[1]
NORONHA S, NEVATIA R Detection and modeling of buildings from multiple aerial images
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2001 , 23 (5 ): 501 - 518
DOI:10.1109/34.922708
[本文引用: 1]
[2]
COTE M, SAEEDI P Automatic rooftop extraction in nadir aerial imagery of suburban regions using corners and variational level set evolution
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2012 , 51 (1 ): 313 - 328
[3]
LI E, FEMIANI J, XU S, et al Robust rooftop extraction from visible band images using higher order CRF
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2015 , 53 (8 ): 4483 - 4495
DOI:10.1109/TGRS.2015.2400462
[4]
胡翔云, 巩晓雅, 张觅 变分法遥感影像人工地物自动检测
[J]. 测绘学报 , 2018 , 47 (6 ): 780 - 789
DOI:10.11947/j.AGCS.2018.20170642
HU Xiang-yun, GONG Xiao-ya, ZHANG Mi A variational approach for automatic man-made object detection from remote sensing image
[J]. Acta Geodaetica at Cartographica Sinica , 2018 , 47 (6 ): 780 - 789
DOI:10.11947/j.AGCS.2018.20170642
[6]
李道纪, 郭海涛, 卢俊, 等 遥感影像地物分类多注意力融和U型网络法
[J]. 测绘学报 , 2020 , 49 (8 ): 1051 - 1064
DOI:10.11947/j.AGCS.2020.20190407
[本文引用: 1]
LI Dao-ji, GUO Hai-tao, LU Jun, et al A remote sensing image classification procedure based on multilevel attention fusion UNet
[J]. Acta Geodaetica at Cartographica Sinica , 2020 , 49 (8 ): 1051 - 1064
DOI:10.11947/j.AGCS.2020.20190407
[本文引用: 1]
[7]
LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild [C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 3730-3738.
[本文引用: 1]
[8]
LONG J, SHELHAMER E, DARRElLL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Santiago: IEEE, 2015: 3431-3440.
[本文引用: 1]
[9]
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation [C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241.
[本文引用: 9]
[10]
BADRINARAYANAN V, KENDALL A, CIPOLLA R Segnet: a deep convolutional encoder-decoder architecture for image segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (12 ): 2481 - 2495
DOI:10.1109/TPAMI.2016.2644615
[本文引用: 1]
[11]
SIMONYAN K, VEDALDI A, ZISSERMAN A. Deep inside convolutional networks: visualizing image classification models and saliency maps [C]// Workshop at International Conference on Learning Representations. Banff: IEEE, 2014.
[本文引用: 1]
[12]
ZhAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2881-2890.
[本文引用: 9]
[13]
OKTAY O, SCHLEMPER J, FOLGOC L L, et al. Attention u-net: learning where to look for the pancreas [EB/OL]. (2018-04-11). https://arxiv.org/abs/1804.03999.
[本文引用: 6]
[14]
LIU P, WEI Y, WANG Q, et al Research on post-earthquake landslide extraction algorithm based on improved U-Net model
[J]. Remote Sensing , 2020 , 12 (5 ): 894
DOI:10.3390/rs12050894
[本文引用: 1]
[15]
TONG X Y, XIA G S, LU Q, et al Land-cover classification with high-resolution remote sensing images using transferable deep models
[J]. Remote Sensing of Environment , 2020 , 237 : 111322
[本文引用: 1]
[16]
SHAO Z, YANG K, ZHOU W Performance evaluation of single-label and multi-label remote sensing image retrieval using a dense labeling dataset
[J]. Remote Sensing , 2018 , 10 (6 ): 964
DOI:10.3390/rs10060964
[本文引用: 1]
[17]
SHAO Z, ZHOU W, DENG X, et al Multilabel remote sensing image retrieval based on fully convolutional network
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2020 , 13 (1 ): 318 - 328
DOI:10.1109/JSTARS.2019.2961634
[本文引用: 1]
[18]
ChEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. (2017-06-17). https://arxiv.org/abs/1706.05587.
[本文引用: 9]
[19]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoderdecoder with atrous separable convolution for semantic image segmentation [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 801-818.
[本文引用: 9]
[20]
RUI L, CEHNXI D, SHUNYI Z. MACU-Net semantic segmentation from high-resolution remote sensing images [EB/OL]. [2020-07-26]. https://arxiv.org/abs/2007.13083.
[本文引用: 5]
[21]
ZHOU Z, SIDDIQUEE M M R, TAJBAKHSH N, et al. Unet++: a nested u-net architecture for medical image segmentation [M]// Deep learning in medical image analysis and multimodal learning for clinical decision support . Cham: Springer, 2018: 3-11.
[本文引用: 5]
Detection and modeling of buildings from multiple aerial images
1
2001
... 早期的遥感影像语义分割,更多依靠研究人员根据人类对各种地物的认知和理解,通过设定不同的特征参数达到对影像地物提取的能力. 根据一种或多种人为归纳的地物特征对影像地物识别,如形状特征、颜色纹理特征或组合特征,对地物(建筑、植被、道路等)[1 -5 ] 进行识别检测. 遥感影像地物的特征千变万化,同一种地物,特征存在非常大的差异. 比如道路的颜色纹理、形状尺寸及光照角度和分辨率的不同,都会产生较大的区别. 基于人为设定特征提取遥感影像地物,变得异常困难[6 ] . ...
