将训练集中的人物身份标签记为 $ Y=\{{y}_{1},{y}_{2},\cdots , $ $ {y}_{K}\} $ K 为训练集中人物身份的个数. 使用预训练的年龄评估模型为该数据集扩展每个身份标签对应的年龄数据. 由于身份标签和年龄标签是一对一的关系,年龄数据记为 $ A = \{ {a_1},{a_2},\cdots ,{a_K}\} $ ai 表示对应身份人物所属的年龄区间. 本研究在训练阶段采取小批量训练方式. 每一批量的音频数据记为 $ V = \{ {v_1},{v_2},\cdots ,{v_N}\} $ N 为训练集中音频数据的个数. 音频对应的身份标签记为 $ {Y^{\text{v}}} = \{ y_1^{\text{v}},y_2^{\text{v}},\cdots ,y_N^{\text{v}}\} $ ${y_i^{\text{v}}} \in Y$ . 音频对应的年龄标签记为 $ {A^{\text{v}}} = \{ a_1^{\text{v}},a_2^{\text{v}},\cdots , $ $ a_N^{\text{v}}\} $ ${a_i^{\text{v}}} \in A$ . 每一批量的人脸图像数据记为 $ F = \{ {f_1},{f_2},\cdots ,{f_M}\} $ M 为训练集中人脸图像数据的个数. N 和M 可以不相等. 人脸图像对应的身份标签记为 ${Y^{\text{f}}} = \{ {{y}}_1^{\text{f}},y_2^{\text{f}},\cdots ,y_M^{\text{f}}\}$ ${y_i^{\text{f}}} \in Y$ . 人脸图像对应的年龄标签记为 $ {A^{\text{f}}} = \{ a_1^{\text{f}},a_2^{\text{f}},\cdots ,a_M^{\text{f}}\} $ ${a_i^{\text{f}}} \in A$ .
[1]
孙颖, 胡艳香, 张雪英, 等 面向情感语音识别的情感维度PAD预测
[J]. 浙江大学学报:工学版 , 2019 , 53 (10 ): 2041 - 2048
[本文引用: 1]
SUN Ying, HU Yan-xiang, ZHANG Xue-ying, et al Prediction of emotional dimensions PAD for emotional speech recognition
[J]. Journal of Zhejiang University: Engineering Science , 2019 , 53 (10 ): 2041 - 2048
[本文引用: 1]
[2]
SINGH R, RAJ B, GENCAGA D. Forensic anthropometry from voice: an articulatory-phonetic approach [C]// 2016 39th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO) . Opatija: IEEE, 2016: 1375-1380.
[本文引用: 1]
[3]
李江, 赵雅琼, 包晔华 基于混沌和替代数据法的中风病人声音分析
[J]. 浙江大学学报:工学版 , 2015 , 49 (1 ): 36 - 41
[本文引用: 1]
LI Jiang, ZHAO Ya-qiong, BAO Ye-hua Voice processing technique for patients with stroke based on chao theory and surrogate data analysis
[J]. Journal of Zhejiang University: Engineering Science , 2015 , 49 (1 ): 36 - 41
[本文引用: 1]
[4]
BELIN P, FECTEAU S, BEDARD C Thinking the voice: neural correlates of voice perception
[J]. Trends in Cognitive Sciences , 2004 , 8 (3 ): 129 - 135
[本文引用: 1]
[5]
KAMACHI M, HILL H, LANDER K, et al Putting the face to the voice’: matching identity across modality
[J]. Current Biology , 2003 , 13 (19 ): 1709 - 1714
[本文引用: 1]
[6]
GOODFELLOW I J, POUGET A J, MIRZA M, et al Generative adversarial networks
[J]. Advances in Neural Information Processing Systems , 2014 , 3 : 2672 - 2680
[本文引用: 1]
[7]
MIRZA M, OSINDERO S. Conditional generative adversarial nets [EB/OL]. (2014-11-06). https://arxiv.org/pdf/1411.1784.pdf.
[本文引用: 1]
[8]
YU Y, GONG Z, ZHONG P, et al. Unsupervised representation learning with deep convolutional neural network for remote sensing images [C]// International Conference on Image and Graphics . Shanghai: Springer, 2017: 97-108.
[本文引用: 1]
[9]
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Hawaii: IEEE, 2017: 1125-1134.
[本文引用: 4]
[10]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2223-2232.
[本文引用: 1]
[11]
王凯, 岳泊暄, 傅骏伟, 等 基于生成对抗网络的图像恢复与SLAM容错研究
[J]. 浙江大学学报: 工学版 , 2019 , 53 (1 ): 115 - 125
[本文引用: 1]
WANG Kai, YUE Bo-xuan, FU Jun-wei, et al Image restoration and fault tolerance of stereo SLAM based on generative adversarial net
[J]. Journal of Zhejiang University: Engineering Science , 2019 , 53 (1 ): 115 - 125
[本文引用: 1]
[12]
段然, 周登文, 赵丽娟, 等 基于多尺度特征映射网络的图像超分辨率重建
[J]. 浙江大学学报: 工学版 , 2019 , 53 (7 ): 1331 - 1339
[本文引用: 1]
DUAN Ran, ZHOU Deng-wen, ZHAO Li-juan, et al Classification and detection method of blood cells images based on multi-scale conditional generative adversarial network
[J]. Journal of Zhejiang University: Engineering Science , 2019 , 53 (7 ): 1331 - 1339
[本文引用: 1]
[13]
OH T H, DEKEL T, KIM C, et al. Speech2face: learning the face behind a voice [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 7539-7548.
[本文引用: 5]
[14]
DUARTE A C, ROLDAN F, TUBAU M, et al. WAV2PIX: speech-conditioned face generation using generative adversarial networks [C]// International Conference on Acoustics, Speech, and Signal Processing . Brighton: IEEE, 2019: 8633-8637.
[本文引用: 1]
[15]
WEN Y, RAJ B, SINGH R Face reconstruction from voice using generative adversarial networks
[J]. Advances in Neural Information Processing Systems , 2019 , 32 : 5265 - 5274
[本文引用: 8]
[16]
ODENA A, OLAH C, SHLENS J. Conditional image synthesis with auxiliary classifier gans [C]// International Conference on Machine Learning . Sydney: ICML, 2017: 2642-2651.
[本文引用: 3]
[17]
CHOI H S, PARK C, LEE K. From inference to generation: end-to-end fully self-supervised generation of human face from speech [C]// International Conference on Learning Representations . Addis Ababaa: ICLR, 2020.
[本文引用: 2]
[18]
RONNEBRGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// International Conference on Medical Image Computing and Computer Assisted Intervention . Munich: Springer, 2015: 234–241.
[本文引用: 2]
[19]
LI C, WAND M. Precomputed real-time texture synthesis with markovian generative adversarial networks [C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 702-716.
[本文引用: 1]
[20]
CHEN Y, TAI Y, LIU X, et al. FSRNet: end-to-end learning face super-resolution with facial priors [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake: IEEE, 2018: 2492-2501.
[本文引用: 1]
[21]
ARANDJELOVIC R, ZISSERMAN A. Look, listen and learn [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 609-617.
[本文引用: 1]
[22]
CASTREJON L, AYTAR Y, VONDRICK C, et al. Learning aligned cross-modal representations from weakly aligned data [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2940-2949.
[本文引用: 1]
[23]
YANG D W, ISMAIL M A, LIU W Y, et al. Disjoint mapping network for crossmodal matching of voices and faces [C]// International Conference on Learning Representations . Addis Ababaa: ICLR, 2018.
