[1]
HEIKKILÄ M, PIETIKÄINEN M, SCHMID C Description of interest regions with local binary patterns
[J]. Pattern Recognition , 2009 , 42 (3 ): 425 - 436
DOI:10.1016/j.patcog.2008.08.014
[本文引用: 1]
[2]
LINDEBERG T. Scale invariant feature transform [M]. 2012: 10491.
[本文引用: 1]
[3]
DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]// 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition . San Diego: IEEE, 2005: 886-893.
[本文引用: 1]
[4]
SUYKENS J A, VANDEWALLE J Least squares support vector machine classifiers
[J]. Neural processing letters , 1999 , 9 (3 ): 293 - 300
DOI:10.1023/A:1018628609742
[本文引用: 1]
[5]
FARHADI A, HEJRATI M, SADEGHI M A, et al. Every picture tells a story: generating sentences from images [M]// DANIILIDIS K, MARAGOS P, PARAGIOS N. Computer vision: ECCV 2010 . [S. l.]: Springer, 2010: 15-29.
[本文引用: 1]
[6]
KIROS R, SALAKHUTDINOV R, ZEMEL R S. Unifying visual-semantic embeddings with multimodal neural language models [EB/OL].[2021-03-05]. https://arxiv.org/pdf/1411.2539.pdf.
[本文引用: 1]
[8]
XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [EB/OL]. [2021-03-05]. https://arxiv.org/pdf/1502.03044.pdf.
[本文引用: 2]
[9]
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 375-383.
[本文引用: 2]
[10]
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6077-6086.
[本文引用: 5]
[11]
GU J, CAI J, WANG G, et al. Stack-captioning: coarse-to-fine learning for image captioning [C]// Thirty-Second AAAI Conference on Artificial Intelligence , 2018: 12266.
[本文引用: 1]
[12]
WANG W, CHEN Z, HU H. Hierarchical attention network for image captioning [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Hawaii: EI, 2019: 8957-8964.
[本文引用: 1]
[13]
赵小虎, 尹良飞, 赵成龙 基于全局-局部特征和自适应注意力机制的图像语义描述算法
[J]. 浙江大学学报:工学版 , 2020 , 54 (1 ): 126 - 134
[本文引用: 2]
ZHAO Xiao-hu, YIN Liang-fei, ZHAO Cheng-long Image captioning based on global-local feature and adaptive-attention
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (1 ): 126 - 134
[本文引用: 2]
[14]
WANG J, WANG W, WANG L, et al Learning visual relationship and context-aware attention for image captioning
[J]. Pattern Recognition , 2020 , 98 : 107075
DOI:10.1016/j.patcog.2019.107075
[本文引用: 2]
[15]
KE L, PEI W, LI R, et al. Reflective decoding network for image captioning [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 8888-8897.
[本文引用: 2]
[16]
ZHOU Y, WANG M, LIU D, et al. More grounded image captioning by distilling image-text matching model [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Venice: IEEE, 2020: 4777-4786.
[本文引用: 2]
[17]
HOU J, WU X, ZHANG X, et al. Joint commonsense and relation reasoning for image and video captioning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: [s. n.], 2020: 10973-10980.
[本文引用: 2]
[18]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 2]
[19]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL].[2021-03-05]. https://arxiv.org/pdf/1706.03762.pdf.
[本文引用: 2]
[20]
WANG J, JIANG W, MA L, et al. Bidirectional attentive fusion with context gating for dense video captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7190-7198.
[本文引用: 1]
[21]
VEDANTAM R, LAWRENCE ZITNICK C, PARIKH D. Cider: consensus-based image description evaluation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 4566-4575.
[本文引用: 2]
[22]
LIN T-Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [M]// FLEET D, PAJDLA T, SCHIELE B, et al. Computer vision: ECCV 2014. [S.l.]: Springer, 2014: 740-755.
[本文引用: 2]
[23]
PLUMMER B A, WANG L, CERVANTES C M, et al. Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models [J] International Journal of Computer Vision , 2017, 123: 74-93.
[本文引用: 2]
[24]
JOHNSON J, KARPATHY A, LI F-F. DenseCap: fully convolutional localization networks for dense captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 4565-4574.
[本文引用: 1]
[25]
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia: IEEE, 2002: 311-318.
[本文引用: 1]
[26]
DENKOWSKI M, LAVIE A. Meteor 1.3: automatic metric for reliable optimization and evaluation of machine translation systems [C]// Proceedings of the Sixth Workshop on Statistical Machine Translation . Scotland: IEEE, 2011: 85-91.
