

在数字化的时代下,丰富的数据资源已经对AI数据驱动的热点技术的发展和应用产生了巨大的影响[1],同时也推进了AI与数据库系统结合的研究. 在众多的数据库操作中,查询是最基础也是最广泛被应用的操作,而查询的效率严重影响着用户使用系统的体验,因此查询优化技术一直是研究者所关注的研究热点.
在数据库系统的查询处理过程中,对于给定的查询,通常采用优化技术获得优化后的执行策略,之后再完成查询操作. 在保证和原查询语句的执行结果相同的情况下,数据库选择更高效率的执行计划,以提高查询效率. 然而,真实的查询代价是在查询执行后才能知道的,因此,数据库系统须准确预估查询的代价(cost),之后基于预估代价选择优化的执行策略. 在数据库系统中,通常以最小化I/O代价为查询优化的核心目标. 基数(cardinality)是指查询执行得到的结果的行数,通常被视为代价估计的重要参数. 同样,本研究也基于查询结果的基数来评估查询代价,并基于此构建多表连接排序的优化模型.
传统的数据库优化器主要基于统计学的原理预测查询的基数,不能总是提供高质量的估计结果. 它们可能不能有效地捕捉多个表之间的相关性,同时在表的数量增加时,估计误差的扩大会越来越明显,最终导致无法准确估计计划的代价. 使用基于包括动态规划、贪婪算法、启发式算法等静态方法的传统数据库优化器会有计算时间开销过大、不能保证计划质量的不足.
AI能够从历史数据和行为中学习和推理出更好优化方案,为数据库优化技术带来了新的机遇[2]. 例如深度学习技术可以高效地学习关系表数据、 查询条件和连接条件之间的关系. 目前,学者们对于基数估计优化和连接排序优化提出了多种模型,都在一定程度上提高了查询的效率. 但是已有的工作均须把模型嵌入数据库,且没有把基数估计和连接排序的学习方法有机地结合起来.
数据库中有显式的连接顺序控制参数,本研究关注数据库外挂的基数估计方法和连接排序方法,之后将优化后的查询返回给数据库系统,无须将模型嵌入到数据库中.
本研究结合AI技术使用基数估计模型与连接排序优化模型来提高查询的执行效率. 训练基数估计模型通常需要大量的训练数据,并最终将基数估计结果提供给连接排序优化使用,当训练数据不足时存在冷启动问题. 为了解决上述问题,本研究面向数据库中的所有表,基于表间主外键关系构建表关联图;基于表的关联图,以子关联图为模型单位,基于查询获得训练集并学习多模型的基数估计模型;基于多模型基数估计值,使用代价模型估计出查询代价;将查询代价估计值作为下一步连接排序优化的反馈进行强化学习;最终得到良好的查询执行策略.
本研究的主要贡献如下:1)提出基于多模型的基数估计方法(multiple cardinality estimation method based on multi-model, MCM). 提出表的关联图的概念,并为每个表的关联图(统称子关联图)建立基数估计模型,在数据库外基于查询构建训练数据集并完成模型,能为查询提高较为精准的基数估计值. 2)提出基于强化学习的连接排序优化方法,基于查询代价模型得到学习的反馈,最终学习到良好的多表连接顺序. 3)通过实验证明本研究提出的方法在不嵌入数据库的情况下的优化效果.
1. 相关工作
与本研究工作密切相关的基于代价的查询优化技术,主要包括基数估计优化和连接排序优化2部分. Durand等[3]提出的 LogLog和Flajolet等[4]提出的 HyperLogLog,是基于非机器学习方法遍历数据库中的所有行,并对应到哈希位图上,然后根据哈希位图上的 0和 1的连续次数来推断出基数;Wu等[5]基于历史查询记录采用泊松回归模型学习基数. 近年来深度学习模型逐渐被用于基数估计,例如,Lakshmi等[6]率先把全连接神经网络运用到数据库系统上,核心思想是基于基数估计准确优化谓词的顺序,从而提高查询的执行效率;Dutt等[7]使用标准的全连接神经网络,并以 ReLu 作为隐藏神经元的激活函数,将查询和查询得到的真实选择率直接向量化,输入到神经网络中,训练获得预测选择率的模型;Hasan等[8]提出将选择率估计制定为一个有监督的深度学习问题,采用全连接神经网络,从查询日志中获得训练集,预测给定查询的选择率. 另外,还有基于卷积网络模型和长短期记忆网络(long short term memory, LSTM)模型的方法,例如,Kipf等[9]使用多集卷积的网络(multi-set convolutional network, MSCN)的深度学习方式来估计基数,该方法基于抽样估计捕获连接交叉的相关性;Sun等[10]基于 LSTM 模型进行基数估计,核心思想是把查询看作一棵树,每个树节点都是查询的一个子操作,把每个子操作涉及的元数据信息、谓词信息作为嵌入输入,输出结果为下一个 LSTM 的一个输入,最终估计查询的基数.