[本文引用: 1]
[24]
张晓冰, 龚海刚, 杨帆, 等 基于端到端句子级别的中文唇语识别研究
[J]. 软件学报 , 2020 , 31 (6 ): 1747 - 1760
[本文引用: 1]
ZHANG Xiao-bing, GONG Hai-gang, YANG Fan, et al Chinese sentence-level lip reading based on end-to-end model
[J]. Journal of Software , 2020 , 31 (6 ): 1747 - 1760
[本文引用: 1]
[25]
HOOVER K, CHAUDHURI S, PANTOFARU C, et al. Putting a face to the voice: fusing audio and visual signals across a video to determine speakers [EB/OL]. (2017-5-31) [2021-10-24]. https://arxiv.org/pdf/1706.00079.pdf.
[本文引用: 1]
[26]
唐郅, 侯进 基于深度神经网络的语音驱动发音器官的运动合成
[J]. 自动化学报 , 2016 , 42 (6 ): 923 - 930
[本文引用: 1]
TANG Zhi, HOU Jin Speech driven articulator motion synthesis with deep neural networks
[J]. Acta Automatica Sinica , 2016 , 42 (6 ): 923 - 930
[本文引用: 1]
[27]
SUN Y, ZHOU H, LIU Z, et al. Speech2Talking-Face: inferring and driving a face with synchronized audio-visual representation [C]// International Joint Conference on Artificial Intelligence . Montreal: IJCAI, 2021: 1018-1024.
[本文引用: 1]
[28]
ZHOU H, SUN Y, WU W, et al. Pose-controllable talking face generation by implicitly modularized audio-visual representation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Virtual reality: IEEE, 2021: 4176-4186.
[本文引用: 1]
[29]
NAGRANI A, ALBANIE S, ZISSERMAN A. Seeing voices and hearing faces: cross-modal biometric matching [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8427-8436.
[本文引用: 1]
[30]
OMKAR M P, ANDREA V, ANDREW Z, et al. Deep face recognition [C]// British Machine Vision Conference . Swansea: BMVC, 2015: 1, 6.
[本文引用: 1]
[31]
NAGRANI A, ALBANIE S, ZISSERMAN A. Seeing voices and hearing faces: cross-modal biometric matching [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake: BMVC, 2018: 8427-8436.
[本文引用: 1]
[32]
ROTHE R, TIMOFTE R, VAN GOOL L Deep expectation of real and apparent age from a single image without facial landmarks
[J]. International Journal of Computer Vision , 2018 , 126 (2 ): 144 - 157
[本文引用: 1]
[33]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[34]
KING D E Dlib-ml: a machine learning toolkit
[J]. The Journal of Machine Learning Research , 2009 , 10 : 1755 - 1758
[本文引用: 1]
[35]
EPHRAT A, MOSSERI I, LANG O, et al Looking to listen at the cocktail party: a speaker-independent audio-visual model for speech separation
[J]. ACM Transactions on Graphics (TOG) , 2018 , 37 (4 ): 1 - 11
[本文引用: 1]
[36]
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium [C]// Advances in Neural Information Processing Systems . Long Beach: NIPS, 2017, 30.
[本文引用: 1]
面向情感语音识别的情感维度PAD预测
1
2019
... 传统的语音分析技术已经能从语音推断说话人多方面的信息,例如情感[1 ] 、身高体重[2 ] 、健康状况[3 ] 等.生物学的研究证明,人类的知觉隐式地建立了语音与对应人脸的联系[4 ] ,人类具备将未知个体的声音与他们的面部图片联系起来的能力[5 ] ,根据语音推测说话人的面部特征是可行的. 近年来,以生成对抗网络(generative adversarial network,GAN)[6 ] 为代表的图像生成技术给语音分析的研究带来新的进展,通过语音来直接重建说话人的面部图像得以实现. ...
面向情感语音识别的情感维度PAD预测
1
2019
... 传统的语音分析技术已经能从语音推断说话人多方面的信息,例如情感[1 ] 、身高体重[2 ] 、健康状况[3 ] 等.生物学的研究证明,人类的知觉隐式地建立了语音与对应人脸的联系[4 ] ,人类具备将未知个体的声音与他们的面部图片联系起来的能力[5 ] ,根据语音推测说话人的面部特征是可行的. 近年来,以生成对抗网络(generative adversarial network,GAN)[6 ] 为代表的图像生成技术给语音分析的研究带来新的进展,通过语音来直接重建说话人的面部图像得以实现. ...
1
... 传统的语音分析技术已经能从语音推断说话人多方面的信息,例如情感[1 ] 、身高体重[2 ] 、健康状况[3 ] 等.生物学的研究证明,人类的知觉隐式地建立了语音与对应人脸的联系[4 ] ,人类具备将未知个体的声音与他们的面部图片联系起来的能力[5 ] ,根据语音推测说话人的面部特征是可行的. 近年来,以生成对抗网络(generative adversarial network,GAN)[6 ] 为代表的图像生成技术给语音分析的研究带来新的进展,通过语音来直接重建说话人的面部图像得以实现. ...
基于混沌和替代数据法的中风病人声音分析
1
2015
... 传统的语音分析技术已经能从语音推断说话人多方面的信息,例如情感[1 ] 、身高体重[2 ] 、健康状况[3 ] 等.生物学的研究证明,人类的知觉隐式地建立了语音与对应人脸的联系[4 ] ,人类具备将未知个体的声音与他们的面部图片联系起来的能力[5 ] ,根据语音推测说话人的面部特征是可行的. 近年来,以生成对抗网络(generative adversarial network,GAN)[6 ] 为代表的图像生成技术给语音分析的研究带来新的进展,通过语音来直接重建说话人的面部图像得以实现. ...
基于混沌和替代数据法的中风病人声音分析
1
2015
... 传统的语音分析技术已经能从语音推断说话人多方面的信息,例如情感[1 ] 、身高体重[2 ] 、健康状况[3 ] 等.生物学的研究证明,人类的知觉隐式地建立了语音与对应人脸的联系[4 ] ,人类具备将未知个体的声音与他们的面部图片联系起来的能力[5 ] ,根据语音推测说话人的面部特征是可行的. 近年来,以生成对抗网络(generative adversarial network,GAN)[6 ] 为代表的图像生成技术给语音分析的研究带来新的进展,通过语音来直接重建说话人的面部图像得以实现. ...
Thinking the voice: neural correlates of voice perception
1
2004
... 传统的语音分析技术已经能从语音推断说话人多方面的信息,例如情感[1 ] 、身高体重[2 ] 、健康状况[3 ] 等.生物学的研究证明,人类的知觉隐式地建立了语音与对应人脸的联系[4 ] ,人类具备将未知个体的声音与他们的面部图片联系起来的能力[5 ] ,根据语音推测说话人的面部特征是可行的. 近年来,以生成对抗网络(generative adversarial network,GAN)[6 ] 为代表的图像生成技术给语音分析的研究带来新的进展,通过语音来直接重建说话人的面部图像得以实现. ...
Putting the face to the voice’: matching identity across modality
1
2003
... 传统的语音分析技术已经能从语音推断说话人多方面的信息,例如情感[1 ] 、身高体重[2 ] 、健康状况[3 ] 等.生物学的研究证明,人类的知觉隐式地建立了语音与对应人脸的联系[4 ] ,人类具备将未知个体的声音与他们的面部图片联系起来的能力[5 ] ,根据语音推测说话人的面部特征是可行的. 近年来,以生成对抗网络(generative adversarial network,GAN)[6 ] 为代表的图像生成技术给语音分析的研究带来新的进展,通过语音来直接重建说话人的面部图像得以实现. ...
