

随着区块链技术的发展,越来越多的数据被分散存储在不同区块链上,形成复杂的多链场景. 然而,不同区块链间具有隔离性,链与链间形成数据孤岛,导致数据无法直接互通,使得在多链间检索出用户感兴趣的信息,即多区块链的连接查询操作变得复杂. 现有区块链系统只支持基于单链的数据查询操作,没有考虑多区块链场景下的数据连接查询处理. 考虑到区块链间跨地域部署,直接进行数据连接操作会产生巨大的本地计算负载与网络传输开销,严重影响连接查询效率,影响用户体验. 因此多区块链连接查询处理的优化尤为重要.
以现实场景为例,有2家拥有不同区块链的医疗机构. 当用户发出查询‘Q[Amy]’时,须返回2家机构与‘Amy’相关的病例. 运用现有的查询技术,仅能先在区块链A上查询获得相关数据,再在区块链B上查询获得数据,最后进行整合. 这种查询方式会产生高昂的本地计算负载代价和网络延迟. 尤其在面对海量数据时,数据的网络传输开销逐渐增加,连接计算的效率逐渐降低,会导致较差的用户体验.
本研究的重点是对多区块链连接查询进行优化,尽可能降低代价成本,减少响应时间. 主要面临以下2个挑战. 1)连接语义较弱. 虽然区块链上的事务包含多个属性,但是现有的多区块链框架并没有仔细考虑这一点,每个属性值并没有对应的语义描述. 因此事务之间无法建立关系,不支持区块链上和区块链间的连接操作. 2)连接查询效率低. 事务存储在链上区块内,事务之间没有索引,数据查询须遍历完整的链,遍历造成的磁盘随机读取次数增加,时间消耗大;并且考虑到多区块链跨地域部署的特点,多个区块链没有连接,须分别进行查询,再进行结果合并,网络通信代价大,因此查询效率低.
本研究针对多区块链连接查询优化问题,面对以上挑战,提出一种多链连接查询优化方法. 首先,针对连接语义较弱,为了便于进行多链连接,设计一种语义多区块链模型(semantic multi-blockchain model, SMM),通过更改区块链的原有数据存储模型,添加语义信息. 其次,针对连接查询效率低,在语义区块链模型上,设计基于语义区块链模型的多链连接索引(semantic multi-chains model join index, SMMI),进行链间属性的连接;基于SMMI设计多链连接查询优化算法,提升多区块链连接查询的效率. 最后,在真实公开的数据集上进行实验,验证多链连接查询优化算法的有效性.
1. 相关工作
为了应对区块链在各个领域应用中所面临的数据管理方面的新需求,来自学术界和工业界的许多研究开始专注于区块链技术与数据管理技术的结合,促使区块链技术在传统行业领域广泛使用. ChainSQL[10]通过在区块链上实现拜占庭协议,实现区块链和数据库结合,并将所有事务传输到关系型数据库中丰富查询功能. 但是该方法存在2个数据复制备份,并且无法证明数据的完整性. EtherQL[11]为以太坊添加了一个高效的查询层,通过使用MongoDB为外部数据提供分析查询. FlureeDB[12]是结合了区块链技术的可扩展的图形数据库,虽然它们丰富了查询的功能,但未提高查询的性能. SEBDB[13]为区块数据添加了关系语义,并将SQL实现. 这些研究都增加了区块链本身的查询能力,但是都是基于单链进行的研究.
随着区块链技术在数据管理方面的广泛应用,有时一个机构内多个部门会运用多条区块链进行数据管理,多个机构也会运用多条区块链进行数据管理. 多区块链环境愈发常见,多区块链之间的数据共享成为了一个研究热点. 由于区块链技术的相互独立性,现存各区块链系统之间的数据通信、价值转移面临挑战,跨链技术是多个区块链系统之间实现互联互通、提升可扩展性的重要技术手段[14]. 李芳等[15]针对适用于不同应用场景的区块链技术如比特币、以太坊和Hyperledger Fabric等公有链,以及私有链、联盟链大量共存的特点对跨链技术领域的成果进行了系统总结. Zakhary等[16]提出AC3WN协议,即去中心化的原子跨链共识协议. 多种跨链技术为链间的数据共享提供了技术支持.
