[1]
STRASSMANN S. Hairy brushes [C]// Proceedings of the 13th Annual Conference on Computer Graphics and Interactive Techniques . New York: ACM, 1986: 225-232.
[本文引用: 1]
[3]
LEE J Simulating oriental black-ink painting
[J]. IEEE Computer Graphics Application , 1999 , 19 (3 ): 74 - 81
DOI:10.1109/38.761553
[本文引用: 1]
[4]
张宪荣 电子计算机毛笔字体的形成
[J]. 计算机工程 , 1985 , (3 ): 40 - 45
[本文引用: 1]
ZHANG Xian-rong Generation of Chinese brush character font by computer
[J]. Computer Engineering , 1985 , (3 ): 40 - 45
[本文引用: 1]
[5]
陈实午 一种由点阵汉字生成高质量矢量汉字的方法
[J]. 计算机研究与发展 , 1989 , (8 ): 47 - 50
[本文引用: 1]
CHEN Shi-wu A method for generating high-quality vector Chinese characters from dot matrix Chinese characters
[J]. Journal of Computer Research and Development , 1989 , (8 ): 47 - 50
[本文引用: 1]
[6]
王新 点阵字库自动生成曲线字库
[J]. 计算机应用 , 1995 , (1 ): 61 - 62
[本文引用: 1]
WANG Xin Building curvilinear character-library from dots character-library automatically
[J]. Journal of Computer Applications , 1995 , (1 ): 61 - 62
[本文引用: 1]
[7]
GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2414-2423.
[本文引用: 4]
[8]
YANN L, BOTTOU L Gradient-based learning applied to document recognition
[J]. Proceedings of the IEEE , 1998 , 86 (11 ): 2278 - 2324
DOI:10.1109/5.726791
[本文引用: 1]
[9]
GOODFELLOW I, POUGETABADIE J, MIRZA M, et al Generative adversarial networks
[J]. Advances in Neural Information Processing Systems , 2014 , (3 ): 2672 - 2680
[本文引用: 1]
[10]
JOHNSON J, ALAHI A, LI F F Perceptual losses for real-time style transfer and super-resolution
[J]. Lecture Notes in Computer Science , 2016 , 9906 : 694 - 711
[本文引用: 1]
[11]
TIAN Y. Rewrite [CP/OL]. [2021-05-26]. https://github.com/kaonashi-tyc/Rewrite.
[本文引用: 3]
[12]
JIANG Y, LIAN Z H, TANG Y M, et al. DCFont: an end-to-end deep Chinese font generation system [C]// SIGGRAPH Asia 2017 Technical Briefs . New York: ACM, 2017: 1–4.
[本文引用: 3]
[14]
HSU S C, LEE I. Drawing and animation using skeletal strokes [C]// Proceedings of the 21st Annual Conference on Computer Graphics and Interactive Techniques . New York: ACM, 1994: 109-118.
[15]
于金辉, 张积东, 丛延奇 一个基于骨架的笔刷模型
[J]. 计算机辅助设计与图形学学报 , 1996 , (4 ): 2 - 6
YU Jin-hui, ZHANG Ji-dong, CONG Yan-qi A physically based brush pen model
[J]. Journal of Computer-Aided Design and Computer Graphics , 1996 , (4 ): 2 - 6
[16]
宓晓峰, 唐敏, 林建贞, 等 基于经验的虚拟毛笔模型
[J]. 计算机研究与发展 , 2003 , (8 ): 1244 - 1251
[本文引用: 1]
MI Xiao-feng, TANG Min, LIN Jian-zhen, et al An experience based virtual brush model
[J]. Journal of Computer Research and Development , 2003 , (8 ): 1244 - 1251
[本文引用: 1]
[17]
IP H H S, WONG H T F. Calligraphic character synthesis using a brush model [C]// Proceedings Computer Graphics International . [S. l.]: IEEE, 1997: 13-21.
[本文引用: 1]
[18]
WONG H T F, IP H H S Virtual brush: a model-based synthesis of Chinese calligraphy
[J]. Computer Graphics , 2000 , 24 (1 ): 99 - 113
DOI:10.1016/S0097-8493(99)00141-7
[19]
朱墨子, 申飞, 吴仲成, 等 基于统计分析的虚拟毛笔模型及其应用
[J]. 计算机工程 , 2009 , 35 (16 ): 283 - 284
DOI:10.3969/j.issn.1000-3428.2009.16.102
ZHU Mo-zi, SHEN Fei, WU Zhong-cheng, et al Virtual brush model based on statistical analysis and its application
[J]. Computer Engineering , 2009 , 35 (16 ): 283 - 284
DOI:10.3969/j.issn.1000-3428.2009.16.102
[20]
YHANG Y C, LIU Y, ZHU Q. Modeling virtual Chinese brush using camshaft curve and stochastic process [C]// International Conference on Computer-aided Design and Computer Graphics . Piscataway: IEEE, 2015: 228-229.
[本文引用: 1]
[21]
BAXTER B, SCHEIB V, LIN M C, et al. DAB: interactive haptic painting with 3D virtual brushes [C]// Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques . New York: ACM, 2001: 461-468.
[本文引用: 1]
[22]
BAXTER W, LIN M C. A versatile interactive 3D brush model [C]// Proceedings of the 12th Pacific Conference on Computer Graphics and Applications . New York: IEEE, 2004: 319-328.
[23]
ADAMS B, WICKE M, DUTRE P, et al. Interactive 3D painting on point-sampled objects [C]// Proceedings of the 1st Eurographics Conference on Point-Based Graphics . Goslar: Eurographics Association, 2004: 57-66.
[24]
CHU N S H, TAI C L. An efficient brush model for physically-based 3D painting [C]// Proceedings of the 10th Pacific Conference on Computer Graphics and Applications . Beijing: IEEE, 2002: 413-421.
[本文引用: 1]
[25]
XU S H, TANG M, LAU F, et al A solid model based virtual hairy brush
[J]. Computer Graphics Forum , 2002 , 21 (3 ): 299 - 308
DOI:10.1111/1467-8659.00589
[本文引用: 1]
[27]
BAXTER W, GOVINDARAJU N. Simple data-driven modeling of brushes [C]// Proceedings of the 2010 ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games . New York: ACM, 2010: 135-142.
[本文引用: 1]
[28]
GUO C, HOU Z X, SHI Y Z, et al A virtual 3D interactive painting method for Chinese calligraphy and painting based on real-time force feedback technology
[J]. Frontiers of Information Technology and Electronic Engineering , 2017 , 18 (11 ): 1843 - 1853
DOI:10.1631/FITEE.1601283
[本文引用: 1]
[29]
高晓, 蔡士杰 一种从黑体到隶书的汉字字形自动变体方法
[J]. 软件学报 , 1995 , (9 ): 542 - 550
[本文引用: 1]
GAO Xiao, CAI Shi-jie An automatic derivation of Chinese characters typeface from Hei-Ti to Li-Shu
[J]. Journal of Software , 1995 , (9 ): 542 - 550
[本文引用: 1]
[30]
庞健雄, 冯著明 曲线轮廓汉字自动生成技术研究
[J]. 桂林电子工业学院学报 , 1996 , (4 ): 50 - 55
[本文引用: 1]
PANG Jian-xiong, FENG Zhu-ming Research of automatic generation for curve outline Chinese font
[J]. Journal of Guilin University of Electronic Technology , 1996 , (4 ): 50 - 55
[本文引用: 1]
[31]
潘志庚, 马小虎, 石教英 动态汉字库自动生成算法
[J]. 自动化学报 , 1996 , (5 ): 561 - 567
[本文引用: 1]
PAN Zhi-geng, MA Xiao-hu, SHI Jiao-ying The automatic generation algorithm for dynamic Chinese font
[J]. Acta Automatica Sinica , 1996 , (5 ): 561 - 567
[本文引用: 1]
[32]
潘志庚, 马小虎, 张明敏, 等 基于Fourier级数描述器的多种汉字字形自动生成
[J]. 软件学报 , 1996 , (6 ): 331 - 338
[本文引用: 1]
PAN Zhi-geng, MA Xiao-hu, ZHANG Ming-min, et al The fourier descriptor based automatic generation method for multiple Chinese fonts
[J]. Journal of Software , 1996 , (6 ): 331 - 338
[本文引用: 1]
[34]
杨建, 张明敏, 张纪文, 等 基于C-Bézier曲线的汉字轮廓字库描述及生成
[J]. 计算机辅助设计与图形学学报 , 2000 , (9 ): 660 - 663
DOI:10.3321/j.issn:1003-9775.2000.09.004
[本文引用: 1]
YANG Jian, ZHANG Ming-min, ZHANG Ji-wen, et al Description and generation of Chinese outline based on C-Bézier curves
[J]. Journal of Computer-Aided Design and Computer Graphics , 2000 , (9 ): 660 - 663
DOI:10.3321/j.issn:1003-9775.2000.09.004
[本文引用: 1]
[35]
ZONG A, ZHU Y. StrokeBank: automating personalized Chinese handwriting generation [C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence . Québec: AAAI, 2014, 4: 3024-3029.
