

现有的API推荐工具按所需输入信息的不同可以划分为1)利用查询信息的推荐,2)利用编程上下文信息的推荐. 方式1)类似于搜索引擎,开发者输入自然语言查询,推荐工具返回对应的API. 这种方式往往会受制于开发者,原因是程序员想要描述的功能与实际查询输入的自然语言间存在语义鸿沟,查询时输入的自然语言与目标API的自然语言文档描述也存在语义鸿沟,这2层语义鸿沟导致查询的最后结果与初始的API需求有偏差. Deep API Learning[4]、BIKER[5]、BRAID[6]、PreMa[7]等都尝试用不同方式跨越语义鸿沟. 方式2)根据开发者已经完成的代码,通过传统的数据挖掘或深度学习如卷积神经网络[8]、循环神经网络[9]、图神经网络[10-11]等手段找到与当前开发上下文关联度较高的API,为开发者提供提示. 这种方式往往比使用查询信息更为准确,因为与自然语言相比,程序语言更加标准化. 此外,在程序代码中还能提取出如抽象语法树、程序控制流图、API调用结构图等结构化信息,在更深层次匹配开发者需要的API. 不同于方式1)在使用时能根据开发者自由变换较为灵活,方式2)依赖于开发场景,如果开发者的整个项目只写了几行代码,那么推荐性能就会大打折扣.
研究者提出许多方法从不同维度提高方式2)的精度与效率. MAPO[12]、UP-Miner[13]是常用的数据挖掘工具,它们使用基于频度的模式挖掘与聚类技术,从包含海量项目的数据集中抓取所需的API. PAM[14]使用静态的概率模型对API调用序列进行解析找到目标API. 这些方法往往效率较低且没有利用编程上下文整体的结构信息. Nguyen等[15]提出的FOCUS模型在API推荐领域取得较为优秀的成果. FOCUS利用编程上下文的整体结构信息,通过协同过滤[16]的方式结合相似的项目与方法声明,为当前编程现场推荐API. FOCUS模型在协同过滤前需要筛选相似项目,在对相似项目进行筛选时使用 KNN(k-nearest neighbors)[17],无法动态地根据当前的输入对近邻的数量进行变化. 这会在实际选取相似项目时导致少选或多选. 协同过滤进行推荐时会使用向量空间[18]对项目进行存储与表示. FOCUS采用的TF-IDF方法表示相似项目,该方法对单个API的影响程度没有上限,也因此会影响项目整体信息的表示精度.
本研究提出基于自然近邻与协同过滤的API推荐算法. 根据数据集中项目本身的相似度构建自然近邻图,为每次推荐选取最合适的相似项目,利用BM25(best matching 25)[19]对项目进行向量化,控制各个API对整体项目影响程度的阈值,提高向量对项目整体信息的表示精度 ,提升最终的推荐效果.
1. 预备知识
1.1. 逆文本频度算法算法
逆文本频度算法(term frequency-inverse document frequency, TF-IDF)[20]是统计学中常用的方法,用于表示某一字或者词语在文档中的重要程度. 字或者词的重要性与其在文档中出现的次数成正比,但也会随着它在语料库中出现的频率成反比下降. 比如文章中出现多次“推荐”,那么“推荐”这个词很可能是这个文章的关键词,如果重复出现多次的是“的”或者“因为”这样的字词,由于它们在几乎所有文章中都会出现,因此其重要性不会很高.
1.2. BM25算法
BM25作为信息检索领域的方法,往往被用作文本表示. 相较于TF-IDF方法,它关注到词频与相关性间并非线性关系,而是随着词频的上升到达上限. BM25通过参数k、b增加对词频影响因素的控制,使单一词的影响程度存在上限. 例如,文章中出现生僻词“菡萏”,由于这个词在绝大部分文章中都没有出现,使用TF-IDF将导致词的权重过高,即使剩下的内容毫不相干,也可能因为这个词判定2篇文章相似. BM25避免了这种情况,使得后续使用余弦相似度或者欧式距离方式衡量相似度时更具有全局性.
1.3. 自然近邻
自然近邻[21]是新型的近邻概念,相较于KNN或者类似的近邻关系,自然邻居的搜索无须预设参数,是无尺度的最近邻概念,其利用数据集自身的特性进行自然邻居搜索,通过每个数据点的自然邻居数目,判断其周围的数据分布情况,在不同的数据集上都有比较好的表现.