Generative adversarial networks
1
2014
... 传统的语音分析技术已经能从语音推断说话人多方面的信息,例如情感[1 ] 、身高体重[2 ] 、健康状况[3 ] 等.生物学的研究证明,人类的知觉隐式地建立了语音与对应人脸的联系[4 ] ,人类具备将未知个体的声音与他们的面部图片联系起来的能力[5 ] ,根据语音推测说话人的面部特征是可行的. 近年来,以生成对抗网络(generative adversarial network,GAN)[6 ] 为代表的图像生成技术给语音分析的研究带来新的进展,通过语音来直接重建说话人的面部图像得以实现. ...
1
... GAN自2014年提出至今,已经成为图像生成乃至计算机视觉领域的一种主流方法. 最初的GAN仅根据随机向量来生成真实但无法指定具体内容的图片. 之后出现的条件对抗生成网络(conditional generative adversarial network,CGAN)[7 ] ,通过在输入中加入额外的条件信息来控制输出. 深度卷积对抗生成网络(deep convolutional generative adversarial networks,DCGAN)[8 ] 将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,借助CNN更强的拟合与表达能力,能够生成更复杂清晰的图像. 之后GAN的应用范围不断拓展. 例如pix2pix(image-to-image translation with conditional adversarial networks)[9 ] 将GAN引入了图像转换任务. cycleGAN[10 ] 则打破了“输入和输出图像必须一一对应”的限制,能实现从域到域的图像转换. 王凯等[11 ] 以pix2pix为基础完成图像恢复任务,提高了SLAM(simultaneous localization and mapping)系统的容错能力. 段然等[12 ] 利用GAN完成图像超分辨率重建任务. ...
1
... GAN自2014年提出至今,已经成为图像生成乃至计算机视觉领域的一种主流方法. 最初的GAN仅根据随机向量来生成真实但无法指定具体内容的图片. 之后出现的条件对抗生成网络(conditional generative adversarial network,CGAN)[7 ] ,通过在输入中加入额外的条件信息来控制输出. 深度卷积对抗生成网络(deep convolutional generative adversarial networks,DCGAN)[8 ] 将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,借助CNN更强的拟合与表达能力,能够生成更复杂清晰的图像. 之后GAN的应用范围不断拓展. 例如pix2pix(image-to-image translation with conditional adversarial networks)[9 ] 将GAN引入了图像转换任务. cycleGAN[10 ] 则打破了“输入和输出图像必须一一对应”的限制,能实现从域到域的图像转换. 王凯等[11 ] 以pix2pix为基础完成图像恢复任务,提高了SLAM(simultaneous localization and mapping)系统的容错能力. 段然等[12 ] 利用GAN完成图像超分辨率重建任务. ...
4
... GAN自2014年提出至今,已经成为图像生成乃至计算机视觉领域的一种主流方法. 最初的GAN仅根据随机向量来生成真实但无法指定具体内容的图片. 之后出现的条件对抗生成网络(conditional generative adversarial network,CGAN)[7 ] ,通过在输入中加入额外的条件信息来控制输出. 深度卷积对抗生成网络(deep convolutional generative adversarial networks,DCGAN)[8 ] 将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,借助CNN更强的拟合与表达能力,能够生成更复杂清晰的图像. 之后GAN的应用范围不断拓展. 例如pix2pix(image-to-image translation with conditional adversarial networks)[9 ] 将GAN引入了图像转换任务. cycleGAN[10 ] 则打破了“输入和输出图像必须一一对应”的限制,能实现从域到域的图像转换. 王凯等[11 ] 以pix2pix为基础完成图像恢复任务,提高了SLAM(simultaneous localization and mapping)系统的容错能力. 段然等[12 ] 利用GAN完成图像超分辨率重建任务. ...
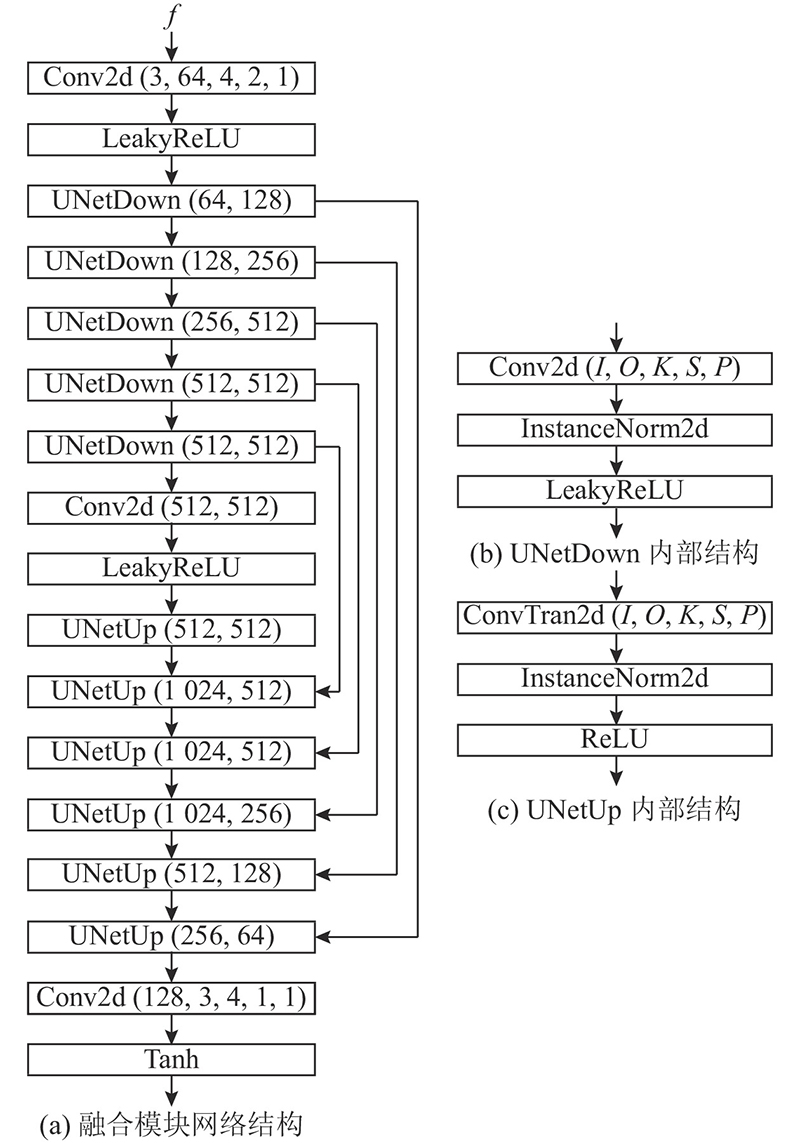
... 目前GAN在图像转换任务上有广泛应用.在一对一图像转换任务上,典型的工作有pix2pix[9 ] . 该工作将U-Net[18 ] 结构引入生成器,使用跳层连接缓解梯度消失和爆炸问题;判别器使用PatchGAN[19 ] 的结构,在关注图像高频信息的同时,也减小了计算量加快了训练速度.在人脸图像超分辨率任务中,典型的工作有FSRNet[20 ] .该工作充分利用人脸图像的几何先验信息(以面部landmark和热力图的形式)提升图像的生成效果. ...