[本文引用: 2]
[36]
栗青生, 徐强, 肖建国, 等 汉字动态生成的结构与风格模型
[J]. 北京大学学报:自然科学版 , 2017 , 53 (2 ): 219 - 229
[本文引用: 1]
LI Qing-sheng, XU Qiang, XIAO Jian-guo, et al A structure and style model for Chinese character dynamic generation
[J]. Acta Scientiarum Naturalium Universitatis Pekinensis , 2017 , 53 (2 ): 219 - 229
[本文引用: 1]
[37]
LI Q S, YANG Y X A human-computer interactive dynamic description method for Jiaguwen characters
[J]. Procedia Engineering , 2012 , 29 : 1013 - 1017
DOI:10.1016/j.proeng.2012.01.081
[38]
栗青生, 熊晶, 吴琴霞, 等 基于特征加权的汉字点笔画生成研究
[J]. 北京大学学报:自然科学版 , 2014 , 50 (1 ): 153 - 160
LI Qing-sheng, XIONG Jing, WU Qin-xia, et al Study of feature weighted-based generation method for dian strokes of Chinese character
[J]. Acta Scientiarum Naturalium Universitatis Pekinensis , 2014 , 50 (1 ): 153 - 160
[39]
LI Q S, LI X. Dynamic generation and editing system for wrongly written Chinese characters font [J]. Mathematical Problems in Engineering , 2015: 282408.
[本文引用: 2]
[40]
LIAN Z, XIAO J. Automatic shape morphing for chinese characters [C]// SIGGRAPH Asia 2012 Technical Briefs . New York: ACM, 2012: 1-4.
[本文引用: 1]
[41]
LIN J W, WANG C Y, TING C L, et al. Font generation of personal handwritten Chinese characters [C]// 5th International Conference on Graphic and Image Processing . Hong Kong: SPIE, 2013(9069): 1T.
[42]
CAMPBELL N D F, KAUTZ J Learning a manifold of fonts
[J]. ACM Transactions on Graphics , 2014 , 33 (4 ): 1 - 11
[43]
PHAN H, FU H, CHAN A FlexyFont: learning transferring rules for flexible typeface synthesis
[J]. Computer Graphics Forum , 2015 , 34 (7 ): 245 - 256
DOI:10.1111/cgf.12763
[本文引用: 1]
[44]
LIAN Z H, ZHAO B, XIAO J G. Automatic generation of large-scale handwriting fonts via style learning [C]//SIGGRAPH ASIA 2016 Technical Briefs . New York: ACM, 2016, 12: 1-4.
[本文引用: 2]
[45]
BERNHARDSSON E. Analyzing 50k fonts using deep neural networks [EB/OL]. [2021-05-26]. https://erikbern.com/2016/01/21analyzing-50k-fonts-using-deep-neural-networks.
[本文引用: 2]
[46]
BALUJA S Learning typographic style: from discrimination to synthesis
[J]. Machine Vision and Applications , 2017 , 28 (5/6 ): 551 - 568
[本文引用: 2]
[47]
GUO Y, LIAN Z H, TANG Y M, et al. Creating new Chinese fonts based on manifold learning and adversarial networks [C]// Eurographics 2018 . Delft: Eurographics Association, 2018: 61–64.
[本文引用: 2]
[48]
JIANG Y, LIAN Z H, TANG Y M Y, et al. SCFont: structure-guided Chinese font generation via deep stacked networks [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Québec: AAAI, 2019, 33: 4015-4022.
[本文引用: 1]
[49]
ZHANG X, YIN F, ZHANG Y, et al Drawing and recognizing Chinese characters with recurrent neural network
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2018 , 40 (4 ): 849 - 862
DOI:10.1109/TPAMI.2017.2695539
[本文引用: 1]
[50]
CHANG B, ZHANG Q, PAN S, et al. Generating handwritten Chinese characters using CycleGAN [C]// 2018 IEEE Winter Conference on Applications of Computer Vision . Lake Tahoe: IEEE, 2018: 199-207.
[本文引用: 4]
[51]
CHANG J, GU Y, ZHANG Y, et al. Chinese handwriting imitation with hierarchical generative adversarial network [C]// 29th British Machine Vision Conference . Newcastle: British Machine Vision Association, 2018: 290.
[本文引用: 2]
[52]
TIAN Y. Zi2zi [CP/OL]. [2021-05-26]. https://github.com/kaonashi-tyc/zi2zi.
[本文引用: 2]
[53]
XIAO F, ZHANG J, HUANG B, et al. Multiform fonts-to-fonts translation via style and content disentangled representations of Chinese character [EB/OL]. [2021-07-06]. https://arxiv.org/abs/2004.03338.
[本文引用: 1]
[54]
ZHANG Y X, ZHANG Y, CAI W B. Separating style and content for generalized style transfer [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2018: 8447-8455.
[本文引用: 1]
[55]
ZHU A, LU X, BAI X, et al Few-shot text style transfer via deep feature similarity
[J]. IEEE Transactions on Image Processing , 2020 , 29 : 6932 - 6946
DOI:10.1109/TIP.2020.2995062
[本文引用: 1]
[56]
JIANG H C, YANG G Y, HUANG K Z, et al. W-Net: one-shot arbitrary-style Chinese character generation with deep neural networks [C]// International Conference on Neural Information Processing . Berlin: Springer, 2018: 483-493.
[本文引用: 2]
[57]
WU S J, YANG C Y, HSU J. CalliGAN: style and structure-aware Chinese calligraphy character generator [EB/OL]. (2020-05-26)[2021-07-06]. https://arxiv.org/abs/2005.12500.
[本文引用: 3]
[58]
WANG Y Z, GAO Y, LIAN Z H Attribute2Font: creating fonts you want from attributes
[J]. ACM Transactions on Graphics , 2020 , 39 : 1 - 15
[本文引用: 3]
[59]
HUANG G, LIU Z, MAATEN V D L, et al. Densely connected convolutional networks [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2017: 2261-2269.
[本文引用: 1]
[60]
ZHU J Y, TAESUNG P, PHILLIP I, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// 2017 IEEE International Conference on Computer Vision . Los Alamitos: IEEE, 2017: 2242-2251.
[本文引用: 1]
[62]
ANDERSON D O An introduction to bilinear time series models
[J]. Journal of the Royal Statistical Society , 1979 , 28 (3 ): 305 - 306
[本文引用: 1]
[63]
ISOLA P, ZHU J, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2017: 5967-5976.
[本文引用: 1]
[64]
JOHNSON M, SCHUSTER M, LE Q V, et al Google's multilingual neural machine translation system: enabling zero-shot translation
[J]. Transactions of the Association for Computational Linguistics , 2017 , 5 (2 ): 339 - 351
[本文引用: 1]
[65]
ODENA A, OLAH C, SHLENS J. Conditional image synthesis with auxiliary classifier GANs [C]// Proceedings of the 34th International Conference on Machine Learning . Sydney: PMLR, 2017, 70: 2642-2651.
[本文引用: 1]
[66]
YANIV T, ADAM P, LIOR W. Unsupervised cross-domain image generation [EB/OL]. [2021-07-06]. https://arxiv.org/abs/1611.02200.