在机器学习技术应用到数据库之前,连接排序优化一般使用动态规划或启发式算法之类的静态方式计算. Seling等[11]开创性地提出了经典的动态规划的方式,通过连接的关系的数量来组织动态规划. 之后,数据库的设计和实现都广泛运用该动态规划方法或其变体来进行连接排序优化,但是这种算法为了简化搜索空间只考虑了左深(left-deep)树而没有考虑浓密(bushy)树. 例如,Vance等[12]提出基于快速子集枚举的策略减少搜索空间;Waas等[13]提出 Quickpick 算法,将随机生成的连接谓词序列映射到查询计划,利用自底向上的查询计划构造方法,在部分计划计算的成本超过目前发现的最佳成本时立即丢弃它们;Neumann等[14]提出贪婪的启发式方法来简化动态规划的连接顺序搜索过程,如果一个查询太复杂而无法精确优化,须使用贪婪的启发式方法简化它,直到它变得易于使用动态规划. 近年来,机器学习逐渐被用到连接排序优化中,例如,Krishnan等[15]认为连接排序与强化学习有较强的联系,把连接顺序视为一个马尔科夫过程,对查询图使用 one-hot 编码,然后以数据库执行的性能变化(执行延迟或者吞吐量)作为反馈来训练模型;Marcus等[16]应用基于策略的强化学习方法,先将查询树编码,然后在神经网络中获得策略,以数据库优化器的代价模型提供的查询代价为反馈来训练模型;Trummer等[17]应用强化学习设计可靠的连接顺序的查询引擎,而且无须维护数据统计信息,也不使用成本或基数模型,他们把查询的执行分为不同的时间片,在不同的时间片中尝试不同的连接顺序.
与已有的工作相比,本研究侧重将基数估计与连接排序优化策略结合,在数据库外完成优化过程,在避免对数据库修改的同时拥有良好的优化效果.
2. 基于代价的查询优化框架
2.1. 传统数据库系统的查询流程
查询被输入到数据库中,在查询执行之前须经过3个重要的过程即查询解析、查询重写和查询优化.
如图1所示为查询的处理过程示意图. 查询解析是将结构查询语言(structured query language, SQL)语句解析为语法树;查询重写是基于规则的重写方式,将语法树中冗余的部分去掉,重写成等价的查询语句;查询优化包括选择索引、代价估计和选择最优的查询计划等过程,数据库中有内置的基数估计、成本模型组件.
图 1
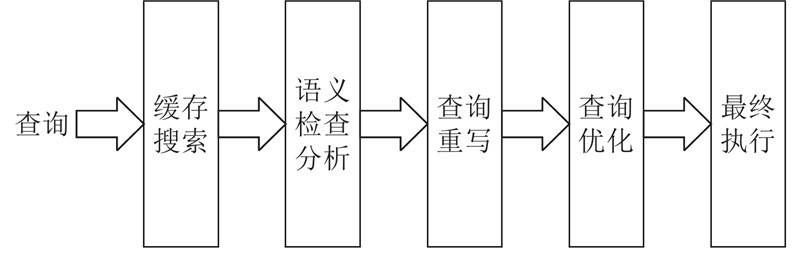
传统的数据库(如postgresql数据库)一般使用直方图方式来描述数据分布,依据直方图将数据值范围划分为频率相同的桶. 数据库优化器根据查询谓词的过滤条件,找到查询的谓词的值所在的桶位置,假定每个桶中的数据是简单线性假设关系,根据谓词操作符计算出查询的基数的估计值.
在存在多表连接查询时,数据库会假设各表独立,直接进行简单计算得到基数估计值;根据基数估计值和内置的成本计算组件来预估查询执行的代价数值(可以理解为查询执行的时间或IO的代价);数据库优化器在众多连接计划中选择代价最低的一个作为最终的执行计划,选择方法主要包括穷举法和启发式方法.
