

病毒或病菌(如COVID-19、Ebola、SARS等)的传播是包括人类在内的各类生物无法避免且必须面对的问题. 如果一个正常对象在一段连续时间内与携带病毒或病菌的传染源近距离接触,很可能导致传染事件的发生. 可见,病毒或病菌在对象间的传播与其行动轨迹具有一定的相关性. 同时,传染事件的发生具有传递性,这也使各种传染性病毒或病菌往往具有指数性传播的特点[4]. 对于病毒或病菌的传播模式的研究可以帮助人们了解传播路径、区域和速度等重要信息,进而有助于人们开展及时和准确的检查、隔离、治疗等措施.
近年来,基于轨迹数据的模式挖掘已经被广泛研究. Laube[5]等提出Flock[6]模式,但该模式只考虑移动对象在单一时刻的行为特征. 随后Jeung等[7]提出Convoy[8-9]模式,要求移动对象在连续k个时间戳内一起移动,这种严格的时间限制在现实世界中并不适用. Li等[10]提出更为通用的Swarm[11]模式,该模式旨在挖掘至少在k个(可以不连续的)时间戳内一起移动的对象簇. 此外,Traveling Companion模式[12]、Gathering模式[13-14]以及Loose Travelling Companion模式[15]都专注于从轨迹数据中发现共同移动的对象簇. 与现在广泛挖掘的轨迹模式不同,基于移动对象的传染模式是新的问题,目前还没有被广泛研究过. 当前,仅有文献[16]给出了基于轨迹数据的严格型传染事件模式定义,若在一个给定大小的时间窗口W内,对象o与传染源s连续近距离接触(即在该时间窗口W内的所有采样时间点上,o与s的距离都小于给定的传染距离阈值),判定对象o被s传染. 同时,文献[16]也给出了挖掘严格型传染事件的查询方案IMO. 不过,IMO中使用的传染事件的定义过于严格,在实际场景中,o与s可能并没有连续近距离接触,只是在一段时间内近距离接触的密度较高,在这种情况下,o同样可能被s感染,对于此类潜在的传染事件,IMO无法发现. 因此,须定义更加符合实际的传染事件模型,并设计相应的模式挖掘算法,以解决IMO方案中存在的问题.
本研究提出面向移动对象的松散型传染模式挖掘算法. 给出松散型传染事件的模式定义;提出基于滑动窗口的传染模式挖掘算法——松散型传染模式挖掘算法(loose infection pattern mining algorithm, LIPMA),对每一个待检测对象进行分析处理,进而挖掘所有传染事件;为了进一步提高挖掘效率,提出基于R-tree的优化挖掘算法LIPMA+,该优化算法在每一轮的处理过程中,只针对满足传染事件距离阈值要求的潜在感染对象进行处理.
1. 问题描述
以图1为例对传染事件的发生条件进行阐述. 图中,虚线表示移动对象未感染时的运动轨迹,实线表示移动对象被感染后的运动轨迹.
图 1
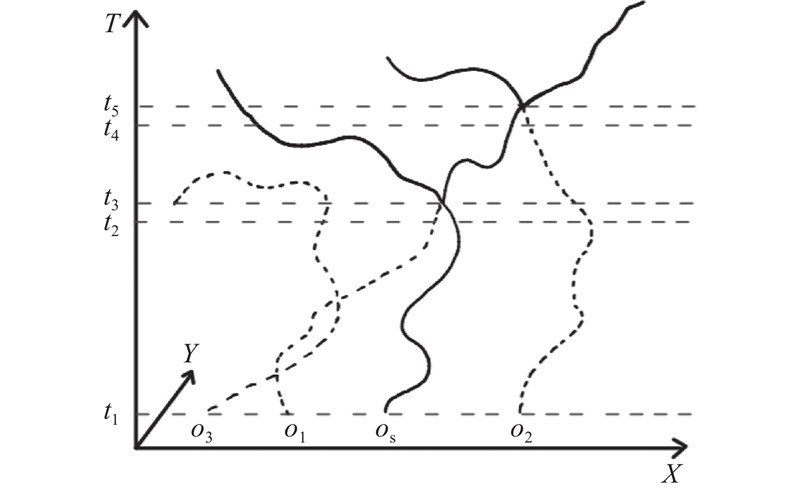
假设os为携带病毒的初始传染源,在t2~t3时刻,由于对象o1和os发生近距离接触,o1被传染;虽然o2和os之间没有直接的近距离接触,但o2在t4~t5时刻与o1有近距离接触,而此时的o1已被传染,导致o2也被传染.
