为了解决这个问题,Wang等[17]和Lin等[18]分别在不同的关系空间中使用不同的表示形式计算具有相同实体的三重分数,有效地避免了收敛问题. Ji等[19]所提出的模型通过使用由对应的实体和关系确定的转移矩阵来解决实体和关系的多样性问题. 自TransE模型提出后,在这个框架下提出了多种方法,如基于关系映射属性的转换嵌入(translating embedding based on relation mapping properties, TransM)[20]模型和基于自适应方法的转换嵌入(translating embedding based on adaptive approach, TransA)[21]模型.
DALTON J, DIETA L, ALLAN J. Entity query feature expansion using knowledge base links [C]// Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval. Gold Coast: ACM, 2014: 365-374.
MINTZ M, BILLS S, SNOW R, et al. Distant supervision for relation extraction without labeled data [C]// Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of theAsian Federation of Natural Language Processing. Singapore: ACL, 2009: 1003-1011.
BOLLACKER K, EVANS C, PARITOSH P, et al. Freebase: a collaboratively created graph database for structuring human knowledge [C]// Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. Vancouver: ACM, 2008: 1247-1250.
NICKEL M, TRESP V, KRIEGEL H P. A three-way model for collective learning on multi-relational data [C]// Proceedings of the 28th International Conference on Machine Learning. Bellevue: ACM, 2011.
SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks [C]// Proceedings of the 15th European Semantic Web Conference . Heraklion: Springer, 2018: 593-607.
MARCHEGGIANI D, TITOV I. Encoding sentences with graph convolutional networks for semantic role labeling [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: ACL, 2017: 1506-1515.
SHANG C, TANG Y, HUANG J, et al. End-to-end structure-aware convolutional networks for knowledge base completion [C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu: AAAI, 2019: 3060-3067.
NATHANI D, CHAUHAN J, SHARMA C, et al. Learning attention-based embeddings for relation prediction in knowledge graphs [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: ACL, 2019: 4710-4723.
SOCHER R, CHEN D, MANNING C D, et al. Reasoning with neural tensor networks for knowledge base completion [C]// Proceedings of the 27thConference on Neural Information Processing Systems. Lake Tahoe: MIT Press, 2013: 926-934.
NICKEL M, ROSASCO L, POGGIO T. Holographic embeddings of knowledge graphs [C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix: AAAI, 2016: 1955-1961.
BALAZEVIC I, ALLEN C, HOSPEDALES T. TuckER: tensor factorization for knowledge graph completion [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: ACL, 2019: 5188-5197.
WANG Z, ZHANG J, FENG J, et al. Knowledge graph embedding by translating on hyperplanes [C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence. Quebec: AAAI, 2014: 1112-1119.
LIN Y, LIU Z, SUN M, et al. Learning entity and relation embeddings for knowledge graph completion [C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin: AAAI, 2015: 2181-2187.
JI G, HE S, XU L, et al. Knowledge graph embedding via dynamic mapping matrix [C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing: ACL, 2015: 687-696.
FAN M, ZHOU Q, CHANG E, et al. Transition-based knowledge graph embedding with relational mapping properties [C]// Proceedings of the 28th Pacific Asia Conference on Language, Information and Computing. Hong Kong: [s.n.], 2014: 328-337.
XIAO H, HUANG M, HAO Y, et al. TransA: an adaptive approach for knowledge graph embedding [EB/OL]. [2021-05-10]. https://arxiv.org/pdf/1509.05490v1.pdf.
EBISU T, ICHISE R. Toruse: knowledge graph embedding on a lie group [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans: AAAI, 2018: 1819-1826.
SUN Z, DENG Z H, NIE J Y, et al. RotatE: knowledge graph embedding by relational rotation in complex space [C]// Proceedings of the 6thInternational Conference on Learning Representations. Vancouver: [s. n. ], 2018.
ZHANG Z, CAI J, ZHANG Y, et al. Learning hierarchy-aware knowledge graph embeddings for link prediction [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York: AAAI, 2020: 3065-3072.
ZHANG S, TAY Y, YAO L, et al. Quaternion knowledge graph embeddings [C]// Proceedings of the 33rd Conference on Neural Information Processing Systems. Vancouver: MIT Press, 2019: 2735-2745.
NGUYEN T D, NGUYEN D Q, PHUNG D. A novel embedding model for knowledge base completion based on convolutional neural network [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New Orleans: NAACL, 2018: 327-333.
STOICA G, STRETCU O, PLATANIOS E A, et al. Contextual parameter generation for knowledge graph link prediction [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York: AAAI, 2020: 3000-3008.
YANG B, YIH W, HE X, et al. Embedding entities and relations for learning and inference in knowledge bases[EB/OL]. [2021- 05 -10]. https://arxiv.org/pdf/1412.6575v4.pdf.
VASHISHTH S, SANYAL S, NITIN V, et al. Composition-based multi-relational graph convolutional networks [C]// Proceedings of the 7thInternational Conference on Learning Representations. New Orleans: [s. n. ], 2019.
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31stConference on Neural Information Processing Systems. Long Beach: MIT Press, 2017: 5998-6008.
VELICKOVIC P, CUCURULL G, CASANOVA A, et al. Graph attention networks [C]// International Conference on Learning Representations. Vancouver: [s. n. ], 2018.
SUN Z, VASHISHTH S, SANYAL S, et al. A re-evaluation of knowledge graph completion methods [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Seattle: ACL, 2020: 5516-5522.
BANSAL T, JUAN D C, RAVI S, et al. A2N: attending to neighbors for knowledge graph inference [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: ACL, 2019: 4387-4392.