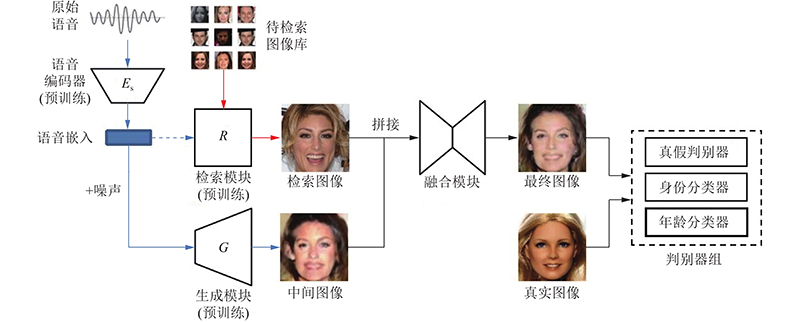
... 在得到预训练完毕的检索模块和生成器模块后,将它们加入整体模型,最后开始训练融合模块.融合模块及判别器的结构参考pix2pix[9 ] ,改进之处在于不使用pix2pix原本结构的判别器,而是使用本研究通过ACGAN[16 ] 的结构改进而来的判别器. 融合模块接收检索模块输出的检索图像和生成模块输出的生成图像,融合两者信息,输出最终图像. ...
... 检索模块输出的图像和生成器G 输出的图像,在频道维度上拼接(concatenate)后送入融合模块,产生最终的生成图像. 融合模块的结构借鉴自pix2pix[9 ] 的生成器,使用U-Net[18 ] 结构,一种引入了跳层连接的编码-解码器. 使用U-Net结构的理由是,融合模块的输入和输出都是人脸图像(尽管维度不同),所以输入和输出具有相似的底层结构. 如果使用传统的编码-解码器结构,输入的信息会经过一系列下采样层、瓶颈层、上采样层后才传达至最终的输出,一些低层信息在这个过程中可能会损失. 而U-Net的跳层连接让输入的信息可以更直接地传达至输出端. ...
1
... GAN自2014年提出至今,已经成为图像生成乃至计算机视觉领域的一种主流方法. 最初的GAN仅根据随机向量来生成真实但无法指定具体内容的图片. 之后出现的条件对抗生成网络(conditional generative adversarial network,CGAN)[7 ] ,通过在输入中加入额外的条件信息来控制输出. 深度卷积对抗生成网络(deep convolutional generative adversarial networks,DCGAN)[8 ] 将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,借助CNN更强的拟合与表达能力,能够生成更复杂清晰的图像. 之后GAN的应用范围不断拓展. 例如pix2pix(image-to-image translation with conditional adversarial networks)[9 ] 将GAN引入了图像转换任务. cycleGAN[10 ] 则打破了“输入和输出图像必须一一对应”的限制,能实现从域到域的图像转换. 王凯等[11 ] 以pix2pix为基础完成图像恢复任务,提高了SLAM(simultaneous localization and mapping)系统的容错能力. 段然等[12 ] 利用GAN完成图像超分辨率重建任务. ...
基于生成对抗网络的图像恢复与SLAM容错研究
1
2019
... GAN自2014年提出至今,已经成为图像生成乃至计算机视觉领域的一种主流方法. 最初的GAN仅根据随机向量来生成真实但无法指定具体内容的图片. 之后出现的条件对抗生成网络(conditional generative adversarial network,CGAN)[7 ] ,通过在输入中加入额外的条件信息来控制输出. 深度卷积对抗生成网络(deep convolutional generative adversarial networks,DCGAN)[8 ] 将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,借助CNN更强的拟合与表达能力,能够生成更复杂清晰的图像. 之后GAN的应用范围不断拓展. 例如pix2pix(image-to-image translation with conditional adversarial networks)[9 ] 将GAN引入了图像转换任务. cycleGAN[10 ] 则打破了“输入和输出图像必须一一对应”的限制,能实现从域到域的图像转换. 王凯等[11 ] 以pix2pix为基础完成图像恢复任务,提高了SLAM(simultaneous localization and mapping)系统的容错能力. 段然等[12 ] 利用GAN完成图像超分辨率重建任务. ...
基于生成对抗网络的图像恢复与SLAM容错研究
1
2019
... GAN自2014年提出至今,已经成为图像生成乃至计算机视觉领域的一种主流方法. 最初的GAN仅根据随机向量来生成真实但无法指定具体内容的图片. 之后出现的条件对抗生成网络(conditional generative adversarial network,CGAN)[7 ] ,通过在输入中加入额外的条件信息来控制输出. 深度卷积对抗生成网络(deep convolutional generative adversarial networks,DCGAN)[8 ] 将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,借助CNN更强的拟合与表达能力,能够生成更复杂清晰的图像. 之后GAN的应用范围不断拓展. 例如pix2pix(image-to-image translation with conditional adversarial networks)[9 ] 将GAN引入了图像转换任务. cycleGAN[10 ] 则打破了“输入和输出图像必须一一对应”的限制,能实现从域到域的图像转换. 王凯等[11 ] 以pix2pix为基础完成图像恢复任务,提高了SLAM(simultaneous localization and mapping)系统的容错能力. 段然等[12 ] 利用GAN完成图像超分辨率重建任务. ...
基于多尺度特征映射网络的图像超分辨率重建
1
2019
... GAN自2014年提出至今,已经成为图像生成乃至计算机视觉领域的一种主流方法. 最初的GAN仅根据随机向量来生成真实但无法指定具体内容的图片. 之后出现的条件对抗生成网络(conditional generative adversarial network,CGAN)[7 ] ,通过在输入中加入额外的条件信息来控制输出. 深度卷积对抗生成网络(deep convolutional generative adversarial networks,DCGAN)[8 ] 将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,借助CNN更强的拟合与表达能力,能够生成更复杂清晰的图像. 之后GAN的应用范围不断拓展. 例如pix2pix(image-to-image translation with conditional adversarial networks)[9 ] 将GAN引入了图像转换任务. cycleGAN[10 ] 则打破了“输入和输出图像必须一一对应”的限制,能实现从域到域的图像转换. 王凯等[11 ] 以pix2pix为基础完成图像恢复任务,提高了SLAM(simultaneous localization and mapping)系统的容错能力. 段然等[12 ] 利用GAN完成图像超分辨率重建任务. ...
基于多尺度特征映射网络的图像超分辨率重建
1
2019
... GAN自2014年提出至今,已经成为图像生成乃至计算机视觉领域的一种主流方法. 最初的GAN仅根据随机向量来生成真实但无法指定具体内容的图片. 之后出现的条件对抗生成网络(conditional generative adversarial network,CGAN)[7 ] ,通过在输入中加入额外的条件信息来控制输出. 深度卷积对抗生成网络(deep convolutional generative adversarial networks,DCGAN)[8 ] 将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,借助CNN更强的拟合与表达能力,能够生成更复杂清晰的图像. 之后GAN的应用范围不断拓展. 例如pix2pix(image-to-image translation with conditional adversarial networks)[9 ] 将GAN引入了图像转换任务. cycleGAN[10 ] 则打破了“输入和输出图像必须一一对应”的限制,能实现从域到域的图像转换. 王凯等[11 ] 以pix2pix为基础完成图像恢复任务,提高了SLAM(simultaneous localization and mapping)系统的容错能力. 段然等[12 ] 利用GAN完成图像超分辨率重建任务. ...
5
... 目前已有一些语音-人脸图像重建任务的工作. 该任务最早是由Oh等[13 ] 提出的,该工作的主要目的是揭示面部特征和语音在统计学上的相关性. Duarte等[14 ] 将GAN引入该任务,其工作证明GAN在语音-面部图像跨模态生成场景下是适用的. Wen等[15 ] 将带辅助分类器的GAN(auxiliary classifier generative adversarial network,ACGAN)[16 ] ,即CGAN的一个变种引入该任务. Choi等[17 ] 将自监督学习的方法引入该任务,即在未使用人工标注身份信息的数据上,实现从语音到对应身份的人脸图像的重建. ...
... 语音-人脸图像重建任务,最早是由Oh等[13 ] 提出的,模型名称为Speech2Face. 该工作通过预训练的图像编码器将图像编码为图像特征向量,再通过语音编码器将对应的语音编码嵌入到图像特征向量的空间中,最终通过预训练的解码器还原出面部图像. 该方法十分简单,生成的人脸图像是背景和头发模糊的正面像. ...