任意移动对象的轨迹数据均为依赖时间的函数模型. 该模型由多个时间间隔和在这个时间间隔内的线性运动来描述. 令O = {o1, o2, ···, on}表示所有移动对象的集合,给出如下定义.
定义1 轨迹(trajectory). 对于任意oi∈O,oi的轨迹是一组时空数据序列,记为trai=
定义2 滑动窗口(sliding window). 在给定滑动窗口宽度阈值τ的情况下,滑动窗口Wi由τ个连续的采样时间点序列构成,Wi = {ti, ti+1
定义3 松散型传染事件(loose infection event). 三元组e=(source, object, ts)表示传染对象object在ts时刻被传染源source传染。若存在一个滑动窗口Wi
式中:d为传染距离阈值,δ为传染敏感度阈值,Dist (source,object,t)表示对象source和object在t时刻的欧氏距离.
由定义3可知,在宽度为τ的滑动窗口Wi中,当对象object和传染源source之间的距离不大于阈值d的采样时间点个数与τ的比例不低于δ时,表明object在滑动窗口Wi的结束时间点
通过示例对松散型传染事件的定义做进一步说明. 如图2所示,假设距离阈值d=10,滑动窗口宽度阈值τ=10,敏感度阈值δ=0.8,source为传染源,object为检测对象. 在阴影矩形区域表示的滑动窗口中,存在8个采样时间点(object轨迹中空心的点),使得object和source之间的距离不大于d,此时,根据定义3即可以判定(souce,object, 11)为已发生的松散型传染事件,表示对象object在时间点11被source传染.
图 2
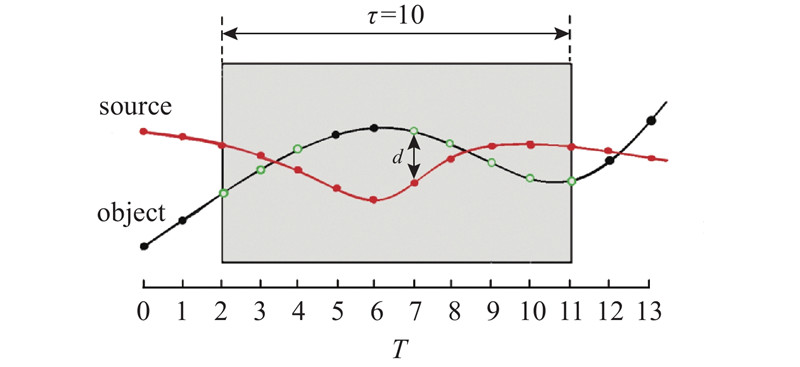
本研究的研究目标就是要根据给定移动对象的轨迹数据以及初始传染源,挖掘导致各对象被传染的最早发生的所有松散型传染事件,以及时、准确发现所有的被传染对象及其对应的被传染时间.