Automatic rooftop extraction in nadir aerial imagery of suburban regions using corners and variational level set evolution
0
2012
Robust rooftop extraction from visible band images using higher order CRF
0
2015
面向对象的形态学建筑物指数及其高分辨率遥感影像建筑物提取应用
1
2017
... 早期的遥感影像语义分割,更多依靠研究人员根据人类对各种地物的认知和理解,通过设定不同的特征参数达到对影像地物提取的能力. 根据一种或多种人为归纳的地物特征对影像地物识别,如形状特征、颜色纹理特征或组合特征,对地物(建筑、植被、道路等)[1 -5 ] 进行识别检测. 遥感影像地物的特征千变万化,同一种地物,特征存在非常大的差异. 比如道路的颜色纹理、形状尺寸及光照角度和分辨率的不同,都会产生较大的区别. 基于人为设定特征提取遥感影像地物,变得异常困难[6 ] . ...
面向对象的形态学建筑物指数及其高分辨率遥感影像建筑物提取应用
1
2017
... 早期的遥感影像语义分割,更多依靠研究人员根据人类对各种地物的认知和理解,通过设定不同的特征参数达到对影像地物提取的能力. 根据一种或多种人为归纳的地物特征对影像地物识别,如形状特征、颜色纹理特征或组合特征,对地物(建筑、植被、道路等)[1 -5 ] 进行识别检测. 遥感影像地物的特征千变万化,同一种地物,特征存在非常大的差异. 比如道路的颜色纹理、形状尺寸及光照角度和分辨率的不同,都会产生较大的区别. 基于人为设定特征提取遥感影像地物,变得异常困难[6 ] . ...
遥感影像地物分类多注意力融和U型网络法
1
2020
... 早期的遥感影像语义分割,更多依靠研究人员根据人类对各种地物的认知和理解,通过设定不同的特征参数达到对影像地物提取的能力. 根据一种或多种人为归纳的地物特征对影像地物识别,如形状特征、颜色纹理特征或组合特征,对地物(建筑、植被、道路等)[1 -5 ] 进行识别检测. 遥感影像地物的特征千变万化,同一种地物,特征存在非常大的差异. 比如道路的颜色纹理、形状尺寸及光照角度和分辨率的不同,都会产生较大的区别. 基于人为设定特征提取遥感影像地物,变得异常困难[6 ] . ...
遥感影像地物分类多注意力融和U型网络法
1
2020
... 早期的遥感影像语义分割,更多依靠研究人员根据人类对各种地物的认知和理解,通过设定不同的特征参数达到对影像地物提取的能力. 根据一种或多种人为归纳的地物特征对影像地物识别,如形状特征、颜色纹理特征或组合特征,对地物(建筑、植被、道路等)[1 -5 ] 进行识别检测. 遥感影像地物的特征千变万化,同一种地物,特征存在非常大的差异. 比如道路的颜色纹理、形状尺寸及光照角度和分辨率的不同,都会产生较大的区别. 基于人为设定特征提取遥感影像地物,变得异常困难[6 ] . ...
1
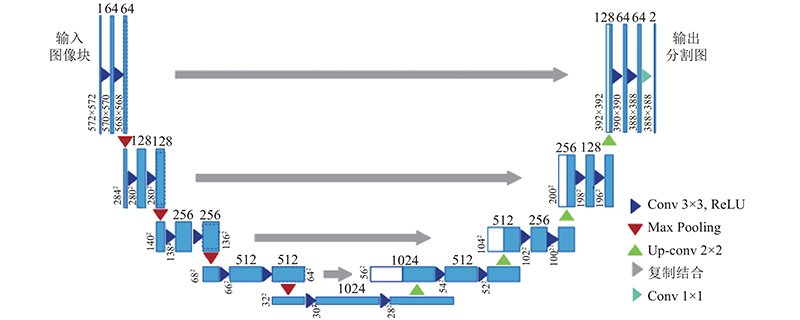
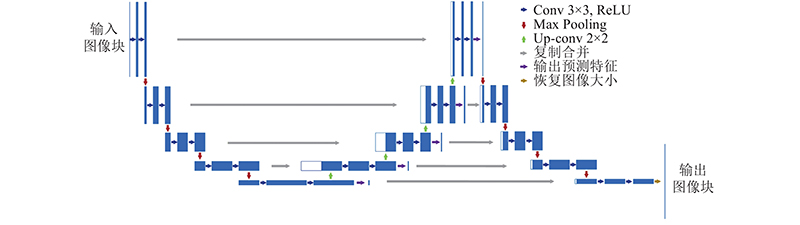
... 近年来,深度学习取得了突破性进展,其中卷积神经网络(CNN)通过非线性结构有效地提取中级和高级抽象特征,已广泛应用于图像分析领域并产生了巨大的影响[7 ] . 全卷积网络(FCNs)的出现,使遥感图像语义分割取得进一步的突破[8 ] . 在FCN之后,大量性能优异的语义分割网络被相继提出,典型的代表网络包括U-Net[9 ] 、SegNet[10 ] 、DeconvNet[11 ] 、PSPNet[12 ] . 其中U-Net对高低级语义信息进行融合,改善物体边界语义细节的分类效果,提高了网络的分类性能. ...