[本文引用: 1]
[67]
ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein generative adversarial networks [C]// Proceedings of the 34th International Conference on Machine Learning . Sydney: PMLR, 2017, 70: 214-223.
[本文引用: 1]
[69]
LIU C L, YIN F, WANG D H, et al. CASIA online and offline Chinese handwriting database [DB/OL]. [2021-05-26]. http://www.nlpr.ia.ac.cn/databases/handwriting/home.html.
[本文引用: 1]
[70]
PAN W Q, LIAN Z H, SUN R J, et al. FlexiFont: a flexible system to generate personal font libraries [C]// Proceedings of the 2014 ACM Symposium on Document Engineering . New York: ACM, 2014: 17-20.
[本文引用: 1]
[71]
赵忠. 中国书法文字图像库[DB/OL]. [2021-05-26]. http://163.20.160.14/˜word/modules/myalbum/
[本文引用: 1]
[72]
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity
[J]. IEEE Transactions on Image Processing , 2004 , 13 (4 ): 600 - 612
[本文引用: 1]
[73]
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2818–2826.
[本文引用: 1]
[74]
LIAN Z H, ZHAO B, CHEN X D, et al EasyFont: a style learning-based system to easily build your large-scale handwriting fonts
[J]. ACM Transactions on Graphics , 2018 , 38 (1 ): 1 - 18
[本文引用: 1]
1
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
Physically-based modeling of brush painting
1
1997
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
Simulating oriental black-ink painting
1
1999
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
电子计算机毛笔字体的形成
1
1985
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
电子计算机毛笔字体的形成
1
1985
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
一种由点阵汉字生成高质量矢量汉字的方法
1
1989
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
一种由点阵汉字生成高质量矢量汉字的方法
1
1989
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
点阵字库自动生成曲线字库
1
1995
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
点阵字库自动生成曲线字库
1
1995
... 字体风格转换的先期研究工作在20世纪80年代计算机逐渐普及和计算机字体缺乏的背景下展开,其研究目的是减少字体制作的时间,加快字体更新换代的进度,生产出更多风格各异的字体.传统的研究方法主要有虚拟笔刷模型和基于字形描述的汉字自动生成方法.虚拟笔刷模型由Strassmann[1 ] 于1986年提出,随后不断有学者提出各式模型. 为了体现笔刷“柔软”的性质,Lee[2 -3 ] 在弹性理论的基础上提出三维动态笔刷模型. 有研究者认为虚拟笔刷只是设计工具,不能帮助设计师在字体设计上减少工作量,因此出现许多基于字形描述的汉字自动生成方法,如张宪荣[4 ] 提出用特征参数表示法生成计算机毛笔字,陈实午等[5 -6 ] 提出点阵字自动转化为曲线字的方法. ...
4
... 深度学习的流行使得计算机视觉领域中图像翻译的研究发展得到质的飞跃. 一方面,受Gatys等[7 ] 提出的利用卷积神经网络[8 ] (convolutional neural networks, CNN)进行图像风格迁移的启发,出现大量基于神经风格迁移的研究方法;另一方面,Goodfellow等[9 ] 提出的生成对抗网络(generative adversarial networks,GAN)在图像生成领域获得令人惊艳的生成效果,引发新一轮的研究热潮. Johnson等[10 ] 提出的神经风格迁移网络模型中在图像风格迁移领域应用对抗训练的思想,在实验结果精度相当的情况下,其训练速度比Gatys等[7 ] 的方法的高出3个数量级. 受此启发,研究者提出许多基于深度神经网络的中文字体风格转换方法,如Tian[11 ] 的Rewrite、Jiang等[12 ] 提出的DCFont. ...
... [7 ]的方法的高出3个数量级. 受此启发,研究者提出许多基于深度神经网络的中文字体风格转换方法,如Tian[11 ] 的Rewrite、Jiang等[12 ] 提出的DCFont. ...
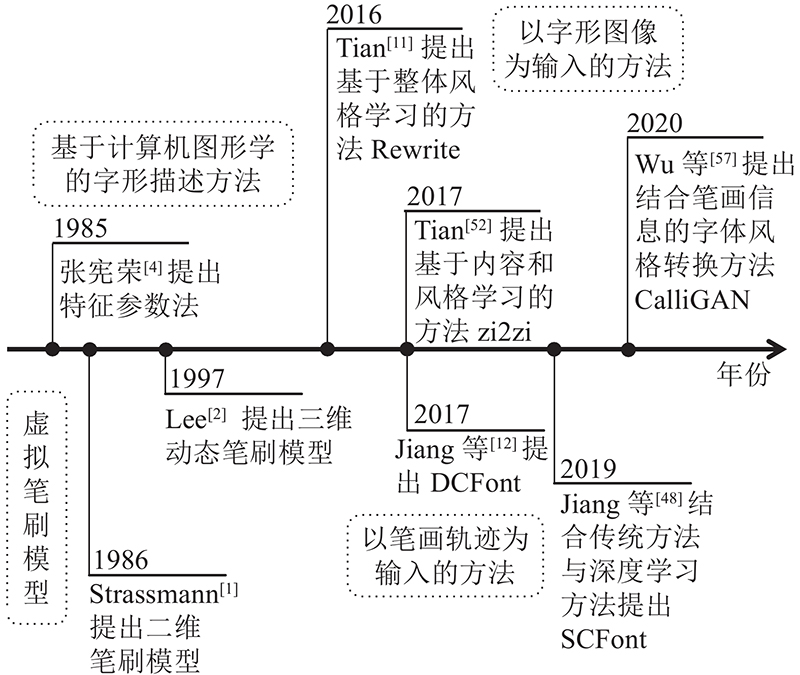
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... [7 ]舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
Gradient-based learning applied to document recognition
1
1998
... 深度学习的流行使得计算机视觉领域中图像翻译的研究发展得到质的飞跃. 一方面,受Gatys等[7 ] 提出的利用卷积神经网络[8 ] (convolutional neural networks, CNN)进行图像风格迁移的启发,出现大量基于神经风格迁移的研究方法;另一方面,Goodfellow等[9 ] 提出的生成对抗网络(generative adversarial networks,GAN)在图像生成领域获得令人惊艳的生成效果,引发新一轮的研究热潮. Johnson等[10 ] 提出的神经风格迁移网络模型中在图像风格迁移领域应用对抗训练的思想,在实验结果精度相当的情况下,其训练速度比Gatys等[7 ] 的方法的高出3个数量级. 受此启发,研究者提出许多基于深度神经网络的中文字体风格转换方法,如Tian[11 ] 的Rewrite、Jiang等[12 ] 提出的DCFont. ...
Generative adversarial networks
1
2014
... 深度学习的流行使得计算机视觉领域中图像翻译的研究发展得到质的飞跃. 一方面,受Gatys等[7 ] 提出的利用卷积神经网络[8 ] (convolutional neural networks, CNN)进行图像风格迁移的启发,出现大量基于神经风格迁移的研究方法;另一方面,Goodfellow等[9 ] 提出的生成对抗网络(generative adversarial networks,GAN)在图像生成领域获得令人惊艳的生成效果,引发新一轮的研究热潮. Johnson等[10 ] 提出的神经风格迁移网络模型中在图像风格迁移领域应用对抗训练的思想,在实验结果精度相当的情况下,其训练速度比Gatys等[7 ] 的方法的高出3个数量级. 受此启发,研究者提出许多基于深度神经网络的中文字体风格转换方法,如Tian[11 ] 的Rewrite、Jiang等[12 ] 提出的DCFont. ...
Perceptual losses for real-time style transfer and super-resolution
1
2016
... 深度学习的流行使得计算机视觉领域中图像翻译的研究发展得到质的飞跃. 一方面,受Gatys等[7 ] 提出的利用卷积神经网络[8 ] (convolutional neural networks, CNN)进行图像风格迁移的启发,出现大量基于神经风格迁移的研究方法;另一方面,Goodfellow等[9 ] 提出的生成对抗网络(generative adversarial networks,GAN)在图像生成领域获得令人惊艳的生成效果,引发新一轮的研究热潮. Johnson等[10 ] 提出的神经风格迁移网络模型中在图像风格迁移领域应用对抗训练的思想,在实验结果精度相当的情况下,其训练速度比Gatys等[7 ] 的方法的高出3个数量级. 受此启发,研究者提出许多基于深度神经网络的中文字体风格转换方法,如Tian[11 ] 的Rewrite、Jiang等[12 ] 提出的DCFont. ...