2. 面向移动对象的传染模式挖掘
2.1. 基于滑动窗口的传染模式挖掘算法
给出针对松散型传染事件(下文简称为“传染事件”)的松散型传染模式挖掘算法LIPMA. 该算法首先将初始传染源对象集合Os按照传染模式三元组e=(source, object, ts)的形式加入待处理的候选传染事件集合Cand;然后按照传染事件发生的时间先后顺序,依次对Cand中每一个确定的传染事件e的被传染对象objecte进行传染模式挖掘分析,并将结果存入临时传染事件集合Temp,同时将e移入传染事件结果集R;在此基础上,根据Temp对Cand进行更新. 直到Cand为空,R即为最终的传染事件结果集. 具体过程如算法1所示.
算法1:LIPMA(Tra, Os, τ, d, δ)
输入:轨迹数据集Tra,初始传染源对象集合Os,滑动窗口宽度阈值τ,距离阈值d,敏感度阈值δ
输出:传染事件结果集R
1. 初始化传染事件结果集R=Ø,待处理的候选传染事件集合Cand=Ø,临时传染事件集合Temp=Ø,待检测对象的集合O'=O − Os;
2. FOR EACH oi∈OsDO
3. 构造初始传染事件e = (Ø, oi, t1),并加入Cand;
4. END FOR
5. WHILE Cand
6. 将Cand中最早发生的传染事件e移入R;
7. Temp =SWAnalyze (Tra, τ,d, δ, objecte, tse, O');
8. FOR EACH ei∈TempDO
9. flag =FALSE;
10. FOR EACH ej∈Cand DO
11. IF objectei= obejctej∧tsei<tsej THEN
12. tsej = tsei, sourceej = sourceei;
13. flag = TRUE;
14. BREAK;
15. END IF
16. END FOR
17. IF flag = FALSE THEN
18. 将ei加入Cand;
19. END IF
20. END FOR
21. END WHILE
22. RETURN R.
在算法1中,变量Cand表示当前待处理的候选传染事件集合,在初始化时,首先为初始传染源Os中的每一个对象构造初始传染事件e,并加入Cand(步骤2)~4)),然后开始执行对Cand中各传染事件的循环处理(步骤5)~21)). 在每一轮的处理中,Cand中最早发生的传染事件e即为确定的传染事件,直接从Cand移入传染事件结果集R(步骤6));调用SWAnalyze函数,获取由e中新确定的传染源objecte所引发的所有潜在传染事件构成的集合Temp(步骤7));将Temp中的传染事件加入Cand(步骤8)~20)),对于Temp中的每一个传染事件ei,若Cand中存在传染事件ej,满足传染对象object相同且传染事件的发生时间前者早于后者的条件,则表明发现了针对该对象的更早发生的传染事件,此时就须利用更早发生的传染事件ei去更新ej;否则,将ej直接加入Cand. 当Cand中的所有候选传染事件全部处理结束时,最终形成的集合R即为挖掘算法得到的传染事件结果集.
算法2给出了算法1中步骤7)调用的SWAnalyze函数的具体实现. 该算法采用滑动窗口机制,根据输入的一个确定传染源,挖掘由其引发的所有潜在传染事件,并将结果存储在临时传染事件集合Temp中.