2. 问题定义
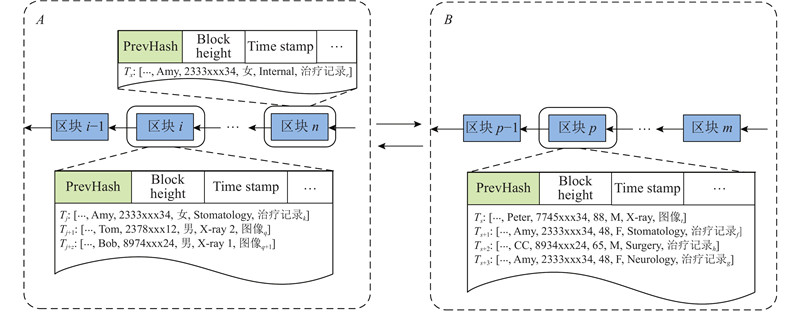
定义1 多区块链模型.链的集合为Chains= BC1∪ BC2∪ BC3∪···,BCi为一条区块链. 如图1所示为一个多区块链模型,包含区块链A和区块链B,2条医疗区块链.
定义2 多区块链连接查询. 查询由1个二元组构成,Q=[k1,k2
图 1
3. 语义多区块链模型
考虑到现有的多区块链系统数据存储不包含语义,限制了连接查询,因此本节基于现有多链模型,设计了语义多区块链模型(SMM).
定义3 语义区块链. 定义添加语义信息的区块链为语义区块链(Sematic Blockchain,S),S=S-Block1+ S-Block2+ S-Block3+···,S-Blocki为语义区块. SMM每条区块链的区块结构如图2所示.
图 2
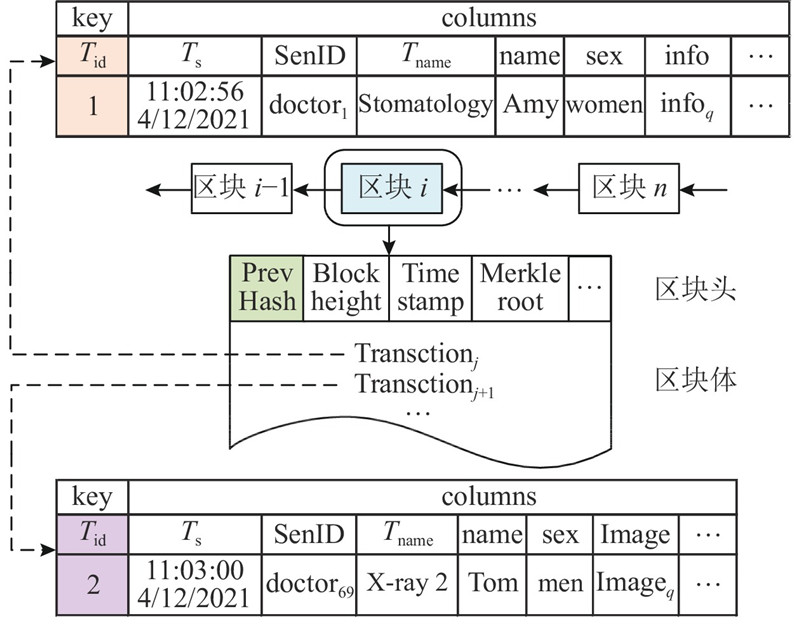
定义4 语义区块. 如图2所示,S-Block包含区块头(Block head)和语义区块体(S-Block body)两部分. S-Block=Block head+S-Block body. Block head与传统区块链区块结构相同,Block head存放Merkle根(Merkle root)、前块哈希(PrevHash)、区块高度(block height)、时间戳(time stamp)等. Merkle根基于块内的事务数据哈希生成,实现块内事务数据不可篡改;前块哈希为前一区块内事务生成的哈希值,提供了区块间的链接;区块高度为当前区块在链上的位置;时间戳表明了该区块的生成时间. S-Block body包含大量的事务. 为了提供语义信息,将S-Block body事务数据的存储形式改变为<Key, Columns>,对每个属性值都对应添加了语义信息,如图2所示为更改后的存储模型,不同类型事务Columns中包含不同的属性语义信息和属性值,如“name=Amy,sex=women,info=Infoq”,其中name为属性语义信息,对应的“Amy”为属性值.
定义5 语义事务. Tx={Tid=v1, Ts=v2, SenID=v3, Tname=v4, Attributes},Tid为事务的唯一标识,Ts为该事务的时间戳,SenID为事务发起者,Tname为事务类型,vi为属性值,Attributes为用户自定义的应用级属性的集合Attributes={attr1=vm,attr2=vm+1, ···, attrn=vn-m+1},针对不同应用场合和事务类型,设为不同的属性集合. 如图2所示,事务Tj+1={Tid=2, Ts=11:03:00 4/12/2021, SenID=doctor1, Tname=X-ray2, name=Tom, sex=men, image=Imageq},说明男病人Tom在2021年4月12日11:03在放射2科的医生1处进行了透视,生成了Imageq.