1
... 近年来,深度学习取得了突破性进展,其中卷积神经网络(CNN)通过非线性结构有效地提取中级和高级抽象特征,已广泛应用于图像分析领域并产生了巨大的影响[7 ] . 全卷积网络(FCNs)的出现,使遥感图像语义分割取得进一步的突破[8 ] . 在FCN之后,大量性能优异的语义分割网络被相继提出,典型的代表网络包括U-Net[9 ] 、SegNet[10 ] 、DeconvNet[11 ] 、PSPNet[12 ] . 其中U-Net对高低级语义信息进行融合,改善物体边界语义细节的分类效果,提高了网络的分类性能. ...
9
... 近年来,深度学习取得了突破性进展,其中卷积神经网络(CNN)通过非线性结构有效地提取中级和高级抽象特征,已广泛应用于图像分析领域并产生了巨大的影响[7 ] . 全卷积网络(FCNs)的出现,使遥感图像语义分割取得进一步的突破[8 ] . 在FCN之后,大量性能优异的语义分割网络被相继提出,典型的代表网络包括U-Net[9 ] 、SegNet[10 ] 、DeconvNet[11 ] 、PSPNet[12 ] . 其中U-Net对高低级语义信息进行融合,改善物体边界语义细节的分类效果,提高了网络的分类性能. ...
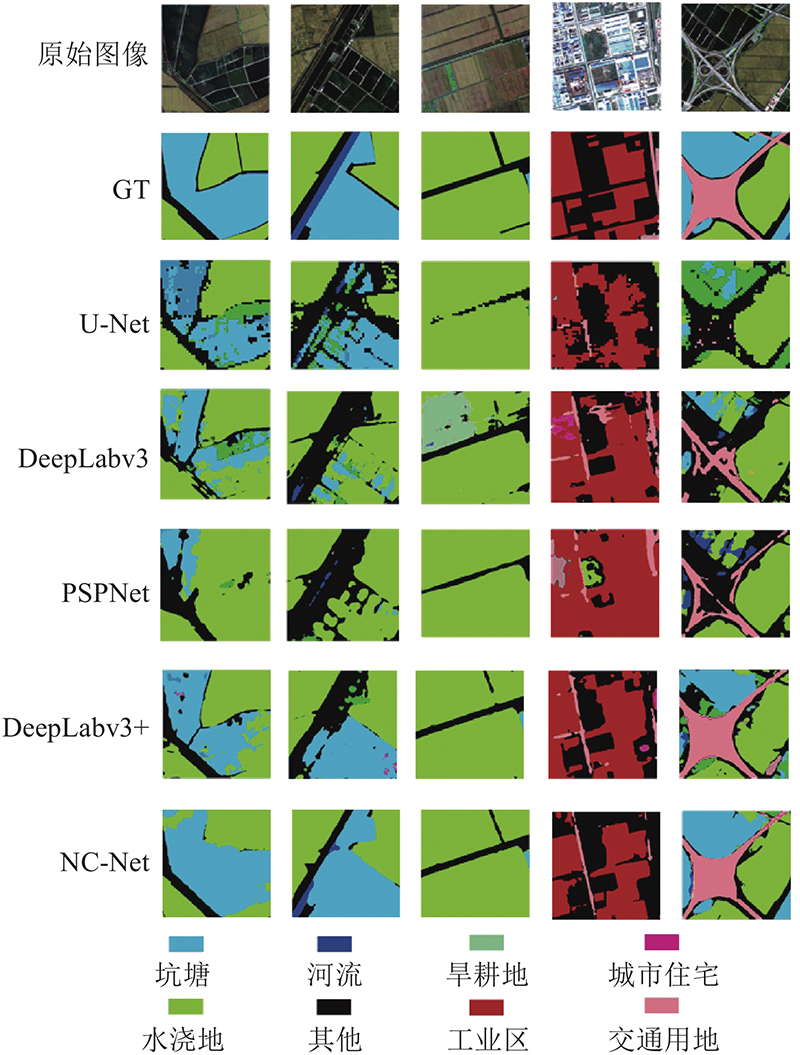
... Experimental results of GID
% Tab.1 方法 OA K FWIoU F 1 U-Net[9 ] 70.721 51.857 56.135 70.131 DeepLabv3[18 ] 74.072 60.702 61.330 75.247 PSPNet[12 ] 72.513 59.147 60.880 75.782 DeepLabv3+[19 ] 75.982 61.958 63.021 77.920 NC-Net 77.331 62.214 64.550 78.694
图 5 NC-Net和其他模型的视觉整体对比 ...