1.4. 基于协同过滤的API推荐算法
FOCUS的主体包括相似项目检索、相似方法声明检索、协同过滤获得候选API,共3个部分. 该算法的流程为1)从数据库检索出相似项目集合,2)由相似项目集合中找到与编辑中的方法声明相似的方法声明,3)用协同过滤法筛选出可能供开发者使用的下个API.
区别于MAPO与PAM推荐方法,FOCUS使用代码的结构化API调用信息,使推荐结果不限于局部代码,能更有效地为开发者提供推荐.
1.5. 编程上下文
编程上下文的概念比较抽象. 对于不同的模型,编程上下文的范围各不相同,大体上分为1)编程上下文涵盖整个项目,如FOCUS以及本文中的方法;2)编程上下文包含当前正在开发代码片段,如方法、函数或类,以及与当前方法有逻辑关系的代码片段,如HiRec[22]中使用到的就是这种编程上下文;3)仅包含当前代码片段,如MAPO、UP-Miner. 在表现形式上,不同的模型中编程上下文可以表示为词袋、token序列、API调用序列、抽象语法树、程序控制流图、API调用结构图等多种形式. 本研究使用API调用结构图的表示形式.
2. 模型流程
模型的整体流程如图1所示. 可以看出,原始数据集中的项目源代码经过解析转化为API调用结构图,使用BM25方法将项目表示为对应的向量,这些向量通过自然的近邻计算得到自然近邻图. 开发者的项目p在推荐时也经过相同步骤转化为向量,再从自然近邻图中获取相似的项目集合S(p). 从相似项目包含的声明中利用API调用序列信息,筛选出与当前开发者的项目中正在开发的声明d相似的声明集合S(d) ,以协同过滤的方式为开发者推荐需要的API.
图 1
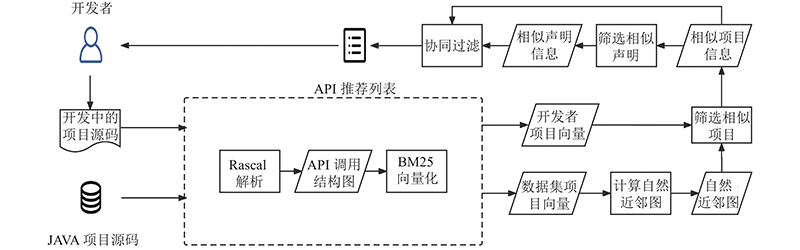
2.1. 数据预处理
图 2
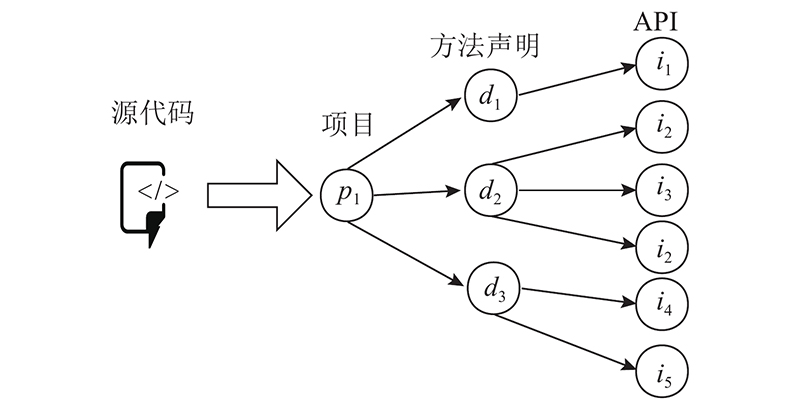
软件项目是独立的源代码单元,它能独立执行一组功能任务,方法声明由名称、参数列表、返回类型和方法体组成,API是接口,它通过隐藏实现细节来抽象提供具体的功能. 软件项目p中包含的所有方法声明组成集合D,其中每个方法声明d∈D都调用若干个API,即i∈I. 图2中,项目p1包含3个方法声明:d1、d2、d3. p1总共调用i1、i2、i3、i4和i5这5种接口.