4. 多区块链连接索引结构
在第3节中,SMM模型使事务具有了语义信息,但是由于事务属性种类、存储顺序不同,区别于表结构,语义区块内无法直接投影进行连接操作. 另外,直接使用原数据进行连接查询会产生大量的计算负载与网络延迟. 为了实现对Columns中各个属性的高效连接查询,须对其建立一个有效的索引.
4.1. 多区块链连接索引
为了高效连接,提出基于SMM的多区块链连接索引(SMMI),由3部分组成.
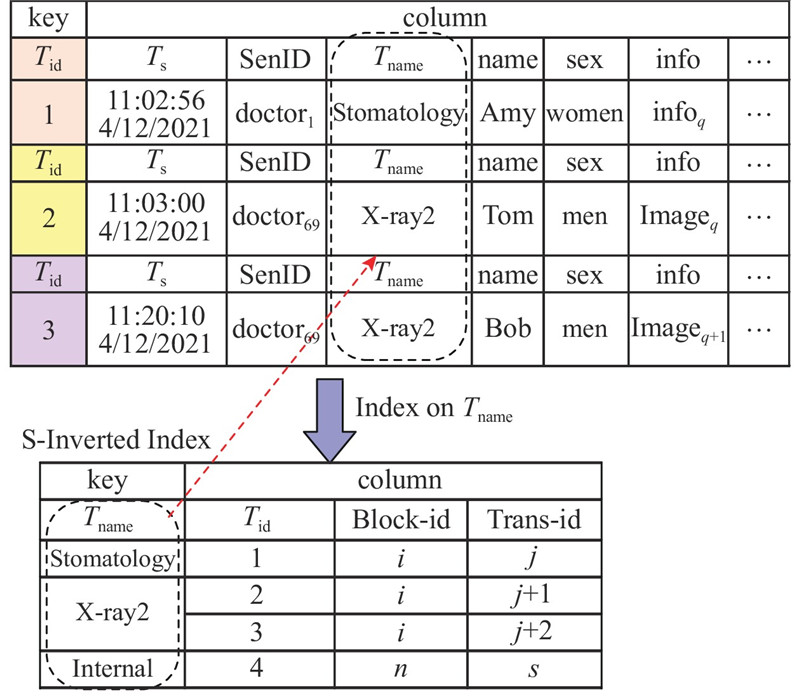
1)S-Inverted Index. 为了降低数据的网络传输代价,减少源数据的I/O读取次数,参考倒排索引,设计索引的结构为<key, column>. 索引由构建属性的语义信息attr进行命名,key为源数据Columns中的属性值,而索引中key对应的column为源数据的位置信息,包含Tid(事务唯一标识)、Block-id(块号)、Trans-id(事务号).
如图3所示,对区块链A的Tname属性建立S-Inverted Index,命名“Tname _S-Inverted Index”,索引的key为属性Tname的值,如图3中虚线箭头标识,下方索引的key值为对应上方源数据中属性列Tname的值,其中“key=Stomatology”为源数据“Tid=1”事务的Tname值. S-Inverted Index中column为对应的事务标识和链内位置,考虑到区块链以块为单位的更新频率,索引文件需要长时间的维护,并且多链间呈异地分布,相互通信须考虑网络传输代价,因此须使用尽量小的数据量构建索引. 该设计简化了索引的存储复杂度,在多链连接查询时减少了数据传输的通信代价、源数据的I/O次数.
图 3
2)S-Bitmap Index.为了提高连接计算的效率,参考位图结构,根据各个区块链的S-Inverted Index构建S-Bitmap Index. S-Bitmap Index描述每个属性(attr)在所有链上的取值分布情况,每个attr对应一个S-Bitmap Index,索引的第th行表示每条语义区块链是否在存在attr为vth值的事务,第th行中第i bit为“0”表示第i条语义区块链不存在attr为vth值的事务,为“1”表示第i条语义区块链存在attr为vth值的事务. 如图4(a)所示,针对Tname属性构建S-Bitmap Index,左侧列为所有语义区块链Tname的取值情况. 最后一行右侧列前2位为1,表示在链A、B中含有符合Tname=X-ray的数据. 每当新的语义区块链加入或区块数量增加时,须通过S-Inverted Index对S-Bitmap Index进行更新. 通过该索引可以大幅提升连接查询的效率,直接判断连接条件是否成立.