... Quantitative indicators for each category of GID
% Tab.2 标签类别 P r R F 1 U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50
表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... [
9 ]
Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50 表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... [
9 ]
Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50 表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
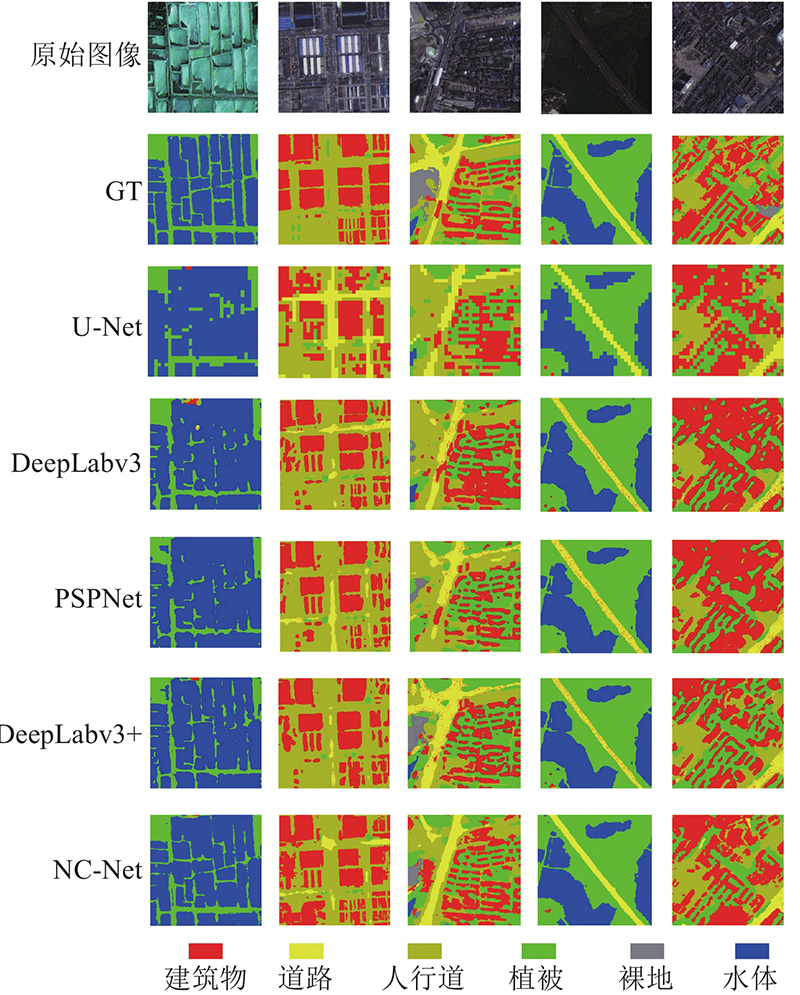
... WHDLD experimental results
% Tab.3 方法 OA K FWIoU F 1 U-Net[9 ] 76.218 70.816 69.709 70.066 DeepLabv3[18 ] 80.053 69.380 71.252 72.391 PSPNet[12 ] 78.406 71.528 69.039 71.002 DeepLabv3+[19 ] 81.295 76.524 73.157 75.563 NC-Net 84.897 79.944 76.025 76.301
图 7 WHDLD的可视化结果 ...
... Quantitative indicators for each category of WHDLD
% Tab.4 标签类别 P r R F 1 U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15
最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
... [
9 ]
Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15 最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
... [
9 ]
Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15 最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
Segnet: a deep convolutional encoder-decoder architecture for image segmentation
1
2017
... 近年来,深度学习取得了突破性进展,其中卷积神经网络(CNN)通过非线性结构有效地提取中级和高级抽象特征,已广泛应用于图像分析领域并产生了巨大的影响[7 ] . 全卷积网络(FCNs)的出现,使遥感图像语义分割取得进一步的突破[8 ] . 在FCN之后,大量性能优异的语义分割网络被相继提出,典型的代表网络包括U-Net[9 ] 、SegNet[10 ] 、DeconvNet[11 ] 、PSPNet[12 ] . 其中U-Net对高低级语义信息进行融合,改善物体边界语义细节的分类效果,提高了网络的分类性能. ...
1
... 近年来,深度学习取得了突破性进展,其中卷积神经网络(CNN)通过非线性结构有效地提取中级和高级抽象特征,已广泛应用于图像分析领域并产生了巨大的影响[7 ] . 全卷积网络(FCNs)的出现,使遥感图像语义分割取得进一步的突破[8 ] . 在FCN之后,大量性能优异的语义分割网络被相继提出,典型的代表网络包括U-Net[9 ] 、SegNet[10 ] 、DeconvNet[11 ] 、PSPNet[12 ] . 其中U-Net对高低级语义信息进行融合,改善物体边界语义细节的分类效果,提高了网络的分类性能. ...
9
... 近年来,深度学习取得了突破性进展,其中卷积神经网络(CNN)通过非线性结构有效地提取中级和高级抽象特征,已广泛应用于图像分析领域并产生了巨大的影响[7 ] . 全卷积网络(FCNs)的出现,使遥感图像语义分割取得进一步的突破[8 ] . 在FCN之后,大量性能优异的语义分割网络被相继提出,典型的代表网络包括U-Net[9 ] 、SegNet[10 ] 、DeconvNet[11 ] 、PSPNet[12 ] . 其中U-Net对高低级语义信息进行融合,改善物体边界语义细节的分类效果,提高了网络的分类性能. ...
... Experimental results of GID
% Tab.1 方法 OA K FWIoU F 1 U-Net[9 ] 70.721 51.857 56.135 70.131 DeepLabv3[18 ] 74.072 60.702 61.330 75.247 PSPNet[12 ] 72.513 59.147 60.880 75.782 DeepLabv3+[19 ] 75.982 61.958 63.021 77.920 NC-Net 77.331 62.214 64.550 78.694
图 5 NC-Net和其他模型的视觉整体对比 ...