3
... 深度学习的流行使得计算机视觉领域中图像翻译的研究发展得到质的飞跃. 一方面,受Gatys等[7 ] 提出的利用卷积神经网络[8 ] (convolutional neural networks, CNN)进行图像风格迁移的启发,出现大量基于神经风格迁移的研究方法;另一方面,Goodfellow等[9 ] 提出的生成对抗网络(generative adversarial networks,GAN)在图像生成领域获得令人惊艳的生成效果,引发新一轮的研究热潮. Johnson等[10 ] 提出的神经风格迁移网络模型中在图像风格迁移领域应用对抗训练的思想,在实验结果精度相当的情况下,其训练速度比Gatys等[7 ] 的方法的高出3个数量级. 受此启发,研究者提出许多基于深度神经网络的中文字体风格转换方法,如Tian[11 ] 的Rewrite、Jiang等[12 ] 提出的DCFont. ...
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 基于整体风格学习的方法通常使用深度神经网络直接提取输入图像的特征信息,学习字体整体的风格生成字体. 该类方法原理简单直接,因此在以字形图像为输入的方法中最先被研究者提出. 受Bernhardsson等[45 -46 ] 的启发,Tian[11 ] 提出应用于中文字体风格转换的Rewrite,其网络结构如表1 所示. 仅使用传统的自顶向下的 CNN结构,网络层数量n 的大小影响生成结果,大的n 值可以得到更好的生成结果,缺点是训练时间更长. 汉字的结构比英文字母的结构复杂得多,因此Rewrite没有使用全连接层,而是采用自上而下的 CNN 结构,并在不同的层次中采取不同大小的卷积,以便捕捉不同尺度的细节特征,在生成字符与真实字符间使用平均绝对误差进行最小化,以此产生更清晰的字符图像. Rewrite的实现证明可以利用图像翻译的方法进行中文的字体风格转换,但是想获得更好的效果须改进网络. ...
3
... 深度学习的流行使得计算机视觉领域中图像翻译的研究发展得到质的飞跃. 一方面,受Gatys等[7 ] 提出的利用卷积神经网络[8 ] (convolutional neural networks, CNN)进行图像风格迁移的启发,出现大量基于神经风格迁移的研究方法;另一方面,Goodfellow等[9 ] 提出的生成对抗网络(generative adversarial networks,GAN)在图像生成领域获得令人惊艳的生成效果,引发新一轮的研究热潮. Johnson等[10 ] 提出的神经风格迁移网络模型中在图像风格迁移领域应用对抗训练的思想,在实验结果精度相当的情况下,其训练速度比Gatys等[7 ] 的方法的高出3个数量级. 受此启发,研究者提出许多基于深度神经网络的中文字体风格转换方法,如Tian[11 ] 的Rewrite、Jiang等[12 ] 提出的DCFont. ...
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 以笔画轨迹为输入的方法受到传统图形学方法的影响,最初Lian等[44 ] 提出能够学习笔画形状和布局变化的系统,它可以根据用户的个人风格自动生成大规模的手写字体库,但是需要对所有笔画进行精确的定位与匹配. Jiang等[12 ] 通过对不同字体进行降维可视化,发现相同字体在深度特征空间中倾向于聚集在一起,因此提出假设:不同字符在风格转换的过程中存在类似的映射关系,并设计字体特征重构网络来学习这种关系,以此避免对笔画轨迹进行精确的定位与匹配. 该方法实现了端到端地生成目标风格字体,使其在工作时无须人工干预,但是当有字符不满足假设条件时将生成失败的结果. Guo等[47 ] 利用字体流型获得新字体:1)将字形分解为骨架与轮廓,利用CNN对已有的多种字体进行特征学习;2)通过非线性映射建立字体流形;3)通过字体流形在已有字体间进行插入和移动操作,获得新的字体特征;4)将这些特征输入生成网络中,利用对抗训练生成新的字体. 该方法能够有效地生成不同样式的高质量中文字体,缺点是新字体通过插值获得,因此不能生成某种特定风格的字体. ...
Bézier brushstrokes
1
1990
... 二维笔刷模型是在笔刷触点周围以某种形状区域绘制像素模拟墨水在纸上的痕迹,在用户自定义的笔画路径上进行重复贴图,实现简单且计算速度快,可以分为基于经验的模型和基于物理的模型. 基于经验的模型根据笔刷的使用经验对笔刷进行建模,以点或者某种二维形状表示笔刷与纸的接触面积[13 -16 ] . 基于物理的模型根据笔刷刷毛的真实物理性质进行建模[17 -20 ] . ...
基于经验的虚拟毛笔模型
1
2003
... 二维笔刷模型是在笔刷触点周围以某种形状区域绘制像素模拟墨水在纸上的痕迹,在用户自定义的笔画路径上进行重复贴图,实现简单且计算速度快,可以分为基于经验的模型和基于物理的模型. 基于经验的模型根据笔刷的使用经验对笔刷进行建模,以点或者某种二维形状表示笔刷与纸的接触面积[13 -16 ] . 基于物理的模型根据笔刷刷毛的真实物理性质进行建模[17 -20 ] . ...
基于经验的虚拟毛笔模型
1
2003
... 二维笔刷模型是在笔刷触点周围以某种形状区域绘制像素模拟墨水在纸上的痕迹,在用户自定义的笔画路径上进行重复贴图,实现简单且计算速度快,可以分为基于经验的模型和基于物理的模型. 基于经验的模型根据笔刷的使用经验对笔刷进行建模,以点或者某种二维形状表示笔刷与纸的接触面积[13 -16 ] . 基于物理的模型根据笔刷刷毛的真实物理性质进行建模[17 -20 ] . ...
1
... 二维笔刷模型是在笔刷触点周围以某种形状区域绘制像素模拟墨水在纸上的痕迹,在用户自定义的笔画路径上进行重复贴图,实现简单且计算速度快,可以分为基于经验的模型和基于物理的模型. 基于经验的模型根据笔刷的使用经验对笔刷进行建模,以点或者某种二维形状表示笔刷与纸的接触面积[13 -16 ] . 基于物理的模型根据笔刷刷毛的真实物理性质进行建模[17 -20 ] . ...
Virtual brush: a model-based synthesis of Chinese calligraphy
0
2000
1
... 二维笔刷模型是在笔刷触点周围以某种形状区域绘制像素模拟墨水在纸上的痕迹,在用户自定义的笔画路径上进行重复贴图,实现简单且计算速度快,可以分为基于经验的模型和基于物理的模型. 基于经验的模型根据笔刷的使用经验对笔刷进行建模,以点或者某种二维形状表示笔刷与纸的接触面积[13 -16 ] . 基于物理的模型根据笔刷刷毛的真实物理性质进行建模[17 -20 ] . ...
1
... 三维笔刷模型是在二维笔刷模型的基础上加入“柔软”的特性改进而来的,与二维模型相比,获得了更好的视觉反馈. 根据建模原理三维笔刷模型可以分为基于骨架和表面的模型[21 -24 ] 、基于实体造型的模型[25 -26 ] 以及基于数据驱动的模型[27 -28 ] . 基于骨架和表面的模型将笔刷建模为被表面网格包裹的骨架模型;基于实体造型的模型根据真实笔刷进行建模;基于数据驱动的模型收集刷毛形变的数据,利用数据统计方法对刷毛进行动态模拟. ...
1
... 三维笔刷模型是在二维笔刷模型的基础上加入“柔软”的特性改进而来的,与二维模型相比,获得了更好的视觉反馈. 根据建模原理三维笔刷模型可以分为基于骨架和表面的模型[21 -24 ] 、基于实体造型的模型[25 -26 ] 以及基于数据驱动的模型[27 -28 ] . 基于骨架和表面的模型将笔刷建模为被表面网格包裹的骨架模型;基于实体造型的模型根据真实笔刷进行建模;基于数据驱动的模型收集刷毛形变的数据,利用数据统计方法对刷毛进行动态模拟. ...