2.2. 基于代价的学习式查询优化框架
主要面向查询优化中的基数估计和连接顺序优化展开研究,针对典型的SPJ(select-project-join)查询. 在基数估计部分,基于子关联图,应用神经网络构建相应的基数估计模型;根据多个子关联图学习连接的数据分布情况;使用强化学习的方法通过不断“试错”获得良好的连接顺序. 本研究通过联合学习基数估计和连接顺序,在数据库外将查询语句优化,架构如图2所示.
图 2
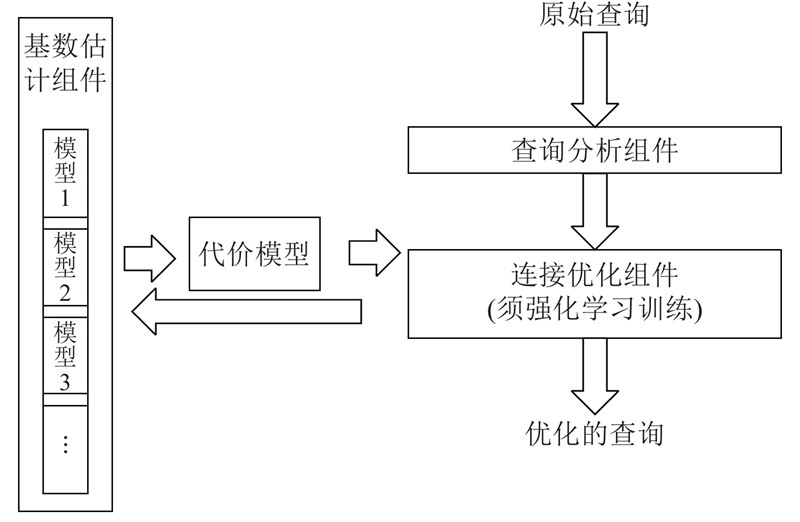
以postgresql数据库为例,其代价模型考虑了部分相关索引、元组大小条件,是一个极其复杂的组件. 但是研究[18]表明,简单的代价模型就可以反映出查询的代价,而且代价模型的误差相比于基数估计误差对数据库系统查询的影响微乎其微. 本研究采用简单的函数作为代价模型,以提高优化模型的学习效率.
结合神经网络和强化学习来解决查询优化问题,通过结合AI技术的方式来解决查询优化问题. 预先建立起多个神经网络,为不同的子关联图连接建立不同的估计模型,并完成多个模型的训练.
如图2 所示,在查询过程中,在原始查询进入后,通过查询分析组件进行语法检查分析,获得须连接的表和涉及到的谓词;由连接优化组件选择新的连接,通过基数估计组件和代价模型计算连接的代价,再将代价返回给连接优化组件;连接优化组件以此为反馈进行强化学习,基于得到的特定模式下的连接经验,最后获得良好的连接顺序即优化的查询执行策略.
3. 多模型的基数估计
查询的基数估计的前提是优化器须知道数据库中数据的分布情况,而数据库中使用直方图统计数据分布. 默认数据库中的各个列都是无关并且均匀分布的. 因此,当查询涉及的表多于1个时,数据库自身优化器获得的查询基数估计值会偏离实际值.
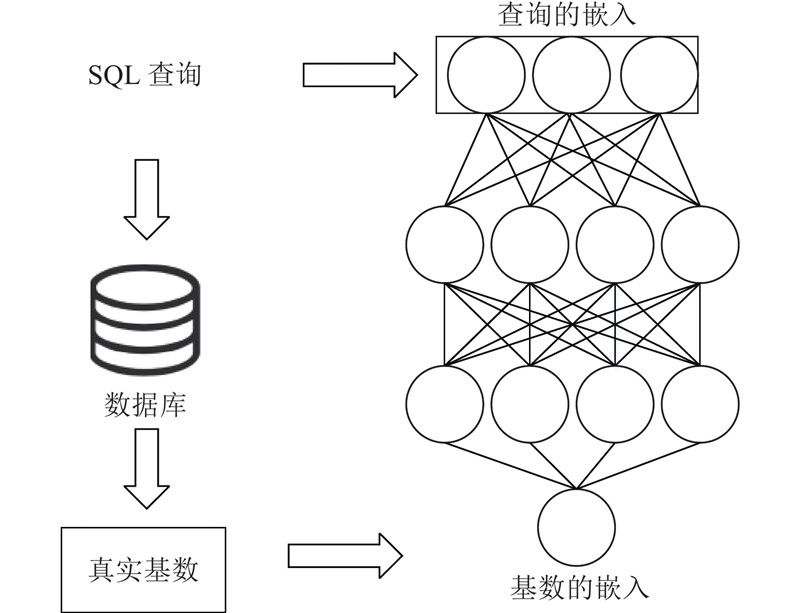
3.1. 已有的基于神经网络的基数估计
图 3
3.2. 多模型基数估计方法的架构
已有的基数估计研究存在如下局限性:1)通常将基数估计作为孤立的问题,没有考虑基数估计模型与其他的优化组件模型相结合,例如基数估计与连接排序优化相关组件的结合;2)基数估计模型一般作为特定数据库的全局模型(global cardinality estimation model ,GCM)来研究,由于涉及复杂的查询,需要更为丰富的训练集才能达到令人满意的训练效果;3)全局模型的可扩展性差,数据库的模式改变后须重新训练模型. 基于以上问题,以子关联图为模型单位,分别构建相应的基数估计模型,单独训练,将大大缩小训练集的大小,在同等预测准确程度下会减少训练集的规模,同时也支持数据库模式改变的扩展.