图 4
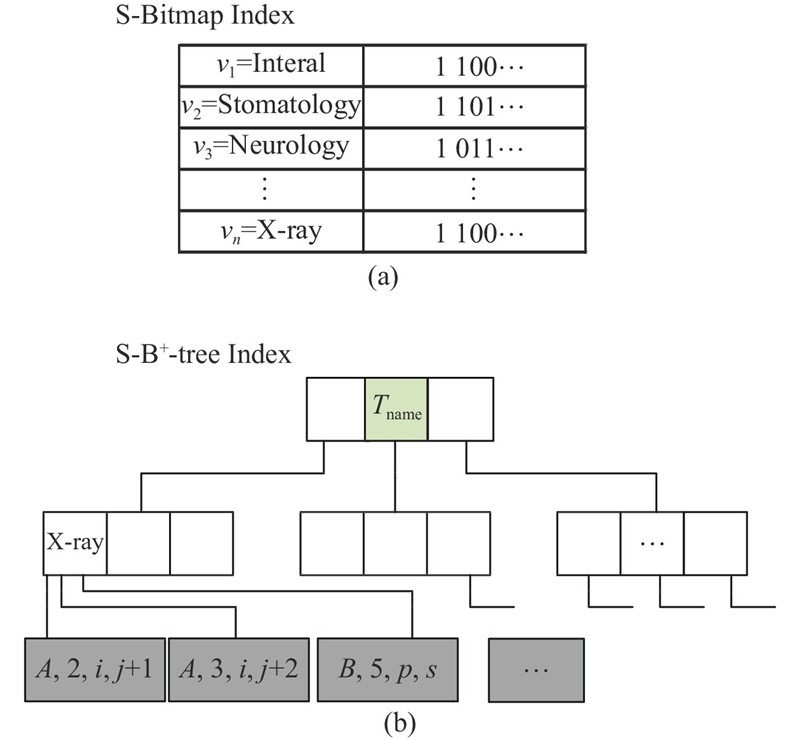
3)S-B+-tree Index.为了提高查询效率,基于S-Inverted Index索引设计了S-B+-tree Index. 通过S-Bitmap Index可以清楚地知道连接是否成立,进一步高效地获取事务的详细信息需要S-B+-tree. 针对可连接的共有属性,建立S-B+-tree Index. 如图4(b)所示,当通过S-Bitmap Index得知链A、B可以进行Tname=X-ray连接时,通过Tname-B+-tree Index找到Tname=X-ray的叶子节点,获取到符合连接条件的事务位置信息{( A, 2, i, j+1), (A, 3, i, j+2), (B, 5, p, s)}.
4.2. SMMI维护算法
定义6 索引增量记录. 存储更新索引信息元组Increment=(attr, key, Tid, Block-id, Trans-id, S),其中attr为建立索引的属性语义名,key为属性值,Tid为事务标识,Block-id为事务所在区块号,Trans-id为块内事务号,S为所属语义区块链.
定义7 S-Inverted Index基本信息. IndexInfo=( attr_S-Inverted Index, attr, Block-id). 记录了索引的名称(attr_S-Inverted Index)、对应建立索引的属性语义名(attr)、当前已维护到的区块号(Block-id).
在维护过程中,首先须创建增量记录集. 在事务进行新一轮共识时,系统获取前一轮共识过事务的信息,创建索引增量记录(increment),该步骤复杂度为线性. 随后,将增量记录进行分组. 由于增量记录数目多、类型多样,按照更新的属性语义名(attr)分组,分别建立增量记录集(increments). 再通过获取增量记录集进行不同索引更新任务. 各个索引更新任务根据增量记录集对应的属性语义名(attr),明确维护的对应索引(attr_S-Inverted Index). 如果对应索引存在则直接将更新写入S-Inverted Index中,如不存在则建立新S-Inverted Index,再进行更新任务. 同时更新对应的S-Bitmap和S-B+-tree索引. 最后,更新索引的基本信息(IndexInfo). 至此SMMI索引维护完毕,具体步骤如算法1所示.