A solid model based virtual hairy brush
1
2002
... 三维笔刷模型是在二维笔刷模型的基础上加入“柔软”的特性改进而来的,与二维模型相比,获得了更好的视觉反馈. 根据建模原理三维笔刷模型可以分为基于骨架和表面的模型[21 -24 ] 、基于实体造型的模型[25 -26 ] 以及基于数据驱动的模型[27 -28 ] . 基于骨架和表面的模型将笔刷建模为被表面网格包裹的骨架模型;基于实体造型的模型根据真实笔刷进行建模;基于数据驱动的模型收集刷毛形变的数据,利用数据统计方法对刷毛进行动态模拟. ...
Advanced design for a realistic virtual brush
1
2003
... 三维笔刷模型是在二维笔刷模型的基础上加入“柔软”的特性改进而来的,与二维模型相比,获得了更好的视觉反馈. 根据建模原理三维笔刷模型可以分为基于骨架和表面的模型[21 -24 ] 、基于实体造型的模型[25 -26 ] 以及基于数据驱动的模型[27 -28 ] . 基于骨架和表面的模型将笔刷建模为被表面网格包裹的骨架模型;基于实体造型的模型根据真实笔刷进行建模;基于数据驱动的模型收集刷毛形变的数据,利用数据统计方法对刷毛进行动态模拟. ...
1
... 三维笔刷模型是在二维笔刷模型的基础上加入“柔软”的特性改进而来的,与二维模型相比,获得了更好的视觉反馈. 根据建模原理三维笔刷模型可以分为基于骨架和表面的模型[21 -24 ] 、基于实体造型的模型[25 -26 ] 以及基于数据驱动的模型[27 -28 ] . 基于骨架和表面的模型将笔刷建模为被表面网格包裹的骨架模型;基于实体造型的模型根据真实笔刷进行建模;基于数据驱动的模型收集刷毛形变的数据,利用数据统计方法对刷毛进行动态模拟. ...
A virtual 3D interactive painting method for Chinese calligraphy and painting based on real-time force feedback technology
1
2017
... 三维笔刷模型是在二维笔刷模型的基础上加入“柔软”的特性改进而来的,与二维模型相比,获得了更好的视觉反馈. 根据建模原理三维笔刷模型可以分为基于骨架和表面的模型[21 -24 ] 、基于实体造型的模型[25 -26 ] 以及基于数据驱动的模型[27 -28 ] . 基于骨架和表面的模型将笔刷建模为被表面网格包裹的骨架模型;基于实体造型的模型根据真实笔刷进行建模;基于数据驱动的模型收集刷毛形变的数据,利用数据统计方法对刷毛进行动态模拟. ...
一种从黑体到隶书的汉字字形自动变体方法
1
1995
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
一种从黑体到隶书的汉字字形自动变体方法
1
1995
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
曲线轮廓汉字自动生成技术研究
1
1996
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
曲线轮廓汉字自动生成技术研究
1
1996
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
动态汉字库自动生成算法
1
1996
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
动态汉字库自动生成算法
1
1996
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
基于Fourier级数描述器的多种汉字字形自动生成
1
1996
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
基于Fourier级数描述器的多种汉字字形自动生成
1
1996
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
基于B-样条小波变换汉字字形生成方法的研究
1
1998
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
基于B-样条小波变换汉字字形生成方法的研究
1
1998
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
基于C-Bézier曲线的汉字轮廓字库描述及生成
1
2000
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
基于C-Bézier曲线的汉字轮廓字库描述及生成
1
2000
... 字形描述方法在计算机图形学的基础上,将汉字的拓扑结构与笔画进行描述,抽象为多层级的数据结构,分析汉字的几何特征,利用这些启发式信息引导汉字的自动生成. 这些研究工作用到的方法可以总结为3种:部件拼接法、骨架法和轮廓法. 大部分的研究工作会综合2~3种方法描述字符. 部件拼接法将汉字化整为零,分为多个部件,利用汉字部件重复使用的特点,对所有部件进行描述,在设计字形时将各部件进行拼接得到完整字形[29 -30 ] . 骨架法提取汉字字符的骨架,进行风格上的调整与填充,得到新字体[31 -32 ] . 轮廓法通过扫描目标字体的字稿得到数字化的字符轮廓,以各式曲线拟合得到曲线轮廓字[33 -34 ] . ...
2
... 受限于技术,基于字形描述的方法没有明显的发展,自动生成手写字体的研究也很少见. 2014年,Zong等[35 ] 针对手写字体提出StrokeBank,可以在半监督的情况下建立组件映射字典. 栗青生等[36 -39 ] 通过2012年到2017年间的研究,提出对笔画进一步分解,以便更精细地控制生成汉字的结构与风格. ...
... 基于计算机图形学的字形描述比人工设计的方法更加高效快捷,但是存在字体风格多样化与字形描述结构化间的矛盾,难以生成更灵活丰富的个性化字体.该问题虽然在Zong等[35 -39 ] 的研究中稍有改进,却未达到令人满意的程度. 因此越来越多的研究者将目光转向深度学习,希望利用深度神经网络解决此问题. ...
汉字动态生成的结构与风格模型
1
2017
... 受限于技术,基于字形描述的方法没有明显的发展,自动生成手写字体的研究也很少见. 2014年,Zong等[35 ] 针对手写字体提出StrokeBank,可以在半监督的情况下建立组件映射字典. 栗青生等[36 -39 ] 通过2012年到2017年间的研究,提出对笔画进一步分解,以便更精细地控制生成汉字的结构与风格. ...
汉字动态生成的结构与风格模型
1
2017
... 受限于技术,基于字形描述的方法没有明显的发展,自动生成手写字体的研究也很少见. 2014年,Zong等[35 ] 针对手写字体提出StrokeBank,可以在半监督的情况下建立组件映射字典. 栗青生等[36 -39 ] 通过2012年到2017年间的研究,提出对笔画进一步分解,以便更精细地控制生成汉字的结构与风格. ...
A human-computer interactive dynamic description method for Jiaguwen characters
0
2012
2
... 受限于技术,基于字形描述的方法没有明显的发展,自动生成手写字体的研究也很少见. 2014年,Zong等[35 ] 针对手写字体提出StrokeBank,可以在半监督的情况下建立组件映射字典. 栗青生等[36 -39 ] 通过2012年到2017年间的研究,提出对笔画进一步分解,以便更精细地控制生成汉字的结构与风格. ...
... 基于计算机图形学的字形描述比人工设计的方法更加高效快捷,但是存在字体风格多样化与字形描述结构化间的矛盾,难以生成更灵活丰富的个性化字体.该问题虽然在Zong等[35 -39 ] 的研究中稍有改进,却未达到令人满意的程度. 因此越来越多的研究者将目光转向深度学习,希望利用深度神经网络解决此问题. ...
1
... 在深度学习流行初期,为了进一步减少传统方法中的手动操作,研究者提出自动生成字体的方法[40 -43 ] ,这些方法需要为所有输入字符手动创建精确且复杂的形状模型,因此不适用于处理包含大量复杂形状字符的大型字库. 为此Lian等[44 ] 提出基于人工神经网络的个人手写字体系统,实现大规模手写字体的风格学习. 随着深度学习的应用越来越广泛,各式各样的深度神经网络被用于计算机视觉领域的各个研究方向,字体风格转换研究在深度学习中可解释为图像翻译(image translation)的子任务. ...
Learning a manifold of fonts
0
2014
FlexyFont: learning transferring rules for flexible typeface synthesis
1
2015
... 在深度学习流行初期,为了进一步减少传统方法中的手动操作,研究者提出自动生成字体的方法[40 -43 ] ,这些方法需要为所有输入字符手动创建精确且复杂的形状模型,因此不适用于处理包含大量复杂形状字符的大型字库. 为此Lian等[44 ] 提出基于人工神经网络的个人手写字体系统,实现大规模手写字体的风格学习. 随着深度学习的应用越来越广泛,各式各样的深度神经网络被用于计算机视觉领域的各个研究方向,字体风格转换研究在深度学习中可解释为图像翻译(image translation)的子任务. ...