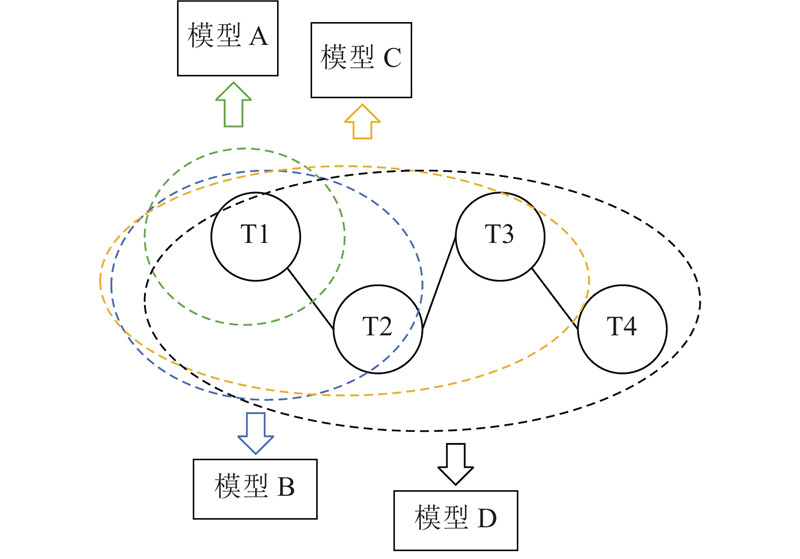
在多模型的基数估计方法中,数据库中存在若干个表,基于表的主外键关系构成表关联图. 从表关联图中抽取出单表、两表、多表连通的多类型的子关联图,基于不同的子关联图建立不同的模型. 例如,如图4所示为数据库中有4个表和4个连接关系的样例,T1和T2、T2与T3、T3与T4均有连接关系,且它们的连接关系满足结合律. 图中,被椭圆形所标识的是以T1、T2、T3和T4为整体的4个子关联图,分别包含1、2、3、4个表,每个子关联图都对应一个基数估计模型.
图 4
在训练之前须将大量的查询编码为向量. 多模型的基数估计方法(MCM)不同于以往将全局模式作为一个模型(即GCM)的方法. 如图5所示为涉及表T2与T3的查询基于全局模型(GCM)的编码方式和多模型方法(MCM)的查询编码方式,不失一般性,本研究默认谓词操作都为大于等于.
图 5

GCM方法适用于数据库中的所有查询,所以须记录被编码的查询的表的使用情况. 一般使用one-hot向量表示表信息,其中0代表未使用该表,1表示使用了该表. 在过滤谓词部分,未使用到的谓词使用0表示,使用到的谓词根据查询中的值和数据库中该列的最大值与最小值将其规格化为0~1.0的数字,如某列中的最小值是0最大值是100且过滤谓词的值为10则编码为0.1.
在MCM方法中直接将2个谓词的值编码,与GCM中类似,规格化为0~1.0的数字,减小了表的维度从而减小了向量的长度. 在MCM方法中,由于建立了多个模型,须对这些模型进行索引管理,使得给定的查询能快速找到相应的基数估计模型. 为此,本研究为数据库中的表标注序号并构建模型空间M.
定义1 模型空间M. 模型空间M定义为{<key, model>}. 其中,key由子关联图中的表计算生成. 该方法为数据库模式中的每个表标注序号,按照子关联图含有的序号计算key,如选取1号表和2号表的子关联图的key为2的0次方加上2的1次方即为3. model为key对应的基数估计模型. 在每个子关联图对应的模型训练好后,根据表生成特定的key,然后将<key, model>加入到空间M中.