... Quantitative indicators for each category of GID
% Tab.2 标签类别 P r R F 1 U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50
表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... [
12 ]
Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50 表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... [
12 ]
Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50 表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... WHDLD experimental results
% Tab.3 方法 OA K FWIoU F 1 U-Net[9 ] 76.218 70.816 69.709 70.066 DeepLabv3[18 ] 80.053 69.380 71.252 72.391 PSPNet[12 ] 78.406 71.528 69.039 71.002 DeepLabv3+[19 ] 81.295 76.524 73.157 75.563 NC-Net 84.897 79.944 76.025 76.301
图 7 WHDLD的可视化结果 ...
... Quantitative indicators for each category of WHDLD
% Tab.4 标签类别 P r R F 1 U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15
最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
... [
12 ]
Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15 最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
... [
12 ]
Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15 最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
6
... 已有大量研究针对网络改进,达到对遥感影像更高的识别精度. 将已有的高精度网络加上其他模块或针对网络本身的结构进行修改,都能够达到对遥感影像更好的理解和识别. 例如,Attention U-Net[13 ] 结构在U-Net网络高低级语义信息融合的过程中,加入注意力控制模块(Attention gates),强化了有效信息的传递,对无效信息的传输进行抑制. Liu等[14 ] 提出改进U-Net模型来提取地震后滑坡,通过在上下采样过程中增加学习单元,重建U-Net模型,解决传统U-Net模型无法完全提取六通道滑坡特征的问题,最终的准确率达到91.3%,比传统U-Net模型高8%. ...
... 为了评估NC-Net的有效性,与目前比较先进的PSPNet、DeepLabv3[18 ] 、DeepLabv3+[19 ] 及基线模型U-Net方法进行对比试验,还与文献[13 ,20 ,21 ]的方法进行对比. ...
... 前人已有关于U-Net网络方面的改进和性能提升方法. 对WHDLD数据集与Oktay等[13 ,20 -21 ] 提出的改进网络进行比较. 比较结果如表5 所示. 可以看出,提出的NC-Net相较于其他关于U-Net的改进,具有一定的性能优势. 与MACU-Net[20 ] 相比,K 提高了1.7%,F 1 提高了1%. 与U-Net++[21 ] 相比,OA提高了0.8%,FWIoU提升了1.6%. NC-Net在各项指标中均高于U-NetAtt[13 ] . 提出的NC-Net较其他人提出的关于U-Net的改进模型,具有一定的优势. ...
... [13 ]. 提出的NC-Net较其他人提出的关于U-Net的改进模型,具有一定的优势. ...
... Comparison of NC-Net with other improved networks on WHDLD
Tab.5 % 方法 OA K FWIoU F 1 U-NetAtt[13 ] 82.602 75.484 73.474 69.622 U-Net++[21 ] 84.067 77.430 74.496 74.633 MACU-Net[20 ] 84.623 78.233 75.231 75.245 NC-Net 84.897 79.944 76.025 76.301
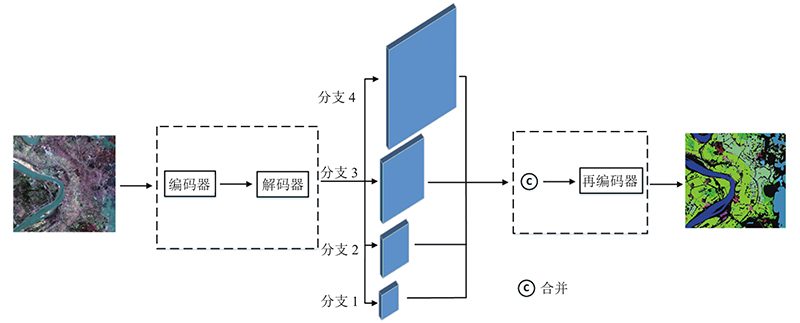
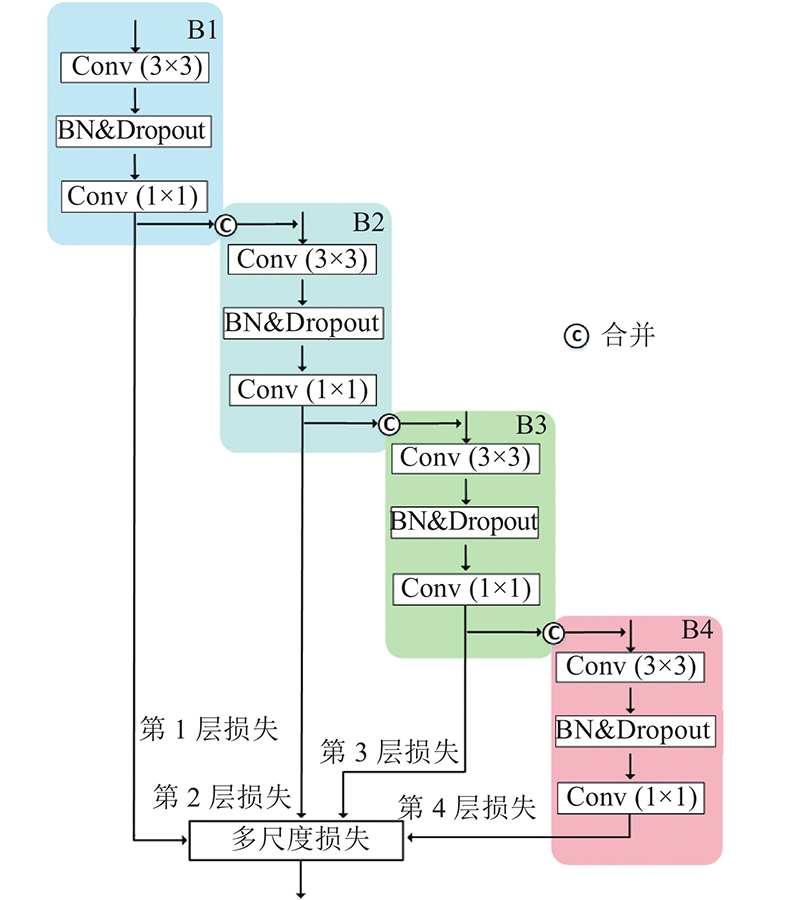
3. 结 语 本文提出基于U-Net网络结构的改进网络NC-Net. 该网络在标记数据不足和数据类别不平衡的遥感图像多类别语义分割中具有较好的性能. 提出多尺度特征融合再采样结构,能够有效地获取全局上下文信息. 提出多尺度损失函数级联算法,优化网络整体学习过程. 通过与其他方法进行对比,测试提出的网络架构. 实验结果表明,该方法在GID、WHDLD数据集上达到最高的精度. ...