[本文引用: 1]
[27]
LIN C Y. Rouge: a package for automatic evaluation of summaries [C]// Proceedings of Workshop on Text Summarization Branches Out, Post-Conference Workshop of ACL 2004 . Barcelona: [s. n.], 2004: 1-10.
[本文引用: 1]
[28]
ANDERSON P, FERNANDO B, JOHNSON M, et al. Spice: semantic propositional image caption evaluation [M]// LEIBE B, MATAS J, SEBE N, et al. Computer vision: ECCV 2016 . [S. l.]: Springer, 2016: 382-398.
[本文引用: 1]
[29]
KRISHNA R, ZHU Y, GROTH O, et al Visual genome: connecting language and vision using crowdsourced dense image annotations
[J]. International Journal of Computer Vision , 2017 , 123 (1 ): 32 - 73
DOI:10.1007/s11263-016-0981-7
[本文引用: 1]
[30]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE conference on computer vision and pattern recognition. Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[31]
PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . [S. l.]: ACL, 2014: 1532-1543.
[本文引用: 1]
[32]
KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL].[2021-03-05]. https://arxiv.org/pdf/1412.6980.pdf.
[本文引用: 1]
[33]
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 7008-7024.
[本文引用: 1]
[34]
LU J, YANG J, BATRA D, et al. Neural baby talk [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7219-7228.
[本文引用: 1]
Description of interest regions with local binary patterns
1
2009
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
1
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
1
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
Least squares support vector machine classifiers
1
1999
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
1
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
1
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
Long short-term memory
3
1997
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
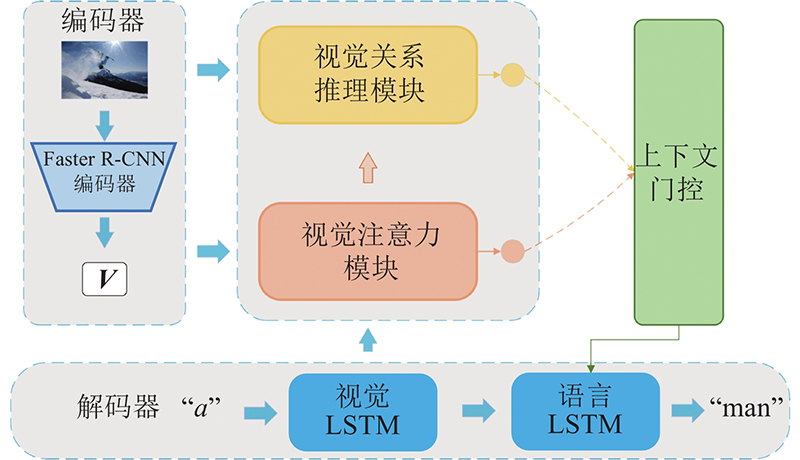
... 本研究算法的架构如图1 所示. 当给定图像I 作为输入,图像描述模型需要生成一段描述序列 ${\boldsymbol{S}}=\left[ {{w_1},{w_2}, \ldots ,{w_T}} \right],{w_t} \in D$ D 为词典词汇集合,T 是序列长度. 采用Anderson等[10 ] 提出的R-CNN-LSTM架构作为图像描述模型的基础框架. 具体来说,使用目标检测模块(Faster R-CNN)[18 ] 检测每张图片中的视觉对象 ${{\boldsymbol{V}}}=\left[ {{{\boldsymbol{v}}_1},{{\boldsymbol{v}}_2}, \ldots ,{{\boldsymbol{v}}_N}} \right]$ $ {\boldsymbol{v}} $ d 维的视觉对象语义向量,同时每个视觉对象还拥有对应的边界框位置特征b x , y , w , h ],其中x 、 y 为边界框的中心坐标,w 、h 分别为边界框的宽度、高度. 在解码器端,RNN被用来引导注意力机制和描述序列的生成. 受启发于Anderson等[10 ] 提出的自上而下的注意力框架,本研究采用2层LSTM[7 ] 作为解码器. ...