2
... 在深度学习流行初期,为了进一步减少传统方法中的手动操作,研究者提出自动生成字体的方法[40 -43 ] ,这些方法需要为所有输入字符手动创建精确且复杂的形状模型,因此不适用于处理包含大量复杂形状字符的大型字库. 为此Lian等[44 ] 提出基于人工神经网络的个人手写字体系统,实现大规模手写字体的风格学习. 随着深度学习的应用越来越广泛,各式各样的深度神经网络被用于计算机视觉领域的各个研究方向,字体风格转换研究在深度学习中可解释为图像翻译(image translation)的子任务. ...
... 以笔画轨迹为输入的方法受到传统图形学方法的影响,最初Lian等[44 ] 提出能够学习笔画形状和布局变化的系统,它可以根据用户的个人风格自动生成大规模的手写字体库,但是需要对所有笔画进行精确的定位与匹配. Jiang等[12 ] 通过对不同字体进行降维可视化,发现相同字体在深度特征空间中倾向于聚集在一起,因此提出假设:不同字符在风格转换的过程中存在类似的映射关系,并设计字体特征重构网络来学习这种关系,以此避免对笔画轨迹进行精确的定位与匹配. 该方法实现了端到端地生成目标风格字体,使其在工作时无须人工干预,但是当有字符不满足假设条件时将生成失败的结果. Guo等[47 ] 利用字体流型获得新字体:1)将字形分解为骨架与轮廓,利用CNN对已有的多种字体进行特征学习;2)通过非线性映射建立字体流形;3)通过字体流形在已有字体间进行插入和移动操作,获得新的字体特征;4)将这些特征输入生成网络中,利用对抗训练生成新的字体. 该方法能够有效地生成不同样式的高质量中文字体,缺点是新字体通过插值获得,因此不能生成某种特定风格的字体. ...
2
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 基于整体风格学习的方法通常使用深度神经网络直接提取输入图像的特征信息,学习字体整体的风格生成字体. 该类方法原理简单直接,因此在以字形图像为输入的方法中最先被研究者提出. 受Bernhardsson等[45 -46 ] 的启发,Tian[11 ] 提出应用于中文字体风格转换的Rewrite,其网络结构如表1 所示. 仅使用传统的自顶向下的 CNN结构,网络层数量n 的大小影响生成结果,大的n 值可以得到更好的生成结果,缺点是训练时间更长. 汉字的结构比英文字母的结构复杂得多,因此Rewrite没有使用全连接层,而是采用自上而下的 CNN 结构,并在不同的层次中采取不同大小的卷积,以便捕捉不同尺度的细节特征,在生成字符与真实字符间使用平均绝对误差进行最小化,以此产生更清晰的字符图像. Rewrite的实现证明可以利用图像翻译的方法进行中文的字体风格转换,但是想获得更好的效果须改进网络. ...
Learning typographic style: from discrimination to synthesis
2
2017
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 基于整体风格学习的方法通常使用深度神经网络直接提取输入图像的特征信息,学习字体整体的风格生成字体. 该类方法原理简单直接,因此在以字形图像为输入的方法中最先被研究者提出. 受Bernhardsson等[45 -46 ] 的启发,Tian[11 ] 提出应用于中文字体风格转换的Rewrite,其网络结构如表1 所示. 仅使用传统的自顶向下的 CNN结构,网络层数量n 的大小影响生成结果,大的n 值可以得到更好的生成结果,缺点是训练时间更长. 汉字的结构比英文字母的结构复杂得多,因此Rewrite没有使用全连接层,而是采用自上而下的 CNN 结构,并在不同的层次中采取不同大小的卷积,以便捕捉不同尺度的细节特征,在生成字符与真实字符间使用平均绝对误差进行最小化,以此产生更清晰的字符图像. Rewrite的实现证明可以利用图像翻译的方法进行中文的字体风格转换,但是想获得更好的效果须改进网络. ...
2
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 以笔画轨迹为输入的方法受到传统图形学方法的影响,最初Lian等[44 ] 提出能够学习笔画形状和布局变化的系统,它可以根据用户的个人风格自动生成大规模的手写字体库,但是需要对所有笔画进行精确的定位与匹配. Jiang等[12 ] 通过对不同字体进行降维可视化,发现相同字体在深度特征空间中倾向于聚集在一起,因此提出假设:不同字符在风格转换的过程中存在类似的映射关系,并设计字体特征重构网络来学习这种关系,以此避免对笔画轨迹进行精确的定位与匹配. 该方法实现了端到端地生成目标风格字体,使其在工作时无须人工干预,但是当有字符不满足假设条件时将生成失败的结果. Guo等[47 ] 利用字体流型获得新字体:1)将字形分解为骨架与轮廓,利用CNN对已有的多种字体进行特征学习;2)通过非线性映射建立字体流形;3)通过字体流形在已有字体间进行插入和移动操作,获得新的字体特征;4)将这些特征输入生成网络中,利用对抗训练生成新的字体. 该方法能够有效地生成不同样式的高质量中文字体,缺点是新字体通过插值获得,因此不能生成某种特定风格的字体. ...
1
... Jiang等[48 ] 提出SCFont,将传统的计算机图形学方法与深度学习结合起来,取二者优势以保证在减少人工干预的情况下,合成出具有目标风格的高质量字形. 其主要步骤为:1)利用非均匀采样方法获得笔画关键点并连接起来形成骨架图像;2)结合笔画类别信息从骨架图像中提取出高级语义特征嵌入骨架合成网络,引导生成目标风格的骨架图像;3)利用生成对抗网络恢复目标风格骨架图像在字形轮廓上的细节. 相比之前的方法,SCFont获得了更好的视觉表现. ...
Drawing and recognizing Chinese characters with recurrent neural network
1
2018
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
4
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 在基于深度学习的图像翻译研究中往往需要输入图像对,制作匹配好的数据集通常需要额外的数据处理步骤.用于字体风格转换任务的数据集很少,专门制作为成对匹配的数据集更是少之又少.为了解决成对数据集缺乏的问题,Chang等[50 ] 放弃使用成对匹配的字符图像作为网络输入,结合DenseNet[59 ] 和CycleGAN[60 ] 替代CNN结构,提出HCCG网络生成个性化手写字体.HCCG利用CycleGAN的循环一致损失实现不成对的字体风格转换,用DenseNet Block组成传输网络,在减少参数量的同时获得了更好的生成效果. 由于结构复杂的汉字笔画数量多且交叉点密集,这种方法的网络无法很好地提取笔画细节信息,会导致生成难以辨认的字符图像.为了在提取整体风格特征的同时保有恢复笔画细节的能力,Chang等[51 ] 提出层次生成对抗网络HGAN进行中文字体风格转换.HGAN由内容编码器、层次生成器以及层次判别器组成,层次生成器根据不同尺度卷积层的特征信息生成多组字符图像,并分别与层次判别器对应的卷积层计算对抗损失.HGAN利用多尺度特征捕获字体的局部特征与全局特征,使得生成字体与目标字体在不同尺度的特征空间中具有类似的分布,获得更真实的生成结果. ...
... 中文字体风格转换方法大多是从网络上收集公开的字体数据,根据实验的需要制作数据集,这类数据集很少公开发布. 印刷字体数据集通常可在公开的字体下载网站获得,但是手写字体和书法字体的数据集较少. 可直接从网上获取的有CASIA-HWDB[69 ] 、FlexiFont手写字体库[70 ] 、兰亭数据集[50 ] 、中国书法文字图像库[71 ] ,数据集字体示例如图2 所示. ...
... 兰亭数据集由Chang等[50 ] 制作,通过对《兰亭集序》的手稿进行数据处理得到,包含324个草书字,图像大小为128×128. ...