算法2:SWAnalyze(Tra, τ, d, δ, obj, ts, O')
输入:轨迹数据集Tra,滑动窗口宽度阈值τ,距离阈值d,敏感度阈值δ,传染源obj,obj被传染的发生时间ts,待检测对象的集合O'
输出:临时传染事件集合Temp
1. 初始化Temp= Ø; 时间戳变量k=ts; 滑动窗口计数器数组变量count [1, 2, ···, n] = 0,其中count [i]用于统计对象oi在当前滑动窗口中与传染源obj之间的距离不大于d的采样点的数量;
2. WHILE k ≤ ts+τ−1DO //初始化滑动窗口
3. FOR EACH oi∈O' DO
4. IF Dist (obj, oi, k) ≤ d THEN
5. count [i]++;
6. IF (count [i])/τ ≥ δTHEN
7. 构造传染事件(obj, oi, k),并加入Temp;
8. O′=O′−{oi};
9. BREAK;
10. END IF
11. END IF
12. END FOR
13. k++;
14. END WHILE
15. WHILE k ≤ tm DO //滑动窗口移动处理
16. FOR EACH oi∈O′ DO
17. IF Dist (obj, oi, k)≤d∧Dist (obj, oi, k−τ)>d THEN
18. count [i]++;
19. IF (count [i])/τ ≥ δTHEN
20. 构造传染事件(obj, oi, k),并加入Temp;
21. O′=O′−{oi};
22. BREAK;
23. END IF
24. ELSE IF Dist (obj, oi, k) > d∧Dist (obj, oi, k−τ) ≤ dTHEN
25. count [i] −−;
26. END IF
27. END FOR
28. k++;
29. END WHILE
30. RETURN Temp;
由算法2可知,该算法主要包含滑动窗口初始化模块(步骤2)~14))和滑动窗口移动处理模块(步骤15)~29)). 在滑动窗口初始化过程中,对O′中每一个检测对象在从ts到ts+τ−1的时序区间内满足传染事件距离阈值要求的采样点的数量进行统计,进而完成对于滑动窗口计数器数组count []的初始化;须注意的是,在上述初始化过程中,若被检测对象满足传染事件定义要求,则创建新传染事件,并加入Temp,再将该检测对象从O′中删除(步骤6)~10)). 在滑动窗口每次移动一个单位的滑动处理过程中,根据O′中每一个检测对象在当前移出滑动窗口的时间位置和新移入滑动窗口的时间位置上,与传染源obj之间是否满足传染事件距离阈值要求的状态变化(步骤17)、24)),对时间窗口计数器数组count []进行更新(步骤18)、25));若发现被检测对象已经满足传染事件定义要求,则创建新传染事件,并加入Temp,再将该检测对象从O′中删除(步骤19)~23)).
结合算法1、2的具体执行过程,给出LIPMA算法的时间复杂度. 假设移动对象中传染源的总数量为α,每个传染源在滑动窗口移动处理过程中所经过的时间点的平均数量为β,每个时间点被检测对象的平均数量为γ,则LIPMA的时间复杂度为O(αβγ).
2.2. 基于R-tree索引的算法优化
LIPMA+的算法思想与LIPMA类似,都包含算法1的处理过程,但他们在根据新确定的传染源挖掘由其导致的传染事件的算法实现上存在差异,须将算法1的步骤7)中的SWAnalyze替换为基于R-tree的挖掘算法SWAnalyze+. 该算法中的函数Neighbor (RTree, obj, k, d)表示利用RTree索引获取在k时刻与传染源obj的距离不大于d的所有对象;滑动窗口计数器数组变量count [i]用于统计对象oi在当前滑动窗口与传染源obj之间的距离不大于d的采样点数量;滑动窗口锚点数组变量anchor [i]用于记录对象oi距离当前检测时间点最近一次与obj的距离满足传染事件阈值d要求的时间点;滑动窗口中待补全的时间点计数器数组lost [i]用于记录对象oi对应的滑动窗口中待补全的时间点数量.
SWAnalyze+算法的实现过程如下所示.