... 为了控制视觉关系模块和视觉注意力模块生成的不同模态特征的输出,即当需要生成视觉对象词时,更多地考虑视觉对象注意力模块的特征,在生成关系词时,更多地考虑视觉关系推理模块的特征,受LSTM[7 ] 中的门控机制和密集视频描述[20 ] 中工作的启发,将上下文门控机制动态引入模型中,以控制视觉对象级别上下文和视觉关系级别上下文的贡献. 当视觉注意力模块生成视觉对象特征A R
2
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
... 在图像描述模型中,图像中的视觉对象的完整性、全面性对描述质量非常重要. 为此,本研究将软注意力机制[8 ] 引入视觉注意力模块. 传统的注意力机制在产生视觉对象词汇方面已经充分展示了其优势. 因此,相比于描述每个视觉区域特征间的关系,视觉注意力模块主要目的是找到与当前时间步视觉实体单词最相关的视觉区域特征,可以理解为该模块试图找到每张图片中的名词视觉对象. 具体的,给定视觉区域的特征V
2
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
5
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
... 本研究算法的架构如图1 所示. 当给定图像I 作为输入,图像描述模型需要生成一段描述序列 ${\boldsymbol{S}}=\left[ {{w_1},{w_2}, \ldots ,{w_T}} \right],{w_t} \in D$ D 为词典词汇集合,T 是序列长度. 采用Anderson等[10 ] 提出的R-CNN-LSTM架构作为图像描述模型的基础框架. 具体来说,使用目标检测模块(Faster R-CNN)[18 ] 检测每张图片中的视觉对象 ${{\boldsymbol{V}}}=\left[ {{{\boldsymbol{v}}_1},{{\boldsymbol{v}}_2}, \ldots ,{{\boldsymbol{v}}_N}} \right]$ $ {\boldsymbol{v}} $ d 维的视觉对象语义向量,同时每个视觉对象还拥有对应的边界框位置特征b x , y , w , h ],其中x 、 y 为边界框的中心坐标,w 、h 分别为边界框的宽度、高度. 在解码器端,RNN被用来引导注意力机制和描述序列的生成. 受启发于Anderson等[10 ] 提出的自上而下的注意力框架,本研究采用2层LSTM[7 ] 作为解码器. ...
... [10 ]提出的自上而下的注意力框架,本研究采用2层LSTM[7 ] 作为解码器. ...
... 使用Anderson等[10 ] 的自下而上的方法进行图像特征提取. 由Krishna等[29 ] 提出的Visual genome数据集结合ResNet-101[30 ] 预训练的Faster R-CNN[18 ] 的生成. Faster R-CNN提取出图像中前36个置信度最高的显著目标区域并生成相应的边界框,在最后一个卷积层的特征图中使用ResNet-101获得2 048维区域特征. 边界框的坐标还用于计算空间特征. ...
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
1
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
1
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
基于全局-局部特征和自适应注意力机制的图像语义描述算法
2
2020
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
基于全局-局部特征和自适应注意力机制的图像语义描述算法
2
2020
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
Learning visual relationship and context-aware attention for image captioning
2
2020
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
2
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
2
... 图像描述是高级视觉任务,旨在描述图像正确内容. 对机器来说,执行图像描述不仅要全面了解对象、场景及其相互关系,还要使用语义和句法正确的句子描述图像的内容. 传统图像描述算法主要通过基于手工特征的语言模板生成描述:1)通过局部二值模式(local binary pattens, LBP)[1 ] 、尺度不变特征转换(scale-invariant feature transform, SIFT)[2 ] 、方向梯度直方图(histogram of oriented gradients, HOG)[3 ] 等算法提取图像的视觉特征;2)提取的特征被作为输入数据,传输到支持向量机(support vector machine, SVM)分类器[4 ] 识别出对应物体的类别. 由于不同的任务需要构造不同的手工特征,同时用于生成语句的模板较为固定,会导致生成的句子形式不够丰富. Farhadi等[5 ] 使用物体检测算法推断图像场景的关键物体,通过模板的方法生成描述内容的自然语句. Kiros等[6 ] 提出基于深度神经网络的图像描述算法:将图像特征映射到对应描述信息的嵌入表示空间,并通过长短期记忆(long short-term memory,LSTM)[7 ] 模型生成图像描述. Xu等[8 ] 提出基于软注意力和硬注意力机制的图像描述模型,该机制允许模型根据不同的单词增加图像相关区域的权重. 由于句中存在不需要图像信息也能生成的非视觉单词,Lu等[9 ] 提出的视觉门控机制,使模型可以选择是否在每个时间都对图像进行注意力机制操作. Anderson等[10 ] 提出的模型结合自下而上和自上而下的注意力机制,引入目标检测使模型可以在视觉对象级别上处理图像信息. Gu等[11 ] 提出针对图像描述的多阶段预测框架,通过不断提高注意力权重,让模型提取到更细致的图像信息. Wang等[12 ] 提出的层次注意力网络,计算各种模态视觉特征的注意力,并通过并行的多元残差模块执行特征融合. 赵小虎等[13 ] 提出基于全局–局部特征与自适应注意力机制的图像描述模型,该方法通过提取图像不同粒度的特征加强图像信息的丰富程度,并通过自适应注意力机制对图像特征加权输入,有效提高了模型描述图像的全面性,对于微小物体的识别准确率更高. Wang等[14 ] 提出基于门控循环单元(gated recurrent unit,GRU)的图像实体整合模块,它通过GRU建立卷积神经网络各个通道语义向量间的初等关系,提升了模型编码端的整体效果. Ke等[15 ] 提出反射解码网络,同时运用图像注意力和文本注意力,通过应用语言的内在特性提高图像描述的性能. Zhou等[16 ] 提出SCAN模块,对图像描述模型中的注意力结果进行弱监督. ...