... 本文研究基于深度学习的遥感图像语义分割. 为了实现高分辨率遥感影像的语义分割,基于U-Net基线网络提出NC-Net模型,在标记数据不足和数据类别不平衡的遥感图像多类别语义分割中表现出了较好的性能. 提出的多尺度输出特征能够学习到全局信息,通过融合再采样加强对上下文的理解. 在GID以及WHDLD上的实验表明, NC-Net算法超过了其他的基线算法. 与文献[13 ,20 ,21 ]算法的比较可知,本文提出的NC-Net具有一定的性能优势. 随着遥感图像信息的不断增加,未来可以继续优化网络结构,引入Transformer结构,提高网络对图像的识别准确率,增强鲁棒性. ...
Research on post-earthquake landslide extraction algorithm based on improved U-Net model
1
2020
... 已有大量研究针对网络改进,达到对遥感影像更高的识别精度. 将已有的高精度网络加上其他模块或针对网络本身的结构进行修改,都能够达到对遥感影像更好的理解和识别. 例如,Attention U-Net[13 ] 结构在U-Net网络高低级语义信息融合的过程中,加入注意力控制模块(Attention gates),强化了有效信息的传递,对无效信息的传输进行抑制. Liu等[14 ] 提出改进U-Net模型来提取地震后滑坡,通过在上下采样过程中增加学习单元,重建U-Net模型,解决传统U-Net模型无法完全提取六通道滑坡特征的问题,最终的准确率达到91.3%,比传统U-Net模型高8%. ...
Land-cover classification with high-resolution remote sensing images using transferable deep models
1
2020
... 使用到的第1个数据集为 GaoFen Image Dataset(GID)[15 ] . 该数据集包含中国60多个城市的高分2号卫星拍摄的7 200×6 800像素的RGB图像. GID由以下2个部分组成:一个是大型分类数据集,包含150个像素级别的GF-2图像;另一个是精细分类数据集,由30 000个多尺度图像块和10个像素级别的GF-2图像组成,类别扩充到15个. 选用后者包含15个类别的RGB图像. ...
Performance evaluation of single-label and multi-label remote sensing image retrieval using a dense labeling dataset
1
2018
... 使用到的第2个数据集WHDLD[16 -17 ] ,它是从武汉市区的大型遥感图像中裁剪出来的. WHDLD中每个图像的像素手动标记为以下6类,即建筑物、道路、路面、植被、裸土和水. 该数据集包含 4940 张 RGB 图像,像素大小为 256×256,分辨率为2 m. ...
Multilabel remote sensing image retrieval based on fully convolutional network
1
2020
... 使用到的第2个数据集WHDLD[16 -17 ] ,它是从武汉市区的大型遥感图像中裁剪出来的. WHDLD中每个图像的像素手动标记为以下6类,即建筑物、道路、路面、植被、裸土和水. 该数据集包含 4940 张 RGB 图像,像素大小为 256×256,分辨率为2 m. ...
9
... 为了评估NC-Net的有效性,与目前比较先进的PSPNet、DeepLabv3[18 ] 、DeepLabv3+[19 ] 及基线模型U-Net方法进行对比试验,还与文献[13 ,20 ,21 ]的方法进行对比. ...
... Experimental results of GID
% Tab.1 方法 OA K FWIoU F 1 U-Net[9 ] 70.721 51.857 56.135 70.131 DeepLabv3[18 ] 74.072 60.702 61.330 75.247 PSPNet[12 ] 72.513 59.147 60.880 75.782 DeepLabv3+[19 ] 75.982 61.958 63.021 77.920 NC-Net 77.331 62.214 64.550 78.694
图 5 NC-Net和其他模型的视觉整体对比 ...
... Quantitative indicators for each category of GID
% Tab.2 标签类别 P r R F 1 U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50
表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... [
18 ]
PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50 表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... [
18 ]
PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50 表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... WHDLD experimental results
% Tab.3 方法 OA K FWIoU F 1 U-Net[9 ] 76.218 70.816 69.709 70.066 DeepLabv3[18 ] 80.053 69.380 71.252 72.391 PSPNet[12 ] 78.406 71.528 69.039 71.002 DeepLabv3+[19 ] 81.295 76.524 73.157 75.563 NC-Net 84.897 79.944 76.025 76.301
图 7 WHDLD的可视化结果 ...