算法3:SWAnalyze+ (τ, d, δ, obj, ts, O′, RTree)
输入:τ、d、δ、obj、ts和O'的定义与算法2相同,RTree为R树索引
输出:临时传染事件集合Temp
1. 初始化Temp= NULL;候选对象集合变量C= NULL;时间戳变量k=ts; 滑动窗口计数器数组变量count [1, 2
2. WHILE k ≤ tm DO //滑动窗口移动处理
3. C=Neighbor (RTree, obj, k, d);
4. FOR EACH oi∈C DO
5. nepoints=k − anchor [i] −1;
6. IF nepoints>
7. count [i]=1, lost [i]=τ −1;
8. ELSE
9. FOR EACH j=anchor [i]+1
10. IF lost [i]=0∧Dist (obj, oi, j−τ) ≤ d THEN
11. count [i]−−;
12. ELSE IF lost [i] > 0 THEN
13. lost [i]−−;
14. END IF
15. END FOR
16. IF lost [i] > 0 THEN
17. count [i]++, lost [i]−−;
18. ELSE IF lost [i]=0∧Dist (obj, oi, k−τ)>d THEN
19. count [i]++;
20. END IF
21. IF (count [i])/τ ≥ δTHEN
22. 构造传染事件(obj, oi, k),并加入Temp;
23. O′=O′ − { oi};
24. BREAK;
25. END IF
26. END IF
27. anchor [i]=k;
28. END FOR
29. k++;
30. END WHILE
31. RETURN Temp;
在算法3中,步骤2)~30)给出了在每一个时间点上的分析处理过程. 首先,通过Neighbor函数获取在当前时间点与传染源obj的距离不大于d的所有对象构成的集合C,C中的对象均有可能在当前时间点确定被传染,又称之为潜在传染对象. 然后,针对C中的每一个对象oi,计算oi从时间点anchor[i]到当前时间点k之内不满足距离阈值要求的时间点的数量nepoints(步骤5)). 如果nepoints大于