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
2
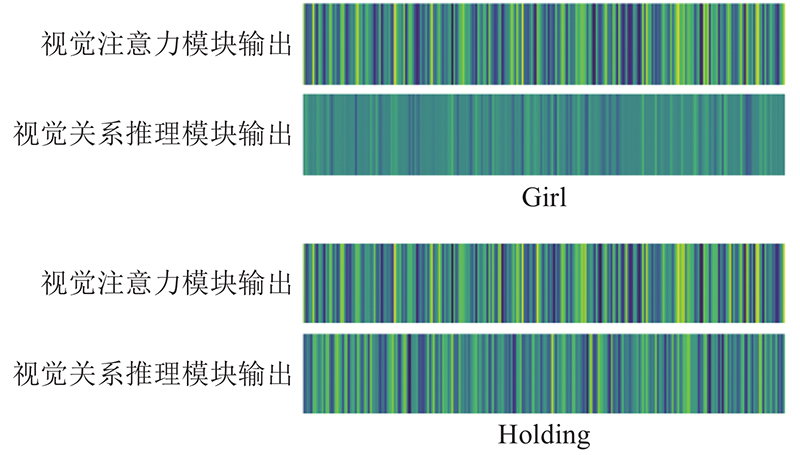
... 大多数的图像描述模型均基于注意力机制,解码器端每生成一个单词,都会通过注意力机制将与当前单词最相关的视觉实体区域提取出来,达到增加效果的目的. 但当人们描述某个图像场景时,不仅会关注场景中的每个实体,也会思考每个实体间的关系. 实体和实体间的关系共同组成一个恰当的句子来描述当前场景. 这是大多数的模型尚未探索的领域. 对此,本研究提出视觉关系推理模块以构建视觉关系推理模型,该模型可以根据不同的语义和空间上下文,动态编码视觉区域间的关系模式;引入自适应上下文门控机制以动态控制视觉注意力模块和视觉关系推理模块的作用,该机制允许根据不同类型的特征(视觉实体或视觉关系)预测不同的单词. 相对于Hou等[17 ] 提出的基于关系推理的图像描述方法,本研究没有引入额外的常识引导数据,而是期望模型从现有数据里集中端到端的建模对象关系,同时利用改造的注意力机制更直接地建模对象多对多的关系. ...
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
Faster R-CNN: towards real-time object detection with region proposal networks
2
2017
... 本研究算法的架构如图1 所示. 当给定图像I 作为输入,图像描述模型需要生成一段描述序列 ${\boldsymbol{S}}=\left[ {{w_1},{w_2}, \ldots ,{w_T}} \right],{w_t} \in D$ D 为词典词汇集合,T 是序列长度. 采用Anderson等[10 ] 提出的R-CNN-LSTM架构作为图像描述模型的基础框架. 具体来说,使用目标检测模块(Faster R-CNN)[18 ] 检测每张图片中的视觉对象 ${{\boldsymbol{V}}}=\left[ {{{\boldsymbol{v}}_1},{{\boldsymbol{v}}_2}, \ldots ,{{\boldsymbol{v}}_N}} \right]$ $ {\boldsymbol{v}} $ d 维的视觉对象语义向量,同时每个视觉对象还拥有对应的边界框位置特征b x , y , w , h ],其中x 、 y 为边界框的中心坐标,w 、h 分别为边界框的宽度、高度. 在解码器端,RNN被用来引导注意力机制和描述序列的生成. 受启发于Anderson等[10 ] 提出的自上而下的注意力框架,本研究采用2层LSTM[7 ] 作为解码器. ...