... 选取Speech2Face[13 ] 和Voice2Face[15 ] 作为对比模型. 所有模型在训练和测试时均使用8 s长度的音频数据. 本研究的数据处理方式和特征提取手段与Voice2Face的相同. 对于人脸图像,使用人脸检测模型提取VGGface数据集中的图像,通过相似变换后得到尺寸为3×64×64和3×128×128像素的RGB人脸图像,分别供Voice2Face和本研究的模型使用.使用预训练的ResNet-50[33 ] 模型作为图像编码器提取图像特征. 将图像中的每个像素减去127.5后再除以127.5进行归一化处理. 对于音频片段,均提取64维的梅尔频谱图,窗口宽度为25 ms,帧间距为10 ms,再进行均值和方差归一化处理. Speech2Face的数据处理方式略有不同. 对于人脸图像,使用基于Dlib[34 ] 的人脸检测器,从视频中裁剪人脸区域,经相似变换得到3×224×224像素的面部图像,通过预训练的VGG模型提取图像特征. 对于音频片段,Speech2Face的处理方式与Ephrat等[35 ] 的工作相同. ...
... 本研究和对比算法均采用小批量训练方式. 对比算法的批量大小和训练次数均和原文记录保持一致. 对Speech2Face[13 ] ,批量大小设置为8,迭代30000次. 对Voice2Face[15 ] ,使用已公开的模型作为对比模型,不需要另外训练. 对本研究中的生成模块,批量大小设置为128,共迭代6250次. 对本研究中的整体模型,批量大小设置为64,共迭代6875次. ...
... Experimental results of proposed method compared with popular methods
Tab.1 模型 距离度量 ResNet-50 VGG-16 FID Top-1/% Top-5/% Top-10/% Top-1/% Top-5/% Top-10/% random − 0.53 1.30 2.17 0.53 1.30 2.17 − Speech2Face[13 ] L1 0.61 2.59 4.44 0.58 2.96 5.45 233.92 cos 0.56 2.59 4.60 0.69 3.31 5.93 Voice2Face[15 ] L1 1.88 5.21 8.47 1.30 6.06 10.79 51.45 cos 1.98 5.58 8.33 1.32 5.66 10.90 仅生成模块 L1 2.30 5.71 8.33 1.38 6.46 11.08 38.60 cos 2.25 5.77 8.49 1.69 6.48 11.53 本研究方法 L1 2.59 5.98 9.20 1.75 6.60 11.60 40.32 cos 2.32 5.81 9.17 1.71 6.56 11.58
对比模型和本模型生成图像的样例如图8 所示. 可以看出,无论是生成模块生成的图像,还是模型整体生成的图像,均比对比模型的图像更接近原图,在性别、种族、肤色、年龄等属性上与真实图像更接近,图像质量也更出色. ...
1
... 目前已有一些语音-人脸图像重建任务的工作. 该任务最早是由Oh等[13 ] 提出的,该工作的主要目的是揭示面部特征和语音在统计学上的相关性. Duarte等[14 ] 将GAN引入该任务,其工作证明GAN在语音-面部图像跨模态生成场景下是适用的. Wen等[15 ] 将带辅助分类器的GAN(auxiliary classifier generative adversarial network,ACGAN)[16 ] ,即CGAN的一个变种引入该任务. Choi等[17 ] 将自监督学习的方法引入该任务,即在未使用人工标注身份信息的数据上,实现从语音到对应身份的人脸图像的重建. ...
Face reconstruction from voice using generative adversarial networks
8
2019
... 目前已有一些语音-人脸图像重建任务的工作. 该任务最早是由Oh等[13 ] 提出的,该工作的主要目的是揭示面部特征和语音在统计学上的相关性. Duarte等[14 ] 将GAN引入该任务,其工作证明GAN在语音-面部图像跨模态生成场景下是适用的. Wen等[15 ] 将带辅助分类器的GAN(auxiliary classifier generative adversarial network,ACGAN)[16 ] ,即CGAN的一个变种引入该任务. Choi等[17 ] 将自监督学习的方法引入该任务,即在未使用人工标注身份信息的数据上,实现从语音到对应身份的人脸图像的重建. ...
... Wen等[15 ] 使用了ACGAN[16 ] ,即CGAN的一个变种,模型名称为Voice2Face. 该工作通过一个预训练的语音编码器将语音编码为更低维的向量,在加上噪声后作为条件向量送入生成器. 在判别器部分添加了辅助分类器,使用身份监督信息改善生成效果. ...
... 本研究所提出的方法与上述方法有以下不同之处:1)先前方法没有试图使用除了身份监督信息之外的其他监督信息,但本研究通过预训练的年龄评估模型,为当前数据集扩充年龄数据,给每个身份标注了年龄区间;2)先前方法没有使用人脸先验信息来改善生成效果,本研究通过语音-图像跨模态检索技术,为给定的语音检索与说话人真实图像相似的人脸图像来作为人脸先验信息使用;3)与Wen等[15 ] 的工作相比,本研究能够生成128×128像素的较大尺寸的图片. ...