算法1 SMMI维护算法
输入:已共识的事务集合Tc,S-Inverted Index信息IndexInfo,S-Inverted Index集合I;
输出:无;
01. Increment←Tc //将共识事务传入增量记录
02. Increments.attr←Increment.search(attr);
03. new TaskQueue; //新建索引维护任务队列
04. Task.Index_attr←Increments.attr;
05. TaskQueue.push(Task);
06. while(!TaskQueue.empty(·));
07. TaskHead←TaskQueue.front(·);
08. TaskQueue.pop(·);
09. i←基于维护任务列属性名称TaskHead.attr在I中查找索引;
10. if(!Index_attr) new Index_attr;
11. Rows←添加增量记录集TaskHead. Increments获得新增行集;
12. update (i, Rows); //新增的行集添加到第1个索引中
13. update S-Bitmap&S-B+-tree;
14. IndexInfo←更新S-Inverted Index信息;
15. Endwhile
算法1描述了SMMI的维护过程,算法第1、2行获取共识成功事务创建增量记录,并分类存放于不同的增量记录集中. 第3行创建维护索引的任务队列. 第4、5行将增量记录集对应任务存入任务队列. 第7~9行取出任务队列的头任务,查找S-Inverted Index集合I中相应的S-Inverted Index. 第10~12行表示将增量记录集添加到对应的索引i中,进行索引维护. 第14行表示基于维护任务的信息更新S-Inverted Index信息. 算法1的时间复杂度为O(n).
5. 基于SMMI的连接查询算法
基于上一节提出的SMMI结构,提出多区块链连接查询的基准算法,并为了进一步提高查询效率提出其优化算法.
5.1. 多区块链连接查询基准算法
基准算法是在SMMI结构中只应用S-Inverted Index进行查询. 通过客户端获得查询请求Q=[attri=value,Chains],即连接Chains中attri=va-lue的所有事务. 假设attri的S-Inverted Index存在,具体算法如下.
算法2 S-Inverted Index查询算法
输入:区块链Chains,S-Inverted索引Index_attri,查询条件attri =value;
输出:满足查询条件的事务集合T.
01. listT←NULL;
02. For each BCi in Chains
03. 取list local←get(Index_attri, value). getLocation;
04. 对local中的每个事务
05. t=get(Block-id、Trans-id).getTran;
06. T.add(t);
07. return T;
第1行初始化一个对象数组,可以存储事务. 第2行开始循环Chains中每条链S-Inverted Index. 第3行对Index_attri按照attri=value进行查找,返回该行的Tid、Block-id以及Trans-id. 第4、5行按照Block-id、Trans-id获取符合条件的Tid事务,存入T中. 当循环结束,返回T即结果. 例如,当用户发出Q=[Tname=stomatology,A∪B],如图3虚线所示,在链A进行满足Tname=stomatology条件的事务查找,通过S-Inverted Index (Index_Tname)获取符合条件的事务位置,若第i块的第j+1个事务符合条件,在链A上直接获取完整事务. 在B链上执行同样过程. 算法的时间复杂度为O(n). 此方法的连接查询效率相对较低,须对连接查询算法进一步优化.
5.2. 多区块链连接查询优化算法
为了进一步优化连接查询效率,应用S-Bitmap Index和S-B+-tree Index. 首先,在S-Bitmap Index上根据查询条件,找到对应的S-Bitmap Index,通过第vth bit 为“0”或“1”判断是否可以连接,当连接的链对应位全为1时连接成立,否则不成立. 然后,在连接条件成立时,根据对应的S-B+-tree Index获取符合条件的事务信息,包含事务标识、所在块号、事务号. 以图4为例,当查询为Q=[Tname=X-ray,A∪B]时,首先通过Bitmap Index_Tname获取到“
算法3 多链关键字查询算法
输入:区块链集合Chains,查询条件attri=value,S-Bitmap_attr Index, S-B+-tree Index;
输出:满足查询条件的事务T;
01. list T←NULL;
02. if(get(S-Bitmap,value). getbit=1);
03. list local←get(S-B+-tree Index,value). getlocal;
04. 对local中的每个事务
05. t=get(Block-id、Trans-id).getTran(Chains)
06. T.add(t);
07. return T;
第1行初始化一个对象数组,可以存储事务. 第2行对S-Bitmap索引按照attri =value进行查找,返回值为value行的bit,当Chains对应位都为1时,连接成立. 否则连接不成立,停止查询. 这里的复杂度为O(m). 第3行对S-B+-tree索引l进行查找,返回符合条件事务的Tid、Block-id以及Trans-id. 第5、6行按照Block-id、Trans-id获取符合条件的Tid事务,存入T中,这里的复杂度为O(n). 当循环结束,返回结果T,整个算法的时间复杂度为O(mn).