2.2. 相似项目检索
抽取出API调用结构图后,下一步是对相似项目的检索. 检索相似项目的目的,是为了在整个数据集中选取合适规模的子集,减少后续协同过滤步骤形成的矩阵大小进而减少检索的时间. 这一步也对最后的推荐效果有重要的影响,如果子集选取不恰当,便会漏掉许多有用信息,造成推荐结果下降.
2.2.1. 使用BM25对项目进行向量化
相似项目检索的第一步就是使用BM25将项目表示为向量. 对API的推荐而言,BM25使用的不再是单词词频与文本,而是项目中的API调用信息. 对于待推荐API的项目p,把p中调用的所有API均看作其中的词即
式中:ft为接口it在该编程项目中所占的权重;Tt 为it在该程序项目p中出现的次数;k、b为先验参数,其值须自行设置,在本研究中设置k=2.8、 b=0.75;Lavg为平均文本长度,经过对MV、SH数据集的统计,平均单个项目的API调用数为537个,因此设置Lavg=537;αt为结合逆文本频度后该API在项目中的权重;|P|为该数据集中项目的数量;ht为数据集中调用过接口it的项目数量,项目p由此种方式可表示为由α1,α2,α3等由不同API权重组成的向量.
2.2.2. 项目相似性计算
项目经过BM25方法表示为向量后,不同项目的相似度便可量化. 使用传统的余弦相似度度量2个项目间的相似程度,余弦相似度的公式为
式中:sp表示项目相似度,q为数据集P中的某个项目,n为代码数据集P中所有包含的API接口种类数,βt为接口it在项目q中的权重.
通过余弦相似度,原本多维的项目向量间形成全序关系,可得按相似度降序排列的列表List(p). 如表1所示为项目“g_batik-codec-1.8”的相似度列表. 同理,能用这种方式离线得到数据集P中每个项目的相似度列表.
表 1 项目g_batik-codec-1.8的相似度列表
Tab.1
| 项目名称 | sp |
| g_xmlgraphics-commons-1.5 | 0.418 |
| g_batik-awt-util-1.7 | 0.284 |
| g_filters-2.0.235 | 0.107 |
| g_fop-2.0 | 0.054 |
| g_jcaptcha-2.0-alpha-1-SNA | 0.031 |
| g_jwi-2.2.3 | 0.029 |
| g_pdfxstream-3.5.0 | 0.026 |
| g_objenesis-1.2 | 0.026 |
| g_apache-mime4j-core-0.7.2 | 0.025 |
| g_spring-security-crypto-3.2 | 0.023 |
| g_batik-svggen-1.7 | 0.022 |
| g_itextpdf-5.5.13 | 0.021 |
2.2.3. 计算自然近邻图与选取相似项目
计算完成相似性后,要根据List(p)选取相似项目,以往的做法比如在FOCUS[15]中,都是使用KNN,固定地选取前K个项目作为数据集的子集,再在子集上进行检索,为后续协同过滤减少计算时间与复杂度.
实际上,子集的选取影响着整个推荐的准确率和时间效率. 在不同的推荐任务中,与当前项目相似的项目数并不固定,以固定的数目选择的子集往往会偏离真正的近似集合,造成少选或多选,引起在后续推荐过程中的准确度下降或时间消耗增加. 为了解决这一问题,本研究采用自然近邻算法选取相似项目的集合. 对于每个数据集计算数据,集中每个项目的自然近邻数目,构建自然近邻图的具体算法如下.
算法1 自然近邻图生成算法
输入: 数据集P中每个项目的相似度列表List(i).
输出: 数据集中项目的平均自然近邻数navg,每个 项目的自然近邻数nb.
1. x=1,f=0,a1=P中的项目数量,a2=0;
2.
3. While f=0;
4. If a1−a2==0, Then f=1;
5. else;
6. for
7. 根据List(i)查找i的第x个邻居nx(i);
8. nb(nx(i))=nb(nx(i))+1;
9. end for;
10. If x>=2;
11. a1=a2;
12. end if;
13. x=x+1,a2=P中nb (i)为0的个数;
14. end while;
15. navg=x−1.