算法1表述了一个模式的模型下的基数估计的流程,如下所示.
算法1 查询估计基数
输入:查询语句s,无过滤时查询的总行数total
输出:基数k
1. M← set of <key, model>
2. key←initialize key=0
3. analyse to tableset and predicts
4. for table in tableset:
5. key←key+(tableNo−1)2
6. end for
7. model←M(key)
8. p←model(predicts)
9. k←total×p
在算法1中,total 为去掉过滤条件的查询的基数,tableset 为查询涉及的表的集合,predicts 为查询使用的谓词集合. 第1、2行为初始化key和分析查询语句得到查询涉及到的表和谓词值. 第4~7行为根据查询中的表的信息,按位计算相应的key,并根据key找到对应的基数估计模型. 第8、9行将查询中的谓词按照MCM的方式编码后,输入到模型中,得到查询的选择率p,再将p乘以对应无过滤谓词的查询的总行数得到基数值.
如果向数据库中添加一个表T5,且T5只与T4有连接关系. 在这种情况下,数据库中增加了5个子关联图,须再向模型空间中添加5个模型. 对比GCM方法,MCM方法只是在模型数量上有所增多,仅须对新增加的子关联图进行单独训练,若数据没有变化,无须重新训练已有模型. 可见,MCM方法具有扩展性.
在执行查询之前,模型空间中的各个模型已经训练完毕,在进行连接排序优化时可以直接使用,解决了冷启动的问题. 在后续面向特定模型训练或升级过程中,这些模型可以作为先验知识,有助于提高特定模型训练效率和准确性.
4. 基于强化学习的连接排序优化
查询中的连接排序是一个NP难题. 连接排序优化是指在查询计划空间中寻找最优的查询计划,这个过程可以看作是每次选择一个新连接的马尔科夫决策过程. 在马尔科夫决策过程中,主体每次选择一个新行动ai+1,这个新行动的选择只取决于当前的状态si. 在新行动选择后状态会根据行动的影响转移到新状态si+1. 连接排序优化的定义如下.
定义2 连接排序优化. 设 n为查询涉及到的表的数量, C为数据库的代价模型,连接排序优化的目的是找到一个连接执行的序列a1,a2
式中:代价模型C(at)为对行动at的代价计算,在数据库中由代价估计的组件估算;at(st)表示行动at作用于状态st.
强化学习算法可以应用于数据库优化,强化学习中的智能体须得到环境的反馈,查询优化中的反馈一般来自于数据库的实际执行效果或者数据库的代价模型. 这种情况会带来一些缺点:一方面,实际执行新的查询会导致强化学习的训练代价更大;另一方面,数据库组件的基数估计值存在前提假设,导致代价估计不准确.
基于以上考虑,本研究使用Cmm[18]代价模型,以查询的基数为输入进行查询代价的估计. 然后使用q-learning的强化学习算法对指定的查询确定表的连接排序,其中反馈来自于Cmm代价模型. Cmm代价模型通过不同的连接操作,以查询以及子查询的基数值为输入,计算查询执行期间操作的元组数量,可以较为准确地预测查询的运行时间.
已经被连接的表表示状态,初始状态s0是一个表,行动a是选择一个表进行连接. 在只考虑左深树的连接情况下使用多模型基数估计方法的连接排序优化算法如下所示.