2
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 在基于深度学习的图像翻译研究中往往需要输入图像对,制作匹配好的数据集通常需要额外的数据处理步骤.用于字体风格转换任务的数据集很少,专门制作为成对匹配的数据集更是少之又少.为了解决成对数据集缺乏的问题,Chang等[50 ] 放弃使用成对匹配的字符图像作为网络输入,结合DenseNet[59 ] 和CycleGAN[60 ] 替代CNN结构,提出HCCG网络生成个性化手写字体.HCCG利用CycleGAN的循环一致损失实现不成对的字体风格转换,用DenseNet Block组成传输网络,在减少参数量的同时获得了更好的生成效果. 由于结构复杂的汉字笔画数量多且交叉点密集,这种方法的网络无法很好地提取笔画细节信息,会导致生成难以辨认的字符图像.为了在提取整体风格特征的同时保有恢复笔画细节的能力,Chang等[51 ] 提出层次生成对抗网络HGAN进行中文字体风格转换.HGAN由内容编码器、层次生成器以及层次判别器组成,层次生成器根据不同尺度卷积层的特征信息生成多组字符图像,并分别与层次判别器对应的卷积层计算对抗损失.HGAN利用多尺度特征捕获字体的局部特征与全局特征,使得生成字体与目标字体在不同尺度的特征空间中具有类似的分布,获得更真实的生成结果. ...
2
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
1
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
1
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
Few-shot text style transfer via deep feature similarity
1
2020
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
2
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
3
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... Wu等[57 ] 于2020年提出CalliGAN,将汉字的笔画信息纳入模型中,利用汉字分解系统获得笔画序列,该系统定义517个组成大部分汉字的笔画构成. 给定输入字符,使用该系统获得它的笔画组成序列,并设计序列编码器将变长序列转换为固定长度的特征向量. 序列编码器包含1个嵌入层和1个长短期记忆(long short-term memory, LSTM)[68 ] 模型,嵌入层将组件代码转换为定长向量输入LSTM模型中得到输入字符的笔画结构特征向量. 对目标风格字符进行目标风格特征提取,将提取的风格特征与笔画结构特征以及类别嵌入相连接,输入生成网络中进行对抗训练,得到目标风格的生成字符. 该方法在很大程度上解决了笔画粘连、连笔模糊、风格不一致等问题,笔画结构特征的使用使得该网络即使没有更复杂的笔画提取阶段,也能生成细节较好的高质量字形图像. 与Wu等[57 ] 利用笔画信息进行结构引导不同的是,Wang等[58 ] 利用字体属性来定制用户想要的字体,提出基于属性注意力的Attribute2Font. 该方法提出新颖的思路:将可控制的属性融入风格转换的任务中. 由于属性标注需要一定的人工操作,Wang等[58 ] 通过设计半监督学习方案来降低人工成本,利用属性注意力模块合成高度多样化且具有美感的字形图像. ...
... [57 ]利用笔画信息进行结构引导不同的是,Wang等[58 ] 利用字体属性来定制用户想要的字体,提出基于属性注意力的Attribute2Font. 该方法提出新颖的思路:将可控制的属性融入风格转换的任务中. 由于属性标注需要一定的人工操作,Wang等[58 ] 通过设计半监督学习方案来降低人工成本,利用属性注意力模块合成高度多样化且具有美感的字形图像. ...
Attribute2Font: creating fonts you want from attributes
3
2020
... 图像翻译的研究在Gatys等[7 ] 取得突破之前大多不具有可移植性,所提出的方法只能适用于某一种具体的风格或者场景,且都要手动设计统计特征模型,各类方法的主要思想基本是各自发展的,实验的最终效果一般. 2015年,Gatys等[7 ] 舍弃传统手动建模方法,提出用神经网络进行图像翻译,分别提取图像的内容与风格,将图片内容与不同风格相结合得到新的图像,随后Bernhardsson[45 ] 将其应用于字体设计,并在博客上展示英文字体的自动转换. 不久,Baluja[46 ] 提出学习印刷字体风格,为后续想做相关研究的人提供了研究思路. 英文字体风格转换的成功让研究者联想到中文字体风格转换也可以利用类似的方法,有研究者提出基于深度神经网络的中文字体风格转换方法. 本研究按照输入样本类型将基于深度学习的字体风格转换方法分为以笔画轨迹为输入的方法[12 ,47 -49 ] 和以字形图像为输入的方法,其中以字形图像为输入的方法按照学习原理分为基于整体风格学习的方法[11 ,50 -51 ] 、基于内容与风格学习的方法[52 -56 ] 和基于领域知识的方法[57 -58 ] . 如图1 所示,当前深度学习方法的主要研究发展趋势是在生成模型中融合传统方法中的汉字领域知识,以获得质量更佳的生成字符图像. ...
... Wu等[57 ] 于2020年提出CalliGAN,将汉字的笔画信息纳入模型中,利用汉字分解系统获得笔画序列,该系统定义517个组成大部分汉字的笔画构成. 给定输入字符,使用该系统获得它的笔画组成序列,并设计序列编码器将变长序列转换为固定长度的特征向量. 序列编码器包含1个嵌入层和1个长短期记忆(long short-term memory, LSTM)[68 ] 模型,嵌入层将组件代码转换为定长向量输入LSTM模型中得到输入字符的笔画结构特征向量. 对目标风格字符进行目标风格特征提取,将提取的风格特征与笔画结构特征以及类别嵌入相连接,输入生成网络中进行对抗训练,得到目标风格的生成字符. 该方法在很大程度上解决了笔画粘连、连笔模糊、风格不一致等问题,笔画结构特征的使用使得该网络即使没有更复杂的笔画提取阶段,也能生成细节较好的高质量字形图像. 与Wu等[57 ] 利用笔画信息进行结构引导不同的是,Wang等[58 ] 利用字体属性来定制用户想要的字体,提出基于属性注意力的Attribute2Font. 该方法提出新颖的思路:将可控制的属性融入风格转换的任务中. 由于属性标注需要一定的人工操作,Wang等[58 ] 通过设计半监督学习方案来降低人工成本,利用属性注意力模块合成高度多样化且具有美感的字形图像. ...
... [58 ]通过设计半监督学习方案来降低人工成本,利用属性注意力模块合成高度多样化且具有美感的字形图像. ...
1
... 在基于深度学习的图像翻译研究中往往需要输入图像对,制作匹配好的数据集通常需要额外的数据处理步骤.用于字体风格转换任务的数据集很少,专门制作为成对匹配的数据集更是少之又少.为了解决成对数据集缺乏的问题,Chang等[50 ] 放弃使用成对匹配的字符图像作为网络输入,结合DenseNet[59 ] 和CycleGAN[60 ] 替代CNN结构,提出HCCG网络生成个性化手写字体.HCCG利用CycleGAN的循环一致损失实现不成对的字体风格转换,用DenseNet Block组成传输网络,在减少参数量的同时获得了更好的生成效果. 由于结构复杂的汉字笔画数量多且交叉点密集,这种方法的网络无法很好地提取笔画细节信息,会导致生成难以辨认的字符图像.为了在提取整体风格特征的同时保有恢复笔画细节的能力,Chang等[51 ] 提出层次生成对抗网络HGAN进行中文字体风格转换.HGAN由内容编码器、层次生成器以及层次判别器组成,层次生成器根据不同尺度卷积层的特征信息生成多组字符图像,并分别与层次判别器对应的卷积层计算对抗损失.HGAN利用多尺度特征捕获字体的局部特征与全局特征,使得生成字体与目标字体在不同尺度的特征空间中具有类似的分布,获得更真实的生成结果. ...