6. 实验分析
6.1. 实验环境
本研究主要从2个方面对所提出方法进行性能评价,首先通过索引构建时间评价第4节提出的SMMI的稳定性;其次通过查询的响应时间评价索引结构与连接算法的实用性.
6.2. SMMI索引性能评估
通过3组实验测试区块链索引的性能,第1组实验,在控制区块链链数、区块数量、总数据量的情况下,对不同的属性构建SMMI索引,测量索引构建时间;第2组实验,在控制相同的区块链数情况下,按比例增加区块数和数据量,再测量SMMI的构建时间;第3组实验,控制区块链每条链的区块数量,按比例增加链和数据量,测量SMMI的构建时间.
第1组实验,应用D1将8万行数据均匀分布在2个区块链10个区块中,分别构建每条链不同属性attr的S-Inverted Index,测量构建时间t1,实验结果如表1所示. 根据算法1,在S-Inverted Index的创建过程中,对每一条数据都分别进行1次读取与写入,经实验测试建立索引的时间均约为4687 ms,证明算法具有较好的稳定性.
表 1 索引构建所需时间
Tab.1
| attr | t1/ms | t2/ms |
| 1 | 4929 | 4791 |
| 2 | 4658 | 4624 |
| 3 | 4656 | 4944 |
| 4 | 4646 | 4713 |
| 5 | 4660 | 4710 |
| 6 | 4638 | 4751 |
| 7 | 4628 | 4764 |
| 8 | 4687 | 4863 |
第2组实验在同样条件下,分别创建每条链不同属性的SMMI索引,测量所花费的时间t2,实验结果如表1所示. 根据算法1,SMMI的创建过程包含3个索引的建立,经实验测试,建立索引的时间均约为4770 ms,算法执行具有较好的稳定性. 与第1组实验对比发现,SMMI构建时间主要消耗在构建S-Inverted Index上,S-Bitmap Index和S-B+-tree Index的构建基本不消耗时间. 产生这种结果的原因是,构建S-Inverted Index须对每条区块链每个区块中的数据遍历,I/O代价大、消耗时间多;基于S-Inverted Index构建的S-Bitmap Index和S-B+-tree Index则无须读取源数据,减小了I/O代价的产生.
如图5所示为第2组实验,应用D1将不同数据量(8、16、24、32、40万行),均匀分布在2个区块链中,数据量随区块数量B增加而增加,测量创建索引所花费的时间T. 实验结果表明,随着块数的增多,SMMI的构建时间大幅增多,S-Bitmap Index和S-B+-tree Index的构建增幅较小. 原因是,随着区块数量的增多,事务增多,S-Inverted Index的构建须读取源数据,I/O代价大;基于S-Inverted Index构建S-Bitmap Index和S-B+-tree Index则无须读取源数据,通过获取S-Inverted Index直接构建索引,而S-Inverted Index中数据较小,通信代价少,因此构建时间无明显增加.
图 5
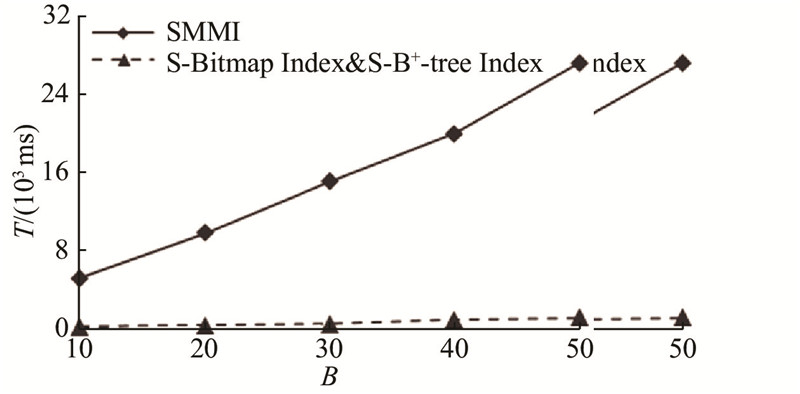
图 5 不同区块数时索引构建时间的变化
Fig.5 Time changes of index construction with different block numbers
如图6所示为第3组实验,应用D2将不同数据量(6、7、8、9、10万行)均匀分布区块中,控制每条链的区块数量,数据量随链数量C增加而增加,测量创建索引所花费的时间T. 结果与第2组实验结果相似,因为构建时间主要受到事务数量的影响,与增加事务的方式无关.