TOUTANOVA K, CHEN D, PANTEL P, et al. Representing text for joint embedding of text and knowledge bases [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon: ACL, 2015: 1499-1509.
LIN X V, SOCHER R, XIONG C. Multi-hop knowledge graph reasoning with reward shaping [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: ACL, 2018: 3243-3253.
... 基于距离平移的模型以能量函数为基础,通过能量函数的计算来判断建立的三元组是否正确,即正确三元组能量较低,而无效三元组能量较高. TransE[6]模型考虑头实体和尾实体之间的转换操作,但在处理一对多和多对一关系时存在一定的问题. 为了解决这个问题,Wang等[17]和Lin等[18]分别在不同的关系空间中使用不同的表示形式计算具有相同实体的三重分数,有效地避免了收敛问题. Ji等[19]所提出的模型通过使用由对应的实体和关系确定的转移矩阵来解决实体和关系的多样性问题. 自TransE模型提出后,在这个框架下提出了多种方法,如基于关系映射属性的转换嵌入(translating embedding based on relation mapping properties, TransM)[20]模型和基于自适应方法的转换嵌入(translating embedding based on adaptive approach, TransA)[21]模型. ...
... 基于距离平移的模型以能量函数为基础,通过能量函数的计算来判断建立的三元组是否正确,即正确三元组能量较低,而无效三元组能量较高. TransE[6]模型考虑头实体和尾实体之间的转换操作,但在处理一对多和多对一关系时存在一定的问题. 为了解决这个问题,Wang等[17]和Lin等[18]分别在不同的关系空间中使用不同的表示形式计算具有相同实体的三重分数,有效地避免了收敛问题. Ji等[19]所提出的模型通过使用由对应的实体和关系确定的转移矩阵来解决实体和关系的多样性问题. 自TransE模型提出后,在这个框架下提出了多种方法,如基于关系映射属性的转换嵌入(translating embedding based on relation mapping properties, TransM)[20]模型和基于自适应方法的转换嵌入(translating embedding based on adaptive approach, TransA)[21]模型. ...
1
... 基于距离平移的模型以能量函数为基础,通过能量函数的计算来判断建立的三元组是否正确,即正确三元组能量较低,而无效三元组能量较高. TransE[6]模型考虑头实体和尾实体之间的转换操作,但在处理一对多和多对一关系时存在一定的问题. 为了解决这个问题,Wang等[17]和Lin等[18]分别在不同的关系空间中使用不同的表示形式计算具有相同实体的三重分数,有效地避免了收敛问题. Ji等[19]所提出的模型通过使用由对应的实体和关系确定的转移矩阵来解决实体和关系的多样性问题. 自TransE模型提出后,在这个框架下提出了多种方法,如基于关系映射属性的转换嵌入(translating embedding based on relation mapping properties, TransM)[20]模型和基于自适应方法的转换嵌入(translating embedding based on adaptive approach, TransA)[21]模型. ...
1
... 基于距离平移的模型以能量函数为基础,通过能量函数的计算来判断建立的三元组是否正确,即正确三元组能量较低,而无效三元组能量较高. TransE[6]模型考虑头实体和尾实体之间的转换操作,但在处理一对多和多对一关系时存在一定的问题. 为了解决这个问题,Wang等[17]和Lin等[18]分别在不同的关系空间中使用不同的表示形式计算具有相同实体的三重分数,有效地避免了收敛问题. Ji等[19]所提出的模型通过使用由对应的实体和关系确定的转移矩阵来解决实体和关系的多样性问题. 自TransE模型提出后,在这个框架下提出了多种方法,如基于关系映射属性的转换嵌入(translating embedding based on relation mapping properties, TransM)[20]模型和基于自适应方法的转换嵌入(translating embedding based on adaptive approach, TransA)[21]模型. ...
1
... 基于距离平移的模型以能量函数为基础,通过能量函数的计算来判断建立的三元组是否正确,即正确三元组能量较低,而无效三元组能量较高. TransE[6]模型考虑头实体和尾实体之间的转换操作,但在处理一对多和多对一关系时存在一定的问题. 为了解决这个问题,Wang等[17]和Lin等[18]分别在不同的关系空间中使用不同的表示形式计算具有相同实体的三重分数,有效地避免了收敛问题. Ji等[19]所提出的模型通过使用由对应的实体和关系确定的转移矩阵来解决实体和关系的多样性问题. 自TransE模型提出后,在这个框架下提出了多种方法,如基于关系映射属性的转换嵌入(translating embedding based on relation mapping properties, TransM)[20]模型和基于自适应方法的转换嵌入(translating embedding based on adaptive approach, TransA)[21]模型. ...
1
... 基于距离平移的模型以能量函数为基础,通过能量函数的计算来判断建立的三元组是否正确,即正确三元组能量较低,而无效三元组能量较高. TransE[6]模型考虑头实体和尾实体之间的转换操作,但在处理一对多和多对一关系时存在一定的问题. 为了解决这个问题,Wang等[17]和Lin等[18]分别在不同的关系空间中使用不同的表示形式计算具有相同实体的三重分数,有效地避免了收敛问题. Ji等[19]所提出的模型通过使用由对应的实体和关系确定的转移矩阵来解决实体和关系的多样性问题. 自TransE模型提出后,在这个框架下提出了多种方法,如基于关系映射属性的转换嵌入(translating embedding based on relation mapping properties, TransM)[20]模型和基于自适应方法的转换嵌入(translating embedding based on adaptive approach, TransA)[21]模型. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}