自然近邻数nb的计算从x=1开始,遍历数据集中的每个项目i∈P,每个项目i将加入其距离x内的项目的自然近邻,遍历一次后统计nb(i)=0的项目个数,接着增加x并继续下轮遍历,直到有一轮遍历中nb (i)=0的项目个数没有发生变化,此时自然近邻计算完成. navg与nb(i)结合相似度列表List(i)后,便能用邻接表的形式表示整个数据集的自然近邻图. 对于每个需要API推荐的项目p,只需遍历一次P将其插入自然近邻图中,就能得到推荐项目p的自然近邻数nb (p). 相似项目数量为
式中:g(p)为相似项目列表List(p)中斜率下降最快的点. 如图3所示为项目p与数据集中各个项目的相似度变化曲线. 相似列表中,排第4的点到第5的点斜率最为陡峭,因此截取前4个,g(p)=4.
图 3
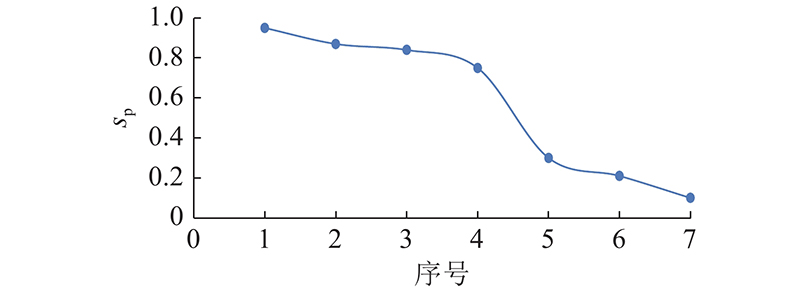
通常会有个别的项目自然近邻数量过多,导致相似项目集合过于庞大,此时式(4)中navg会对Snum起到限制作用. 此外,在计算出自然近邻后,少数项目的自然近邻存在一部分较为相似,一部分最为相似的情况,式(4)中g(p)起到控制作用,选出项目p其自然近邻中相似度最高的那个部分. 根据相似项目数Snum(p)能够从List(p)中得到相似项目集合S (p).
2.3. 相似声明检索
在获取到相似项目后,S(p)和p中包含的所有声明组成集合D. 下一步是选取相似的方法声明,在传统Jaccard相似度[24]外加入API调用序列信息,方法声明间的相似度计算式为
式中:sd(d,e)为声明d与声明e相似度,d为当前正在开发的声明;e为D中的声明;F(d)为声明中所有调用的API集合;L(e)为声明e的API调用序列长度,如某个名为“attend_Write_Information”的方法声明中API调用序列为“appned( )、newLine( )、flush( )、flush( )、error()”,其API调用序列长度是5,调用集合大小为4;LCS( )为声明d、e的最长公共子序列长度,2个序列只要保证各自去掉若干个元素后剩下的字符串相同,剩下的字符串就是两者的公共子序列 ,最长公共子序列则是能够得到的子序列中长度最长的. 如字符串s0=“abdfg”,字符串s1=“abceg”,两者的公共子序列为{a,b,g,ab,bg,ag,abg},最长公共子序列为abg,可以得到LCS(s0,s1)的值为3.
在计算完声明相似度后,须从按相似度排序的列表中选取合适数量的声明. 在这一步中不适合再使用自然近邻的方法,原因是每次推荐由相似项目中的声明构成的声明集合D都是不相同的,须根据每次推荐任务重新生成自然近邻图。这样做的开销过高,因此直接用g(p)确定相似声明集合S(d).
2.4. API协同过滤推荐
利用信息进行协同过滤,为候选API进行评分生成API列表. p与S (p)中调用的每种API构成候选API集合I,对于所有的i∈I用协同过滤[16]进行评分:
公式中:rp,d,i为项目p中开发者正在开发的声明d对API接口i的评分,q为声明e所在的相似项目,
通过对I中每个API进行评分,得到降序排列的API推荐列表rp,d. 开发者可以根据列表中推荐出的相关API完成开发任务.