图 6
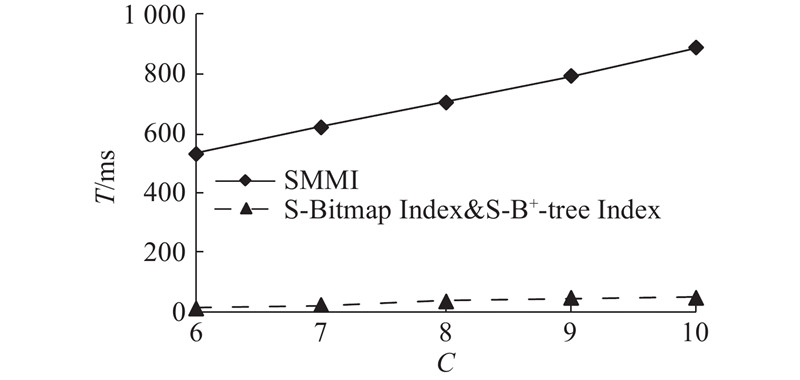
图 6 不同链数时索引构建时间的变化
Fig.6 Time changes of index construction with different number of chains
6.3. 连接查询性能评估
控制区块链大小不变,改变区块链的链数或区块链的查询结果集,在2个数据集上分别进行实验. 进行3种方法的下连接查询性能对比,包括1)无索引扫描所有区块(Scanning-S);2)基准算法,应用S-Inverted Index进行连接查询(S-Inverted Index-I);3)优化算法,应用S-Bitmap Index和S-B+-tree Index进行连接查询(S-Bitmap Index&S-B+-tree Index-B). 使用SD1、ID1、BD1、SD2、ID2、BD2分别表示3种方法在2个数据集的查询时间.
如图7所示,在D1中,控制链数不变的情况下,即总数据量不变,改变查询结果集行数R的大小,观察连接查询的时间变化. 本实验中定义连接查询为Q=[money=16.99, A∪B]. 结果表明, BD1优化查询方法性能明显优于其他2种方法. 主要原因如下:1)借助S-B+-tree Index,可以快速找到查询的事务,避免扫描整个区块链;2)利用S-Bitmap Index,只在连接条件成立下,查询事务. ID1优于SD1是因为读取的区块更少. 随着结果集数量的增加,查询响应时间增加,参与连接操作的块越来越多,磁盘读取的事务也越来越多,从而导致ID1和SD1性能下降.
图 7
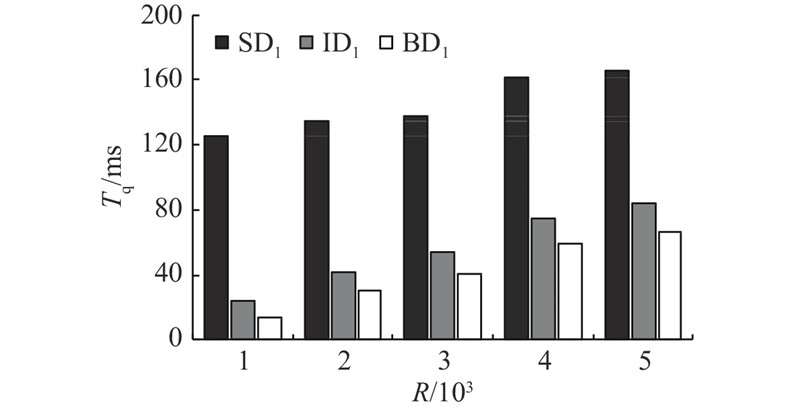
图 7 D1数据集中不同结果集的连接查询时间变化
Fig.7 Time changes of join query with different result sets in D1
如图8所示,在D2上控制链数不变,改变R的大小,测试不同结果集情况下连接查询Q=[rating=6, A∪B]的查询时间Tq. 结果同样表明, BD2优化查询方法性能明显优于其他2种方法,证明了优化方法的高效性. 但是,BD2与ID2这2个方法差别不明显. 分析发现,是数据集自身属性取值数量的不同所导致的. D2中的rating属性取值包含10个种类,而D1中money属性取值粗略计算包含上百种. 由于索引结构的特性,当查询属性的取值较少时,S-B+-tree Index和S-Inverted Index的查询性能差别较小,反之当查询属性的取值较大时,S-B+-tree Index将大幅优于S-Inverted Index的查询性能. 综上,优化算法的性能更佳.