... 使用Anderson等[10 ] 的自下而上的方法进行图像特征提取. 由Krishna等[29 ] 提出的Visual genome数据集结合ResNet-101[30 ] 预训练的Faster R-CNN[18 ] 的生成. Faster R-CNN提取出图像中前36个置信度最高的显著目标区域并生成相应的边界框,在最后一个卷积层的特征图中使用ResNet-101获得2 048维区域特征. 边界框的坐标还用于计算空间特征. ...
2
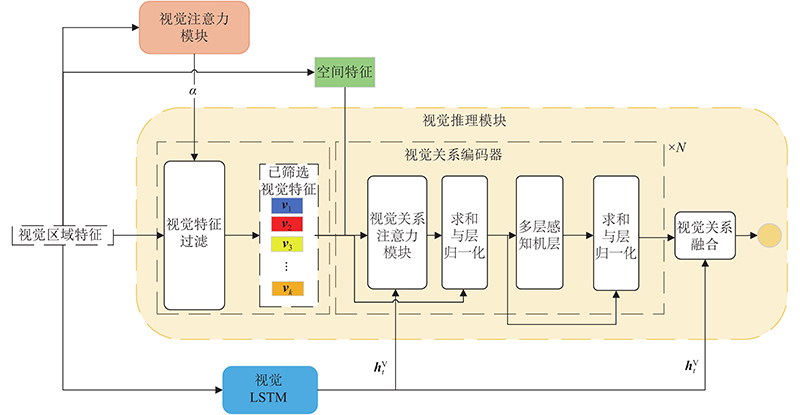
... 视觉对象间的关系在不同的语义和空间上下文中应该是不同的,同时每个视觉对象间应该存在一对多,多对多的关系. 为了建模视觉注意力模块提取的视觉对象间复杂多变的关系,基于扩展的自注意力机制[19 ] ,使用视觉关系推理模块扩展模型. 直观来说,该模块可以通过每个视觉区域在不同语义和空间状态下的关系,在每个时间步t 处推断出适当的关系词特征. 视觉关系推理模块由3个部分组成:1)基于注意力数值的视觉对象过滤机制,可以使用视觉注意模块筛选视觉区域特征的子集;2)视觉关系编码器,可以动态地编码每个视觉区域间的语义和空间位置关系;3)视觉关系融合,可以推断当前时间步与视觉关系词最相关的视觉关系特征. 视觉关系推理模块框架如图2 所示. ...
... 为了增加泛化性,参考文献[19 ]中的多头自注意力模块的形式,对视觉关系注意力模块进行堆叠: ...
1
... 为了控制视觉关系模块和视觉注意力模块生成的不同模态特征的输出,即当需要生成视觉对象词时,更多地考虑视觉对象注意力模块的特征,在生成关系词时,更多地考虑视觉关系推理模块的特征,受LSTM[7 ] 中的门控机制和密集视频描述[20 ] 中工作的启发,将上下文门控机制动态引入模型中,以控制视觉对象级别上下文和视觉关系级别上下文的贡献. 当视觉注意力模块生成视觉对象特征A R
2
... 为了优化模型,采用交叉熵损失(XE). XE不是完成图像描述任务的最终指标,因此CIDEr[21 ] 也被用作目标函数微调本研究模型. 具体流程为将CIDEr的负面期望得分降至最低: ...
... 为了公平地评估所生成描述的质量,使用在以往的模型中广泛使用的评价指标:BLEU[25 ] 、METEOR[26 ] 、ROUGE[27 ] 、CIDEr[21 ] 和SPICE[28 ] . ...
2
... 在2个公共基准数据集Microsoft COCO[22 ] 、Flickr30k[23 ] 上将本研究模型与以往方法进行比较. ...
... Microsoft COCO[22 ] 数据集是最大的公共图像标题数据集,本研究将其引为基准数据集. 数据集中有123 287张图像,其中82 783张用于训练,40 504张用于验证. 每个图像都有5条人类注释. 为了进行评估,本研究使用Johnson等[24 ] 的划分包含113 287、5 000和5 000张图像进行训练、验证和评估. ...
2
... 在2个公共基准数据集Microsoft COCO[22 ] 、Flickr30k[23 ] 上将本研究模型与以往方法进行比较. ...
... Flickr30k[23 ] 包含158 915句描述和从Flickr收集的31 783张图像. 该数据集扩展了以前的Flickr8k数据集,主要描述人类的日常活动和事件. 每个图像在数据集中都有5个参考标题. 为了与现有研究进行公平比较,使用公开可用的训练测试集划分:用于训练的图像为29 783张,用于验证的图像为1 000张,用于测试的图像为1 000张. ...