算法2 连接排序优化算法
输入:查询语句s,规定值r,折扣率g,代价估计函数C,学习速率α
输出:优化后的查询语句s′
1. analyse s to tableset and predicts
2. len←len(tableset)
3. Q←initialize matrix(2len, len)
4. while Q is not restrained:
5. tableA←random table in tableset
6. jT←tables have been joined //已经连接的表的集合
7. jT.apeend(tableA)
8. Q[0][tableA] ←−C(jT)
9. while len(jT) != len:
10. x←random float in (0,1)
11. nT←next joined table //下一个被连接的表
12. if x>r:
13. nT←random next table
14. else:
15. nT←table of min C(jT+table)
16. end if
17. newjT = jT.append(nT)
18. reward = C(jT)−C(newjT)
19. if jT is not in tableset:
20. update Q by reward,r, α and g
21. end if
22. jT = newjT
23. end while
24. end while
25. for table in tableset:
26. jT←[table]
27. while jT not include all tables in tableset:
28. jTNo←analyse jT //jT的序号
29. choose nT to satisfy max Q[jTNo]
30. jT.append[nT]
31. end while
32. max jt = max (jT, maxjT)
33. end for
34. s′ ←analyse maxjT
算法第1~3行是分析查询语句的表和初始化经验表Q. len是查询中的表的数量,最多含有len2种表示已经连接的情况,最多有len种下一步连接的选择,因此,初始化Q为matrix(2len, len). 第4~24行是对于经验Q的训练过程,训练若干轮直到经验Q收敛. 其中,在每一轮训练中,随机选取一个初始状态. 然后生成一个随机数,若随机数大于规定值r则随机选取另一个表连接,否则使用当前代价最小的行动. 每一次选择行动,都会基于MCM方法和代价模型进行代价估计(函数C),并用该代价作为强化学习的反馈. 该算法使用Q表记录不同的初始状态的初始代价. 第25~33行是利用已经训练好的经验Q来进行连接操作,从不同的初始状态中选择代价最小的连接方式. 在该算法中,由于代价越小越优,使用代价的负值进行计算作为学习的奖励. 该算法中Q的更新方式为
式中:re为每次新的表进行连接时的奖励,通过代价模型和基数估计值计算得来;s为已经连接的状态;a为要连接的新表;α为对于以往训练效果的保留程度;g为对以往的经验的保留程度. 本研究中α=1.0,g=0.8.
5. 实验分析与结果
5.1. 实验设置与数据集
本研究所提出的算法对有数字型的列的表有优化效果,因此选择有数字型值的列较多的TPC-H数据集为实验测试集. 在实验中使用postgreSQL数据库进行测试. TPC-H为事务处理性能委员会(transaction processing performance council )制定的基准程序之一,可以测试数据库查询性能. 如表1所示为本次实验使用的TPC-H数据集基本信息.
本实验测试基数估计的准确程度和训练集的密集程度的影响,以及进行查询优化前、后的执行效率比较. 实验环境如下. CPU:i7-8700;操作系统:windows 10;算法实现:Pytorch,python 3.7.
表 1 基数估计与连接优化实验的表
Tab.1
| 表名 | 行数 | 可连接的表的序号 | 序号 |
| lineitem | 6001215 | ②, ⑥ | ① |
| orders | 1500000 | ①, ③ | ② |
| customer | 150000 | ②, ④ | ③ |
| nation | 25 | ③, ⑧ | ④ |
| Supplier | 10000 | ⑥ | ⑤ |
| partsupp | 800000 | ⑤, ⑦ | ⑥ |
| part | 200000 | ⑥ | ⑦ |
| region | 5 | ④ | ⑧ |
5.2. 实验分析
1)MCM的有效性分析. 首先验证基数估计的有效性. 针对关联图中每个表的数值型属性列,按属性值生成训练集. 在实验中,对每个子关联图的每个表随机生成10个查询,分别查询数据库估计的基数和获得模型预测的基数,两者分别与实际的基数做差的绝对值,取平均数. 如表2所示为多模型估计方法中4个表可以形成的7个子关联图的估计效果. 使用数据库默认的连接顺序执行explain语句得到数据库的估计值. Pgsql的偏差值是数据库的估计的基数值和真实基数的偏差. 在TPC-H数据集上,MCM预测的基数值比数据库预测的更为准确. 实验证明了多模型算法的有效性.
表 2 基数估计值准确度对比
Tab.2
| 关联图包含的表 | Pgsql偏差值 | MCM偏差值 | 比率 |
| 表① | 29049 | 27207 | 1.06 |
| 表② | 3583 | 3253 | 1.10 |
| 表①, ② | 315276 | 95562 | 3.30 |
| 表①, ⑥ | 1031819 | 181906 | 5.70 |
| 表①, ②, ⑥ | 1513111 | 172456 | 8.80 |
| 表①, ②, ③ | 1724555 | 203435 | 8.50 |
| 表①, ②, ③, ⑥ | 2323443 | 249033 | 9.30 |
在查询涉及多个表的时候,数据库的基数估计值与MCM基数估计值的比率均超过3. 在查询只涉及1个表的时候,使用模型的基数估计值与数据库的基数估计值相当. 这是因为数据库的基数估计的局限性(假设数据独立和均匀分布)会随着表的连接个数的增长而扩大,而多模型基数估计方法相较于数据库更能捕捉到数据分布特点.