图 8
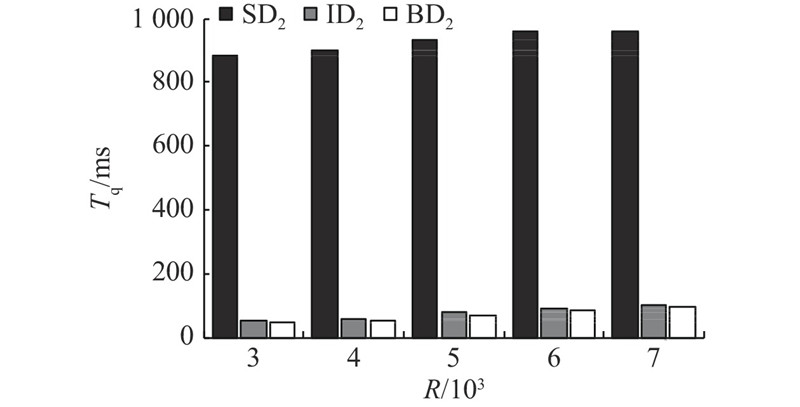
图 8 D2数据集中不同结果集的连接查询时间变化
Fig.8 Time changes of join query with different result sets in D2
为了测试不同区块链数量下的性能,固定结果大小,保持每条链的区块数量和大小不变,增加链的数量C. 如图9所示,在D1中进行查询响应时间实验,固定R=20,将链的数量从2增加到6,测试不同链数时连接查询Q=[money=16.99,A∪B
图 9
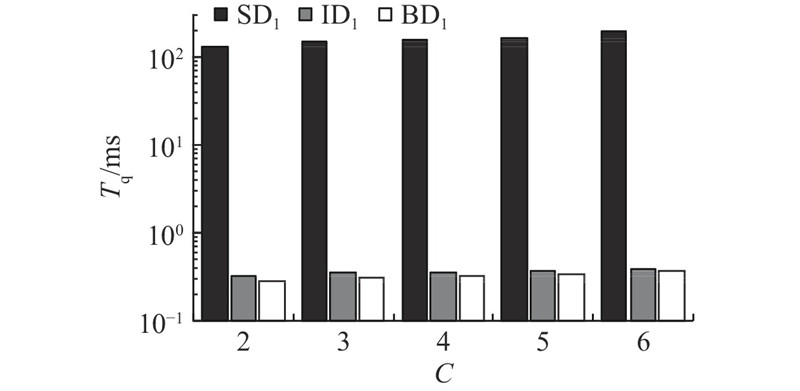
图 9 D1数据集中不同链数时连接查询时间
Fig.9 Time changes of join query with different number of chains in D1
7. 结 语
针对现有区块链系统只支持基于单链的数据查询操作,在进行多区块链间的连接查询时操作计算负载大、查询效率低的问题,提出多区块链环境下连接查询优化算法,实现多区块链快速连接查询. 基于带有语义的多区块链模型,通过多区块链间的连接索引结构,实现多条区块链进行属性连接,提高连接计算的效率,减少数据传输的通信代价. 实验结果表明,索引结构具有良好稳定性,与传统的连接查询相比效率大幅提升.
在下一步的研究中,将考虑引入连接属性的选择机制,并在保证查询结果准确性的前提下,进一步研究多区块链间并发查询策略.
参考文献
Bitcoin: a peer-to-peer electronic cash system
[J].
Ethereum: a secure decentralised generalised transaction ledger
[J].
Designing a permissioned blockchain network for the Halal industry using hyperledger fabric with multiple channels and the raft consensus mechanism
[J].DOI:10.1186/s40537-020-00387-6 [本文引用: 1]
Fine-grained, secure and efficient data provenance on blockchain systems
[J].DOI:10.14778/3329772.3329775 [本文引用: 1]
Dynamic autonomous cross consortium chain mechanism in e-Healthcare
[J].DOI:10.1109/JBHI.2019.2963437 [本文引用: 1]
Caper: a cross-application permissioned blockchain
[J].DOI:10.14778/3342263.3342275 [本文引用: 1]
Design of multimedia blockchain privacy protection system based on distributed trusted communication
[J].
区块链系统的数据存储与查询技术综述
[J].
Survey of data storage and query techniques in Blockchain systems
[J].
Renovating blockchain with distributed databases: an open source system
[J].DOI:10.1016/j.future.2018.07.042 [本文引用: 1]
区块链跨链技术进展研究
[J].
Research on the progress in cross-chain technology of blockchains
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}