... Quantitative indicators for each category of WHDLD
% Tab.4 标签类别 P r R F 1 U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15
最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
... [
18 ]
PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15 最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
... [
18 ]
PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15 最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
9
... 为了评估NC-Net的有效性,与目前比较先进的PSPNet、DeepLabv3[18 ] 、DeepLabv3+[19 ] 及基线模型U-Net方法进行对比试验,还与文献[13 ,20 ,21 ]的方法进行对比. ...
... Experimental results of GID
% Tab.1 方法 OA K FWIoU F 1 U-Net[9 ] 70.721 51.857 56.135 70.131 DeepLabv3[18 ] 74.072 60.702 61.330 75.247 PSPNet[12 ] 72.513 59.147 60.880 75.782 DeepLabv3+[19 ] 75.982 61.958 63.021 77.920 NC-Net 77.331 62.214 64.550 78.694
图 5 NC-Net和其他模型的视觉整体对比 ...
... Quantitative indicators for each category of GID
% Tab.2 标签类别 P r R F 1 U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50
表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... [
19 ]
NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50 表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... [
19 ]
NC- 水浇地 85.61 84.95 81.77 88.22 86.73 83.69 86.91 91.59 89.73 91.94 84.63 85.91 86.40 88.96 89.25 园地 33.25 19.71 24.58 37.08 38.83 1.17 1.32 1.58 5.51 8.12 2.26 2.47 2.96 9.59 13.43 工业区 54.01 62.69 55.73 79.15 74.27 43.07 62.85 55.73 50.47 51.39 47.92 62.76 55.73 61.52 60.74 村镇住宅 73.97 82.92 76.73 78.77 90.65 64.75 74.15 75.52 83.78 65.10 69.05 78.29 76.12 81.19 75.77 交通用地 66.45 72.15 45.53 68.21 67.05 17.31 42.56 35.58 61.63 47.45 27.46 53.53 39.94 64.75 55.57 河流 39.91 23.70 21.47 22.43 42.87 3.95 1.21 4.25 4.43 5.30 7.18 2.30 7.09 7.39 9.43 湖泊 87.77 89.48 88.97 85.93 86.09 16.22 20.40 3.56 39.31 74.89 27.38 33.22 6.84 53.94 80.10 其他 38.62 39.23 34.07 43.90 46.69 48.25 61.84 44.02 59.59 62.65 42.90 48.00 38.41 50.55 53.50 表2 中已将最佳指标加粗标注. 从3项指标、多个类别的单独分析可以看出,NC-Net在大多数情况下都达到了最高分数,部分类别虽然没有达到, 但是与最高指标相差不多. 其次效果较好的是DeepLabv3+网络,这得益于该网络更精细化的设计. 可以看出,本文提出的网络在性能上优于其他网络. ...
... WHDLD experimental results
% Tab.3 方法 OA K FWIoU F 1 U-Net[9 ] 76.218 70.816 69.709 70.066 DeepLabv3[18 ] 80.053 69.380 71.252 72.391 PSPNet[12 ] 78.406 71.528 69.039 71.002 DeepLabv3+[19 ] 81.295 76.524 73.157 75.563 NC-Net 84.897 79.944 76.025 76.301
图 7 WHDLD的可视化结果 ...
... Quantitative indicators for each category of WHDLD
% Tab.4 标签类别 P r R F 1 U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15
最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
... [
19 ]
NC- U- [9 ] Deep- [18 ] PSP- [12 ] Deep- [19 ] NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15 最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
... [
19 ]
NC- 建筑物 67.72 70.28 69.53 72.36 72.78 68.07 68.93 70.33 72.98 72.19 67.89 69.59 69.92 72.16 72.48 道路 68.65 73.06 68.86 72.20 75.71 73.66 82.61 75.26 87.01 90.36 71.06 77.54 71.91 78.91 82.78 人行道 70.88 69.51 71.74 75.74 70.54 61.28 60.02 63.85 62.55 60.36 65.73 64.41 67.56 67.68 65.04 植被 65.07 66.03 65.91 68.04 68.98 68.80 70.33 69.04 70.83 71.12 66.88 68.11 67.43 69.40 70.03 裸地 71.92 74.43 72.09 75.97 76.26 66.31 69.95 70.72 71.76 72.07 69.00 72.12 71.39 72.84 74.10 水体 80.53 85.82 84.25 89.61 91.01 81.56 84.61 83.78 84.06 86.47 81.04 85.21 84.01 86.74 89.15 最佳指标已经加粗标注. 从表4 可以看出,NC-Net在较多类中占据最佳指标分数. 尤其在水体类别中,识别精度达到91%. 其他网络对水体类的识别效果较好. 分析原因可知,该数据集具有较大范围的水体标注,存在多张图片具有完全水体类别的现象. 所有网络对水体的识别准确率都较高. DeepLabv3+网络表现较好. 在建筑物、人行道2个类别中均有指标超过NC-Net. 总体来说,提出的NC-Net性能是最好的. ...
5
... 为了评估NC-Net的有效性,与目前比较先进的PSPNet、DeepLabv3[18 ] 、DeepLabv3+[19 ] 及基线模型U-Net方法进行对比试验,还与文献[13 ,20 ,21 ]的方法进行对比. ...