由算法3的执行过程可知,该算法中各对象的滑动窗口在移动处理过程中的大小是可变的,他们的终止时间点相同,均为算法处理的当前时间点,但他们的起始时间点可以不相同,因此算法3中的滑动窗口是一种动态的滑动窗口. 假设每个时间点的潜在传染对象的平均数量记为ε,则LIPMA+的时间复杂度减少为O(αβε). 与算法2相比较,算法3只须对C中每一个待检测的潜在传染对象进行基于滑动窗口的分析处理,算法2则须对O′中每一个待检测对象进行处理,而|C|<|O′|,因此算法3的执行效率优于算法2.
3. 实验结果
本研究实验的硬件环境为Intel i5-6200U(4核2.3 GHz)CPU、8G内存;软件环境为64位windows 10操作系统、Visual C++. 实验参数默认设置如下:移动对象数量(即轨迹数量)n=1500,传染事件距离阈值d=50,滑动窗口宽度阈值τ=10,传染敏感度阈值δ=0.8,轨迹数据采样点数量m=1 300.
3.1. 挖掘结果实验分析
改变实验相关参数,算法LIPMA、LIPMA+和IMO挖掘的松散型传染事件数量L的变化曲线如图3所示.
图 3
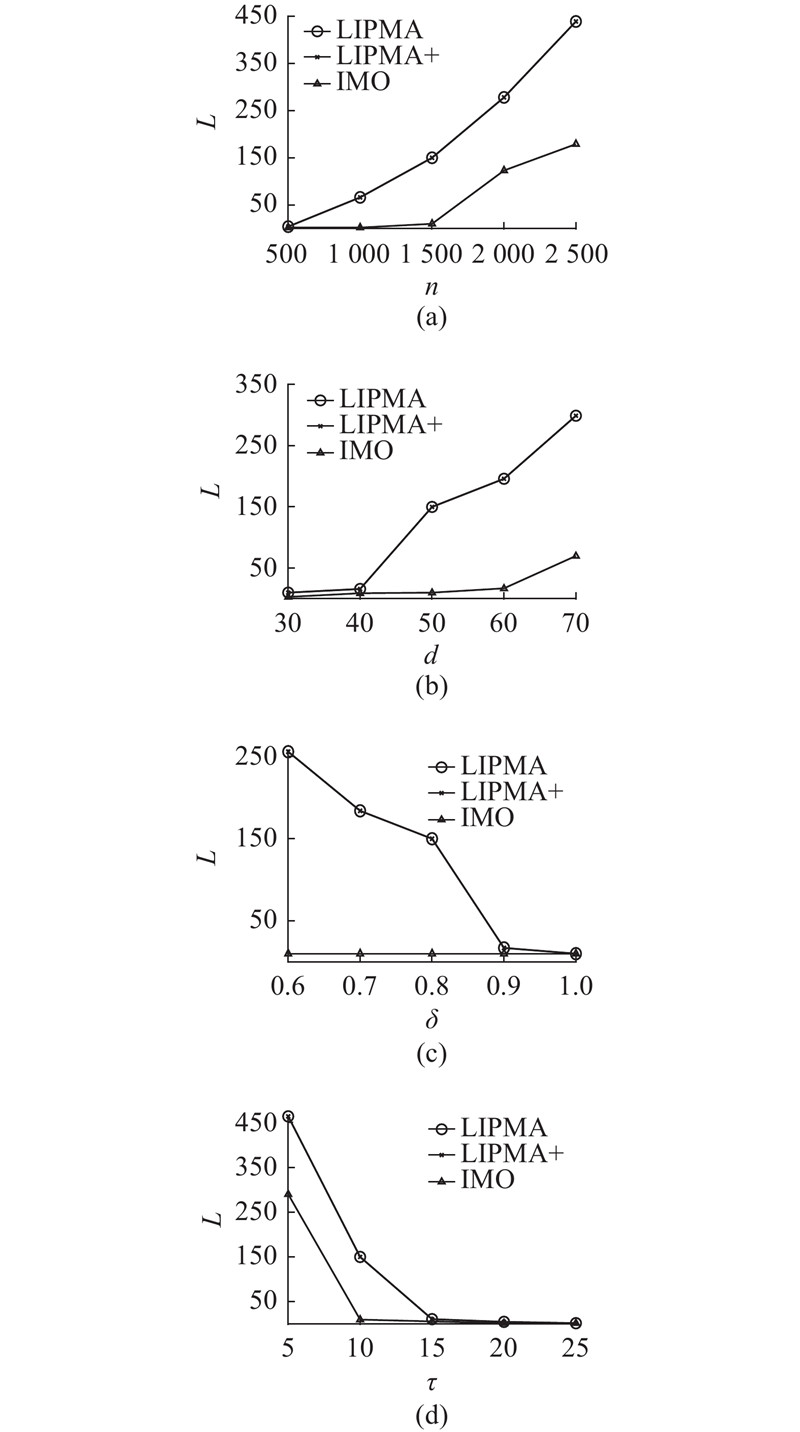
由图3(c)可知,LIPMA、LIPMA+和IMO挖掘得到的传染事件数量都随着传染事件判定的敏感度阈值δ的增大而减少. 其原因在于,δ的增大,意味着在判定传染事件时,对于单一滑动窗口中检测对象与传染源之间满足距离阈值条件的时间点数量与滑动窗口宽度阈值的比例要求增大,即判定传染事件的条件随着δ的增大而变得更加严格,这也将直接导致挖掘得到的传染事件减少. 由图3(d)可以看出,3种算法的挖掘结果也都随着滑动窗口阈值τ的增大而减少,其原因在于τ的增大,使得传染事件定义中的滑动窗口中检测对象与传染源之间满足距离阈值条件的时间点数量增大,这也意味着判定传染事件的条件随着τ的增大而变严格,导致挖掘得到的传染事件减少.
由图3可以看出,LIPMA和LIPMA+的挖掘结果完全相同,其发现的传染事件的数量均高于IMO,这是由于IMO采用严格型传染事件定义,仅当检测对象在滑动窗口的所有时间点均满足距离阈值要求时,才能判定传染事件的发生;而本研究提出的LIPMA和LIPMA+采用的是松散型传染事件模式定义,当检测对象在滑动窗口中符合距离阈值要求的时间点的数量满足一定比例要求时,即可判定传染事件的发生,显然该约束要求更符合现实应用场景,能够挖掘更多的传染事件.