1
... 在基于深度学习的图像翻译研究中往往需要输入图像对,制作匹配好的数据集通常需要额外的数据处理步骤.用于字体风格转换任务的数据集很少,专门制作为成对匹配的数据集更是少之又少.为了解决成对数据集缺乏的问题,Chang等[50 ] 放弃使用成对匹配的字符图像作为网络输入,结合DenseNet[59 ] 和CycleGAN[60 ] 替代CNN结构,提出HCCG网络生成个性化手写字体.HCCG利用CycleGAN的循环一致损失实现不成对的字体风格转换,用DenseNet Block组成传输网络,在减少参数量的同时获得了更好的生成效果. 由于结构复杂的汉字笔画数量多且交叉点密集,这种方法的网络无法很好地提取笔画细节信息,会导致生成难以辨认的字符图像.为了在提取整体风格特征的同时保有恢复笔画细节的能力,Chang等[51 ] 提出层次生成对抗网络HGAN进行中文字体风格转换.HGAN由内容编码器、层次生成器以及层次判别器组成,层次生成器根据不同尺度卷积层的特征信息生成多组字符图像,并分别与层次判别器对应的卷积层计算对抗损失.HGAN利用多尺度特征捕获字体的局部特征与全局特征,使得生成字体与目标字体在不同尺度的特征空间中具有类似的分布,获得更真实的生成结果. ...
Separating style and content with bilinear models
1
2000
... 基于内容与风格学习的方法是将字体的内容与风格分别进行特征提取,Tenenbaum等[61 ] 用Bilinear Model[62 ] 将风格从内容中分离出来,应用到口语分类、字体生成以及人脸生成.研究者利用深度神经网络将字体风格与字符内容分离,可以获得比整体特征提取更丰富的信息. ...
An introduction to bilinear time series models
1
1979
... 基于内容与风格学习的方法是将字体的内容与风格分别进行特征提取,Tenenbaum等[61 ] 用Bilinear Model[62 ] 将风格从内容中分离出来,应用到口语分类、字体生成以及人脸生成.研究者利用深度神经网络将字体风格与字符内容分离,可以获得比整体特征提取更丰富的信息. ...
1
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
Google's multilingual neural machine translation system: enabling zero-shot translation
1
2017
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
1
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
1
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
1
... 在基于整体风格学习的方法中,由于是对目标字体的整体特征进行直接提取,没有考虑将风格从字体上分离出来,容易导致生成字符出现字形模糊、笔画缺失、笔画粘连等问题. Tian[52 ] 基于pix2pix[63 ] 改进Rewrite,提出zi2zi. 同一字符在不同字体中形态各异,为了能够学习多种字体风格,zi2zi引入文献[64 ]的类别嵌入,利用高斯噪声作为字体类别标签与字符特征相结合,通过添加AC-GAN[65 ] 的多类别损失解决生成字符的风格与目标风格不统一的问题. 为了使源字符与生成字符是同一个字符内容,zi2zi加入DTN[66 ] 中的恒定损失以确保二者在特征空间中接近. 但该方法仅适用于目标字体风格与源字体风格相差不大的情况,当二者风格差异过大时容易产生“墨团”. 为了解决这个问题,研究者尝试使用多个网络结构分别对字体内容与字体风格进行提取. Xiao等[53 ] 使用2个带CNN的编码器分别学习字符内容特征和字体风格特征,将学习得到的特征输入解码器生成目标风格字体. Zhang等[54 ] 提出可泛化的风格转换网络,利用图像内容和风格各自的条件依赖性学习独立的内容特征和风格特征. 该网络除了可以进行字体风格转换任务,还可以进行自然图像与艺术作品风格的转换. 与其他研究者将内容特征与风格特征完全分离不同的是,Zhu等[55 ] 认为字体的字符内容特征与风格特征不是完全相互独立的,二者存在一定联系(内容特征包含笔触、结构、形状等风格信息,只包含直线笔画的字符无法提取到曲线笔画的特征), 因此提出利用特征相似矩阵提取加权风格特征,将内容特征与加权风格特征相结合得到完整的特征表示. 此外,研究者还尝试使用更少数量的字符样本进行风格学习. Jiang等[56 ] 提出只使用样本的中文字体风格转换网络W-Net,其网络结构类似“W”并使用Arjovsky等[67 ] 的Wasserstein距离进行优化. 给定具有特定风格的单个字符,W-Net模型能够学习并生成与给定单个字符相似风格的任意字符. W-Net由原型内容编码器、风格参考编码器以及解码器组成. 为了获得字体原型的低层细节信息,W-Net在原型内容编码器和解码器间进行残差连接. 在原型内容编码器和风格参考编码器的高层与解码器对应层直连,以减小梯度在传播过程中的发散,减少训练误差. ...
Long short-term memory
1
1997
... Wu等[57 ] 于2020年提出CalliGAN,将汉字的笔画信息纳入模型中,利用汉字分解系统获得笔画序列,该系统定义517个组成大部分汉字的笔画构成. 给定输入字符,使用该系统获得它的笔画组成序列,并设计序列编码器将变长序列转换为固定长度的特征向量. 序列编码器包含1个嵌入层和1个长短期记忆(long short-term memory, LSTM)[68 ] 模型,嵌入层将组件代码转换为定长向量输入LSTM模型中得到输入字符的笔画结构特征向量. 对目标风格字符进行目标风格特征提取,将提取的风格特征与笔画结构特征以及类别嵌入相连接,输入生成网络中进行对抗训练,得到目标风格的生成字符. 该方法在很大程度上解决了笔画粘连、连笔模糊、风格不一致等问题,笔画结构特征的使用使得该网络即使没有更复杂的笔画提取阶段,也能生成细节较好的高质量字形图像. 与Wu等[57 ] 利用笔画信息进行结构引导不同的是,Wang等[58 ] 利用字体属性来定制用户想要的字体,提出基于属性注意力的Attribute2Font. 该方法提出新颖的思路:将可控制的属性融入风格转换的任务中. 由于属性标注需要一定的人工操作,Wang等[58 ] 通过设计半监督学习方案来降低人工成本,利用属性注意力模块合成高度多样化且具有美感的字形图像. ...
1
... 中文字体风格转换方法大多是从网络上收集公开的字体数据,根据实验的需要制作数据集,这类数据集很少公开发布. 印刷字体数据集通常可在公开的字体下载网站获得,但是手写字体和书法字体的数据集较少. 可直接从网上获取的有CASIA-HWDB[69 ] 、FlexiFont手写字体库[70 ] 、兰亭数据集[50 ] 、中国书法文字图像库[71 ] ,数据集字体示例如图2 所示. ...
1
... 中文字体风格转换方法大多是从网络上收集公开的字体数据,根据实验的需要制作数据集,这类数据集很少公开发布. 印刷字体数据集通常可在公开的字体下载网站获得,但是手写字体和书法字体的数据集较少. 可直接从网上获取的有CASIA-HWDB[69 ] 、FlexiFont手写字体库[70 ] 、兰亭数据集[50 ] 、中国书法文字图像库[71 ] ,数据集字体示例如图2 所示. ...
1
... 中文字体风格转换方法大多是从网络上收集公开的字体数据,根据实验的需要制作数据集,这类数据集很少公开发布. 印刷字体数据集通常可在公开的字体下载网站获得,但是手写字体和书法字体的数据集较少. 可直接从网上获取的有CASIA-HWDB[69 ] 、FlexiFont手写字体库[70 ] 、兰亭数据集[50 ] 、中国书法文字图像库[71 ] ,数据集字体示例如图2 所示. ...
Image quality assessment: from error visibility to structural similarity
1
2004
... 5)结构相似性(structural similarity, SSIM)[72 ] ,用于衡量生成字符 ${\boldsymbol{Y}}$ ${\boldsymbol{Y}}'$
1
... 6)FID(Frechet inception distance)[73 ] ,用于衡量目标字符的分布与生成字符的分布的距离,其值越小表示2种分布越接近,生成字符质量越好.计算公式为 ...
EasyFont: a style learning-based system to easily build your large-scale handwriting fonts
1
2018
... 手写字体的一大特点是同一字符存在多种形态,即使同一 个人多次书写同一个字,得到的字形通常也存在一定的差异.这并非是不同风格的字形,而是同一风格下的个性化差异.如何表现出这样的差异是手写字体风格转换研究的难点.大多数研究手写字体的方法未解决该问题,Lian等[74 ] 尝试用真实手写字符与机器生成字符互相掺杂的方法减轻生成文本的统一感,但是这样不能从根本上解决个性化差异表现的问题.可能的解决方法是在生成字符的时候加入不影响风格的随机增量特征,以获得同一风格同一汉字的不同字形. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}