3. 实验设计
3.1. 研究问题
推荐方法在实际应用场景中的推荐是否准确是最为关键的,因此需要量化对比准确率相关指标. 此外,还需通过消融实验探究方法中的模块对于推荐结果是否都影响最终的推荐效果,出于实际使用的考量,探究代码完成度对于推荐效果的影响. 推荐时间和开发者的开发效率息息相关,如果一次推荐耗时过长,对实际编程的辅助效果则十分有限. 由此,本研究将对以下4个问题进行探究. 1)N-APIRec的推荐准确率如何,它是否能比现有的同类型方法表现得更好。2)N-APIRec的各个模块是否都起到了作用,这些模块对推荐效果的影响有多大。3)代码完成度会对实验结果有哪些影响。4)N-APIRec的时间效率如何。
3.2. 数据集
实验使用2个公开的数据集:MV、SH. 这2个数据集中包含的都是JAVA项目. MV的原始数据有3 600个Maven库中的项目,为了防止同一项目的不同版本对实验结果造成影响,经过筛选,剩下1 600个各不相同的Maven项目,构成MV数据集. SH数据集由200个规模较小的项目组成,这些项目都是从GitHub上随机挑610个项目后,再筛选其中最小的200个得到的。由于PAM不适用于大规模数据,SH数据集是为了适应PAM的对照而设置的小样本数据集. 数据集的统计数据如表2所示.
表 2 实验数据集统计信息
Tab.2
| 数据集 | 项目数量 | 方法数量 | API数量 | API调用次数 |
| MV | 1 600 | 97 255 | 30 442 | 939 645 |
| SH | 200 | 4 530 | 5 351 | 27 312 |
3.3. 对比工具
为了验证方法的有效性,探究模型中各个模块对最终API推荐效果的影响程度,将PAM、FOCUS以及N-APIRec的几种变体作为对照.
PAM:无参数概率挖掘API使用模式的方法,使用API调用序列作为模型中输入的编程上下文信息,具有较低的冗余度和较高的精度,优于其他统计方法. 选择PAM作为比较基准的原因是它已经被证明比其他类似的方法(如MAPO、UP-Miner)表现更好.
FOCUS:前沿的基于协同过滤的API推荐方法. 使用API调用结构图作为模型中输入的编程上下文信息. FOCUS使用向量空间模型来表示API调用关系,并且使用TF-IDF方法把项目进行向量化表示.
N-APIRec-S: N-APIRec的变体,去掉N-APIRec中的序列相似度计算模块.
N-APIRec-B: N-APIRec的变体,去掉N-APIRec中的BM25的模块,为了整个模型能够正常运行,作为代替由TF-IDF方法进行向量表示.
N-APIRec-N: N-APIRec的变体,去掉N-APIRec中的自然近邻的模块,为了整个模型能够正常运行,作为代替由KNN来选取相似项目,设定K=2.
3.4. 评估指标
在实验中,对于每次推荐,截取项目p中的部分编程上下文为输入. 输入包含项目p已开发完成的方法声明和当前需要推荐API的声明d中的部分API,并且把剩余的部分作为正确结果即G(d),推荐系统会返回API列表,本研究的目的是让推荐系统能够返回G(d)中的API. 除了有关代码完成度的实验,统一设置输入编程上下文的范围为p中前50%的方法声明与当前方法声明d中调用的前4个API .
在工具实际完成推荐任务时,一般认为开发者只会注意到前面若干个推荐结果而非整个推荐列表,因此在结果评估时只考虑前面n个返回结果. 前n个结果中相匹配的个数记为Mn=G(d)∩rp,d,Mn越大,说明推荐结果越精确. 实验采用成功率(success),召回率(recall),准确率(precision),共3个指标衡量方法的有效性.
成功率:给定一组测试项目集合P,对于其中的每个项目p,统计其是否能成功返回正确结果的次数. 成功率反映推荐系统在推荐上的有效性.
式中:SUCn为推荐出的前n个结果的成功率,c( )为统计成功返回正确结果的次数,只要返回有1个或以上的正确结果,c( )的计数就增加1.
召回率:用于衡量推荐结果对正确答案的覆盖程度.
式中:RECn为推荐出的前n个结果的召回率.
准确率:用于衡量推荐结果中有效结果的占比,区别于成功率,准确率更偏向于衡量单次推荐的精确程度,即在一次推荐中,有效结果的在所有推荐结果中的占比.
式中:PREn为推荐出的前n个结果的准确率.
3.5. 实验环境
实验均在Windows操作系统下完成,软件与硬件条件如下. 1)软件环境:操作系统为Win10,数据集源码JDK版本为1.8.0,推荐工具运行JDK版本为14.0.2,编辑工具环境为vscode 1.36.2)硬件环境:CPU版本为Intel Core i7-4720HQ 2.60 GHz 8核心,内存为16 GB.