2)训练集大小对预测准确度的影响. 如图6所示为以2个表为一个数据库整体的情况下训练集大小对于基数估计的影响情况. 如图6(a)、(b)所示,分别以表①、②和表①、⑥作为数据库整体模式. 如图7所示为以4个表为一个整体的基数估计情况,图7(a)、(b)分别以表①、②、③、⑥和表①、②、③、④作为数据库全局模式. 图中,Δ为实际基数与估计基数的偏差值,N为训练集大小. 实验结果显示随着训练集大小的变化,基于GCM的基数估计方法和MCM的基数估计方法的基数估计值的偏差程度. 其中,基于GCM 的基数估计方法的训练集数是指支持全局模型训练的所有训练集;而在基于MCM的基数估计方法中,其训练集包含各个子关联图的训练集.
图 6
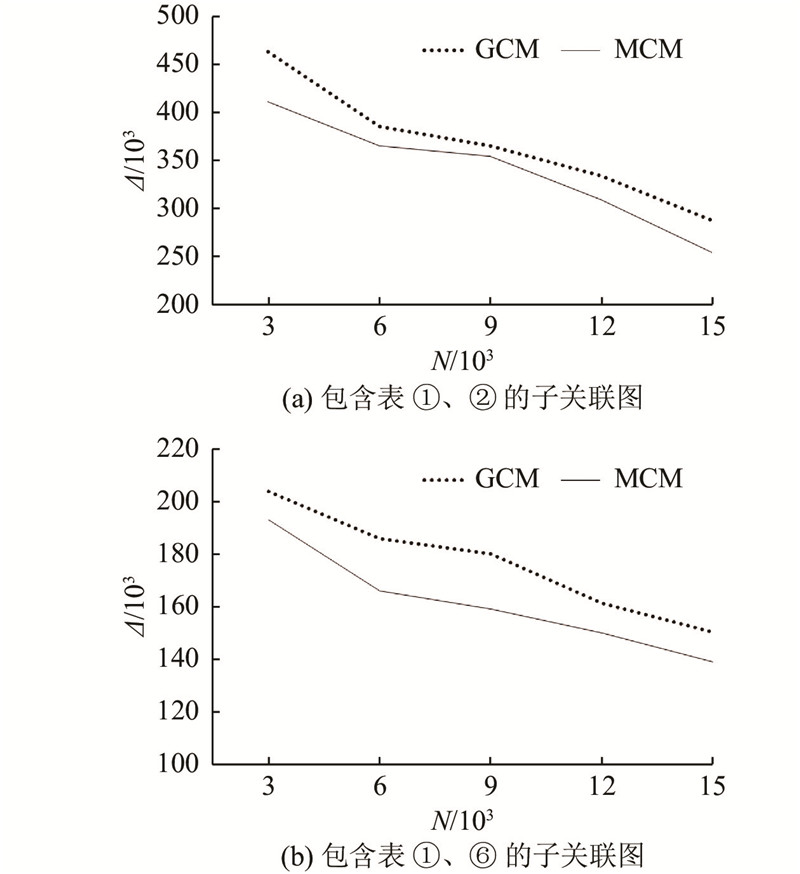
图 6 2个表的情况下训练集对基数估计的影响
Fig.6 Effect of training set on cardinality estimation in case of two tables
图 7
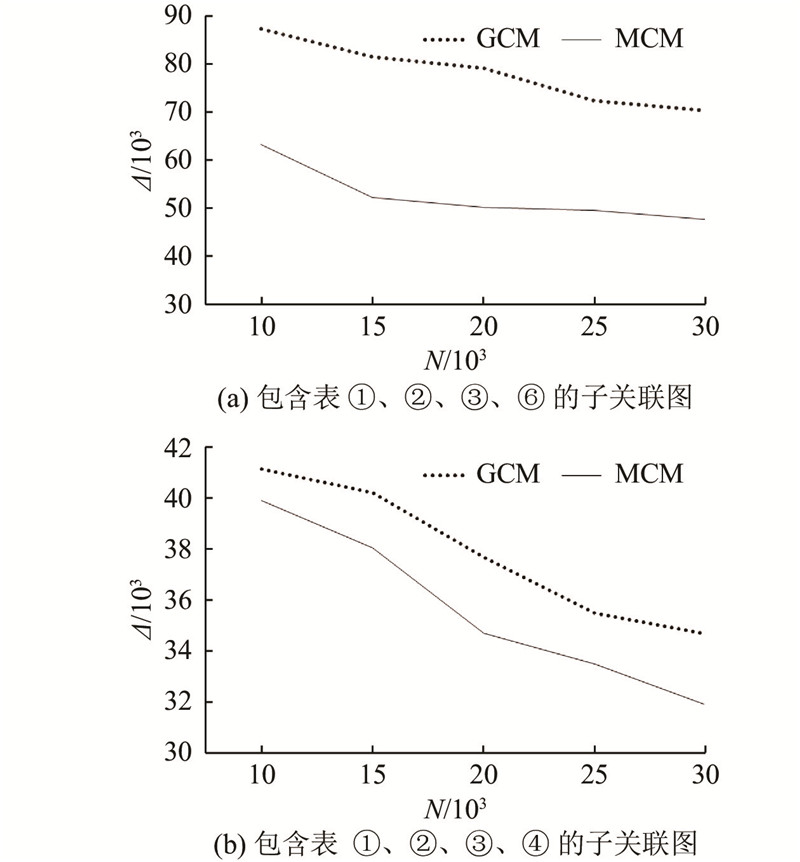
图 7 4个表的情况下训练集对基数估计的影响
Fig.7 Effect of training set on cardinality estimation in case of four tables
结果表明,在达到相同偏差值时,MCM所需要的训练集更少. 同时MCM可以更方便地扩展新的表,模型空间中的模型可以被重用. 而GCM基数估计方法只能重新训练模型并需要更大的训练集.