... 前人已有关于U-Net网络方面的改进和性能提升方法. 对WHDLD数据集与Oktay等[13 ,20 -21 ] 提出的改进网络进行比较. 比较结果如表5 所示. 可以看出,提出的NC-Net相较于其他关于U-Net的改进,具有一定的性能优势. 与MACU-Net[20 ] 相比,K 提高了1.7%,F 1 提高了1%. 与U-Net++[21 ] 相比,OA提高了0.8%,FWIoU提升了1.6%. NC-Net在各项指标中均高于U-NetAtt[13 ] . 提出的NC-Net较其他人提出的关于U-Net的改进模型,具有一定的优势. ...
... [20 ]相比,K 提高了1.7%,F 1 提高了1%. 与U-Net++[21 ] 相比,OA提高了0.8%,FWIoU提升了1.6%. NC-Net在各项指标中均高于U-NetAtt[13 ] . 提出的NC-Net较其他人提出的关于U-Net的改进模型,具有一定的优势. ...
... Comparison of NC-Net with other improved networks on WHDLD
Tab.5 % 方法 OA K FWIoU F 1 U-NetAtt[13 ] 82.602 75.484 73.474 69.622 U-Net++[21 ] 84.067 77.430 74.496 74.633 MACU-Net[20 ] 84.623 78.233 75.231 75.245 NC-Net 84.897 79.944 76.025 76.301
3. 结 语 本文提出基于U-Net网络结构的改进网络NC-Net. 该网络在标记数据不足和数据类别不平衡的遥感图像多类别语义分割中具有较好的性能. 提出多尺度特征融合再采样结构,能够有效地获取全局上下文信息. 提出多尺度损失函数级联算法,优化网络整体学习过程. 通过与其他方法进行对比,测试提出的网络架构. 实验结果表明,该方法在GID、WHDLD数据集上达到最高的精度. ...
... 本文研究基于深度学习的遥感图像语义分割. 为了实现高分辨率遥感影像的语义分割,基于U-Net基线网络提出NC-Net模型,在标记数据不足和数据类别不平衡的遥感图像多类别语义分割中表现出了较好的性能. 提出的多尺度输出特征能够学习到全局信息,通过融合再采样加强对上下文的理解. 在GID以及WHDLD上的实验表明, NC-Net算法超过了其他的基线算法. 与文献[13 ,20 ,21 ]算法的比较可知,本文提出的NC-Net具有一定的性能优势. 随着遥感图像信息的不断增加,未来可以继续优化网络结构,引入Transformer结构,提高网络对图像的识别准确率,增强鲁棒性. ...
5
... 为了评估NC-Net的有效性,与目前比较先进的PSPNet、DeepLabv3[18 ] 、DeepLabv3+[19 ] 及基线模型U-Net方法进行对比试验,还与文献[13 ,20 ,21 ]的方法进行对比. ...
... 前人已有关于U-Net网络方面的改进和性能提升方法. 对WHDLD数据集与Oktay等[13 ,20 -21 ] 提出的改进网络进行比较. 比较结果如表5 所示. 可以看出,提出的NC-Net相较于其他关于U-Net的改进,具有一定的性能优势. 与MACU-Net[20 ] 相比,K 提高了1.7%,F 1 提高了1%. 与U-Net++[21 ] 相比,OA提高了0.8%,FWIoU提升了1.6%. NC-Net在各项指标中均高于U-NetAtt[13 ] . 提出的NC-Net较其他人提出的关于U-Net的改进模型,具有一定的优势. ...
... [21 ]相比,OA提高了0.8%,FWIoU提升了1.6%. NC-Net在各项指标中均高于U-NetAtt[13 ] . 提出的NC-Net较其他人提出的关于U-Net的改进模型,具有一定的优势. ...
... Comparison of NC-Net with other improved networks on WHDLD
Tab.5 % 方法 OA K FWIoU F 1 U-NetAtt[13 ] 82.602 75.484 73.474 69.622 U-Net++[21 ] 84.067 77.430 74.496 74.633 MACU-Net[20 ] 84.623 78.233 75.231 75.245 NC-Net 84.897 79.944 76.025 76.301
3. 结 语 本文提出基于U-Net网络结构的改进网络NC-Net. 该网络在标记数据不足和数据类别不平衡的遥感图像多类别语义分割中具有较好的性能. 提出多尺度特征融合再采样结构,能够有效地获取全局上下文信息. 提出多尺度损失函数级联算法,优化网络整体学习过程. 通过与其他方法进行对比,测试提出的网络架构. 实验结果表明,该方法在GID、WHDLD数据集上达到最高的精度. ...
... 本文研究基于深度学习的遥感图像语义分割. 为了实现高分辨率遥感影像的语义分割,基于U-Net基线网络提出NC-Net模型,在标记数据不足和数据类别不平衡的遥感图像多类别语义分割中表现出了较好的性能. 提出的多尺度输出特征能够学习到全局信息,通过融合再采样加强对上下文的理解. 在GID以及WHDLD上的实验表明, NC-Net算法超过了其他的基线算法. 与文献[13 ,20 ,21 ]算法的比较可知,本文提出的NC-Net具有一定的性能优势. 随着遥感图像信息的不断增加,未来可以继续优化网络结构,引入Transformer结构,提高网络对图像的识别准确率,增强鲁棒性. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}