4. 实验结果
4.1. 推荐准确率与有效性
问题1)探讨方法的准确率与有效性。只有当推荐工具能较为精确地返回API时,才能有效地提高开发者的开发效率. 在数据集MV、SH上对PAM、FOCUS、N-APIRec进行比较. APIRec的成功率、准确率、召回率等指标如表3中所示.
表 3 N-APIRec在数据集MV、SH上的表现
Tab.3
| n | MV | SH | |||||
| SUCn/% | PREn | RECn | SUCn/% | PREn | RECn | ||
| 1 | 77.4 | 0.774 | 0.107 | 30.0 | 0.300 | 0.098 | |
| 5 | 87.5 | 0.569 | 0.366 | 42.0 | 0.143 | 0.185 | |
| 10 | 90.3 | 0.394 | 0.481 | 47.5 | 0.099 | 0.234 | |
| 15 | 91.9 | 0.297 | 0.529 | 50.5 | 0.078 | 0.269 | |
| 20 | 92.7 | 0.238 | 0.555 | 52.5 | 0.062 | 0.287 | |
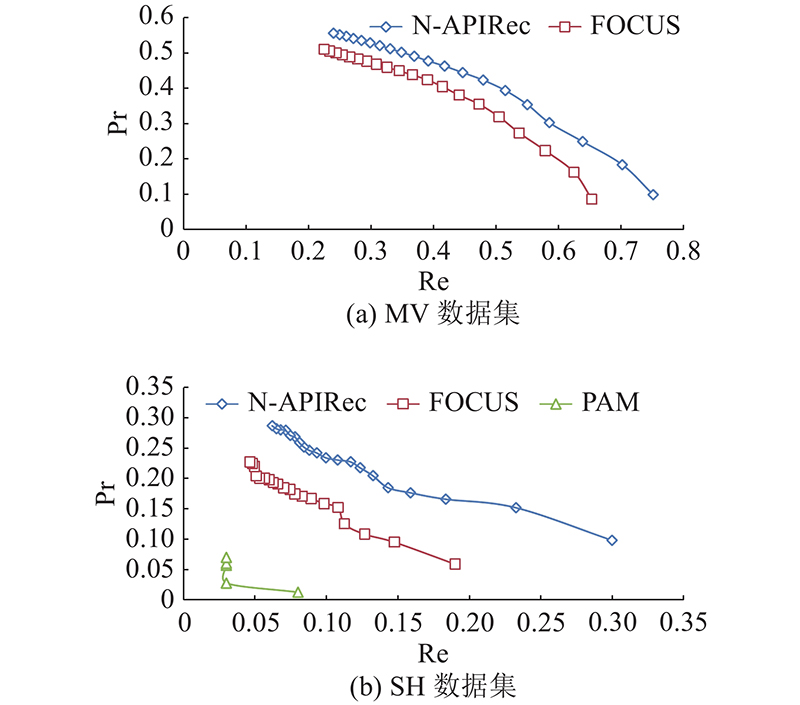
可以看到,N-APIRec在数据集MV的表现优于SH. 主要原因是MV数据集较大,有更大概率包含类似的API调用结构. 结合如表4、5中的信息对比不同工具的表现,可以看到N-APIRec在MV数据集上SUC1=77.4%,相较于FOCUS提升12.1%; SUC20=92.7%,相较于FOCUS提升3.9%. 在数据集SH上SUC1=30.0%,相较于FOCUS提升11%,且相较于PAM提升22%; SUC20=52.5%,相较于FOCUS提升11.5%,且相较于PAM提升19%. 和其他方法相比,N-APIRec对SUC1的提升相较于SUC20的提升更为显著,这也是实际推荐时开发者所需要的. 原因是对于每次推荐,即使把正确结果推荐出来却不在列表前几个,仍然需要花费较大的时间去检索推荐列表. 为了更直观地观察PAM、FOCUS、N-APIRec的综合表现,绘制如图4所示的精确度召回率(P-R)曲线. 可以看到,不论是在SH还是在MV上,N-APIRec的曲线都处于FOCUS与PAM工具的右上侧,表明N-APIRec在PREn与RECn的综合表现优于FOCUS、PAM. 且在SH中FOCUS与N-APIRec的精确度Pr召回率Re曲线明显优于PAM,体现出协同过滤方法在API推荐上的表现相较于传统基于概率的数据挖掘有一定优势.