3)查询优化效果分析. 在postgresql数据库中,使用者可以在一定程度上用显式JOIN语法控制查询规划器. 在将postgresql运行时参数join_collapse_limit设置为 1后,规划器会被强制遵循显式JOIN的连接顺序. 基于这条规则,使用强化学习方法将含有多个表的查询语句改写为优化后的连接排序而不规定具体的连接操作,具体连接的操作由数据库决定. 然后使数据库固定执行优化后的查询语句.
在以表①、②、③、④、⑥(模式1)和表①、②、③、⑤、⑥(模式2)分别作为数据库全局模式的基础上,分别以3、4、5个表作为一个整体各随机取一组查询,每组查询分别在未优化的形式上和优化的形式上进行执行. 取执行时间的平均值. 如表3所示为未优化与优化后的查询效率对比. 表中,tu、to分别为未优化、优化后执行时间. 可以看出,在3个表连接上的执行效率区别不大,在4个表连接和5个表连接上,本研究所提出的优化方式的执行效率更好. 同时也证明了多模型基数估计方法在查询优化上的有效性. 此外,本研究的方法在连接排序中,使用基数估计模型预测基数计算查询代价,并将其作为反馈,与执行查询得到执行时间的反馈的方法相比,训练时间大大减少.
表 3 未优化与优化后的查询执行效率对比
Tab.3
| 实验设置 | tu/s | to/s |
| 模式1-3joins | 35.1 | 34.3 |
| 模式1-4joins | 95.5 | 75.4 |
| 模式1-5joins | 105.7 | 92.0 |
| 模式2-3joins | 41.1 | 38.3 |
| 模式2-4joins | 100.2 | 88.6 |
| 模式2-5joins | 111.0 | 99.8 |
6. 结 语
提出在数据库外结合神经网络与强化学习的查询优化学习方法. 该方法面向子关联图构建基数估计模型集,通过查询构建训练数据集,并在数据库系统外完成模型训练,模型具有较好的性能,不存在冷启动问题,且模型构建灵活,可扩展性好,尤其适应于分析性任务的查询优化. 另外,通过结合基数估计与连接优化,学习查询优化模型,有效提高了查询优化性能.
本研究方法还存在一定的局限性. 在表的数量增长下,基数估计所需的训练集的数量的增长速度会越来越快,生成训练的代价会更大,下一步将尝试用聚类子关联图来减少模型的数量和模型训练的代价,并寻找更好的基数估计方法以减少模型的训练代价. 本研究主要探究了左深树的查询优化形式,减少了搜索空间但是可能会忽略更优的连接方式,下一步将考虑浓密树的优化形式. 另外,本研究工作也将延伸探索数据库外优化和数据库内优化的性能对比.
参考文献
Big data: a revolution that will transform how we live, work, and think
[J].
基于机器学习的数据库技术综述
[J].
A survey of machine learning based database techniques
[J].
Towards a learning optimizer for shared clouds
[J].DOI:10.14778/3291264.3291267 [本文引用: 1]
Selectivity estimation for range predicates using lightweight models
[J].DOI:10.14778/3329772.3329780 [本文引用: 1]
An end-to-end learning-based cost estimator
[J].DOI:10.14778/3368289.3368296 [本文引用: 2]
How good are query optimizers, really?
[J].DOI:10.14778/2850583.2850594 [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}