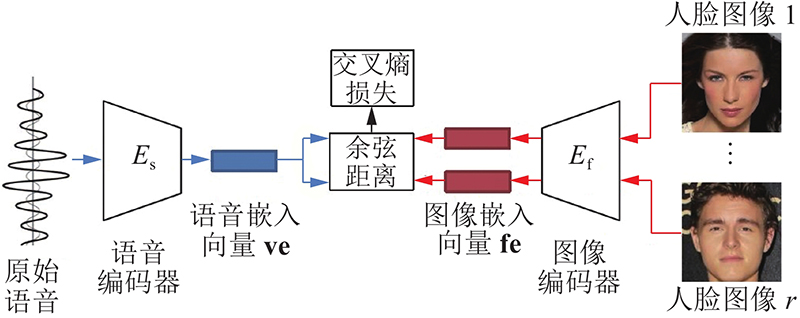
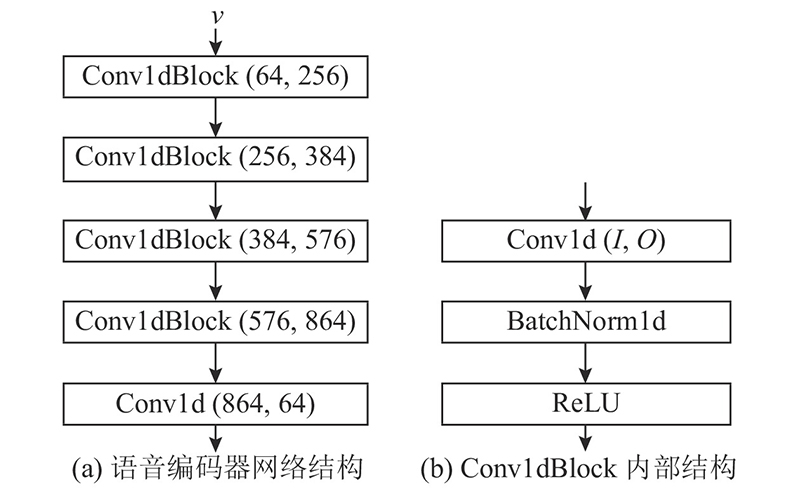
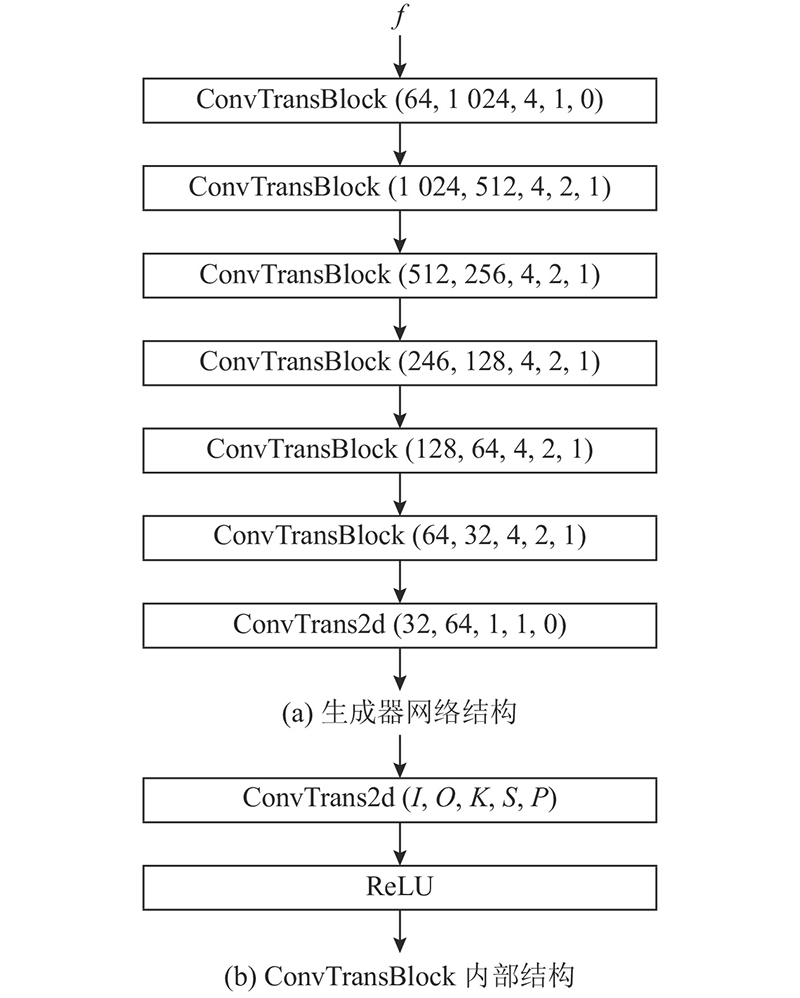
... 检索模块由语音编码器和图像编码器两部分组成. 图像编码器在预训练的ResNet-50的基础上微调得到. 语音编码器在Wen等[15 ] 的工作所提供的语音编码器的基础上微调得到,该语音编码器以处理成Mel频谱的语音特征作为输入. 语音编码器是一个卷积神经网络,详细结构如图3 所示. 图中,I 、O 分别为输入和输出频道数. 除了最后一层外,在语音编码器的每层卷积操作后都进行批量归一化(batch-normalization),并使用线性修正单元(rectified linear units,ReLU)作为激活函数. 2个编码器都通过各自最后一层的线性层,将对应模态的表示嵌入到同一特征空间中. 图像检索库由从训练集中抽取每个身份的部分图片得到. 图像检索库中的人脸图像数据记为 $ {F^{\text{r}}} = \{ f_1^{\text{r}},f_2^{\text{r}},\cdots ,f_L^{\text{r}}\} $ L 为检索库中人脸图像数据的个数,且 $ {f_i^{\text{r}}} \in F $ . 库中图像对应的身份标签记为 $ {Y^{\text{r}}} = \{ y_1^{\text{r}},y_2^{\text{r}},\cdots ,y_L^{\text{r}}\} $ $ {y_i^{\text{r}}} \in Y $ . 对于语音 $ {v_{{i}}} $ $ f_j^{\text{r}} $
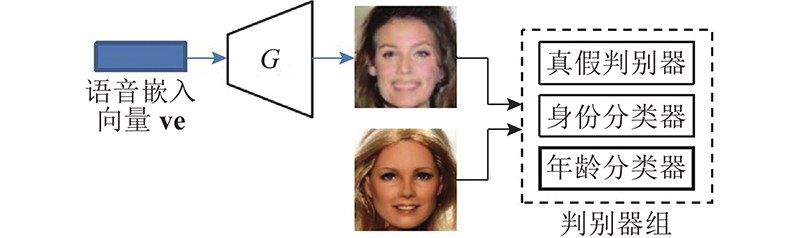
... 生成模块的训练模型根据Wen等[15 ] 的工作改进而来,与其主要差别在于,判别器组除了原有的身份分类器和真假判别器外,新增了年龄分类器. 生成模块的预训练须复用检索模块的语音编码器,在训练生成模块时,语音编码器的权重固定. 将原始语音输入语音编码器,得到语音的高维特征表示,该表示也可以作为生成器G 的条件向量,在加上高斯噪声后将其送入生成器G . ...
... 选取Speech2Face[13 ] 和Voice2Face[15 ] 作为对比模型. 所有模型在训练和测试时均使用8 s长度的音频数据. 本研究的数据处理方式和特征提取手段与Voice2Face的相同. 对于人脸图像,使用人脸检测模型提取VGGface数据集中的图像,通过相似变换后得到尺寸为3×64×64和3×128×128像素的RGB人脸图像,分别供Voice2Face和本研究的模型使用.使用预训练的ResNet-50[33 ] 模型作为图像编码器提取图像特征. 将图像中的每个像素减去127.5后再除以127.5进行归一化处理. 对于音频片段,均提取64维的梅尔频谱图,窗口宽度为25 ms,帧间距为10 ms,再进行均值和方差归一化处理. Speech2Face的数据处理方式略有不同. 对于人脸图像,使用基于Dlib[34 ] 的人脸检测器,从视频中裁剪人脸区域,经相似变换得到3×224×224像素的面部图像,通过预训练的VGG模型提取图像特征. 对于音频片段,Speech2Face的处理方式与Ephrat等[35 ] 的工作相同. ...
... 本研究和对比算法均采用小批量训练方式. 对比算法的批量大小和训练次数均和原文记录保持一致. 对Speech2Face[13 ] ,批量大小设置为8,迭代30000次. 对Voice2Face[15 ] ,使用已公开的模型作为对比模型,不需要另外训练. 对本研究中的生成模块,批量大小设置为128,共迭代6250次. 对本研究中的整体模型,批量大小设置为64,共迭代6875次. ...
... Experimental results of proposed method compared with popular methods
Tab.1 模型 距离度量 ResNet-50 VGG-16 FID Top-1/% Top-5/% Top-10/% Top-1/% Top-5/% Top-10/% random − 0.53 1.30 2.17 0.53 1.30 2.17 − Speech2Face[13 ] L1 0.61 2.59 4.44 0.58 2.96 5.45 233.92 cos 0.56 2.59 4.60 0.69 3.31 5.93 Voice2Face[15 ] L1 1.88 5.21 8.47 1.30 6.06 10.79 51.45 cos 1.98 5.58 8.33 1.32 5.66 10.90 仅生成模块 L1 2.30 5.71 8.33 1.38 6.46 11.08 38.60 cos 2.25 5.77 8.49 1.69 6.48 11.53 本研究方法 L1 2.59 5.98 9.20 1.75 6.60 11.60 40.32 cos 2.32 5.81 9.17 1.71 6.56 11.58
对比模型和本模型生成图像的样例如图8 所示. 可以看出,无论是生成模块生成的图像,还是模型整体生成的图像,均比对比模型的图像更接近原图,在性别、种族、肤色、年龄等属性上与真实图像更接近,图像质量也更出色. ...