3.2. 挖掘效率实验分析
由于本研究所提出的LIPMA和LIPMA+在传染事件模式定义上与IMO并不相同,即挖掘目标在内涵上存在差异,仅给出算法LIPMA和LIPMA+挖掘效率J的变化曲线,具体实验结果如图4所示.
图 4
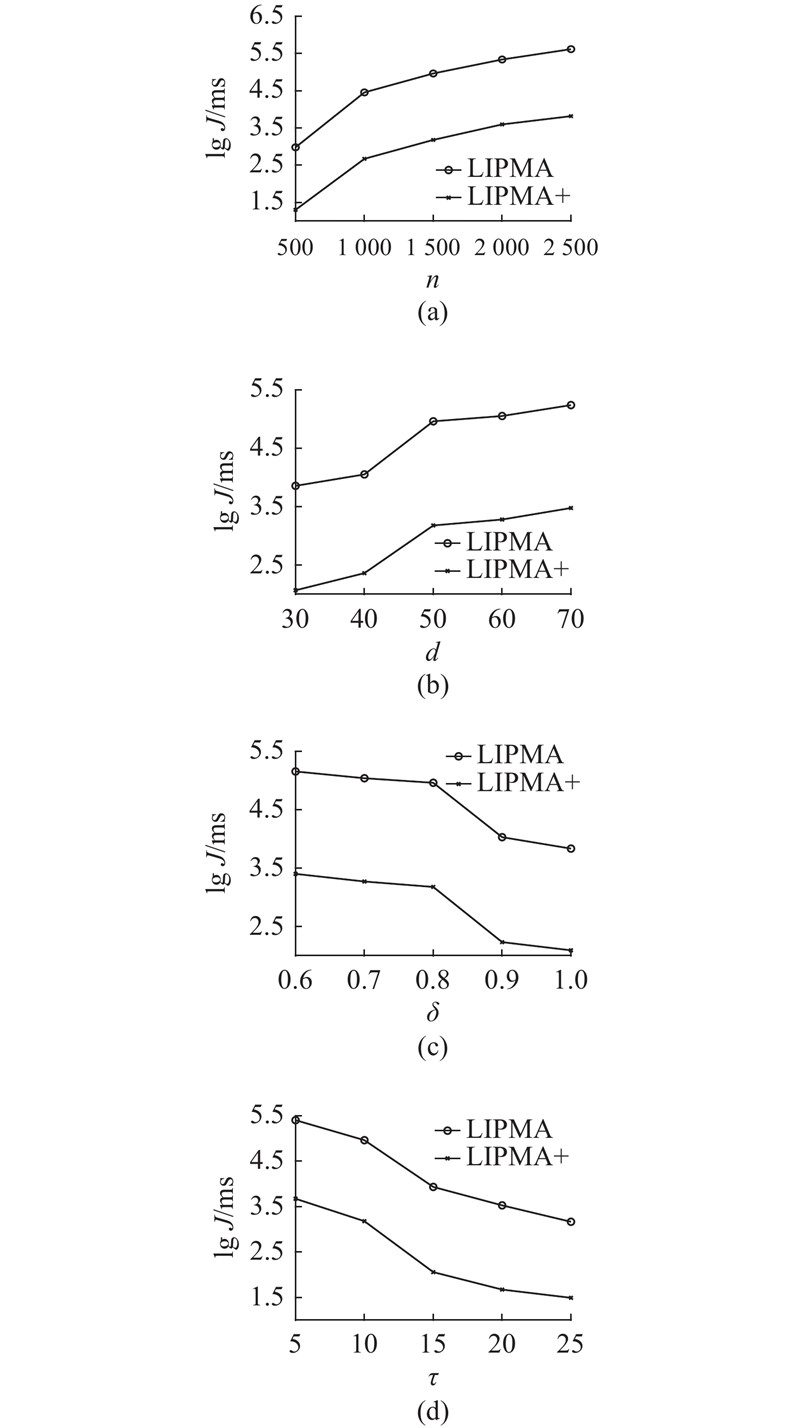
由图4(a)、(b)可以看出,LIPMA和LIPMA+算法的挖掘时间都随着n和d的增大而增大,其原因在于:当n增大时,对于每个传染源而言,在每个时间点须处理的待检测对象数也同步增多,这也使得2个算法的挖掘时间也同步增多;传染事件距离阈值d的增大意味着传染能力的增强,因此,当d增大时,在2个算法中,都将有更多的对象由于被传染而成为新的传染源,这也直接导致更多的挖掘时间的消耗.