表 4 在SH数据集上不同方法的成功率
Tab.4
| % | |||||
| 方法 | SUC1 | SUC5 | SUC10 | SUC15 | SUC20 |
| PAM | 8.0 | 15.0 | 27.4 | 29.5 | 33.5 |
| FOCUS | 19.0 | 31.5 | 37.0 | 37.5 | 41.0 |
| N-APIRec-S | 25.5 | 33.0 | 40.5 | 44.0 | 46.5 |
| N-APIRec-B | 29.0 | 42.0 | 48.5 | 49.5 | 51.5 |
| N-APIRec-N | 25.0 | 40.0 | 45.0 | 49.0 | 51.5 |
| N-APIRec | 30.0 | 42.0 | 47.5 | 50.5 | 52.5 |
图 4
4.2. 消融实验
问题2)是为了能够了解各个模块对整个推荐系统的影响. 为此设置N-APIRec的不同版本并进行实验. 在表4、5中可以看到,在SH、MV上n={1,5,10,15,20}的成功率. 即使是去除其中不同部分的模块,N-APIRec在成功率上的整体表现仍然比PAM与FOCUS好. 在实验中发现,这3个模块都在一定程度上影响了推荐效果. 其中,去除自然近邻模块对结果的影响程度最高,N-APIRec-N相较于完整版在SH中SUC1下降5%;在MV中SUC1下降3.4%. 相较而言,BM25在SH上对SUC1的影响偏小为1%. 推测可能的原因是SH内每个项目都较小,BM25算法对较短文本的影响不够显著.
表 5 在MV数据集上不同方法的成功率
Tab.5
| % | |||||
| 方法 | SUC1 | SUC5 | SUC10 | SUC15 | SUC20 |
| FOCUS | 65.3 | 81.3 | 85.8 | 87.7 | 88.8 |
| N-APIRec-S | 74.9 | 85.5 | 89.1 | 91.0 | 91.9 |
| N-APIRec-B | 75.1 | 86.2 | 89.9 | 91.6 | 92.6 |
| N-APIRec-N | 74.0 | 85.8 | 88.6 | 89.9 | 90.9 |
| N-APIRec | 77.4 | 87.5 | 90.3 | 91.9 | 92.7 |
4.3. 代码完成度
前面的实验,统一设置输入为p中前50%的方法声明与当前方法声明d中调用的前4个API. 实际上代码的完成度与推荐效果息息相关. 为了回答问题3),进行如下实验. 代码完成度可以分为1)项目完成度Cp,即项目中已完成的方法声明在整个项目中的所占比例;2)方法声明完成度Cd,即当前开发方法声明中已调用的API的个数.
仍以方法声明中的前4个API作为输入,改变项目完成度. 由于项目完成度不同,当前方法声明d会发生变化,为了控制变量,在关于项目完成度的实验中,不根据项目完成度动态选择当前方法声明,而是统一将项目p中的最后1个方法声明用于测试,实验结果如表6所示. 可以看到,当项目完成度由80%降低到20%时,SUC20仅降低3.5%,随着项目完成度的改变,推荐成功率SUCn并无显著变化. 在实验中发现,仅在整个项目极度不完整时,项目相似度对N-APIRec的推荐效果有较大影响.