3
... 目前已有一些语音-人脸图像重建任务的工作. 该任务最早是由Oh等[13 ] 提出的,该工作的主要目的是揭示面部特征和语音在统计学上的相关性. Duarte等[14 ] 将GAN引入该任务,其工作证明GAN在语音-面部图像跨模态生成场景下是适用的. Wen等[15 ] 将带辅助分类器的GAN(auxiliary classifier generative adversarial network,ACGAN)[16 ] ,即CGAN的一个变种引入该任务. Choi等[17 ] 将自监督学习的方法引入该任务,即在未使用人工标注身份信息的数据上,实现从语音到对应身份的人脸图像的重建. ...
... Wen等[15 ] 使用了ACGAN[16 ] ,即CGAN的一个变种,模型名称为Voice2Face. 该工作通过一个预训练的语音编码器将语音编码为更低维的向量,在加上噪声后作为条件向量送入生成器. 在判别器部分添加了辅助分类器,使用身份监督信息改善生成效果. ...
... 在得到预训练完毕的检索模块和生成器模块后,将它们加入整体模型,最后开始训练融合模块.融合模块及判别器的结构参考pix2pix[9 ] ,改进之处在于不使用pix2pix原本结构的判别器,而是使用本研究通过ACGAN[16 ] 的结构改进而来的判别器. 融合模块接收检索模块输出的检索图像和生成模块输出的生成图像,融合两者信息,输出最终图像. ...
2
... 目前已有一些语音-人脸图像重建任务的工作. 该任务最早是由Oh等[13 ] 提出的,该工作的主要目的是揭示面部特征和语音在统计学上的相关性. Duarte等[14 ] 将GAN引入该任务,其工作证明GAN在语音-面部图像跨模态生成场景下是适用的. Wen等[15 ] 将带辅助分类器的GAN(auxiliary classifier generative adversarial network,ACGAN)[16 ] ,即CGAN的一个变种引入该任务. Choi等[17 ] 将自监督学习的方法引入该任务,即在未使用人工标注身份信息的数据上,实现从语音到对应身份的人脸图像的重建. ...
... Choi等[17 ] 则实现了自监督学习,即在模型训练过程中没有使用显式的身份监督信息. 该工作的整体框架分为2个阶段,推断阶段和生成阶段. 在推断阶段,通过跨模态身份匹配任务训练得到图像编码器和语音编码器. 在生成阶段,使用推理阶段转移来的预训练网络来训练CGAN,即使用推断阶段得到的语音编码器将语音编码为伪条件向量,并将推理阶段得到的图像编码器作为判别器使用. ...
2
... 目前GAN在图像转换任务上有广泛应用.在一对一图像转换任务上,典型的工作有pix2pix[9 ] . 该工作将U-Net[18 ] 结构引入生成器,使用跳层连接缓解梯度消失和爆炸问题;判别器使用PatchGAN[19 ] 的结构,在关注图像高频信息的同时,也减小了计算量加快了训练速度.在人脸图像超分辨率任务中,典型的工作有FSRNet[20 ] .该工作充分利用人脸图像的几何先验信息(以面部landmark和热力图的形式)提升图像的生成效果. ...
... 检索模块输出的图像和生成器G 输出的图像,在频道维度上拼接(concatenate)后送入融合模块,产生最终的生成图像. 融合模块的结构借鉴自pix2pix[9 ] 的生成器,使用U-Net[18 ] 结构,一种引入了跳层连接的编码-解码器. 使用U-Net结构的理由是,融合模块的输入和输出都是人脸图像(尽管维度不同),所以输入和输出具有相似的底层结构. 如果使用传统的编码-解码器结构,输入的信息会经过一系列下采样层、瓶颈层、上采样层后才传达至最终的输出,一些低层信息在这个过程中可能会损失. 而U-Net的跳层连接让输入的信息可以更直接地传达至输出端. ...
1
... 目前GAN在图像转换任务上有广泛应用.在一对一图像转换任务上,典型的工作有pix2pix[9 ] . 该工作将U-Net[18 ] 结构引入生成器,使用跳层连接缓解梯度消失和爆炸问题;判别器使用PatchGAN[19 ] 的结构,在关注图像高频信息的同时,也减小了计算量加快了训练速度.在人脸图像超分辨率任务中,典型的工作有FSRNet[20 ] .该工作充分利用人脸图像的几何先验信息(以面部landmark和热力图的形式)提升图像的生成效果. ...
1
... 目前GAN在图像转换任务上有广泛应用.在一对一图像转换任务上,典型的工作有pix2pix[9 ] . 该工作将U-Net[18 ] 结构引入生成器,使用跳层连接缓解梯度消失和爆炸问题;判别器使用PatchGAN[19 ] 的结构,在关注图像高频信息的同时,也减小了计算量加快了训练速度.在人脸图像超分辨率任务中,典型的工作有FSRNet[20 ] .该工作充分利用人脸图像的几何先验信息(以面部landmark和热力图的形式)提升图像的生成效果. ...
1
... 音频包括自然界的声音、演奏的音乐和语音,图像也包括人或自然风光的照片. Arandjelovic等[21 ] 通过训练深度神经网络来识别给定的视频和音频是否匹配,从而学习通用的跨模态表示. Castrejon等[22 ] 使用类似的方式学习一种跨模态表示. 这些跨模态表示常被用于跨模态检索任务. ...
1
... 音频包括自然界的声音、演奏的音乐和语音,图像也包括人或自然风光的照片. Arandjelovic等[21 ] 通过训练深度神经网络来识别给定的视频和音频是否匹配,从而学习通用的跨模态表示. Castrejon等[22 ] 使用类似的方式学习一种跨模态表示. 这些跨模态表示常被用于跨模态检索任务. ...
1
... 具体到语音-人脸图像的子集,细分任务和相关工作仍有很多. 例如,Yang等[23 ] 完成了语音-人脸图像跨模态身份匹配任务,即对于给定的语音,在人脸图像库里匹配与之身份对应的人脸图像;张晓冰等[24 ] 完成了中文识别唇语任务;Hoover等[25 ] 完成了从出现多人的视频中识别出正在说话/演讲的人的任务. ...
基于端到端句子级别的中文唇语识别研究
1
2020
... 具体到语音-人脸图像的子集,细分任务和相关工作仍有很多. 例如,Yang等[23 ] 完成了语音-人脸图像跨模态身份匹配任务,即对于给定的语音,在人脸图像库里匹配与之身份对应的人脸图像;张晓冰等[24 ] 完成了中文识别唇语任务;Hoover等[25 ] 完成了从出现多人的视频中识别出正在说话/演讲的人的任务. ...
基于端到端句子级别的中文唇语识别研究
1
2020
... 具体到语音-人脸图像的子集,细分任务和相关工作仍有很多. 例如,Yang等[23 ] 完成了语音-人脸图像跨模态身份匹配任务,即对于给定的语音,在人脸图像库里匹配与之身份对应的人脸图像;张晓冰等[24 ] 完成了中文识别唇语任务;Hoover等[25 ] 完成了从出现多人的视频中识别出正在说话/演讲的人的任务. ...
1
... 具体到语音-人脸图像的子集,细分任务和相关工作仍有很多. 例如,Yang等[23 ] 完成了语音-人脸图像跨模态身份匹配任务,即对于给定的语音,在人脸图像库里匹配与之身份对应的人脸图像;张晓冰等[24 ] 完成了中文识别唇语任务;Hoover等[25 ] 完成了从出现多人的视频中识别出正在说话/演讲的人的任务. ...
基于深度神经网络的语音驱动发音器官的运动合成
1
2016
... 基于音频的视觉重建(visual reconstruction from audio)从不同类型的音频信号中重建视觉信息,例如talking face任务,即给定一个静态人脸图像和一个语音剪辑,生成一段该人脸说话的视频,其中嘴唇与音频要同步. 唐郅等[26 ] 完成了语音驱动发音器官的运动合成任务. Sun等[27 ] 通过对比学习和课程学习的方法,完成了talking face任务. Zhou等[28 ] 在相同任务里通过低维姿态编码的方式,完成说话人脸的姿态可控生成. ...