1
... Microsoft COCO[22 ] 数据集是最大的公共图像标题数据集,本研究将其引为基准数据集. 数据集中有123 287张图像,其中82 783张用于训练,40 504张用于验证. 每个图像都有5条人类注释. 为了进行评估,本研究使用Johnson等[24 ] 的划分包含113 287、5 000和5 000张图像进行训练、验证和评估. ...
1
... 为了公平地评估所生成描述的质量,使用在以往的模型中广泛使用的评价指标:BLEU[25 ] 、METEOR[26 ] 、ROUGE[27 ] 、CIDEr[21 ] 和SPICE[28 ] . ...
1
... 为了公平地评估所生成描述的质量,使用在以往的模型中广泛使用的评价指标:BLEU[25 ] 、METEOR[26 ] 、ROUGE[27 ] 、CIDEr[21 ] 和SPICE[28 ] . ...
1
... 为了公平地评估所生成描述的质量,使用在以往的模型中广泛使用的评价指标:BLEU[25 ] 、METEOR[26 ] 、ROUGE[27 ] 、CIDEr[21 ] 和SPICE[28 ] . ...
1
... 为了公平地评估所生成描述的质量,使用在以往的模型中广泛使用的评价指标:BLEU[25 ] 、METEOR[26 ] 、ROUGE[27 ] 、CIDEr[21 ] 和SPICE[28 ] . ...
Visual genome: connecting language and vision using crowdsourced dense image annotations
1
2017
... 使用Anderson等[10 ] 的自下而上的方法进行图像特征提取. 由Krishna等[29 ] 提出的Visual genome数据集结合ResNet-101[30 ] 预训练的Faster R-CNN[18 ] 的生成. Faster R-CNN提取出图像中前36个置信度最高的显著目标区域并生成相应的边界框,在最后一个卷积层的特征图中使用ResNet-101获得2 048维区域特征. 边界框的坐标还用于计算空间特征. ...
1
... 使用Anderson等[10 ] 的自下而上的方法进行图像特征提取. 由Krishna等[29 ] 提出的Visual genome数据集结合ResNet-101[30 ] 预训练的Faster R-CNN[18 ] 的生成. Faster R-CNN提取出图像中前36个置信度最高的显著目标区域并生成相应的边界框,在最后一个卷积层的特征图中使用ResNet-101获得2 048维区域特征. 边界框的坐标还用于计算空间特征. ...
1
... 词向量采用Glove方法[31 ] 进行训练,其向量维度是1 024. 对于动态图关系推理模块,将2个LSTM的隐层维度大小设置为1 024,视觉对象过滤机制参数m=9. 视觉关系注意力模块的堆叠层数设N =6,多头注意力数设H =5. 视觉注意力模块的隐层大小设置为768. 训练的批次大小为256的Adam[32 ] 优化器训练整个模型. 本研究最初将交叉熵训练的学习率设置为 $ 5\times {10}^{-4} $ $ 20 $ $ 5\mathrm{ }\times {10}^{-5} $ $ 20\mathrm{\%} $
1
... 词向量采用Glove方法[31 ] 进行训练,其向量维度是1 024. 对于动态图关系推理模块,将2个LSTM的隐层维度大小设置为1 024,视觉对象过滤机制参数m=9. 视觉关系注意力模块的堆叠层数设N =6,多头注意力数设H =5. 视觉注意力模块的隐层大小设置为768. 训练的批次大小为256的Adam[32 ] 优化器训练整个模型. 本研究最初将交叉熵训练的学习率设置为 $ 5\times {10}^{-4} $ $ 20 $ $ 5\mathrm{ }\times {10}^{-5} $ $ 20\mathrm{\%} $
1
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...
1
... 为了评估Microsoft COCO与Flickr30k数据集,对比提出的2种模型与最新模型的性能:Adaptive[9 ] 、Att2in[33 ] 、NBT[34 ] 、GL-Att[13 ] 、LRCA[14 ] 、RFNet[15 ] 、POS-SCAN[16 ] 、JCRR[17 ] 和Updown[10 ] . 如表3 所示为Microsoft COCO基于Karparthy测试集的结果. 可以看出,本研究的2种模型在所有指标上XE目标和CIDEr都有所提高. 其中本研究模型对比基线POS-SCAN模型在CIDEr指标方面提高1.1%. 表4 中显示本研究提出的模型在Flick30k数据集上全面领先以往模型. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}