表 6 SH数据集上不同项目完成度下的成功率
Tab.6
| % | |||||
| Cp | SUC1 | SUC5 | SUC10 | SUC15 | SUC20 |
| 20 | 21.0 | 26.5 | 29.5 | 31.5 | 32.0 |
| 40 | 22.5 | 26.5 | 29.5 | 32.0 | 32.0 |
| 60 | 22.5 | 27.0 | 30.0 | 33.0 | 33.5 |
| 80 | 22.5 | 27.5 | 30.5 | 33.0 | 35.5 |
表 7 SH数据集上不同方法声明完成度下的召回率
Tab.7
| Cd | REC1 | REC5 | REC10 | REC15 | REC20 |
| 1 | 0.030 | 0.082 | 0.110 | 0.123 | 0.134 |
| 2 | 0.054 | 0.135 | 0.175 | 0.206 | 0.220 |
| 3 | 0.074 | 0.160 | 0.208 | 0.237 | 0.251 |
| 4 | 0.098 | 0.185 | 0.234 | 0.269 | 0.287 |
4.4. 时间效率
为了回答问题4),记录下不同数据集上的平均推荐时长,PAM推荐时间过长且只适合数据量较小的场景,因此只与FOCUS进行比较. N-APIRec在数据集MV、SH上平均每次推荐用时0.233 s,FOCUS在MV、SH上平均每次推荐用时0.126 s. 虽然与FOCUS平均单次推荐时间0.126 s相比多用0.107 s,但研究表明,只要响应时间不超过1.0 s[25],对于用户来说是难以察觉的,并且N-APIRec在成功率、召回率、准确率上较FOCUS有一定提升,推荐时长的增加程度仍在可以接受的范围内.
为了考虑数据集P规模较大时方法是否仍旧可行,需要探究方法整体的复杂度。对于整个方法而言,时间消耗主要在以下阶段. 1)自然近邻图生成. 自然近邻图生成根据其算法容易得出时间复杂度为o(|P|^2). 2)相似项目检索. 相似项目检索需遍历数据集中所有项目,并计算相似度,计算相似度的时间消耗是由项目平均代码量确定的,不会因数据集P的规模产生变化. 因此该阶段实际复杂度为o(|P|). 3)协同过滤. 实际上协同过滤阶段的复杂度与数据集P的规模无关,只与当前项目p的相似项目个数有关,不会随着P变化,因此无须考虑此环境复杂度的影响. 仅有自然近邻图生成与相似项目检索阶段的时间消耗会随着数据集P的规模增大,自然近邻图的生成是离线完成的,不会影响到推荐时间. 因此推荐时长仅受相似项目检索环节影响,大体上随着数据集P的规模线性增长,在数据集P规模较大时该复杂度是可以接受的.
5. 结 论
(1)本研究基于自然近邻与协同过滤的API推荐方法——N-APIRec。该方法用BM25将项目向量化表示,再使用自然近邻算法筛选数据集中的相似项目得到相似声明,通过协同过滤推荐API.
(2)N-APIRec的主要优点是使用了自然近邻的概念,无须预先设置参数,就能适应不同的数据集,针对每次推荐减少无效的搜索,捕获更多有用的相似项目. 此外,该方法考虑到代码全局的相似性,使用BM25对项目进行向量化,使得推荐结果更为精确.
(3)将N-APIRec与PAM、FOCUS工具在数据集MV、SH上进行比较,实验结果表明,N-APIRec在成功率、准确率、召回率等表现上都更为出色.
(4)未来API推荐还可以研究的问题如下. 1)序列化推荐. 考虑到现有的API推荐方法往往只能推荐单个的API,推荐场景下API序列能够给开发者更好的帮助. 下一步可以研究是否能在该方法的基础上提供序列推荐的能力. 2)API使用模式的推荐. 在为开发者提供推荐时,由于开发者对API不了解,API的文档描述也不一定能帮助开发者使用API. API使用模式推荐在推荐API时,为开发者找到对应API的代码样例,开发者根据样例来进行编程,检索过程类似于搜索代码片段如ROSF、Aroma[26],这些方法推荐出的代码片段往往是独立的,无法与API对应. 如何在推荐API的过程中推荐对应的代码样例是可以研究的方向.
参考文献
Query expansion based on crowd knowledge for code search
[J].DOI:10.1109/TSC.2016.2560165 [本文引用: 1]
ROSF: leveraging information retrieval and supervised learning for recommending code snippets
[J].DOI:10.1109/TSC.2016.2592909 [本文引用: 1]
Boosting API recommendation with implicit feedback
[J].
Convolutional networks for images, speech, and time series
[J].
Long short-term memory
[J].DOI:10.1162/neco.1997.9.8.1735 [本文引用: 1]
The graph neural network model
[J].
A clustering algorithm based on natural nearest neighbor
[J].
The distribution of the flora in the alpine zone
[J].
A study on tolerable waiting time: how long are web users willing to wait?
[J].DOI:10.1080/01449290410001669914 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}