基于深度神经网络的语音驱动发音器官的运动合成
1
2016
... 基于音频的视觉重建(visual reconstruction from audio)从不同类型的音频信号中重建视觉信息,例如talking face任务,即给定一个静态人脸图像和一个语音剪辑,生成一段该人脸说话的视频,其中嘴唇与音频要同步. 唐郅等[26 ] 完成了语音驱动发音器官的运动合成任务. Sun等[27 ] 通过对比学习和课程学习的方法,完成了talking face任务. Zhou等[28 ] 在相同任务里通过低维姿态编码的方式,完成说话人脸的姿态可控生成. ...
1
... 基于音频的视觉重建(visual reconstruction from audio)从不同类型的音频信号中重建视觉信息,例如talking face任务,即给定一个静态人脸图像和一个语音剪辑,生成一段该人脸说话的视频,其中嘴唇与音频要同步. 唐郅等[26 ] 完成了语音驱动发音器官的运动合成任务. Sun等[27 ] 通过对比学习和课程学习的方法,完成了talking face任务. Zhou等[28 ] 在相同任务里通过低维姿态编码的方式,完成说话人脸的姿态可控生成. ...
1
... 基于音频的视觉重建(visual reconstruction from audio)从不同类型的音频信号中重建视觉信息,例如talking face任务,即给定一个静态人脸图像和一个语音剪辑,生成一段该人脸说话的视频,其中嘴唇与音频要同步. 唐郅等[26 ] 完成了语音驱动发音器官的运动合成任务. Sun等[27 ] 通过对比学习和课程学习的方法,完成了talking face任务. Zhou等[28 ] 在相同任务里通过低维姿态编码的方式,完成说话人脸的姿态可控生成. ...
1
... Voxceleb 1数据集[29 ] 包含来自1251个不同身份的说话人的超过15万条语音片段. 每个语音片段的平均长度为8.2 s. 对应身份的人脸图像可以从VGG face数据集[30 ] 中获取,数量与语音片段相当.根据先前工作[31 ] 的划分方式,依照说话人的姓名首字母将数据集划分为训练集/验证集/测试集,验证集的首字母为A、B,测试集的首字母为C、D、E,其余为训练集. 将语音数据提前处理成Mel频谱的形式,人脸图像裁剪缩放为128×128像素的大小. ...
1
... Voxceleb 1数据集[29 ] 包含来自1251个不同身份的说话人的超过15万条语音片段. 每个语音片段的平均长度为8.2 s. 对应身份的人脸图像可以从VGG face数据集[30 ] 中获取,数量与语音片段相当.根据先前工作[31 ] 的划分方式,依照说话人的姓名首字母将数据集划分为训练集/验证集/测试集,验证集的首字母为A、B,测试集的首字母为C、D、E,其余为训练集. 将语音数据提前处理成Mel频谱的形式,人脸图像裁剪缩放为128×128像素的大小. ...
1
... Voxceleb 1数据集[29 ] 包含来自1251个不同身份的说话人的超过15万条语音片段. 每个语音片段的平均长度为8.2 s. 对应身份的人脸图像可以从VGG face数据集[30 ] 中获取,数量与语音片段相当.根据先前工作[31 ] 的划分方式,依照说话人的姓名首字母将数据集划分为训练集/验证集/测试集,验证集的首字母为A、B,测试集的首字母为C、D、E,其余为训练集. 将语音数据提前处理成Mel频谱的形式,人脸图像裁剪缩放为128×128像素的大小. ...
Deep expectation of real and apparent age from a single image without facial landmarks
1
2018
... 使用年龄评估模型[32 ] 给各个身份标注年龄区间. 每个身份随机取10张图片,取预测结果的平均值. 将年龄划分为10个区间,≤20岁为一组,>60岁为一组,20~60岁之间每5岁一组. ...
1
... 选取Speech2Face[13 ] 和Voice2Face[15 ] 作为对比模型. 所有模型在训练和测试时均使用8 s长度的音频数据. 本研究的数据处理方式和特征提取手段与Voice2Face的相同. 对于人脸图像,使用人脸检测模型提取VGGface数据集中的图像,通过相似变换后得到尺寸为3×64×64和3×128×128像素的RGB人脸图像,分别供Voice2Face和本研究的模型使用.使用预训练的ResNet-50[33 ] 模型作为图像编码器提取图像特征. 将图像中的每个像素减去127.5后再除以127.5进行归一化处理. 对于音频片段,均提取64维的梅尔频谱图,窗口宽度为25 ms,帧间距为10 ms,再进行均值和方差归一化处理. Speech2Face的数据处理方式略有不同. 对于人脸图像,使用基于Dlib[34 ] 的人脸检测器,从视频中裁剪人脸区域,经相似变换得到3×224×224像素的面部图像,通过预训练的VGG模型提取图像特征. 对于音频片段,Speech2Face的处理方式与Ephrat等[35 ] 的工作相同. ...
Dlib-ml: a machine learning toolkit
1
2009
... 选取Speech2Face[13 ] 和Voice2Face[15 ] 作为对比模型. 所有模型在训练和测试时均使用8 s长度的音频数据. 本研究的数据处理方式和特征提取手段与Voice2Face的相同. 对于人脸图像,使用人脸检测模型提取VGGface数据集中的图像,通过相似变换后得到尺寸为3×64×64和3×128×128像素的RGB人脸图像,分别供Voice2Face和本研究的模型使用.使用预训练的ResNet-50[33 ] 模型作为图像编码器提取图像特征. 将图像中的每个像素减去127.5后再除以127.5进行归一化处理. 对于音频片段,均提取64维的梅尔频谱图,窗口宽度为25 ms,帧间距为10 ms,再进行均值和方差归一化处理. Speech2Face的数据处理方式略有不同. 对于人脸图像,使用基于Dlib[34 ] 的人脸检测器,从视频中裁剪人脸区域,经相似变换得到3×224×224像素的面部图像,通过预训练的VGG模型提取图像特征. 对于音频片段,Speech2Face的处理方式与Ephrat等[35 ] 的工作相同. ...
Looking to listen at the cocktail party: a speaker-independent audio-visual model for speech separation
1
2018
... 选取Speech2Face[13 ] 和Voice2Face[15 ] 作为对比模型. 所有模型在训练和测试时均使用8 s长度的音频数据. 本研究的数据处理方式和特征提取手段与Voice2Face的相同. 对于人脸图像,使用人脸检测模型提取VGGface数据集中的图像,通过相似变换后得到尺寸为3×64×64和3×128×128像素的RGB人脸图像,分别供Voice2Face和本研究的模型使用.使用预训练的ResNet-50[33 ] 模型作为图像编码器提取图像特征. 将图像中的每个像素减去127.5后再除以127.5进行归一化处理. 对于音频片段,均提取64维的梅尔频谱图,窗口宽度为25 ms,帧间距为10 ms,再进行均值和方差归一化处理. Speech2Face的数据处理方式略有不同. 对于人脸图像,使用基于Dlib[34 ] 的人脸检测器,从视频中裁剪人脸区域,经相似变换得到3×224×224像素的面部图像,通过预训练的VGG模型提取图像特征. 对于音频片段,Speech2Face的处理方式与Ephrat等[35 ] 的工作相同. ...
1
... 为了衡量图像生成质量,使用FID(Fréchet inception distance)[36 ] 作为评估指标. FID越小,图像生成质量越佳. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}