由图4(c)、(d)可以看出,LIPMA和LIPMA+算法的挖掘时间都随着δ和τ的增大而减小,其原因在于:当δ或τ增大时,均意味着判定传染事件的条件变得更加严格,挖掘得到的传染对象减少,即算法须分析处理的传染事件总个数减少,导致2个算法的挖掘时间都同步减少.
由图4可以看出,LIPMA+算法的挖掘时间消耗均显著低于LIPMA,说明LIPMA+算法的执行效率比LIPMA高,具体而言,LIPMA+的平均挖掘时间仅为LIPMA的约2%. 这是由于LIPMA算法在每个时间点上都须对当前所有未感染对象进行分析处理,而LIPMA+算法只须对利用R-tree选取的少量潜在传染对象进行分析处理即可,这也显著降低了LIPMA+的挖掘时间消耗. 同时,本研究也对LIPMA和LIPMA+算法的存储空间进行了实验,LIPMA+针对每个移动对象都构造了R-tree索引,且每个对象平均只增加了0.12 MB大小的内存.
4. 结 语
本研究提出面向移动对象的松散型传染模式挖掘算法,实验结果表明,该算法能够发现更多的传染事件,同时优化算法进一步提高了挖掘效率. 基于移动对象的传染模式挖掘是人类在遏制病毒或病菌传播的首个且有效的途径.在后续的工作中,将从挖掘效率角度,研究优化的索引结构以及更加高效的挖掘算法.
参考文献
Animals exhibit consistent individual differences in their movement: a case study on location trajectories of Japanese macaques
[J].DOI:10.1016/j.ecoinf.2020.101057 [本文引用: 1]
Blockchain for secure and efficient data sharing in vehicular edge computing and networks
[J].DOI:10.1109/JIOT.2018.2875542 [本文引用: 1]
Influence maximization in trajectory databases
[J].
一类具有logistic增长的随机SIRS传染病模型的平稳分布和灭绝性
[J].DOI:10.3969/j.issn.1007-9831.2020.10.004 [本文引用: 1]
Stationary distribution and extinction of a stochastic SIRS epidemic model with logistic growth
[J].DOI:10.3969/j.issn.1007-9831.2020.10.004 [本文引用: 1]
A distributed flocking control strategy for UAV groups
[J].DOI:10.1016/j.comcom.2020.01.076 [本文引用: 1]
Discovery of convoys in trajectory databases
[J].DOI:10.14778/1453856.1453971 [本文引用: 1]
k/2-hop: fast mining of convoy patterns with effective pruning
[J].DOI:10.14778/3329772.3329773 [本文引用: 1]
Convoy movement problem: a civilian perspective
[J].
Swarm: mining relaxed temporal moving object clusters
[J].
Solving multi-objective problems using bird swarm algorithm
[J].DOI:10.1109/ACCESS.2021.3063218 [本文引用: 1]
Predictive trajectory-based mobile data gathering scheme for wireless sensor networks
[J].
A dynamic hierarchical clustering data gathering algorithm based on multiple criteria decision making for 3D underwater sensor networks
[J].
A framework of loose travelling companion discovery from human trajectories
[J].DOI:10.1109/TMC.2018.2813369 [本文引用: 3]
IMO: a toolbox for simulating and querying “infected” moving objects
[J].DOI:10.14778/3415478.3415485 [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}